Add support for backing up partial segments to remote storage. Disabled
by default, can be enabled with `--partial-backup-enabled`.
Safekeeper timeline has a background task which is subscribed to
`commit_lsn` and `flush_lsn` updates. After the partial segment was
updated (`flush_lsn` was changed), the segment will be uploaded to S3 in
about 15 minutes.
The filename format for partial segments is
`Segment_Term_Flush_Commit_skNN.partial`, where:
- `Segment` – the segment name, like `000000010000000000000001`
- `Term` – current term
- `Flush` – flush_lsn in hex format `{:016X}`, e.g. `00000000346BC568`
- `Commit` – commit_lsn in the same hex format
- `NN` – safekeeper_id, like `1`
The full object name example:
`000000010000000000000002_2_0000000002534868_0000000002534410_sk1.partial`
Each safekeeper will keep info about remote partial segments in its
control file. Code updates state in the control file before doing any S3
operations. This way control file stores information about all
potentially existing remote partial segments and can clean them up after
uploading a newer version.
Closes#6336
## Problem
The existing secondary download API relied on the caller to wait as long
as it took to complete -- for large shards that could be a long time, so
typical clients that might have a baked-in ~30s timeout would have a
problem.
## Summary of changes
- Take a `wait_ms` query parameter to instruct the pageserver how long
to wait: if the download isn't complete in this duration, then 201 is
returned instead of 200.
- For both 200 and 201 responses, include response body describing
download progress, in terms of layers and bytes. This is sufficient for
the caller to track how much data is being transferred and log/present
that status.
- In storage controller live migrations, use this API to apply a much
longer outer timeout, with smaller individual per-request timeouts, and
log the progress of the downloads.
- Add a test that injects layer download delays to exercise the new
behavior
## Problem
These fields were only optional for the convenience of the `local_fs`
test helper -- real remote storage backends provide them. It complicated
any code that actually wanted to use them for anything.
## Summary of changes
- Make these fields non-optional
- For azure/S3 it is an error if the server doesn't provide them
- For local_fs, use random strings as etags and the file's mtime for
last_modified.
Cancellation and timeouts are handled at remote_storage callsites, if
they are. However they should always be handled, because we've had
transient problems with remote storage connections.
- Add cancellation token to the `trait RemoteStorage` methods
- For `download*`, `list*` methods there is
`DownloadError::{Cancelled,Timeout}`
- For the rest now using `anyhow::Error`, it will have root cause
`remote_storage::TimeoutOrCancel::{Cancel,Timeout}`
- Both types have `::is_permanent` equivalent which should be passed to
`backoff::retry`
- New generic RemoteStorageConfig option `timeout`, defaults to 120s
- Start counting timeouts only after acquiring concurrency limiter
permit
- Cancellable permit acquiring
- Download stream timeout or cancellation is communicated via an
`std::io::Error`
- Exit backoff::retry by marking cancellation errors permanent
Fixes: #6096Closes: #4781
Co-authored-by: arpad-m <arpad-m@users.noreply.github.com>
Do list-delete operations in batches instead of doing full list first, to ensure
deletion makes progress even if there are a lot of files to remove.
To this end, add max_keys limit to remote storage list_files.
This PR is preliminary cleanups and refactoring around `remote_storage`
for next PR which will move the timeouts and cancellation into
`remote_storage`.
Summary:
- smaller drive-by fixes
- code simplification
- refactor common parts like `DownloadError::is_permanent`
- align error types with `RemoteStorage::list_*` to use more
`download_retry` helper
Cc: #6096
The solution we ended up for `backoff::retry` requires always cloning of
cancellation tokens even though there is just `.await`. Fix that, and
also turn the return type into `Option<Result<T, E>>` avoiding the need
for the `E::cancelled()` fn passed in.
Cc: #6096
Adds an endpoint to the pageserver to S3-recover an entire tenant to a
specific given timestamp.
Required input parameters:
* `travel_to`: the target timestamp to recover the S3 state to
* `done_if_after`: a timestamp that marks the beginning of the recovery
process. retries of the query should keep this value constant. it *must*
be after `travel_to`, and also after any changes we want to revert, and
must represent a point in time before the endpoint is being called, all
of these time points in terms of the time source used by S3. these
criteria need to hold even in the face of clock differences, so I
recommend waiting a specific amount of time, then taking
`done_if_after`, then waiting some amount of time again, and only then
issuing the request.
Also important to note: the timestamps in S3 work at second accuracy, so
one needs to add generous waits before and after for the process to work
smoothly (at least 2-3 seconds).
We ignore the added test for the mocked S3 for now due to a limitation
in moto: https://github.com/getmoto/moto/issues/7300 .
Part of https://github.com/neondatabase/cloud/issues/8233
Don't require AWS access keys (AWS_ACCESS_KEY_ID and
AWS_SECRET_ACCESS_KEY) for S3 usage in the pytests, and also allow
AWS_PROFILE to be passed.
One of the two methods is required however.
This allows local development like:
```
aws sso login --profile dev
export ENABLE_REAL_S3_REMOTE_STORAGE=nonempty REMOTE_STORAGE_S3_REGION=eu-central-1 REMOTE_STORAGE_S3_BUCKET=neon-github-ci-tests AWS_PROFILE=dev
cargo build_testing && RUST_BACKTRACE=1 ./scripts/pytest -k debug-pg16 test_runner/regress/test_tenant_delete.py::test_tenant_delete_smoke
```
related earlier PR for the cargo unit tests of the `remote_storage` crate: #6202
---------
Co-authored-by: Alexander Bayandin <alexander@neon.tech>
Adds a new `time_travel_recover` function to the `RemoteStorage` trait
that allows time travel like functionality for S3 buckets, regardless of
their content (it is not even pageserver related). It takes a different
approach from [this
post](https://aws.amazon.com/blogs/storage/point-in-time-restore-for-amazon-s3-buckets/)
that is more complicated.
It takes as input a prefix a target timestamp, and a limit timestamp:
* executes [`ListObjectVersions`](https://docs.aws.amazon.com/AmazonS3/latest/API/API_ListObjectVersions.html)
* obtains the latest version that comes before the target timestamp
* copies that latest version to the same prefix
* if there is versions newer than the limit timestamp, it doesn't do
anything for the file
The limit timestamp is meant to be some timestamp before the start of
the recovery operation and after any changes that one wants to revert.
For example, it might be the time point after a tenant was detached from
all involved pageservers. The limiting mechanism ensures that the
operation is idempotent and can be retried without causing additional
writes/copies.
The approach fulfills all the requirements laid out in 8233, and is a
recoverable operation. Nothing is deleted permanently, only new entries
added to the version log.
I also enable [nextest retries](https://nexte.st/book/retries.html) to
help with some general S3 flakiness (on top of low level retries).
Part of https://github.com/neondatabase/cloud/issues/8233
Makes the `RemoteStorage` trait not be based on `async_trait` any more.
To avoid recursion in async (not supported by Rust), we made
`GenericRemoteStorage` generic on the "Unreliable" variant. That allows
us to have the unreliable wrapper never contain/call itself.
related earlier work: #6305
Implement API for cloning a single timeline inside a safekeeper. Also
add API for calculating a sha256 hash of WAL, which is used in tests.
`/copy` API works by copying objects inside S3 for all but the last
segments, and the last segments are copied on-disk. A special temporary
directory is created for a timeline, because copy can take a lot of
time, especially for large timelines. After all files segments have been
prepared, this directory is mounted to the main tree and timeline is
loaded to memory.
Some caveats:
- large timelines can take a lot of time to copy, because we need to
copy many S3 segments
- caller should wait for HTTP call to finish indefinetely and don't
close the HTTP connection, because it will stop the process, which is
not continued in the background
- `until_lsn` must be a valid LSN, otherwise bad things can happen
- API will return 200 if specified `timeline_id` already exists, even if
it's not a copy
- each safekeeper will try to copy S3 segments, so it's better to not
call this API in-parallel on different safekeepers
Store the content of the `last-modified` and `etag` HTTP headers in
`Download`.
This serves both as the first step towards #6199 and as a preparation
for tests in #6155 .
There is double buffering in remote_storage and in pageserver for 8KiB
in using `tokio::io::copy` to read `BufReader<ReaderStream<_>>`.
Switches downloads and uploads to use `Stream<Item =
std::io::Result<Bytes>>`. Caller and only caller now handles setting up
buffering. For reading, `Stream<Item = ...>` is also a `AsyncBufRead`,
so when writing to a file, we now have `tokio::io::copy_buf` reading
full buffers and writing them to `tokio::io::BufWriter` which handles
the buffering before dispatching over to `tokio::fs::File`.
Additionally implements streaming uploads for azure. With azure
downloads are a bit nicer than before, but not much; instead of one huge
vec they just hold on to N allocations we got over the wire.
This PR will also make it trivial to switch reading and writing to
io-uring based methods.
Cc: #5563.
## Problem
The pageserver had two ways of loading a tenant:
- `spawn_load` would trust on-disk content to reflect all existing
timelines
- `spawn_attach` would list timelines in remote storage.
It was incorrect for `spawn_load` to trust local disk content, because
it doesn't know if the tenant might have been attached and written
somewhere else. To make this correct would requires some generation
number checks, but the payoff is to avoid one S3 op per tenant at
startup, so it's not worth the complexity -- it is much simpler to have
one way to load a tenant.
## Summary of changes
- `Tenant` objects are always created with `Tenant::spawn`: there is no
more distinction between "load" and "attach".
- The ability to run without remote storage (for `neon_local`) is
preserved by adding a branch inside `attach` that uses a fallback
`load_local` if no remote_storage is present.
- Fix attaching a tenant when it has a timeline with no IndexPart: this
can occur if a newly created timeline manages to upload a layer before
it has uploaded an index.
- The attach marker file that used to indicate whether a tenant should
be "loaded" or "attached" is no longer needed, and is removed.
- The GenericRemoteStorage interface gets a `list()` method that maps
more directly to what ListObjects does, returning both keys and common
prefixes. The existing `list_files` and `list_prefixes` methods are just
calls into `list()` now -- these can be removed later if we would like
to shrink the interface a bit.
- The remote deletion marker is moved into `timelines/` and detected as
part of listing timelines rather than as a separate GET request. If any
existing tenants have a marker in the old location (unlikely, only
happens if something crashes mid-delete), then they will rely on the
control plane retrying to complete their deletion.
- Revise S3 calls for timeline listing and tenant load to take a
cancellation token, and retry forever: it never makes sense to make a
Tenant broken because of a transient S3 issue.
## Breaking changes
- The remote deletion marker is moved from `deleted` to
`timelines/deleted` within the tenant prefix. Markers in the old
location will be ignored: it is the control plane's responsibility to
retry deletions until they succeed. Markers in the new location will be
tolerated by the previous release of pageserver via
https://github.com/neondatabase/neon/pull/5632
- The local `attaching` marker file is no longer written. Therefore, if
the pageserver is downgraded after running this code, the old pageserver
will not be able to distinguish between partially attached tenants and
fully attached tenants. This would only impact tenants that were partway
through attaching at the moment of downgrade. In the unlikely even t
that we do experience an incident that prompts us to roll back, then we
may check for attach operations in flight, and manually insert
`attaching` marker files as needed.
---------
Co-authored-by: Christian Schwarz <christian@neon.tech>
Adds prototype-level support for [Azure blob storage](https://azure.microsoft.com/en-us/products/storage/blobs). Some corners were cut, see the TODOs and the followup issue #5567 for details.
Steps to try it out:
* Create a storage account with block blobs (this is a per-storage
account setting).
* Create a container inside that storage account.
* Set the appropriate env vars: `AZURE_STORAGE_ACCOUNT,
AZURE_STORAGE_ACCESS_KEY, REMOTE_STORAGE_AZURE_CONTAINER,
REMOTE_STORAGE_AZURE_REGION`
* Set the env var `ENABLE_REAL_AZURE_REMOTE_STORAGE=y` and run `cargo
test -p remote_storage azure`
Fixes #5562
Fixes#4689 by replacing all of `std::Path` , `std::PathBuf` with
`camino::Utf8Path`, `camino::Utf8PathBuf` in
- pageserver
- safekeeper
- control_plane
- libs/remote_storage
Co-authored-by: Joonas Koivunen <joonas@neon.tech>
## Problem
Pageservers must not delete objects or advertise updates to
remote_consistent_lsn without checking that they hold the latest
generation for the tenant in question (see [the RFC](
https://github.com/neondatabase/neon/blob/main/docs/rfcs/025-generation-numbers.md))
In this PR:
- A new "deletion queue" subsystem is introduced, through which
deletions flow
- `RemoteTimelineClient` is modified to send deletions through the
deletion queue:
- For GC & compaction, deletions flow through the full generation
verifying process
- For timeline deletions, deletions take a fast path that bypasses
generation verification
- The `last_uploaded_consistent_lsn` value in `UploadQueue` is replaced
with a mechanism that maintains a "projected" lsn (equivalent to the
previous property), and a "visible" LSN (which is the one that we may
share with safekeepers).
- Until `control_plane_api` is set, all deletions skip generation
validation
- Tests are introduced for the new functionality in
`test_pageserver_generations.py`
Once this lands, if a pageserver is configured with the
`control_plane_api` configuration added in
https://github.com/neondatabase/neon/pull/5163, it becomes safe to
attach a tenant to multiple pageservers concurrently.
---------
Co-authored-by: Joonas Koivunen <joonas@neon.tech>
Co-authored-by: Christian Schwarz <christian@neon.tech>
Add infrastructure to dynamically load postgres extensions and shared libraries from remote extension storage.
Before postgres start downloads list of available remote extensions and libraries, and also downloads 'shared_preload_libraries'. After postgres is running, 'compute_ctl' listens for HTTP requests to load files.
Postgres has new GUC 'extension_server_port' to specify port on which 'compute_ctl' listens for requests.
When PostgreSQL requests a file, 'compute_ctl' downloads it.
See more details about feature design and remote extension storage layout in docs/rfcs/024-extension-loading.md
---------
Co-authored-by: Anastasia Lubennikova <anastasia@neon.tech>
Co-authored-by: Alek Westover <alek.westover@gmail.com>
## Problem
`cargo +nightly doc` is giving a lot of warnings: broken links, naked
URLs, etc.
## Summary of changes
* update the `proc-macro2` dependency so that it can compile on latest
Rust nightly, see https://github.com/dtolnay/proc-macro2/pull/391 and
https://github.com/dtolnay/proc-macro2/issues/398
* allow the `private_intra_doc_links` lint, as linking to something
that's private is always more useful than just mentioning it without a
link: if the link breaks in the future, at least there is a warning due
to that. Also, one might enable
[`--document-private-items`](https://doc.rust-lang.org/cargo/commands/cargo-doc.html#documentation-options)
in the future and make these links work in general.
* fix all the remaining warnings given by `cargo +nightly doc`
* make it possible to run `cargo doc` on stable Rust by updating
`opentelemetry` and associated crates to version 0.19, pulling in a fix
that previously broke `cargo doc` on stable:
https://github.com/open-telemetry/opentelemetry-rust/pull/904
* Add `cargo doc` to CI to ensure that it won't get broken in the
future.
Fixes#2557
## Future work
* Potentially, it might make sense, for development purposes, to publish
the generated rustdocs somewhere, like for example [how the rust
compiler does
it](https://doc.rust-lang.org/nightly/nightly-rustc/rustc_driver/index.html).
I will file an issue for discussion.
Handle test failures like:
```
AssertionError: assert not ['$ts WARN delete_timeline{tenant_id=X timeline_id=Y}: About to remove 1 files\n']
```
Instead of logging:
```
WARN delete_timeline{tenant_id=X timeline_id=Y}: Found 1 files not bound to index_file.json, proceeding with their deletion
WARN delete_timeline{tenant_id=X timeline_id=Y}: About to remove 1 files
```
For each one operation of timeline deletion, list all unref files with
`info!`, and then continue to delete them with the added spice of
logging the rare/never happening non-utf8 name with `warn!`.
Rationale for `info!` instead of `warn!`: this is a normal operation;
like we had mentioned in `test_import.py` -- basically whenever we
delete a timeline which is not idle.
Rationale for N * (`ìnfo!`|`warn!`): symmetry for the layer deletions;
if we could ever need those, we could also need these for layer files
which are not yet mentioned in `index_part.json`.
---------
Co-authored-by: Christian Schwarz <christian@neon.tech>
We currently have a semaphore based rate limiter which we hope will keep
us under S3 limits. However, the semaphore does not consider time, so
I've been hesitant to raise the concurrency limit of 100.
See #3698.
The PR Introduces a leaky-bucket based rate limiter instead of the
`tokio::sync::Semaphore` which will allow us to raise the limit later
on. The configuration changes are not contained here.
Replaces `Box<(dyn io::AsyncRead + Unpin + Send + Sync + 'static)>` with
`impl io::AsyncRead + Unpin + Send + Sync + 'static` usages in the
`RemoteStorage` interface, to make it closer to
[`#![feature(async_fn_in_trait)]`](https://blog.rust-lang.org/inside-rust/2022/11/17/async-fn-in-trait-nightly.html)
For `GenericRemoteStorage`, replaces `type Target = dyn RemoteStorage`
with another impl with `RemoteStorage` methods inside it.
We can reuse the trait, that would require importing the trait in every
file where it's used and makes us farther from the unstable feature.
After this PR, I've manged to create a patch with the changes:
https://github.com/neondatabase/neon/compare/kb/less-dyn-storage...kb/nightly-async-trait?expand=1
Current rust implementation does not like recursive async trait calls,
so `UnreliableWrapper` was removed: it contained a
`GenericRemoteStorage` that implemented the `RemoteStorage` trait, and
itself implemented the trait, which nightly rustc did not like and
proposed to box the future.
Similarly, `GenericRemoteStorage` cannot implement `RemoteStorage` for
nightly rustc to work, since calls various remote storages' methods from
inside.
I've compiled current `main` and the nightly branch both with `time env
RUSTC_WRAPPER="" cargo +nightly build --all --timings` command, and got
```
Finished dev [optimized + debuginfo] target(s) in 2m 04s
env RUSTC_WRAPPER="" cargo +nightly build --all --timings 1283.19s user 50.40s system 1074% cpu 2:04.15 total
for the new feature tried and
Finished dev [optimized + debuginfo] target(s) in 2m 40s
env RUSTC_WRAPPER="" cargo +nightly build --all --timings 1288.59s user 52.06s system 834% cpu 2:40.71 total
for the old async_trait approach.
```
On my machine, the `remote_storage` lib compilation takes ~10 less time
with the nightly feature (left) than the regular main (right).
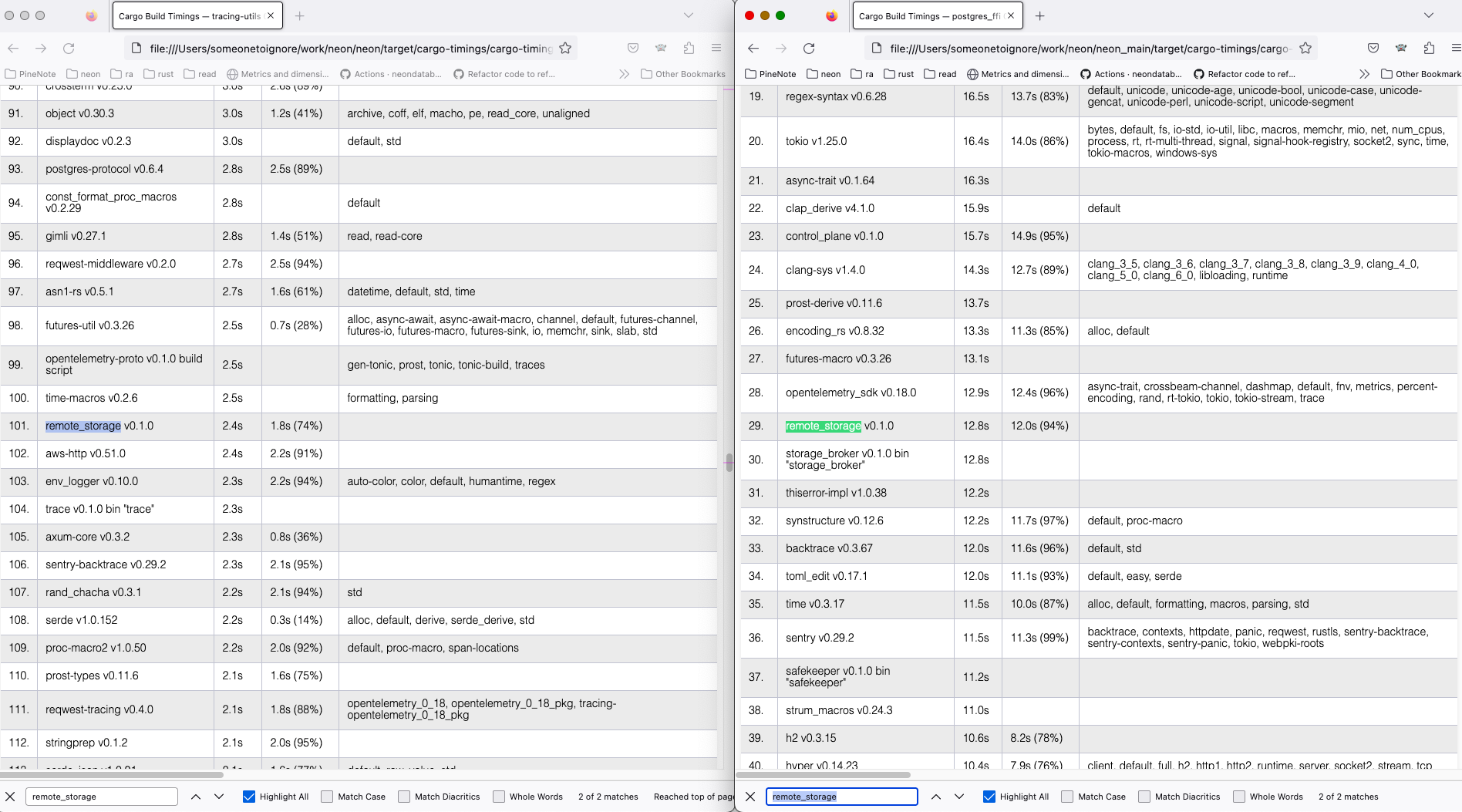
Full cargo reports are available at
[timings.zip](https://github.com/neondatabase/neon/files/11179369/timings.zip)
In S3, pageserver only lists tenants (prefixes) on S3, no other keys.
Remove the list operation from the API, since S3 impl does not seem to
work normally and not used anyway,
- Add support for splitting async postgres_backend into read and write halfes.
Safekeeper needs this for bidirectional streams. To this end, encapsulate
reading-writing postgres messages to framed.rs with split support without any
additional changes (relying on BufRead for reading and BytesMut out buffer for
writing).
- Use async postgres_backend throughout safekeeper (and in proxy auth link
part).
- In both safekeeper COPY streams, do read-write from the same thread/task with
select! for easier error handling.
- Tidy up finishing CopyBoth streams in safekeeper sending and receiving WAL
-- join split parts back catching errors from them before returning.
Initially I hoped to do that read-write without split at all, through polling
IO:
https://github.com/neondatabase/neon/pull/3522
However that turned out to be more complicated than I initially expected
due to 1) borrow checking and 2) anon Future types. 1) required Rc<Refcell<...>>
which is Send construct just to satisfy the checker; 2) can be workaround with
transmute. But this is so messy that I decided to leave split.
Remote operations fail sometimes due to network failures or other
external reasons. Add retry logic to all the remote downloads, so that
a transient failure at pageserver startup or tenant attach doesn't
cause the whole tenant to be marked as Broken.
Like in the uploads retry logic, we print the failure to the log as a
WARNing after three retries, but keep retrying. We will retry up to 10
times now, before returning the error to the caller.
To test the retries, I created a new RemoteStorage wrapper that simulates
failures, by returning an error for the first N times that a remote
operation is performed. It can be enabled by setting a new
"test_remote_failures" option in the pageserver config file.
Fixes#3112
Removes the race during pageserver initial timeline creation that lead to partial layer uploads.
This race is only reproducible in test code, we do not create initial timelines in cloud (yet, at least), but still nice to remove the non-deterministic behavior.
refactor: use new type LayerFileName when referring to layer file names in PathBuf/RemotePath
Before this patch, we would sometimes carry around plain file names in
`Path` types and/or awkwardly "rebase" paths to have a unified
representation of the layer file name between local and remote.
This patch introduces a new type `LayerFileName` which replaces the use
of `Path` / `PathBuf` / `RemotePath` in the `storage_sync2` APIs.
Instead of holding a string, it contains the parsed representation of
the image and delta file name.
When we need the file name, e.g., to construct a local path or
remote object key, we construct the name ad-hoc.
`LayerFileName` is also serde {Dese,Se}rializable, and in an initial
version of this patch, it was supposed to be used directly inside
`IndexPart`, replacing `RemotePath`.
However,
commit 3122f3282f
Ignore backup files (ones with .n.old suffix) in download_missing
fixed handling of `*.old` backup file names in IndexPart, and we need
to carry that behavior forward.
The solution is to remove `*.old` backup files names during
deserialization. When we re-serialize the IndexPart, the `*.old` file
will be gone.
This leaks the `.old` file in the remote storage, but makes it safe
to clean it up later.
There is additional churn by a preliminary refactoring that got squashed
into this change:
split off LayerMap's needs from trait Layer into super trait
That refactoring renames `Layer` to `PersistentLayer` and splits off a subset
of the functions into a super-trait called `Layer`.
The upser trait implements just the functions needed by `LayerMap`, whereas
`PersisentLayer` adds the context of the pageserver.
The naming is imperfect as some functions that reside in `PersistentLayer`
have nothing persistence-specific to it. But it's a step in the right direction.
Changes:
* Remove `RemoteObjectId` concept from remote_storage.
Operate directly on /-separated names instead.
These names are now represented by struct `RemotePath` which was renamed from struct `RelativePath`
* Require remote storage to operate on relative paths for its contents, thus simplifying the way to derive them in pageserver and safekeeper
* Make `IndexPart` to use `String` instead of `RelativePath` for its entries, since those are just the layer names
We had a pattern like this:
match remote_storage {
GenericRemoteStorage::Local(storage) => {
let source = storage.remote_object_id(&file_path)?;
...
storage
.function(&source, ...)
.await
},
GenericRemoteStorage::S3(storage) => {
... exact same code as for the Local case ...
},
This removes the code duplication, by allowing you to call the functions
directly on GenericRemoteStorage.
Also change RemoveObjectId to be just a type alias for String. Now that
the callers of GenericRemoteStorage functions don't know whether they're
dealing with the LocalFs or S3 implementation, RemoveObjectId must be the
same type for both.
download operations of all timelines for one tenant are now grouped
together so when attach is invoked pageserver downloads all of them
and registers them in a single apply_sync_status_update call so
branches can be used safely with attach/detach
Separate task is launched for each timeline and stopped when timeline doesn't
need offloading. Decision who offloads is done through etcd leader election;
currently there is no pre condition for participating, that's a TODO.
neon_local and tests infrastructure for remote storage in safekeepers added,
along with the test itself.
ref #1009
Co-authored-by: Anton Shyrabokau <ahtoxa@Antons-MacBook-Pro.local>
{kind=link}