If the other end of a TCP connection closes its read end of the socket,
you get an EPIPE when you try to send. I saw that happen in the CI once:
https://neon-github-public-dev.s3.amazonaws.com/reports/pr-4136/release/4869464644/index.html#suites/c19bc2126511ef8cb145cca25c438215/7ec87b016c0b4b50/
```
2023-05-03T07:53:22.394152Z ERROR Task 'serving compute connection task' tenant_id: Some(c204447079e02e7ba8f593cb8bc57e76), timeline_id: Some(b666f26600e6deaa9f43e1aeee5bacb7) exited with error: Postgres connection error
Caused by:
Broken pipe (os error 32)
Stack backtrace:
0: pageserver::page_service::page_service_conn_main::{{closure}}
at /__w/neon/neon/pageserver/src/page_service.rs:282:17
<core::panic::unwind_safe::AssertUnwindSafe<F> as core::future::future::Future>::poll
at /rustc/9eb3afe9ebe9c7d2b84b71002d44f4a0edac95e0/library/core/src/panic/unwind_safe.rs:296:9
<futures_util::future::future::catch_unwind::CatchUnwind<Fut> as core::future::future::Future>::poll::{{closure}}
at /__w/neon/neon/.cargo/registry/src/github.com-1ecc6299db9ec823/futures-util-0.3.28/src/future/future/catch_unwind.rs:36:42
<core::panic::unwind_safe::AssertUnwindSafe<F> as core::ops::function::FnOnce<()>>::call_once
at /rustc/9eb3afe9ebe9c7d2b84b71002d44f4a0edac95e0/library/core/src/panic/unwind_safe.rs:271:9
...
```
In the passing, add a comment to explain what the "expected" in the
`is_expected_io_error` function means.
wal_craft had accumulated some trouble by using `use anyhow::*;`. Fixes
that, removes redundant conversions (never need to convert a Path to
OsStr), especially at the `Process` args.
Originally in #4100 but we merged a later PR instead for the fixes. I
dropped the `postmaster.pid` polling in favor of just having a longer
connect timeout.
noticed while describing `RequestSpan`, this fix will omit the otherwise
logged message about request being cancelled when panicking in the
request handler. this was missed on #4064.
Refactors walsenders out of timeline.rs to makes it less convoluted into
separate WalSenders with its own lock, but otherwise having the same structure.
Tracking of in-memory remote_consistent_lsn is also moved there as it is mainly
received from pageserver.
State of walsender (feedback) is also restructured to be cleaner; now it is
either PageserverFeedback or StandbyFeedback(StandbyReply, HotStandbyFeedback),
but not both.
Notes:
- This still needs UI support from the Console
- I've not tuned any GUCs for PostgreSQL to make this work better
- Safekeeper has gotten a tweak in which WAL is sent and how: It now
sends zero-ed WAL data from the start of the timeline's first segment up to
the first byte of the timeline to be compatible with normal PostgreSQL
WAL streaming.
- This includes the commits of #3714
Fixes one part of https://github.com/neondatabase/neon/issues/769
Co-authored-by: Anastasia Lubennikova <anastasia@neon.tech>
- Remove repeated tenant & timeline from span
- Demote logging of the path to debug level
- Log completion at info level, in the same function where we log errors
- distinguish between layer file download success & on-demand download
succeeding as a whole in the log message wording
- Assert that the span contains a tenant id and a timeline id
fixes https://github.com/neondatabase/neon/issues/3945
Before:
```
INFO compaction_loop{tenant_id=$TENANT_ID}:compact_timeline{timeline=$TIMELINE_ID}:download_remote_layer{tenant_id=$TENANT_ID timeline_id=$TIMELINE_ID layer=000000000000000000000000000000000000-FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF__00000000020C8A71-00000000020CAF91}: download complete: /storage/pageserver/data/tenants/$TENANT_ID/timelines/$TIMELINE_ID/000000000000000000000000000000000000-FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF__00000000020C8A71-00000000020CAF91
INFO compaction_loop{tenant_id=$TENANT_ID}:compact_timeline{timeline=$TIMELINE_ID}:download_remote_layer{tenant_id=$TENANT_ID timeline_id=$TIMELINE_ID layer=000000000000000000000000000000000000-FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF__00000000020C8A71-00000000020CAF91}: Rebuilt layer map. Did 9 insertions to process a batch of 1 updates.
```
After:
```
INFO compaction_loop{tenant_id=$TENANT_ID}:compact_timeline{timeline=$TIMELINE_ID}:download_remote_layer{layer=000000000000000000000000000000000000-FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF__00000000020C8A71-00000000020CAF91}: layer file download finished
INFO compaction_loop{tenant_id=$TENANT_ID}:compact_timeline{timeline=$TIMELINE_ID}:download_remote_layer{layer=000000000000000000000000000000000000-FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF__00000000020C8A71-00000000020CAF91}: Rebuilt layer map. Did 9 insertions to process a batch of 1 updates.
INFO compaction_loop{tenant_id=$TENANT_ID}:compact_timeline{timeline=$TIMELINE_ID}:download_remote_layer{layer=000000000000000000000000000000000000-FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF__00000000020C8A71-00000000020CAF91}: on-demand download successful
```
Add a simple disarmable dropguard to log if request is cancelled before
it is completed. We currently don't have this, and it makes for
difficult to know when the request was dropped.
This patch extends the libmetrics logging setup functionality with a
`tracing` layer that increments a Prometheus counter each time we log a
log message. We have the counter per tracing event level. This allows
for monitoring WARN and ERR log volume without parsing the log. Also, it
would allow cross-checking whether logs got dropped on the way into
Loki.
It would be nicer if we could hook deeper into the tracing logging
layer, to avoid evaluating the filter twice.
But I don't know how to do it.
Do several attempts to get spec from the control-plane and retry network
errors and all reasonable HTTP response codes. Do not hang waiting for
spec without confirmation from the control-plane that compute is known
and is in the `Empty` state.
Adjust the way we track `total_startup_ms` metric, it should be
calculated since the moment we received spec, not from the moment
`compute_ctl` started. Also introduce a new `wait_for_spec_ms` metric
to track the time spent sleeping and waiting for spec to be delivered
from control-plane.
Part of neondatabase/cloud#3533
See https://github.com/neondatabase/neon/pull/3991
Brings the changes back with the right way to use new `toml_edit` to
deserialize values and a unit test for this.
All non-trivial updates extracted into separate commits, also `carho hakari` data and its manifest format were updated.
3 sets of crates remain unupdated:
* `base64` — touches proxy in a lot of places and changed its api (by 0.21 version) quite strongly since our version (0.13).
* `opentelemetry` and `opentelemetry-*` crates
```
error[E0308]: mismatched types
--> libs/tracing-utils/src/http.rs:65:21
|
65 | span.set_parent(parent_ctx);
| ---------- ^^^^^^^^^^ expected struct `opentelemetry_api::context::Context`, found struct `opentelemetry::Context`
| |
| arguments to this method are incorrect
|
= note: struct `opentelemetry::Context` and struct `opentelemetry_api::context::Context` have similar names, but are actually distinct types
note: struct `opentelemetry::Context` is defined in crate `opentelemetry_api`
--> /Users/someonetoignore/.cargo/registry/src/github.com-1ecc6299db9ec823/opentelemetry_api-0.19.0/src/context.rs:77:1
|
77 | pub struct Context {
| ^^^^^^^^^^^^^^^^^^
note: struct `opentelemetry_api::context::Context` is defined in crate `opentelemetry_api`
--> /Users/someonetoignore/.cargo/registry/src/github.com-1ecc6299db9ec823/opentelemetry_api-0.18.0/src/context.rs:77:1
|
77 | pub struct Context {
| ^^^^^^^^^^^^^^^^^^
= note: perhaps two different versions of crate `opentelemetry_api` are being used?
note: associated function defined here
--> /Users/someonetoignore/.cargo/registry/src/github.com-1ecc6299db9ec823/tracing-opentelemetry-0.18.0/src/span_ext.rs:43:8
|
43 | fn set_parent(&self, cx: Context);
| ^^^^^^^^^^
For more information about this error, try `rustc --explain E0308`.
error: could not compile `tracing-utils` due to previous error
warning: build failed, waiting for other jobs to finish...
error: could not compile `tracing-utils` due to previous error
```
`tracing-opentelemetry` of version `0.19` is not yet released, that is supposed to have the update we need.
* similarly, `rustls`, `tokio-rustls`, `rustls-*` and `tls-listener` crates have similar issue:
```
error[E0308]: mismatched types
--> libs/postgres_backend/tests/simple_select.rs:112:78
|
112 | let mut make_tls_connect = tokio_postgres_rustls::MakeRustlsConnect::new(client_cfg);
| --------------------------------------------- ^^^^^^^^^^ expected struct `rustls::client::client_conn::ClientConfig`, found struct `ClientConfig`
| |
| arguments to this function are incorrect
|
= note: struct `ClientConfig` and struct `rustls::client::client_conn::ClientConfig` have similar names, but are actually distinct types
note: struct `ClientConfig` is defined in crate `rustls`
--> /Users/someonetoignore/.cargo/registry/src/github.com-1ecc6299db9ec823/rustls-0.21.0/src/client/client_conn.rs:125:1
|
125 | pub struct ClientConfig {
| ^^^^^^^^^^^^^^^^^^^^^^^
note: struct `rustls::client::client_conn::ClientConfig` is defined in crate `rustls`
--> /Users/someonetoignore/.cargo/registry/src/github.com-1ecc6299db9ec823/rustls-0.20.8/src/client/client_conn.rs:91:1
|
91 | pub struct ClientConfig {
| ^^^^^^^^^^^^^^^^^^^^^^^
= note: perhaps two different versions of crate `rustls` are being used?
note: associated function defined here
--> /Users/someonetoignore/.cargo/registry/src/github.com-1ecc6299db9ec823/tokio-postgres-rustls-0.9.0/src/lib.rs:23:12
|
23 | pub fn new(config: ClientConfig) -> Self {
| ^^^
For more information about this error, try `rustc --explain E0308`.
error: could not compile `postgres_backend` due to previous error
warning: build failed, waiting for other jobs to finish...
```
* aws crates: I could not make new API to work with bucket endpoint overload, and console e2e tests failed.
Other our tests passed, further investigation is worth to be done in https://github.com/neondatabase/neon/issues/4008
Before this patch, if a tenant would override its eviction_policy
setting to use a lower LayerAccessThreshold::threshold than the
`evictions_low_residence_duration_metric_threshold`, the evictions done
for that tenant would count towards the
`evictions_with_low_residence_duration` metric.
That metric is used to identify pre-mature evictions, commonly triggered
by disk-usage-based eviction under disk pressure.
We don't want that to happen for the legitimate evictions of the tenant
that overrides its eviction_policy.
So, this patch
- moves the setting into TenantConf
- adds test coverage
- updates the staging & prod yamls
Forward Compatibility:
Software before this patch will ignore the new tenant conf field and use
the global one instead.
So we can roll back safely.
Backward Compatibility:
Parsing old configs with software as of this patch will fail in
`PageServerConf::parse_and_validate` with error
`unrecognized pageserver option 'evictions_low_residence_duration_metric_threshold'`
if the option is still present in the global section.
We deal with this by updating the configs in Ansible.
fixes https://github.com/neondatabase/neon/issues/3940
With this commit one can request compute reconfiguration
from the running `compute_ctl` with compute in `Running` state
by sending a new spec:
```shell
curl -d "{\"spec\": $(cat ./compute-spec-new.json)}" http://localhost:3080/configure
```
Internally, we start a separate configurator thread that is waiting on
`Condvar` for `ConfigurationPending` compute state in a loop. Then it does
reconfiguration, sets compute back to `Running` state and notifies other
waiters.
It will need some follow-ups, e.g. for retry logic for control-plane
requests, but should be useful for testing in the current state. This
shouldn't affect any existing environment, since computes are configured
in a different way there.
Resolvesneondatabase/cloud#4433
Reason and backtrace are added to the Broken state. Backtrace is automatically collected when tenant entered the broken state. The format for API, CLI and metrics is changed and unified to return tenant state name in camel case. Previously snake case was used for metrics and camel case was used for everything else. Now tenant state field in TenantInfo swagger spec is changed to contain state name in "slug" field and other fields (currently only reason and backtrace for Broken variant in "data" field). To allow for this breaking change state was removed from TenantInfo swagger spec because it was not used anywhere.
Please note that the tenant's broken reason is not persisted on disk so the reason is lost when pageserver is restarted.
Requires changes to grafana dashboard that monitors tenant states.
Closes#3001
---------
Co-authored-by: theirix <theirix@gmail.com>
All non-trivial updates extracted into separate commits, also `carho
hakari` data and its manifest format were updated.
3 sets of crates remain unupdated:
* `base64` — touches proxy in a lot of places and changed its api (by
0.21 version) quite strongly since our version (0.13).
* `opentelemetry` and `opentelemetry-*` crates
```
error[E0308]: mismatched types
--> libs/tracing-utils/src/http.rs:65:21
|
65 | span.set_parent(parent_ctx);
| ---------- ^^^^^^^^^^ expected struct `opentelemetry_api::context::Context`, found struct `opentelemetry::Context`
| |
| arguments to this method are incorrect
|
= note: struct `opentelemetry::Context` and struct `opentelemetry_api::context::Context` have similar names, but are actually distinct types
note: struct `opentelemetry::Context` is defined in crate `opentelemetry_api`
--> /Users/someonetoignore/.cargo/registry/src/github.com-1ecc6299db9ec823/opentelemetry_api-0.19.0/src/context.rs:77:1
|
77 | pub struct Context {
| ^^^^^^^^^^^^^^^^^^
note: struct `opentelemetry_api::context::Context` is defined in crate `opentelemetry_api`
--> /Users/someonetoignore/.cargo/registry/src/github.com-1ecc6299db9ec823/opentelemetry_api-0.18.0/src/context.rs:77:1
|
77 | pub struct Context {
| ^^^^^^^^^^^^^^^^^^
= note: perhaps two different versions of crate `opentelemetry_api` are being used?
note: associated function defined here
--> /Users/someonetoignore/.cargo/registry/src/github.com-1ecc6299db9ec823/tracing-opentelemetry-0.18.0/src/span_ext.rs:43:8
|
43 | fn set_parent(&self, cx: Context);
| ^^^^^^^^^^
For more information about this error, try `rustc --explain E0308`.
error: could not compile `tracing-utils` due to previous error
warning: build failed, waiting for other jobs to finish...
error: could not compile `tracing-utils` due to previous error
```
`tracing-opentelemetry` of version `0.19` is not yet released, that is
supposed to have the update we need.
* similarly, `rustls`, `tokio-rustls`, `rustls-*` and `tls-listener`
crates have similar issue:
```
error[E0308]: mismatched types
--> libs/postgres_backend/tests/simple_select.rs:112:78
|
112 | let mut make_tls_connect = tokio_postgres_rustls::MakeRustlsConnect::new(client_cfg);
| --------------------------------------------- ^^^^^^^^^^ expected struct `rustls::client::client_conn::ClientConfig`, found struct `ClientConfig`
| |
| arguments to this function are incorrect
|
= note: struct `ClientConfig` and struct `rustls::client::client_conn::ClientConfig` have similar names, but are actually distinct types
note: struct `ClientConfig` is defined in crate `rustls`
--> /Users/someonetoignore/.cargo/registry/src/github.com-1ecc6299db9ec823/rustls-0.21.0/src/client/client_conn.rs:125:1
|
125 | pub struct ClientConfig {
| ^^^^^^^^^^^^^^^^^^^^^^^
note: struct `rustls::client::client_conn::ClientConfig` is defined in crate `rustls`
--> /Users/someonetoignore/.cargo/registry/src/github.com-1ecc6299db9ec823/rustls-0.20.8/src/client/client_conn.rs:91:1
|
91 | pub struct ClientConfig {
| ^^^^^^^^^^^^^^^^^^^^^^^
= note: perhaps two different versions of crate `rustls` are being used?
note: associated function defined here
--> /Users/someonetoignore/.cargo/registry/src/github.com-1ecc6299db9ec823/tokio-postgres-rustls-0.9.0/src/lib.rs:23:12
|
23 | pub fn new(config: ClientConfig) -> Self {
| ^^^
For more information about this error, try `rustc --explain E0308`.
error: could not compile `postgres_backend` due to previous error
warning: build failed, waiting for other jobs to finish...
```
* aws crates: I could not make new API to work with bucket endpoint
overload, and console e2e tests failed.
Other our tests passed, further investigation is worth to be done in
https://github.com/neondatabase/neon/issues/4008
Sometimes, it contained real values, sometimes just defaults if the
spec was not received yet. Make the state more clear by making it an
Option instead.
One consequence is that if some of the required settings like
neon.tenant_id are missing from the spec file sent to the /configure
endpoint, it is spotted earlier and you get an immediate HTTP error
response. Not that it matters very much, but it's nicer nevertheless.
TCP_KEEPALIVE is not enabled by default, so this prevents hanged up connections
in case of abrupt client termination. Add 'closed' flag to PostgresBackendReader
and pass it during handles join to prevent attempts to read from socket if we
errored out previously -- now with timeouts this is a common situation.
It looks like
2023-04-10T18:08:37.493448Z INFO {cid=68}:WAL
receiver{ttid=59f91ad4e821ab374f9ccdf918da3a85/16438f99d61572c72f0c7b0ed772785d}:
terminated: timed out
Presumably fixes https://github.com/neondatabase/neon/issues/3971
This is in preparation of using compute_ctl to launch postgres nodes
in the neon_local control plane. And seems like a good idea to
separate the public interfaces anyway.
One non-mechanical change here is that the 'metrics' field is moved
under the Mutex, instead of using atomics. We were not using atomics
for performance but for convenience here, and it seems more clear to
not use atomics in the model for the HTTP response type.
Replaces `Box<(dyn io::AsyncRead + Unpin + Send + Sync + 'static)>` with
`impl io::AsyncRead + Unpin + Send + Sync + 'static` usages in the
`RemoteStorage` interface, to make it closer to
[`#![feature(async_fn_in_trait)]`](https://blog.rust-lang.org/inside-rust/2022/11/17/async-fn-in-trait-nightly.html)
For `GenericRemoteStorage`, replaces `type Target = dyn RemoteStorage`
with another impl with `RemoteStorage` methods inside it.
We can reuse the trait, that would require importing the trait in every
file where it's used and makes us farther from the unstable feature.
After this PR, I've manged to create a patch with the changes:
https://github.com/neondatabase/neon/compare/kb/less-dyn-storage...kb/nightly-async-trait?expand=1
Current rust implementation does not like recursive async trait calls,
so `UnreliableWrapper` was removed: it contained a
`GenericRemoteStorage` that implemented the `RemoteStorage` trait, and
itself implemented the trait, which nightly rustc did not like and
proposed to box the future.
Similarly, `GenericRemoteStorage` cannot implement `RemoteStorage` for
nightly rustc to work, since calls various remote storages' methods from
inside.
I've compiled current `main` and the nightly branch both with `time env
RUSTC_WRAPPER="" cargo +nightly build --all --timings` command, and got
```
Finished dev [optimized + debuginfo] target(s) in 2m 04s
env RUSTC_WRAPPER="" cargo +nightly build --all --timings 1283.19s user 50.40s system 1074% cpu 2:04.15 total
for the new feature tried and
Finished dev [optimized + debuginfo] target(s) in 2m 40s
env RUSTC_WRAPPER="" cargo +nightly build --all --timings 1288.59s user 52.06s system 834% cpu 2:40.71 total
for the old async_trait approach.
```
On my machine, the `remote_storage` lib compilation takes ~10 less time
with the nightly feature (left) than the regular main (right).
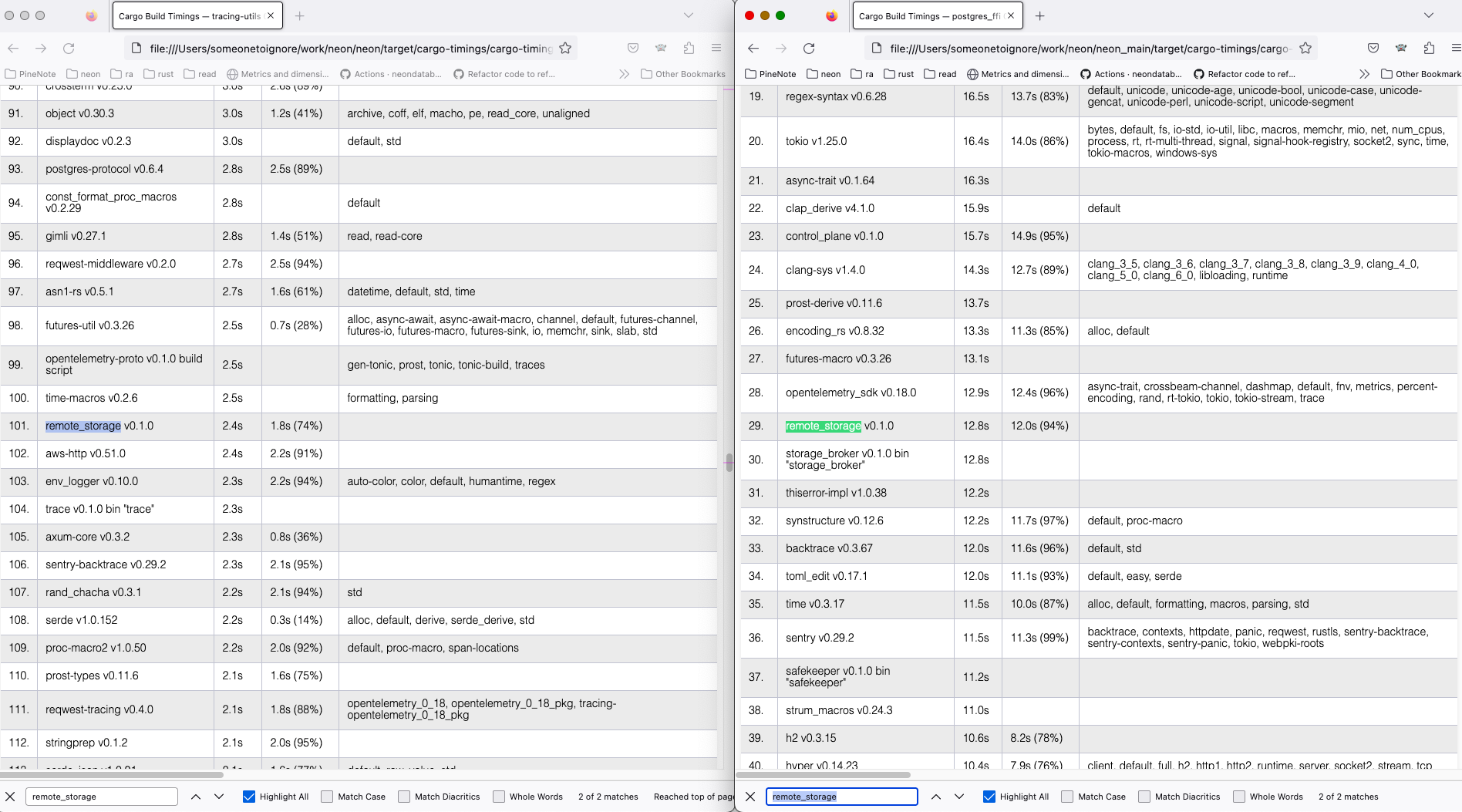
Full cargo reports are available at
[timings.zip](https://github.com/neondatabase/neon/files/11179369/timings.zip)
in real env testing we noted that the disk-usage based eviction sails 1
percentage point above the configured value, which might be a source of
confusion, so it might be better to get rid of that confusion now.
confusion: "I configured 85% but pageserver sails at 86%".
Co-authored-by: Christian Schwarz <christian@neon.tech>
In S3, pageserver only lists tenants (prefixes) on S3, no other keys.
Remove the list operation from the API, since S3 impl does not seem to
work normally and not used anyway,
This is the the feedback originating from pageserver, so change previous
confusing names to
s/ReplicationFeedback/PageserverFeedback
s/ps_writelsn/last_receive_lsn
s/ps_flushlsn/disk_consistent_lsn
s/ps_apply_lsn/remote_consistent_lsn
I haven't changed on the wire format to keep compatibility. However,
understanding of new field names is added to compute, so once all computes
receive this patch we can change the wire names as well. Safekeepers/pageservers
are deployed roughly at the same time and it is ok to live without feedbacks
during the short period, so this is not a problem there.
This patch adds a pageserver-global background loop that evicts layers
in response to a shortage of available bytes in the $repo/tenants
directory's filesystem.
The loop runs periodically at a configurable `period`.
Each loop iteration uses `statvfs` to determine filesystem-level space
usage. It compares the returned usage data against two different types
of thresholds. The iteration tries to evict layers until app-internal
accounting says we should be below the thresholds. We cross-check this
internal accounting with the real world by making another `statvfs` at
the end of the iteration. We're good if that second statvfs shows that
we're _actually_ below the configured thresholds. If we're still above
one or more thresholds, we emit a warning log message, leaving it to the
operator to investigate further.
There are two thresholds:
- `max_usage_pct` is the relative available space, expressed in percent
of the total filesystem space. If the actual usage is higher, the
threshold is exceeded.
- `min_avail_bytes` is the absolute available space in bytes. If the
actual usage is lower, the threshold is exceeded.
The iteration evicts layers in LRU fashion with a reservation of up to
`tenant_min_resident_size` bytes of the most recent layers per tenant.
The layers not part of the per-tenant reservation are evicted
least-recently-used first until we're below all thresholds. The
`tenant_min_resident_size` can be overridden per tenant as
`min_resident_size_override` (bytes).
In addition to the loop, there is also an HTTP endpoint to perform one
loop iteration synchronous to the request. The endpoint takes an
absolute number of bytes that the iteration needs to evict before
pressure is relieved. The tests use this endpoint, which is a great
simplification over setting up loopback-mounts in the tests, which would
be required to test the statvfs part of the implementation. We will rely
on manual testing in staging to test the statvfs parts.
The HTTP endpoint is also handy in emergencies where an operator wants
the pageserver to evict a given amount of space _now. Hence, it's
arguments documented in openapi_spec.yml. The response type isn't
documented though because we don't consider it stable. The endpoint
should _not_ be used by Console but it could be used by on-call.
Co-authored-by: Joonas Koivunen <joonas@neon.tech>
Co-authored-by: Dmitry Rodionov <dmitry@neon.tech>
Co-authored-by: Heikki Linnakangas <heikki@neon.tech>
neon_local sends SIGQUIT, which otherwise dumps core by default. Also, remove
obsolete install_shutdown_handlers; in all binaries it was overridden by
ShutdownSignals::handle later.
ref https://github.com/neondatabase/neon/issues/3847
The PR enforces current newest `index_part.json` format in the type
system (version `1`), not allowing any previous forms of it, that were
used in the past.
Similarly, the code to mitigate the
https://github.com/neondatabase/neon/issues/3024 issue is now also
removed.
Current code does not produce old formats and extra files in the
index_part.json, in the future we will be able to use
https://github.com/neondatabase/aversion or other approach to make
version transitions more explicit.
See https://neondb.slack.com/archives/C033RQ5SPDH/p1679134185248119 for
the justification on the breaking changes.
The control plane currently only supports EdDSA. We need to either teach
the storage to use EdDSA, or the control plane to use RSA. EdDSA is more
modern, so let's use that.
We could support both, but it would require a little more code and tests,
and we don't really need the flexibility since we control both sides.
Otherwise they get lost. Normally buffer is empty before proxy pass, but this is
not the case with pipeline mode of out npm driver; fixes connection hangup
introduced by b80fe41af3 for it.
fixes https://github.com/neondatabase/neon/issues/3822
- handle automatically fixable future clippies
- tune run-clippy.sh to remove macos specifics which we no longer have
Co-authored-by: Alexander Bayandin <alexander@neon.tech>
Previously, we only accepted RS256. Seems like a pointless limitation,
and when I was testing it with RS512 tokens, it took me a while to
understand why it wasn't working.
1) Remove allocation and data copy during each message read. Instead, parsing
functions now accept BytesMut from which data they form messages, with
pointers (e.g. in CopyData) pointing directly into BytesMut buffer. Accordingly,
move ConnectionError containing IO error subtype into framed.rs providing this
and leave in pq_proto only ProtocolError.
2) Remove anyhow from pq_proto.
3) Move FeStartupPacket out of FeMessage. Now FeStartupPacket::parse returns it
directly, eliminating dead code where user wants startup packet but has to match
for others.
proxy stream.rs is adapted to framed.rs with minimal changes. It also benefits
from framed.rs improvements described above.
- Add support for splitting async postgres_backend into read and write halfes.
Safekeeper needs this for bidirectional streams. To this end, encapsulate
reading-writing postgres messages to framed.rs with split support without any
additional changes (relying on BufRead for reading and BytesMut out buffer for
writing).
- Use async postgres_backend throughout safekeeper (and in proxy auth link
part).
- In both safekeeper COPY streams, do read-write from the same thread/task with
select! for easier error handling.
- Tidy up finishing CopyBoth streams in safekeeper sending and receiving WAL
-- join split parts back catching errors from them before returning.
Initially I hoped to do that read-write without split at all, through polling
IO:
https://github.com/neondatabase/neon/pull/3522
However that turned out to be more complicated than I initially expected
due to 1) borrow checking and 2) anon Future types. 1) required Rc<Refcell<...>>
which is Send construct just to satisfy the checker; 2) can be workaround with
transmute. But this is so messy that I decided to leave split.
To untie cyclic dependency between sync and async versions of postgres_backend,
copy QueryError and some logging/error routines to postgres_backend.rs. This is
temporal glue to make commits smaller, sync version will be dropped by the
upcoming commit completely.
Adds a newtype that creates a span with request_id from
https://github.com/neondatabase/neon/pull/3708 for every HTTP request
served.
Moves request logging and error handlers under the new wrapper, so every request-related event now is logged under the request span.
For compatibility reasons, error handler is left on the general router, since not every service uses the new handler wrappers yet.
{kind=link}