This PR enforces that the tenant create / update-config APIs reject
requests with unknown fields.
This is a desirable property because some tenant config settings control
the lifetime of user data (e.g., GC horizon or PITR interval).
Suppose we inadvertently rename the `pitr_interval` field in the Rust
code.
Then, right now, a client that still uses the old name will send a
tenant config request to configure a new PITR interval.
Before this PR, we would accept such a request, ignore the old name
field, and use the pageserver.toml default value for what the new PITR
interval is.
With this PR, we will instead reject such a request.
One might argue that the client could simply check whether the config it
sent has been applied, using the `/v1/tenant/.../config` endpoint.
That is correct for tenant create and update-config.
But, attach will soon [^1] grow the ability to have attach-time config
as well.
If we ignore unknown fields and fall back to global defaults in that
case, we risk data loss.
Example:
1. Default PITR in pageservers is 7 days.
2. Create a tenant and set its PITR to 30 days.
3. For 30 days, fill the tenant continuously with data.
4. Detach the tenant.
5. Attach tenant.
Attach must use the 30-day PITR setting in this scenario.
If it were to fall back to the 7-day default value, we would lose 23
days of PITR capability for the tenant.
So, the PR that adds attach-time tenant config will build on the
(clunky) infrastructure added in this PR
[^1]: https://github.com/neondatabase/neon/pull/4255
Implementation Notes
====================
This could have been a simple `#[serde(deny_unknown_fields)]` but sadly,
that is documented- but silent-at-compile-time-incompatible with
`#[serde(flatten)]`. But we are still using this by adding on outer struct and use unit tests to ensure it is correct.
`neon_local tenant config` now uses the `.remove()` pattern + bail if
there are leftover config args. That's in line with what
`neon_local tenant create` does. We should dedupe that logic in a future
PR.
---------
Signed-off-by: Alex Chi <iskyzh@gmail.com>
Co-authored-by: Alex Chi <iskyzh@gmail.com>
We had a hot debate on whether we should try to make our code
cancellation-safe, or just accept that it's not, and make sure that
our Futures are driven to completion. The decision is that we drive
Futures to completion. This documents the decision, and summarizes the
reasoning for that.
Discussion that sparked this:
https://github.com/neondatabase/neon/pull/4198#discussion_r1190209316
This is prep for https://github.com/neondatabase/neon/pull/4255
[1/X] OpenAPI: share a single definition of TenantConfig
DRYs up the pageserver OpenAPI YAML's representation of
tenant config.
All the fields of tenant config are now located in a model schema
called TenantConfig.
The tenant create & config-change endpoints have separate schemas,
TenantCreateInfo and TenantConfigureArg, respectively.
These schemas inherit from TenantConfig, using allOf 1.
The tenant config-GET handler's response was previously named
TenantConfig.
It's now named TenantConfigResponse.
None of these changes affect how the request looks on the wire.
The generated Go code will change for Console because the OpenAPI code
generator maps `allOf` to a Go struct embedding.
Luckily, usage of tenant config in Console is still very lightweigt,
but that will change in the near future.
So, this is a good chance to set things straight.
The console changes are tracked in
https://github.com/neondatabase/cloud/pull/5046
[2/x]: extract the tenant config parts of create & config requests
[3/x]: code movement: move TenantConfigRequestConfig next to
TenantCreateRequestConfig
[4/x] type-alias TenantConfigRequestConfig = TenantCreateRequestConfig;
They are exactly the same.
[5/x] switch to qualified use for tenant create/config request api
models
[6/x] rename models::TenantConfig{RequestConfig,} and remove the alias
[7/x] OpenAPI: sync tenant create & configure body names from Rust code
[8/x]: dedupe the two TryFrom<...> for TenantConfOpt impls
The only difference is that the TenantConfigRequest impl does
```
tenant_conf.max_lsn_wal_lag = request_data.max_lsn_wal_lag;
tenant_conf.trace_read_requests = request_data.trace_read_requests;
```
and the TenantCreateRequest impl does
```
if let Some(max_lsn_wal_lag) = request_data.max_lsn_wal_lag {
tenant_conf.max_lsn_wal_lag = Some(max_lsn_wal_lag);
}
if let Some(trace_read_requests) = request_data.trace_read_requests {
tenant_conf.trace_read_requests = Some(trace_read_requests);
}
```
As far as I can tell, these are identical.
This PR is simply the patch from
https://github.com/neondatabase/neon/issues/4008 except we enabled
`force_path_style` for custom endpoints. This is because at some
version, the s3 sdk by default uses the virtual-host style access, which
is not supported by MinIO in the default configuration. By enforcing
path style access for custom endpoints, we can pass all e2e test cases.
SDK 0.55 is not the latest version and we can bump it further later when
all flaky tests in this PR are resolved.
This PR also (hopefully) fixes flaky test
`test_ondemand_download_timetravel`.
close https://github.com/neondatabase/neon/issues/4008
Signed-off-by: Alex Chi <iskyzh@gmail.com>
After tenant attach, there is a window where the child timeline is
loaded and accepts GetPage requests, but its parent is not. If a
GetPage request needs to traverse to the parent, it needs to wait for
the parent timeline to become active, or it might miss some records on
the parent timeline.
It's also possible that the parent timeline is active, but it hasn't
yet received all the WAL up to the branch point from the safekeeper.
This happens if a pageserver crashes soon after creating a timeline,
so that the WAL leading to the branch point has not yet been uploaded
to remote storage. After restart, the WAL will be re-streamed and
ingested from the safekeeper, but that takes a while. Because of that,
it's not enough to check that the parent timeline is active, we also
need to wait for the WAL to arrive on the parent timeline, just like
at the beginning of GetPage handling. We probably should change the
behavior at create_timeline so that a timeline can only be created
after all the WAL up to the branch point has been uploaded to remote
storage, but that's not currently the case and out of scope for this
PR (see github issue #4218).
@NanoBjorn encountered this while working on tenant migration. After
migrating a tenant with a parent and child branch, connecting to the
child branch failed with an error like:
```
FATAL: "base/16385" is not a valid data directory
DETAIL: File "base/16385/PG_VERSION" is missing.
```
This commit adds two tests that reproduce the bug, with slightly
different symptoms.
This PR adds tests runs on Postgres 15 and created unified Allure report
with results for all tests.
- Split `.github/actions/allure-report` into
`.github/actions/allure-report-store` and
`.github/actions/allure-report-generate`
- Add debug or release pytest parameter for all tests (depending on
`BUILD_TYPE` env variable)
- Add Postgres version as a pytest parameter for all tests (depending on
`DEFAULT_PG_VERSION` env variable)
- Fix `test_wal_restore` and `restore_from_wal.sh` to support path with
`[`/`]` in it (fixed by applying spellcheck to the script and fixing all
warnings), `restore_from_wal_archive.sh` is deleted as unused.
- All known failures on Postgres 15 marked with xfail
I tried to use failpoint_sleep_millis_async(...) in a source file that
didn't do `use std::time::Duration`, and got a compiler error:
```
error[E0433]: failed to resolve: use of undeclared type `Duration`
--> pageserver/src/walingest.rs:316:17
|
316 | utils::failpoint_sleep_millis_async!("wal-ingest-logical-message-sleep");
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ not found in this scope
|
= note: this error originates in the macro `utils::failpoint_sleep_millis_async` (in Nightly builds, run with -Z macro-backtrace for more info)
help: consider importing one of these items
|
24 | use chrono::Duration;
|
24 | use core::time::Duration;
|
24 | use humantime::Duration;
|
24 | use serde_with::__private__::Duration;
|
and 2 other candidates
```
Control Plane currently [^1] polls for `has_in_progress_downloads ==
false` after /attach to determine that an attach operation succeeded.
As pointed out in the OpenAPI spec as of neon#4151, polling for
`has_in_progress_downloads` is incorrect.
This patch changes the situation by
- removing `has_in_progress_downloads`
- adding a new field `attachment_status.`
- changing instructions for `/attach` to poll for `attachment_status ==
attached`.
This makes the instructions in `/attach` actionable for Control Plane.
NB that we don't expose the TenantState in the OpenAPI docs, even though
we expose it in the endpoint. That is with good reason because we don't
want to commit to a fixed set of tenant states forever. Hence, the
separate `attachment_status` field that exposes the bare minimum
required to make /attach + subsequent polling 100% safe wrt split brain.
It would have been nice to report failures explicitly, but the problem
is that we lose that state when we restart. So, we return `attached`
upon attach failure. The tenant is Broken in that case, causing Control
Plane's subsequent health check will fail. Control Plane can roll back
the relocation operation then.
NB: the reliance on the subsequent health check is no change to what we
had before this patch!
NB: we can always add additional TenantAttachmentStatus'es in the future
to communicate failure.
This PR also moves the attach-marker file's creation to the API
handler's synchronous part. That was done to avoid the need to
distinguish
* `Attaching but marker not yet written => AttachmentStatus::Maybe` from
* `Attaching, marker written, but attach failed for other reason =>
AttachmentStatus::Attached`
Coincidentally, this also adds more transactionality to the /attach API
because we only return 202 once we've written the marker file. But, in
the end, it doesn't affect how the control plane interacts with us or
how it needs to do retries. So, we don't mention any of this in the API
docs.
[^1]: The one-click tenant relocation PR cloud#4740, currently WIP, is
the first real user.
Before this patch, the following sequence would lead to the resurrection of a deleted timeline:
- create timeline
- wait for its index part to reach s3
- delete timeline
- wait an arbitrary amount of time, including 0 seconds
- detach tenant
- attach tenant
- the timeline is there and Active again
This happens because we only kept track of the deletion in the tenant dir (by deleting the timeline dir) but not in S3.
The solution is to turn the deleted timeline's IndexPart into a tombstone.
The deletion status of the timeline is expressed in the `deleted_at: Option<NativeDateTime>` field of IndexPart.
It's `None` while the timeline is alive and `Some(deletion time stamp)` if it is deleted.
We change the timeline deletion handler to upload this tombstoned IndexPart.
The handler does not return success if the upload fails.
Coincidentally, this fixes the long-stanging TODO about the `std::fs::remove_dir_all` being not atomic.
It need not be atomic anymore because we set the `deleted_at=Some()` before starting the `remove_dir_all`.
The tombstone is in the IndexPart only, not in the `metadata`.
So, we only have the tombstone and the `remove_dir_all` benefits mentioned above if remote storage is configured.
This was a conscious trade-off because there's no good format evolution story for the current metadata file format.
The introduction of this additional step into `delete_timeline` was painful because delete_timeline needs to be
1. cancel-safe
2. idempotent
3. safe to call concurrently
These are mostly self-inflicted limitations that can be avoided by using request-coalescing.
PR https://github.com/neondatabase/neon/pull/4159 will do that.
fixes https://github.com/neondatabase/neon/issues/3560
refs https://github.com/neondatabase/neon/issues/3889 (part of tenant relocation)
Co-authored-by: Joonas Koivunen <joonas@neon.tech>
Co-authored-by: Christian Schwarz <christian@neon.tech>
If compute_ctl is launched without a spec file, it fetches it from the
control plane with an HTTP request. We cannot get the startup tracing
context from the compute spec in that case, because we don't have it
available on start. We could still read the tracing context from the
compute spec after we have fetched it, but that would leave the fetch
itself out of the context. Pass the tracing context in environment
variables instead.
Our scale-to-zero logic was optimized for short auto-suspend intervals,
e.g. minutes or hours. In this case, if compute was restarted by k8s due
to some reason (OOM, k8s node went down, pod relocation, etc.),
`last_active` got bumped, we start counting auto-suspend timeout again.
It's not a big deal, i.e. we suspend completely idle compute not after 5
minutes, but after 10 minutes or so.
Yet, some clients may want days or even weeks. And chance that compute
could be restarted during this interval is pretty high, but in this case
we could be not able to suspend some computes for weeks.
After this commit, we won't initialize `last_active` on start, so
`/status` could return an unset attribute. This means that there was no
user activity since start. Control-plane should deal with it by taking
`max()` out of all available activity timestamps: `started_at`,
`last_active`, etc.
compute_ctl part of neondatabase/cloud#4853
This patch adds a regression test for the threshold-based layer
eviction.
The test asserts the basic invariant that, if left alone, the residence
statuses will stabilize, with some layers resident and some layers
evicted.
Thereby, we cover both the aspect of last-access-time-threshold-based
eviction, and the "imitate access" hacks that we put in recently.
The aggressive `period` and `threshold` values revealed a subtle bug
which is also fixed in this patch.
The symptom was that, without the Rust changes of this patch, there
would be occasional test failures due to `WARN... unexpectedly
downloading` log messages.
These log messages were caused by the "imitate access" calls of the
eviction task.
But, the whole point of the "imitate access" hack was to prevent
eviction of the layers that we access there.
After some digging, I found the root cause, which is the following race
condition:
1. Compact: Write out an L1 layer from several L0 layers. This records
residence event `LayerCreate` with the current timestamp.
2. Eviction: imitate access logical size calculation. This accesses the
L0 layers because the L1 layer is not yet in the layer map.
3. Compact: Grab layer map lock, add the new L1 to layer map and remove
the L0s, release layer map lock.
4. Eviction: observes the new L1 layer whose only activity timestamp is
the `LayerCreate` event.
The L1 layer had no chance of being accessed until after (3).
So, if enough time passes between (1) and (3), then (4) will observe a
layer with `now-last_activity > threshold` and evict it
The fix is to require the first `record_residence_event` to happen while
we already hold the layer map lock.
The API requires a ref to a `BatchedUpdates` as a witness that we are
inside a layer map lock.
That is not fool-proof, e.g., new call sites for `insert_historic` could
just completely forget to record the residence event.
It would be nice to prevent this at the type level.
In the meantime, we have a rate-limited log messages to warn us, if such
an implementation error sneaks in in the future.
fixes https://github.com/neondatabase/neon/issues/3593
fixes https://github.com/neondatabase/neon/issues/3942
---------
Co-authored-by: Joonas Koivunen <joonas@neon.tech>
The field means the same thing as the `wal_end` field in the XLogData
struct. And in the postgres-protocol crate's corresponding
PrimaryKeepAlive struct, it's also called `wal_end`. Let's be
consistent.
As noted by Arthur at
https://github.com/neondatabase/neon/pull/4144#pullrequestreview-1411031881
If the other end of a TCP connection closes its read end of the socket,
you get an EPIPE when you try to send. I saw that happen in the CI once:
https://neon-github-public-dev.s3.amazonaws.com/reports/pr-4136/release/4869464644/index.html#suites/c19bc2126511ef8cb145cca25c438215/7ec87b016c0b4b50/
```
2023-05-03T07:53:22.394152Z ERROR Task 'serving compute connection task' tenant_id: Some(c204447079e02e7ba8f593cb8bc57e76), timeline_id: Some(b666f26600e6deaa9f43e1aeee5bacb7) exited with error: Postgres connection error
Caused by:
Broken pipe (os error 32)
Stack backtrace:
0: pageserver::page_service::page_service_conn_main::{{closure}}
at /__w/neon/neon/pageserver/src/page_service.rs:282:17
<core::panic::unwind_safe::AssertUnwindSafe<F> as core::future::future::Future>::poll
at /rustc/9eb3afe9ebe9c7d2b84b71002d44f4a0edac95e0/library/core/src/panic/unwind_safe.rs:296:9
<futures_util::future::future::catch_unwind::CatchUnwind<Fut> as core::future::future::Future>::poll::{{closure}}
at /__w/neon/neon/.cargo/registry/src/github.com-1ecc6299db9ec823/futures-util-0.3.28/src/future/future/catch_unwind.rs:36:42
<core::panic::unwind_safe::AssertUnwindSafe<F> as core::ops::function::FnOnce<()>>::call_once
at /rustc/9eb3afe9ebe9c7d2b84b71002d44f4a0edac95e0/library/core/src/panic/unwind_safe.rs:271:9
...
```
In the passing, add a comment to explain what the "expected" in the
`is_expected_io_error` function means.
wal_craft had accumulated some trouble by using `use anyhow::*;`. Fixes
that, removes redundant conversions (never need to convert a Path to
OsStr), especially at the `Process` args.
Originally in #4100 but we merged a later PR instead for the fixes. I
dropped the `postmaster.pid` polling in favor of just having a longer
connect timeout.
noticed while describing `RequestSpan`, this fix will omit the otherwise
logged message about request being cancelled when panicking in the
request handler. this was missed on #4064.
Refactors walsenders out of timeline.rs to makes it less convoluted into
separate WalSenders with its own lock, but otherwise having the same structure.
Tracking of in-memory remote_consistent_lsn is also moved there as it is mainly
received from pageserver.
State of walsender (feedback) is also restructured to be cleaner; now it is
either PageserverFeedback or StandbyFeedback(StandbyReply, HotStandbyFeedback),
but not both.
Notes:
- This still needs UI support from the Console
- I've not tuned any GUCs for PostgreSQL to make this work better
- Safekeeper has gotten a tweak in which WAL is sent and how: It now
sends zero-ed WAL data from the start of the timeline's first segment up to
the first byte of the timeline to be compatible with normal PostgreSQL
WAL streaming.
- This includes the commits of #3714
Fixes one part of https://github.com/neondatabase/neon/issues/769
Co-authored-by: Anastasia Lubennikova <anastasia@neon.tech>
- Remove repeated tenant & timeline from span
- Demote logging of the path to debug level
- Log completion at info level, in the same function where we log errors
- distinguish between layer file download success & on-demand download
succeeding as a whole in the log message wording
- Assert that the span contains a tenant id and a timeline id
fixes https://github.com/neondatabase/neon/issues/3945
Before:
```
INFO compaction_loop{tenant_id=$TENANT_ID}:compact_timeline{timeline=$TIMELINE_ID}:download_remote_layer{tenant_id=$TENANT_ID timeline_id=$TIMELINE_ID layer=000000000000000000000000000000000000-FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF__00000000020C8A71-00000000020CAF91}: download complete: /storage/pageserver/data/tenants/$TENANT_ID/timelines/$TIMELINE_ID/000000000000000000000000000000000000-FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF__00000000020C8A71-00000000020CAF91
INFO compaction_loop{tenant_id=$TENANT_ID}:compact_timeline{timeline=$TIMELINE_ID}:download_remote_layer{tenant_id=$TENANT_ID timeline_id=$TIMELINE_ID layer=000000000000000000000000000000000000-FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF__00000000020C8A71-00000000020CAF91}: Rebuilt layer map. Did 9 insertions to process a batch of 1 updates.
```
After:
```
INFO compaction_loop{tenant_id=$TENANT_ID}:compact_timeline{timeline=$TIMELINE_ID}:download_remote_layer{layer=000000000000000000000000000000000000-FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF__00000000020C8A71-00000000020CAF91}: layer file download finished
INFO compaction_loop{tenant_id=$TENANT_ID}:compact_timeline{timeline=$TIMELINE_ID}:download_remote_layer{layer=000000000000000000000000000000000000-FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF__00000000020C8A71-00000000020CAF91}: Rebuilt layer map. Did 9 insertions to process a batch of 1 updates.
INFO compaction_loop{tenant_id=$TENANT_ID}:compact_timeline{timeline=$TIMELINE_ID}:download_remote_layer{layer=000000000000000000000000000000000000-FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF__00000000020C8A71-00000000020CAF91}: on-demand download successful
```
Add a simple disarmable dropguard to log if request is cancelled before
it is completed. We currently don't have this, and it makes for
difficult to know when the request was dropped.
This patch extends the libmetrics logging setup functionality with a
`tracing` layer that increments a Prometheus counter each time we log a
log message. We have the counter per tracing event level. This allows
for monitoring WARN and ERR log volume without parsing the log. Also, it
would allow cross-checking whether logs got dropped on the way into
Loki.
It would be nicer if we could hook deeper into the tracing logging
layer, to avoid evaluating the filter twice.
But I don't know how to do it.
Do several attempts to get spec from the control-plane and retry network
errors and all reasonable HTTP response codes. Do not hang waiting for
spec without confirmation from the control-plane that compute is known
and is in the `Empty` state.
Adjust the way we track `total_startup_ms` metric, it should be
calculated since the moment we received spec, not from the moment
`compute_ctl` started. Also introduce a new `wait_for_spec_ms` metric
to track the time spent sleeping and waiting for spec to be delivered
from control-plane.
Part of neondatabase/cloud#3533
See https://github.com/neondatabase/neon/pull/3991
Brings the changes back with the right way to use new `toml_edit` to
deserialize values and a unit test for this.
All non-trivial updates extracted into separate commits, also `carho hakari` data and its manifest format were updated.
3 sets of crates remain unupdated:
* `base64` — touches proxy in a lot of places and changed its api (by 0.21 version) quite strongly since our version (0.13).
* `opentelemetry` and `opentelemetry-*` crates
```
error[E0308]: mismatched types
--> libs/tracing-utils/src/http.rs:65:21
|
65 | span.set_parent(parent_ctx);
| ---------- ^^^^^^^^^^ expected struct `opentelemetry_api::context::Context`, found struct `opentelemetry::Context`
| |
| arguments to this method are incorrect
|
= note: struct `opentelemetry::Context` and struct `opentelemetry_api::context::Context` have similar names, but are actually distinct types
note: struct `opentelemetry::Context` is defined in crate `opentelemetry_api`
--> /Users/someonetoignore/.cargo/registry/src/github.com-1ecc6299db9ec823/opentelemetry_api-0.19.0/src/context.rs:77:1
|
77 | pub struct Context {
| ^^^^^^^^^^^^^^^^^^
note: struct `opentelemetry_api::context::Context` is defined in crate `opentelemetry_api`
--> /Users/someonetoignore/.cargo/registry/src/github.com-1ecc6299db9ec823/opentelemetry_api-0.18.0/src/context.rs:77:1
|
77 | pub struct Context {
| ^^^^^^^^^^^^^^^^^^
= note: perhaps two different versions of crate `opentelemetry_api` are being used?
note: associated function defined here
--> /Users/someonetoignore/.cargo/registry/src/github.com-1ecc6299db9ec823/tracing-opentelemetry-0.18.0/src/span_ext.rs:43:8
|
43 | fn set_parent(&self, cx: Context);
| ^^^^^^^^^^
For more information about this error, try `rustc --explain E0308`.
error: could not compile `tracing-utils` due to previous error
warning: build failed, waiting for other jobs to finish...
error: could not compile `tracing-utils` due to previous error
```
`tracing-opentelemetry` of version `0.19` is not yet released, that is supposed to have the update we need.
* similarly, `rustls`, `tokio-rustls`, `rustls-*` and `tls-listener` crates have similar issue:
```
error[E0308]: mismatched types
--> libs/postgres_backend/tests/simple_select.rs:112:78
|
112 | let mut make_tls_connect = tokio_postgres_rustls::MakeRustlsConnect::new(client_cfg);
| --------------------------------------------- ^^^^^^^^^^ expected struct `rustls::client::client_conn::ClientConfig`, found struct `ClientConfig`
| |
| arguments to this function are incorrect
|
= note: struct `ClientConfig` and struct `rustls::client::client_conn::ClientConfig` have similar names, but are actually distinct types
note: struct `ClientConfig` is defined in crate `rustls`
--> /Users/someonetoignore/.cargo/registry/src/github.com-1ecc6299db9ec823/rustls-0.21.0/src/client/client_conn.rs:125:1
|
125 | pub struct ClientConfig {
| ^^^^^^^^^^^^^^^^^^^^^^^
note: struct `rustls::client::client_conn::ClientConfig` is defined in crate `rustls`
--> /Users/someonetoignore/.cargo/registry/src/github.com-1ecc6299db9ec823/rustls-0.20.8/src/client/client_conn.rs:91:1
|
91 | pub struct ClientConfig {
| ^^^^^^^^^^^^^^^^^^^^^^^
= note: perhaps two different versions of crate `rustls` are being used?
note: associated function defined here
--> /Users/someonetoignore/.cargo/registry/src/github.com-1ecc6299db9ec823/tokio-postgres-rustls-0.9.0/src/lib.rs:23:12
|
23 | pub fn new(config: ClientConfig) -> Self {
| ^^^
For more information about this error, try `rustc --explain E0308`.
error: could not compile `postgres_backend` due to previous error
warning: build failed, waiting for other jobs to finish...
```
* aws crates: I could not make new API to work with bucket endpoint overload, and console e2e tests failed.
Other our tests passed, further investigation is worth to be done in https://github.com/neondatabase/neon/issues/4008
Before this patch, if a tenant would override its eviction_policy
setting to use a lower LayerAccessThreshold::threshold than the
`evictions_low_residence_duration_metric_threshold`, the evictions done
for that tenant would count towards the
`evictions_with_low_residence_duration` metric.
That metric is used to identify pre-mature evictions, commonly triggered
by disk-usage-based eviction under disk pressure.
We don't want that to happen for the legitimate evictions of the tenant
that overrides its eviction_policy.
So, this patch
- moves the setting into TenantConf
- adds test coverage
- updates the staging & prod yamls
Forward Compatibility:
Software before this patch will ignore the new tenant conf field and use
the global one instead.
So we can roll back safely.
Backward Compatibility:
Parsing old configs with software as of this patch will fail in
`PageServerConf::parse_and_validate` with error
`unrecognized pageserver option 'evictions_low_residence_duration_metric_threshold'`
if the option is still present in the global section.
We deal with this by updating the configs in Ansible.
fixes https://github.com/neondatabase/neon/issues/3940
With this commit one can request compute reconfiguration
from the running `compute_ctl` with compute in `Running` state
by sending a new spec:
```shell
curl -d "{\"spec\": $(cat ./compute-spec-new.json)}" http://localhost:3080/configure
```
Internally, we start a separate configurator thread that is waiting on
`Condvar` for `ConfigurationPending` compute state in a loop. Then it does
reconfiguration, sets compute back to `Running` state and notifies other
waiters.
It will need some follow-ups, e.g. for retry logic for control-plane
requests, but should be useful for testing in the current state. This
shouldn't affect any existing environment, since computes are configured
in a different way there.
Resolvesneondatabase/cloud#4433
Reason and backtrace are added to the Broken state. Backtrace is automatically collected when tenant entered the broken state. The format for API, CLI and metrics is changed and unified to return tenant state name in camel case. Previously snake case was used for metrics and camel case was used for everything else. Now tenant state field in TenantInfo swagger spec is changed to contain state name in "slug" field and other fields (currently only reason and backtrace for Broken variant in "data" field). To allow for this breaking change state was removed from TenantInfo swagger spec because it was not used anywhere.
Please note that the tenant's broken reason is not persisted on disk so the reason is lost when pageserver is restarted.
Requires changes to grafana dashboard that monitors tenant states.
Closes#3001
---------
Co-authored-by: theirix <theirix@gmail.com>
All non-trivial updates extracted into separate commits, also `carho
hakari` data and its manifest format were updated.
3 sets of crates remain unupdated:
* `base64` — touches proxy in a lot of places and changed its api (by
0.21 version) quite strongly since our version (0.13).
* `opentelemetry` and `opentelemetry-*` crates
```
error[E0308]: mismatched types
--> libs/tracing-utils/src/http.rs:65:21
|
65 | span.set_parent(parent_ctx);
| ---------- ^^^^^^^^^^ expected struct `opentelemetry_api::context::Context`, found struct `opentelemetry::Context`
| |
| arguments to this method are incorrect
|
= note: struct `opentelemetry::Context` and struct `opentelemetry_api::context::Context` have similar names, but are actually distinct types
note: struct `opentelemetry::Context` is defined in crate `opentelemetry_api`
--> /Users/someonetoignore/.cargo/registry/src/github.com-1ecc6299db9ec823/opentelemetry_api-0.19.0/src/context.rs:77:1
|
77 | pub struct Context {
| ^^^^^^^^^^^^^^^^^^
note: struct `opentelemetry_api::context::Context` is defined in crate `opentelemetry_api`
--> /Users/someonetoignore/.cargo/registry/src/github.com-1ecc6299db9ec823/opentelemetry_api-0.18.0/src/context.rs:77:1
|
77 | pub struct Context {
| ^^^^^^^^^^^^^^^^^^
= note: perhaps two different versions of crate `opentelemetry_api` are being used?
note: associated function defined here
--> /Users/someonetoignore/.cargo/registry/src/github.com-1ecc6299db9ec823/tracing-opentelemetry-0.18.0/src/span_ext.rs:43:8
|
43 | fn set_parent(&self, cx: Context);
| ^^^^^^^^^^
For more information about this error, try `rustc --explain E0308`.
error: could not compile `tracing-utils` due to previous error
warning: build failed, waiting for other jobs to finish...
error: could not compile `tracing-utils` due to previous error
```
`tracing-opentelemetry` of version `0.19` is not yet released, that is
supposed to have the update we need.
* similarly, `rustls`, `tokio-rustls`, `rustls-*` and `tls-listener`
crates have similar issue:
```
error[E0308]: mismatched types
--> libs/postgres_backend/tests/simple_select.rs:112:78
|
112 | let mut make_tls_connect = tokio_postgres_rustls::MakeRustlsConnect::new(client_cfg);
| --------------------------------------------- ^^^^^^^^^^ expected struct `rustls::client::client_conn::ClientConfig`, found struct `ClientConfig`
| |
| arguments to this function are incorrect
|
= note: struct `ClientConfig` and struct `rustls::client::client_conn::ClientConfig` have similar names, but are actually distinct types
note: struct `ClientConfig` is defined in crate `rustls`
--> /Users/someonetoignore/.cargo/registry/src/github.com-1ecc6299db9ec823/rustls-0.21.0/src/client/client_conn.rs:125:1
|
125 | pub struct ClientConfig {
| ^^^^^^^^^^^^^^^^^^^^^^^
note: struct `rustls::client::client_conn::ClientConfig` is defined in crate `rustls`
--> /Users/someonetoignore/.cargo/registry/src/github.com-1ecc6299db9ec823/rustls-0.20.8/src/client/client_conn.rs:91:1
|
91 | pub struct ClientConfig {
| ^^^^^^^^^^^^^^^^^^^^^^^
= note: perhaps two different versions of crate `rustls` are being used?
note: associated function defined here
--> /Users/someonetoignore/.cargo/registry/src/github.com-1ecc6299db9ec823/tokio-postgres-rustls-0.9.0/src/lib.rs:23:12
|
23 | pub fn new(config: ClientConfig) -> Self {
| ^^^
For more information about this error, try `rustc --explain E0308`.
error: could not compile `postgres_backend` due to previous error
warning: build failed, waiting for other jobs to finish...
```
* aws crates: I could not make new API to work with bucket endpoint
overload, and console e2e tests failed.
Other our tests passed, further investigation is worth to be done in
https://github.com/neondatabase/neon/issues/4008
Sometimes, it contained real values, sometimes just defaults if the
spec was not received yet. Make the state more clear by making it an
Option instead.
One consequence is that if some of the required settings like
neon.tenant_id are missing from the spec file sent to the /configure
endpoint, it is spotted earlier and you get an immediate HTTP error
response. Not that it matters very much, but it's nicer nevertheless.
TCP_KEEPALIVE is not enabled by default, so this prevents hanged up connections
in case of abrupt client termination. Add 'closed' flag to PostgresBackendReader
and pass it during handles join to prevent attempts to read from socket if we
errored out previously -- now with timeouts this is a common situation.
It looks like
2023-04-10T18:08:37.493448Z INFO {cid=68}:WAL
receiver{ttid=59f91ad4e821ab374f9ccdf918da3a85/16438f99d61572c72f0c7b0ed772785d}:
terminated: timed out
Presumably fixes https://github.com/neondatabase/neon/issues/3971
This is in preparation of using compute_ctl to launch postgres nodes
in the neon_local control plane. And seems like a good idea to
separate the public interfaces anyway.
One non-mechanical change here is that the 'metrics' field is moved
under the Mutex, instead of using atomics. We were not using atomics
for performance but for convenience here, and it seems more clear to
not use atomics in the model for the HTTP response type.
Replaces `Box<(dyn io::AsyncRead + Unpin + Send + Sync + 'static)>` with
`impl io::AsyncRead + Unpin + Send + Sync + 'static` usages in the
`RemoteStorage` interface, to make it closer to
[`#![feature(async_fn_in_trait)]`](https://blog.rust-lang.org/inside-rust/2022/11/17/async-fn-in-trait-nightly.html)
For `GenericRemoteStorage`, replaces `type Target = dyn RemoteStorage`
with another impl with `RemoteStorage` methods inside it.
We can reuse the trait, that would require importing the trait in every
file where it's used and makes us farther from the unstable feature.
After this PR, I've manged to create a patch with the changes:
https://github.com/neondatabase/neon/compare/kb/less-dyn-storage...kb/nightly-async-trait?expand=1
Current rust implementation does not like recursive async trait calls,
so `UnreliableWrapper` was removed: it contained a
`GenericRemoteStorage` that implemented the `RemoteStorage` trait, and
itself implemented the trait, which nightly rustc did not like and
proposed to box the future.
Similarly, `GenericRemoteStorage` cannot implement `RemoteStorage` for
nightly rustc to work, since calls various remote storages' methods from
inside.
I've compiled current `main` and the nightly branch both with `time env
RUSTC_WRAPPER="" cargo +nightly build --all --timings` command, and got
```
Finished dev [optimized + debuginfo] target(s) in 2m 04s
env RUSTC_WRAPPER="" cargo +nightly build --all --timings 1283.19s user 50.40s system 1074% cpu 2:04.15 total
for the new feature tried and
Finished dev [optimized + debuginfo] target(s) in 2m 40s
env RUSTC_WRAPPER="" cargo +nightly build --all --timings 1288.59s user 52.06s system 834% cpu 2:40.71 total
for the old async_trait approach.
```
On my machine, the `remote_storage` lib compilation takes ~10 less time
with the nightly feature (left) than the regular main (right).
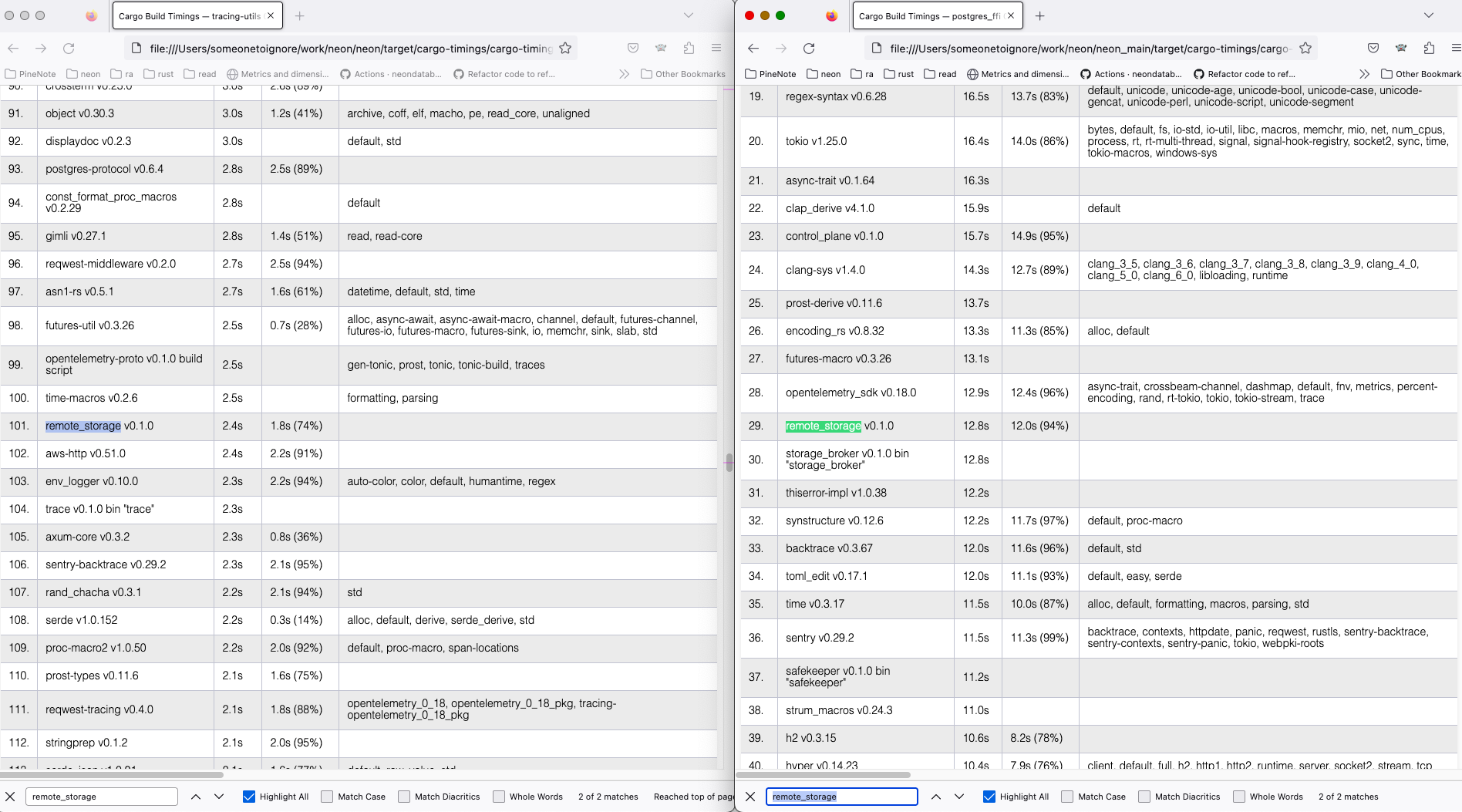
Full cargo reports are available at
[timings.zip](https://github.com/neondatabase/neon/files/11179369/timings.zip)
in real env testing we noted that the disk-usage based eviction sails 1
percentage point above the configured value, which might be a source of
confusion, so it might be better to get rid of that confusion now.
confusion: "I configured 85% but pageserver sails at 86%".
Co-authored-by: Christian Schwarz <christian@neon.tech>
In S3, pageserver only lists tenants (prefixes) on S3, no other keys.
Remove the list operation from the API, since S3 impl does not seem to
work normally and not used anyway,
This is the the feedback originating from pageserver, so change previous
confusing names to
s/ReplicationFeedback/PageserverFeedback
s/ps_writelsn/last_receive_lsn
s/ps_flushlsn/disk_consistent_lsn
s/ps_apply_lsn/remote_consistent_lsn
I haven't changed on the wire format to keep compatibility. However,
understanding of new field names is added to compute, so once all computes
receive this patch we can change the wire names as well. Safekeepers/pageservers
are deployed roughly at the same time and it is ok to live without feedbacks
during the short period, so this is not a problem there.
This patch adds a pageserver-global background loop that evicts layers
in response to a shortage of available bytes in the $repo/tenants
directory's filesystem.
The loop runs periodically at a configurable `period`.
Each loop iteration uses `statvfs` to determine filesystem-level space
usage. It compares the returned usage data against two different types
of thresholds. The iteration tries to evict layers until app-internal
accounting says we should be below the thresholds. We cross-check this
internal accounting with the real world by making another `statvfs` at
the end of the iteration. We're good if that second statvfs shows that
we're _actually_ below the configured thresholds. If we're still above
one or more thresholds, we emit a warning log message, leaving it to the
operator to investigate further.
There are two thresholds:
- `max_usage_pct` is the relative available space, expressed in percent
of the total filesystem space. If the actual usage is higher, the
threshold is exceeded.
- `min_avail_bytes` is the absolute available space in bytes. If the
actual usage is lower, the threshold is exceeded.
The iteration evicts layers in LRU fashion with a reservation of up to
`tenant_min_resident_size` bytes of the most recent layers per tenant.
The layers not part of the per-tenant reservation are evicted
least-recently-used first until we're below all thresholds. The
`tenant_min_resident_size` can be overridden per tenant as
`min_resident_size_override` (bytes).
In addition to the loop, there is also an HTTP endpoint to perform one
loop iteration synchronous to the request. The endpoint takes an
absolute number of bytes that the iteration needs to evict before
pressure is relieved. The tests use this endpoint, which is a great
simplification over setting up loopback-mounts in the tests, which would
be required to test the statvfs part of the implementation. We will rely
on manual testing in staging to test the statvfs parts.
The HTTP endpoint is also handy in emergencies where an operator wants
the pageserver to evict a given amount of space _now. Hence, it's
arguments documented in openapi_spec.yml. The response type isn't
documented though because we don't consider it stable. The endpoint
should _not_ be used by Console but it could be used by on-call.
Co-authored-by: Joonas Koivunen <joonas@neon.tech>
Co-authored-by: Dmitry Rodionov <dmitry@neon.tech>
Co-authored-by: Heikki Linnakangas <heikki@neon.tech>
neon_local sends SIGQUIT, which otherwise dumps core by default. Also, remove
obsolete install_shutdown_handlers; in all binaries it was overridden by
ShutdownSignals::handle later.
ref https://github.com/neondatabase/neon/issues/3847
The PR enforces current newest `index_part.json` format in the type
system (version `1`), not allowing any previous forms of it, that were
used in the past.
Similarly, the code to mitigate the
https://github.com/neondatabase/neon/issues/3024 issue is now also
removed.
Current code does not produce old formats and extra files in the
index_part.json, in the future we will be able to use
https://github.com/neondatabase/aversion or other approach to make
version transitions more explicit.
See https://neondb.slack.com/archives/C033RQ5SPDH/p1679134185248119 for
the justification on the breaking changes.
{kind=link}