diff --git a/.github/workflows/develop.yml b/.github/workflows/develop.yml
index d0d2804c6a..65546dcc25 100644
--- a/.github/workflows/develop.yml
+++ b/.github/workflows/develop.yml
@@ -669,18 +669,28 @@ jobs:
- name: "Basic"
opts: ""
kafka: false
+ postgres: false
+ mysql: false
- name: "Remote WAL"
opts: "-w kafka -k 127.0.0.1:9092"
kafka: true
+ postgres: false
+ mysql: false
- name: "PostgreSQL KvBackend"
- opts: "--setup-pg"
+ opts: "--setup-pg postgresql://greptimedb:admin@127.0.0.1:5432/postgres"
kafka: false
- - name: "MySQL Kvbackend"
- opts: "--setup-mysql"
+ postgres: true
+ mysql: false
+ - name: "MySQL KvBackend"
+ opts: "--setup-mysql mysql://greptimedb:admin@127.0.0.1:3306/mysql"
kafka: false
+ postgres: false
+ mysql: true
- name: "Flat format"
opts: "--enable-flat-format"
kafka: false
+ postgres: false
+ mysql: false
timeout-minutes: 60
steps:
- uses: actions/checkout@v4
@@ -688,9 +698,19 @@ jobs:
persist-credentials: false
- if: matrix.mode.kafka
- name: Setup kafka server
+ name: Setup Kafka
working-directory: tests-integration/fixtures
- run: ../../.github/scripts/pull-test-deps-images.sh && docker compose up -d --wait kafka
+ run: ../../.github/scripts/pull-test-deps-images.sh && docker compose up -d --wait kafka
+
+ - if: matrix.mode.postgres
+ name: Setup PostgreSQL
+ working-directory: tests-integration/fixtures
+ run: ../../.github/scripts/pull-test-deps-images.sh && docker compose up -d --wait postgres
+
+ - if: matrix.mode.mysql
+ name: Setup MySQL
+ working-directory: tests-integration/fixtures
+ run: ../../.github/scripts/pull-test-deps-images.sh && docker compose up -d --wait mysql
- name: Download pre-built binaries
uses: actions/download-artifact@v4
diff --git a/.github/workflows/nightly-jsonbench.yaml b/.github/workflows/nightly-jsonbench.yaml
new file mode 100644
index 0000000000..3667ee26a6
--- /dev/null
+++ b/.github/workflows/nightly-jsonbench.yaml
@@ -0,0 +1,162 @@
+name: Nightly JSONBench
+
+on:
+ schedule:
+ # Trigger at 00:00(Asia/Shanghai) on every weekday.
+ - cron: "0 16 * * 0-4"
+ workflow_dispatch:
+
+concurrency:
+ group: ${{ github.workflow }}-${{ github.head_ref || github.run_id }}
+ cancel-in-progress: true
+
+jobs:
+ allocate-runner:
+ name: Allocate runner
+ if: ${{ github.repository == 'GreptimeTeam/greptimedb' }}
+ runs-on: ubuntu-latest
+ outputs:
+ linux-arm64-runner: ${{ steps.start-linux-arm64-runner.outputs.label }}
+
+ # The following EC2 resource id will be used for resource releasing.
+ linux-arm64-ec2-runner-label: ${{ steps.start-linux-arm64-runner.outputs.label }}
+ linux-arm64-ec2-runner-instance-id: ${{ steps.start-linux-arm64-runner.outputs.ec2-instance-id }}
+ steps:
+ - name: Checkout
+ uses: actions/checkout@v4
+ with:
+ fetch-depth: 0
+ persist-credentials: false
+
+ - name: Allocate Linux ARM64 runner
+ uses: ./.github/actions/start-runner
+ id: start-linux-arm64-runner
+ with:
+ runner: ${{ vars.DEFAULT_ARM64_RUNNER }}
+ aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
+ aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
+ aws-region: ${{ vars.EC2_RUNNER_REGION }}
+ github-token: ${{ secrets.GH_PERSONAL_ACCESS_TOKEN }}
+ image-id: ${{ vars.EC2_RUNNER_LINUX_ARM64_IMAGE_ID }}
+ security-group-id: ${{ vars.EC2_RUNNER_SECURITY_GROUP_ID }}
+ subnet-id: ${{ vars.EC2_RUNNER_SUBNET_ID }}
+
+ jsonbench:
+ name: Run JSONBench
+ if: ${{ github.repository == 'GreptimeTeam/greptimedb' }}
+ needs: [ allocate-runner ]
+ runs-on: ${{ needs.allocate-runner.outputs.linux-arm64-runner }}
+ timeout-minutes: 120
+ env:
+ JSONBENCH_DATA_DIR: /home/runner/data/bluesky
+ JSONBENCH_OUTPUT_PREFIX: _ubuntu-latest
+ steps:
+ - name: Checkout
+ uses: actions/checkout@v4
+ with:
+ fetch-depth: 0
+ persist-credentials: false
+
+ - uses: arduino/setup-protoc@v3
+ with:
+ repo-token: ${{ secrets.GITHUB_TOKEN }}
+
+ - uses: actions-rust-lang/setup-rust-toolchain@v1
+
+ - name: Rust Cache
+ uses: Swatinem/rust-cache@v2
+ with:
+ shared-key: "nightly-jsonbench"
+ cache-all-crates: "true"
+ save-if: ${{ github.ref == 'refs/heads/main' }}
+
+ - name: Build GreptimeDB
+ run: cargo build --profile nightly --bin greptime
+
+ - name: Reclaim disk space
+ shell: bash
+ run: |
+ set -euo pipefail
+
+ mkdir -p "${RUNNER_TEMP}/greptimedb-bin"
+ cp ./target/nightly/greptime "${RUNNER_TEMP}/greptimedb-bin/greptime"
+ chmod +x "${RUNNER_TEMP}/greptimedb-bin/greptime"
+
+ rm -rf ./target
+
+ - name: Run JSONBench
+ shell: bash
+ run: |
+ set -euo pipefail
+
+ cd "${RUNNER_TEMP}"
+ cp "${RUNNER_TEMP}/greptimedb-bin/greptime" ./greptime
+ chmod +x ./greptime
+
+ export GREPTIMEDB_STANDALONE__WAL__DIR=greptimedb_data/wal
+ export GREPTIMEDB_STANDALONE__STORAGE__DATA_HOME=greptimedb_data
+ export GREPTIMEDB_STANDALONE__LOGGING__DIR=greptimedb_data/logs
+ export GREPTIMEDB_STANDALONE__LOGGING__APPEND_STDOUT=false
+ export GREPTIMEDB_STANDALONE__HTTP__BODY_LIMIT=1GB
+ export GREPTIMEDB_STANDALONE__HTTP__TIMEOUT=500s
+
+ ./greptime standalone start > greptimedb.log 2>&1 &
+ greptime_pid=$!
+ trap 'kill "${greptime_pid}" 2>/dev/null || true' EXIT
+
+ until curl -s --fail -o /dev/null http://localhost:4000/health; do
+ if ! kill -0 "${greptime_pid}" 2>/dev/null; then
+ cat greptimedb.log
+ exit 1
+ fi
+ sleep 1
+ done
+
+ git clone --branch greptimedb-new-json --depth 1 https://github.com/GreptimeTeam/JSONBench.git JSONBench
+ cp ./greptime JSONBench/greptimedb/greptime
+
+ cd JSONBench/greptimedb
+ ./main.sh 3 "${JSONBENCH_DATA_DIR}" success.log error.log "${JSONBENCH_OUTPUT_PREFIX}" false
+
+ - name: Upload JSONBench results
+ if: always()
+ uses: actions/upload-artifact@v4
+ with:
+ name: jsonbench-results
+ path: |
+ ${{ runner.temp }}/greptimedb.log
+ ${{ runner.temp }}/JSONBench/greptimedb/*.log
+ ${{ runner.temp }}/JSONBench/greptimedb/*.total_size
+ ${{ runner.temp }}/JSONBench/greptimedb/*.data_size
+ ${{ runner.temp }}/JSONBench/greptimedb/*.index_size
+ ${{ runner.temp }}/JSONBench/greptimedb/*.count
+ ${{ runner.temp }}/JSONBench/greptimedb/*.results_runtime
+ ${{ runner.temp }}/JSONBench/greptimedb/*.query_results
+ if-no-files-found: ignore
+ retention-days: 7
+
+ stop-linux-arm64-runner:
+ name: Stop Linux ARM64 runner
+ # It's always run as the last job in the workflow to make sure that the runner is released.
+ if: ${{ always() }}
+ runs-on: ubuntu-latest
+ needs: [
+ allocate-runner,
+ jsonbench,
+ ]
+ steps:
+ - name: Checkout
+ uses: actions/checkout@v4
+ with:
+ fetch-depth: 0
+ persist-credentials: false
+
+ - name: Stop Linux ARM64 runner
+ uses: ./.github/actions/stop-runner
+ with:
+ label: ${{ needs.allocate-runner.outputs.linux-arm64-ec2-runner-label }}
+ ec2-instance-id: ${{ needs.allocate-runner.outputs.linux-arm64-ec2-runner-instance-id }}
+ aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
+ aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
+ aws-region: ${{ vars.EC2_RUNNER_REGION }}
+ github-token: ${{ secrets.GH_PERSONAL_ACCESS_TOKEN }}
diff --git a/Cargo.lock b/Cargo.lock
index aafa225b4b..63ba289947 100644
--- a/Cargo.lock
+++ b/Cargo.lock
@@ -1321,9 +1321,9 @@ dependencies = [
[[package]]
name = "bitpacking"
-version = "0.9.2"
+version = "0.9.3"
source = "registry+https://github.com/rust-lang/crates.io-index"
-checksum = "4c1d3e2bfd8d06048a179f7b17afc3188effa10385e7b00dc65af6aae732ea92"
+checksum = "96a7139abd3d9cebf8cd6f920a389cf3dc9576172e32f4563f188cae3c3eb019"
dependencies = [
"crunchy",
]
@@ -1832,7 +1832,7 @@ source = "registry+https://github.com/rust-lang/crates.io-index"
checksum = "c7d8d1efd5109b9c1cd3b7966bd071cdfb53bb6eb0b22a473a68c2f70a11a1eb"
dependencies = [
"parse-zoneinfo",
- "phf_codegen",
+ "phf_codegen 0.12.1",
"phf_shared 0.12.1",
"uncased",
]
@@ -4380,6 +4380,12 @@ dependencies = [
"tracing",
]
+[[package]]
+name = "datasketches"
+version = "0.2.0"
+source = "registry+https://github.com/rust-lang/crates.io-index"
+checksum = "c286de4e81ea2590afc24d754e0f83810c566f50a1388fa75ebd57928c0d9745"
+
[[package]]
name = "datatypes"
version = "1.1.0"
@@ -5486,12 +5492,12 @@ dependencies = [
[[package]]
name = "fs4"
-version = "0.8.4"
+version = "0.13.1"
source = "registry+https://github.com/rust-lang/crates.io-index"
-checksum = "f7e180ac76c23b45e767bd7ae9579bc0bb458618c4bc71835926e098e61d15f8"
+checksum = "8640e34b88f7652208ce9e88b1a37a2ae95227d84abec377ccd3c5cfeb141ed4"
dependencies = [
- "rustix 0.38.44",
- "windows-sys 0.52.0",
+ "rustix 1.0.7",
+ "windows-sys 0.59.0",
]
[[package]]
@@ -5820,7 +5826,7 @@ dependencies = [
[[package]]
name = "greptime-proto"
version = "0.1.0"
-source = "git+https://github.com/GreptimeTeam/greptime-proto.git?rev=dfd2a6d7d3d9c718cb159fcf9abae144b74fc503#dfd2a6d7d3d9c718cb159fcf9abae144b74fc503"
+source = "git+https://github.com/GreptimeTeam/greptime-proto.git?rev=7224c2ad6d11db612fbdb621c36135fc37ffce35#7224c2ad6d11db612fbdb621c36135fc37ffce35"
dependencies = [
"prost 0.14.1",
"prost-types 0.14.1",
@@ -6564,27 +6570,37 @@ checksum = "cb56e1aa765b4b4f3aadfab769793b7087bb03a4ea4920644a6d238e2df5b9ed"
[[package]]
name = "include-flate"
-version = "0.3.0"
+version = "0.3.3"
source = "registry+https://github.com/rust-lang/crates.io-index"
-checksum = "df49c16750695486c1f34de05da5b7438096156466e7f76c38fcdf285cf0113e"
+checksum = "23e233413926ef735f7d87024466cfda5a4b87467730846bd82ea7d504121347"
dependencies = [
"include-flate-codegen",
- "lazy_static",
- "libflate",
+ "include-flate-compress",
]
[[package]]
name = "include-flate-codegen"
-version = "0.2.0"
+version = "0.3.3"
source = "registry+https://github.com/rust-lang/crates.io-index"
-checksum = "8c5b246c6261be723b85c61ecf87804e8ea4a35cb68be0ff282ed84b95ffe7d7"
+checksum = "5e7148f24ef8922cc0e5574ebb908729ccdd3a110c440a45165733fedadd9969"
dependencies = [
- "libflate",
+ "include-flate-compress",
+ "proc-macro-error2",
"proc-macro2",
"quote",
"syn 2.0.117",
]
+[[package]]
+name = "include-flate-compress"
+version = "0.3.3"
+source = "registry+https://github.com/rust-lang/crates.io-index"
+checksum = "74783a9ed407e844e99d5e7a57bd650acbfa124cf6e97ffd790ba59d8ab8e7ff"
+dependencies = [
+ "libflate",
+ "zstd",
+]
+
[[package]]
name = "include_dir"
version = "0.7.4"
@@ -6918,25 +6934,25 @@ checksum = "4a5f13b858c8d314ee3e8f639011f7ccefe71f97f96e50151fb991f267928e2c"
[[package]]
name = "jieba-macros"
-version = "0.8.0"
+version = "0.10.0"
source = "registry+https://github.com/rust-lang/crates.io-index"
-checksum = "6105f38f083bb1a79ad523bd32fa0d8ffcb6abd2fc4da9da203c32bca5b6ace3"
+checksum = "661344b2412fb00aee1841d2405c9a31f7c91cf6e578a8e953647c43dd1a8b0a"
dependencies = [
- "phf_codegen",
+ "phf_codegen 0.13.1",
]
[[package]]
name = "jieba-rs"
-version = "0.8.0"
+version = "0.10.0"
source = "registry+https://github.com/rust-lang/crates.io-index"
-checksum = "47982a320106da83b0c5d6aec0fb83e109f0132b69670b063adaa6fa5b4f3f4a"
+checksum = "d7ef90d6209fcff084a01b488c4199d882e3764b15ff0e7a6b5d7efaa46e1e4f"
dependencies = [
"cedarwood",
- "fxhash",
"include-flate",
"jieba-macros",
- "phf 0.12.1",
+ "phf 0.13.1",
"regex",
+ "rustc-hash 2.1.1",
]
[[package]]
@@ -7483,25 +7499,25 @@ checksum = "bcc35a38544a891a5f7c865aca548a982ccb3b8650a5b06d0fd33a10283c56fc"
[[package]]
name = "libflate"
-version = "2.1.0"
+version = "2.3.0"
source = "registry+https://github.com/rust-lang/crates.io-index"
-checksum = "45d9dfdc14ea4ef0900c1cddbc8dcd553fbaacd8a4a282cf4018ae9dd04fb21e"
+checksum = "cd96e993e5f3368b0cb8497dae6c860c22af8ff18388c61c6c0b86c58d86b5df"
dependencies = [
"adler32",
- "core2",
"crc32fast",
"dary_heap",
"libflate_lz77",
+ "no_std_io2",
]
[[package]]
name = "libflate_lz77"
-version = "2.1.0"
+version = "2.3.0"
source = "registry+https://github.com/rust-lang/crates.io-index"
-checksum = "e6e0d73b369f386f1c44abd9c570d5318f55ccde816ff4b562fa452e5182863d"
+checksum = "ff7a10e427698aef6eef269482776debfef63384d30f13aad39a1a95e0e098fd"
dependencies = [
- "core2",
- "hashbrown 0.14.5",
+ "hashbrown 0.16.1",
+ "no_std_io2",
"rle-decode-fast",
]
@@ -7816,6 +7832,15 @@ dependencies = [
"hashbrown 0.15.4",
]
+[[package]]
+name = "lru"
+version = "0.16.4"
+source = "registry+https://github.com/rust-lang/crates.io-index"
+checksum = "7f66e8d5d03f609abc3a39e6f08e4164ebf1447a732906d39eb9b99b7919ef39"
+dependencies = [
+ "hashbrown 0.16.1",
+]
+
[[package]]
name = "lru-slab"
version = "0.1.2"
@@ -8299,6 +8324,7 @@ dependencies = [
"either",
"futures",
"greptime-proto",
+ "humantime",
"humantime-serde",
"index",
"itertools 0.14.0",
@@ -8434,7 +8460,7 @@ dependencies = [
"flate2",
"io-enum",
"libc",
- "lru",
+ "lru 0.12.5",
"mysql_common 0.34.1",
"named_pipe",
"pem",
@@ -8497,7 +8523,7 @@ dependencies = [
"futures-sink",
"futures-util",
"keyed_priority_queue",
- "lru",
+ "lru 0.12.5",
"mysql_common 0.34.1",
"pem",
"percent-encoding",
@@ -8695,6 +8721,15 @@ dependencies = [
"libc",
]
+[[package]]
+name = "no_std_io2"
+version = "0.9.4"
+source = "registry+https://github.com/rust-lang/crates.io-index"
+checksum = "418abd1b6d34fbf6cae440dc874771b0525a604428704c76e48b29a5e67b8003"
+dependencies = [
+ "memchr",
+]
+
[[package]]
name = "nohash"
version = "0.2.0"
@@ -9635,6 +9670,15 @@ dependencies = [
"serde",
]
+[[package]]
+name = "ordered-float"
+version = "5.3.0"
+source = "registry+https://github.com/rust-lang/crates.io-index"
+checksum = "b7d950ca161dc355eaf28f82b11345ed76c6e1f6eb1f4f4479e0323b9e2fbd0e"
+dependencies = [
+ "num-traits",
+]
+
[[package]]
name = "ordered-multimap"
version = "0.4.3"
@@ -10122,6 +10166,15 @@ checksum = "913273894cec178f401a31ec4b656318d95473527be05c0752cc41cdc32be8b7"
dependencies = [
"phf_macros",
"phf_shared 0.12.1",
+]
+
+[[package]]
+name = "phf"
+version = "0.13.1"
+source = "registry+https://github.com/rust-lang/crates.io-index"
+checksum = "c1562dc717473dbaa4c1f85a36410e03c047b2e7df7f45ee938fbef64ae7fadf"
+dependencies = [
+ "phf_shared 0.13.1",
"serde",
]
@@ -10131,10 +10184,20 @@ version = "0.12.1"
source = "registry+https://github.com/rust-lang/crates.io-index"
checksum = "efbdcb6f01d193b17f0b9c3360fa7e0e620991b193ff08702f78b3ce365d7e61"
dependencies = [
- "phf_generator",
+ "phf_generator 0.12.1",
"phf_shared 0.12.1",
]
+[[package]]
+name = "phf_codegen"
+version = "0.13.1"
+source = "registry+https://github.com/rust-lang/crates.io-index"
+checksum = "49aa7f9d80421bca176ca8dbfebe668cc7a2684708594ec9f3c0db0805d5d6e1"
+dependencies = [
+ "phf_generator 0.13.1",
+ "phf_shared 0.13.1",
+]
+
[[package]]
name = "phf_generator"
version = "0.12.1"
@@ -10145,13 +10208,23 @@ dependencies = [
"phf_shared 0.12.1",
]
+[[package]]
+name = "phf_generator"
+version = "0.13.1"
+source = "registry+https://github.com/rust-lang/crates.io-index"
+checksum = "135ace3a761e564ec88c03a77317a7c6b80bb7f7135ef2544dbe054243b89737"
+dependencies = [
+ "fastrand",
+ "phf_shared 0.13.1",
+]
+
[[package]]
name = "phf_macros"
version = "0.12.1"
source = "registry+https://github.com/rust-lang/crates.io-index"
checksum = "d713258393a82f091ead52047ca779d37e5766226d009de21696c4e667044368"
dependencies = [
- "phf_generator",
+ "phf_generator 0.12.1",
"phf_shared 0.12.1",
"proc-macro2",
"quote",
@@ -10178,6 +10251,15 @@ dependencies = [
"uncased",
]
+[[package]]
+name = "phf_shared"
+version = "0.13.1"
+source = "registry+https://github.com/rust-lang/crates.io-index"
+checksum = "e57fef6bc5981e38c2ce2d63bfa546861309f875b8a75f092d1d54ae2d64f266"
+dependencies = [
+ "siphasher",
+]
+
[[package]]
name = "pin-project"
version = "1.1.10"
@@ -11415,16 +11497,6 @@ version = "0.10.0"
source = "registry+https://github.com/rust-lang/crates.io-index"
checksum = "0c8d0fd677905edcbeedbf2edb6494d676f0e98d54d5cf9bda0b061cb8fb8aba"
-[[package]]
-name = "rand_distr"
-version = "0.4.3"
-source = "registry+https://github.com/rust-lang/crates.io-index"
-checksum = "32cb0b9bc82b0a0876c2dd994a7e7a2683d3e7390ca40e6886785ef0c7e3ee31"
-dependencies = [
- "num-traits",
- "rand 0.8.5",
-]
-
[[package]]
name = "rand_xorshift"
version = "0.4.0"
@@ -12705,6 +12777,7 @@ dependencies = [
"metric-engine",
"mime_guess",
"mysql_async",
+ "mysql_common 0.34.1",
"notify",
"object-pool",
"once_cell",
@@ -12960,9 +13033,9 @@ checksum = "56199f7ddabf13fe5074ce809e7d3f42b42ae711800501b5b16ea82ad029c39d"
[[package]]
name = "sketches-ddsketch"
-version = "0.3.0"
+version = "0.4.0"
source = "registry+https://github.com/rust-lang/crates.io-index"
-checksum = "c1e9a774a6c28142ac54bb25d25562e6bcf957493a184f15ad4eebccb23e410a"
+checksum = "05e40b6cf54d988dc1a2223531b969c9a9e30906ad90ef64890c27b4bfbb46ea"
dependencies = [
"serde",
]
@@ -13863,9 +13936,9 @@ checksum = "7b2093cf4c8eb1e67749a6762251bc9cd836b6fc171623bd0a9d324d37af2417"
[[package]]
name = "tantivy"
-version = "0.24.2"
+version = "0.26.1"
source = "registry+https://github.com/rust-lang/crates.io-index"
-checksum = "64a966cb0e76e311f09cf18507c9af192f15d34886ee43d7ba7c7e3803660c43"
+checksum = "edde6a10743fff00a4e1a8c9ef020bf5f3cbad301b7d2d39f2b07f123c4eac07"
dependencies = [
"aho-corasick",
"arc-swap",
@@ -13876,17 +13949,17 @@ dependencies = [
"census",
"crc32fast",
"crossbeam-channel",
+ "datasketches",
"downcast-rs",
"fastdivide",
"fnv",
"fs4",
"htmlescape",
- "hyperloglogplus",
"itertools 0.14.0",
"levenshtein_automata",
"log",
- "lru",
- "lz4_flex 0.11.6",
+ "lru 0.16.4",
+ "lz4_flex 0.13.1",
"measure_time",
"memmap2",
"once_cell",
@@ -13909,6 +13982,7 @@ dependencies = [
"tempfile",
"thiserror 2.0.17",
"time",
+ "typetag",
"uuid",
"winapi",
"zstd",
@@ -13916,18 +13990,18 @@ dependencies = [
[[package]]
name = "tantivy-bitpacker"
-version = "0.8.0"
+version = "0.10.0"
source = "registry+https://github.com/rust-lang/crates.io-index"
-checksum = "1adc286a39e089ae9938935cd488d7d34f14502544a36607effd2239ff0e2494"
+checksum = "4fed3d674429bcd2de5d0a6d1aa5495fed8afd9c5ecce993019caf7615f53fa4"
dependencies = [
"bitpacking",
]
[[package]]
name = "tantivy-columnar"
-version = "0.5.0"
+version = "0.7.0"
source = "registry+https://github.com/rust-lang/crates.io-index"
-checksum = "6300428e0c104c4f7db6f95b466a6f5c1b9aece094ec57cdd365337908dc7344"
+checksum = "c57166f5bcfd478f370ab8445afb4678dce44801fa5ce5c451aaf8595583c5dc"
dependencies = [
"downcast-rs",
"fastdivide",
@@ -13941,9 +14015,9 @@ dependencies = [
[[package]]
name = "tantivy-common"
-version = "0.9.0"
+version = "0.11.0"
source = "registry+https://github.com/rust-lang/crates.io-index"
-checksum = "e91b6ea6090ce03dc72c27d0619e77185d26cc3b20775966c346c6d4f7e99d7f"
+checksum = "bbf10915aa75da3c3b0d58b58853d2e889efbaf32d4982a4c3715dde6bba23e5"
dependencies = [
"async-trait",
"byteorder",
@@ -13965,9 +14039,9 @@ dependencies = [
[[package]]
name = "tantivy-jieba"
-version = "0.16.0"
+version = "0.20.0"
source = "registry+https://github.com/rust-lang/crates.io-index"
-checksum = "3b08147cc130e323ecc522117927b198bec617fe1df562a0b6449905858d0363"
+checksum = "3392170e86f1c387170aba7d171a466ffdc98a8b55b006e19ac64b123a7b690a"
dependencies = [
"jieba-rs",
"lazy_static",
@@ -13976,20 +14050,22 @@ dependencies = [
[[package]]
name = "tantivy-query-grammar"
-version = "0.24.0"
+version = "0.26.0"
source = "registry+https://github.com/rust-lang/crates.io-index"
-checksum = "e810cdeeebca57fc3f7bfec5f85fdbea9031b2ac9b990eb5ff49b371d52bbe6a"
+checksum = "dfadb8526b6da90704feb293b0701a6aae62ea14983143344be2dc5ce30f1d82"
dependencies = [
+ "fnv",
"nom 7.1.3",
+ "ordered-float 5.3.0",
"serde",
"serde_json",
]
[[package]]
name = "tantivy-sstable"
-version = "0.5.0"
+version = "0.7.0"
source = "registry+https://github.com/rust-lang/crates.io-index"
-checksum = "709f22c08a4c90e1b36711c1c6cad5ae21b20b093e535b69b18783dd2cb99416"
+checksum = "8a2cfc3ac5164cbadc28965ffb145a8f47582a60ae5897859ad8d4316596c606"
dependencies = [
"futures-util",
"itertools 0.14.0",
@@ -14001,20 +14077,19 @@ dependencies = [
[[package]]
name = "tantivy-stacker"
-version = "0.5.0"
+version = "0.7.0"
source = "registry+https://github.com/rust-lang/crates.io-index"
-checksum = "2bcdebb267671311d1e8891fd9d1301803fdb8ad21ba22e0a30d0cab49ba59c1"
+checksum = "6cbb051742da9d53ca9e8fff43a9b10e319338b24e2c0e15d0372df19ffeb951"
dependencies = [
"murmurhash32",
- "rand_distr",
"tantivy-common",
]
[[package]]
name = "tantivy-tokenizer-api"
-version = "0.5.0"
+version = "0.7.0"
source = "registry+https://github.com/rust-lang/crates.io-index"
-checksum = "dfa942fcee81e213e09715bbce8734ae2180070b97b33839a795ba1de201547d"
+checksum = "eac258c2c6390673f2685813afeeafcb8c4e0ee7de8dd3fc46838dcc37263f98"
dependencies = [
"serde",
]
@@ -15017,9 +15092,9 @@ checksum = "1dccffe3ce07af9386bfd29e80c0ab1a8205a2fc34e4bcd40364df902cfa8f3f"
[[package]]
name = "typetag"
-version = "0.2.20"
+version = "0.2.22"
source = "registry+https://github.com/rust-lang/crates.io-index"
-checksum = "73f22b40dd7bfe8c14230cf9702081366421890435b2d625fa92b4acc4c3de6f"
+checksum = "c5a897b12c6c1151ad0b138b8db50252dc301f93bc3b027db05eec82aeed298c"
dependencies = [
"erased-serde",
"inventory",
@@ -15030,9 +15105,9 @@ dependencies = [
[[package]]
name = "typetag-impl"
-version = "0.2.20"
+version = "0.2.22"
source = "registry+https://github.com/rust-lang/crates.io-index"
-checksum = "35f5380909ffc31b4de4f4bdf96b877175a016aa2ca98cee39fcfd8c4d53d952"
+checksum = "cf808357c6ed7e13ba0f3277ec8d8f21b2d501274895104263985330c726c1c5"
dependencies = [
"proc-macro2",
"quote",
diff --git a/Cargo.toml b/Cargo.toml
index eeddc7099f..32407f31cf 100644
--- a/Cargo.toml
+++ b/Cargo.toml
@@ -158,7 +158,7 @@ fs2 = "0.4"
fst = "0.4.7"
futures = "0.3"
futures-util = "0.3"
-greptime-proto = { git = "https://github.com/GreptimeTeam/greptime-proto.git", rev = "dfd2a6d7d3d9c718cb159fcf9abae144b74fc503" }
+greptime-proto = { git = "https://github.com/GreptimeTeam/greptime-proto.git", rev = "7224c2ad6d11db612fbdb621c36135fc37ffce35" }
hex = "0.4"
http = "1"
humantime = "2.1"
diff --git a/README.md b/README.md
index 4ed99fa306..127dd1ba85 100644
--- a/README.md
+++ b/README.md
@@ -9,7 +9,7 @@
One database for metrics, logs, and traces
replacing Prometheus, Loki, and Elasticsearch
-> The unified OpenTelemetry backend — with SQL + PromQL on object storage.
+> The unified OpenTelemetry backend — with SQL + PromQL on object storage.
@@ -30,11 +30,11 @@ replacing Prometheus, Loki, and Elasticsearch
 -
-
-
- +
+
+
+ -
-
-
- +
+
+
+
@@ -51,7 +51,8 @@ replacing Prometheus, Loki, and Elasticsearch
- [Introduction](#introduction)
-- [⭐ Key Features](#features)
+- [Overview](#overview)
+- [Features](#features)
- [How GreptimeDB Compares](#how-greptimedb-compares)
- [Architecture](#architecture)
- [Try GreptimeDB](#try-greptimedb)
@@ -69,37 +70,47 @@ replacing Prometheus, Loki, and Elasticsearch
**GreptimeDB** is an open-source observability database built for [Observability 2.0](https://docs.greptime.com/user-guide/concepts/observability-2/) — treating metrics, logs, and traces as one unified data model (wide events) instead of three separate pillars.
-Use it as the single OpenTelemetry backend — replacing Prometheus, Loki, and Elasticsearch with one database built on object storage. Query with SQL and PromQL, scale without pain, cut costs up to 50x.
+Use it as the single OpenTelemetry backend — replacing Prometheus, Loki, and Elasticsearch with one database built on object storage. Query with SQL and PromQL, scale without pain, cut costs up to 50×.
+
+## Overview
+
+A quick overview of what GreptimeDB ingests, how it connects to other systems, and what its distributed engine lets you do.
+
+
+
+  +
+
+
+
## Features
-| Feature | Description |
-| --------- | ----------- |
-| Drop-in replacement | [PromQL](https://docs.greptime.com/user-guide/query-data/promql/), [Prometheus remote write](https://docs.greptime.com/user-guide/ingest-data/for-observability/prometheus/), [Jaeger](https://docs.greptime.com/user-guide/query-data/jaeger/), and [OpenTelemetry](https://docs.greptime.com/user-guide/ingest-data/for-observability/opentelemetry/) native. Use as your single backend for all three signals, or migrate one at a time.|
-| 50x lower cost | Object storage (S3, GCS, Azure Blob etc.) as [primary storage](https://docs.greptime.com/user-guide/deployments-administration/configuration/#storage-options). Compute-storage separation scales without pain.|
-| SQL + PromQL | Monitor with [PromQL](https://docs.greptime.com/user-guide/query-data/promql), analyze with [SQL](https://docs.greptime.com/user-guide/query-data/sql). One database replaces Prometheus + your data warehouse.|
-| Sub-second at PB-EB scale | Columnar engine with [fulltext, inverted, and skipping indexes](https://docs.greptime.com/user-guide/manage-data/data-index). Written in Rust.|
+| Feature | Description |
+|---------|-------------|
+| **Observability 2.0 native** | Logs, metrics, and traces in one engine with [SQL + PromQL](https://docs.greptime.com/user-guide/query-data/overview/). Native [OpenTelemetry](https://docs.greptime.com/user-guide/ingest-data/for-observability/opentelemetry/), [Prometheus remote write](https://docs.greptime.com/user-guide/ingest-data/for-observability/prometheus/), and [Jaeger](https://docs.greptime.com/user-guide/query-data/jaeger/). Migrate one signal at a time, or use as a single backend. |
+| **Elastic compute-storage separation** | Scale reads independently with horizontal replicas. Serve high-concurrency workloads from dashboards, alerting, and AI agents — without resharding or data migration. |
+| **Sub-second on PB–EB-scale data** | Columnar engine with [fulltext, inverted, and skipping indexes](https://docs.greptime.com/user-guide/manage-data/data-index). Written in Rust. Designed for high-concurrency point queries, not just analytical scans. |
+| **50× lower cost** | Object storage (S3, GCS, Azure Blob) as [primary storage](https://docs.greptime.com/user-guide/deployments-administration/configuration/#storage-options), with a tiered cache (memory + local disk) to keep writes and queries fast. |
- ✅ **Perfect for:**
- * Replacing Prometheus + Loki + Elasticsearch with one database
+**Perfect for:**
+ * Replacing Prometheus + Loki + Elasticsearch with a single observability backend
* Scaling past Prometheus — high cardinality, long-term storage, no Thanos/Mimir overhead
- * Cutting observability costs with object storage (up to 50x savings on traces, 30% on logs)
- * AI/LLM observability — store and analyze high-volume conversation data, agent traces, and token metrics via [OpenTelemetry GenAI conventions](https://opentelemetry.io/docs/specs/semconv/gen-ai/)
+ * AI/agent workloads — store GenAI telemetry ([OTel GenAI conventions](https://opentelemetry.io/docs/specs/semconv/gen-ai/)), and serve high-concurrency reads from SRE/developer agents via horizontal read replicas
+ * Cutting observability costs with object storage (up to 50× savings on traces, 30% on logs)
* Edge-to-cloud observability with unified APIs on resource-constrained devices
-> **Why Observability 2.0?** The three-pillar model (separate databases for metrics, logs, traces) creates data silos and operational complexity. GreptimeDB treats all observability data as timestamped wide events in a single columnar engine — enabling cross-signal SQL JOINs, eliminating redundant infrastructure, and naturally supporting emerging workloads like AI agent observability. Read more: [Observability 2.0 and the Database for It](https://greptime.com/blogs/2025-04-25-greptimedb-observability2-new-database).
+> **Why Observability 2.0?** Three separate databases for metrics, logs, and traces means three storage layers, three query languages, and three sets of dashboards. GreptimeDB stores all three as timestamped wide events in one columnar engine — JOIN across signals in SQL, run one stack instead of three, and ingest AI agent telemetry the same way. Read more: [Observability 2.0 and the Database for It](https://greptime.com/blogs/2025-04-25-greptimedb-observability2-new-database).
Learn more in [Why GreptimeDB](https://docs.greptime.com/user-guide/concepts/why-greptimedb).
## How GreptimeDB Compares
-| Feature | GreptimeDB | Prometheus / Thanos / Mimir | Grafana Loki | Elasticsearch |
+| Capability | GreptimeDB | Prometheus / Thanos / Mimir | Grafana Loki | Elasticsearch |
|---|---|---|---|---|
| Data types | Metrics, logs, traces | Metrics only | Logs only | Logs, traces |
| Query language | SQL + PromQL | PromQL | LogQL | Query DSL |
| Storage | Native object storage (S3, etc.) | Local disk + object storage (Thanos/Mimir) | Object storage (chunks) | Local disk |
| Scaling | Compute-storage separation, stateless nodes | Federation / Thanos / Mimir — multi-component, ops heavy | Stateless + object storage | Shard-based, ops heavy |
-| Cost efficiency | Up to 50x lower storage | High at scale | Moderate | High (inverted index overhead) |
+| Cost efficiency | Up to 50× lower storage cost | High at scale | Moderate | High (inverted index overhead) |
| OpenTelemetry | Native (metrics + logs + traces) | Partial (metrics only) | Partial (logs only) | Via instrumentation |
**Benchmarks:**
@@ -110,19 +121,26 @@ Learn more in [Why GreptimeDB](https://docs.greptime.com/user-guide/concepts/why
## Architecture
GreptimeDB can run in two modes:
-* **Standalone Mode** - Single binary for development and small deployments
-* **Distributed Mode** - Separate components for production scale:
- - Frontend: Query processing and protocol handling
- - Datanode: Data storage and retrieval
- - Metasrv: Metadata management and coordination
-
-Read the [architecture](https://docs.greptime.com/contributor-guide/overview/#architecture) document. [DeepWiki](https://deepwiki.com/GreptimeTeam/greptimedb/1-overview) provides an in-depth look at GreptimeDB:
-  +* **Standalone** — single binary for development and small deployments.
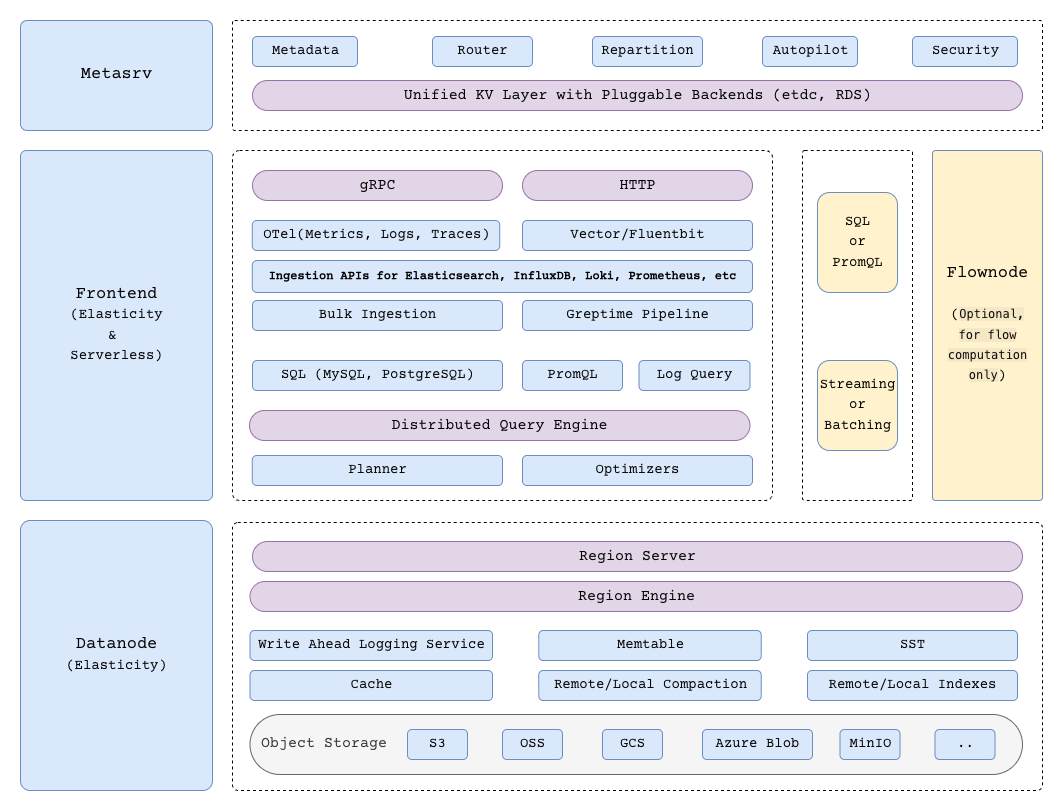
+* **Distributed** — four components, each independently scalable:
+ - **Frontend** — protocol entry (OTel, Prometheus, MySQL/PostgreSQL, gRPC, ingestion APIs for Elasticsearch/InfluxDB/Loki) and the distributed query engine. Stateless, scales horizontally.
+ - **Datanode** — region engine with WAL, memtable, SST, cache, compaction, and indexes. Persists data to object storage. Elastic.
+ - **Metasrv** — metadata, routing, repartitioning, autopilot, and security. Backed by a pluggable KV layer (etcd or RDS).
+ - **Flownode** (optional) — continuous flow computation (streaming and materialized views).
+
+For deeper coverage, see the [architecture doc](https://docs.greptime.com/contributor-guide/overview/#architecture) or [DeepWiki](https://deepwiki.com/GreptimeTeam/greptimedb/1-overview).
+
+
+
+* **Standalone** — single binary for development and small deployments.
+* **Distributed** — four components, each independently scalable:
+ - **Frontend** — protocol entry (OTel, Prometheus, MySQL/PostgreSQL, gRPC, ingestion APIs for Elasticsearch/InfluxDB/Loki) and the distributed query engine. Stateless, scales horizontally.
+ - **Datanode** — region engine with WAL, memtable, SST, cache, compaction, and indexes. Persists data to object storage. Elastic.
+ - **Metasrv** — metadata, routing, repartitioning, autopilot, and security. Backed by a pluggable KV layer (etcd or RDS).
+ - **Flownode** (optional) — continuous flow computation (streaming and materialized views).
+
+For deeper coverage, see the [architecture doc](https://docs.greptime.com/contributor-guide/overview/#architecture) or [DeepWiki](https://deepwiki.com/GreptimeTeam/greptimedb/1-overview).
+
+
+  +
## Try GreptimeDB
-```shell
-docker pull greptime/greptimedb
+**For AI agents** — paste this prompt into your agent:
+
+```text
+Read https://docs.greptime.com/SKILL.md and follow the instructions
+to deploy, configure, ingest, and query GreptimeDB.
```
```shell
@@ -131,7 +149,7 @@ docker run -p 127.0.0.1:4000-4003:4000-4003 \
--name greptime --rm \
greptime/greptimedb:latest standalone start \
--http-addr 0.0.0.0:4000 \
- --grpc-bind-addr 0.0.0.0:4001 \
+ --rpc-bind-addr 0.0.0.0:4001 \
--mysql-addr 0.0.0.0:4002 \
--postgres-addr 0.0.0.0:4003
```
@@ -153,20 +171,30 @@ Read more in the [full Install Guide](https://docs.greptime.com/getting-started/
## Build From Source
**Prerequisites:**
-* [Rust toolchain](https://www.rust-lang.org/tools/install) (nightly)
+* [Rust toolchain](https://www.rust-lang.org/tools/install) — nightly, pinned by [`rust-toolchain.toml`](https://github.com/GreptimeTeam/greptimedb/blob/main/rust-toolchain.toml)
* [Protobuf compiler](https://grpc.io/docs/protoc-installation/) (>= 3.15)
-* C/C++ building essentials, including `gcc`/`g++`/`autoconf` and glibc library (eg. `libc6-dev` on Ubuntu and `glibc-devel` on Fedora)
-* Python toolchain (optional): Required only if using some test scripts.
+* C/C++ building essentials: `gcc` / `g++` / `autoconf` and the glibc dev package (`libc6-dev` on Ubuntu, `glibc-devel` on Fedora)
+* Python toolchain (optional, only for some test scripts)
-**Build and Run:**
+**Build and run:**
```bash
-make
-cargo run -- standalone start
+make # build greptime binary
+cargo run -- standalone start # start in standalone mode
```
+**Common dev commands:**
+```bash
+make fmt # format Rust code
+make clippy # lint (fails on warnings)
+make test # unit + integration tests (uses cargo-nextest)
+make sqlness-test # SQL regression tests
+```
+
+See the [Contribution Guidelines](CONTRIBUTING.md) for the full developer workflow.
+
## Tools & Extensions
-- **Kubernetes**: [GreptimeDB Operator](https://github.com/GrepTimeTeam/greptimedb-operator)
+- **Kubernetes**: [GreptimeDB Operator](https://github.com/GreptimeTeam/greptimedb-operator)
- **Helm Charts**: [Greptime Helm Charts](https://github.com/GreptimeTeam/helm-charts)
- **Dashboard**: [Web UI](https://github.com/GreptimeTeam/dashboard)
- **gRPC Ingester**: [Go](https://github.com/GreptimeTeam/greptimedb-ingester-go), [Java](https://github.com/GreptimeTeam/greptimedb-ingester-java), [C++](https://github.com/GreptimeTeam/greptimedb-ingester-cpp), [Erlang](https://github.com/GreptimeTeam/greptimedb-ingester-erl), [Rust](https://github.com/GreptimeTeam/greptimedb-ingester-rust), [.NET](https://github.com/GreptimeTeam/greptimedb-ingester-dotnet)
@@ -175,18 +203,11 @@ cargo run -- standalone start
## Project Status
-> **Status:** [v1.0 GA](https://github.com/GreptimeTeam/greptimedb/releases/tag/v1.0.0) — generally available and production-ready! 🎉
+GreptimeDB is at [v1.0 GA](https://github.com/GreptimeTeam/greptimedb/releases/tag/v1.0.0) with stable APIs and regular releases. It runs in production at scale — [OceanBase Cloud](https://greptime.com/blogs/2025-07-22-user-case-obcloud-log-management-greptimedb) operates 80+ GreptimeDB clusters managing 300 TB of logs, cutting log storage cost by 60% after migrating from Grafana Loki. See more in [case studies](https://greptime.com/blogs/?category=Use%20Case).
-- Deployed in production handling billions of data points daily
-- Stable APIs, actively maintained, with regular releases ([version info](https://docs.greptime.com/nightly/reference/about-greptimedb-version))
+Read the [v1.0 highlights](https://greptime.com/blogs/2025-11-05-greptimedb-v1-highlights) and [2026 roadmap](https://greptime.com/blogs/2026-02-11-greptimedb-roadmap-2026), or browse the [version reference](https://docs.greptime.com/nightly/reference/about-greptimedb-version).
-GreptimeDB v1.0 marks a major milestone — stable APIs, production readiness, and proven performance at scale.
-
-**Learn more:** [v1.0 highlights](https://greptime.com/blogs/2025-11-05-greptimedb-v1-highlights) and [2026 roadmap](https://greptime.com/blogs/2026-02-11-greptimedb-roadmap-2026).
-
-For production use, we recommend v1.0 or later.
-
-If you find this project useful, a ⭐ would mean a lot to us!
+If GreptimeDB is useful to you, please star the repo.
[](https://www.star-history.com/#GreptimeTeam/GreptimeDB&Date)
@@ -216,15 +237,19 @@ We offer enterprise add-ons, services, training, and consulting.
## Contributing
-- Read our [Contribution Guidelines](https://github.com/GreptimeTeam/greptimedb/blob/main/CONTRIBUTING.md).
+- Read our [Contribution Guidelines](CONTRIBUTING.md).
- Explore [Internal Concepts](https://docs.greptime.com/contributor-guide/overview.html) and [DeepWiki](https://deepwiki.com/GreptimeTeam/greptimedb).
- Pick up a [good first issue](https://github.com/GreptimeTeam/greptimedb/issues?q=is%3Aissue+is%3Aopen+label%3A%22good+first+issue%22) and join the #contributors [Slack](https://greptime.com/slack) channel.
## Acknowledgement
-Special thanks to all contributors! See [AUTHORS.md](https://github.com/GreptimeTeam/greptimedb/blob/main/AUTHOR.md).
+Special thanks to all contributors! See [AUTHOR.md](AUTHOR.md).
- Uses [Apache Arrow™](https://arrow.apache.org/) (memory model)
- [Apache Parquet™](https://parquet.apache.org/) (file storage)
-- [Apache DataFusion™](https://arrow.apache.org/datafusion/) (query engine)
+- [Apache DataFusion™](https://datafusion.apache.org/) (query engine)
- [Apache OpenDAL™](https://opendal.apache.org/) (data access abstraction)
+
+---
+
+*All trademarks, logos, and brand names referenced in this README and in the Overview diagram are the property of their respective owners. Their use is for identification purposes only and does not imply endorsement or affiliation.*
diff --git a/config/config.md b/config/config.md
index b1630d97ad..0fae0caaa4 100644
--- a/config/config.md
+++ b/config/config.md
@@ -155,6 +155,8 @@
| `region_engine.mito.vector_cache_size` | String | Auto | Cache size for vectors and arrow arrays. Setting it to 0 to disable the cache.
+
## Try GreptimeDB
-```shell
-docker pull greptime/greptimedb
+**For AI agents** — paste this prompt into your agent:
+
+```text
+Read https://docs.greptime.com/SKILL.md and follow the instructions
+to deploy, configure, ingest, and query GreptimeDB.
```
```shell
@@ -131,7 +149,7 @@ docker run -p 127.0.0.1:4000-4003:4000-4003 \
--name greptime --rm \
greptime/greptimedb:latest standalone start \
--http-addr 0.0.0.0:4000 \
- --grpc-bind-addr 0.0.0.0:4001 \
+ --rpc-bind-addr 0.0.0.0:4001 \
--mysql-addr 0.0.0.0:4002 \
--postgres-addr 0.0.0.0:4003
```
@@ -153,20 +171,30 @@ Read more in the [full Install Guide](https://docs.greptime.com/getting-started/
## Build From Source
**Prerequisites:**
-* [Rust toolchain](https://www.rust-lang.org/tools/install) (nightly)
+* [Rust toolchain](https://www.rust-lang.org/tools/install) — nightly, pinned by [`rust-toolchain.toml`](https://github.com/GreptimeTeam/greptimedb/blob/main/rust-toolchain.toml)
* [Protobuf compiler](https://grpc.io/docs/protoc-installation/) (>= 3.15)
-* C/C++ building essentials, including `gcc`/`g++`/`autoconf` and glibc library (eg. `libc6-dev` on Ubuntu and `glibc-devel` on Fedora)
-* Python toolchain (optional): Required only if using some test scripts.
+* C/C++ building essentials: `gcc` / `g++` / `autoconf` and the glibc dev package (`libc6-dev` on Ubuntu, `glibc-devel` on Fedora)
+* Python toolchain (optional, only for some test scripts)
-**Build and Run:**
+**Build and run:**
```bash
-make
-cargo run -- standalone start
+make # build greptime binary
+cargo run -- standalone start # start in standalone mode
```
+**Common dev commands:**
+```bash
+make fmt # format Rust code
+make clippy # lint (fails on warnings)
+make test # unit + integration tests (uses cargo-nextest)
+make sqlness-test # SQL regression tests
+```
+
+See the [Contribution Guidelines](CONTRIBUTING.md) for the full developer workflow.
+
## Tools & Extensions
-- **Kubernetes**: [GreptimeDB Operator](https://github.com/GrepTimeTeam/greptimedb-operator)
+- **Kubernetes**: [GreptimeDB Operator](https://github.com/GreptimeTeam/greptimedb-operator)
- **Helm Charts**: [Greptime Helm Charts](https://github.com/GreptimeTeam/helm-charts)
- **Dashboard**: [Web UI](https://github.com/GreptimeTeam/dashboard)
- **gRPC Ingester**: [Go](https://github.com/GreptimeTeam/greptimedb-ingester-go), [Java](https://github.com/GreptimeTeam/greptimedb-ingester-java), [C++](https://github.com/GreptimeTeam/greptimedb-ingester-cpp), [Erlang](https://github.com/GreptimeTeam/greptimedb-ingester-erl), [Rust](https://github.com/GreptimeTeam/greptimedb-ingester-rust), [.NET](https://github.com/GreptimeTeam/greptimedb-ingester-dotnet)
@@ -175,18 +203,11 @@ cargo run -- standalone start
## Project Status
-> **Status:** [v1.0 GA](https://github.com/GreptimeTeam/greptimedb/releases/tag/v1.0.0) — generally available and production-ready! 🎉
+GreptimeDB is at [v1.0 GA](https://github.com/GreptimeTeam/greptimedb/releases/tag/v1.0.0) with stable APIs and regular releases. It runs in production at scale — [OceanBase Cloud](https://greptime.com/blogs/2025-07-22-user-case-obcloud-log-management-greptimedb) operates 80+ GreptimeDB clusters managing 300 TB of logs, cutting log storage cost by 60% after migrating from Grafana Loki. See more in [case studies](https://greptime.com/blogs/?category=Use%20Case).
-- Deployed in production handling billions of data points daily
-- Stable APIs, actively maintained, with regular releases ([version info](https://docs.greptime.com/nightly/reference/about-greptimedb-version))
+Read the [v1.0 highlights](https://greptime.com/blogs/2025-11-05-greptimedb-v1-highlights) and [2026 roadmap](https://greptime.com/blogs/2026-02-11-greptimedb-roadmap-2026), or browse the [version reference](https://docs.greptime.com/nightly/reference/about-greptimedb-version).
-GreptimeDB v1.0 marks a major milestone — stable APIs, production readiness, and proven performance at scale.
-
-**Learn more:** [v1.0 highlights](https://greptime.com/blogs/2025-11-05-greptimedb-v1-highlights) and [2026 roadmap](https://greptime.com/blogs/2026-02-11-greptimedb-roadmap-2026).
-
-For production use, we recommend v1.0 or later.
-
-If you find this project useful, a ⭐ would mean a lot to us!
+If GreptimeDB is useful to you, please star the repo.
[](https://www.star-history.com/#GreptimeTeam/GreptimeDB&Date)
@@ -216,15 +237,19 @@ We offer enterprise add-ons, services, training, and consulting.
## Contributing
-- Read our [Contribution Guidelines](https://github.com/GreptimeTeam/greptimedb/blob/main/CONTRIBUTING.md).
+- Read our [Contribution Guidelines](CONTRIBUTING.md).
- Explore [Internal Concepts](https://docs.greptime.com/contributor-guide/overview.html) and [DeepWiki](https://deepwiki.com/GreptimeTeam/greptimedb).
- Pick up a [good first issue](https://github.com/GreptimeTeam/greptimedb/issues?q=is%3Aissue+is%3Aopen+label%3A%22good+first+issue%22) and join the #contributors [Slack](https://greptime.com/slack) channel.
## Acknowledgement
-Special thanks to all contributors! See [AUTHORS.md](https://github.com/GreptimeTeam/greptimedb/blob/main/AUTHOR.md).
+Special thanks to all contributors! See [AUTHOR.md](AUTHOR.md).
- Uses [Apache Arrow™](https://arrow.apache.org/) (memory model)
- [Apache Parquet™](https://parquet.apache.org/) (file storage)
-- [Apache DataFusion™](https://arrow.apache.org/datafusion/) (query engine)
+- [Apache DataFusion™](https://datafusion.apache.org/) (query engine)
- [Apache OpenDAL™](https://opendal.apache.org/) (data access abstraction)
+
+---
+
+*All trademarks, logos, and brand names referenced in this README and in the Overview diagram are the property of their respective owners. Their use is for identification purposes only and does not imply endorsement or affiliation.*
diff --git a/config/config.md b/config/config.md
index b1630d97ad..0fae0caaa4 100644
--- a/config/config.md
+++ b/config/config.md
@@ -155,6 +155,8 @@
| `region_engine.mito.vector_cache_size` | String | Auto | Cache size for vectors and arrow arrays. Setting it to 0 to disable the cache.
If not set, it's default to 1/16 of OS memory with a max limitation of 512MB. |
| `region_engine.mito.page_cache_size` | String | Auto | Cache size for pages of SST row groups. Setting it to 0 to disable the cache.
If not set, it's default to 1/8 of OS memory. |
| `region_engine.mito.selector_result_cache_size` | String | Auto | Cache size for time series selector (e.g. `last_value()`). Setting it to 0 to disable the cache.
If not set, it's default to 1/16 of OS memory with a max limitation of 512MB. |
+| `region_engine.mito.range_result_cache_size` | String | Auto | Cache size for flat range scan results. Setting it to 0 to disable the cache.
If not set, it's default to 1/16 of OS memory with a max limitation of 512MB. |
+| `region_engine.mito.prefilter_result_cache_size` | String | Auto | Cache size for prefilter results. Setting it to 0 to disable the cache.
If not set, it's default to 1/32 of OS memory with a max limitation of 128MB. |
| `region_engine.mito.enable_write_cache` | Bool | `false` | Whether to enable the write cache, it's enabled by default when using object storage. It is recommended to enable it when using object storage for better performance. |
| `region_engine.mito.write_cache_path` | String | `""` | File system path for write cache, defaults to `{data_home}`. |
| `region_engine.mito.write_cache_size` | String | `5GiB` | Capacity for write cache. If your disk space is sufficient, it is recommended to set it larger. |
@@ -543,6 +545,8 @@
| `region_engine.mito.vector_cache_size` | String | Auto | Cache size for vectors and arrow arrays. Setting it to 0 to disable the cache.
If not set, it's default to 1/16 of OS memory with a max limitation of 512MB. |
| `region_engine.mito.page_cache_size` | String | Auto | Cache size for pages of SST row groups. Setting it to 0 to disable the cache.
If not set, it's default to 1/8 of OS memory. |
| `region_engine.mito.selector_result_cache_size` | String | Auto | Cache size for time series selector (e.g. `last_value()`). Setting it to 0 to disable the cache.
If not set, it's default to 1/16 of OS memory with a max limitation of 512MB. |
+| `region_engine.mito.range_result_cache_size` | String | Auto | Cache size for flat range scan results. Setting it to 0 to disable the cache.
If not set, it's default to 1/16 of OS memory with a max limitation of 512MB. |
+| `region_engine.mito.prefilter_result_cache_size` | String | Auto | Cache size for prefilter results. Setting it to 0 to disable the cache.
If not set, it's default to 1/32 of OS memory with a max limitation of 128MB. |
| `region_engine.mito.enable_write_cache` | Bool | `false` | Whether to enable the write cache, it's enabled by default when using object storage. It is recommended to enable it when using object storage for better performance. |
| `region_engine.mito.write_cache_path` | String | `""` | File system path for write cache, defaults to `{data_home}`. |
| `region_engine.mito.write_cache_size` | String | `5GiB` | Capacity for write cache. If your disk space is sufficient, it is recommended to set it larger. |
diff --git a/config/datanode.example.toml b/config/datanode.example.toml
index 170045a090..d558918daf 100644
--- a/config/datanode.example.toml
+++ b/config/datanode.example.toml
@@ -480,6 +480,16 @@ auto_flush_interval = "1h"
## @toml2docs:none-default="Auto"
#+ selector_result_cache_size = "512MB"
+## Cache size for flat range scan results. Setting it to 0 to disable the cache.
+## If not set, it's default to 1/16 of OS memory with a max limitation of 512MB.
+## @toml2docs:none-default="Auto"
+#+ range_result_cache_size = "512MB"
+
+## Cache size for prefilter results. Setting it to 0 to disable the cache.
+## If not set, it's default to 1/32 of OS memory with a max limitation of 128MB.
+## @toml2docs:none-default="Auto"
+#+ prefilter_result_cache_size = "128MB"
+
## Whether to enable the write cache, it's enabled by default when using object storage. It is recommended to enable it when using object storage for better performance.
enable_write_cache = false
diff --git a/config/standalone.example.toml b/config/standalone.example.toml
index 24249270b2..d5c42e744c 100644
--- a/config/standalone.example.toml
+++ b/config/standalone.example.toml
@@ -599,6 +599,16 @@ auto_flush_interval = "1h"
## @toml2docs:none-default="Auto"
#+ selector_result_cache_size = "512MB"
+## Cache size for flat range scan results. Setting it to 0 to disable the cache.
+## If not set, it's default to 1/16 of OS memory with a max limitation of 512MB.
+## @toml2docs:none-default="Auto"
+#+ range_result_cache_size = "512MB"
+
+## Cache size for prefilter results. Setting it to 0 to disable the cache.
+## If not set, it's default to 1/32 of OS memory with a max limitation of 128MB.
+## @toml2docs:none-default="Auto"
+#+ prefilter_result_cache_size = "128MB"
+
## Whether to enable the write cache, it's enabled by default when using object storage. It is recommended to enable it when using object storage for better performance.
enable_write_cache = false
diff --git a/docs/architecture.png b/docs/architecture.png
index 992b6c856d..697292ef2f 100644
Binary files a/docs/architecture.png and b/docs/architecture.png differ
diff --git a/docs/overview.png b/docs/overview.png
new file mode 100644
index 0000000000..5ab20834a4
Binary files /dev/null and b/docs/overview.png differ
diff --git a/src/auth/src/permission.rs b/src/auth/src/permission.rs
index 88adfda633..8914635290 100644
--- a/src/auth/src/permission.rs
+++ b/src/auth/src/permission.rs
@@ -16,6 +16,7 @@ use std::fmt::Debug;
use std::sync::Arc;
use api::v1::greptime_request::Request;
+use api::v1::query_request::Query;
use common_telemetry::debug;
use sql::statements::statement::Statement;
@@ -42,10 +43,12 @@ impl<'a> PermissionReq<'a> {
/// Returns true if the permission request is for read operations.
pub fn is_readonly(&self) -> bool {
match self {
- PermissionReq::GrpcRequest(Request::Query(_))
- | PermissionReq::PromQuery
- | PermissionReq::LogQuery
- | PermissionReq::PromStoreRead => true,
+ PermissionReq::GrpcRequest(Request::Query(query_request)) => {
+ !matches!(query_request.query, Some(Query::InsertIntoPlan(_)))
+ }
+ PermissionReq::PromQuery | PermissionReq::LogQuery | PermissionReq::PromStoreRead => {
+ true
+ }
PermissionReq::SqlStatement(stmt) => stmt.is_readonly(),
PermissionReq::GrpcRequest(_)
@@ -196,4 +199,14 @@ mod tests {
assert!(matches!(read_result, PermissionResp::Reject));
assert!(matches!(write_result, PermissionResp::Allow));
}
+
+ #[test]
+ fn test_grpc_insert_into_plan_is_write_request() {
+ let request = Request::Query(api::v1::QueryRequest {
+ query: Some(Query::InsertIntoPlan(api::v1::InsertIntoPlan::default())),
+ });
+ let req = PermissionReq::GrpcRequest(&request);
+
+ assert!(req.is_write());
+ }
}
diff --git a/src/catalog/src/system_schema/information_schema.rs b/src/catalog/src/system_schema/information_schema.rs
index 9715aa9402..a35950194c 100644
--- a/src/catalog/src/system_schema/information_schema.rs
+++ b/src/catalog/src/system_schema/information_schema.rs
@@ -20,6 +20,7 @@ pub mod key_column_usage;
mod partitions;
mod procedure_info;
pub mod process_list;
+mod region_info;
pub mod region_peers;
mod region_statistics;
pub mod schemata;
@@ -47,6 +48,8 @@ use datatypes::schema::SchemaRef;
use lazy_static::lazy_static;
use paste::paste;
use process_list::InformationSchemaProcessList;
+use region_info::InformationSchemaRegionInfo;
+use store_api::region_info::RegionInfoEntry;
use store_api::sst_entry::{ManifestSstEntry, PuffinIndexMetaEntry, StorageSstEntry};
use store_api::storage::{ScanRequest, TableId};
use table::TableRef;
@@ -242,6 +245,9 @@ impl SystemSchemaProviderInner for InformationSchemaProvider {
self.catalog_manager.clone(),
),
) as _),
+ REGION_INFO => Some(Arc::new(InformationSchemaRegionInfo::new(
+ self.catalog_manager.clone(),
+ )) as _),
PROCESS_LIST => self
.process_manager
.as_ref()
@@ -320,6 +326,10 @@ impl InformationSchemaProvider {
REGION_STATISTICS.to_string(),
self.build_table(REGION_STATISTICS).unwrap(),
);
+ tables.insert(
+ REGION_INFO.to_string(),
+ self.build_table(REGION_INFO).unwrap(),
+ );
tables.insert(
SSTS_MANIFEST.to_string(),
self.build_table(SSTS_MANIFEST).unwrap(),
@@ -447,6 +457,8 @@ pub enum DatanodeInspectKind {
SstStorage,
/// List index metadata collected from manifest
SstIndexMeta,
+ /// List region runtime and manifest info
+ RegionInfo,
}
impl DatanodeInspectRequest {
@@ -456,6 +468,7 @@ impl DatanodeInspectRequest {
DatanodeInspectKind::SstManifest => ManifestSstEntry::build_plan(self.scan),
DatanodeInspectKind::SstStorage => StorageSstEntry::build_plan(self.scan),
DatanodeInspectKind::SstIndexMeta => PuffinIndexMetaEntry::build_plan(self.scan),
+ DatanodeInspectKind::RegionInfo => RegionInfoEntry::build_plan(self.scan),
}
}
}
@@ -488,3 +501,28 @@ impl InformationExtension for NoopInformationExtension {
Ok(common_recordbatch::RecordBatches::empty().as_stream())
}
}
+
+#[cfg(test)]
+mod tests {
+ use store_api::region_info::RegionInfoEntry;
+
+ use super::*;
+
+ #[test]
+ fn test_datanode_inspect_region_info_build_plan() {
+ let plan = DatanodeInspectRequest {
+ kind: DatanodeInspectKind::RegionInfo,
+ scan: ScanRequest::default(),
+ }
+ .build_plan()
+ .unwrap();
+
+ let LogicalPlan::TableScan(scan) = plan else {
+ panic!("expected table scan");
+ };
+ assert_eq!(
+ scan.table_name.to_string(),
+ RegionInfoEntry::reserved_table_name_for_inspection()
+ );
+ }
+}
diff --git a/src/catalog/src/system_schema/information_schema/region_info.rs b/src/catalog/src/system_schema/information_schema/region_info.rs
new file mode 100644
index 0000000000..ffc9dfc7ae
--- /dev/null
+++ b/src/catalog/src/system_schema/information_schema/region_info.rs
@@ -0,0 +1,86 @@
+// Copyright 2023 Greptime Team
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+use std::sync::{Arc, Weak};
+
+use common_catalog::consts::INFORMATION_SCHEMA_REGION_INFO_TABLE_ID;
+use common_error::ext::BoxedError;
+use common_recordbatch::SendableRecordBatchStream;
+use common_recordbatch::adapter::AsyncRecordBatchStreamAdapter;
+use datatypes::schema::SchemaRef;
+use snafu::ResultExt;
+use store_api::region_info::RegionInfoEntry;
+use store_api::storage::{ScanRequest, TableId};
+
+use crate::CatalogManager;
+use crate::error::{ProjectSchemaSnafu, Result};
+use crate::information_schema::{
+ DatanodeInspectKind, DatanodeInspectRequest, InformationTable, REGION_INFO,
+};
+use crate::system_schema::utils;
+
+/// Information schema table for region info.
+pub struct InformationSchemaRegionInfo {
+ schema: SchemaRef,
+ catalog_manager: Weak,
+}
+
+impl InformationSchemaRegionInfo {
+ pub(super) fn new(catalog_manager: Weak) -> Self {
+ Self {
+ schema: RegionInfoEntry::schema(),
+ catalog_manager,
+ }
+ }
+}
+
+impl InformationTable for InformationSchemaRegionInfo {
+ fn table_id(&self) -> TableId {
+ INFORMATION_SCHEMA_REGION_INFO_TABLE_ID
+ }
+
+ fn table_name(&self) -> &'static str {
+ REGION_INFO
+ }
+
+ fn schema(&self) -> SchemaRef {
+ self.schema.clone()
+ }
+
+ fn to_stream(&self, request: ScanRequest) -> Result {
+ let schema = if let Some(p) = request.projection_indices() {
+ Arc::new(self.schema.try_project(p).context(ProjectSchemaSnafu)?)
+ } else {
+ self.schema.clone()
+ };
+
+ let info_ext = utils::information_extension(&self.catalog_manager)?;
+ let req = DatanodeInspectRequest {
+ kind: DatanodeInspectKind::RegionInfo,
+ scan: request,
+ };
+
+ let future = async move {
+ info_ext
+ .inspect_datanode(req)
+ .await
+ .map_err(BoxedError::new)
+ .context(common_recordbatch::error::ExternalSnafu)
+ };
+ Ok(Box::pin(AsyncRecordBatchStreamAdapter::new(
+ schema,
+ Box::pin(future),
+ )))
+ }
+}
diff --git a/src/catalog/src/system_schema/information_schema/table_names.rs b/src/catalog/src/system_schema/information_schema/table_names.rs
index 2a3329fece..3a4c86487a 100644
--- a/src/catalog/src/system_schema/information_schema/table_names.rs
+++ b/src/catalog/src/system_schema/information_schema/table_names.rs
@@ -45,6 +45,7 @@ pub const CLUSTER_INFO: &str = "cluster_info";
pub const VIEWS: &str = "views";
pub const FLOWS: &str = "flows";
pub const PROCEDURE_INFO: &str = "procedure_info";
+pub const REGION_INFO: &str = "region_info";
pub const REGION_STATISTICS: &str = "region_statistics";
pub const PROCESS_LIST: &str = "process_list";
pub const SSTS_MANIFEST: &str = "ssts_manifest";
diff --git a/src/catalog/src/table_source/dummy_catalog.rs b/src/catalog/src/table_source/dummy_catalog.rs
index db49db0eed..20637c3a3a 100644
--- a/src/catalog/src/table_source/dummy_catalog.rs
+++ b/src/catalog/src/table_source/dummy_catalog.rs
@@ -22,6 +22,7 @@ use async_trait::async_trait;
use common_catalog::format_full_table_name;
use datafusion::catalog::{CatalogProvider, CatalogProviderList, SchemaProvider};
use datafusion::datasource::TableProvider;
+use session::context::QueryContextRef;
use snafu::OptionExt;
use table::table::adapter::DfTableProviderAdapter;
@@ -32,12 +33,27 @@ use crate::error::TableNotExistSnafu;
#[derive(Clone)]
pub struct DummyCatalogList {
catalog_manager: CatalogManagerRef,
+ query_ctx: Option,
}
impl DummyCatalogList {
- /// Creates a new catalog list with the given catalog manager.
+ /// Creates a new catalog list with the given catalog manager (no query context).
pub fn new(catalog_manager: CatalogManagerRef) -> Self {
- Self { catalog_manager }
+ Self {
+ catalog_manager,
+ query_ctx: None,
+ }
+ }
+
+ /// Creates a new catalog list with the given catalog manager and query context.
+ pub fn new_with_query_ctx(
+ catalog_manager: CatalogManagerRef,
+ query_ctx: QueryContextRef,
+ ) -> Self {
+ Self {
+ catalog_manager,
+ query_ctx: Some(query_ctx),
+ }
}
}
@@ -68,6 +84,7 @@ impl CatalogProviderList for DummyCatalogList {
Some(Arc::new(DummyCatalogProvider {
catalog_name: catalog_name.to_string(),
catalog_manager: self.catalog_manager.clone(),
+ query_ctx: self.query_ctx.clone(),
}))
}
}
@@ -77,6 +94,7 @@ impl CatalogProviderList for DummyCatalogList {
struct DummyCatalogProvider {
catalog_name: String,
catalog_manager: CatalogManagerRef,
+ query_ctx: Option,
}
impl CatalogProvider for DummyCatalogProvider {
@@ -93,6 +111,7 @@ impl CatalogProvider for DummyCatalogProvider {
catalog_name: self.catalog_name.clone(),
schema_name: schema_name.to_string(),
catalog_manager: self.catalog_manager.clone(),
+ query_ctx: self.query_ctx.clone(),
}))
}
}
@@ -111,6 +130,7 @@ struct DummySchemaProvider {
catalog_name: String,
schema_name: String,
catalog_manager: CatalogManagerRef,
+ query_ctx: Option,
}
#[async_trait]
@@ -126,7 +146,12 @@ impl SchemaProvider for DummySchemaProvider {
async fn table(&self, name: &str) -> datafusion::error::Result>> {
let table = self
.catalog_manager
- .table(&self.catalog_name, &self.schema_name, name, None)
+ .table(
+ &self.catalog_name,
+ &self.schema_name,
+ name,
+ self.query_ctx.as_deref(),
+ )
.await?
.with_context(|| TableNotExistSnafu {
table: format_full_table_name(&self.catalog_name, &self.schema_name, name),
diff --git a/src/cli/src/data/export_v2/command.rs b/src/cli/src/data/export_v2/command.rs
index 3c069a72be..db0f576a4e 100644
--- a/src/cli/src/data/export_v2/command.rs
+++ b/src/cli/src/data/export_v2/command.rs
@@ -15,6 +15,7 @@
//! Export V2 CLI commands.
use std::collections::HashSet;
+use std::io::{self, Write};
use std::time::Duration;
use async_trait::async_trait;
@@ -28,7 +29,7 @@ use crate::Tool;
use crate::common::ObjectStoreConfig;
use crate::data::export_v2::coordinator::export_data;
use crate::data::export_v2::error::{
- ChunkTimeWindowRequiresBoundsSnafu, DatabaseSnafu, EmptyResultSnafu,
+ ChunkTimeWindowRequiresBoundsSnafu, DatabaseSnafu, EmptyResultSnafu, IoSnafu,
ManifestVersionMismatchSnafu, Result, ResumeConfigMismatchSnafu, SchemaOnlyArgsNotAllowedSnafu,
SchemaOnlyModeMismatchSnafu, SnapshotVerifyFailedSnafu, UnexpectedValueTypeSnafu,
};
@@ -38,7 +39,9 @@ use crate::data::export_v2::manifest::{
};
use crate::data::export_v2::schema::{DDL_DIR, SCHEMA_DIR, SCHEMAS_FILE};
use crate::data::path::{data_dir_for_schema_chunk, ddl_path_for_schema};
-use crate::data::snapshot_storage::{OpenDalStorage, SnapshotStorage, validate_uri};
+use crate::data::snapshot_storage::{
+ OpenDalStorage, SnapshotStorage, validate_snapshot_uri, validate_uri,
+};
use crate::data::sql::{escape_sql_identifier, escape_sql_literal};
use crate::database::{DatabaseClient, parse_proxy_opts};
@@ -51,6 +54,8 @@ pub enum ExportV2Command {
List(ExportListCommand),
/// Verify snapshot integrity.
Verify(ExportVerifyCommand),
+ /// Delete a snapshot and all data under it.
+ Delete(ExportDeleteCommand),
}
impl ExportV2Command {
@@ -59,6 +64,7 @@ impl ExportV2Command {
ExportV2Command::Create(cmd) => cmd.build().await,
ExportV2Command::List(cmd) => cmd.build().await,
ExportV2Command::Verify(cmd) => cmd.build().await,
+ ExportV2Command::Delete(cmd) => cmd.build().await,
}
}
}
@@ -172,6 +178,75 @@ impl ExportVerify {
}
}
+/// Delete a snapshot and all data under it.
+#[derive(Debug, Parser)]
+pub struct ExportDeleteCommand {
+ /// Snapshot storage location (e.g., s3://bucket/path, file:///tmp/backup).
+ #[clap(long)]
+ snapshot: String,
+
+ /// Skip interactive confirmation.
+ #[clap(long = "no-confirm", alias = "yes")]
+ skip_confirmation: bool,
+
+ /// Object store configuration for remote storage backends.
+ #[clap(flatten)]
+ storage: ObjectStoreConfig,
+}
+
+impl ExportDeleteCommand {
+ pub async fn build(&self) -> std::result::Result, BoxedError> {
+ validate_snapshot_uri(&self.snapshot).map_err(BoxedError::new)?;
+ let storage =
+ OpenDalStorage::from_uri(&self.snapshot, &self.storage).map_err(BoxedError::new)?;
+
+ Ok(Box::new(ExportDelete {
+ snapshot: self.snapshot.clone(),
+ skip_confirmation: self.skip_confirmation,
+ storage,
+ }))
+ }
+}
+
+/// Export delete tool implementation.
+pub struct ExportDelete {
+ snapshot: String,
+ skip_confirmation: bool,
+ storage: OpenDalStorage,
+}
+
+#[async_trait]
+impl Tool for ExportDelete {
+ async fn do_work(&self) -> std::result::Result<(), BoxedError> {
+ self.run().await.map_err(BoxedError::new)
+ }
+}
+
+impl ExportDelete {
+ async fn run(&self) -> Result<()> {
+ self.run_with_confirmation(confirm_delete).await
+ }
+
+ async fn run_with_confirmation(&self, confirm: F) -> Result<()>
+ where
+ F: FnOnce(&str) -> Result,
+ {
+ let manifest = self.storage.read_manifest().await?;
+ print_delete_summary(&self.snapshot, &manifest);
+
+ if !self.skip_confirmation && !confirm(&self.snapshot)? {
+ println!("Deletion cancelled.");
+ return Ok(());
+ }
+
+ println!("Deleting snapshot...");
+ self.storage.delete_snapshot().await?;
+ println!("Snapshot deleted successfully.");
+
+ Ok(())
+ }
+}
+
/// Create a new snapshot.
#[derive(Debug, Parser)]
pub struct ExportCreateCommand {
@@ -1239,6 +1314,79 @@ fn print_verify_report(snapshot: &str, report: &VerifyReport) {
);
}
+fn print_delete_summary(snapshot: &str, manifest: &Manifest) {
+ println!("Snapshot: {}", manifest.snapshot_id);
+ println!(" Location: {}", snapshot);
+ println!(
+ " Created: {} UTC",
+ manifest.created_at.format("%Y-%m-%d %H:%M:%S")
+ );
+ println!(" Catalog: {}", manifest.catalog);
+ println!(" Schemas: {}", manifest.schemas.join(", "));
+ println!(" Chunks: {}", format_delete_chunks(manifest));
+}
+
+fn format_delete_chunks(manifest: &Manifest) -> String {
+ if manifest.schema_only {
+ return "0 (schema-only)".to_string();
+ }
+
+ let summary = summarize_chunks(manifest);
+ if manifest.is_complete() {
+ format!("{} (all processed)", summary.total)
+ } else {
+ format!(
+ "{} ({} completed, {} skipped, {} pending, {} in_progress, {} failed)",
+ summary.total,
+ summary.completed,
+ summary.skipped,
+ summary.pending,
+ summary.in_progress,
+ summary.failed
+ )
+ }
+}
+
+fn confirm_delete(snapshot: &str) -> Result {
+ println!();
+ println!(
+ "Warning: this removes the entire snapshot directory/prefix, not only files listed in manifest."
+ );
+ println!("This will permanently delete all data under:");
+ println!(" {}", display_snapshot_prefix(snapshot));
+ print!("Type 'yes' to confirm deletion: ");
+ io::stdout().flush().map_err(|error| {
+ IoSnafu {
+ operation: "flushing delete confirmation prompt",
+ error,
+ }
+ .build()
+ })?;
+
+ let mut input = String::new();
+ io::stdin().read_line(&mut input).map_err(|error| {
+ IoSnafu {
+ operation: "reading delete confirmation",
+ error,
+ }
+ .build()
+ })?;
+
+ Ok(delete_confirmation_matches(&input))
+}
+
+fn delete_confirmation_matches(input: &str) -> bool {
+ input.trim() == "yes"
+}
+
+fn display_snapshot_prefix(snapshot: &str) -> String {
+ if snapshot.ends_with('/') {
+ snapshot.to_string()
+ } else {
+ format!("{}/", snapshot)
+ }
+}
+
#[cfg(test)]
mod tests {
use chrono::TimeZone;
@@ -1563,6 +1711,7 @@ mod tests {
);
assert_eq!(snapshot_status(&complete), "complete");
assert_eq!(format_list_chunks(&complete), "2/2");
+ assert_eq!(format_delete_chunks(&complete), "2 (all processed)");
let incomplete = test_manifest(
chrono::Utc.with_ymd_and_hms(2026, 1, 1, 0, 0, 0).unwrap(),
@@ -1571,6 +1720,150 @@ mod tests {
);
assert_eq!(snapshot_status(&incomplete), "incomplete");
assert_eq!(format_list_chunks(&incomplete), "1/2");
+ assert_eq!(
+ format_delete_chunks(&incomplete),
+ "2 (1 completed, 0 skipped, 1 pending, 0 in_progress, 0 failed)"
+ );
+ }
+
+ #[tokio::test]
+ async fn test_delete_build_rejects_bucket_root_uri() {
+ let cmd = ExportDeleteCommand::parse_from([
+ "export-v2-delete",
+ "--snapshot",
+ "s3://bucket",
+ "--no-confirm",
+ ]);
+
+ let error = cmd.build().await.err().unwrap().to_string();
+ assert!(error.contains("non-empty path"));
+ }
+
+ #[test]
+ fn test_delete_skip_confirmation_aliases() {
+ let no_confirm = ExportDeleteCommand::parse_from([
+ "export-v2-delete",
+ "--snapshot",
+ "s3://bucket/snapshot",
+ "--no-confirm",
+ ]);
+ assert!(no_confirm.skip_confirmation);
+
+ let yes = ExportDeleteCommand::parse_from([
+ "export-v2-delete",
+ "--snapshot",
+ "s3://bucket/snapshot",
+ "--yes",
+ ]);
+ assert!(yes.skip_confirmation);
+ }
+
+ #[tokio::test]
+ async fn test_delete_snapshot_with_no_confirm_removes_snapshot_contents() {
+ let parent = tempdir().unwrap();
+ let snapshot = parent.path().join("snapshot");
+ let sibling = parent.path().join("sibling");
+ std::fs::create_dir_all(&snapshot).unwrap();
+ std::fs::create_dir_all(&sibling).unwrap();
+ std::fs::write(sibling.join("keep.txt"), b"keep").unwrap();
+ write_root_manifest(
+ &snapshot,
+ test_manifest(
+ chrono::Utc.with_ymd_and_hms(2026, 1, 1, 0, 0, 0).unwrap(),
+ true,
+ true,
+ ),
+ );
+ write_snapshot_file(&snapshot, "schema/schemas.json", b"[]");
+
+ let uri = Url::from_directory_path(&snapshot).unwrap().to_string();
+ let delete = ExportDelete {
+ snapshot: uri,
+ skip_confirmation: true,
+ storage: file_storage_for_dir(&snapshot),
+ };
+
+ delete
+ .run_with_confirmation(|_| unreachable!())
+ .await
+ .unwrap();
+
+ assert!(!snapshot.join(MANIFEST_FILE).exists());
+ assert!(!snapshot.join("schema/schemas.json").exists());
+ assert!(sibling.join("keep.txt").exists());
+ }
+
+ #[tokio::test]
+ async fn test_delete_snapshot_requires_manifest() {
+ let dir = tempdir().unwrap();
+ let uri = Url::from_directory_path(dir.path()).unwrap().to_string();
+ let delete = ExportDelete {
+ snapshot: uri,
+ skip_confirmation: true,
+ storage: file_storage_for_dir(dir.path()),
+ };
+
+ let error = delete
+ .run_with_confirmation(|_| unreachable!())
+ .await
+ .err()
+ .unwrap()
+ .to_string();
+
+ assert!(error.contains("Snapshot not found"));
+ assert!(dir.path().exists());
+ }
+
+ #[tokio::test]
+ async fn test_delete_snapshot_cancels_without_exact_confirmation() {
+ let dir = tempdir().unwrap();
+ write_root_manifest(
+ dir.path(),
+ test_manifest(
+ chrono::Utc.with_ymd_and_hms(2026, 1, 1, 0, 0, 0).unwrap(),
+ true,
+ true,
+ ),
+ );
+ write_snapshot_file(dir.path(), "schema/schemas.json", b"[]");
+ let uri = Url::from_directory_path(dir.path()).unwrap().to_string();
+ let delete = ExportDelete {
+ snapshot: uri.clone(),
+ skip_confirmation: false,
+ storage: file_storage_for_dir(dir.path()),
+ };
+
+ delete
+ .run_with_confirmation(|snapshot| {
+ assert_eq!(snapshot, uri);
+ Ok(false)
+ })
+ .await
+ .unwrap();
+
+ assert!(dir.path().join(MANIFEST_FILE).exists());
+ assert!(dir.path().join("schema/schemas.json").exists());
+ }
+
+ #[test]
+ fn test_delete_confirmation_requires_exact_yes() {
+ assert!(delete_confirmation_matches("yes"));
+ assert!(delete_confirmation_matches(" yes\n"));
+ assert!(!delete_confirmation_matches("YES"));
+ assert!(!delete_confirmation_matches("y"));
+ assert!(!delete_confirmation_matches("yes please"));
+ }
+
+ #[test]
+ fn test_display_snapshot_prefix_adds_trailing_slash() {
+ assert_eq!(
+ display_snapshot_prefix("s3://bucket/snapshot"),
+ "s3://bucket/snapshot/"
+ );
+ assert_eq!(
+ display_snapshot_prefix("s3://bucket/snapshot/"),
+ "s3://bucket/snapshot/"
+ );
}
#[tokio::test]
diff --git a/src/cli/src/data/export_v2/error.rs b/src/cli/src/data/export_v2/error.rs
index 8d9a53f186..e16e3a6176 100644
--- a/src/cli/src/data/export_v2/error.rs
+++ b/src/cli/src/data/export_v2/error.rs
@@ -71,6 +71,14 @@ pub enum Error {
location: Location,
},
+ #[snafu(display("I/O error while {}: {}", operation, error))]
+ Io {
+ operation: &'static str,
+ error: std::io::Error,
+ #[snafu(implicit)]
+ location: Location,
+ },
+
#[snafu(display(
"Cannot resume snapshot with a different schema_only mode (existing: {}, requested: {}). Use --force to recreate.",
existing_schema_only,
@@ -223,6 +231,8 @@ impl ErrorExt for Error {
| Error::UnexpectedValueType { .. }
| Error::UrlParse { .. } => StatusCode::Internal,
+ Error::Io { .. } => StatusCode::External,
+
Error::Database { error, .. } => error.status_code(),
Error::SnapshotNotFound { .. } => StatusCode::InvalidArguments,
diff --git a/src/cli/src/data/snapshot_storage.rs b/src/cli/src/data/snapshot_storage.rs
index da8fdf6ab1..93e211628a 100644
--- a/src/cli/src/data/snapshot_storage.rs
+++ b/src/cli/src/data/snapshot_storage.rs
@@ -18,6 +18,7 @@
//! to various storage backends (S3, OSS, GCS, Azure Blob, local filesystem).
use std::collections::BTreeSet;
+use std::path::Component;
use async_trait::async_trait;
use futures::TryStreamExt;
@@ -131,6 +132,92 @@ pub fn validate_uri(uri: &str) -> Result {
StorageScheme::from_uri(uri)
}
+/// Validates a URI for snapshot-scoped destructive operations.
+///
+/// Unlike read-only parent scans, destructive commands must target a concrete
+/// snapshot directory instead of a bucket/container root or filesystem root.
+/// Remote storage buckets/containers already provide namespace isolation, so a
+/// non-empty object prefix is enough; local filesystem paths require at least
+/// two non-root path segments to avoid deleting broad system directories.
+pub fn validate_snapshot_uri(uri: &str) -> Result {
+ let scheme = validate_uri(uri)?;
+ reject_query_or_fragment(uri)?;
+ match scheme {
+ StorageScheme::File => validate_file_snapshot_uri(uri)?,
+ StorageScheme::S3 | StorageScheme::Oss | StorageScheme::Gcs | StorageScheme::Azblob => {
+ extract_remote_location_with_root_policy(uri, false)?;
+ }
+ }
+ Ok(scheme)
+}
+
+fn reject_query_or_fragment(uri: &str) -> Result<()> {
+ let url = Url::parse(uri).context(UrlParseSnafu)?;
+ if url.query().is_some() || url.fragment().is_some() {
+ return InvalidUriSnafu {
+ uri,
+ reason: "snapshot URI must not include query or fragment",
+ }
+ .fail();
+ }
+
+ Ok(())
+}
+
+fn validate_file_snapshot_uri(uri: &str) -> Result<()> {
+ if has_explicit_dot_segment(uri) {
+ return InvalidUriSnafu {
+ uri,
+ reason: "file snapshot URI must not contain '.' or '..' path segments",
+ }
+ .fail();
+ }
+
+ let path = extract_file_path_from_uri(uri)?;
+ let mut normal_component_count = 0;
+
+ // This is only a path-shape guard for destructive operations. It does not
+ // resolve symlinks. Drive prefixes and root separators also do not count
+ // toward depth; delete still relies on the manifest check and explicit
+ // confirmation before removing the rooted storage prefix.
+ for component in std::path::Path::new(&path).components() {
+ match component {
+ Component::Normal(_) => normal_component_count += 1,
+ Component::CurDir | Component::ParentDir => {
+ return InvalidUriSnafu {
+ uri,
+ reason: "file snapshot URI must not contain '.' or '..' path segments",
+ }
+ .fail();
+ }
+ Component::Prefix(_) | Component::RootDir => {}
+ }
+ }
+
+ if normal_component_count < 2 {
+ return InvalidUriSnafu {
+ uri,
+ reason: "file snapshot URI must point to a directory at least two levels deep",
+ }
+ .fail();
+ }
+
+ Ok(())
+}
+
+fn has_explicit_dot_segment(uri: &str) -> bool {
+ // Defense in depth: catch dot segments at the raw URI level before
+ // `Url::to_file_path()` can normalize them away. The `Path::components()`
+ // check below still runs because URL decoding can reintroduce them.
+ let without_fragment = uri.split_once('#').map_or(uri, |(path, _)| path);
+ let path = without_fragment
+ .split_once('?')
+ .map_or(without_fragment, |(path, _)| path);
+
+ path.split('/')
+ .any(|segment| segment == "." || segment == "..")
+}
+
fn schema_index_path() -> String {
format!("{}/{}", SCHEMA_DIR, SCHEMAS_FILE)
}
@@ -708,6 +795,43 @@ mod tests {
assert!(OpenDalStorage::from_parent_uri("s3://bucket", &storage).is_ok());
}
+ #[test]
+ fn test_validate_snapshot_uri_rejects_dangerous_roots() {
+ assert!(validate_snapshot_uri("s3://bucket").is_err());
+ assert!(validate_snapshot_uri("s3://bucket/").is_err());
+ assert!(validate_snapshot_uri("oss://bucket").is_err());
+ assert!(validate_snapshot_uri("gs://bucket").is_err());
+ assert!(validate_snapshot_uri("azblob://container").is_err());
+ assert!(validate_snapshot_uri("s3://bucket/snapshot?version=1").is_err());
+ assert!(validate_snapshot_uri("file:///tmp/backup#fragment").is_err());
+ assert!(validate_snapshot_uri("file:///").is_err());
+ assert!(validate_snapshot_uri("file:///tmp").is_err());
+ assert!(validate_snapshot_uri("file:///tmp/backup/.").is_err());
+ assert!(validate_snapshot_uri("file:///tmp/backup/..").is_err());
+ }
+
+ #[test]
+ fn test_validate_snapshot_uri_accepts_snapshot_paths() {
+ assert_eq!(
+ validate_snapshot_uri("s3://bucket/snapshots/prod").unwrap(),
+ StorageScheme::S3
+ );
+
+ let dir = tempdir().unwrap();
+ let snapshot = dir.path().join("snapshot");
+ std::fs::create_dir_all(&snapshot).unwrap();
+ let uri = Url::from_directory_path(snapshot).unwrap().to_string();
+ assert_eq!(validate_snapshot_uri(&uri).unwrap(), StorageScheme::File);
+ }
+
+ #[cfg(windows)]
+ #[test]
+ fn test_validate_snapshot_uri_windows_drive_prefix_depth() {
+ assert!(validate_snapshot_uri("file:///C:/").is_err());
+ assert!(validate_snapshot_uri("file:///C:/Users").is_err());
+ assert!(validate_snapshot_uri("file:///C:/Users/snapshot").is_ok());
+ }
+
#[cfg(not(windows))]
#[test]
fn test_extract_path_from_uri_unix_examples() {
diff --git a/src/cmd/src/datanode/objbench.rs b/src/cmd/src/datanode/objbench.rs
index a298430c83..65f194d19f 100644
--- a/src/cmd/src/datanode/objbench.rs
+++ b/src/cmd/src/datanode/objbench.rs
@@ -588,6 +588,8 @@ async fn build_cache_manager(
.vector_cache_size(config.vector_cache_size.as_bytes())
.page_cache_size(config.page_cache_size.as_bytes())
.selector_result_cache_size(config.selector_result_cache_size.as_bytes())
+ .range_result_cache_size(config.range_result_cache_size.as_bytes())
+ .prefilter_result_cache_size(config.prefilter_result_cache_size.as_bytes())
.index_metadata_size(config.index.metadata_cache_size.as_bytes())
.index_content_size(config.index.content_cache_size.as_bytes())
.index_content_page_size(config.index.content_cache_page_size.as_bytes())
diff --git a/src/cmd/src/standalone.rs b/src/cmd/src/standalone.rs
index b0601088cf..e0f2c673ff 100644
--- a/src/cmd/src/standalone.rs
+++ b/src/cmd/src/standalone.rs
@@ -20,6 +20,7 @@ use std::{fs, path};
use async_trait::async_trait;
use cache::{build_fundamental_cache_registry, with_default_composite_cache_registry};
+use catalog::CatalogManagerRef;
use catalog::information_schema::InformationExtensionRef;
use catalog::kvbackend::{CatalogManagerConfiguratorRef, KvBackendCatalogManagerBuilder};
use catalog::process_manager::ProcessManager;
@@ -28,7 +29,8 @@ use common_base::Plugins;
use common_catalog::consts::{MIN_USER_FLOW_ID, MIN_USER_TABLE_ID};
use common_config::{Configurable, metadata_store_dir};
use common_error::ext::BoxedError;
-use common_meta::cache::LayeredCacheRegistryBuilder;
+use common_meta::DatanodeId;
+use common_meta::cache::{LayeredCacheRegistryBuilder, LayeredCacheRegistryRef};
use common_meta::ddl::flow_meta::FlowMetadataAllocator;
use common_meta::ddl::table_meta::TableMetadataAllocator;
use common_meta::ddl::{DdlContext, NoopRegionFailureDetectorControl};
@@ -53,8 +55,8 @@ use datanode::config::DatanodeOptions;
use datanode::datanode::{Datanode, DatanodeBuilder};
use datanode::region_server::RegionServer;
use flow::{
- FlownodeBuilder, FlownodeInstance, FlownodeOptions, FrontendClient, FrontendInvoker,
- GrpcQueryHandlerWithBoxedError,
+ FlowDualEngineRef, FlownodeBuilder, FlownodeInstance, FlownodeOptions, FrontendClient,
+ FrontendInvoker, GrpcQueryHandlerWithBoxedError,
};
use frontend::frontend::Frontend;
use frontend::instance::StandaloneDatanodeManager;
@@ -124,8 +126,8 @@ pub struct Instance {
frontend: Frontend,
flownode: FlownodeInstance,
procedure_manager: ProcedureManagerRef,
- wal_provider: WalProviderRef,
leader_services_controller: Box,
+ leader_services_context: LeaderServicesContext,
// Keep the logging guard to prevent the worker from being dropped.
_guard: Vec,
}
@@ -159,11 +161,7 @@ impl App for Instance {
self.datanode.start_telemetry();
self.leader_services_controller
- .start(
- self.procedure_manager.clone(),
- self.wal_provider.clone(),
- self.datanode.region_server(),
- )
+ .start(self.leader_services_context.clone())
.await?;
plugins::start_frontend_plugins(self.frontend.instance.plugins().clone())
@@ -379,6 +377,8 @@ impl StartCommand {
opts.grpc.detect_server_addr();
let fe_opts = opts.frontend_options();
let dn_opts = opts.datanode_options();
+ let node_id = dn_opts.node_id;
+ let init_regions_parallelism = dn_opts.init_regions_parallelism;
plugins::setup_frontend_plugins(&mut plugins, &plugin_opts, &fe_opts)
.await
@@ -491,21 +491,18 @@ impl StartCommand {
.await
.map_err(BoxedError::new)
.context(error::OtherSnafu)?;
+ let flow_engine = flownode.flow_engine();
// set the ref to query for the local flow state
{
information_extension
- .set_flow_engine(flownode.flow_engine())
+ .set_flow_engine(flow_engine.clone())
.await;
}
let node_manager = creator
.node_manager_creator
- .create(
- &kv_backend,
- datanode.region_server(),
- flownode.flow_engine(),
- )
+ .create(&kv_backend, datanode.region_server(), flow_engine.clone())
.await?;
let table_id_allocator = creator.table_id_allocator_creator.create(&kv_backend);
@@ -596,7 +593,7 @@ impl StartCommand {
.await;
// set the frontend invoker for flownode
- let flow_streaming_engine = flownode.flow_engine().streaming_engine();
+ let flow_streaming_engine = flow_engine.streaming_engine();
// flow server need to be able to use frontend to write insert requests back
let invoker = FrontendInvoker::build_from(
flow_streaming_engine.clone(),
@@ -620,14 +617,27 @@ impl StartCommand {
servers,
heartbeat_task: None,
};
+ let leader_services_context = LeaderServicesContext {
+ procedure_manager: procedure_manager.clone(),
+ wal_provider: wal_provider.clone(),
+ region_server: datanode.region_server(),
+ kv_backend: kv_backend.clone(),
+ cache_registry: layered_cache_registry,
+ catalog_manager,
+ flow_engine,
+ frontend_client,
+ node_id,
+ init_regions_parallelism,
+ plugin_options: plugin_opts,
+ };
let instance = Instance {
datanode,
frontend,
flownode,
procedure_manager,
- wal_provider,
leader_services_controller: creator.leader_services_controller,
+ leader_services_context,
_guard: vec![],
};
let result = InstanceCreatorResult {
@@ -743,16 +753,11 @@ impl ProcedureExecutorCreator for DefaultProcedureExecutorCreator {
#[async_trait]
pub trait StandaloneLeaderServicesController: Send + Sync {
- /// Starts services that manage standalone metadata or WAL state.
+ /// Starts leader services that manage standalone metadata or WAL state.
///
/// The default implementation starts the procedure manager and WAL provider
/// during instance startup.
- async fn start(
- &self,
- procedure_manager: ProcedureManagerRef,
- wal_provider: WalProviderRef,
- region_server: RegionServer,
- ) -> Result<()>;
+ async fn start(&self, context: LeaderServicesContext) -> Result<()>;
/// Stops services started by [`StandaloneLeaderServicesController::start`].
async fn stop(
@@ -762,21 +767,42 @@ pub trait StandaloneLeaderServicesController: Send + Sync {
) -> Result<()>;
}
+#[derive(Clone)]
+/// Additional runtime handles for custom leader-service controllers.
+///
+/// The default standalone startup only needs to start/stop the procedure
+/// manager and WAL provider. Some embedders need to do more work around
+/// leader-service startup, for example reconciling metadata-backed runtime
+/// state before publishing writable leadership. Grouping those handles here
+/// keeps `Instance` small and avoids expanding
+/// [`StandaloneLeaderServicesController::start`] every time a custom lifecycle
+/// needs one more standalone component.
+pub struct LeaderServicesContext {
+ pub procedure_manager: ProcedureManagerRef,
+ pub wal_provider: WalProviderRef,
+ pub region_server: RegionServer,
+ pub kv_backend: KvBackendRef,
+ pub cache_registry: LayeredCacheRegistryRef,
+ pub catalog_manager: CatalogManagerRef,
+ pub flow_engine: FlowDualEngineRef,
+ pub frontend_client: Arc,
+ pub node_id: Option,
+ pub init_regions_parallelism: usize,
+ pub plugin_options: Vec,
+}
+
pub struct DefaultStandaloneLeaderServicesController;
#[async_trait]
impl StandaloneLeaderServicesController for DefaultStandaloneLeaderServicesController {
- async fn start(
- &self,
- procedure_manager: ProcedureManagerRef,
- wal_provider: WalProviderRef,
- _region_server: RegionServer,
- ) -> Result<()> {
- procedure_manager
+ async fn start(&self, context: LeaderServicesContext) -> Result<()> {
+ context
+ .procedure_manager
.start()
.await
.context(error::StartProcedureManagerSnafu)?;
- wal_provider
+ context
+ .wal_provider
.start()
.await
.context(error::StartWalProviderSnafu)
diff --git a/src/common/catalog/src/consts.rs b/src/common/catalog/src/consts.rs
index 1cd5db8a0c..dd09893177 100644
--- a/src/common/catalog/src/consts.rs
+++ b/src/common/catalog/src/consts.rs
@@ -112,6 +112,8 @@ pub const INFORMATION_SCHEMA_SSTS_STORAGE_TABLE_ID: u32 = 38;
pub const INFORMATION_SCHEMA_SSTS_INDEX_META_TABLE_ID: u32 = 39;
/// id for information_schema.alerts
pub const INFORMATION_SCHEMA_ALERTS_TABLE_ID: u32 = 40;
+/// id for information_schema.region_info
+pub const INFORMATION_SCHEMA_REGION_INFO_TABLE_ID: u32 = 41;
// ----- End of information_schema tables -----
diff --git a/src/common/function/src/scalars/json/json_get_rewriter.rs b/src/common/function/src/scalars/json/json_get_rewriter.rs
index 137b307412..0143ee05d5 100644
--- a/src/common/function/src/scalars/json/json_get_rewriter.rs
+++ b/src/common/function/src/scalars/json/json_get_rewriter.rs
@@ -59,7 +59,10 @@ impl FunctionRewrite for JsonGetRewriter {
// json_get(column, path, )
// )
fn inject_type_from_cast_expr(cast: Cast) -> Result> {
- let Cast { expr, data_type } = cast;
+ let Cast {
+ expr,
+ mut data_type,
+ } = cast;
let mut json_get = match *expr {
Expr::ScalarFunction(f)
@@ -75,6 +78,9 @@ fn inject_type_from_cast_expr(cast: Cast) -> Result> {
}
};
+ if data_type.is_string() {
+ data_type = DataType::Utf8View;
+ }
let with_type = ScalarValue::try_new_null(&data_type).map(|x| Expr::Literal(x, None))?;
json_get.args.push(with_type);
Ok(Transformed::yes(Expr::ScalarFunction(json_get)))
diff --git a/src/common/meta/src/cache/container.rs b/src/common/meta/src/cache/container.rs
index e3a3e13a76..e3a1a50adc 100644
--- a/src/common/meta/src/cache/container.rs
+++ b/src/common/meta/src/cache/container.rs
@@ -196,8 +196,8 @@ where
#[async_trait::async_trait]
impl CacheInvalidator for CacheContainer
where
- K: Send + Sync,
- V: Send + Sync,
+ K: Hash + Eq + Send + Sync + 'static,
+ V: Clone + Send + Sync + 'static,
{
async fn invalidate(&self, _ctx: &Context, caches: &[CacheIdent]) -> Result<()> {
let idents = caches
@@ -211,6 +211,12 @@ where
Ok(())
}
+
+ fn invalidate_all(&self) -> Result<()> {
+ self.inc_version();
+ self.cache.invalidate_all();
+ Ok(())
+ }
}
impl CacheContainer
diff --git a/src/common/meta/src/cache/flow/table_flownode.rs b/src/common/meta/src/cache/flow/table_flownode.rs
index ebe3664202..4d3513a21d 100644
--- a/src/common/meta/src/cache/flow/table_flownode.rs
+++ b/src/common/meta/src/cache/flow/table_flownode.rs
@@ -210,7 +210,7 @@ mod tests {
use crate::cache::flow::table_flownode::{FlowIdent, new_table_flownode_set_cache};
use crate::instruction::{CacheIdent, CreateFlow, DropFlow};
use crate::key::flow::FlowMetadataManager;
- use crate::key::flow::flow_info::FlowInfoValue;
+ use crate::key::flow::flow_info::{FlowInfoValue, FlowStatus};
use crate::key::flow::flow_route::FlowRouteValue;
use crate::kv_backend::memory::MemoryKvBackend;
use crate::peer::Peer;
@@ -242,11 +242,14 @@ mod tests {
catalog_name: DEFAULT_CATALOG_NAME.to_string(),
query_context: None,
flow_name: "my_flow".to_string(),
+ all_source_table_names: vec![],
+ unresolved_source_table_names: vec![],
raw_sql: "sql".to_string(),
expire_after: Some(300),
eval_interval_secs: None,
comment: "comment".to_string(),
options: Default::default(),
+ status: FlowStatus::Active,
created_time: chrono::Utc::now(),
updated_time: chrono::Utc::now(),
},
diff --git a/src/common/meta/src/cache/registry.rs b/src/common/meta/src/cache/registry.rs
index d541525f98..b7ee82b6e5 100644
--- a/src/common/meta/src/cache/registry.rs
+++ b/src/common/meta/src/cache/registry.rs
@@ -67,6 +67,13 @@ impl CacheInvalidator for LayeredCacheRegistry {
}
results.into_iter().collect::>>().map(|_| ())
}
+
+ fn invalidate_all(&self) -> Result<()> {
+ for registry in &self.layers {
+ registry.invalidate_all()?;
+ }
+ Ok(())
+ }
}
impl LayeredCacheRegistry {
@@ -124,6 +131,13 @@ impl CacheInvalidator for CacheRegistry {
.collect::>>()?;
Ok(())
}
+
+ fn invalidate_all(&self) -> Result<()> {
+ for invalidator in &self.indexes {
+ invalidator.invalidate_all()?;
+ }
+ Ok(())
+ }
}
impl CacheRegistry {
@@ -149,6 +163,8 @@ mod tests {
use crate::cache::registry::CacheRegistryBuilder;
use crate::cache::*;
+ use crate::cache_invalidator::{CacheInvalidator, Context};
+ use crate::error::Result;
use crate::instruction::CacheIdent;
fn always_true_filter(_: &CacheIdent) -> bool {
@@ -259,4 +275,91 @@ mod tests {
.unwrap();
assert_eq!(cache.name(), "string_cache");
}
+
+ #[tokio::test]
+ async fn test_registry_invalidate_all() {
+ let invalidator: Invalidator<_, String, CacheIdent> =
+ Box::new(|_, _| Box::pin(async { Ok(()) }));
+ let i32_cache = Arc::new(test_i32_cache("i32_cache", invalidator));
+ let invalidator: Invalidator<_, String, CacheIdent> =
+ Box::new(|_, _| Box::pin(async { Ok(()) }));
+ let string_cache = Arc::new(test_cache("string_cache", invalidator));
+
+ i32_cache.get(1).await.unwrap();
+ string_cache.get_by_ref("foo").await.unwrap();
+ assert!(i32_cache.contains_key(&1));
+ assert!(string_cache.contains_key("foo"));
+
+ let registry = CacheRegistryBuilder::default()
+ .add_cache(i32_cache.clone())
+ .add_cache(string_cache.clone())
+ .build();
+
+ registry.invalidate_all().unwrap();
+
+ assert!(!i32_cache.contains_key(&1));
+ assert!(!string_cache.contains_key("foo"));
+ }
+
+ struct LayerOrderInvalidator {
+ expected_order: i32,
+ order: Arc,
+ }
+
+ #[async_trait::async_trait]
+ impl CacheInvalidator for LayerOrderInvalidator {
+ async fn invalidate(&self, _ctx: &Context, _caches: &[CacheIdent]) -> Result<()> {
+ Ok(())
+ }
+
+ fn invalidate_all(&self) -> Result<()> {
+ let previous = self.order.fetch_add(1, Ordering::Relaxed);
+ assert_eq!(self.expected_order, previous);
+ Ok(())
+ }
+ }
+
+ #[tokio::test]
+ async fn test_layered_registry_invalidate_all() {
+ let order = Arc::new(AtomicI32::new(0));
+ let invalidator: Invalidator<_, String, CacheIdent> =
+ Box::new(|_, _| Box::pin(async { Ok(()) }));
+ let first_layer_cache = Arc::new(test_cache("first_layer_cache", invalidator));
+ let first_layer_order = Arc::new(LayerOrderInvalidator {
+ expected_order: 0,
+ order: order.clone(),
+ });
+ let first_layer = CacheRegistryBuilder::default()
+ .add_cache(first_layer_order)
+ .add_cache(first_layer_cache.clone())
+ .build();
+
+ let invalidator: Invalidator<_, String, CacheIdent> =
+ Box::new(|_, _| Box::pin(async { Ok(()) }));
+ let second_layer_cache = Arc::new(test_i32_cache("second_layer_cache", invalidator));
+ let second_layer_order = Arc::new(LayerOrderInvalidator {
+ expected_order: 1,
+ order: order.clone(),
+ });
+ let second_layer = CacheRegistryBuilder::default()
+ .add_cache(second_layer_order)
+ .add_cache(second_layer_cache.clone())
+ .build();
+
+ first_layer_cache.get_by_ref("foo").await.unwrap();
+ second_layer_cache.get(1).await.unwrap();
+ assert!(first_layer_cache.contains_key("foo"));
+ assert!(second_layer_cache.contains_key(&1));
+
+ let registry = LayeredCacheRegistryBuilder::default()
+ .add_cache_registry(first_layer)
+ .add_cache_registry(second_layer)
+ .build();
+
+ registry.invalidate_all().unwrap();
+
+ assert_eq!(2, order.load(Ordering::Relaxed));
+ assert!(!first_layer_cache.contains_key("foo"));
+ assert!(!second_layer_cache.contains_key(&1));
+ }
}
diff --git a/src/common/meta/src/cache_invalidator.rs b/src/common/meta/src/cache_invalidator.rs
index ffc3dd1c9a..4fe0699ba5 100644
--- a/src/common/meta/src/cache_invalidator.rs
+++ b/src/common/meta/src/cache_invalidator.rs
@@ -55,6 +55,13 @@ pub struct Context {
pub trait CacheInvalidator: Send + Sync {
async fn invalidate(&self, ctx: &Context, caches: &[CacheIdent]) -> Result<()>;
+ /// Invalidates every cache entry owned by this invalidator.
+ ///
+ /// This method is required so each implementer explicitly decides how
+ /// full-cache invalidation should behave. Implementations that intentionally
+ /// do nothing must document why a no-op is safe.
+ fn invalidate_all(&self) -> Result<()>;
+
fn name(&self) -> &'static str {
std::any::type_name::()
}
@@ -69,6 +76,11 @@ impl CacheInvalidator for DummyCacheInvalidator {
async fn invalidate(&self, _ctx: &Context, _caches: &[CacheIdent]) -> Result<()> {
Ok(())
}
+
+ fn invalidate_all(&self) -> Result<()> {
+ // Dummy invalidator owns no cache state, so there is nothing to clear.
+ Ok(())
+ }
}
#[async_trait::async_trait]
@@ -157,4 +169,11 @@ where
}
Ok(())
}
+
+ fn invalidate_all(&self) -> Result<()> {
+ // KvCacheInvalidator only knows how to invalidate explicit metadata
+ // keys. There is no safe generic way to enumerate or clear the backend
+ // keyspace, so full invalidation is intentionally a no-op here.
+ Ok(())
+ }
}
diff --git a/src/common/meta/src/ddl/create_flow.rs b/src/common/meta/src/ddl/create_flow.rs
index 7120e50425..ddfb0c0759 100644
--- a/src/common/meta/src/ddl/create_flow.rs
+++ b/src/common/meta/src/ddl/create_flow.rs
@@ -14,7 +14,7 @@
mod metadata;
-use std::collections::BTreeMap;
+use std::collections::{BTreeMap, HashMap};
use std::fmt;
use api::v1::ExpireAfter;
@@ -34,13 +34,14 @@ use serde::{Deserialize, Serialize};
use snafu::{ResultExt, ensure};
use strum::AsRefStr;
use table::metadata::TableId;
+use table::table_name::TableName;
use crate::cache_invalidator::Context;
use crate::ddl::DdlContext;
use crate::ddl::utils::{add_peer_context_if_needed, map_to_procedure_error};
use crate::error::{self, Result, UnexpectedSnafu};
use crate::instruction::{CacheIdent, CreateFlow, DropFlow};
-use crate::key::flow::flow_info::FlowInfoValue;
+use crate::key::flow::flow_info::{FlowInfoValue, FlowStatus};
use crate::key::flow::flow_route::FlowRouteValue;
use crate::key::table_name::TableNameKey;
use crate::key::{DeserializedValueWithBytes, FlowId, FlowPartitionId};
@@ -67,6 +68,7 @@ impl CreateFlowProcedure {
flow_id: None,
peers: vec![],
source_table_ids: vec![],
+ unresolved_source_table_names: vec![],
flow_context: query_context.into(), // Convert to FlowQueryContext
state: CreateFlowState::Prepare,
prev_flow_info_value: None,
@@ -89,6 +91,8 @@ impl CreateFlowProcedure {
let create_if_not_exists = self.data.task.create_if_not_exists;
let or_replace = self.data.task.or_replace;
+ validate_flow_options(&self.data.task)?;
+
let flow_name_value = self
.context
.flow_metadata_manager
@@ -167,6 +171,21 @@ impl CreateFlowProcedure {
}
self.collect_source_tables().await?;
+ ensure!(
+ self.data.unresolved_source_table_names.is_empty()
+ || defer_on_missing_source(&self.data.task)?,
+ error::UnsupportedSnafu {
+ operation: format!(
+ "Create flow with missing source tables requires WITH ('{DEFER_ON_MISSING_SOURCE_KEY}'='true'): {}",
+ self.data
+ .unresolved_source_table_names
+ .iter()
+ .map(ToString::to_string)
+ .join(", ")
+ )
+ }
+ );
+ self.ensure_supported_replace_transition()?;
// Validate that source and sink tables are not the same
let sink_table_name = &self.data.task.sink_table_name;
@@ -189,13 +208,38 @@ impl CreateFlowProcedure {
if self.data.flow_id.is_none() {
self.allocate_flow_id().await?;
}
- self.data.state = CreateFlowState::CreateFlows;
- // determine flow type
self.data.flow_type = Some(get_flow_type_from_options(&self.data.task)?);
+ self.data.state = if self.data.is_pending() {
+ self.data.peers.clear();
+ CreateFlowState::CreateMetadata
+ } else {
+ CreateFlowState::CreateFlows
+ };
+
Ok(Status::executing(true))
}
+ fn ensure_supported_replace_transition(&self) -> Result<()> {
+ if !self.data.task.or_replace {
+ return Ok(());
+ }
+
+ let Some(prev_flow_info) = self.data.prev_flow_info_value.as_ref() else {
+ return Ok(());
+ };
+ let prev_pending = prev_flow_info.get_inner_ref().is_pending();
+ let new_pending = self.data.is_pending();
+ ensure!(
+ prev_pending == new_pending,
+ error::UnsupportedSnafu {
+ operation: "Replacing between pending and active flow states is not supported yet"
+ }
+ );
+
+ Ok(())
+ }
+
async fn on_flownode_create_flows(&mut self) -> Result {
// Safety: must be allocated.
let mut create_flow = Vec::with_capacity(self.data.peers.len());
@@ -365,6 +409,61 @@ pub fn get_flow_type_from_options(flow_task: &CreateFlowTask) -> Result Result {
+ flow_task
+ .flow_options
+ .get(DEFER_ON_MISSING_SOURCE_KEY)
+ .map(|value| {
+ value
+ .trim()
+ .to_ascii_lowercase()
+ .parse::()
+ .map_err(|_| {
+ error::UnexpectedSnafu {
+ err_msg: format!(
+ "Invalid flow option '{DEFER_ON_MISSING_SOURCE_KEY}': {value}"
+ ),
+ }
+ .build()
+ })
+ })
+ .transpose()
+ .map(|value| value.unwrap_or(false))
+}
+
+pub fn validate_flow_options(flow_task: &CreateFlowTask) -> Result<()> {
+ for key in flow_task.flow_options.keys() {
+ match key.as_str() {
+ DEFER_ON_MISSING_SOURCE_KEY | FlowType::FLOW_TYPE_KEY => {}
+ unknown => {
+ return UnexpectedSnafu {
+ err_msg: format!(
+ "Unknown flow option '{unknown}', supported user options: {DEFER_ON_MISSING_SOURCE_KEY}"
+ ),
+ }
+ .fail();
+ }
+ }
+ }
+
+ defer_on_missing_source(flow_task)?;
+ get_flow_type_from_options(flow_task)?;
+ Ok(())
+}
+
+fn user_runtime_flow_options(options: &HashMap) -> HashMap {
+ let mut options = options.clone();
+ options.remove(DEFER_ON_MISSING_SOURCE_KEY);
+ options
+}
+
+fn metadata_flow_options(options: &HashMap) -> HashMap {
+ options.clone()
+}
+
/// The state of [CreateFlowProcedure].
#[derive(Debug, Clone, Serialize, Deserialize, AsRefStr, PartialEq)]
pub enum CreateFlowState {
@@ -411,6 +510,8 @@ pub struct CreateFlowData {
pub(crate) flow_id: Option,
pub(crate) peers: Vec,
pub(crate) source_table_ids: Vec,
+ #[serde(default)]
+ pub(crate) unresolved_source_table_names: Vec,
/// Use alias for backward compatibility with QueryContext serialized data
#[serde(alias = "query_context")]
pub(crate) flow_context: FlowQueryContext,
@@ -424,6 +525,16 @@ pub struct CreateFlowData {
pub(crate) flow_type: Option,
}
+impl CreateFlowData {
+ pub(crate) fn is_pending(&self) -> bool {
+ !self.unresolved_source_table_names.is_empty()
+ }
+
+ pub(crate) fn is_active(&self) -> bool {
+ !self.is_pending()
+ }
+}
+
impl From<&CreateFlowData> for CreateRequest {
fn from(value: &CreateFlowData) -> Self {
let flow_id = value.flow_id.unwrap();
@@ -446,7 +557,7 @@ impl From<&CreateFlowData> for CreateRequest {
.map(|seconds| api::v1::EvalInterval { seconds }),
comment: value.task.comment.clone(),
sql: value.task.sql.clone(),
- flow_options: value.task.flow_options.clone(),
+ flow_options: user_runtime_flow_options(&value.task.flow_options),
};
let flow_type = value.flow_type.unwrap_or_default().to_string();
@@ -466,9 +577,9 @@ impl From<&CreateFlowData> for (FlowInfoValue, Vec<(FlowPartitionId, FlowRouteVa
eval_interval_secs: eval_interval,
comment,
sql,
- flow_options: mut options,
..
} = value.task.clone();
+ let mut options = metadata_flow_options(&value.task.flow_options);
let flownode_ids = value
.peers
@@ -484,7 +595,7 @@ impl From<&CreateFlowData> for (FlowInfoValue, Vec<(FlowPartitionId, FlowRouteVa
.collect::>();
let flow_type = value.flow_type.unwrap_or_default().to_string();
- options.insert("flow_type".to_string(), flow_type);
+ options.insert(FlowType::FLOW_TYPE_KEY.to_string(), flow_type);
let mut create_time = chrono::Utc::now();
if let Some(prev_flow_value) = value.prev_flow_info_value.as_ref()
@@ -495,6 +606,8 @@ impl From<&CreateFlowData> for (FlowInfoValue, Vec<(FlowPartitionId, FlowRouteVa
let flow_info: FlowInfoValue = FlowInfoValue {
source_table_ids: value.source_table_ids.clone(),
+ all_source_table_names: value.task.source_table_names.clone(),
+ unresolved_source_table_names: value.unresolved_source_table_names.clone(),
sink_table_name,
flownode_ids,
catalog_name,
@@ -506,6 +619,11 @@ impl From<&CreateFlowData> for (FlowInfoValue, Vec<(FlowPartitionId, FlowRouteVa
eval_interval_secs: eval_interval,
comment,
options,
+ status: if value.is_active() {
+ FlowStatus::Active
+ } else {
+ FlowStatus::PendingSources
+ },
created_time: create_time,
updated_time: chrono::Utc::now(),
};
diff --git a/src/common/meta/src/ddl/create_flow/metadata.rs b/src/common/meta/src/ddl/create_flow/metadata.rs
index 27b85b7946..f97ecfdf4a 100644
--- a/src/common/meta/src/ddl/create_flow/metadata.rs
+++ b/src/common/meta/src/ddl/create_flow/metadata.rs
@@ -12,10 +12,8 @@
// See the License for the specific language governing permissions and
// limitations under the License.
-use snafu::OptionExt;
-
use crate::ddl::create_flow::CreateFlowProcedure;
-use crate::error::{self, Result};
+use crate::error::Result;
use crate::key::table_name::TableNameKey;
impl CreateFlowProcedure {
@@ -34,9 +32,8 @@ impl CreateFlowProcedure {
Ok(())
}
- /// Ensures all source tables exist and collects source table ids
+ /// Collects source table ids and keeps track of missing tables.
pub(crate) async fn collect_source_tables(&mut self) -> Result<()> {
- // Ensures all source tables exist.
let keys = self
.data
.task
@@ -52,22 +49,24 @@ impl CreateFlowProcedure {
.batch_get(keys)
.await?;
- let source_table_ids = self
+ let mut resolved = Vec::with_capacity(self.data.task.source_table_names.len());
+ let mut unresolved = Vec::new();
+
+ for (name, table_id) in self
.data
.task
.source_table_names
.iter()
.zip(source_table_ids)
- .map(|(name, table_id)| {
- Ok(table_id
- .with_context(|| error::TableNotFoundSnafu {
- table_name: name.to_string(),
- })?
- .table_id())
- })
- .collect::>>()?;
+ {
+ match table_id {
+ Some(table_id) => resolved.push(table_id.table_id()),
+ None => unresolved.push(name.clone()),
+ }
+ }
- self.data.source_table_ids = source_table_ids;
+ self.data.source_table_ids = resolved;
+ self.data.unresolved_source_table_names = unresolved;
Ok(())
}
}
diff --git a/src/common/meta/src/ddl/drop_flow/metadata.rs b/src/common/meta/src/ddl/drop_flow/metadata.rs
index 0437098be3..7afd00f9d5 100644
--- a/src/common/meta/src/ddl/drop_flow/metadata.rs
+++ b/src/common/meta/src/ddl/drop_flow/metadata.rs
@@ -43,7 +43,7 @@ impl DropFlowProcedure {
.map(|(_, value)| value)
.collect::>();
ensure!(
- !flow_route_values.is_empty(),
+ flow_info_value.is_pending() || !flow_route_values.is_empty(),
error::FlowRouteNotFoundSnafu {
flow_name: format_full_flow_name(catalog_name, flow_name),
}
diff --git a/src/common/meta/src/ddl/tests/create_flow.rs b/src/common/meta/src/ddl/tests/create_flow.rs
index 344fc05024..a1a6c040f1 100644
--- a/src/common/meta/src/ddl/tests/create_flow.rs
+++ b/src/common/meta/src/ddl/tests/create_flow.rs
@@ -16,12 +16,17 @@ use std::assert_matches;
use std::collections::HashMap;
use std::sync::Arc;
+use api::v1::flow::CreateRequest;
use common_catalog::consts::{DEFAULT_CATALOG_NAME, DEFAULT_SCHEMA_NAME};
+use common_procedure::Status;
use common_procedure_test::execute_procedure_until_done;
use table::table_name::TableName;
use crate::ddl::DdlContext;
-use crate::ddl::create_flow::{CreateFlowData, CreateFlowProcedure, CreateFlowState, FlowType};
+use crate::ddl::create_flow::{
+ CreateFlowData, CreateFlowProcedure, CreateFlowState, DEFER_ON_MISSING_SOURCE_KEY, FlowType,
+ defer_on_missing_source,
+};
use crate::ddl::test_util::create_table::test_create_table_task;
use crate::ddl::test_util::flownode_handler::NaiveFlownodeHandler;
use crate::error;
@@ -63,6 +68,11 @@ pub(crate) fn test_create_flow_task(
}
}
+fn enable_defer_on_missing_source(task: &mut CreateFlowTask) {
+ task.flow_options
+ .insert(DEFER_ON_MISSING_SOURCE_KEY.to_string(), "true".to_string());
+}
+
#[tokio::test]
async fn test_create_flow_source_table_not_found() {
let source_table_names = vec![TableName::new(
@@ -78,7 +88,261 @@ async fn test_create_flow_source_table_not_found() {
let query_ctx = test_query_context();
let mut procedure = CreateFlowProcedure::new(task, query_ctx, ddl_context);
let err = procedure.on_prepare().await.unwrap_err();
- assert_matches!(err, error::Error::TableNotFound { .. });
+ assert_matches!(err, error::Error::Unsupported { .. });
+ assert!(
+ err.to_string()
+ .contains("requires WITH ('defer_on_missing_source'='true')")
+ );
+}
+
+#[tokio::test]
+async fn test_create_pending_flow_source_table_not_found_with_defer() {
+ let source_table_names = vec![TableName::new(
+ DEFAULT_CATALOG_NAME,
+ DEFAULT_SCHEMA_NAME,
+ "my_table",
+ )];
+ let sink_table_name =
+ TableName::new(DEFAULT_CATALOG_NAME, DEFAULT_SCHEMA_NAME, "my_sink_table");
+ let mut task = test_create_flow_task("my_flow", source_table_names, sink_table_name, false);
+ enable_defer_on_missing_source(&mut task);
+ let node_manager = Arc::new(MockFlownodeManager::new(NaiveFlownodeHandler));
+ let ddl_context = new_ddl_context(node_manager);
+ let query_ctx = test_query_context();
+ let mut procedure = CreateFlowProcedure::new(task, query_ctx, ddl_context.clone());
+ let status = procedure.on_prepare().await.unwrap();
+ assert_matches!(status, Status::Executing { persist: true, .. });
+ assert_eq!(procedure.data.unresolved_source_table_names.len(), 1);
+ assert_eq!(procedure.data.source_table_ids, Vec::::new());
+
+ let output = execute_procedure_until_done(&mut procedure).await.unwrap();
+ let flow_id = *output.downcast_ref::().unwrap();
+ let flow_info = ddl_context
+ .flow_metadata_manager
+ .flow_info_manager()
+ .get(flow_id)
+ .await
+ .unwrap()
+ .unwrap();
+ assert_eq!(flow_info.source_table_ids(), Vec::::new());
+ assert_eq!(
+ flow_info
+ .options()
+ .get(DEFER_ON_MISSING_SOURCE_KEY)
+ .map(String::as_str),
+ Some("true")
+ );
+}
+
+#[tokio::test]
+async fn test_create_pending_flow_source_table_not_found_with_defer_false() {
+ let source_table_names = vec![TableName::new(
+ DEFAULT_CATALOG_NAME,
+ DEFAULT_SCHEMA_NAME,
+ "my_table",
+ )];
+ let sink_table_name =
+ TableName::new(DEFAULT_CATALOG_NAME, DEFAULT_SCHEMA_NAME, "my_sink_table");
+ let mut task = test_create_flow_task("my_flow", source_table_names, sink_table_name, false);
+ task.flow_options
+ .insert(DEFER_ON_MISSING_SOURCE_KEY.to_string(), "false".to_string());
+ let node_manager = Arc::new(MockFlownodeManager::new(NaiveFlownodeHandler));
+ let ddl_context = new_ddl_context(node_manager);
+ let query_ctx = test_query_context();
+ let mut procedure = CreateFlowProcedure::new(task, query_ctx, ddl_context);
+ let err = procedure.on_prepare().await.unwrap_err();
+ assert_matches!(err, error::Error::Unsupported { .. });
+ assert!(
+ err.to_string()
+ .contains("requires WITH ('defer_on_missing_source'='true')")
+ );
+}
+
+#[tokio::test]
+async fn test_create_pending_flow_records_partial_source_resolution() {
+ let existing_source = TableName::new(
+ DEFAULT_CATALOG_NAME,
+ DEFAULT_SCHEMA_NAME,
+ "partial_existing_source_table",
+ );
+ let missing_source = TableName::new(
+ DEFAULT_CATALOG_NAME,
+ DEFAULT_SCHEMA_NAME,
+ "partial_missing_source_table",
+ );
+ let sink_table_name = TableName::new(
+ DEFAULT_CATALOG_NAME,
+ DEFAULT_SCHEMA_NAME,
+ "partial_pending_sink_table",
+ );
+ let node_manager = Arc::new(MockFlownodeManager::new(NaiveFlownodeHandler));
+ let ddl_context = new_ddl_context(node_manager);
+
+ let existing_table_id = 3026;
+ let create_table_task =
+ test_create_table_task("partial_existing_source_table", existing_table_id);
+ ddl_context
+ .table_metadata_manager
+ .create_table_metadata(
+ create_table_task.table_info.clone(),
+ TableRouteValue::physical(vec![]),
+ HashMap::new(),
+ )
+ .await
+ .unwrap();
+
+ let mut task = test_create_flow_task(
+ "partial_pending_flow",
+ vec![existing_source.clone(), missing_source.clone()],
+ sink_table_name,
+ false,
+ );
+ enable_defer_on_missing_source(&mut task);
+ let query_ctx = test_query_context();
+ let mut procedure = CreateFlowProcedure::new(task, query_ctx, ddl_context.clone());
+ let status = procedure.on_prepare().await.unwrap();
+ assert_matches!(status, Status::Executing { persist: true, .. });
+ assert_eq!(procedure.data.source_table_ids, vec![existing_table_id]);
+ assert_eq!(
+ procedure.data.unresolved_source_table_names,
+ vec![missing_source.clone()]
+ );
+
+ let output = execute_procedure_until_done(&mut procedure).await.unwrap();
+ let flow_id = *output.downcast_ref::().unwrap();
+ let flow_info = ddl_context
+ .flow_metadata_manager
+ .flow_info_manager()
+ .get(flow_id)
+ .await
+ .unwrap()
+ .unwrap();
+
+ assert!(flow_info.is_pending());
+ assert_eq!(flow_info.source_table_ids(), &[existing_table_id]);
+ let expected_all_sources = vec![existing_source, missing_source.clone()];
+ assert_eq!(
+ flow_info.all_source_table_names(),
+ expected_all_sources.as_slice()
+ );
+ assert_eq!(flow_info.unresolved_source_table_names(), &[missing_source]);
+ assert!(flow_info.flownode_ids().is_empty());
+}
+
+#[test]
+fn test_defer_on_missing_source_defaults_false() {
+ let task = test_create_flow_task(
+ "my_flow",
+ vec![],
+ TableName::new(DEFAULT_CATALOG_NAME, DEFAULT_SCHEMA_NAME, "my_sink_table"),
+ false,
+ );
+
+ assert!(!defer_on_missing_source(&task).unwrap());
+}
+
+#[test]
+fn test_defer_on_missing_source_true() {
+ let mut task = test_create_flow_task(
+ "my_flow",
+ vec![],
+ TableName::new(DEFAULT_CATALOG_NAME, DEFAULT_SCHEMA_NAME, "my_sink_table"),
+ false,
+ );
+ task.flow_options
+ .insert(DEFER_ON_MISSING_SOURCE_KEY.to_string(), "true".to_string());
+
+ assert!(defer_on_missing_source(&task).unwrap());
+}
+
+#[test]
+fn test_defer_on_missing_source_invalid_value() {
+ let mut task = test_create_flow_task(
+ "my_flow",
+ vec![],
+ TableName::new(DEFAULT_CATALOG_NAME, DEFAULT_SCHEMA_NAME, "my_sink_table"),
+ false,
+ );
+ task.flow_options.insert(
+ DEFER_ON_MISSING_SOURCE_KEY.to_string(),
+ "invalid".to_string(),
+ );
+
+ let err = defer_on_missing_source(&task).unwrap_err();
+ assert!(
+ err.to_string()
+ .contains("Invalid flow option 'defer_on_missing_source': invalid")
+ );
+}
+
+#[tokio::test]
+async fn test_create_flow_rejects_unknown_option_in_meta_task() {
+ let mut task = test_create_flow_task(
+ "my_flow",
+ vec![],
+ TableName::new(DEFAULT_CATALOG_NAME, DEFAULT_SCHEMA_NAME, "my_sink_table"),
+ false,
+ );
+ task.flow_options
+ .insert("unknown_option".to_string(), "value".to_string());
+ let node_manager = Arc::new(MockFlownodeManager::new(NaiveFlownodeHandler));
+ let ddl_context = new_ddl_context(node_manager);
+ let query_ctx = test_query_context();
+ let mut procedure = CreateFlowProcedure::new(task, query_ctx, ddl_context);
+
+ let err = procedure.on_prepare().await.unwrap_err();
+ assert_matches!(err, error::Error::Unexpected { .. });
+ assert!(
+ err.to_string()
+ .contains("Unknown flow option 'unknown_option'")
+ );
+}
+
+#[test]
+fn test_create_request_strips_defer_on_missing_source_runtime_option() {
+ let mut task = test_create_flow_task(
+ "my_flow",
+ vec![],
+ TableName::new(DEFAULT_CATALOG_NAME, DEFAULT_SCHEMA_NAME, "my_sink_table"),
+ false,
+ );
+ enable_defer_on_missing_source(&mut task);
+
+ let data = CreateFlowData {
+ state: CreateFlowState::CreateFlows,
+ task,
+ flow_id: Some(1024),
+ peers: vec![],
+ source_table_ids: vec![],
+ unresolved_source_table_names: vec![],
+ flow_context: FlowQueryContext {
+ catalog: DEFAULT_CATALOG_NAME.to_string(),
+ schema: DEFAULT_SCHEMA_NAME.to_string(),
+ timezone: "UTC".to_string(),
+ extensions: HashMap::new(),
+ channel: 0,
+ snapshot_seqs: HashMap::new(),
+ sst_min_sequences: HashMap::new(),
+ },
+ prev_flow_info_value: None,
+ did_replace: false,
+ flow_type: Some(FlowType::Batching),
+ };
+
+ let request: CreateRequest = (&data).into();
+
+ assert!(
+ !request
+ .flow_options
+ .contains_key(DEFER_ON_MISSING_SOURCE_KEY)
+ );
+ assert_eq!(
+ request
+ .flow_options
+ .get(FlowType::FLOW_TYPE_KEY)
+ .map(String::as_str),
+ Some(FlowType::BATCHING)
+ );
}
pub(crate) async fn create_test_flow(
@@ -101,6 +365,27 @@ pub(crate) async fn create_test_flow(
*flow_id
}
+pub(crate) async fn create_test_pending_flow(
+ ddl_context: &DdlContext,
+ flow_name: &str,
+ source_table_names: Vec,
+ sink_table_name: TableName,
+) -> FlowId {
+ let mut task = test_create_flow_task(
+ flow_name,
+ source_table_names.clone(),
+ sink_table_name.clone(),
+ false,
+ );
+ enable_defer_on_missing_source(&mut task);
+ let query_ctx = test_query_context();
+ let mut procedure = CreateFlowProcedure::new(task, query_ctx, ddl_context.clone());
+ let output = execute_procedure_until_done(&mut procedure).await.unwrap();
+ let flow_id = output.downcast_ref::().unwrap();
+
+ *flow_id
+}
+
#[tokio::test]
async fn test_create_flow() {
let table_id = 1024;
@@ -154,6 +439,201 @@ async fn test_create_flow() {
assert_matches!(err, error::Error::FlowAlreadyExists { .. });
}
+#[tokio::test]
+async fn test_replace_pending_flow_with_active_flow_is_unsupported() {
+ let source_table_name = TableName::new(
+ DEFAULT_CATALOG_NAME,
+ DEFAULT_SCHEMA_NAME,
+ "replace_pending_source_table",
+ );
+ let sink_table_name = TableName::new(
+ DEFAULT_CATALOG_NAME,
+ DEFAULT_SCHEMA_NAME,
+ "replace_pending_sink_table",
+ );
+ let node_manager = Arc::new(MockFlownodeManager::new(NaiveFlownodeHandler));
+ let ddl_context = new_ddl_context(node_manager);
+
+ let pending_flow_id = create_test_pending_flow(
+ &ddl_context,
+ "replace_pending_flow",
+ vec![source_table_name.clone()],
+ sink_table_name.clone(),
+ )
+ .await;
+
+ let pending_flow = ddl_context
+ .flow_metadata_manager
+ .flow_info_manager()
+ .get(pending_flow_id)
+ .await
+ .unwrap()
+ .unwrap();
+ assert!(pending_flow.is_pending());
+ assert!(pending_flow.flownode_ids().is_empty());
+
+ let create_table_task = test_create_table_task("replace_pending_source_table", 1026);
+ ddl_context
+ .table_metadata_manager
+ .create_table_metadata(
+ create_table_task.table_info.clone(),
+ TableRouteValue::physical(vec![]),
+ HashMap::new(),
+ )
+ .await
+ .unwrap();
+
+ let mut replace_task = test_create_flow_task(
+ "replace_pending_flow",
+ vec![source_table_name],
+ sink_table_name,
+ false,
+ );
+ replace_task.or_replace = true;
+ let query_ctx = test_query_context();
+ let mut procedure = CreateFlowProcedure::new(replace_task, query_ctx, ddl_context.clone());
+ let err = procedure.on_prepare().await.unwrap_err();
+ assert_matches!(err, error::Error::Unsupported { .. });
+ assert!(
+ err.to_string()
+ .contains("Replacing between pending and active flow states")
+ );
+}
+
+#[tokio::test]
+async fn test_replace_active_flow_with_pending_flow_is_unsupported() {
+ let existing_source_table = TableName::new(
+ DEFAULT_CATALOG_NAME,
+ DEFAULT_SCHEMA_NAME,
+ "replace_active_source_table",
+ );
+ let missing_source_table = TableName::new(
+ DEFAULT_CATALOG_NAME,
+ DEFAULT_SCHEMA_NAME,
+ "replace_missing_source_table",
+ );
+ let sink_table_name = TableName::new(
+ DEFAULT_CATALOG_NAME,
+ DEFAULT_SCHEMA_NAME,
+ "replace_active_sink_table",
+ );
+
+ let node_manager = Arc::new(MockFlownodeManager::new(NaiveFlownodeHandler));
+ let ddl_context = new_ddl_context(node_manager);
+
+ let create_table_task = test_create_table_task("replace_active_source_table", 2026);
+ ddl_context
+ .table_metadata_manager
+ .create_table_metadata(
+ create_table_task.table_info.clone(),
+ TableRouteValue::physical(vec![]),
+ HashMap::new(),
+ )
+ .await
+ .unwrap();
+
+ let _flow_id = create_test_flow(
+ &ddl_context,
+ "replace_active_flow_to_pending",
+ vec![existing_source_table],
+ sink_table_name.clone(),
+ )
+ .await;
+
+ let mut replace_task = test_create_flow_task(
+ "replace_active_flow_to_pending",
+ vec![missing_source_table],
+ sink_table_name,
+ false,
+ );
+ enable_defer_on_missing_source(&mut replace_task);
+ replace_task.or_replace = true;
+ let query_ctx = test_query_context();
+ let mut procedure = CreateFlowProcedure::new(replace_task, query_ctx, ddl_context.clone());
+ let err = procedure.on_prepare().await.unwrap_err();
+ assert_matches!(err, error::Error::Unsupported { .. });
+ assert!(
+ err.to_string()
+ .contains("Replacing between pending and active flow states")
+ );
+}
+
+#[tokio::test]
+async fn test_replace_pending_flow_with_pending_flow_updates_metadata() {
+ let first_missing_source = TableName::new(
+ DEFAULT_CATALOG_NAME,
+ DEFAULT_SCHEMA_NAME,
+ "replace_pending_first_missing_source",
+ );
+ let second_missing_source = TableName::new(
+ DEFAULT_CATALOG_NAME,
+ DEFAULT_SCHEMA_NAME,
+ "replace_pending_second_missing_source",
+ );
+ let sink_table_name = TableName::new(
+ DEFAULT_CATALOG_NAME,
+ DEFAULT_SCHEMA_NAME,
+ "replace_pending_to_pending_sink_table",
+ );
+ let node_manager = Arc::new(MockFlownodeManager::new(NaiveFlownodeHandler));
+ let ddl_context = new_ddl_context(node_manager);
+
+ let original_flow_id = create_test_pending_flow(
+ &ddl_context,
+ "replace_pending_to_pending_flow",
+ vec![first_missing_source.clone()],
+ sink_table_name.clone(),
+ )
+ .await;
+
+ let original_flow = ddl_context
+ .flow_metadata_manager
+ .flow_info_manager()
+ .get(original_flow_id)
+ .await
+ .unwrap()
+ .unwrap();
+ assert!(original_flow.is_pending());
+ assert_eq!(
+ original_flow.unresolved_source_table_names(),
+ &[first_missing_source]
+ );
+ assert!(original_flow.flownode_ids().is_empty());
+
+ let mut replace_task = test_create_flow_task(
+ "replace_pending_to_pending_flow",
+ vec![second_missing_source.clone()],
+ sink_table_name,
+ false,
+ );
+ enable_defer_on_missing_source(&mut replace_task);
+ replace_task.or_replace = true;
+ let query_ctx = test_query_context();
+ let mut procedure = CreateFlowProcedure::new(replace_task, query_ctx, ddl_context.clone());
+ let output = execute_procedure_until_done(&mut procedure).await.unwrap();
+ let replaced_flow_id = *output.downcast_ref::().unwrap();
+ assert_eq!(replaced_flow_id, original_flow_id);
+
+ let replaced_flow = ddl_context
+ .flow_metadata_manager
+ .flow_info_manager()
+ .get(replaced_flow_id)
+ .await
+ .unwrap()
+ .unwrap();
+ assert!(replaced_flow.is_pending());
+ assert_eq!(replaced_flow.source_table_ids(), Vec::::new());
+ assert_eq!(
+ replaced_flow.unresolved_source_table_names(),
+ std::slice::from_ref(&second_missing_source)
+ );
+ assert_eq!(
+ replaced_flow.all_source_table_names(),
+ &[second_missing_source]
+ );
+ assert!(replaced_flow.flownode_ids().is_empty());
+}
+
#[tokio::test]
async fn test_create_flow_same_source_and_sink_table() {
let table_id = 1024;
@@ -228,6 +708,7 @@ fn test_create_flow_data_serialization_backward_compatibility() {
"flow_id": null,
"peers": [],
"source_table_ids": [],
+ "unresolved_source_table_names": [],
"query_context": {
"current_catalog": "old_catalog",
"current_schema": "old_schema",
@@ -265,6 +746,7 @@ fn test_create_flow_data_new_format_serialization() {
flow_id: None,
peers: vec![],
source_table_ids: vec![],
+ unresolved_source_table_names: vec![],
flow_context,
prev_flow_info_value: None,
did_replace: false,
@@ -327,6 +809,7 @@ fn test_flow_info_conversion_with_flow_context() {
flow_id: Some(123),
peers: vec![],
source_table_ids: vec![456, 789],
+ unresolved_source_table_names: vec![],
flow_context,
prev_flow_info_value: None,
did_replace: false,
diff --git a/src/common/meta/src/ddl/tests/drop_flow.rs b/src/common/meta/src/ddl/tests/drop_flow.rs
index af34da4809..400fd2e118 100644
--- a/src/common/meta/src/ddl/tests/drop_flow.rs
+++ b/src/common/meta/src/ddl/tests/drop_flow.rs
@@ -23,7 +23,7 @@ use table::table_name::TableName;
use crate::ddl::drop_flow::DropFlowProcedure;
use crate::ddl::test_util::create_table::test_create_table_task;
use crate::ddl::test_util::flownode_handler::NaiveFlownodeHandler;
-use crate::ddl::tests::create_flow::create_test_flow;
+use crate::ddl::tests::create_flow::{create_test_flow, create_test_pending_flow};
use crate::error;
use crate::key::table_route::TableRouteValue;
use crate::rpc::ddl::DropFlowTask;
@@ -91,3 +91,45 @@ async fn test_drop_flow() {
let err = procedure.on_prepare().await.unwrap_err();
assert_matches!(err, error::Error::FlowNotFound { .. });
}
+
+#[tokio::test]
+async fn test_drop_pending_flow_without_routes() {
+ let source_table_name = TableName::new(
+ DEFAULT_CATALOG_NAME,
+ DEFAULT_SCHEMA_NAME,
+ "drop_pending_missing_source_table",
+ );
+ let sink_table_name = TableName::new(
+ DEFAULT_CATALOG_NAME,
+ DEFAULT_SCHEMA_NAME,
+ "drop_pending_sink_table",
+ );
+ let node_manager = Arc::new(MockFlownodeManager::new(NaiveFlownodeHandler));
+ let ddl_context = new_ddl_context(node_manager);
+
+ let flow_id = create_test_pending_flow(
+ &ddl_context,
+ "drop_pending_flow",
+ vec![source_table_name],
+ sink_table_name,
+ )
+ .await;
+ let flow_info = ddl_context
+ .flow_metadata_manager
+ .flow_info_manager()
+ .get(flow_id)
+ .await
+ .unwrap()
+ .unwrap();
+ assert!(flow_info.is_pending());
+ assert!(flow_info.flownode_ids().is_empty());
+
+ let task = test_drop_flow_task("drop_pending_flow", flow_id, false);
+ let mut procedure = DropFlowProcedure::new(task, ddl_context.clone());
+ execute_procedure_until_done(&mut procedure).await;
+
+ let task = test_drop_flow_task("drop_pending_flow", flow_id, false);
+ let mut procedure = DropFlowProcedure::new(task, ddl_context);
+ let err = procedure.on_prepare().await.unwrap_err();
+ assert_matches!(err, error::Error::FlowNotFound { .. });
+}
diff --git a/src/common/meta/src/ddl_manager.rs b/src/common/meta/src/ddl_manager.rs
index 52af4a36af..8dceeb2e5a 100644
--- a/src/common/meta/src/ddl_manager.rs
+++ b/src/common/meta/src/ddl_manager.rs
@@ -15,8 +15,9 @@
use std::sync::Arc;
use std::time::Duration;
-use api::v1::Repartition;
use api::v1::alter_table_expr::Kind;
+use api::v1::repartition::Source as PbRepartitionSource;
+use api::v1::{PartitionExprs, Repartition};
use common_error::ext::BoxedError;
use common_procedure::{
BoxedProcedure, BoxedProcedureLoader, Output, ProcedureId, ProcedureManagerRef,
@@ -151,13 +152,18 @@ macro_rules! procedure_loader {
pub type RepartitionProcedureFactoryRef = Arc;
+pub enum RepartitionSource {
+ Partitioned { exprs: Vec },
+ Unpartitioned { partition_columns: Vec },
+}
+
pub trait RepartitionProcedureFactory: Send + Sync {
fn create(
&self,
ddl_ctx: &DdlContext,
table_name: TableName,
table_id: TableId,
- from_exprs: Vec,
+ source: RepartitionSource,
to_exprs: Vec,
timeout: Option,
) -> std::result::Result;
@@ -280,22 +286,38 @@ impl DdlManager {
&self,
table_id: TableId,
table_name: TableName,
- Repartition {
- from_partition_exprs,
- into_partition_exprs,
- }: Repartition,
+ repartition: Repartition,
wait: bool,
timeout: Duration,
) -> Result<(ProcedureId, Option +
+
+
+ +
## Try GreptimeDB
-```shell
-docker pull greptime/greptimedb
+**For AI agents** — paste this prompt into your agent:
+
+```text
+Read https://docs.greptime.com/SKILL.md and follow the instructions
+to deploy, configure, ingest, and query GreptimeDB.
```
```shell
@@ -131,7 +149,7 @@ docker run -p 127.0.0.1:4000-4003:4000-4003 \
--name greptime --rm \
greptime/greptimedb:latest standalone start \
--http-addr 0.0.0.0:4000 \
- --grpc-bind-addr 0.0.0.0:4001 \
+ --rpc-bind-addr 0.0.0.0:4001 \
--mysql-addr 0.0.0.0:4002 \
--postgres-addr 0.0.0.0:4003
```
@@ -153,20 +171,30 @@ Read more in the [full Install Guide](https://docs.greptime.com/getting-started/
## Build From Source
**Prerequisites:**
-* [Rust toolchain](https://www.rust-lang.org/tools/install) (nightly)
+* [Rust toolchain](https://www.rust-lang.org/tools/install) — nightly, pinned by [`rust-toolchain.toml`](https://github.com/GreptimeTeam/greptimedb/blob/main/rust-toolchain.toml)
* [Protobuf compiler](https://grpc.io/docs/protoc-installation/) (>= 3.15)
-* C/C++ building essentials, including `gcc`/`g++`/`autoconf` and glibc library (eg. `libc6-dev` on Ubuntu and `glibc-devel` on Fedora)
-* Python toolchain (optional): Required only if using some test scripts.
+* C/C++ building essentials: `gcc` / `g++` / `autoconf` and the glibc dev package (`libc6-dev` on Ubuntu, `glibc-devel` on Fedora)
+* Python toolchain (optional, only for some test scripts)
-**Build and Run:**
+**Build and run:**
```bash
-make
-cargo run -- standalone start
+make # build greptime binary
+cargo run -- standalone start # start in standalone mode
```
+**Common dev commands:**
+```bash
+make fmt # format Rust code
+make clippy # lint (fails on warnings)
+make test # unit + integration tests (uses cargo-nextest)
+make sqlness-test # SQL regression tests
+```
+
+See the [Contribution Guidelines](CONTRIBUTING.md) for the full developer workflow.
+
## Tools & Extensions
-- **Kubernetes**: [GreptimeDB Operator](https://github.com/GrepTimeTeam/greptimedb-operator)
+- **Kubernetes**: [GreptimeDB Operator](https://github.com/GreptimeTeam/greptimedb-operator)
- **Helm Charts**: [Greptime Helm Charts](https://github.com/GreptimeTeam/helm-charts)
- **Dashboard**: [Web UI](https://github.com/GreptimeTeam/dashboard)
- **gRPC Ingester**: [Go](https://github.com/GreptimeTeam/greptimedb-ingester-go), [Java](https://github.com/GreptimeTeam/greptimedb-ingester-java), [C++](https://github.com/GreptimeTeam/greptimedb-ingester-cpp), [Erlang](https://github.com/GreptimeTeam/greptimedb-ingester-erl), [Rust](https://github.com/GreptimeTeam/greptimedb-ingester-rust), [.NET](https://github.com/GreptimeTeam/greptimedb-ingester-dotnet)
@@ -175,18 +203,11 @@ cargo run -- standalone start
## Project Status
-> **Status:** [v1.0 GA](https://github.com/GreptimeTeam/greptimedb/releases/tag/v1.0.0) — generally available and production-ready! 🎉
+GreptimeDB is at [v1.0 GA](https://github.com/GreptimeTeam/greptimedb/releases/tag/v1.0.0) with stable APIs and regular releases. It runs in production at scale — [OceanBase Cloud](https://greptime.com/blogs/2025-07-22-user-case-obcloud-log-management-greptimedb) operates 80+ GreptimeDB clusters managing 300 TB of logs, cutting log storage cost by 60% after migrating from Grafana Loki. See more in [case studies](https://greptime.com/blogs/?category=Use%20Case).
-- Deployed in production handling billions of data points daily
-- Stable APIs, actively maintained, with regular releases ([version info](https://docs.greptime.com/nightly/reference/about-greptimedb-version))
+Read the [v1.0 highlights](https://greptime.com/blogs/2025-11-05-greptimedb-v1-highlights) and [2026 roadmap](https://greptime.com/blogs/2026-02-11-greptimedb-roadmap-2026), or browse the [version reference](https://docs.greptime.com/nightly/reference/about-greptimedb-version).
-GreptimeDB v1.0 marks a major milestone — stable APIs, production readiness, and proven performance at scale.
-
-**Learn more:** [v1.0 highlights](https://greptime.com/blogs/2025-11-05-greptimedb-v1-highlights) and [2026 roadmap](https://greptime.com/blogs/2026-02-11-greptimedb-roadmap-2026).
-
-For production use, we recommend v1.0 or later.
-
-If you find this project useful, a ⭐ would mean a lot to us!
+If GreptimeDB is useful to you, please star the repo.
[](https://www.star-history.com/#GreptimeTeam/GreptimeDB&Date)
@@ -216,15 +237,19 @@ We offer enterprise add-ons, services, training, and consulting.
## Contributing
-- Read our [Contribution Guidelines](https://github.com/GreptimeTeam/greptimedb/blob/main/CONTRIBUTING.md).
+- Read our [Contribution Guidelines](CONTRIBUTING.md).
- Explore [Internal Concepts](https://docs.greptime.com/contributor-guide/overview.html) and [DeepWiki](https://deepwiki.com/GreptimeTeam/greptimedb).
- Pick up a [good first issue](https://github.com/GreptimeTeam/greptimedb/issues?q=is%3Aissue+is%3Aopen+label%3A%22good+first+issue%22) and join the #contributors [Slack](https://greptime.com/slack) channel.
## Acknowledgement
-Special thanks to all contributors! See [AUTHORS.md](https://github.com/GreptimeTeam/greptimedb/blob/main/AUTHOR.md).
+Special thanks to all contributors! See [AUTHOR.md](AUTHOR.md).
- Uses [Apache Arrow™](https://arrow.apache.org/) (memory model)
- [Apache Parquet™](https://parquet.apache.org/) (file storage)
-- [Apache DataFusion™](https://arrow.apache.org/datafusion/) (query engine)
+- [Apache DataFusion™](https://datafusion.apache.org/) (query engine)
- [Apache OpenDAL™](https://opendal.apache.org/) (data access abstraction)
+
+---
+
+*All trademarks, logos, and brand names referenced in this README and in the Overview diagram are the property of their respective owners. Their use is for identification purposes only and does not imply endorsement or affiliation.*
diff --git a/config/config.md b/config/config.md
index b1630d97ad..0fae0caaa4 100644
--- a/config/config.md
+++ b/config/config.md
@@ -155,6 +155,8 @@
| `region_engine.mito.vector_cache_size` | String | Auto | Cache size for vectors and arrow arrays. Setting it to 0 to disable the cache.
+
## Try GreptimeDB
-```shell
-docker pull greptime/greptimedb
+**For AI agents** — paste this prompt into your agent:
+
+```text
+Read https://docs.greptime.com/SKILL.md and follow the instructions
+to deploy, configure, ingest, and query GreptimeDB.
```
```shell
@@ -131,7 +149,7 @@ docker run -p 127.0.0.1:4000-4003:4000-4003 \
--name greptime --rm \
greptime/greptimedb:latest standalone start \
--http-addr 0.0.0.0:4000 \
- --grpc-bind-addr 0.0.0.0:4001 \
+ --rpc-bind-addr 0.0.0.0:4001 \
--mysql-addr 0.0.0.0:4002 \
--postgres-addr 0.0.0.0:4003
```
@@ -153,20 +171,30 @@ Read more in the [full Install Guide](https://docs.greptime.com/getting-started/
## Build From Source
**Prerequisites:**
-* [Rust toolchain](https://www.rust-lang.org/tools/install) (nightly)
+* [Rust toolchain](https://www.rust-lang.org/tools/install) — nightly, pinned by [`rust-toolchain.toml`](https://github.com/GreptimeTeam/greptimedb/blob/main/rust-toolchain.toml)
* [Protobuf compiler](https://grpc.io/docs/protoc-installation/) (>= 3.15)
-* C/C++ building essentials, including `gcc`/`g++`/`autoconf` and glibc library (eg. `libc6-dev` on Ubuntu and `glibc-devel` on Fedora)
-* Python toolchain (optional): Required only if using some test scripts.
+* C/C++ building essentials: `gcc` / `g++` / `autoconf` and the glibc dev package (`libc6-dev` on Ubuntu, `glibc-devel` on Fedora)
+* Python toolchain (optional, only for some test scripts)
-**Build and Run:**
+**Build and run:**
```bash
-make
-cargo run -- standalone start
+make # build greptime binary
+cargo run -- standalone start # start in standalone mode
```
+**Common dev commands:**
+```bash
+make fmt # format Rust code
+make clippy # lint (fails on warnings)
+make test # unit + integration tests (uses cargo-nextest)
+make sqlness-test # SQL regression tests
+```
+
+See the [Contribution Guidelines](CONTRIBUTING.md) for the full developer workflow.
+
## Tools & Extensions
-- **Kubernetes**: [GreptimeDB Operator](https://github.com/GrepTimeTeam/greptimedb-operator)
+- **Kubernetes**: [GreptimeDB Operator](https://github.com/GreptimeTeam/greptimedb-operator)
- **Helm Charts**: [Greptime Helm Charts](https://github.com/GreptimeTeam/helm-charts)
- **Dashboard**: [Web UI](https://github.com/GreptimeTeam/dashboard)
- **gRPC Ingester**: [Go](https://github.com/GreptimeTeam/greptimedb-ingester-go), [Java](https://github.com/GreptimeTeam/greptimedb-ingester-java), [C++](https://github.com/GreptimeTeam/greptimedb-ingester-cpp), [Erlang](https://github.com/GreptimeTeam/greptimedb-ingester-erl), [Rust](https://github.com/GreptimeTeam/greptimedb-ingester-rust), [.NET](https://github.com/GreptimeTeam/greptimedb-ingester-dotnet)
@@ -175,18 +203,11 @@ cargo run -- standalone start
## Project Status
-> **Status:** [v1.0 GA](https://github.com/GreptimeTeam/greptimedb/releases/tag/v1.0.0) — generally available and production-ready! 🎉
+GreptimeDB is at [v1.0 GA](https://github.com/GreptimeTeam/greptimedb/releases/tag/v1.0.0) with stable APIs and regular releases. It runs in production at scale — [OceanBase Cloud](https://greptime.com/blogs/2025-07-22-user-case-obcloud-log-management-greptimedb) operates 80+ GreptimeDB clusters managing 300 TB of logs, cutting log storage cost by 60% after migrating from Grafana Loki. See more in [case studies](https://greptime.com/blogs/?category=Use%20Case).
-- Deployed in production handling billions of data points daily
-- Stable APIs, actively maintained, with regular releases ([version info](https://docs.greptime.com/nightly/reference/about-greptimedb-version))
+Read the [v1.0 highlights](https://greptime.com/blogs/2025-11-05-greptimedb-v1-highlights) and [2026 roadmap](https://greptime.com/blogs/2026-02-11-greptimedb-roadmap-2026), or browse the [version reference](https://docs.greptime.com/nightly/reference/about-greptimedb-version).
-GreptimeDB v1.0 marks a major milestone — stable APIs, production readiness, and proven performance at scale.
-
-**Learn more:** [v1.0 highlights](https://greptime.com/blogs/2025-11-05-greptimedb-v1-highlights) and [2026 roadmap](https://greptime.com/blogs/2026-02-11-greptimedb-roadmap-2026).
-
-For production use, we recommend v1.0 or later.
-
-If you find this project useful, a ⭐ would mean a lot to us!
+If GreptimeDB is useful to you, please star the repo.
[](https://www.star-history.com/#GreptimeTeam/GreptimeDB&Date)
@@ -216,15 +237,19 @@ We offer enterprise add-ons, services, training, and consulting.
## Contributing
-- Read our [Contribution Guidelines](https://github.com/GreptimeTeam/greptimedb/blob/main/CONTRIBUTING.md).
+- Read our [Contribution Guidelines](CONTRIBUTING.md).
- Explore [Internal Concepts](https://docs.greptime.com/contributor-guide/overview.html) and [DeepWiki](https://deepwiki.com/GreptimeTeam/greptimedb).
- Pick up a [good first issue](https://github.com/GreptimeTeam/greptimedb/issues?q=is%3Aissue+is%3Aopen+label%3A%22good+first+issue%22) and join the #contributors [Slack](https://greptime.com/slack) channel.
## Acknowledgement
-Special thanks to all contributors! See [AUTHORS.md](https://github.com/GreptimeTeam/greptimedb/blob/main/AUTHOR.md).
+Special thanks to all contributors! See [AUTHOR.md](AUTHOR.md).
- Uses [Apache Arrow™](https://arrow.apache.org/) (memory model)
- [Apache Parquet™](https://parquet.apache.org/) (file storage)
-- [Apache DataFusion™](https://arrow.apache.org/datafusion/) (query engine)
+- [Apache DataFusion™](https://datafusion.apache.org/) (query engine)
- [Apache OpenDAL™](https://opendal.apache.org/) (data access abstraction)
+
+---
+
+*All trademarks, logos, and brand names referenced in this README and in the Overview diagram are the property of their respective owners. Their use is for identification purposes only and does not imply endorsement or affiliation.*
diff --git a/config/config.md b/config/config.md
index b1630d97ad..0fae0caaa4 100644
--- a/config/config.md
+++ b/config/config.md
@@ -155,6 +155,8 @@
| `region_engine.mito.vector_cache_size` | String | Auto | Cache size for vectors and arrow arrays. Setting it to 0 to disable the cache.