This PR adds posting a comment with test results. Each workflow run
updates the comment with new results.
The layout and the information that we post can be changed to our needs,
right now, it contains failed tests and test which changes status after
rerun (i.e. flaky tests)
This PR adds a plugin that automatically reruns (up to 3 times) flaky
tests. Internally, it uses data from `TEST_RESULT_CONNSTR` database and
`pytest-rerunfailures` plugin.
As the first approximation we consider the test flaky if it has failed on
the main branch in the last 10 days.
Flaky tests are fetched by `scripts/flaky_tests.py` script (it's
possible to use it in a standalone mode to learn which tests are flaky),
stored to a JSON file, and then the file is passed to the pytest plugin.
## Describe your changes
https://neondb.slack.com/archives/C039YKBRZB4/p1679413279637059
## Issue ticket number and link
## Checklist before requesting a review
- [ ] I have performed a self-review of my code.
- [ ] If it is a core feature, I have added thorough tests.
- [ ] Do we need to implement analytics? if so did you add the relevant
metrics to the dashboard?
- [ ] If this PR requires public announcement, mark it with
/release-notes label and add several sentences in this section.
Adds two new tags, `run-extra-build-macos` and `run-extra-build-stats`
to trigger corresponding build jobs on any PR.
On every build for `main` or PR with `run-extra-build-stats` tag, publish a GitHub commit status with the link to the `cargo build --all --release --timings` report.
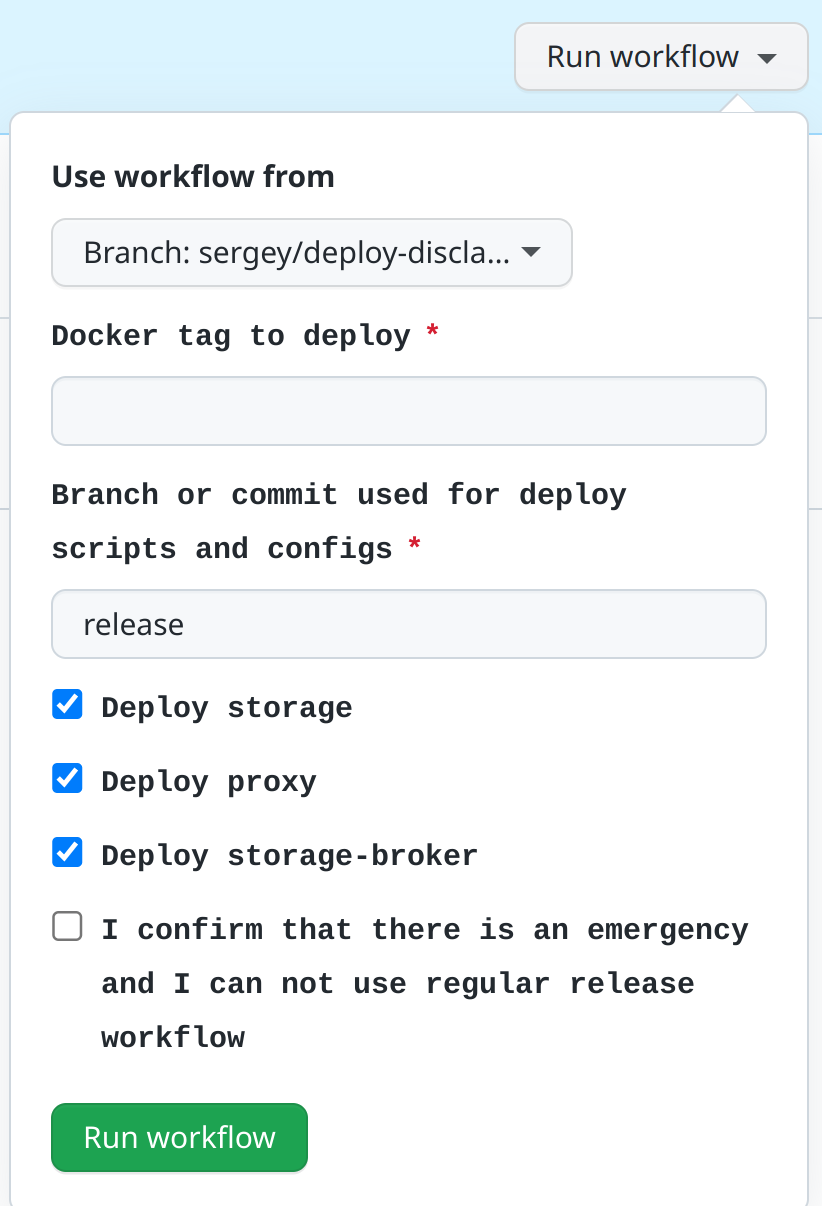
Add 'branch' input to specify commit for deploy scripts/configs. Commit
can't be passed to workflow as ref, and we need to pin configs to
specific commit for main/release deploys
Update deploy input descriptions to match GH interface
Extract deploy jobs from build_and_test.yml to deploy-dev and
deploy-prod workflows.
Add trigger to run this workflows after Neon is build and tested on main and
release branches.
This will allow us to redeploy/rollback/patch config without full
rebuild.
To fix `Error: The requested DurationSeconds exceeds the
MaxSessionDuration set for this role.`
Co-authored-by: Rory de Zoete <rdezoete@Rorys-Mac-Studio.fritz.box>
To fix errors such as:
`An error occurred (ImageAlreadyExistsException) when calling the
PutImage operation: Image with digest
'sha256:da6d8ad97d84e3aec4e6a240c3a35868b626692ee5d199cdd3fe45d29a8e54df'
and tag 'latest' already exists in the repository with name
'compute-node-v14' in registry with id '369495373322'`
Co-authored-by: Rory de Zoete <rdezoete@RorysMacStudio.fritz.box>
Co-authored-by: Rory de Zoete <rdezoete@Rorys-Mac-Studio.fritz.box>
The general idea is that the VM informant binary is added to the
vm-compute-node images only. `compute_tools` then will run whatever's at
`/bin/vm-informant`, if the path exists.
When number of github actions workers is changed, some jobs get killed.
When helm if killed during the upgrade, release stuck in pending-upgrade
state. --atomic should initiate automatic rollback in this case.
It was nice to have and useful at the time, but unfortunately the method
used to gather the profiling data doesn't play nicely with 'async'. PR
#3228 will turn 'get_page_at_lsn' function async, which will break the
profiling support. Let's remove it, and re-introduce some kind of
profiling later, using some different method, if we feel like we need it
again.
{kind=link}