mirror of
https://github.com/lancedb/lancedb.git
synced 2025-12-23 13:29:57 +00:00
Compare commits
125 Commits
python-v0.
...
python-v0.
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
74004161ff | ||
|
|
34ddb1de6d | ||
|
|
1029fc9cb0 | ||
|
|
31c5df6d99 | ||
|
|
dbf37a0434 | ||
|
|
f20f19b804 | ||
|
|
55207ce844 | ||
|
|
c21f9cdda0 | ||
|
|
bc38abb781 | ||
|
|
731f86e44c | ||
|
|
31dad71c94 | ||
|
|
9585f550b3 | ||
|
|
8dc2315479 | ||
|
|
f6bfb5da11 | ||
|
|
661fcecf38 | ||
|
|
07fe284810 | ||
|
|
800bb691c3 | ||
|
|
ec24e09add | ||
|
|
0554db03b3 | ||
|
|
b315ea3978 | ||
|
|
aa7806cf0d | ||
|
|
6799613109 | ||
|
|
0f26915d22 | ||
|
|
32163063dc | ||
|
|
9a9a73a65d | ||
|
|
52fa7f5577 | ||
|
|
0cba0f4f92 | ||
|
|
8391ffee84 | ||
|
|
fe8848efb9 | ||
|
|
213c313b99 | ||
|
|
157e995a43 | ||
|
|
ab97e5d632 | ||
|
|
87e9a0250f | ||
|
|
e587a17a64 | ||
|
|
2f1f9f6338 | ||
|
|
a34fa4df26 | ||
|
|
e20979b335 | ||
|
|
08689c345d | ||
|
|
909b7e90cd | ||
|
|
ae8486cc8f | ||
|
|
b8f32d082f | ||
|
|
ea7522baa5 | ||
|
|
8764741116 | ||
|
|
cc916389a6 | ||
|
|
3d7d903d88 | ||
|
|
cc5e2d3e10 | ||
|
|
30f5bc5865 | ||
|
|
2737315cb2 | ||
|
|
d52422603c | ||
|
|
f35f8e451f | ||
|
|
0b9924b432 | ||
|
|
ba416a571d | ||
|
|
13317ffb46 | ||
|
|
ca961567fe | ||
|
|
31a12a141d | ||
|
|
e3061d4cb4 | ||
|
|
1fcc67fd2c | ||
|
|
ac18812af0 | ||
|
|
8324e0f171 | ||
|
|
f0bcb26f32 | ||
|
|
b281c5255c | ||
|
|
d349d2a44a | ||
|
|
0699a6fa7b | ||
|
|
b1a5c251ba | ||
|
|
722462c38b | ||
|
|
902a402951 | ||
|
|
2f2cb984d4 | ||
|
|
9921b2a4e5 | ||
|
|
03b8f99dca | ||
|
|
aa91f35a28 | ||
|
|
f227658e08 | ||
|
|
fd65887d87 | ||
|
|
4673958543 | ||
|
|
a54d1e5618 | ||
|
|
8f7264f81d | ||
|
|
44b8271fde | ||
|
|
74ef141b9c | ||
|
|
b69b1e3ec8 | ||
|
|
bbfadfe58d | ||
|
|
cf977866d8 | ||
|
|
3ff3068a1e | ||
|
|
593b5939be | ||
|
|
f0e1290ae6 | ||
|
|
4b45128bd6 | ||
|
|
b06e214d29 | ||
|
|
c1f8feb6ed | ||
|
|
cada35d5b7 | ||
|
|
2d25c263e9 | ||
|
|
bcd7f66dc7 | ||
|
|
1daecac648 | ||
|
|
b8e656b2a7 | ||
|
|
ff7c1193a7 | ||
|
|
6d70e7c29b | ||
|
|
73cc12ecc5 | ||
|
|
6036cf48a7 | ||
|
|
15f4787cc8 | ||
|
|
0e4050e706 | ||
|
|
147796ffcd | ||
|
|
6fd465ceef | ||
|
|
e2e5a0fb83 | ||
|
|
ff8d5a6d51 | ||
|
|
8829988ada | ||
|
|
80a32be121 | ||
|
|
8325979bb8 | ||
|
|
ed5ff5a482 | ||
|
|
2c9371dcc4 | ||
|
|
6d5621da4a | ||
|
|
380c1572f3 | ||
|
|
4383848d53 | ||
|
|
473c43860c | ||
|
|
17cf244e53 | ||
|
|
0b60694df4 | ||
|
|
600da476e8 | ||
|
|
458217783c | ||
|
|
21b1a71a6b | ||
|
|
2d899675e8 | ||
|
|
1cbfc1bbf4 | ||
|
|
a2bb497135 | ||
|
|
0cf40c8da3 | ||
|
|
8233c689c3 | ||
|
|
6e24e731b8 | ||
|
|
f4ce86e12c | ||
|
|
0664eaec82 | ||
|
|
63acdc2069 | ||
|
|
a636bb1075 |
@@ -1,5 +1,5 @@
|
|||||||
[bumpversion]
|
[bumpversion]
|
||||||
current_version = 0.1.14
|
current_version = 0.2.6
|
||||||
commit = True
|
commit = True
|
||||||
message = Bump version: {current_version} → {new_version}
|
message = Bump version: {current_version} → {new_version}
|
||||||
tag = True
|
tag = True
|
||||||
|
|||||||
65
.github/workflows/make-release-commit.yml
vendored
65
.github/workflows/make-release-commit.yml
vendored
@@ -25,38 +25,35 @@ jobs:
|
|||||||
bump-version:
|
bump-version:
|
||||||
runs-on: ubuntu-latest
|
runs-on: ubuntu-latest
|
||||||
steps:
|
steps:
|
||||||
- name: Check out main
|
- name: Check out main
|
||||||
uses: actions/checkout@v3
|
uses: actions/checkout@v3
|
||||||
with:
|
with:
|
||||||
ref: main
|
ref: main
|
||||||
persist-credentials: false
|
persist-credentials: false
|
||||||
fetch-depth: 0
|
fetch-depth: 0
|
||||||
lfs: true
|
lfs: true
|
||||||
- name: Set git configs for bumpversion
|
- name: Set git configs for bumpversion
|
||||||
shell: bash
|
shell: bash
|
||||||
run: |
|
run: |
|
||||||
git config user.name 'Lance Release'
|
git config user.name 'Lance Release'
|
||||||
git config user.email 'lance-dev@lancedb.com'
|
git config user.email 'lance-dev@lancedb.com'
|
||||||
- name: Set up Python 3.10
|
- name: Set up Python 3.10
|
||||||
uses: actions/setup-python@v4
|
uses: actions/setup-python@v4
|
||||||
with:
|
with:
|
||||||
python-version: "3.10"
|
python-version: "3.10"
|
||||||
- name: Bump version, create tag and commit
|
- name: Bump version, create tag and commit
|
||||||
run: |
|
run: |
|
||||||
pip install bump2version
|
pip install bump2version
|
||||||
bumpversion --verbose ${{ inputs.part }}
|
bumpversion --verbose ${{ inputs.part }}
|
||||||
- name: Update package-lock.json file
|
- name: Push new version and tag
|
||||||
run: |
|
if: ${{ inputs.dry_run }} == "false"
|
||||||
npm install
|
uses: ad-m/github-push-action@master
|
||||||
git add package-lock.json
|
with:
|
||||||
# Add this change to the commit created by bumpversion
|
github_token: ${{ secrets.LANCEDB_RELEASE_TOKEN }}
|
||||||
git commit --amend --no-edit
|
branch: main
|
||||||
working-directory: node
|
tags: true
|
||||||
- name: Push new version and tag
|
- uses: ./.github/workflows/update_package_lock
|
||||||
if: ${{ inputs.dry_run }} == "false"
|
if: ${{ inputs.dry_run }} == "false"
|
||||||
uses: ad-m/github-push-action@master
|
with:
|
||||||
with:
|
github_token: ${{ secrets.LANCEDB_RELEASE_TOKEN }}
|
||||||
github_token: ${{ secrets.LANCEDB_RELEASE_TOKEN }}
|
|
||||||
branch: main
|
|
||||||
tags: true
|
|
||||||
|
|
||||||
|
|||||||
58
.github/workflows/node.yml
vendored
58
.github/workflows/node.yml
vendored
@@ -9,6 +9,7 @@ on:
|
|||||||
- node/**
|
- node/**
|
||||||
- rust/ffi/node/**
|
- rust/ffi/node/**
|
||||||
- .github/workflows/node.yml
|
- .github/workflows/node.yml
|
||||||
|
- docker-compose.yml
|
||||||
|
|
||||||
env:
|
env:
|
||||||
# Disable full debug symbol generation to speed up CI build and keep memory down
|
# Disable full debug symbol generation to speed up CI build and keep memory down
|
||||||
@@ -70,7 +71,7 @@ jobs:
|
|||||||
npm run tsc
|
npm run tsc
|
||||||
npm run build
|
npm run build
|
||||||
npm run pack-build
|
npm run pack-build
|
||||||
npm install --no-save ./dist/vectordb-*.tgz
|
npm install --no-save ./dist/lancedb-vectordb-*.tgz
|
||||||
# Remove index.node to test with dependency installed
|
# Remove index.node to test with dependency installed
|
||||||
rm index.node
|
rm index.node
|
||||||
- name: Test
|
- name: Test
|
||||||
@@ -101,9 +102,62 @@ jobs:
|
|||||||
npm run tsc
|
npm run tsc
|
||||||
npm run build
|
npm run build
|
||||||
npm run pack-build
|
npm run pack-build
|
||||||
npm install --no-save ./dist/vectordb-*.tgz
|
npm install --no-save ./dist/lancedb-vectordb-*.tgz
|
||||||
# Remove index.node to test with dependency installed
|
# Remove index.node to test with dependency installed
|
||||||
rm index.node
|
rm index.node
|
||||||
- name: Test
|
- name: Test
|
||||||
run: |
|
run: |
|
||||||
npm run test
|
npm run test
|
||||||
|
aws-integtest:
|
||||||
|
timeout-minutes: 45
|
||||||
|
runs-on: "ubuntu-22.04"
|
||||||
|
defaults:
|
||||||
|
run:
|
||||||
|
shell: bash
|
||||||
|
working-directory: node
|
||||||
|
env:
|
||||||
|
AWS_ACCESS_KEY_ID: ACCESSKEY
|
||||||
|
AWS_SECRET_ACCESS_KEY: SECRETKEY
|
||||||
|
AWS_DEFAULT_REGION: us-west-2
|
||||||
|
# this one is for s3
|
||||||
|
AWS_ENDPOINT: http://localhost:4566
|
||||||
|
# this one is for dynamodb
|
||||||
|
DYNAMODB_ENDPOINT: http://localhost:4566
|
||||||
|
steps:
|
||||||
|
- uses: actions/checkout@v3
|
||||||
|
with:
|
||||||
|
fetch-depth: 0
|
||||||
|
lfs: true
|
||||||
|
- uses: actions/setup-node@v3
|
||||||
|
with:
|
||||||
|
node-version: 18
|
||||||
|
cache: 'npm'
|
||||||
|
cache-dependency-path: node/package-lock.json
|
||||||
|
- name: start local stack
|
||||||
|
run: docker compose -f ../docker-compose.yml up -d --wait
|
||||||
|
- name: create s3
|
||||||
|
run: aws s3 mb s3://lancedb-integtest --endpoint $AWS_ENDPOINT
|
||||||
|
- name: create ddb
|
||||||
|
run: |
|
||||||
|
aws dynamodb create-table \
|
||||||
|
--table-name lancedb-integtest \
|
||||||
|
--attribute-definitions '[{"AttributeName": "base_uri", "AttributeType": "S"}, {"AttributeName": "version", "AttributeType": "N"}]' \
|
||||||
|
--key-schema '[{"AttributeName": "base_uri", "KeyType": "HASH"}, {"AttributeName": "version", "KeyType": "RANGE"}]' \
|
||||||
|
--provisioned-throughput '{"ReadCapacityUnits": 10, "WriteCapacityUnits": 10}' \
|
||||||
|
--endpoint-url $DYNAMODB_ENDPOINT
|
||||||
|
- uses: Swatinem/rust-cache@v2
|
||||||
|
- name: Install dependencies
|
||||||
|
run: |
|
||||||
|
sudo apt update
|
||||||
|
sudo apt install -y protobuf-compiler libssl-dev
|
||||||
|
- name: Build
|
||||||
|
run: |
|
||||||
|
npm ci
|
||||||
|
npm run tsc
|
||||||
|
npm run build
|
||||||
|
npm run pack-build
|
||||||
|
npm install --no-save ./dist/lancedb-vectordb-*.tgz
|
||||||
|
# Remove index.node to test with dependency installed
|
||||||
|
rm index.node
|
||||||
|
- name: Test
|
||||||
|
run: npm run integration-test
|
||||||
|
|||||||
119
.github/workflows/npm-publish.yml
vendored
119
.github/workflows/npm-publish.yml
vendored
@@ -46,75 +46,51 @@ jobs:
|
|||||||
matrix:
|
matrix:
|
||||||
target: [x86_64-apple-darwin, aarch64-apple-darwin]
|
target: [x86_64-apple-darwin, aarch64-apple-darwin]
|
||||||
steps:
|
steps:
|
||||||
- name: Checkout
|
- name: Checkout
|
||||||
uses: actions/checkout@v3
|
uses: actions/checkout@v3
|
||||||
- name: Install system dependencies
|
- name: Install system dependencies
|
||||||
run: brew install protobuf
|
run: brew install protobuf
|
||||||
- name: Install npm dependencies
|
- name: Install npm dependencies
|
||||||
run: |
|
run: |
|
||||||
cd node
|
cd node
|
||||||
npm ci
|
npm ci
|
||||||
- name: Install rustup target
|
- name: Install rustup target
|
||||||
if: ${{ matrix.target == 'aarch64-apple-darwin' }}
|
if: ${{ matrix.target == 'aarch64-apple-darwin' }}
|
||||||
run: rustup target add aarch64-apple-darwin
|
run: rustup target add aarch64-apple-darwin
|
||||||
- name: Build MacOS native node modules
|
- name: Build MacOS native node modules
|
||||||
run: bash ci/build_macos_artifacts.sh ${{ matrix.target }}
|
run: bash ci/build_macos_artifacts.sh ${{ matrix.target }}
|
||||||
- name: Upload Darwin Artifacts
|
- name: Upload Darwin Artifacts
|
||||||
uses: actions/upload-artifact@v3
|
uses: actions/upload-artifact@v3
|
||||||
with:
|
with:
|
||||||
name: darwin-native
|
name: native-darwin
|
||||||
path: |
|
path: |
|
||||||
node/dist/vectordb-darwin*.tgz
|
node/dist/lancedb-vectordb-darwin*.tgz
|
||||||
|
|
||||||
node-linux:
|
node-linux:
|
||||||
name: node-linux (${{ matrix.arch}}-unknown-linux-${{ matrix.libc }})
|
name: node-linux (${{ matrix.config.arch}}-unknown-linux-gnu
|
||||||
runs-on: ubuntu-latest
|
runs-on: ${{ matrix.config.runner }}
|
||||||
# Only runs on tags that matches the make-release action
|
# Only runs on tags that matches the make-release action
|
||||||
if: startsWith(github.ref, 'refs/tags/v')
|
if: startsWith(github.ref, 'refs/tags/v')
|
||||||
strategy:
|
strategy:
|
||||||
fail-fast: false
|
fail-fast: false
|
||||||
matrix:
|
matrix:
|
||||||
libc:
|
config:
|
||||||
- gnu
|
- arch: x86_64
|
||||||
# TODO: re-enable musl once we have refactored to pre-built containers
|
runner: ubuntu-latest
|
||||||
# Right now we have to build node from source which is too expensive.
|
- arch: aarch64
|
||||||
# - musl
|
runner: buildjet-4vcpu-ubuntu-2204-arm
|
||||||
arch:
|
|
||||||
- x86_64
|
|
||||||
# Building on aarch64 is too slow for now
|
|
||||||
# - aarch64
|
|
||||||
steps:
|
steps:
|
||||||
- name: Checkout
|
- name: Checkout
|
||||||
uses: actions/checkout@v3
|
uses: actions/checkout@v3
|
||||||
- name: Change owner to root (for npm)
|
- name: Build Linux Artifacts
|
||||||
# The docker container is run as root, so we need the files to be owned by root
|
run: |
|
||||||
# Otherwise npm is a nightmare: https://github.com/npm/cli/issues/3773
|
bash ci/build_linux_artifacts.sh ${{ matrix.config.arch }}
|
||||||
run: sudo chown -R root:root .
|
- name: Upload Linux Artifacts
|
||||||
- name: Set up QEMU
|
uses: actions/upload-artifact@v3
|
||||||
if: ${{ matrix.arch == 'aarch64' }}
|
with:
|
||||||
uses: docker/setup-qemu-action@v2
|
name: native-linux
|
||||||
with:
|
path: |
|
||||||
platforms: arm64
|
node/dist/lancedb-vectordb-linux*.tgz
|
||||||
- name: Build Linux GNU native node modules
|
|
||||||
if: ${{ matrix.libc == 'gnu' }}
|
|
||||||
run: |
|
|
||||||
docker run \
|
|
||||||
-v $(pwd):/io -w /io \
|
|
||||||
rust:1.70-bookworm \
|
|
||||||
bash ci/build_linux_artifacts.sh ${{ matrix.arch }}-unknown-linux-gnu
|
|
||||||
- name: Build musl Linux native node modules
|
|
||||||
if: ${{ matrix.libc == 'musl' }}
|
|
||||||
run: |
|
|
||||||
docker run --platform linux/arm64/v8 \
|
|
||||||
-v $(pwd):/io -w /io \
|
|
||||||
quay.io/pypa/musllinux_1_1_${{ matrix.arch }} \
|
|
||||||
bash ci/build_linux_artifacts.sh ${{ matrix.arch }}-unknown-linux-musl
|
|
||||||
- name: Upload Linux Artifacts
|
|
||||||
uses: actions/upload-artifact@v3
|
|
||||||
with:
|
|
||||||
name: linux-native
|
|
||||||
path: |
|
|
||||||
node/dist/vectordb-linux*.tgz
|
|
||||||
|
|
||||||
node-windows:
|
node-windows:
|
||||||
runs-on: windows-2022
|
runs-on: windows-2022
|
||||||
@@ -145,12 +121,12 @@ jobs:
|
|||||||
- name: Upload Windows Artifacts
|
- name: Upload Windows Artifacts
|
||||||
uses: actions/upload-artifact@v3
|
uses: actions/upload-artifact@v3
|
||||||
with:
|
with:
|
||||||
name: windows-native
|
name: native-windows
|
||||||
path: |
|
path: |
|
||||||
node/dist/vectordb-win32*.tgz
|
node/dist/lancedb-vectordb-win32*.tgz
|
||||||
|
|
||||||
release:
|
release:
|
||||||
needs: [node, node-macos, node-linux]
|
needs: [node, node-macos, node-linux, node-windows]
|
||||||
runs-on: ubuntu-latest
|
runs-on: ubuntu-latest
|
||||||
# Only runs on tags that matches the make-release action
|
# Only runs on tags that matches the make-release action
|
||||||
if: startsWith(github.ref, 'refs/tags/v')
|
if: startsWith(github.ref, 'refs/tags/v')
|
||||||
@@ -170,3 +146,18 @@ jobs:
|
|||||||
for filename in *.tgz; do
|
for filename in *.tgz; do
|
||||||
npm publish $filename
|
npm publish $filename
|
||||||
done
|
done
|
||||||
|
|
||||||
|
update-package-lock:
|
||||||
|
needs: [release]
|
||||||
|
runs-on: ubuntu-latest
|
||||||
|
steps:
|
||||||
|
- name: Checkout
|
||||||
|
uses: actions/checkout@v3
|
||||||
|
with:
|
||||||
|
ref: main
|
||||||
|
persist-credentials: false
|
||||||
|
fetch-depth: 0
|
||||||
|
lfs: true
|
||||||
|
- uses: ./.github/workflows/update_package_lock
|
||||||
|
with:
|
||||||
|
github_token: ${{ secrets.LANCEDB_RELEASE_TOKEN }}
|
||||||
|
|||||||
38
.github/workflows/python.yml
vendored
38
.github/workflows/python.yml
vendored
@@ -30,7 +30,7 @@ jobs:
|
|||||||
python-version: 3.${{ matrix.python-minor-version }}
|
python-version: 3.${{ matrix.python-minor-version }}
|
||||||
- name: Install lancedb
|
- name: Install lancedb
|
||||||
run: |
|
run: |
|
||||||
pip install -e .
|
pip install -e .[tests]
|
||||||
pip install tantivy@git+https://github.com/quickwit-oss/tantivy-py#164adc87e1a033117001cf70e38c82a53014d985
|
pip install tantivy@git+https://github.com/quickwit-oss/tantivy-py#164adc87e1a033117001cf70e38c82a53014d985
|
||||||
pip install pytest pytest-mock black isort
|
pip install pytest pytest-mock black isort
|
||||||
- name: Black
|
- name: Black
|
||||||
@@ -38,7 +38,7 @@ jobs:
|
|||||||
- name: isort
|
- name: isort
|
||||||
run: isort --check --diff --quiet .
|
run: isort --check --diff --quiet .
|
||||||
- name: Run tests
|
- name: Run tests
|
||||||
run: pytest -x -v --durations=30 tests
|
run: pytest -m "not slow" -x -v --durations=30 tests
|
||||||
- name: doctest
|
- name: doctest
|
||||||
run: pytest --doctest-modules lancedb
|
run: pytest --doctest-modules lancedb
|
||||||
mac:
|
mac:
|
||||||
@@ -59,10 +59,40 @@ jobs:
|
|||||||
python-version: "3.11"
|
python-version: "3.11"
|
||||||
- name: Install lancedb
|
- name: Install lancedb
|
||||||
run: |
|
run: |
|
||||||
pip install -e .
|
pip install -e .[tests]
|
||||||
pip install tantivy@git+https://github.com/quickwit-oss/tantivy-py#164adc87e1a033117001cf70e38c82a53014d985
|
pip install tantivy@git+https://github.com/quickwit-oss/tantivy-py#164adc87e1a033117001cf70e38c82a53014d985
|
||||||
pip install pytest pytest-mock black
|
pip install pytest pytest-mock black
|
||||||
- name: Black
|
- name: Black
|
||||||
run: black --check --diff --no-color --quiet .
|
run: black --check --diff --no-color --quiet .
|
||||||
- name: Run tests
|
- name: Run tests
|
||||||
run: pytest -x -v --durations=30 tests
|
run: pytest -m "not slow" -x -v --durations=30 tests
|
||||||
|
pydantic1x:
|
||||||
|
timeout-minutes: 30
|
||||||
|
runs-on: "ubuntu-22.04"
|
||||||
|
defaults:
|
||||||
|
run:
|
||||||
|
shell: bash
|
||||||
|
working-directory: python
|
||||||
|
steps:
|
||||||
|
- uses: actions/checkout@v3
|
||||||
|
with:
|
||||||
|
fetch-depth: 0
|
||||||
|
lfs: true
|
||||||
|
- name: Set up Python
|
||||||
|
uses: actions/setup-python@v4
|
||||||
|
with:
|
||||||
|
python-version: 3.9
|
||||||
|
- name: Install lancedb
|
||||||
|
run: |
|
||||||
|
pip install "pydantic<2"
|
||||||
|
pip install -e .[tests]
|
||||||
|
pip install tantivy@git+https://github.com/quickwit-oss/tantivy-py#164adc87e1a033117001cf70e38c82a53014d985
|
||||||
|
pip install pytest pytest-mock black isort
|
||||||
|
- name: Black
|
||||||
|
run: black --check --diff --no-color --quiet .
|
||||||
|
- name: isort
|
||||||
|
run: isort --check --diff --quiet .
|
||||||
|
- name: Run tests
|
||||||
|
run: pytest -m "not slow" -x -v --durations=30 tests
|
||||||
|
- name: doctest
|
||||||
|
run: pytest --doctest-modules lancedb
|
||||||
26
.github/workflows/trigger-vectordb-recipes.yml
vendored
Normal file
26
.github/workflows/trigger-vectordb-recipes.yml
vendored
Normal file
@@ -0,0 +1,26 @@
|
|||||||
|
name: Trigger vectordb-recipers workflow
|
||||||
|
on:
|
||||||
|
push:
|
||||||
|
branches: [ main ]
|
||||||
|
pull_request:
|
||||||
|
paths:
|
||||||
|
- .github/workflows/trigger-vectordb-recipes.yml
|
||||||
|
workflow_dispatch:
|
||||||
|
|
||||||
|
jobs:
|
||||||
|
build:
|
||||||
|
runs-on: ubuntu-latest
|
||||||
|
|
||||||
|
steps:
|
||||||
|
- name: Trigger vectordb-recipes workflow
|
||||||
|
uses: actions/github-script@v6
|
||||||
|
with:
|
||||||
|
github-token: ${{ secrets.VECTORDB_RECIPES_ACTION_TOKEN }}
|
||||||
|
script: |
|
||||||
|
const result = await github.rest.actions.createWorkflowDispatch({
|
||||||
|
owner: 'lancedb',
|
||||||
|
repo: 'vectordb-recipes',
|
||||||
|
workflow_id: 'examples-test.yml',
|
||||||
|
ref: 'main'
|
||||||
|
});
|
||||||
|
console.log(result);
|
||||||
33
.github/workflows/update_package_lock/action.yml
vendored
Normal file
33
.github/workflows/update_package_lock/action.yml
vendored
Normal file
@@ -0,0 +1,33 @@
|
|||||||
|
name: update_package_lock
|
||||||
|
description: "Update node's package.lock"
|
||||||
|
|
||||||
|
inputs:
|
||||||
|
github_token:
|
||||||
|
required: true
|
||||||
|
description: "github token for the repo"
|
||||||
|
|
||||||
|
runs:
|
||||||
|
using: "composite"
|
||||||
|
steps:
|
||||||
|
- uses: actions/setup-node@v3
|
||||||
|
with:
|
||||||
|
node-version: 20
|
||||||
|
- name: Set git configs
|
||||||
|
shell: bash
|
||||||
|
run: |
|
||||||
|
git config user.name 'Lance Release'
|
||||||
|
git config user.email 'lance-dev@lancedb.com'
|
||||||
|
- name: Update package-lock.json file
|
||||||
|
working-directory: ./node
|
||||||
|
run: |
|
||||||
|
npm install
|
||||||
|
git add package-lock.json
|
||||||
|
git commit -m "Updating package-lock.json"
|
||||||
|
shell: bash
|
||||||
|
- name: Push changes
|
||||||
|
if: ${{ inputs.dry_run }} == "false"
|
||||||
|
uses: ad-m/github-push-action@master
|
||||||
|
with:
|
||||||
|
github_token: ${{ inputs.github_token }}
|
||||||
|
branch: main
|
||||||
|
tags: true
|
||||||
19
.github/workflows/update_package_lock_run.yml
vendored
Normal file
19
.github/workflows/update_package_lock_run.yml
vendored
Normal file
@@ -0,0 +1,19 @@
|
|||||||
|
name: Update package-lock.json
|
||||||
|
|
||||||
|
on:
|
||||||
|
workflow_dispatch:
|
||||||
|
|
||||||
|
jobs:
|
||||||
|
publish:
|
||||||
|
runs-on: ubuntu-latest
|
||||||
|
steps:
|
||||||
|
- name: Checkout
|
||||||
|
uses: actions/checkout@v3
|
||||||
|
with:
|
||||||
|
ref: main
|
||||||
|
persist-credentials: false
|
||||||
|
fetch-depth: 0
|
||||||
|
lfs: true
|
||||||
|
- uses: ./.github/workflows/update_package_lock
|
||||||
|
with:
|
||||||
|
github_token: ${{ secrets.LANCEDB_RELEASE_TOKEN }}
|
||||||
31
Cargo.toml
31
Cargo.toml
@@ -1,16 +1,25 @@
|
|||||||
[workspace]
|
[workspace]
|
||||||
members = [
|
members = ["rust/ffi/node", "rust/vectordb"]
|
||||||
"rust/vectordb",
|
# Python package needs to be built by maturin.
|
||||||
"rust/ffi/node"
|
exclude = ["python"]
|
||||||
]
|
|
||||||
resolver = "2"
|
resolver = "2"
|
||||||
|
|
||||||
[workspace.dependencies]
|
[workspace.dependencies]
|
||||||
lance = "=0.5.8"
|
lance = { "version" = "=0.7.5", "features" = ["dynamodb"] }
|
||||||
arrow-array = "42.0"
|
lance-linalg = { "version" = "=0.7.5" }
|
||||||
arrow-data = "42.0"
|
# Note that this one does not include pyarrow
|
||||||
arrow-schema = "42.0"
|
arrow = { version = "43.0.0", optional = false }
|
||||||
arrow-ipc = "42.0"
|
arrow-array = "43.0"
|
||||||
half = { "version" = "2.2.1", default-features = false }
|
arrow-data = "43.0"
|
||||||
|
arrow-ipc = "43.0"
|
||||||
|
arrow-ord = "43.0"
|
||||||
|
arrow-schema = "43.0"
|
||||||
|
arrow-arith = "43.0"
|
||||||
|
arrow-cast = "43.0"
|
||||||
|
half = { "version" = "=2.2.1", default-features = false, features = [
|
||||||
|
"num-traits"
|
||||||
|
] }
|
||||||
|
log = "0.4"
|
||||||
object_store = "0.6.1"
|
object_store = "0.6.1"
|
||||||
|
snafu = "0.7.4"
|
||||||
|
url = "2"
|
||||||
|
|||||||
83
ci/build_linux_artifacts.sh
Normal file → Executable file
83
ci/build_linux_artifacts.sh
Normal file → Executable file
@@ -1,72 +1,19 @@
|
|||||||
#!/bin/bash
|
#!/bin/bash
|
||||||
# Builds the Linux artifacts (node binaries).
|
|
||||||
# Usage: ./build_linux_artifacts.sh [target]
|
|
||||||
# Targets supported:
|
|
||||||
# - x86_64-unknown-linux-gnu:centos
|
|
||||||
# - aarch64-unknown-linux-gnu:centos
|
|
||||||
# - aarch64-unknown-linux-musl
|
|
||||||
# - x86_64-unknown-linux-musl
|
|
||||||
|
|
||||||
# TODO: refactor this into a Docker container we can pull
|
|
||||||
|
|
||||||
set -e
|
set -e
|
||||||
|
ARCH=${1:-x86_64}
|
||||||
|
|
||||||
setup_dependencies() {
|
# We pass down the current user so that when we later mount the local files
|
||||||
echo "Installing system dependencies..."
|
# into the container, the files are accessible by the current user.
|
||||||
if [[ $1 == *musl ]]; then
|
pushd ci/manylinux_node
|
||||||
# musllinux
|
docker build \
|
||||||
apk add openssl-dev
|
-t lancedb-node-manylinux \
|
||||||
else
|
--build-arg="ARCH=$ARCH" \
|
||||||
# rust / debian
|
--build-arg="DOCKER_USER=$(id -u)" \
|
||||||
apt update
|
--progress=plain \
|
||||||
apt install -y libssl-dev protobuf-compiler
|
.
|
||||||
fi
|
popd
|
||||||
}
|
|
||||||
|
|
||||||
install_node() {
|
docker run \
|
||||||
echo "Installing node..."
|
-v $(pwd):/io -w /io \
|
||||||
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.34.0/install.sh | bash
|
lancedb-node-manylinux \
|
||||||
source "$HOME"/.bashrc
|
bash ci/manylinux_node/build.sh $ARCH
|
||||||
|
|
||||||
if [[ $1 == *musl ]]; then
|
|
||||||
# This node version is 15, we need 16 or higher:
|
|
||||||
# apk add nodejs-current npm
|
|
||||||
# So instead we install from source (nvm doesn't provide binaries for musl):
|
|
||||||
nvm install -s --no-progress 17
|
|
||||||
else
|
|
||||||
nvm install --no-progress 17 # latest that supports glibc 2.17
|
|
||||||
fi
|
|
||||||
}
|
|
||||||
|
|
||||||
build_node_binary() {
|
|
||||||
echo "Building node library for $1..."
|
|
||||||
pushd node
|
|
||||||
|
|
||||||
npm ci
|
|
||||||
|
|
||||||
if [[ $1 == *musl ]]; then
|
|
||||||
# This is needed for cargo to allow build cdylibs with musl
|
|
||||||
export RUSTFLAGS="-C target-feature=-crt-static"
|
|
||||||
fi
|
|
||||||
|
|
||||||
# Cargo can run out of memory while pulling dependencies, especially when running
|
|
||||||
# in QEMU. This is a workaround for that.
|
|
||||||
export CARGO_NET_GIT_FETCH_WITH_CLI=true
|
|
||||||
|
|
||||||
# We don't pass in target, since the native target here already matches
|
|
||||||
# We need to pass OPENSSL_LIB_DIR and OPENSSL_INCLUDE_DIR for static build to work https://github.com/sfackler/rust-openssl/issues/877
|
|
||||||
OPENSSL_STATIC=1 OPENSSL_LIB_DIR=/usr/lib/x86_64-linux-gnu OPENSSL_INCLUDE_DIR=/usr/include/openssl/ npm run build-release
|
|
||||||
npm run pack-build
|
|
||||||
|
|
||||||
popd
|
|
||||||
}
|
|
||||||
|
|
||||||
TARGET=${1:-x86_64-unknown-linux-gnu}
|
|
||||||
# Others:
|
|
||||||
# aarch64-unknown-linux-gnu
|
|
||||||
# x86_64-unknown-linux-musl
|
|
||||||
# aarch64-unknown-linux-musl
|
|
||||||
|
|
||||||
setup_dependencies $TARGET
|
|
||||||
install_node $TARGET
|
|
||||||
build_node_binary $TARGET
|
|
||||||
|
|||||||
31
ci/manylinux_node/Dockerfile
Normal file
31
ci/manylinux_node/Dockerfile
Normal file
@@ -0,0 +1,31 @@
|
|||||||
|
# Many linux dockerfile with Rust, Node, and Lance dependencies installed.
|
||||||
|
# This container allows building the node modules native libraries in an
|
||||||
|
# environment with a very old glibc, so that we are compatible with a wide
|
||||||
|
# range of linux distributions.
|
||||||
|
ARG ARCH=x86_64
|
||||||
|
|
||||||
|
FROM quay.io/pypa/manylinux2014_${ARCH}
|
||||||
|
|
||||||
|
ARG ARCH=x86_64
|
||||||
|
ARG DOCKER_USER=default_user
|
||||||
|
|
||||||
|
# Install static openssl
|
||||||
|
COPY install_openssl.sh install_openssl.sh
|
||||||
|
RUN ./install_openssl.sh ${ARCH} > /dev/null
|
||||||
|
|
||||||
|
# Protobuf is also installed as root.
|
||||||
|
COPY install_protobuf.sh install_protobuf.sh
|
||||||
|
RUN ./install_protobuf.sh ${ARCH}
|
||||||
|
|
||||||
|
ENV DOCKER_USER=${DOCKER_USER}
|
||||||
|
# Create a group and user
|
||||||
|
RUN echo ${ARCH} && adduser --user-group --create-home --uid ${DOCKER_USER} build_user
|
||||||
|
|
||||||
|
# We switch to the user to install Rust and Node, since those like to be
|
||||||
|
# installed at the user level.
|
||||||
|
USER ${DOCKER_USER}
|
||||||
|
|
||||||
|
COPY prepare_manylinux_node.sh prepare_manylinux_node.sh
|
||||||
|
RUN cp /prepare_manylinux_node.sh $HOME/ && \
|
||||||
|
cd $HOME && \
|
||||||
|
./prepare_manylinux_node.sh ${ARCH}
|
||||||
19
ci/manylinux_node/build.sh
Executable file
19
ci/manylinux_node/build.sh
Executable file
@@ -0,0 +1,19 @@
|
|||||||
|
#!/bin/bash
|
||||||
|
# Builds the node module for manylinux. Invoked by ci/build_linux_artifacts.sh.
|
||||||
|
set -e
|
||||||
|
ARCH=${1:-x86_64}
|
||||||
|
|
||||||
|
if [ "$ARCH" = "x86_64" ]; then
|
||||||
|
export OPENSSL_LIB_DIR=/usr/local/lib64/
|
||||||
|
else
|
||||||
|
export OPENSSL_LIB_DIR=/usr/local/lib/
|
||||||
|
fi
|
||||||
|
export OPENSSL_STATIC=1
|
||||||
|
export OPENSSL_INCLUDE_DIR=/usr/local/include/openssl
|
||||||
|
|
||||||
|
source $HOME/.bashrc
|
||||||
|
|
||||||
|
cd node
|
||||||
|
npm ci
|
||||||
|
npm run build-release
|
||||||
|
npm run pack-build
|
||||||
26
ci/manylinux_node/install_openssl.sh
Executable file
26
ci/manylinux_node/install_openssl.sh
Executable file
@@ -0,0 +1,26 @@
|
|||||||
|
#!/bin/bash
|
||||||
|
# Builds openssl from source so we can statically link to it
|
||||||
|
|
||||||
|
# this is to avoid the error we get with the system installation:
|
||||||
|
# /usr/bin/ld: <library>: version node not found for symbol SSLeay@@OPENSSL_1.0.1
|
||||||
|
# /usr/bin/ld: failed to set dynamic section sizes: Bad value
|
||||||
|
set -e
|
||||||
|
|
||||||
|
git clone -b OpenSSL_1_1_1u \
|
||||||
|
--single-branch \
|
||||||
|
https://github.com/openssl/openssl.git
|
||||||
|
|
||||||
|
pushd openssl
|
||||||
|
|
||||||
|
if [[ $1 == x86_64* ]]; then
|
||||||
|
ARCH=linux-x86_64
|
||||||
|
else
|
||||||
|
# gnu target
|
||||||
|
ARCH=linux-aarch64
|
||||||
|
fi
|
||||||
|
|
||||||
|
./Configure no-shared $ARCH
|
||||||
|
|
||||||
|
make
|
||||||
|
|
||||||
|
make install
|
||||||
15
ci/manylinux_node/install_protobuf.sh
Executable file
15
ci/manylinux_node/install_protobuf.sh
Executable file
@@ -0,0 +1,15 @@
|
|||||||
|
#!/bin/bash
|
||||||
|
# Installs protobuf compiler. Should be run as root.
|
||||||
|
set -e
|
||||||
|
|
||||||
|
if [[ $1 == x86_64* ]]; then
|
||||||
|
ARCH=x86_64
|
||||||
|
else
|
||||||
|
# gnu target
|
||||||
|
ARCH=aarch_64
|
||||||
|
fi
|
||||||
|
|
||||||
|
PB_REL=https://github.com/protocolbuffers/protobuf/releases
|
||||||
|
PB_VERSION=23.1
|
||||||
|
curl -LO $PB_REL/download/v$PB_VERSION/protoc-$PB_VERSION-linux-$ARCH.zip
|
||||||
|
unzip protoc-$PB_VERSION-linux-$ARCH.zip -d /usr/local
|
||||||
21
ci/manylinux_node/prepare_manylinux_node.sh
Executable file
21
ci/manylinux_node/prepare_manylinux_node.sh
Executable file
@@ -0,0 +1,21 @@
|
|||||||
|
#!/bin/bash
|
||||||
|
set -e
|
||||||
|
|
||||||
|
install_node() {
|
||||||
|
echo "Installing node..."
|
||||||
|
|
||||||
|
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.34.0/install.sh | bash
|
||||||
|
|
||||||
|
source "$HOME"/.bashrc
|
||||||
|
|
||||||
|
nvm install --no-progress 16
|
||||||
|
}
|
||||||
|
|
||||||
|
install_rust() {
|
||||||
|
echo "Installing rust..."
|
||||||
|
curl https://sh.rustup.rs -sSf | bash -s -- -y
|
||||||
|
export PATH="$PATH:/root/.cargo/bin"
|
||||||
|
}
|
||||||
|
|
||||||
|
install_node
|
||||||
|
install_rust
|
||||||
18
docker-compose.yml
Normal file
18
docker-compose.yml
Normal file
@@ -0,0 +1,18 @@
|
|||||||
|
version: "3.9"
|
||||||
|
services:
|
||||||
|
localstack:
|
||||||
|
image: localstack/localstack:0.14
|
||||||
|
ports:
|
||||||
|
- 4566:4566
|
||||||
|
environment:
|
||||||
|
- SERVICES=s3,dynamodb
|
||||||
|
- DEBUG=1
|
||||||
|
- LS_LOG=trace
|
||||||
|
- DOCKER_HOST=unix:///var/run/docker.sock
|
||||||
|
- AWS_ACCESS_KEY_ID=ACCESSKEY
|
||||||
|
- AWS_SECRET_ACCESS_KEY=SECRETKEY
|
||||||
|
healthcheck:
|
||||||
|
test: [ "CMD", "curl", "-f", "http://localhost:4566/health" ]
|
||||||
|
interval: 5s
|
||||||
|
retries: 3
|
||||||
|
start_period: 10s
|
||||||
@@ -1,5 +1,6 @@
|
|||||||
site_name: LanceDB Docs
|
site_name: LanceDB Docs
|
||||||
repo_url: https://github.com/lancedb/lancedb
|
repo_url: https://github.com/lancedb/lancedb
|
||||||
|
edit_uri: https://github.com/lancedb/lancedb/tree/main/docs/src
|
||||||
repo_name: lancedb/lancedb
|
repo_name: lancedb/lancedb
|
||||||
docs_dir: src
|
docs_dir: src
|
||||||
|
|
||||||
@@ -10,6 +11,16 @@ theme:
|
|||||||
features:
|
features:
|
||||||
- content.code.copy
|
- content.code.copy
|
||||||
- content.tabs.link
|
- content.tabs.link
|
||||||
|
- content.action.edit
|
||||||
|
- toc.follow
|
||||||
|
- toc.integrate
|
||||||
|
- navigation.top
|
||||||
|
- navigation.tabs
|
||||||
|
- navigation.tabs.sticky
|
||||||
|
- navigation.footer
|
||||||
|
- navigation.tracking
|
||||||
|
- navigation.instant
|
||||||
|
- navigation.indexes
|
||||||
icon:
|
icon:
|
||||||
repo: fontawesome/brands/github
|
repo: fontawesome/brands/github
|
||||||
custom_dir: overrides
|
custom_dir: overrides
|
||||||
@@ -53,32 +64,77 @@ markdown_extensions:
|
|||||||
- md_in_html
|
- md_in_html
|
||||||
|
|
||||||
nav:
|
nav:
|
||||||
- Home: index.md
|
- Home:
|
||||||
|
- 🏢 Home: index.md
|
||||||
|
- 💡 Basics: basic.md
|
||||||
|
- 📚 Guides:
|
||||||
|
- Tables: guides/tables.md
|
||||||
|
- Vector Search: search.md
|
||||||
|
- SQL filters: sql.md
|
||||||
|
- Indexing: ann_indexes.md
|
||||||
|
- 🧬 Embeddings: embedding.md
|
||||||
|
- 🔍 Python full-text search: fts.md
|
||||||
|
- 🔌 Integrations:
|
||||||
|
- integrations/index.md
|
||||||
|
- Pandas and PyArrow: python/arrow.md
|
||||||
|
- DuckDB: python/duckdb.md
|
||||||
|
- LangChain 🔗: https://python.langchain.com/en/latest/modules/indexes/vectorstores/examples/lancedb.html
|
||||||
|
- LangChain JS/TS 🔗: https://js.langchain.com/docs/modules/data_connection/vectorstores/integrations/lancedb
|
||||||
|
- LlamaIndex 🦙: https://gpt-index.readthedocs.io/en/latest/examples/vector_stores/LanceDBIndexDemo.html
|
||||||
|
- Pydantic: python/pydantic.md
|
||||||
|
- Voxel51: integrations/voxel51.md
|
||||||
|
- PromptTools: integrations/prompttools.md
|
||||||
|
- 🐍 Python examples:
|
||||||
|
- examples/index.md
|
||||||
|
- YouTube Transcript Search: notebooks/youtube_transcript_search.ipynb
|
||||||
|
- Documentation QA Bot using LangChain: notebooks/code_qa_bot.ipynb
|
||||||
|
- Multimodal search using CLIP: notebooks/multimodal_search.ipynb
|
||||||
|
- Serverless QA Bot with S3 and Lambda: examples/serverless_lancedb_with_s3_and_lambda.md
|
||||||
|
- Serverless QA Bot with Modal: examples/serverless_qa_bot_with_modal_and_langchain.md
|
||||||
|
- 🌐 Javascript examples:
|
||||||
|
- Examples: examples/index_js.md
|
||||||
|
- Serverless Website Chatbot: examples/serverless_website_chatbot.md
|
||||||
|
- YouTube Transcript Search: examples/youtube_transcript_bot_with_nodejs.md
|
||||||
|
- TransformersJS Embedding Search: examples/transformerjs_embedding_search_nodejs.md
|
||||||
- Basics: basic.md
|
- Basics: basic.md
|
||||||
|
- Guides:
|
||||||
|
- Tables: guides/tables.md
|
||||||
|
- Vector Search: search.md
|
||||||
|
- SQL filters: sql.md
|
||||||
|
- Indexing: ann_indexes.md
|
||||||
- Embeddings: embedding.md
|
- Embeddings: embedding.md
|
||||||
- Python full-text search: fts.md
|
- Python full-text search: fts.md
|
||||||
- Python integrations:
|
- Integrations:
|
||||||
|
- integrations/index.md
|
||||||
- Pandas and PyArrow: python/arrow.md
|
- Pandas and PyArrow: python/arrow.md
|
||||||
- DuckDB: python/duckdb.md
|
- DuckDB: python/duckdb.md
|
||||||
- LangChain 🦜️🔗: https://python.langchain.com/en/latest/modules/indexes/vectorstores/examples/lancedb.html
|
- LangChain 🦜️🔗: https://python.langchain.com/en/latest/modules/indexes/vectorstores/examples/lancedb.html
|
||||||
|
- LangChain JS/TS 🦜️🔗: https://js.langchain.com/docs/modules/data_connection/vectorstores/integrations/lancedb
|
||||||
- LlamaIndex 🦙: https://gpt-index.readthedocs.io/en/latest/examples/vector_stores/LanceDBIndexDemo.html
|
- LlamaIndex 🦙: https://gpt-index.readthedocs.io/en/latest/examples/vector_stores/LanceDBIndexDemo.html
|
||||||
- Pydantic: python/pydantic.md
|
- Pydantic: python/pydantic.md
|
||||||
|
- Voxel51: integrations/voxel51.md
|
||||||
|
- PromptTools: integrations/prompttools.md
|
||||||
- Python examples:
|
- Python examples:
|
||||||
|
- examples/index.md
|
||||||
- YouTube Transcript Search: notebooks/youtube_transcript_search.ipynb
|
- YouTube Transcript Search: notebooks/youtube_transcript_search.ipynb
|
||||||
- Documentation QA Bot using LangChain: notebooks/code_qa_bot.ipynb
|
- Documentation QA Bot using LangChain: notebooks/code_qa_bot.ipynb
|
||||||
- Multimodal search using CLIP: notebooks/multimodal_search.ipynb
|
- Multimodal search using CLIP: notebooks/multimodal_search.ipynb
|
||||||
- Serverless QA Bot with S3 and Lambda: examples/serverless_lancedb_with_s3_and_lambda.md
|
- Serverless QA Bot with S3 and Lambda: examples/serverless_lancedb_with_s3_and_lambda.md
|
||||||
- Serverless QA Bot with Modal: examples/serverless_qa_bot_with_modal_and_langchain.md
|
- Serverless QA Bot with Modal: examples/serverless_qa_bot_with_modal_and_langchain.md
|
||||||
- Javascript examples:
|
- Javascript examples:
|
||||||
|
- examples/index_js.md
|
||||||
- YouTube Transcript Search: examples/youtube_transcript_bot_with_nodejs.md
|
- YouTube Transcript Search: examples/youtube_transcript_bot_with_nodejs.md
|
||||||
|
- Serverless Chatbot from any website: examples/serverless_website_chatbot.md
|
||||||
- TransformersJS Embedding Search: examples/transformerjs_embedding_search_nodejs.md
|
- TransformersJS Embedding Search: examples/transformerjs_embedding_search_nodejs.md
|
||||||
- References:
|
|
||||||
- Vector Search: search.md
|
|
||||||
- SQL filters: sql.md
|
|
||||||
- Indexing: ann_indexes.md
|
|
||||||
- API references:
|
- API references:
|
||||||
- Python API: python/python.md
|
- Python API: python/python.md
|
||||||
- Javascript API: javascript/modules.md
|
- Javascript API: javascript/modules.md
|
||||||
|
- LanceDB Cloud↗: https://noteforms.com/forms/lancedb-mailing-list-cloud-kty1o5?notionforms=1&utm_source=notionforms
|
||||||
|
|
||||||
extra_css:
|
extra_css:
|
||||||
- styles/global.css
|
- styles/global.css
|
||||||
|
|
||||||
|
extra:
|
||||||
|
analytics:
|
||||||
|
provider: google
|
||||||
|
property: G-B7NFM40W74
|
||||||
|
|||||||
@@ -94,7 +94,7 @@ There are a couple of parameters that can be used to fine-tune the search:
|
|||||||
.to_df()
|
.to_df()
|
||||||
```
|
```
|
||||||
```
|
```
|
||||||
vector item score
|
vector item _distance
|
||||||
0 [0.44949695, 0.8444449, 0.06281311, 0.23338133... item 1141 103.575333
|
0 [0.44949695, 0.8444449, 0.06281311, 0.23338133... item 1141 103.575333
|
||||||
1 [0.48587373, 0.269207, 0.15095535, 0.65531915,... item 3953 108.393867
|
1 [0.48587373, 0.269207, 0.15095535, 0.65531915,... item 3953 108.393867
|
||||||
```
|
```
|
||||||
@@ -109,9 +109,8 @@ There are a couple of parameters that can be used to fine-tune the search:
|
|||||||
.execute()
|
.execute()
|
||||||
```
|
```
|
||||||
|
|
||||||
The search will return the data requested in addition to the score of each item.
|
The search will return the data requested in addition to the distance of each item.
|
||||||
|
|
||||||
**Note:** The score is the distance between the query vector and the element. A lower number means that the result is more relevant.
|
|
||||||
|
|
||||||
### Filtering (where clause)
|
### Filtering (where clause)
|
||||||
|
|
||||||
@@ -139,7 +138,7 @@ You can select the columns returned by the query using a select clause.
|
|||||||
tbl.search(np.random.random((1536))).select(["vector"]).to_df()
|
tbl.search(np.random.random((1536))).select(["vector"]).to_df()
|
||||||
```
|
```
|
||||||
```
|
```
|
||||||
vector score
|
vector _distance
|
||||||
0 [0.30928212, 0.022668175, 0.1756372, 0.4911822... 93.971092
|
0 [0.30928212, 0.022668175, 0.1756372, 0.4911822... 93.971092
|
||||||
1 [0.2525465, 0.01723831, 0.261568, 0.002007689,... 95.173485
|
1 [0.2525465, 0.01723831, 0.261568, 0.002007689,... 95.173485
|
||||||
...
|
...
|
||||||
|
|||||||
BIN
docs/src/assets/ecosystem-illustration.png
Normal file
BIN
docs/src/assets/ecosystem-illustration.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 104 KiB |
BIN
docs/src/assets/langchain.png
Normal file
BIN
docs/src/assets/langchain.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 170 KiB |
BIN
docs/src/assets/llama-index.jpg
Normal file
BIN
docs/src/assets/llama-index.jpg
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 4.9 KiB |
BIN
docs/src/assets/prompttools.jpeg
Normal file
BIN
docs/src/assets/prompttools.jpeg
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 1.7 MiB |
BIN
docs/src/assets/vercel-template.gif
Normal file
BIN
docs/src/assets/vercel-template.gif
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 205 KiB |
BIN
docs/src/assets/voxel.gif
Normal file
BIN
docs/src/assets/voxel.gif
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 953 KiB |
@@ -79,6 +79,18 @@ We'll cover the basics of using LanceDB on your local machine in this section.
|
|||||||
|
|
||||||
??? info "Under the hood, LanceDB is converting the input data into an Apache Arrow table and persisting it to disk in [Lance format](https://www.github.com/lancedb/lance)."
|
??? info "Under the hood, LanceDB is converting the input data into an Apache Arrow table and persisting it to disk in [Lance format](https://www.github.com/lancedb/lance)."
|
||||||
|
|
||||||
|
### Creating an empty table
|
||||||
|
|
||||||
|
Sometimes you may not have the data to insert into the table at creation time.
|
||||||
|
In this case, you can create an empty table and specify the schema.
|
||||||
|
|
||||||
|
=== "Python"
|
||||||
|
```python
|
||||||
|
import pyarrow as pa
|
||||||
|
schema = pa.schema([pa.field("vector", pa.list_(pa.float32(), list_size=2))])
|
||||||
|
tbl = db.create_table("empty_table", schema=schema)
|
||||||
|
```
|
||||||
|
|
||||||
## How to open an existing table
|
## How to open an existing table
|
||||||
|
|
||||||
Once created, you can open a table using the following code:
|
Once created, you can open a table using the following code:
|
||||||
@@ -122,6 +134,22 @@ After a table has been created, you can always add more data to it using
|
|||||||
{vector: [9.5, 56.2], item: "buzz", price: 200.0}])
|
{vector: [9.5, 56.2], item: "buzz", price: 200.0}])
|
||||||
```
|
```
|
||||||
|
|
||||||
|
## How to search for (approximate) nearest neighbors
|
||||||
|
|
||||||
|
Once you've embedded the query, you can find its nearest neighbors using the following code:
|
||||||
|
|
||||||
|
=== "Python"
|
||||||
|
```python
|
||||||
|
tbl.search([100, 100]).limit(2).to_df()
|
||||||
|
```
|
||||||
|
|
||||||
|
This returns a pandas DataFrame with the results.
|
||||||
|
|
||||||
|
=== "Javascript"
|
||||||
|
```javascript
|
||||||
|
const query = await tbl.search([100, 100]).limit(2).execute();
|
||||||
|
```
|
||||||
|
|
||||||
## How to delete rows from a table
|
## How to delete rows from a table
|
||||||
|
|
||||||
Use the `delete()` method on tables to delete rows from a table. To choose
|
Use the `delete()` method on tables to delete rows from a table. To choose
|
||||||
@@ -151,24 +179,34 @@ To see what expressions are supported, see the [SQL filters](sql.md) section.
|
|||||||
|
|
||||||
Read more: [vectordb.Table.delete](javascript/interfaces/Table.md#delete)
|
Read more: [vectordb.Table.delete](javascript/interfaces/Table.md#delete)
|
||||||
|
|
||||||
## How to search for (approximate) nearest neighbors
|
## How to remove a table
|
||||||
|
|
||||||
Once you've embedded the query, you can find its nearest neighbors using the following code:
|
Use the `drop_table()` method on the database to remove a table.
|
||||||
|
|
||||||
=== "Python"
|
=== "Python"
|
||||||
```python
|
```python
|
||||||
tbl.search([100, 100]).limit(2).to_df()
|
db.drop_table("my_table")
|
||||||
```
|
```
|
||||||
|
|
||||||
This returns a pandas DataFrame with the results.
|
This permanently removes the table and is not recoverable, unlike deleting rows.
|
||||||
|
By default, if the table does not exist an exception is raised. To suppress this,
|
||||||
|
you can pass in `ignore_missing=True`.
|
||||||
|
|
||||||
=== "Javascript"
|
|
||||||
```javascript
|
|
||||||
const query = await tbl.search([100, 100]).limit(2).execute();
|
|
||||||
```
|
|
||||||
|
|
||||||
## What's next
|
## What's next
|
||||||
|
|
||||||
This section covered the very basics of the LanceDB API.
|
This section covered the very basics of the LanceDB API.
|
||||||
LanceDB supports many additional features when creating indices to speed up search and options for search.
|
LanceDB supports many additional features when creating indices to speed up search and options for search.
|
||||||
These are contained in the next section of the documentation.
|
These are contained in the next section of the documentation.
|
||||||
|
|
||||||
|
## Note: Bundling vectorDB apps with webpack
|
||||||
|
Since LanceDB contains a prebuilt Node binary, you must configure `next.config.js` to exclude it from webpack. This is required for both using Next.js and deploying on Vercel.
|
||||||
|
```javascript
|
||||||
|
/** @type {import('next').NextConfig} */
|
||||||
|
module.exports = ({
|
||||||
|
webpack(config) {
|
||||||
|
config.externals.push({ vectordb: 'vectordb' })
|
||||||
|
return config;
|
||||||
|
}
|
||||||
|
})
|
||||||
|
```
|
||||||
@@ -66,7 +66,7 @@ You can also use an external API like OpenAI to generate embeddings
|
|||||||
to generate embeddings for each row.
|
to generate embeddings for each row.
|
||||||
|
|
||||||
Say if you have a pandas DataFrame with a `text` column that you want to be embedded,
|
Say if you have a pandas DataFrame with a `text` column that you want to be embedded,
|
||||||
you can use the [with_embeddings](https://lancedb.github.io/lancedb/python/#lancedb.embeddings.with_embeddings)
|
you can use the [with_embeddings](https://lancedb.github.io/lancedb/python/python/#lancedb.embeddings.with_embeddings)
|
||||||
function to generate embeddings and add create a combined pyarrow table:
|
function to generate embeddings and add create a combined pyarrow table:
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
23
docs/src/examples/index.md
Normal file
23
docs/src/examples/index.md
Normal file
@@ -0,0 +1,23 @@
|
|||||||
|
# Examples
|
||||||
|
|
||||||
|
Here are some of the examples, projects and applications using LanceDB python library. Some examples are covered in detail in the next sections. You can find more on [VectorDB Recipes](https://github.com/lancedb/vectordb-recipes)
|
||||||
|
|
||||||
|
| Example | Interactive Envs | Scripts |
|
||||||
|
|-------- | ---------------- | ------ |
|
||||||
|
| | | |
|
||||||
|
| [Youtube transcript search bot](https://github.com/lancedb/vectordb-recipes/tree/main/examples/youtube_bot/) | <a href="https://colab.research.google.com/github/lancedb/vectordb-recipes/blob/main/examples/youtube_bot/main.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a>| [](https://github.com/lancedb/vectordb-recipes/tree/main/examples/youtube_bot/main.py)|
|
||||||
|
| [Langchain: Code Docs QA bot](https://github.com/lancedb/vectordb-recipes/tree/main/examples/Code-Documentation-QA-Bot/) | <a href="https://colab.research.google.com/github/lancedb/vectordb-recipes/blob/main/examples/Code-Documentation-QA-Bot/main.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a>| [](https://github.com/lancedb/vectordb-recipes/tree/main/examples/Code-Documentation-QA-Bot/main.py) |
|
||||||
|
| [AI Agents: Reducing Hallucination](https://github.com/lancedb/vectordb-recipes/tree/main/examples/reducing_hallucinations_ai_agents/) | <a href="https://colab.research.google.com/github/lancedb/vectordb-recipes/blob/main/examples/reducing_hallucinations_ai_agents/main.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a>| [](https://github.com/lancedb/vectordb-recipes/tree/main/examples/reducing_hallucinations_ai_agents/main.py)|
|
||||||
|
| [Multimodal CLIP: DiffusionDB](https://github.com/lancedb/vectordb-recipes/tree/main/examples/multimodal_clip/) | <a href="https://colab.research.google.com/github/lancedb/vectordb-recipes/blob/main/examples/multimodal_clip/main.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a>| [](https://github.com/lancedb/vectordb-recipes/tree/main/examples/multimodal_clip/main.py) |
|
||||||
|
| [Multimodal CLIP: Youtube videos](https://github.com/lancedb/vectordb-recipes/tree/main/examples/multimodal_video_search/) | <a href="https://colab.research.google.com/github/lancedb/vectordb-recipes/blob/main/examples/multimodal_video_search/main.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a>| [](https://github.com/lancedb/vectordb-recipes/tree/main/examples/multimodal_video_search/main.py) |
|
||||||
|
| [Movie Recommender](https://github.com/lancedb/vectordb-recipes/tree/main/examples/movie-recommender/) | <a href="https://colab.research.google.com/github/lancedb/vectordb-recipes/blob/main/examples/movie-recommender/main.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a> | [](https://github.com/lancedb/vectordb-recipes/tree/main/examples/movie-recommender/main.py) |
|
||||||
|
| [Audio Search](https://github.com/lancedb/vectordb-recipes/tree/main/examples/audio_search/) | <a href="https://colab.research.google.com/github/lancedb/vectordb-recipes/blob/main/examples/audio_search/main.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a> | [](https://github.com/lancedb/vectordb-recipes/tree/main/examples/audio_search/main.py) |
|
||||||
|
| [Multimodal Image + Text Search](https://github.com/lancedb/vectordb-recipes/tree/main/examples/multimodal_search/) | <a href="https://colab.research.google.com/github/lancedb/vectordb-recipes/blob/main/examples/multimodal_search/main.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a> | [](https://github.com/lancedb/vectordb-recipes/tree/main/examples/multimodal_search/main.py) |
|
||||||
|
| [Evaluating Prompts with Prompttools](https://github.com/lancedb/vectordb-recipes/tree/main/examples/prompttools-eval-prompts/) | <a href="https://colab.research.google.com/github/lancedb/vectordb-recipes/blob/main/examples/prompttools-eval-prompts/main.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a> | |
|
||||||
|
|
||||||
|
## Projects & Applications powered by LanceDB
|
||||||
|
|
||||||
|
| Project Name | Description | Screenshot |
|
||||||
|
|-----------------------------------------------------|----------------------------------------------------------------------------------------------------------------------|-------------------------------------------|
|
||||||
|
| [YOLOExplorer](https://github.com/lancedb/yoloexplorer) | Iterate on your YOLO / CV datasets using SQL, Vector semantic search, and more within seconds | 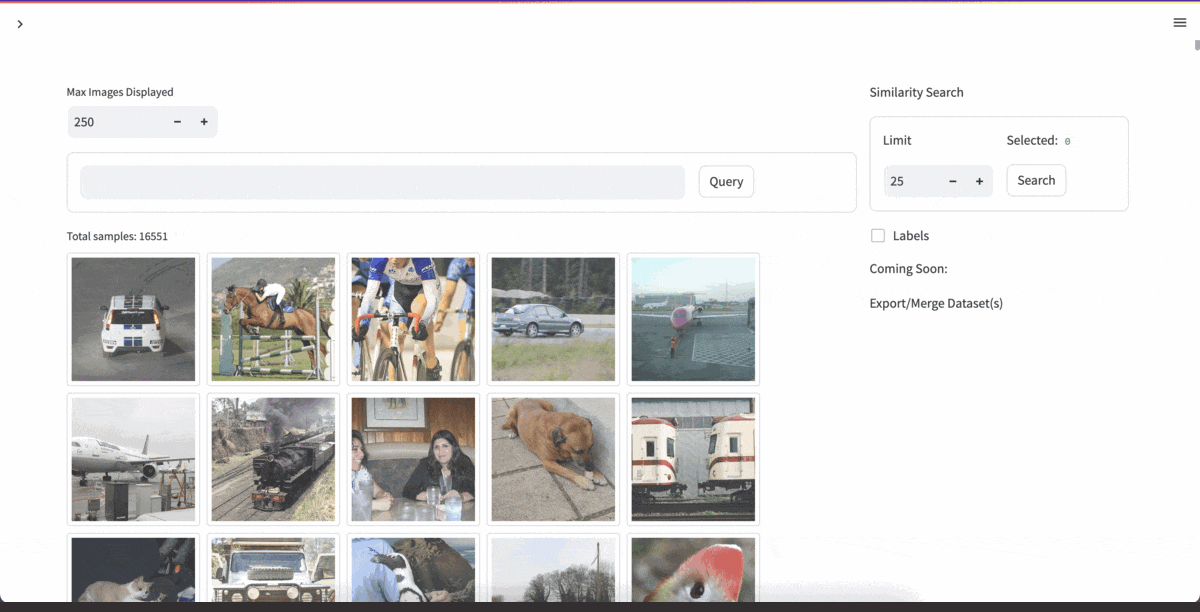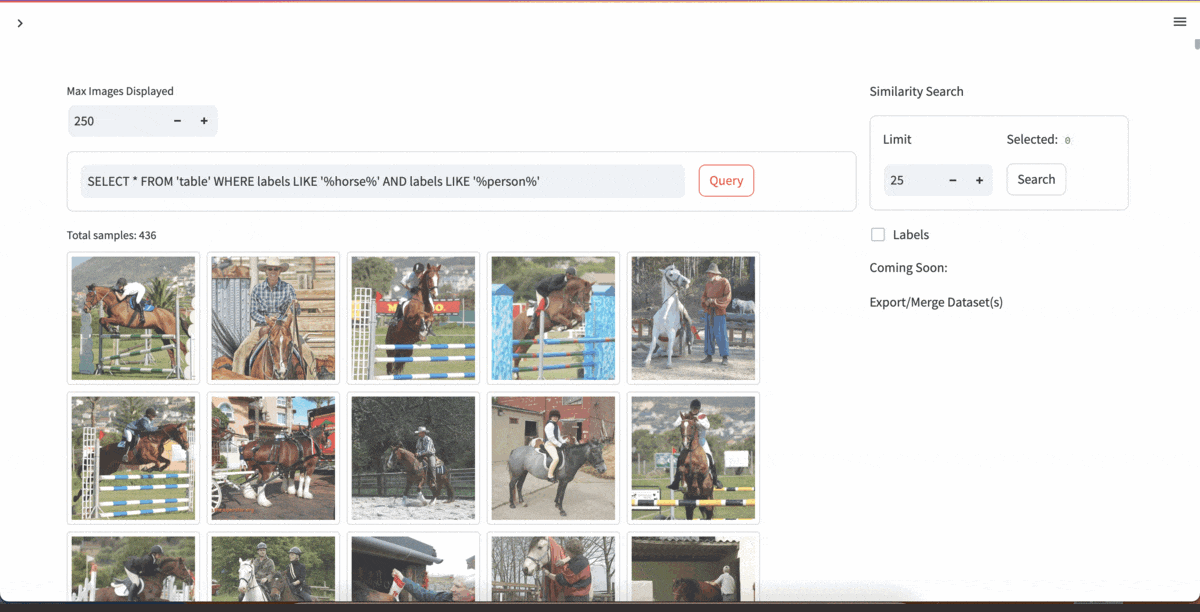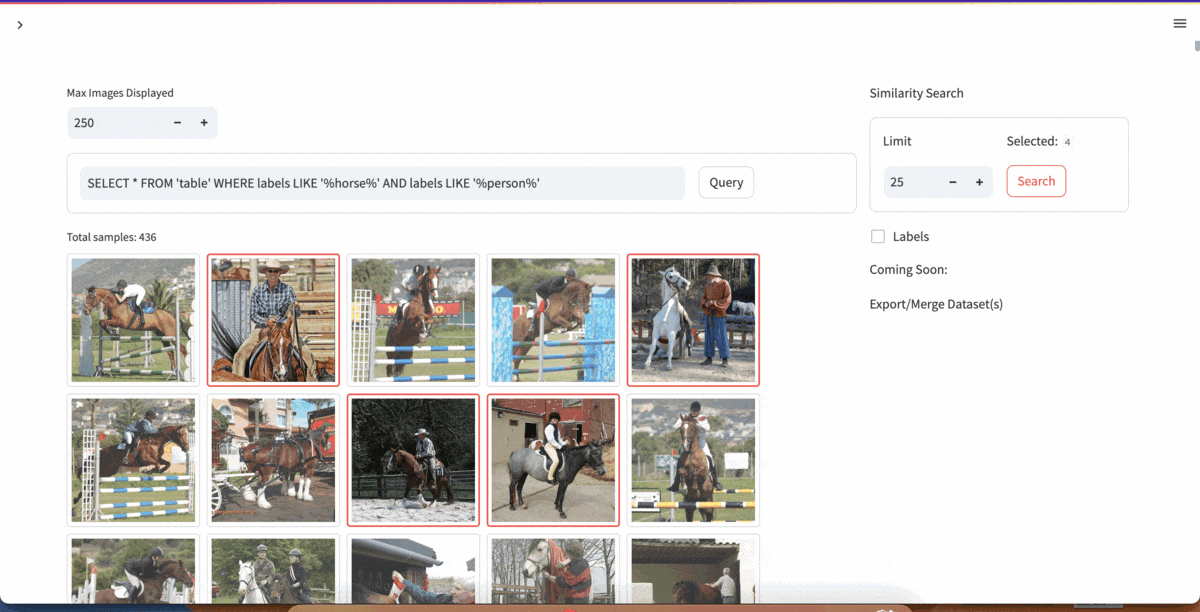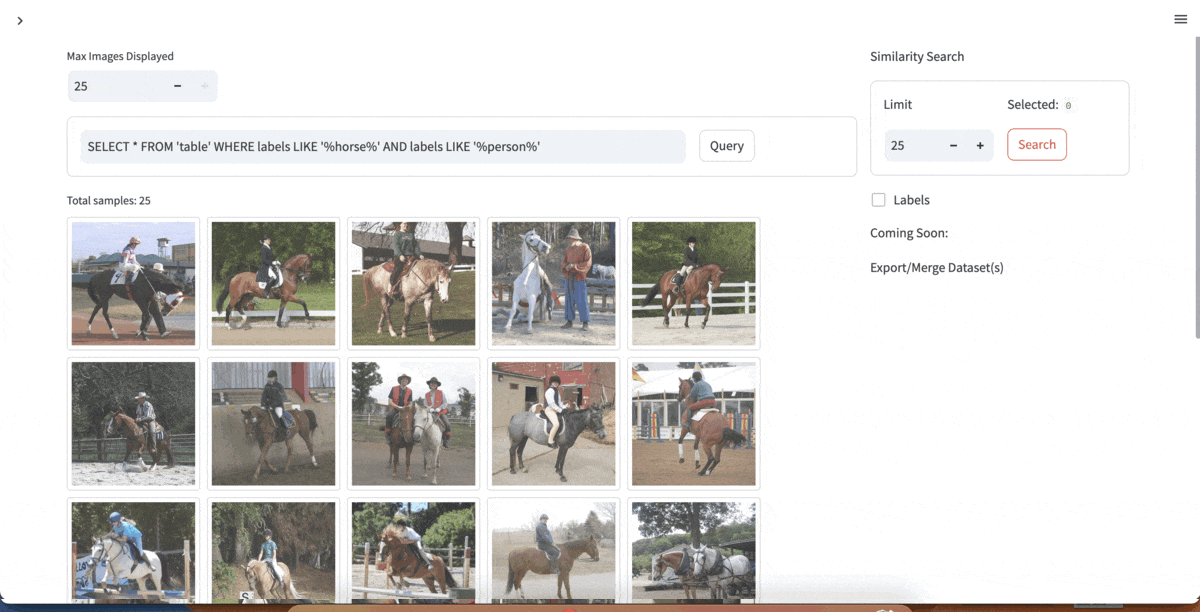 |
|
||||||
|
| [Website Chatbot (Deployable Vercel Template)](https://github.com/lancedb/lancedb-vercel-chatbot) | Create a chatbot from the sitemap of any website/docs of your choice. Built using vectorDB serverless native javascript package. |  |
|
||||||
19
docs/src/examples/index_js.md
Normal file
19
docs/src/examples/index_js.md
Normal file
@@ -0,0 +1,19 @@
|
|||||||
|
# Examples
|
||||||
|
|
||||||
|
Here are some of the examples, projects and applications using vectordb native javascript library.
|
||||||
|
Some examples are covered in detail in the next sections. You can find more on [VectorDB Recipes](https://github.com/lancedb/vectordb-recipes)
|
||||||
|
|
||||||
|
| Example | Scripts |
|
||||||
|
|-------- | ------ |
|
||||||
|
| | |
|
||||||
|
| [Youtube transcript search bot](https://github.com/lancedb/vectordb-recipes/tree/main/examples/youtube_bot/) | [](https://github.com/lancedb/vectordb-recipes/tree/main/examples/youtube_bot/index.js)|
|
||||||
|
| [Langchain: Code Docs QA bot](https://github.com/lancedb/vectordb-recipes/tree/main/examples/Code-Documentation-QA-Bot/) | [](https://github.com/lancedb/vectordb-recipes/tree/main/examples/Code-Documentation-QA-Bot/index.js)|
|
||||||
|
| [AI Agents: Reducing Hallucination](https://github.com/lancedb/vectordb-recipes/tree/main/examples/reducing_hallucinations_ai_agents/) | [](https://github.com/lancedb/vectordb-recipes/tree/main/examples/reducing_hallucinations_ai_agents/index.js)|
|
||||||
|
| [TransformersJS Embedding example](https://github.com/lancedb/vectordb-recipes/tree/main/examples/js-transformers/) | [](https://github.com/lancedb/vectordb-recipes/tree/main/examples/js-transformers/index.js) |
|
||||||
|
|
||||||
|
## Projects & Applications
|
||||||
|
|
||||||
|
| Project Name | Description | Screenshot |
|
||||||
|
|-----------------------------------------------------|----------------------------------------------------------------------------------------------------------------------|-------------------------------------------|
|
||||||
|
| [YOLOExplorer](https://github.com/lancedb/yoloexplorer) | Iterate on your YOLO / CV datasets using SQL, Vector semantic search, and more within seconds |  |
|
||||||
|
| [Website Chatbot (Deployable Vercel Template)](https://github.com/lancedb/lancedb-vercel-chatbot) | Create a chatbot from the sitemap of any website/docs of your choice. Built using vectorDB serverless native javascript package. |  |
|
||||||
61
docs/src/examples/serverless_website_chatbot.md
Normal file
61
docs/src/examples/serverless_website_chatbot.md
Normal file
@@ -0,0 +1,61 @@
|
|||||||
|
# LanceDB Chatbot - Vercel Next.js Template
|
||||||
|
Use an AI chatbot with website context retrieved from a vector store like LanceDB. LanceDB is lightweight and can be embedded directly into Next.js, with data stored on-prem.
|
||||||
|
|
||||||
|
## One click deploy on Vercel
|
||||||
|
[](https://vercel.com/new/clone?repository-url=https%3A%2F%2Fgithub.com%2Flancedb%2Flancedb-vercel-chatbot&env=OPENAI_API_KEY&envDescription=OpenAI%20API%20Key%20for%20chat%20completion.&project-name=lancedb-vercel-chatbot&repository-name=lancedb-vercel-chatbot&demo-title=LanceDB%20Chatbot%20Demo&demo-description=Demo%20website%20chatbot%20with%20LanceDB.&demo-url=https%3A%2F%2Flancedb.vercel.app&demo-image=https%3A%2F%2Fi.imgur.com%2FazVJtvr.png)
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## Development
|
||||||
|
|
||||||
|
First, rename `.env.example` to `.env.local`, and fill out `OPENAI_API_KEY` with your OpenAI API key. You can get one [here](https://openai.com/blog/openai-api).
|
||||||
|
|
||||||
|
Run the development server:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
npm run dev
|
||||||
|
# or
|
||||||
|
yarn dev
|
||||||
|
# or
|
||||||
|
pnpm dev
|
||||||
|
```
|
||||||
|
|
||||||
|
Open [http://localhost:3000](http://localhost:3000) with your browser to see the result.
|
||||||
|
|
||||||
|
This project uses [`next/font`](https://nextjs.org/docs/basic-features/font-optimization) to automatically optimize and load Inter, a custom Google Font.
|
||||||
|
|
||||||
|
## Learn More
|
||||||
|
|
||||||
|
To learn more about LanceDB or Next.js, take a look at the following resources:
|
||||||
|
|
||||||
|
- [LanceDB Documentation](https://lancedb.github.io/lancedb/) - learn about LanceDB, the developer-friendly serverless vector database.
|
||||||
|
- [Next.js Documentation](https://nextjs.org/docs) - learn about Next.js features and API.
|
||||||
|
- [Learn Next.js](https://nextjs.org/learn) - an interactive Next.js tutorial.
|
||||||
|
|
||||||
|
## LanceDB on Next.js and Vercel
|
||||||
|
|
||||||
|
FYI: these configurations have been pre-implemented in this template.
|
||||||
|
|
||||||
|
Since LanceDB contains a prebuilt Node binary, you must configure `next.config.js` to exclude it from webpack. This is required for both using Next.js and deploying on Vercel.
|
||||||
|
```js
|
||||||
|
/** @type {import('next').NextConfig} */
|
||||||
|
module.exports = ({
|
||||||
|
webpack(config) {
|
||||||
|
config.externals.push({ vectordb: 'vectordb' })
|
||||||
|
return config;
|
||||||
|
}
|
||||||
|
})
|
||||||
|
```
|
||||||
|
|
||||||
|
To deploy on Vercel, we need to make sure that the NodeJS runtime static file analysis for Vercel can find the binary, since LanceDB uses dynamic imports by default. We can do this by modifying `package.json` in the `scripts` section.
|
||||||
|
```json
|
||||||
|
{
|
||||||
|
...
|
||||||
|
"scripts": {
|
||||||
|
...
|
||||||
|
"vercel-build": "sed -i 's/nativeLib = require(`@lancedb\\/vectordb-\\${currentTarget()}`);/nativeLib = require(`@lancedb\\/vectordb-linux-x64-gnu`);/' node_modules/vectordb/native.js && next build",
|
||||||
|
...
|
||||||
|
},
|
||||||
|
...
|
||||||
|
}
|
||||||
|
```
|
||||||
@@ -1,6 +1,6 @@
|
|||||||
# Vector embedding search using TransformersJS
|
# Vector embedding search using TransformersJS
|
||||||
|
|
||||||
## Embed and query data from LacneDB using TransformersJS
|
## Embed and query data from LanceDB using TransformersJS
|
||||||
|
|
||||||
<img id="splash" width="400" alt="transformersjs" src="https://github.com/lancedb/lancedb/assets/43097991/88a31e30-3d6f-4eef-9216-4b7c688f1b4f">
|
<img id="splash" width="400" alt="transformersjs" src="https://github.com/lancedb/lancedb/assets/43097991/88a31e30-3d6f-4eef-9216-4b7c688f1b4f">
|
||||||
|
|
||||||
@@ -99,7 +99,7 @@ Output of `results`:
|
|||||||
id: 5,
|
id: 5,
|
||||||
text: 'Banana',
|
text: 'Banana',
|
||||||
type: 'fruit',
|
type: 'fruit',
|
||||||
score: 0.4919965863227844
|
_distance: 0.4919965863227844
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
vector: Float32Array(384) [
|
vector: Float32Array(384) [
|
||||||
@@ -111,7 +111,7 @@ Output of `results`:
|
|||||||
id: 1,
|
id: 1,
|
||||||
text: 'Cherry',
|
text: 'Cherry',
|
||||||
type: 'fruit',
|
type: 'fruit',
|
||||||
score: 0.5540297031402588
|
_distance: 0.5540297031402588
|
||||||
}
|
}
|
||||||
]
|
]
|
||||||
```
|
```
|
||||||
|
|||||||
@@ -4,4 +4,10 @@
|
|||||||
|
|
||||||
<img id="splash" width="400" alt="youtube transcript search" src="https://user-images.githubusercontent.com/917119/236965568-def7394d-171c-45f2-939d-8edfeaadd88c.png">
|
<img id="splash" width="400" alt="youtube transcript search" src="https://user-images.githubusercontent.com/917119/236965568-def7394d-171c-45f2-939d-8edfeaadd88c.png">
|
||||||
|
|
||||||
|
|
||||||
|
<a href="https://colab.research.google.com/github/lancedb/vectordb-recipes/blob/main/examples/youtube_bot/main.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab">
|
||||||
|
|
||||||
|
Scripts - [](https://github.com/lancedb/vectordb-recipesexamples/youtube_bot/main.py) [](https://github.com/lancedb/vectordb-recipes/examples/youtube_bot/index.js)
|
||||||
|
|
||||||
|
|
||||||
This example is in a [notebook](https://github.com/lancedb/lancedb/blob/main/docs/src/notebooks/youtube_transcript_search.ipynb)
|
This example is in a [notebook](https://github.com/lancedb/lancedb/blob/main/docs/src/notebooks/youtube_transcript_search.ipynb)
|
||||||
|
|||||||
369
docs/src/guides/tables.md
Normal file
369
docs/src/guides/tables.md
Normal file
@@ -0,0 +1,369 @@
|
|||||||
|
<a href="https://colab.research.google.com/github/lancedb/lancedb/blob/main/docs/src/notebooks/tables_guide.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a><br/>
|
||||||
|
A Table is a collection of Records in a LanceDB Database. You can follow along on colab!
|
||||||
|
|
||||||
|
## Creating a LanceDB Table
|
||||||
|
|
||||||
|
=== "Python"
|
||||||
|
### LanceDB Connection
|
||||||
|
|
||||||
|
```python
|
||||||
|
import lancedb
|
||||||
|
db = lancedb.connect("./.lancedb")
|
||||||
|
```
|
||||||
|
|
||||||
|
LanceDB allows ingesting data from various sources - `dict`, `list[dict]`, `pd.DataFrame`, `pa.Table` or a `Iterator[pa.RecordBatch]`. Let's take a look at some of the these.
|
||||||
|
|
||||||
|
### From list of tuples or dictionaries
|
||||||
|
|
||||||
|
```python
|
||||||
|
import lancedb
|
||||||
|
|
||||||
|
db = lancedb.connect("./.lancedb")
|
||||||
|
|
||||||
|
data = [{"vector": [1.1, 1.2], "lat": 45.5, "long": -122.7},
|
||||||
|
{"vector": [0.2, 1.8], "lat": 40.1, "long": -74.1}]
|
||||||
|
|
||||||
|
db.create_table("my_table", data)
|
||||||
|
|
||||||
|
db["my_table"].head()
|
||||||
|
```
|
||||||
|
|
||||||
|
!!! info "Note"
|
||||||
|
If the table already exists, LanceDB will raise an error by default. If you want to overwrite the table, you can pass in mode="overwrite" to the createTable function.
|
||||||
|
|
||||||
|
```python
|
||||||
|
db.create_table("name", data, mode="overwrite")
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
### From pandas DataFrame
|
||||||
|
|
||||||
|
```python
|
||||||
|
import pandas as pd
|
||||||
|
|
||||||
|
data = pd.DataFrame({
|
||||||
|
"vector": [[1.1, 1.2], [0.2, 1.8]],
|
||||||
|
"lat": [45.5, 40.1],
|
||||||
|
"long": [-122.7, -74.1]
|
||||||
|
})
|
||||||
|
|
||||||
|
db.create_table("table2", data)
|
||||||
|
|
||||||
|
db["table2"].head()
|
||||||
|
```
|
||||||
|
!!! info "Note"
|
||||||
|
Data is converted to Arrow before being written to disk. For maximum control over how data is saved, either provide the PyArrow schema to convert to or else provide a PyArrow Table directly.
|
||||||
|
|
||||||
|
```python
|
||||||
|
custom_schema = pa.schema([
|
||||||
|
pa.field("vector", pa.list_(pa.float32(), 2)),
|
||||||
|
pa.field("lat", pa.float32()),
|
||||||
|
pa.field("long", pa.float32())
|
||||||
|
])
|
||||||
|
|
||||||
|
table = db.create_table("table3", data, schema=custom_schema)
|
||||||
|
```
|
||||||
|
|
||||||
|
### From PyArrow Tables
|
||||||
|
You can also create LanceDB tables directly from pyarrow tables
|
||||||
|
|
||||||
|
```python
|
||||||
|
table = pa.Table.from_arrays(
|
||||||
|
[
|
||||||
|
pa.array([[3.1, 4.1], [5.9, 26.5]],
|
||||||
|
pa.list_(pa.float32(), 2)),
|
||||||
|
pa.array(["foo", "bar"]),
|
||||||
|
pa.array([10.0, 20.0]),
|
||||||
|
],
|
||||||
|
["vector", "item", "price"],
|
||||||
|
)
|
||||||
|
|
||||||
|
db = lancedb.connect("db")
|
||||||
|
|
||||||
|
tbl = db.create_table("test1", table)
|
||||||
|
```
|
||||||
|
|
||||||
|
### From Pydantic Models
|
||||||
|
When you create an empty table without data, you must specify the table schema.
|
||||||
|
LanceDB supports creating tables by specifying a pyarrow schema or a specialized
|
||||||
|
pydantic model called `LanceModel`.
|
||||||
|
|
||||||
|
For example, the following Content model specifies a table with 5 columns:
|
||||||
|
movie_id, vector, genres, title, and imdb_id. When you create a table, you can
|
||||||
|
pass the class as the value of the `schema` parameter to `create_table`.
|
||||||
|
The `vector` column is a `Vector` type, which is a specialized pydantic type that
|
||||||
|
can be configured with the vector dimensions. It is also important to note that
|
||||||
|
LanceDB only understands subclasses of `lancedb.pydantic.LanceModel`
|
||||||
|
(which itself derives from `pydantic.BaseModel`).
|
||||||
|
|
||||||
|
```python
|
||||||
|
from lancedb.pydantic import Vector, LanceModel
|
||||||
|
|
||||||
|
class Content(LanceModel):
|
||||||
|
movie_id: int
|
||||||
|
vector: Vector(128)
|
||||||
|
genres: str
|
||||||
|
title: str
|
||||||
|
imdb_id: int
|
||||||
|
|
||||||
|
@property
|
||||||
|
def imdb_url(self) -> str:
|
||||||
|
return f"https://www.imdb.com/title/tt{self.imdb_id}"
|
||||||
|
|
||||||
|
import pyarrow as pa
|
||||||
|
db = lancedb.connect("~/.lancedb")
|
||||||
|
table_name = "movielens_small"
|
||||||
|
table = db.create_table(table_name, schema=Content)
|
||||||
|
```
|
||||||
|
|
||||||
|
### Using Iterators / Writing Large Datasets
|
||||||
|
|
||||||
|
It is recommended to use itertators to add large datasets in batches when creating your table in one go. This does not create multiple versions of your dataset unlike manually adding batches using `table.add()`
|
||||||
|
|
||||||
|
LanceDB additionally supports pyarrow's `RecordBatch` Iterators or other generators producing supported data types.
|
||||||
|
|
||||||
|
Here's an example using using `RecordBatch` iterator for creating tables.
|
||||||
|
|
||||||
|
```python
|
||||||
|
import pyarrow as pa
|
||||||
|
|
||||||
|
def make_batches():
|
||||||
|
for i in range(5):
|
||||||
|
yield pa.RecordBatch.from_arrays(
|
||||||
|
[
|
||||||
|
pa.array([[3.1, 4.1], [5.9, 26.5]],
|
||||||
|
pa.list_(pa.float32(), 2)),
|
||||||
|
pa.array(["foo", "bar"]),
|
||||||
|
pa.array([10.0, 20.0]),
|
||||||
|
],
|
||||||
|
["vector", "item", "price"],
|
||||||
|
)
|
||||||
|
|
||||||
|
schema = pa.schema([
|
||||||
|
pa.field("vector", pa.list_(pa.float32(), 2)),
|
||||||
|
pa.field("item", pa.utf8()),
|
||||||
|
pa.field("price", pa.float32()),
|
||||||
|
])
|
||||||
|
|
||||||
|
db.create_table("table4", make_batches(), schema=schema)
|
||||||
|
```
|
||||||
|
|
||||||
|
You can also use iterators of other types like Pandas dataframe or Pylists directly in the above example.
|
||||||
|
|
||||||
|
## Creating Empty Table
|
||||||
|
You can also create empty tables in python. Initialize it with schema and later ingest data into it.
|
||||||
|
|
||||||
|
```python
|
||||||
|
import lancedb
|
||||||
|
import pyarrow as pa
|
||||||
|
|
||||||
|
schema = pa.schema(
|
||||||
|
[
|
||||||
|
pa.field("vector", pa.list_(pa.float32(), 2)),
|
||||||
|
pa.field("item", pa.string()),
|
||||||
|
pa.field("price", pa.float32()),
|
||||||
|
])
|
||||||
|
tbl = db.create_table("table5", schema=schema)
|
||||||
|
data = [
|
||||||
|
{"vector": [3.1, 4.1], "item": "foo", "price": 10.0},
|
||||||
|
{"vector": [5.9, 26.5], "item": "bar", "price": 20.0},
|
||||||
|
]
|
||||||
|
tbl.add(data=data)
|
||||||
|
```
|
||||||
|
|
||||||
|
You can also use Pydantic to specify the schema
|
||||||
|
|
||||||
|
```python
|
||||||
|
import lancedb
|
||||||
|
from lancedb.pydantic import LanceModel, vector
|
||||||
|
|
||||||
|
class Model(LanceModel):
|
||||||
|
vector: Vector(2)
|
||||||
|
|
||||||
|
tbl = db.create_table("table5", schema=Model.to_arrow_schema())
|
||||||
|
```
|
||||||
|
|
||||||
|
=== "Javascript/Typescript"
|
||||||
|
|
||||||
|
### VectorDB Connection
|
||||||
|
|
||||||
|
```javascript
|
||||||
|
const lancedb = require("vectordb");
|
||||||
|
|
||||||
|
const uri = "data/sample-lancedb";
|
||||||
|
const db = await lancedb.connect(uri);
|
||||||
|
```
|
||||||
|
|
||||||
|
### Creating a Table
|
||||||
|
|
||||||
|
You can create a LanceDB table in javascript using an array of records.
|
||||||
|
|
||||||
|
```javascript
|
||||||
|
data
|
||||||
|
const tb = await db.createTable("my_table",
|
||||||
|
data=[{"vector": [3.1, 4.1], "item": "foo", "price": 10.0},
|
||||||
|
{"vector": [5.9, 26.5], "item": "bar", "price": 20.0}])
|
||||||
|
```
|
||||||
|
|
||||||
|
!!! info "Note"
|
||||||
|
If the table already exists, LanceDB will raise an error by default. If you want to overwrite the table, you need to specify the `WriteMode` in the createTable function.
|
||||||
|
|
||||||
|
```javascript
|
||||||
|
const table = await con.createTable(tableName, data, { writeMode: WriteMode.Overwrite })
|
||||||
|
```
|
||||||
|
|
||||||
|
## Open existing tables
|
||||||
|
|
||||||
|
If you forget the name of your table, you can always get a listing of all table names:
|
||||||
|
|
||||||
|
|
||||||
|
=== "Python"
|
||||||
|
### Get a list of existing Tables
|
||||||
|
|
||||||
|
```python
|
||||||
|
print(db.table_names())
|
||||||
|
```
|
||||||
|
=== "Javascript/Typescript"
|
||||||
|
|
||||||
|
```javascript
|
||||||
|
console.log(await db.tableNames());
|
||||||
|
```
|
||||||
|
|
||||||
|
Then, you can open any existing tables
|
||||||
|
|
||||||
|
=== "Python"
|
||||||
|
|
||||||
|
```python
|
||||||
|
tbl = db.open_table("my_table")
|
||||||
|
```
|
||||||
|
=== "Javascript/Typescript"
|
||||||
|
|
||||||
|
```javascript
|
||||||
|
const tbl = await db.openTable("my_table");
|
||||||
|
```
|
||||||
|
|
||||||
|
## Adding to a Table
|
||||||
|
After a table has been created, you can always add more data to it using
|
||||||
|
|
||||||
|
=== "Python"
|
||||||
|
You can add any of the valid data structures accepted by LanceDB table, i.e, `dict`, `list[dict]`, `pd.DataFrame`, or a `Iterator[pa.RecordBatch]`. Here are some examples.
|
||||||
|
|
||||||
|
### Adding Pandas DataFrame
|
||||||
|
|
||||||
|
```python
|
||||||
|
df = pd.DataFrame([{"vector": [1.3, 1.4], "item": "fizz", "price": 100.0},
|
||||||
|
{"vector": [9.5, 56.2], "item": "buzz", "price": 200.0}])
|
||||||
|
tbl.add(df)
|
||||||
|
```
|
||||||
|
|
||||||
|
You can also add a large dataset batch in one go using Iterator of any supported data types.
|
||||||
|
|
||||||
|
### Adding to table using Iterator
|
||||||
|
|
||||||
|
```python
|
||||||
|
import pandas as pd
|
||||||
|
|
||||||
|
def make_batches():
|
||||||
|
for i in range(5):
|
||||||
|
yield pd.DataFrame(
|
||||||
|
{
|
||||||
|
"vector": [[3.1, 4.1], [1, 1]],
|
||||||
|
"item": ["foo", "bar"],
|
||||||
|
"price": [10.0, 20.0],
|
||||||
|
})
|
||||||
|
|
||||||
|
tbl.add(make_batches())
|
||||||
|
```
|
||||||
|
|
||||||
|
The other arguments accepted:
|
||||||
|
|
||||||
|
| Name | Type | Description | Default |
|
||||||
|
|---|---|---|---|
|
||||||
|
| data | DATA | The data to insert into the table. | required |
|
||||||
|
| mode | str | The mode to use when writing the data. Valid values are "append" and "overwrite". | append |
|
||||||
|
| on_bad_vectors | str | What to do if any of the vectors are not the same size or contains NaNs. One of "error", "drop", "fill". | drop |
|
||||||
|
| fill value | float | The value to use when filling vectors: Only used if on_bad_vectors="fill". | 0.0 |
|
||||||
|
|
||||||
|
|
||||||
|
=== "Javascript/Typescript"
|
||||||
|
|
||||||
|
```javascript
|
||||||
|
await tbl.add([{vector: [1.3, 1.4], item: "fizz", price: 100.0},
|
||||||
|
{vector: [9.5, 56.2], item: "buzz", price: 200.0}])
|
||||||
|
```
|
||||||
|
|
||||||
|
## Deleting from a Table
|
||||||
|
|
||||||
|
Use the `delete()` method on tables to delete rows from a table. To choose which rows to delete, provide a filter that matches on the metadata columns. This can delete any number of rows that match the filter.
|
||||||
|
|
||||||
|
=== "Python"
|
||||||
|
|
||||||
|
```python
|
||||||
|
tbl.delete('item = "fizz"')
|
||||||
|
```
|
||||||
|
|
||||||
|
### Deleting row with specific column value
|
||||||
|
|
||||||
|
```python
|
||||||
|
import lancedb
|
||||||
|
import pandas as pd
|
||||||
|
|
||||||
|
data = pd.DataFrame({"x": [1, 2, 3], "vector": [[1, 2], [3, 4], [5, 6]]})
|
||||||
|
db = lancedb.connect("./.lancedb")
|
||||||
|
table = db.create_table("my_table", data)
|
||||||
|
table.to_pandas()
|
||||||
|
# x vector
|
||||||
|
# 0 1 [1.0, 2.0]
|
||||||
|
# 1 2 [3.0, 4.0]
|
||||||
|
# 2 3 [5.0, 6.0]
|
||||||
|
|
||||||
|
table.delete("x = 2")
|
||||||
|
table.to_pandas()
|
||||||
|
# x vector
|
||||||
|
# 0 1 [1.0, 2.0]
|
||||||
|
# 1 3 [5.0, 6.0]
|
||||||
|
```
|
||||||
|
|
||||||
|
### Delete from a list of values
|
||||||
|
|
||||||
|
```python
|
||||||
|
to_remove = [1, 5]
|
||||||
|
to_remove = ", ".join(str(v) for v in to_remove)
|
||||||
|
|
||||||
|
table.delete(f"x IN ({to_remove})")
|
||||||
|
table.to_pandas()
|
||||||
|
# x vector
|
||||||
|
# 0 3 [5.0, 6.0]
|
||||||
|
```
|
||||||
|
|
||||||
|
=== "Javascript/Typescript"
|
||||||
|
|
||||||
|
```javascript
|
||||||
|
await tbl.delete('item = "fizz"')
|
||||||
|
```
|
||||||
|
|
||||||
|
### Deleting row with specific column value
|
||||||
|
|
||||||
|
```javascript
|
||||||
|
const con = await lancedb.connect("./.lancedb")
|
||||||
|
const data = [
|
||||||
|
{id: 1, vector: [1, 2]},
|
||||||
|
{id: 2, vector: [3, 4]},
|
||||||
|
{id: 3, vector: [5, 6]},
|
||||||
|
];
|
||||||
|
const tbl = await con.createTable("my_table", data)
|
||||||
|
await tbl.delete("id = 2")
|
||||||
|
await tbl.countRows() // Returns 2
|
||||||
|
```
|
||||||
|
|
||||||
|
### Delete from a list of values
|
||||||
|
|
||||||
|
```javascript
|
||||||
|
const to_remove = [1, 5];
|
||||||
|
await tbl.delete(`id IN (${to_remove.join(",")})`)
|
||||||
|
await tbl.countRows() // Returns 1
|
||||||
|
```
|
||||||
|
|
||||||
|
## What's Next?
|
||||||
|
|
||||||
|
Learn how to Query your tables and create indices
|
||||||
@@ -1,20 +1,23 @@
|
|||||||
# Welcome to LanceDB's Documentation
|
# LanceDB
|
||||||
|
|
||||||
LanceDB is an open-source database for vector-search built with persistent storage, which greatly simplifies retrevial, filtering and management of embeddings.
|
LanceDB is an open-source database for vector-search built with persistent storage, which greatly simplifies retrieval, filtering and management of embeddings.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
The key features of LanceDB include:
|
The key features of LanceDB include:
|
||||||
|
|
||||||
* Production-scale vector search with no servers to manage.
|
|
||||||
|
|
||||||
* Store, query and filter vectors, metadata and multi-modal data (text, images, videos, point clouds, and more).
|
* Store, query and filter vectors, metadata and multi-modal data (text, images, videos, point clouds, and more).
|
||||||
|
|
||||||
* Support for vector similarity search, full-text search and SQL.
|
* Support for production-scale vector similarity search, full-text search and SQL, with no servers to manage.
|
||||||
|
|
||||||
* Native Python and Javascript/Typescript support.
|
* Native Python and Javascript/Typescript support.
|
||||||
|
|
||||||
* Zero-copy, automatic versioning, manage versions of your data without needing extra infrastructure.
|
* Zero-copy, automatic versioning, manage versions of your data without needing extra infrastructure.
|
||||||
|
|
||||||
* Ecosystem integrations with [LangChain 🦜️🔗](https://python.langchain.com/en/latest/modules/indexes/vectorstores/examples/lancedb.html), [LlamaIndex 🦙](https://gpt-index.readthedocs.io/en/latest/examples/vector_stores/LanceDBIndexDemo.html), Apache-Arrow, Pandas, Polars, DuckDB and more on the way.
|
* Persisted on HDD, allowing scalability without breaking the bank.
|
||||||
|
|
||||||
|
* Ingest your favorite data formats directly, like pandas DataFrames, Pydantic objects and more.
|
||||||
|
|
||||||
|
|
||||||
LanceDB's core is written in Rust 🦀 and is built using <a href="https://github.com/lancedb/lance">Lance</a>, an open-source columnar format designed for performant ML workloads.
|
LanceDB's core is written in Rust 🦀 and is built using <a href="https://github.com/lancedb/lance">Lance</a>, an open-source columnar format designed for performant ML workloads.
|
||||||
|
|
||||||
@@ -69,4 +72,4 @@ LanceDB's core is written in Rust 🦀 and is built using <a href="https://githu
|
|||||||
* [`Full text search`](fts.md) - [EXPERIMENTAL] full-text search API
|
* [`Full text search`](fts.md) - [EXPERIMENTAL] full-text search API
|
||||||
* [`Ecosystem Integrations`](python/integration.md) - integrating LanceDB with python data tooling ecosystem.
|
* [`Ecosystem Integrations`](python/integration.md) - integrating LanceDB with python data tooling ecosystem.
|
||||||
* [`Python API Reference`](python/python.md) - detailed documentation for the LanceDB Python SDK.
|
* [`Python API Reference`](python/python.md) - detailed documentation for the LanceDB Python SDK.
|
||||||
* [`Node API Reference`](javascript/modules.md) - detailed documentation for the LanceDB Python SDK.
|
* [`Node API Reference`](javascript/modules.md) - detailed documentation for the LanceDB Node SDK.
|
||||||
|
|||||||
21
docs/src/integrations/index.md
Normal file
21
docs/src/integrations/index.md
Normal file
@@ -0,0 +1,21 @@
|
|||||||
|
# Integrations
|
||||||
|
|
||||||
|
## Data Formats
|
||||||
|
|
||||||
|
LanceDB supports ingesting from your favorite data tools.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
|
## Tools
|
||||||
|
|
||||||
|
LanceDB is integrated with most of the popular AI tools, with more coming soon.
|
||||||
|
Get started using these examples and quick links.
|
||||||
|
|
||||||
|
| Integrations | |
|
||||||
|
|---|---:|
|
||||||
|
| <h3> LlamaIndex </h3>LlamaIndex is a simple, flexible data framework for connecting custom data sources to large language models. Llama index integrates with LanceDB as the serverless VectorDB. <h3>[Lean More](https://gpt-index.readthedocs.io/en/latest/examples/vector_stores/LanceDBIndexDemo.html) </h3> |<img src="../assets/llama-index.jpg" alt="image" width="150" height="auto">|
|
||||||
|
| <h3>Langchain</h3>Langchain allows building applications with LLMs through composability <h3>[Lean More](https://python.langchain.com/en/latest/modules/indexes/vectorstores/examples/lancedb.html) | <img src="../assets/langchain.png" alt="image" width="150" height="auto">|
|
||||||
|
| <h3>Langchain TS</h3> Javascript bindings for Langchain. It integrates with LanceDB's serverless vectordb allowing you to build powerful AI applications through composibility using only serverless functions. <h3>[Learn More]( https://js.langchain.com/docs/modules/data_connection/vectorstores/integrations/lancedb) | <img src="../assets/langchain.png" alt="image" width="150" height="auto">|
|
||||||
|
| <h3>Voxel51</h3> It is an open source toolkit that enables you to build better computer vision workflows by improving the quality of your datasets and delivering insights about your models.<h3>[Learn More](./voxel51.md) | <img src="../assets/voxel.gif" alt="image" width="150" height="auto">|
|
||||||
|
| <h3>PromptTools</h3> Offers a set of free, open-source tools for testing and experimenting with models, prompts, and configurations. The core idea is to enable developers to evaluate prompts using familiar interfaces like code and notebooks. You can use it to experiment with different configurations of LanceDB, and test how LanceDB integrates with the LLM of your choice.<h3>[Learn More](./prompttools.md) | <img src="../assets/prompttools.jpeg" alt="image" width="150" height="auto">|
|
||||||
7
docs/src/integrations/prompttools.md
Normal file
7
docs/src/integrations/prompttools.md
Normal file
@@ -0,0 +1,7 @@
|
|||||||
|
|
||||||
|
[PromptTools](https://github.com/hegelai/prompttools) offers a set of free, open-source tools for testing and experimenting with models, prompts, and configurations. The core idea is to enable developers to evaluate prompts using familiar interfaces like code and notebooks. You can use it to experiment with different configurations of LanceDB, and test how LanceDB integrates with the LLM of your choice.
|
||||||
|
|
||||||
|
[Evaluating Prompts with PromptTools](./examples/prompttools-eval-prompts/) | <a href="https://colab.research.google.com/github/lancedb/vectordb-recipes/blob/main/examples/prompttools-eval-prompts/main.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a>
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
71
docs/src/integrations/voxel51.md
Normal file
71
docs/src/integrations/voxel51.md
Normal file
@@ -0,0 +1,71 @@
|
|||||||
|

|
||||||
|
|
||||||
|
Basic recipe
|
||||||
|
____________
|
||||||
|
|
||||||
|
The basic workflow to use LanceDB to create a similarity index on your FiftyOne
|
||||||
|
datasets and use this to query your data is as follows:
|
||||||
|
|
||||||
|
1) Load a dataset into FiftyOne
|
||||||
|
|
||||||
|
2) Compute embedding vectors for samples or patches in your dataset, or select
|
||||||
|
a model to use to generate embeddings
|
||||||
|
|
||||||
|
3) Use the `compute_similarity()`
|
||||||
|
method to generate a LanceDB table for the samples or object
|
||||||
|
patches embeddings in a dataset by setting the parameter `backend="lancedb"` and
|
||||||
|
specifying a `brain_key` of your choice
|
||||||
|
|
||||||
|
4) Use this LanceDB table to query your data with
|
||||||
|
`sort_by_similarity()`
|
||||||
|
|
||||||
|
5) If desired, delete the table
|
||||||
|
|
||||||
|
The example below demonstrates this workflow.
|
||||||
|
|
||||||
|
!!! Note
|
||||||
|
|
||||||
|
You must install the LanceDB Python client to run this
|
||||||
|
```
|
||||||
|
pip install lancedb
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
|
||||||
|
import fiftyone as fo
|
||||||
|
import fiftyone.brain as fob
|
||||||
|
import fiftyone.zoo as foz
|
||||||
|
|
||||||
|
# Step 1: Load your data into FiftyOne
|
||||||
|
dataset = foz.load_zoo_dataset("quickstart")
|
||||||
|
|
||||||
|
# Steps 2 and 3: Compute embeddings and create a similarity index
|
||||||
|
lancedb_index = fob.compute_similarity(
|
||||||
|
dataset,
|
||||||
|
model="clip-vit-base32-torch",
|
||||||
|
brain_key="lancedb_index",
|
||||||
|
backend="lancedb",
|
||||||
|
)
|
||||||
|
```
|
||||||
|
Once the similarity index has been generated, we can query our data in FiftyOne
|
||||||
|
by specifying the `brain_key`:
|
||||||
|
|
||||||
|
```python
|
||||||
|
# Step 4: Query your data
|
||||||
|
query = dataset.first().id # query by sample ID
|
||||||
|
view = dataset.sort_by_similarity(
|
||||||
|
query,
|
||||||
|
brain_key="lancedb_index",
|
||||||
|
k=10, # limit to 10 most similar samples
|
||||||
|
)
|
||||||
|
|
||||||
|
# Step 5 (optional): Cleanup
|
||||||
|
|
||||||
|
# Delete the LanceDB table
|
||||||
|
lancedb_index.cleanup()
|
||||||
|
|
||||||
|
# Delete run record from FiftyOne
|
||||||
|
dataset.delete_brain_run("lancedb_index")
|
||||||
|
```
|
||||||
|
|
||||||
|
More in depth walkthrough of the integration, visit the LanceDB guide on Voxel51 - [LaceDB x Voxel51](https://docs.voxel51.com/integrations/lancedb.html)
|
||||||
@@ -10,7 +10,11 @@
|
|||||||
"\n",
|
"\n",
|
||||||
"This Q&A bot will allow you to query your own documentation easily using questions. We'll also demonstrate the use of LangChain and LanceDB using the OpenAI API. \n",
|
"This Q&A bot will allow you to query your own documentation easily using questions. We'll also demonstrate the use of LangChain and LanceDB using the OpenAI API. \n",
|
||||||
"\n",
|
"\n",
|
||||||
"In this example we'll use Pandas 2.0 documentation, but, this could be replaced for your own docs as well"
|
"In this example we'll use Pandas 2.0 documentation, but, this could be replaced for your own docs as well\n",
|
||||||
|
"\n",
|
||||||
|
"<a href=\"https://colab.research.google.com/github/lancedb/vectordb-recipes/blob/main/examples/Code-Documentation-QA-Bot/main.ipynb\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"></a>\n",
|
||||||
|
"\n",
|
||||||
|
"Scripts - [](./examples/Code-Documentation-QA-Bot/main.py) [](./examples/Code-Documentation-QA-Bot/index.js)"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@@ -181,7 +185,7 @@
|
|||||||
"id": "c3852dd3",
|
"id": "c3852dd3",
|
||||||
"metadata": {},
|
"metadata": {},
|
||||||
"source": [
|
"source": [
|
||||||
"# Generating emebeddings from our docs\n",
|
"# Generating embeddings from our docs\n",
|
||||||
"\n",
|
"\n",
|
||||||
"Now that we have our raw documents loaded, we need to pre-process them to generate embeddings:"
|
"Now that we have our raw documents loaded, we need to pre-process them to generate embeddings:"
|
||||||
]
|
]
|
||||||
|
|||||||
@@ -1,5 +1,14 @@
|
|||||||
{
|
{
|
||||||
"cells": [
|
"cells": [
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"\n",
|
||||||
|
"\n",
|
||||||
|
" <a href=\"https://colab.research.google.com/github/lancedb/vectordb-recipes/blob/main/examples/multimodal_clip/main.ipynb\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"></a>| [](./examples/multimodal_clip/main.py) |"
|
||||||
|
]
|
||||||
|
},
|
||||||
{
|
{
|
||||||
"cell_type": "code",
|
"cell_type": "code",
|
||||||
"execution_count": 2,
|
"execution_count": 2,
|
||||||
@@ -42,6 +51,19 @@
|
|||||||
"## First run setup: Download data and pre-process"
|
"## First run setup: Download data and pre-process"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"### Get dataset\n",
|
||||||
|
"\n",
|
||||||
|
"!wget https://eto-public.s3.us-west-2.amazonaws.com/datasets/diffusiondb_lance.tar.gz\n",
|
||||||
|
"!tar -xvf diffusiondb_lance.tar.gz\n",
|
||||||
|
"!mv diffusiondb_test rawdata.lance\n"
|
||||||
|
]
|
||||||
|
},
|
||||||
{
|
{
|
||||||
"cell_type": "code",
|
"cell_type": "code",
|
||||||
"execution_count": 30,
|
"execution_count": 30,
|
||||||
@@ -247,7 +269,7 @@
|
|||||||
],
|
],
|
||||||
"metadata": {
|
"metadata": {
|
||||||
"kernelspec": {
|
"kernelspec": {
|
||||||
"display_name": "Python 3 (ipykernel)",
|
"display_name": "Python 3.11.4 64-bit",
|
||||||
"language": "python",
|
"language": "python",
|
||||||
"name": "python3"
|
"name": "python3"
|
||||||
},
|
},
|
||||||
@@ -261,7 +283,12 @@
|
|||||||
"name": "python",
|
"name": "python",
|
||||||
"nbconvert_exporter": "python",
|
"nbconvert_exporter": "python",
|
||||||
"pygments_lexer": "ipython3",
|
"pygments_lexer": "ipython3",
|
||||||
"version": "3.11.3"
|
"version": "3.11.4"
|
||||||
|
},
|
||||||
|
"vscode": {
|
||||||
|
"interpreter": {
|
||||||
|
"hash": "b0fa6594d8f4cbf19f97940f81e996739fb7646882a419484c72d19e05852a7e"
|
||||||
|
}
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"nbformat": 4,
|
"nbformat": 4,
|
||||||
|
|||||||
831
docs/src/notebooks/tables_guide.ipynb
Normal file
831
docs/src/notebooks/tables_guide.ipynb
Normal file
@@ -0,0 +1,831 @@
|
|||||||
|
{
|
||||||
|
"cells": [
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"id": "d24eb4c6-e246-44ca-ba7c-6eae7923bd4c",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## LanceDB Tables\n",
|
||||||
|
"A Table is a collection of Records in a LanceDB Database.\n",
|
||||||
|
"\n",
|
||||||
|
""
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 50,
|
||||||
|
"id": "c1b4e34b-a49c-471d-a343-a5940bb5138a",
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"!pip install lancedb -qq"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 1,
|
||||||
|
"id": "4e5a8d07-d9a1-48c1-913a-8e0629289579",
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"import lancedb\n",
|
||||||
|
"db = lancedb.connect(\"./.lancedb\")"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"id": "66fb93d5-3551-406b-99b2-488442d61d06",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"LanceDB allows ingesting data from various sources - `dict`, `list[dict]`, `pd.DataFrame`, `pa.Table` or a `Iterator[pa.RecordBatch]`. Let's take a look at some of the these.\n",
|
||||||
|
"\n",
|
||||||
|
" ### From list of tuples or dictionaries"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 2,
|
||||||
|
"id": "5df12f66-8d99-43ad-8d0b-22189ec0a6b9",
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [
|
||||||
|
{
|
||||||
|
"data": {
|
||||||
|
"text/plain": [
|
||||||
|
"pyarrow.Table\n",
|
||||||
|
"vector: fixed_size_list<item: float>[2]\n",
|
||||||
|
" child 0, item: float\n",
|
||||||
|
"lat: double\n",
|
||||||
|
"long: double\n",
|
||||||
|
"----\n",
|
||||||
|
"vector: [[[1.1,1.2],[0.2,1.8]]]\n",
|
||||||
|
"lat: [[45.5,40.1]]\n",
|
||||||
|
"long: [[-122.7,-74.1]]"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
"execution_count": 2,
|
||||||
|
"metadata": {},
|
||||||
|
"output_type": "execute_result"
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"source": [
|
||||||
|
"import lancedb\n",
|
||||||
|
"\n",
|
||||||
|
"db = lancedb.connect(\"./.lancedb\")\n",
|
||||||
|
"\n",
|
||||||
|
"data = [{\"vector\": [1.1, 1.2], \"lat\": 45.5, \"long\": -122.7},\n",
|
||||||
|
" {\"vector\": [0.2, 1.8], \"lat\": 40.1, \"long\": -74.1}]\n",
|
||||||
|
"\n",
|
||||||
|
"db.create_table(\"my_table\", data)\n",
|
||||||
|
"\n",
|
||||||
|
"db[\"my_table\"].head()"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"id": "10ce802f-1a10-49ee-8ee3-a9bfb302d86c",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## From pandas DataFrame\n"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 3,
|
||||||
|
"id": "f4d87ae9-0ccb-48eb-b31d-bb8f2370e47e",
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [
|
||||||
|
{
|
||||||
|
"data": {
|
||||||
|
"text/plain": [
|
||||||
|
"pyarrow.Table\n",
|
||||||
|
"vector: fixed_size_list<item: float>[2]\n",
|
||||||
|
" child 0, item: float\n",
|
||||||
|
"lat: double\n",
|
||||||
|
"long: double\n",
|
||||||
|
"----\n",
|
||||||
|
"vector: [[[1.1,1.2],[0.2,1.8]]]\n",
|
||||||
|
"lat: [[45.5,40.1]]\n",
|
||||||
|
"long: [[-122.7,-74.1]]"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
"execution_count": 3,
|
||||||
|
"metadata": {},
|
||||||
|
"output_type": "execute_result"
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"source": [
|
||||||
|
"import pandas as pd\n",
|
||||||
|
"\n",
|
||||||
|
"data = pd.DataFrame({\n",
|
||||||
|
" \"vector\": [[1.1, 1.2], [0.2, 1.8]],\n",
|
||||||
|
" \"lat\": [45.5, 40.1],\n",
|
||||||
|
" \"long\": [-122.7, -74.1]\n",
|
||||||
|
"})\n",
|
||||||
|
"\n",
|
||||||
|
"db.create_table(\"table2\", data)\n",
|
||||||
|
"\n",
|
||||||
|
"db[\"table2\"].head() "
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"id": "4be81469-5b57-4f78-9c72-3938c0378d9d",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"Data is converted to Arrow before being written to disk. For maximum control over how data is saved, either provide the PyArrow schema to convert to or else provide a PyArrow Table directly.\n",
|
||||||
|
" "
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 8,
|
||||||
|
"id": "25f34bcf-fca0-4431-8601-eac95d1bd347",
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [
|
||||||
|
{
|
||||||
|
"data": {
|
||||||
|
"text/plain": [
|
||||||
|
"vector: fixed_size_list<item: float>[2]\n",
|
||||||
|
" child 0, item: float\n",
|
||||||
|
"lat: float\n",
|
||||||
|
"long: float"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
"execution_count": 8,
|
||||||
|
"metadata": {},
|
||||||
|
"output_type": "execute_result"
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"source": [
|
||||||
|
"import pyarrow as pa\n",
|
||||||
|
"\n",
|
||||||
|
"custom_schema = pa.schema([\n",
|
||||||
|
"pa.field(\"vector\", pa.list_(pa.float32(), 2)),\n",
|
||||||
|
"pa.field(\"lat\", pa.float32()),\n",
|
||||||
|
"pa.field(\"long\", pa.float32())\n",
|
||||||
|
"])\n",
|
||||||
|
"\n",
|
||||||
|
"table = db.create_table(\"table3\", data, schema=custom_schema, mode=\"overwrite\")\n",
|
||||||
|
"table.schema"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"id": "4df51925-7ca2-4005-9c72-38b3d26240c6",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"### From PyArrow Tables\n",
|
||||||
|
"\n",
|
||||||
|
"You can also create LanceDB tables directly from pyarrow tables"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 12,
|
||||||
|
"id": "90a880f6-be43-4c9d-ba65-0b05197c0f6f",
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [
|
||||||
|
{
|
||||||
|
"data": {
|
||||||
|
"text/plain": [
|
||||||
|
"vector: fixed_size_list<item: float>[2]\n",
|
||||||
|
" child 0, item: float\n",
|
||||||
|
"item: string\n",
|
||||||
|
"price: double"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
"execution_count": 12,
|
||||||
|
"metadata": {},
|
||||||
|
"output_type": "execute_result"
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"source": [
|
||||||
|
"table = pa.Table.from_arrays(\n",
|
||||||
|
" [\n",
|
||||||
|
" pa.array([[3.1, 4.1], [5.9, 26.5]],\n",
|
||||||
|
" pa.list_(pa.float32(), 2)),\n",
|
||||||
|
" pa.array([\"foo\", \"bar\"]),\n",
|
||||||
|
" pa.array([10.0, 20.0]),\n",
|
||||||
|
" ],\n",
|
||||||
|
" [\"vector\", \"item\", \"price\"],\n",
|
||||||
|
" )\n",
|
||||||
|
"\n",
|
||||||
|
"db = lancedb.connect(\"db\")\n",
|
||||||
|
"\n",
|
||||||
|
"tbl = db.create_table(\"test1\", table, mode=\"overwrite\")\n",
|
||||||
|
"tbl.schema"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"id": "0f36c51c-d902-449d-8292-700e53990c32",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"### From Pydantic Models\n",
|
||||||
|
"\n",
|
||||||
|
"LanceDB supports to create Apache Arrow Schema from a Pydantic BaseModel."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 13,
|
||||||
|
"id": "d81121d7-e4b7-447c-a48c-974b6ebb464a",
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [
|
||||||
|
{
|
||||||
|
"data": {
|
||||||
|
"text/plain": [
|
||||||
|
"movie_id: int64 not null\n",
|
||||||
|
"vector: fixed_size_list<item: float>[128] not null\n",
|
||||||
|
" child 0, item: float\n",
|
||||||
|
"genres: string not null\n",
|
||||||
|
"title: string not null\n",
|
||||||
|
"imdb_id: int64 not null"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
"execution_count": 13,
|
||||||
|
"metadata": {},
|
||||||
|
"output_type": "execute_result"
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"source": [
|
||||||
|
"from lancedb.pydantic import Vector, LanceModel\n",
|
||||||
|
"\n",
|
||||||
|
"class Content(LanceModel):\n",
|
||||||
|
" movie_id: int\n",
|
||||||
|
" vector: Vector(128)\n",
|
||||||
|
" genres: str\n",
|
||||||
|
" title: str\n",
|
||||||
|
" imdb_id: int\n",
|
||||||
|
" \n",
|
||||||
|
" @property\n",
|
||||||
|
" def imdb_url(self) -> str:\n",
|
||||||
|
" return f\"https://www.imdb.com/title/tt{self.imdb_id}\"\n",
|
||||||
|
"\n",
|
||||||
|
"import pyarrow as pa\n",
|
||||||
|
"db = lancedb.connect(\"~/.lancedb\")\n",
|
||||||
|
"table_name = \"movielens_small\"\n",
|
||||||
|
"table = db.create_table(table_name, schema=Content)\n",
|
||||||
|
"table.schema"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"id": "860e1f77-e860-46a9-98b7-b2979092ccd6",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"### Using Iterators / Writing Large Datasets\n",
|
||||||
|
"\n",
|
||||||
|
"It is recommended to use itertators to add large datasets in batches when creating your table in one go. This does not create multiple versions of your dataset unlike manually adding batches using `table.add()`\n",
|
||||||
|
"\n",
|
||||||
|
"LanceDB additionally supports pyarrow's `RecordBatch` Iterators or other generators producing supported data types.\n",
|
||||||
|
"\n",
|
||||||
|
"## Here's an example using using `RecordBatch` iterator for creating tables."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 14,
|
||||||
|
"id": "bc247142-4e3c-41a2-b94c-8e00d2c2a508",
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [
|
||||||
|
{
|
||||||
|
"data": {
|
||||||
|
"text/plain": [
|
||||||
|
"LanceTable(table4)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
"execution_count": 14,
|
||||||
|
"metadata": {},
|
||||||
|
"output_type": "execute_result"
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"source": [
|
||||||
|
"import pyarrow as pa\n",
|
||||||
|
"\n",
|
||||||
|
"def make_batches():\n",
|
||||||
|
" for i in range(5):\n",
|
||||||
|
" yield pa.RecordBatch.from_arrays(\n",
|
||||||
|
" [\n",
|
||||||
|
" pa.array([[3.1, 4.1], [5.9, 26.5]],\n",
|
||||||
|
" pa.list_(pa.float32(), 2)),\n",
|
||||||
|
" pa.array([\"foo\", \"bar\"]),\n",
|
||||||
|
" pa.array([10.0, 20.0]),\n",
|
||||||
|
" ],\n",
|
||||||
|
" [\"vector\", \"item\", \"price\"],\n",
|
||||||
|
" )\n",
|
||||||
|
"\n",
|
||||||
|
"schema = pa.schema([\n",
|
||||||
|
" pa.field(\"vector\", pa.list_(pa.float32(), 2)),\n",
|
||||||
|
" pa.field(\"item\", pa.utf8()),\n",
|
||||||
|
" pa.field(\"price\", pa.float32()),\n",
|
||||||
|
"])\n",
|
||||||
|
"\n",
|
||||||
|
"db.create_table(\"table4\", make_batches(), schema=schema)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"id": "94f7dd2b-bae4-4bdf-8534-201437c31027",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"### Using pandas `DataFrame` Iterator and Pydantic Schema\n",
|
||||||
|
"\n",
|
||||||
|
"You can set the schema via pyarrow schema object or using Pydantic object"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 16,
|
||||||
|
"id": "25ad3523-e0c9-4c28-b3df-38189c4e0e5f",
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [
|
||||||
|
{
|
||||||
|
"data": {
|
||||||
|
"text/plain": [
|
||||||
|
"vector: fixed_size_list<item: float>[2] not null\n",
|
||||||
|
" child 0, item: float\n",
|
||||||
|
"item: string not null\n",
|
||||||
|
"price: double not null"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
"execution_count": 16,
|
||||||
|
"metadata": {},
|
||||||
|
"output_type": "execute_result"
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"source": [
|
||||||
|
"import pyarrow as pa\n",
|
||||||
|
"import pandas as pd\n",
|
||||||
|
"\n",
|
||||||
|
"class PydanticSchema(LanceModel):\n",
|
||||||
|
" vector: Vector(2)\n",
|
||||||
|
" item: str\n",
|
||||||
|
" price: float\n",
|
||||||
|
"\n",
|
||||||
|
"def make_batches():\n",
|
||||||
|
" for i in range(5):\n",
|
||||||
|
" yield pd.DataFrame(\n",
|
||||||
|
" {\n",
|
||||||
|
" \"vector\": [[3.1, 4.1], [1, 1]],\n",
|
||||||
|
" \"item\": [\"foo\", \"bar\"],\n",
|
||||||
|
" \"price\": [10.0, 20.0],\n",
|
||||||
|
" })\n",
|
||||||
|
"\n",
|
||||||
|
"tbl = db.create_table(\"table5\", make_batches(), schema=PydanticSchema)\n",
|
||||||
|
"tbl.schema"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"id": "4aa955e9-fcd0-4c99-b644-f218f3bb3f1a",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Creating Empty Table\n",
|
||||||
|
"\n",
|
||||||
|
"You can create an empty table by just passing the schema and later add to it using `table.add()`"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 17,
|
||||||
|
"id": "2814173a-eacc-4dd8-a64d-6312b44582cc",
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"import lancedb\n",
|
||||||
|
"from lancedb.pydantic import LanceModel, Vector\n",
|
||||||
|
"\n",
|
||||||
|
"class Model(LanceModel):\n",
|
||||||
|
" vector: Vector(2)\n",
|
||||||
|
"\n",
|
||||||
|
"tbl = db.create_table(\"table6\", schema=Model.to_arrow_schema())"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"id": "1d1b0f5c-a1d9-459f-8614-8376b6f577e1",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Open Existing Tables\n",
|
||||||
|
"\n",
|
||||||
|
"If you forget the name of your table, you can always get a listing of all table names:\n"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 18,
|
||||||
|
"id": "df9e13c0-41f6-437f-9dfa-2fd71d3d9c45",
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [
|
||||||
|
{
|
||||||
|
"data": {
|
||||||
|
"text/plain": [
|
||||||
|
"['table6', 'table4', 'table5', 'movielens_small']"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
"execution_count": 18,
|
||||||
|
"metadata": {},
|
||||||
|
"output_type": "execute_result"
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"source": [
|
||||||
|
"db.table_names()"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 20,
|
||||||
|
"id": "9343f5ad-6024-42ee-ac2f-6c1471df8679",
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [
|
||||||
|
{
|
||||||
|
"data": {
|
||||||
|
"text/html": [
|
||||||
|
"<div>\n",
|
||||||
|
"<style scoped>\n",
|
||||||
|
" .dataframe tbody tr th:only-of-type {\n",
|
||||||
|
" vertical-align: middle;\n",
|
||||||
|
" }\n",
|
||||||
|
"\n",
|
||||||
|
" .dataframe tbody tr th {\n",
|
||||||
|
" vertical-align: top;\n",
|
||||||
|
" }\n",
|
||||||
|
"\n",
|
||||||
|
" .dataframe thead th {\n",
|
||||||
|
" text-align: right;\n",
|
||||||
|
" }\n",
|
||||||
|
"</style>\n",
|
||||||
|
"<table border=\"1\" class=\"dataframe\">\n",
|
||||||
|
" <thead>\n",
|
||||||
|
" <tr style=\"text-align: right;\">\n",
|
||||||
|
" <th></th>\n",
|
||||||
|
" <th>vector</th>\n",
|
||||||
|
" <th>item</th>\n",
|
||||||
|
" <th>price</th>\n",
|
||||||
|
" </tr>\n",
|
||||||
|
" </thead>\n",
|
||||||
|
" <tbody>\n",
|
||||||
|
" <tr>\n",
|
||||||
|
" <th>0</th>\n",
|
||||||
|
" <td>[3.1, 4.1]</td>\n",
|
||||||
|
" <td>foo</td>\n",
|
||||||
|
" <td>10.0</td>\n",
|
||||||
|
" </tr>\n",
|
||||||
|
" <tr>\n",
|
||||||
|
" <th>1</th>\n",
|
||||||
|
" <td>[5.9, 26.5]</td>\n",
|
||||||
|
" <td>bar</td>\n",
|
||||||
|
" <td>20.0</td>\n",
|
||||||
|
" </tr>\n",
|
||||||
|
" <tr>\n",
|
||||||
|
" <th>2</th>\n",
|
||||||
|
" <td>[3.1, 4.1]</td>\n",
|
||||||
|
" <td>foo</td>\n",
|
||||||
|
" <td>10.0</td>\n",
|
||||||
|
" </tr>\n",
|
||||||
|
" <tr>\n",
|
||||||
|
" <th>3</th>\n",
|
||||||
|
" <td>[5.9, 26.5]</td>\n",
|
||||||
|
" <td>bar</td>\n",
|
||||||
|
" <td>20.0</td>\n",
|
||||||
|
" </tr>\n",
|
||||||
|
" <tr>\n",
|
||||||
|
" <th>4</th>\n",
|
||||||
|
" <td>[3.1, 4.1]</td>\n",
|
||||||
|
" <td>foo</td>\n",
|
||||||
|
" <td>10.0</td>\n",
|
||||||
|
" </tr>\n",
|
||||||
|
" <tr>\n",
|
||||||
|
" <th>5</th>\n",
|
||||||
|
" <td>[5.9, 26.5]</td>\n",
|
||||||
|
" <td>bar</td>\n",
|
||||||
|
" <td>20.0</td>\n",
|
||||||
|
" </tr>\n",
|
||||||
|
" <tr>\n",
|
||||||
|
" <th>6</th>\n",
|
||||||
|
" <td>[3.1, 4.1]</td>\n",
|
||||||
|
" <td>foo</td>\n",
|
||||||
|
" <td>10.0</td>\n",
|
||||||
|
" </tr>\n",
|
||||||
|
" <tr>\n",
|
||||||
|
" <th>7</th>\n",
|
||||||
|
" <td>[5.9, 26.5]</td>\n",
|
||||||
|
" <td>bar</td>\n",
|
||||||
|
" <td>20.0</td>\n",
|
||||||
|
" </tr>\n",
|
||||||
|
" <tr>\n",
|
||||||
|
" <th>8</th>\n",
|
||||||
|
" <td>[3.1, 4.1]</td>\n",
|
||||||
|
" <td>foo</td>\n",
|
||||||
|
" <td>10.0</td>\n",
|
||||||
|
" </tr>\n",
|
||||||
|
" <tr>\n",
|
||||||
|
" <th>9</th>\n",
|
||||||
|
" <td>[5.9, 26.5]</td>\n",
|
||||||
|
" <td>bar</td>\n",
|
||||||
|
" <td>20.0</td>\n",
|
||||||
|
" </tr>\n",
|
||||||
|
" </tbody>\n",
|
||||||
|
"</table>\n",
|
||||||
|
"</div>"
|
||||||
|
],
|
||||||
|
"text/plain": [
|
||||||
|
" vector item price\n",
|
||||||
|
"0 [3.1, 4.1] foo 10.0\n",
|
||||||
|
"1 [5.9, 26.5] bar 20.0\n",
|
||||||
|
"2 [3.1, 4.1] foo 10.0\n",
|
||||||
|
"3 [5.9, 26.5] bar 20.0\n",
|
||||||
|
"4 [3.1, 4.1] foo 10.0\n",
|
||||||
|
"5 [5.9, 26.5] bar 20.0\n",
|
||||||
|
"6 [3.1, 4.1] foo 10.0\n",
|
||||||
|
"7 [5.9, 26.5] bar 20.0\n",
|
||||||
|
"8 [3.1, 4.1] foo 10.0\n",
|
||||||
|
"9 [5.9, 26.5] bar 20.0"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
"execution_count": 20,
|
||||||
|
"metadata": {},
|
||||||
|
"output_type": "execute_result"
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"source": [
|
||||||
|
"tbl = db.open_table(\"table4\")\n",
|
||||||
|
"tbl.to_pandas()"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"id": "5019246f-12e3-4f78-88a8-9f4939802c76",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Adding to table\n",
|
||||||
|
"After a table has been created, you can always add more data to it using\n",
|
||||||
|
"\n",
|
||||||
|
"You can add any of the valid data structures accepted by LanceDB table, i.e, `dict`, `list[dict]`, `pd.DataFrame`, or a `Iterator[pa.RecordBatch]`. Here are some examples."
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 21,
|
||||||
|
"id": "8a56250f-73a1-4c26-a6ad-5c7a0ce3a9ab",
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"df = pd.DataFrame([{\"vector\": [1.3, 1.4], \"item\": \"fizz\", \"price\": 100.0},\n",
|
||||||
|
" {\"vector\": [9.5, 56.2], \"item\": \"buzz\", \"price\": 200.0}])\n",
|
||||||
|
"tbl.add(df)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"id": "9985f6ee-67e1-45a9-b233-94e3d121ecbf",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"You can also add a large dataset batch in one go using Iterator of supported data types\n",
|
||||||
|
"\n",
|
||||||
|
"### Adding via Iterator\n",
|
||||||
|
"\n",
|
||||||
|
"here, we'll use pandas DataFrame Iterator"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 22,
|
||||||
|
"id": "030c7057-b98e-4e2f-be14-b8c1f927f83c",
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"\n",
|
||||||
|
"import pandas as pd\n",
|
||||||
|
"\n",
|
||||||
|
"def make_batches():\n",
|
||||||
|
" for i in range(5):\n",
|
||||||
|
" yield pd.DataFrame(\n",
|
||||||
|
" {\n",
|
||||||
|
" \"vector\": [[3.1, 4.1], [1, 1]],\n",
|
||||||
|
" \"item\": [\"foo\", \"bar\"],\n",
|
||||||
|
" \"price\": [10.0, 20.0],\n",
|
||||||
|
" })\n",
|
||||||
|
"tbl.add(make_batches())"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"id": "b8316d5d-0a23-4675-b0ee-178711db873a",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"## Deleting from a Table\n",
|
||||||
|
"\n",
|
||||||
|
"Use the `delete()` method on tables to delete rows from a table. To choose which rows to delete, provide a filter that matches on the metadata columns. This can delete any number of rows that match the filter, like:\n",
|
||||||
|
"\n",
|
||||||
|
"\n",
|
||||||
|
"```python\n",
|
||||||
|
"tbl.delete('item = \"fizz\"')\n",
|
||||||
|
"```\n"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 24,
|
||||||
|
"id": "e7a17de2-08d2-41b7-bd05-f63d1045ab1f",
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [
|
||||||
|
{
|
||||||
|
"name": "stdout",
|
||||||
|
"output_type": "stream",
|
||||||
|
"text": [
|
||||||
|
"32\n"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"data": {
|
||||||
|
"text/plain": [
|
||||||
|
"17"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
"execution_count": 24,
|
||||||
|
"metadata": {},
|
||||||
|
"output_type": "execute_result"
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"source": [
|
||||||
|
"print(len(tbl))\n",
|
||||||
|
" \n",
|
||||||
|
"tbl.delete(\"price = 20.0\")\n",
|
||||||
|
" \n",
|
||||||
|
"len(tbl)"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"id": "74ac180b-5432-4c14-b1a8-22c35ac83af8",
|
||||||
|
"metadata": {},
|
||||||
|
"source": [
|
||||||
|
"### Delete from a list of values"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 30,
|
||||||
|
"id": "fe3310bd-08f4-4a22-a63b-b3127d22f9f7",
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [
|
||||||
|
{
|
||||||
|
"name": "stdout",
|
||||||
|
"output_type": "stream",
|
||||||
|
"text": [
|
||||||
|
" vector item price\n",
|
||||||
|
"0 [3.1, 4.1] foo 10.0\n",
|
||||||
|
"1 [3.1, 4.1] foo 10.0\n",
|
||||||
|
"2 [3.1, 4.1] foo 10.0\n",
|
||||||
|
"3 [3.1, 4.1] foo 10.0\n",
|
||||||
|
"4 [3.1, 4.1] foo 10.0\n",
|
||||||
|
"5 [1.3, 1.4] fizz 100.0\n",
|
||||||
|
"6 [9.5, 56.2] buzz 200.0\n",
|
||||||
|
"7 [3.1, 4.1] foo 10.0\n",
|
||||||
|
"8 [3.1, 4.1] foo 10.0\n",
|
||||||
|
"9 [3.1, 4.1] foo 10.0\n",
|
||||||
|
"10 [3.1, 4.1] foo 10.0\n",
|
||||||
|
"11 [3.1, 4.1] foo 10.0\n",
|
||||||
|
"12 [3.1, 4.1] foo 10.0\n",
|
||||||
|
"13 [3.1, 4.1] foo 10.0\n",
|
||||||
|
"14 [3.1, 4.1] foo 10.0\n",
|
||||||
|
"15 [3.1, 4.1] foo 10.0\n",
|
||||||
|
"16 [3.1, 4.1] foo 10.0\n"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"ename": "OSError",
|
||||||
|
"evalue": "LanceError(IO): Error during planning: column foo does not exist",
|
||||||
|
"output_type": "error",
|
||||||
|
"traceback": [
|
||||||
|
"\u001b[0;31m---------------------------------------------------------------------------\u001b[0m",
|
||||||
|
"\u001b[0;31mOSError\u001b[0m Traceback (most recent call last)",
|
||||||
|
"Cell \u001b[0;32mIn[30], line 4\u001b[0m\n\u001b[1;32m 2\u001b[0m to_remove \u001b[38;5;241m=\u001b[39m \u001b[38;5;124m\"\u001b[39m\u001b[38;5;124m, \u001b[39m\u001b[38;5;124m\"\u001b[39m\u001b[38;5;241m.\u001b[39mjoin(\u001b[38;5;28mstr\u001b[39m(v) \u001b[38;5;28;01mfor\u001b[39;00m v \u001b[38;5;129;01min\u001b[39;00m to_remove)\n\u001b[1;32m 3\u001b[0m \u001b[38;5;28mprint\u001b[39m(tbl\u001b[38;5;241m.\u001b[39mto_pandas())\n\u001b[0;32m----> 4\u001b[0m \u001b[43mtbl\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mdelete\u001b[49m\u001b[43m(\u001b[49m\u001b[38;5;124;43mf\u001b[39;49m\u001b[38;5;124;43m\"\u001b[39;49m\u001b[38;5;124;43mitem IN (\u001b[39;49m\u001b[38;5;132;43;01m{\u001b[39;49;00m\u001b[43mto_remove\u001b[49m\u001b[38;5;132;43;01m}\u001b[39;49;00m\u001b[38;5;124;43m)\u001b[39;49m\u001b[38;5;124;43m\"\u001b[39;49m\u001b[43m)\u001b[49m\n\u001b[1;32m 5\u001b[0m tbl\u001b[38;5;241m.\u001b[39mto_pandas()\n",
|
||||||
|
"File \u001b[0;32m~/Documents/lancedb/lancedb/python/lancedb/table.py:610\u001b[0m, in \u001b[0;36mLanceTable.delete\u001b[0;34m(self, where)\u001b[0m\n\u001b[1;32m 609\u001b[0m \u001b[38;5;28;01mdef\u001b[39;00m \u001b[38;5;21mdelete\u001b[39m(\u001b[38;5;28mself\u001b[39m, where: \u001b[38;5;28mstr\u001b[39m):\n\u001b[0;32m--> 610\u001b[0m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_dataset\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mdelete\u001b[49m\u001b[43m(\u001b[49m\u001b[43mwhere\u001b[49m\u001b[43m)\u001b[49m\n",
|
||||||
|
"File \u001b[0;32m~/Documents/lancedb/lancedb/env/lib/python3.11/site-packages/lance/dataset.py:489\u001b[0m, in \u001b[0;36mLanceDataset.delete\u001b[0;34m(self, predicate)\u001b[0m\n\u001b[1;32m 487\u001b[0m \u001b[38;5;28;01mif\u001b[39;00m \u001b[38;5;28misinstance\u001b[39m(predicate, pa\u001b[38;5;241m.\u001b[39mcompute\u001b[38;5;241m.\u001b[39mExpression):\n\u001b[1;32m 488\u001b[0m predicate \u001b[38;5;241m=\u001b[39m \u001b[38;5;28mstr\u001b[39m(predicate)\n\u001b[0;32m--> 489\u001b[0m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_ds\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mdelete\u001b[49m\u001b[43m(\u001b[49m\u001b[43mpredicate\u001b[49m\u001b[43m)\u001b[49m\n",
|
||||||
|
"\u001b[0;31mOSError\u001b[0m: LanceError(IO): Error during planning: column foo does not exist"
|
||||||
|
]
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"source": [
|
||||||
|
"to_remove = [\"foo\", \"buzz\"]\n",
|
||||||
|
"to_remove = \", \".join(str(v) for v in to_remove)\n",
|
||||||
|
"print(tbl.to_pandas())\n",
|
||||||
|
"tbl.delete(f\"item IN ({to_remove})\")\n"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 43,
|
||||||
|
"id": "87d5bc21-847f-4c81-b56e-f6dbe5d05aac",
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"df = pd.DataFrame(\n",
|
||||||
|
" {\n",
|
||||||
|
" \"vector\": [[3.1, 4.1], [1, 1]],\n",
|
||||||
|
" \"item\": [\"foo\", \"bar\"],\n",
|
||||||
|
" \"price\": [10.0, 20.0],\n",
|
||||||
|
" })\n",
|
||||||
|
"\n",
|
||||||
|
"tbl = db.create_table(\"table7\", data=df, mode=\"overwrite\")"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 44,
|
||||||
|
"id": "9cba4519-eb3a-4941-ab7e-873d762e750f",
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"to_remove = [10.0, 20.0]\n",
|
||||||
|
"to_remove = \", \".join(str(v) for v in to_remove)\n",
|
||||||
|
"\n",
|
||||||
|
"tbl.delete(f\"price IN ({to_remove})\")"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 46,
|
||||||
|
"id": "5bdc9801-d5ed-4871-92d0-88b27108e788",
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [
|
||||||
|
{
|
||||||
|
"data": {
|
||||||
|
"text/html": [
|
||||||
|
"<div>\n",
|
||||||
|
"<style scoped>\n",
|
||||||
|
" .dataframe tbody tr th:only-of-type {\n",
|
||||||
|
" vertical-align: middle;\n",
|
||||||
|
" }\n",
|
||||||
|
"\n",
|
||||||
|
" .dataframe tbody tr th {\n",
|
||||||
|
" vertical-align: top;\n",
|
||||||
|
" }\n",
|
||||||
|
"\n",
|
||||||
|
" .dataframe thead th {\n",
|
||||||
|
" text-align: right;\n",
|
||||||
|
" }\n",
|
||||||
|
"</style>\n",
|
||||||
|
"<table border=\"1\" class=\"dataframe\">\n",
|
||||||
|
" <thead>\n",
|
||||||
|
" <tr style=\"text-align: right;\">\n",
|
||||||
|
" <th></th>\n",
|
||||||
|
" <th>vector</th>\n",
|
||||||
|
" <th>item</th>\n",
|
||||||
|
" <th>price</th>\n",
|
||||||
|
" </tr>\n",
|
||||||
|
" </thead>\n",
|
||||||
|
" <tbody>\n",
|
||||||
|
" </tbody>\n",
|
||||||
|
"</table>\n",
|
||||||
|
"</div>"
|
||||||
|
],
|
||||||
|
"text/plain": [
|
||||||
|
"Empty DataFrame\n",
|
||||||
|
"Columns: [vector, item, price]\n",
|
||||||
|
"Index: []"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
"execution_count": 46,
|
||||||
|
"metadata": {},
|
||||||
|
"output_type": "execute_result"
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"source": [
|
||||||
|
"tbl.to_pandas()"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"id": "752d33d4-ce1c-48e5-90d2-c85f0982182d",
|
||||||
|
"metadata": {},
|
||||||
|
"outputs": [],
|
||||||
|
"source": []
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"kernelspec": {
|
||||||
|
"display_name": "Python 3 (ipykernel)",
|
||||||
|
"language": "python",
|
||||||
|
"name": "python3"
|
||||||
|
},
|
||||||
|
"language_info": {
|
||||||
|
"codemirror_mode": {
|
||||||
|
"name": "ipython",
|
||||||
|
"version": 3
|
||||||
|
},
|
||||||
|
"file_extension": ".py",
|
||||||
|
"mimetype": "text/x-python",
|
||||||
|
"name": "python",
|
||||||
|
"nbconvert_exporter": "python",
|
||||||
|
"pygments_lexer": "ipython3",
|
||||||
|
"version": "3.11.4"
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"nbformat": 4,
|
||||||
|
"nbformat_minor": 5
|
||||||
|
}
|
||||||
@@ -8,7 +8,12 @@
|
|||||||
"source": [
|
"source": [
|
||||||
"# Youtube Transcript Search QA Bot\n",
|
"# Youtube Transcript Search QA Bot\n",
|
||||||
"\n",
|
"\n",
|
||||||
"This Q&A bot will allow you to search through youtube transcripts using natural language! By going through this notebook, we'll introduce how you can use LanceDB to store and manage your data easily."
|
"This Q&A bot will allow you to search through youtube transcripts using natural language! By going through this notebook, we'll introduce how you can use LanceDB to store and manage your data easily.\n",
|
||||||
|
"\n",
|
||||||
|
"\n",
|
||||||
|
"<a href=\"https://colab.research.google.com/github/lancedb/vectordb-recipes/blob/main/examples/youtube_bot/main.ipynb\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\">\n",
|
||||||
|
"\n",
|
||||||
|
"Scripts - [](./examples/youtube_bot/main.py) [](./examples/youtube_bot/index.js)\n"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
|
|||||||
@@ -79,7 +79,7 @@ print(df)
|
|||||||
```
|
```
|
||||||
|
|
||||||
```
|
```
|
||||||
vector item price score
|
vector item price _distance
|
||||||
0 [5.9, 26.5] bar 20.0 14257.05957
|
0 [5.9, 26.5] bar 20.0 14257.05957
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|||||||
@@ -1,6 +1,7 @@
|
|||||||
# Pydantic
|
# Pydantic
|
||||||
|
|
||||||
[Pydantic](https://docs.pydantic.dev/latest/) is a data validation library in Python.
|
[Pydantic](https://docs.pydantic.dev/latest/) is a data validation library in Python.
|
||||||
|
LanceDB integrates with Pydantic for schema inference, data ingestion, and query result casting.
|
||||||
|
|
||||||
## Schema
|
## Schema
|
||||||
|
|
||||||
@@ -12,10 +13,10 @@ via [pydantic_to_schema()](python.md##lancedb.pydantic.pydantic_to_schema) metho
|
|||||||
|
|
||||||
## Vector Field
|
## Vector Field
|
||||||
|
|
||||||
LanceDB provides a [`vector(dim)`](python.md#lancedb.pydantic.vector) method to define a
|
LanceDB provides a [`Vector(dim)`](python.md#lancedb.pydantic.Vector) method to define a
|
||||||
vector Field in a Pydantic Model.
|
vector Field in a Pydantic Model.
|
||||||
|
|
||||||
::: lancedb.pydantic.vector
|
::: lancedb.pydantic.Vector
|
||||||
|
|
||||||
## Type Conversion
|
## Type Conversion
|
||||||
|
|
||||||
@@ -32,4 +33,4 @@ Current supported type conversions:
|
|||||||
| `str` | `pyarrow.utf8()` |
|
| `str` | `pyarrow.utf8()` |
|
||||||
| `list` | `pyarrow.List` |
|
| `list` | `pyarrow.List` |
|
||||||
| `BaseModel` | `pyarrow.Struct` |
|
| `BaseModel` | `pyarrow.Struct` |
|
||||||
| `vector(n)` | `pyarrow.FixedSizeList(float32, n)` |
|
| `Vector(n)` | `pyarrow.FixedSizeList(float32, n)` |
|
||||||
|
|||||||
@@ -26,9 +26,19 @@ pip install lancedb
|
|||||||
|
|
||||||
## Embeddings
|
## Embeddings
|
||||||
|
|
||||||
::: lancedb.embeddings.with_embeddings
|
::: lancedb.embeddings.functions.EmbeddingFunctionRegistry
|
||||||
|
|
||||||
::: lancedb.embeddings.EmbeddingFunction
|
::: lancedb.embeddings.functions.EmbeddingFunction
|
||||||
|
|
||||||
|
::: lancedb.embeddings.functions.TextEmbeddingFunction
|
||||||
|
|
||||||
|
::: lancedb.embeddings.functions.SentenceTransformerEmbeddings
|
||||||
|
|
||||||
|
::: lancedb.embeddings.functions.OpenAIEmbeddings
|
||||||
|
|
||||||
|
::: lancedb.embeddings.functions.OpenClipEmbeddings
|
||||||
|
|
||||||
|
::: lancedb.embeddings.with_embeddings
|
||||||
|
|
||||||
## Context
|
## Context
|
||||||
|
|
||||||
@@ -56,4 +66,4 @@ pip install lancedb
|
|||||||
|
|
||||||
::: lancedb.pydantic.vector
|
::: lancedb.pydantic.vector
|
||||||
|
|
||||||
|
::: lancedb.pydantic.LanceModel
|
||||||
|
|||||||
@@ -3,4 +3,13 @@
|
|||||||
--md-primary-fg-color--dark: #4338ca;
|
--md-primary-fg-color--dark: #4338ca;
|
||||||
--md-text-font: ui-sans-serif, system-ui, -apple-system, BlinkMacSystemFont, "Segoe UI", Roboto, "Helvetica Neue", Arial, "Noto Sans", sans-serif, "Apple Color Emoji", "Segoe UI Emoji", "Segoe UI Symbol", "Noto Color Emoji";
|
--md-text-font: ui-sans-serif, system-ui, -apple-system, BlinkMacSystemFont, "Segoe UI", Roboto, "Helvetica Neue", Arial, "Noto Sans", sans-serif, "Apple Color Emoji", "Segoe UI Emoji", "Segoe UI Symbol", "Noto Color Emoji";
|
||||||
--md-code-font: ui-monospace, SFMono-Regular, Menlo, Monaco, Consolas, "Liberation Mono", "Courier New", monospace;
|
--md-code-font: ui-monospace, SFMono-Regular, Menlo, Monaco, Consolas, "Liberation Mono", "Courier New", monospace;
|
||||||
}
|
}
|
||||||
|
|
||||||
|
.md-nav__item, .md-tabs__item {
|
||||||
|
font-size: large;
|
||||||
|
}
|
||||||
|
|
||||||
|
/* Maximum space for text block */
|
||||||
|
.md-grid {
|
||||||
|
max-width: 90%;
|
||||||
|
}
|
||||||
|
|||||||
@@ -2,18 +2,17 @@ const glob = require("glob");
|
|||||||
const fs = require("fs");
|
const fs = require("fs");
|
||||||
const path = require("path");
|
const path = require("path");
|
||||||
|
|
||||||
const excludedFiles = [
|
const globString = "../src/**/*.md";
|
||||||
|
const excludedGlobs = [
|
||||||
"../src/fts.md",
|
"../src/fts.md",
|
||||||
"../src/embedding.md",
|
"../src/embedding.md",
|
||||||
"../src/examples/serverless_lancedb_with_s3_and_lambda.md",
|
"../src/examples/*.md",
|
||||||
"../src/examples/serverless_qa_bot_with_modal_and_langchain.md",
|
"../src/guides/tables.md",
|
||||||
"../src/examples/transformerjs_embedding_search_nodejs.md",
|
|
||||||
"../src/examples/youtube_transcript_bot_with_nodejs.md",
|
|
||||||
];
|
];
|
||||||
|
|
||||||
const nodePrefix = "javascript";
|
const nodePrefix = "javascript";
|
||||||
const nodeFile = ".js";
|
const nodeFile = ".js";
|
||||||
const nodeFolder = "node";
|
const nodeFolder = "node";
|
||||||
const globString = "../src/**/*.md";
|
|
||||||
const asyncPrefix = "(async () => {\n";
|
const asyncPrefix = "(async () => {\n";
|
||||||
const asyncSuffix = "})();";
|
const asyncSuffix = "})();";
|
||||||
|
|
||||||
@@ -32,6 +31,7 @@ function* yieldLines(lines, prefix, suffix) {
|
|||||||
}
|
}
|
||||||
|
|
||||||
const files = glob.sync(globString, { recursive: true });
|
const files = glob.sync(globString, { recursive: true });
|
||||||
|
const excludedFiles = glob.sync(excludedGlobs, { recursive: true });
|
||||||
|
|
||||||
for (const file of files.filter((file) => !excludedFiles.includes(file))) {
|
for (const file of files.filter((file) => !excludedFiles.includes(file))) {
|
||||||
const lines = [];
|
const lines = [];
|
||||||
@@ -49,4 +49,4 @@ for (const file of files.filter((file) => !excludedFiles.includes(file))) {
|
|||||||
fs.mkdirSync(path.dirname(outPath), { recursive: true });
|
fs.mkdirSync(path.dirname(outPath), { recursive: true });
|
||||||
fs.writeFileSync(outPath, asyncPrefix + "\n" + lines.join("\n") + asyncSuffix);
|
fs.writeFileSync(outPath, asyncPrefix + "\n" + lines.join("\n") + asyncSuffix);
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
@@ -2,18 +2,22 @@ import glob
|
|||||||
from typing import Iterator
|
from typing import Iterator
|
||||||
from pathlib import Path
|
from pathlib import Path
|
||||||
|
|
||||||
excluded_files = [
|
glob_string = "../src/**/*.md"
|
||||||
|
excluded_globs = [
|
||||||
"../src/fts.md",
|
"../src/fts.md",
|
||||||
"../src/embedding.md",
|
"../src/embedding.md",
|
||||||
"../src/examples/serverless_lancedb_with_s3_and_lambda.md",
|
"../src/examples/*.md",
|
||||||
"../src/examples/serverless_qa_bot_with_modal_and_langchain.md",
|
"../src/integrations/voxel51.md",
|
||||||
"../src/examples/youtube_transcript_bot_with_nodejs.md"
|
"../src/guides/tables.md",
|
||||||
|
"../src/python/duckdb.md",
|
||||||
]
|
]
|
||||||
|
|
||||||
python_prefix = "py"
|
python_prefix = "py"
|
||||||
python_file = ".py"
|
python_file = ".py"
|
||||||
python_folder = "python"
|
python_folder = "python"
|
||||||
glob_string = "../src/**/*.md"
|
|
||||||
|
files = glob.glob(glob_string, recursive=True)
|
||||||
|
excluded_files = [f for excluded_glob in excluded_globs for f in glob.glob(excluded_glob, recursive=True)]
|
||||||
|
|
||||||
def yield_lines(lines: Iterator[str], prefix: str, suffix: str):
|
def yield_lines(lines: Iterator[str], prefix: str, suffix: str):
|
||||||
in_code_block = False
|
in_code_block = False
|
||||||
@@ -29,7 +33,7 @@ def yield_lines(lines: Iterator[str], prefix: str, suffix: str):
|
|||||||
elif in_code_block:
|
elif in_code_block:
|
||||||
yield line[strip_length:]
|
yield line[strip_length:]
|
||||||
|
|
||||||
for file in filter(lambda file: file not in excluded_files, glob.glob(glob_string, recursive=True)):
|
for file in filter(lambda file: file not in excluded_files, files):
|
||||||
with open(file, "r") as f:
|
with open(file, "r") as f:
|
||||||
lines = list(yield_lines(iter(f), "```", "```"))
|
lines = list(yield_lines(iter(f), "```", "```"))
|
||||||
|
|
||||||
@@ -38,4 +42,4 @@ for file in filter(lambda file: file not in excluded_files, glob.glob(glob_strin
|
|||||||
print(out_path)
|
print(out_path)
|
||||||
out_path.parent.mkdir(exist_ok=True, parents=True)
|
out_path.parent.mkdir(exist_ok=True, parents=True)
|
||||||
with open(out_path, "w") as out:
|
with open(out_path, "w") as out:
|
||||||
out.writelines(lines)
|
out.writelines(lines)
|
||||||
@@ -50,7 +50,7 @@ async function example() {
|
|||||||
{ id: 5, text: 'Banana', type: 'fruit' }
|
{ id: 5, text: 'Banana', type: 'fruit' }
|
||||||
]
|
]
|
||||||
|
|
||||||
const table = await db.createTable('food_table', data, "create", embed_fun)
|
const table = await db.createTable('food_table', data, embed_fun)
|
||||||
|
|
||||||
|
|
||||||
// Query the table
|
// Query the table
|
||||||
|
|||||||
@@ -10,7 +10,7 @@
|
|||||||
"license": "Apache-2.0",
|
"license": "Apache-2.0",
|
||||||
"dependencies": {
|
"dependencies": {
|
||||||
"@xenova/transformers": "^2.4.1",
|
"@xenova/transformers": "^2.4.1",
|
||||||
"vectordb": "^0.1.12"
|
"vectordb": "file:../.."
|
||||||
}
|
}
|
||||||
|
|
||||||
}
|
}
|
||||||
|
|||||||
@@ -12,26 +12,25 @@
|
|||||||
// See the License for the specific language governing permissions and
|
// See the License for the specific language governing permissions and
|
||||||
// limitations under the License.
|
// limitations under the License.
|
||||||
|
|
||||||
const { currentTarget } = require('@neon-rs/load');
|
const { currentTarget } = require('@neon-rs/load')
|
||||||
|
|
||||||
let nativeLib;
|
let nativeLib
|
||||||
|
|
||||||
try {
|
try {
|
||||||
nativeLib = require(`vectordb-${currentTarget()}`);
|
// When developing locally, give preference to the local built library
|
||||||
} catch (e) {
|
nativeLib = require('./index.node')
|
||||||
try {
|
} catch {
|
||||||
// Might be developing locally, so try that. But don't expose that error
|
try {
|
||||||
// to the user.
|
nativeLib = require(`@lancedb/vectordb-${currentTarget()}`)
|
||||||
nativeLib = require("./index.node");
|
} catch (e) {
|
||||||
} catch {
|
throw new Error(`vectordb: failed to load native library.
|
||||||
throw new Error(`vectordb: failed to load native library.
|
You may need to run \`npm install @lancedb/vectordb-${currentTarget()}\`.
|
||||||
You may need to run \`npm install vectordb-${currentTarget()}\`.
|
|
||||||
|
|
||||||
If that does not work, please file a bug report at https://github.com/lancedb/lancedb/issues
|
If that does not work, please file a bug report at https://github.com/lancedb/lancedb/issues
|
||||||
|
|
||||||
Source error: ${e}`);
|
Source error: ${e}`)
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
// Dynamic require for runtime.
|
// Dynamic require for runtime.
|
||||||
module.exports = nativeLib;
|
module.exports = nativeLib
|
||||||
|
|||||||
363
node/package-lock.json
generated
363
node/package-lock.json
generated
@@ -1,12 +1,12 @@
|
|||||||
{
|
{
|
||||||
"name": "vectordb",
|
"name": "vectordb",
|
||||||
"version": "0.1.14",
|
"version": "0.2.6",
|
||||||
"lockfileVersion": 2,
|
"lockfileVersion": 2,
|
||||||
"requires": true,
|
"requires": true,
|
||||||
"packages": {
|
"packages": {
|
||||||
"": {
|
"": {
|
||||||
"name": "vectordb",
|
"name": "vectordb",
|
||||||
"version": "0.1.14",
|
"version": "0.2.6",
|
||||||
"cpu": [
|
"cpu": [
|
||||||
"x64",
|
"x64",
|
||||||
"arm64"
|
"arm64"
|
||||||
@@ -24,13 +24,14 @@
|
|||||||
"axios": "^1.4.0"
|
"axios": "^1.4.0"
|
||||||
},
|
},
|
||||||
"devDependencies": {
|
"devDependencies": {
|
||||||
"@neon-rs/cli": "^0.0.74",
|
"@neon-rs/cli": "^0.0.160",
|
||||||
"@types/chai": "^4.3.4",
|
"@types/chai": "^4.3.4",
|
||||||
"@types/chai-as-promised": "^7.1.5",
|
"@types/chai-as-promised": "^7.1.5",
|
||||||
"@types/mocha": "^10.0.1",
|
"@types/mocha": "^10.0.1",
|
||||||
"@types/node": "^18.16.2",
|
"@types/node": "^18.16.2",
|
||||||
"@types/sinon": "^10.0.15",
|
"@types/sinon": "^10.0.15",
|
||||||
"@types/temp": "^0.9.1",
|
"@types/temp": "^0.9.1",
|
||||||
|
"@types/uuid": "^9.0.3",
|
||||||
"@typescript-eslint/eslint-plugin": "^5.59.1",
|
"@typescript-eslint/eslint-plugin": "^5.59.1",
|
||||||
"cargo-cp-artifact": "^0.1",
|
"cargo-cp-artifact": "^0.1",
|
||||||
"chai": "^4.3.7",
|
"chai": "^4.3.7",
|
||||||
@@ -48,14 +49,15 @@
|
|||||||
"ts-node-dev": "^2.0.0",
|
"ts-node-dev": "^2.0.0",
|
||||||
"typedoc": "^0.24.7",
|
"typedoc": "^0.24.7",
|
||||||
"typedoc-plugin-markdown": "^3.15.3",
|
"typedoc-plugin-markdown": "^3.15.3",
|
||||||
"typescript": "*"
|
"typescript": "*",
|
||||||
|
"uuid": "^9.0.0"
|
||||||
},
|
},
|
||||||
"optionalDependencies": {
|
"optionalDependencies": {
|
||||||
"vectordb-darwin-arm64": "0.1.14",
|
"@lancedb/vectordb-darwin-arm64": "0.2.6",
|
||||||
"vectordb-darwin-x64": "0.1.14",
|
"@lancedb/vectordb-darwin-x64": "0.2.6",
|
||||||
"vectordb-linux-arm64-gnu": "0.1.14",
|
"@lancedb/vectordb-linux-arm64-gnu": "0.2.6",
|
||||||
"vectordb-linux-x64-gnu": "0.1.14",
|
"@lancedb/vectordb-linux-x64-gnu": "0.2.6",
|
||||||
"vectordb-win32-x64-msvc": "0.1.14"
|
"@lancedb/vectordb-win32-x64-msvc": "0.2.6"
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"node_modules/@apache-arrow/ts": {
|
"node_modules/@apache-arrow/ts": {
|
||||||
@@ -85,6 +87,97 @@
|
|||||||
"resolved": "https://registry.npmjs.org/tslib/-/tslib-2.5.0.tgz",
|
"resolved": "https://registry.npmjs.org/tslib/-/tslib-2.5.0.tgz",
|
||||||
"integrity": "sha512-336iVw3rtn2BUK7ORdIAHTyxHGRIHVReokCR3XjbckJMK7ms8FysBfhLR8IXnAgy7T0PTPNBWKiH514FOW/WSg=="
|
"integrity": "sha512-336iVw3rtn2BUK7ORdIAHTyxHGRIHVReokCR3XjbckJMK7ms8FysBfhLR8IXnAgy7T0PTPNBWKiH514FOW/WSg=="
|
||||||
},
|
},
|
||||||
|
"node_modules/@cargo-messages/android-arm-eabi": {
|
||||||
|
"version": "0.0.160",
|
||||||
|
"resolved": "https://registry.npmjs.org/@cargo-messages/android-arm-eabi/-/android-arm-eabi-0.0.160.tgz",
|
||||||
|
"integrity": "sha512-PTgCEmBHEPKJbxwlHVXB3aGES+NqpeBvn6hJNYWIkET3ZQCSJnScMlIDQXEkWndK7J+hW3Or3H32a93B/MbbfQ==",
|
||||||
|
"cpu": [
|
||||||
|
"arm"
|
||||||
|
],
|
||||||
|
"dev": true,
|
||||||
|
"optional": true,
|
||||||
|
"os": [
|
||||||
|
"android"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
"node_modules/@cargo-messages/darwin-arm64": {
|
||||||
|
"version": "0.0.160",
|
||||||
|
"resolved": "https://registry.npmjs.org/@cargo-messages/darwin-arm64/-/darwin-arm64-0.0.160.tgz",
|
||||||
|
"integrity": "sha512-YSVUuc8TUTi/XmZVg9KrH0bDywKLqC1zeTyZYAYDDmqVDZW9KeTnbBUECKRs56iyHeO+kuEkVW7MKf7j2zb/FA==",
|
||||||
|
"cpu": [
|
||||||
|
"arm64"
|
||||||
|
],
|
||||||
|
"dev": true,
|
||||||
|
"optional": true,
|
||||||
|
"os": [
|
||||||
|
"darwin"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
"node_modules/@cargo-messages/darwin-x64": {
|
||||||
|
"version": "0.0.160",
|
||||||
|
"resolved": "https://registry.npmjs.org/@cargo-messages/darwin-x64/-/darwin-x64-0.0.160.tgz",
|
||||||
|
"integrity": "sha512-U+YlAR+9tKpBljnNPWMop5YhvtwfIPQSAaUYN2llteC7ZNU5/cv8CGT1vm7uFNxr2LeGuAtRbzIh2gUmTV8mng==",
|
||||||
|
"cpu": [
|
||||||
|
"x64"
|
||||||
|
],
|
||||||
|
"dev": true,
|
||||||
|
"optional": true,
|
||||||
|
"os": [
|
||||||
|
"darwin"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
"node_modules/@cargo-messages/linux-arm-gnueabihf": {
|
||||||
|
"version": "0.0.160",
|
||||||
|
"resolved": "https://registry.npmjs.org/@cargo-messages/linux-arm-gnueabihf/-/linux-arm-gnueabihf-0.0.160.tgz",
|
||||||
|
"integrity": "sha512-wqAelTzVv1E7Ls4aviqUbem5xjzCaJQxQtVnLhv6pf1k0UyEHCS2WdufFFmWcojGe7QglI4uve3KTe01MKYj0A==",
|
||||||
|
"cpu": [
|
||||||
|
"arm"
|
||||||
|
],
|
||||||
|
"dev": true,
|
||||||
|
"optional": true,
|
||||||
|
"os": [
|
||||||
|
"linux"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
"node_modules/@cargo-messages/linux-x64-gnu": {
|
||||||
|
"version": "0.0.160",
|
||||||
|
"resolved": "https://registry.npmjs.org/@cargo-messages/linux-x64-gnu/-/linux-x64-gnu-0.0.160.tgz",
|
||||||
|
"integrity": "sha512-LQ6e7O7YYkWfDNIi/53q2QG/+lZok72LOG+NKDVCrrY4TYUcrTqWAybOV6IlkVntKPnpx8YB95umSQGeVuvhpQ==",
|
||||||
|
"cpu": [
|
||||||
|
"x64"
|
||||||
|
],
|
||||||
|
"dev": true,
|
||||||
|
"optional": true,
|
||||||
|
"os": [
|
||||||
|
"linux"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
"node_modules/@cargo-messages/win32-arm64-msvc": {
|
||||||
|
"version": "0.0.160",
|
||||||
|
"resolved": "https://registry.npmjs.org/@cargo-messages/win32-arm64-msvc/-/win32-arm64-msvc-0.0.160.tgz",
|
||||||
|
"integrity": "sha512-VDMBhyun02gIDwmEhkYP1W9Z0tYqn4drgY5Iua1qV2tYOU58RVkWhzUYxM9rzYbnwKZlltgM46J/j5QZ3VaFrA==",
|
||||||
|
"cpu": [
|
||||||
|
"arm64"
|
||||||
|
],
|
||||||
|
"dev": true,
|
||||||
|
"optional": true,
|
||||||
|
"os": [
|
||||||
|
"win32"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
"node_modules/@cargo-messages/win32-x64-msvc": {
|
||||||
|
"version": "0.0.160",
|
||||||
|
"resolved": "https://registry.npmjs.org/@cargo-messages/win32-x64-msvc/-/win32-x64-msvc-0.0.160.tgz",
|
||||||
|
"integrity": "sha512-vnoglDxF6zj0W/Co9D0H/bgnrhUuO5EumIf9v3ujLtBH94rAX11JsXh/FgC/8wQnQSsLyWSq70YxNS2wdETxjA==",
|
||||||
|
"cpu": [
|
||||||
|
"x64"
|
||||||
|
],
|
||||||
|
"dev": true,
|
||||||
|
"optional": true,
|
||||||
|
"os": [
|
||||||
|
"win32"
|
||||||
|
]
|
||||||
|
},
|
||||||
"node_modules/@cspotcode/source-map-support": {
|
"node_modules/@cspotcode/source-map-support": {
|
||||||
"version": "0.8.1",
|
"version": "0.8.1",
|
||||||
"resolved": "https://registry.npmjs.org/@cspotcode/source-map-support/-/source-map-support-0.8.1.tgz",
|
"resolved": "https://registry.npmjs.org/@cspotcode/source-map-support/-/source-map-support-0.8.1.tgz",
|
||||||
@@ -223,13 +316,82 @@
|
|||||||
"@jridgewell/sourcemap-codec": "^1.4.10"
|
"@jridgewell/sourcemap-codec": "^1.4.10"
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
|
"node_modules/@lancedb/vectordb-darwin-arm64": {
|
||||||
|
"version": "0.2.6",
|
||||||
|
"resolved": "https://registry.npmjs.org/@lancedb/vectordb-darwin-arm64/-/vectordb-darwin-arm64-0.2.6.tgz",
|
||||||
|
"integrity": "sha512-9KCUvDmhVMuGIhleib/Gq43QhrRXjy2QJz21S85HDwL3DTH4J9n00A0V6eyLTBUyctnvMTcp3XZijosYUy1A8Q==",
|
||||||
|
"cpu": [
|
||||||
|
"arm64"
|
||||||
|
],
|
||||||
|
"optional": true,
|
||||||
|
"os": [
|
||||||
|
"darwin"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
"node_modules/@lancedb/vectordb-darwin-x64": {
|
||||||
|
"version": "0.2.6",
|
||||||
|
"resolved": "https://registry.npmjs.org/@lancedb/vectordb-darwin-x64/-/vectordb-darwin-x64-0.2.6.tgz",
|
||||||
|
"integrity": "sha512-WCYRFV9w13STgVYn4WSYne39mp+g8ET6TgMLvSSQBYJKp3xEggpSCtACetaDfmNpkml9DK/b5R95Jc7PBbmYgA==",
|
||||||
|
"cpu": [
|
||||||
|
"x64"
|
||||||
|
],
|
||||||
|
"optional": true,
|
||||||
|
"os": [
|
||||||
|
"darwin"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
"node_modules/@lancedb/vectordb-linux-arm64-gnu": {
|
||||||
|
"version": "0.2.6",
|
||||||
|
"resolved": "https://registry.npmjs.org/@lancedb/vectordb-linux-arm64-gnu/-/vectordb-linux-arm64-gnu-0.2.6.tgz",
|
||||||
|
"integrity": "sha512-SE9OUgsOT6dG1q9v3nFr9ew+kwPTA4ktvNiHiyQstNz9BniuLNldF/Wtxzk/Z7DhbkPci4MfkR6RdsPTHBatHg==",
|
||||||
|
"cpu": [
|
||||||
|
"arm64"
|
||||||
|
],
|
||||||
|
"optional": true,
|
||||||
|
"os": [
|
||||||
|
"linux"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
"node_modules/@lancedb/vectordb-linux-x64-gnu": {
|
||||||
|
"version": "0.2.6",
|
||||||
|
"resolved": "https://registry.npmjs.org/@lancedb/vectordb-linux-x64-gnu/-/vectordb-linux-x64-gnu-0.2.6.tgz",
|
||||||
|
"integrity": "sha512-hvUsRQbaJiQnSjjKHIRhJM/eObJOqDJUXcpzz1fWw/MMSoy/CFaQwf9Uen2IWTgcngGkJAkeEKG7N5GxQxVbBQ==",
|
||||||
|
"cpu": [
|
||||||
|
"x64"
|
||||||
|
],
|
||||||
|
"optional": true,
|
||||||
|
"os": [
|
||||||
|
"linux"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
"node_modules/@lancedb/vectordb-win32-x64-msvc": {
|
||||||
|
"version": "0.2.6",
|
||||||
|
"resolved": "https://registry.npmjs.org/@lancedb/vectordb-win32-x64-msvc/-/vectordb-win32-x64-msvc-0.2.6.tgz",
|
||||||
|
"integrity": "sha512-XPIzbBPt28nsAa7INuyvYMZyJ78bgLfxjSyazlydzO10orIBHvR+sjcrdnCK4l48YmvPXcSYnKxlKMa1oUeIWQ==",
|
||||||
|
"cpu": [
|
||||||
|
"x64"
|
||||||
|
],
|
||||||
|
"optional": true,
|
||||||
|
"os": [
|
||||||
|
"win32"
|
||||||
|
]
|
||||||
|
},
|
||||||
"node_modules/@neon-rs/cli": {
|
"node_modules/@neon-rs/cli": {
|
||||||
"version": "0.0.74",
|
"version": "0.0.160",
|
||||||
"resolved": "https://registry.npmjs.org/@neon-rs/cli/-/cli-0.0.74.tgz",
|
"resolved": "https://registry.npmjs.org/@neon-rs/cli/-/cli-0.0.160.tgz",
|
||||||
"integrity": "sha512-9lPmNmjej5iKKOTMPryOMubwkgMRyTWRuaq1yokASvI5mPhr2kzPN7UVjdCOjQvpunNPngR9yAHoirpjiWhUHw==",
|
"integrity": "sha512-GQjzHPJVTOARbX3nP/fAWqBq7JlQ8XgfYlCa+iwzIXf0LC1EyfJTX+vqGD/36b9lKoyY01Z/aDUB9o/qF6ztHA==",
|
||||||
"dev": true,
|
"dev": true,
|
||||||
"bin": {
|
"bin": {
|
||||||
"neon": "index.js"
|
"neon": "index.js"
|
||||||
|
},
|
||||||
|
"optionalDependencies": {
|
||||||
|
"@cargo-messages/android-arm-eabi": "0.0.160",
|
||||||
|
"@cargo-messages/darwin-arm64": "0.0.160",
|
||||||
|
"@cargo-messages/darwin-x64": "0.0.160",
|
||||||
|
"@cargo-messages/linux-arm-gnueabihf": "0.0.160",
|
||||||
|
"@cargo-messages/linux-x64-gnu": "0.0.160",
|
||||||
|
"@cargo-messages/win32-arm64-msvc": "0.0.160",
|
||||||
|
"@cargo-messages/win32-x64-msvc": "0.0.160"
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"node_modules/@neon-rs/load": {
|
"node_modules/@neon-rs/load": {
|
||||||
@@ -436,6 +598,12 @@
|
|||||||
"@types/node": "*"
|
"@types/node": "*"
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
|
"node_modules/@types/uuid": {
|
||||||
|
"version": "9.0.3",
|
||||||
|
"resolved": "https://registry.npmjs.org/@types/uuid/-/uuid-9.0.3.tgz",
|
||||||
|
"integrity": "sha512-taHQQH/3ZyI3zP8M/puluDEIEvtQHVYcC6y3N8ijFtAd28+Ey/G4sg1u2gB01S8MwybLOKAp9/yCMu/uR5l3Ug==",
|
||||||
|
"dev": true
|
||||||
|
},
|
||||||
"node_modules/@typescript-eslint/eslint-plugin": {
|
"node_modules/@typescript-eslint/eslint-plugin": {
|
||||||
"version": "5.59.1",
|
"version": "5.59.1",
|
||||||
"resolved": "https://registry.npmjs.org/@typescript-eslint/eslint-plugin/-/eslint-plugin-5.59.1.tgz",
|
"resolved": "https://registry.npmjs.org/@typescript-eslint/eslint-plugin/-/eslint-plugin-5.59.1.tgz",
|
||||||
@@ -4291,48 +4459,21 @@
|
|||||||
"punycode": "^2.1.0"
|
"punycode": "^2.1.0"
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
|
"node_modules/uuid": {
|
||||||
|
"version": "9.0.0",
|
||||||
|
"resolved": "https://registry.npmjs.org/uuid/-/uuid-9.0.0.tgz",
|
||||||
|
"integrity": "sha512-MXcSTerfPa4uqyzStbRoTgt5XIe3x5+42+q1sDuy3R5MDk66URdLMOZe5aPX/SQd+kuYAh0FdP/pO28IkQyTeg==",
|
||||||
|
"dev": true,
|
||||||
|
"bin": {
|
||||||
|
"uuid": "dist/bin/uuid"
|
||||||
|
}
|
||||||
|
},
|
||||||
"node_modules/v8-compile-cache-lib": {
|
"node_modules/v8-compile-cache-lib": {
|
||||||
"version": "3.0.1",
|
"version": "3.0.1",
|
||||||
"resolved": "https://registry.npmjs.org/v8-compile-cache-lib/-/v8-compile-cache-lib-3.0.1.tgz",
|
"resolved": "https://registry.npmjs.org/v8-compile-cache-lib/-/v8-compile-cache-lib-3.0.1.tgz",
|
||||||
"integrity": "sha512-wa7YjyUGfNZngI/vtK0UHAN+lgDCxBPCylVXGp0zu59Fz5aiGtNXaq3DhIov063MorB+VfufLh3JlF2KdTK3xg==",
|
"integrity": "sha512-wa7YjyUGfNZngI/vtK0UHAN+lgDCxBPCylVXGp0zu59Fz5aiGtNXaq3DhIov063MorB+VfufLh3JlF2KdTK3xg==",
|
||||||
"dev": true
|
"dev": true
|
||||||
},
|
},
|
||||||
"node_modules/vectordb-darwin-arm64": {
|
|
||||||
"version": "0.1.14",
|
|
||||||
"resolved": "https://registry.npmjs.org/vectordb-darwin-arm64/-/vectordb-darwin-arm64-0.1.14.tgz",
|
|
||||||
"integrity": "sha512-5doSFMUR4scxseo73thCxScmO3Wpb+cqPsIa7+2uneTEtBSViMbkw/1mGTC+rV4NTCnxhoiqHk9pJzZVeDMkPg==",
|
|
||||||
"cpu": [
|
|
||||||
"arm64"
|
|
||||||
],
|
|
||||||
"optional": true,
|
|
||||||
"os": [
|
|
||||||
"darwin"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
"node_modules/vectordb-darwin-x64": {
|
|
||||||
"version": "0.1.14",
|
|
||||||
"resolved": "https://registry.npmjs.org/vectordb-darwin-x64/-/vectordb-darwin-x64-0.1.14.tgz",
|
|
||||||
"integrity": "sha512-x+qVaKNhAG65HdENL6GRJjxl1hZ7erRm3a2rhplyYoQyzuRPPBILeWzxkE01G1fb0+47dehe7Q4f/8BDaghcCQ==",
|
|
||||||
"cpu": [
|
|
||||||
"x64"
|
|
||||||
],
|
|
||||||
"optional": true,
|
|
||||||
"os": [
|
|
||||||
"darwin"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
"node_modules/vectordb-linux-x64-gnu": {
|
|
||||||
"version": "0.1.14",
|
|
||||||
"resolved": "https://registry.npmjs.org/vectordb-linux-x64-gnu/-/vectordb-linux-x64-gnu-0.1.14.tgz",
|
|
||||||
"integrity": "sha512-hvA2YYwTZK92k6nPH99Jn5N0CwagDOdnwMmjtCpzFOEYK7dY/2kcTOoQNlBwwNP9MYvgN6jdFD/Cwkih1X/qjA==",
|
|
||||||
"cpu": [
|
|
||||||
"x64"
|
|
||||||
],
|
|
||||||
"optional": true,
|
|
||||||
"os": [
|
|
||||||
"linux"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
"node_modules/vscode-oniguruma": {
|
"node_modules/vscode-oniguruma": {
|
||||||
"version": "1.7.0",
|
"version": "1.7.0",
|
||||||
"resolved": "https://registry.npmjs.org/vscode-oniguruma/-/vscode-oniguruma-1.7.0.tgz",
|
"resolved": "https://registry.npmjs.org/vscode-oniguruma/-/vscode-oniguruma-1.7.0.tgz",
|
||||||
@@ -4578,6 +4719,55 @@
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
|
"@cargo-messages/android-arm-eabi": {
|
||||||
|
"version": "0.0.160",
|
||||||
|
"resolved": "https://registry.npmjs.org/@cargo-messages/android-arm-eabi/-/android-arm-eabi-0.0.160.tgz",
|
||||||
|
"integrity": "sha512-PTgCEmBHEPKJbxwlHVXB3aGES+NqpeBvn6hJNYWIkET3ZQCSJnScMlIDQXEkWndK7J+hW3Or3H32a93B/MbbfQ==",
|
||||||
|
"dev": true,
|
||||||
|
"optional": true
|
||||||
|
},
|
||||||
|
"@cargo-messages/darwin-arm64": {
|
||||||
|
"version": "0.0.160",
|
||||||
|
"resolved": "https://registry.npmjs.org/@cargo-messages/darwin-arm64/-/darwin-arm64-0.0.160.tgz",
|
||||||
|
"integrity": "sha512-YSVUuc8TUTi/XmZVg9KrH0bDywKLqC1zeTyZYAYDDmqVDZW9KeTnbBUECKRs56iyHeO+kuEkVW7MKf7j2zb/FA==",
|
||||||
|
"dev": true,
|
||||||
|
"optional": true
|
||||||
|
},
|
||||||
|
"@cargo-messages/darwin-x64": {
|
||||||
|
"version": "0.0.160",
|
||||||
|
"resolved": "https://registry.npmjs.org/@cargo-messages/darwin-x64/-/darwin-x64-0.0.160.tgz",
|
||||||
|
"integrity": "sha512-U+YlAR+9tKpBljnNPWMop5YhvtwfIPQSAaUYN2llteC7ZNU5/cv8CGT1vm7uFNxr2LeGuAtRbzIh2gUmTV8mng==",
|
||||||
|
"dev": true,
|
||||||
|
"optional": true
|
||||||
|
},
|
||||||
|
"@cargo-messages/linux-arm-gnueabihf": {
|
||||||
|
"version": "0.0.160",
|
||||||
|
"resolved": "https://registry.npmjs.org/@cargo-messages/linux-arm-gnueabihf/-/linux-arm-gnueabihf-0.0.160.tgz",
|
||||||
|
"integrity": "sha512-wqAelTzVv1E7Ls4aviqUbem5xjzCaJQxQtVnLhv6pf1k0UyEHCS2WdufFFmWcojGe7QglI4uve3KTe01MKYj0A==",
|
||||||
|
"dev": true,
|
||||||
|
"optional": true
|
||||||
|
},
|
||||||
|
"@cargo-messages/linux-x64-gnu": {
|
||||||
|
"version": "0.0.160",
|
||||||
|
"resolved": "https://registry.npmjs.org/@cargo-messages/linux-x64-gnu/-/linux-x64-gnu-0.0.160.tgz",
|
||||||
|
"integrity": "sha512-LQ6e7O7YYkWfDNIi/53q2QG/+lZok72LOG+NKDVCrrY4TYUcrTqWAybOV6IlkVntKPnpx8YB95umSQGeVuvhpQ==",
|
||||||
|
"dev": true,
|
||||||
|
"optional": true
|
||||||
|
},
|
||||||
|
"@cargo-messages/win32-arm64-msvc": {
|
||||||
|
"version": "0.0.160",
|
||||||
|
"resolved": "https://registry.npmjs.org/@cargo-messages/win32-arm64-msvc/-/win32-arm64-msvc-0.0.160.tgz",
|
||||||
|
"integrity": "sha512-VDMBhyun02gIDwmEhkYP1W9Z0tYqn4drgY5Iua1qV2tYOU58RVkWhzUYxM9rzYbnwKZlltgM46J/j5QZ3VaFrA==",
|
||||||
|
"dev": true,
|
||||||
|
"optional": true
|
||||||
|
},
|
||||||
|
"@cargo-messages/win32-x64-msvc": {
|
||||||
|
"version": "0.0.160",
|
||||||
|
"resolved": "https://registry.npmjs.org/@cargo-messages/win32-x64-msvc/-/win32-x64-msvc-0.0.160.tgz",
|
||||||
|
"integrity": "sha512-vnoglDxF6zj0W/Co9D0H/bgnrhUuO5EumIf9v3ujLtBH94rAX11JsXh/FgC/8wQnQSsLyWSq70YxNS2wdETxjA==",
|
||||||
|
"dev": true,
|
||||||
|
"optional": true
|
||||||
|
},
|
||||||
"@cspotcode/source-map-support": {
|
"@cspotcode/source-map-support": {
|
||||||
"version": "0.8.1",
|
"version": "0.8.1",
|
||||||
"resolved": "https://registry.npmjs.org/@cspotcode/source-map-support/-/source-map-support-0.8.1.tgz",
|
"resolved": "https://registry.npmjs.org/@cspotcode/source-map-support/-/source-map-support-0.8.1.tgz",
|
||||||
@@ -4678,11 +4868,50 @@
|
|||||||
"@jridgewell/sourcemap-codec": "^1.4.10"
|
"@jridgewell/sourcemap-codec": "^1.4.10"
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
|
"@lancedb/vectordb-darwin-arm64": {
|
||||||
|
"version": "0.2.6",
|
||||||
|
"resolved": "https://registry.npmjs.org/@lancedb/vectordb-darwin-arm64/-/vectordb-darwin-arm64-0.2.6.tgz",
|
||||||
|
"integrity": "sha512-9KCUvDmhVMuGIhleib/Gq43QhrRXjy2QJz21S85HDwL3DTH4J9n00A0V6eyLTBUyctnvMTcp3XZijosYUy1A8Q==",
|
||||||
|
"optional": true
|
||||||
|
},
|
||||||
|
"@lancedb/vectordb-darwin-x64": {
|
||||||
|
"version": "0.2.6",
|
||||||
|
"resolved": "https://registry.npmjs.org/@lancedb/vectordb-darwin-x64/-/vectordb-darwin-x64-0.2.6.tgz",
|
||||||
|
"integrity": "sha512-WCYRFV9w13STgVYn4WSYne39mp+g8ET6TgMLvSSQBYJKp3xEggpSCtACetaDfmNpkml9DK/b5R95Jc7PBbmYgA==",
|
||||||
|
"optional": true
|
||||||
|
},
|
||||||
|
"@lancedb/vectordb-linux-arm64-gnu": {
|
||||||
|
"version": "0.2.6",
|
||||||
|
"resolved": "https://registry.npmjs.org/@lancedb/vectordb-linux-arm64-gnu/-/vectordb-linux-arm64-gnu-0.2.6.tgz",
|
||||||
|
"integrity": "sha512-SE9OUgsOT6dG1q9v3nFr9ew+kwPTA4ktvNiHiyQstNz9BniuLNldF/Wtxzk/Z7DhbkPci4MfkR6RdsPTHBatHg==",
|
||||||
|
"optional": true
|
||||||
|
},
|
||||||
|
"@lancedb/vectordb-linux-x64-gnu": {
|
||||||
|
"version": "0.2.6",
|
||||||
|
"resolved": "https://registry.npmjs.org/@lancedb/vectordb-linux-x64-gnu/-/vectordb-linux-x64-gnu-0.2.6.tgz",
|
||||||
|
"integrity": "sha512-hvUsRQbaJiQnSjjKHIRhJM/eObJOqDJUXcpzz1fWw/MMSoy/CFaQwf9Uen2IWTgcngGkJAkeEKG7N5GxQxVbBQ==",
|
||||||
|
"optional": true
|
||||||
|
},
|
||||||
|
"@lancedb/vectordb-win32-x64-msvc": {
|
||||||
|
"version": "0.2.6",
|
||||||
|
"resolved": "https://registry.npmjs.org/@lancedb/vectordb-win32-x64-msvc/-/vectordb-win32-x64-msvc-0.2.6.tgz",
|
||||||
|
"integrity": "sha512-XPIzbBPt28nsAa7INuyvYMZyJ78bgLfxjSyazlydzO10orIBHvR+sjcrdnCK4l48YmvPXcSYnKxlKMa1oUeIWQ==",
|
||||||
|
"optional": true
|
||||||
|
},
|
||||||
"@neon-rs/cli": {
|
"@neon-rs/cli": {
|
||||||
"version": "0.0.74",
|
"version": "0.0.160",
|
||||||
"resolved": "https://registry.npmjs.org/@neon-rs/cli/-/cli-0.0.74.tgz",
|
"resolved": "https://registry.npmjs.org/@neon-rs/cli/-/cli-0.0.160.tgz",
|
||||||
"integrity": "sha512-9lPmNmjej5iKKOTMPryOMubwkgMRyTWRuaq1yokASvI5mPhr2kzPN7UVjdCOjQvpunNPngR9yAHoirpjiWhUHw==",
|
"integrity": "sha512-GQjzHPJVTOARbX3nP/fAWqBq7JlQ8XgfYlCa+iwzIXf0LC1EyfJTX+vqGD/36b9lKoyY01Z/aDUB9o/qF6ztHA==",
|
||||||
"dev": true
|
"dev": true,
|
||||||
|
"requires": {
|
||||||
|
"@cargo-messages/android-arm-eabi": "0.0.160",
|
||||||
|
"@cargo-messages/darwin-arm64": "0.0.160",
|
||||||
|
"@cargo-messages/darwin-x64": "0.0.160",
|
||||||
|
"@cargo-messages/linux-arm-gnueabihf": "0.0.160",
|
||||||
|
"@cargo-messages/linux-x64-gnu": "0.0.160",
|
||||||
|
"@cargo-messages/win32-arm64-msvc": "0.0.160",
|
||||||
|
"@cargo-messages/win32-x64-msvc": "0.0.160"
|
||||||
|
}
|
||||||
},
|
},
|
||||||
"@neon-rs/load": {
|
"@neon-rs/load": {
|
||||||
"version": "0.0.74",
|
"version": "0.0.74",
|
||||||
@@ -4881,6 +5110,12 @@
|
|||||||
"@types/node": "*"
|
"@types/node": "*"
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
|
"@types/uuid": {
|
||||||
|
"version": "9.0.3",
|
||||||
|
"resolved": "https://registry.npmjs.org/@types/uuid/-/uuid-9.0.3.tgz",
|
||||||
|
"integrity": "sha512-taHQQH/3ZyI3zP8M/puluDEIEvtQHVYcC6y3N8ijFtAd28+Ey/G4sg1u2gB01S8MwybLOKAp9/yCMu/uR5l3Ug==",
|
||||||
|
"dev": true
|
||||||
|
},
|
||||||
"@typescript-eslint/eslint-plugin": {
|
"@typescript-eslint/eslint-plugin": {
|
||||||
"version": "5.59.1",
|
"version": "5.59.1",
|
||||||
"resolved": "https://registry.npmjs.org/@typescript-eslint/eslint-plugin/-/eslint-plugin-5.59.1.tgz",
|
"resolved": "https://registry.npmjs.org/@typescript-eslint/eslint-plugin/-/eslint-plugin-5.59.1.tgz",
|
||||||
@@ -7632,30 +7867,18 @@
|
|||||||
"punycode": "^2.1.0"
|
"punycode": "^2.1.0"
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
|
"uuid": {
|
||||||
|
"version": "9.0.0",
|
||||||
|
"resolved": "https://registry.npmjs.org/uuid/-/uuid-9.0.0.tgz",
|
||||||
|
"integrity": "sha512-MXcSTerfPa4uqyzStbRoTgt5XIe3x5+42+q1sDuy3R5MDk66URdLMOZe5aPX/SQd+kuYAh0FdP/pO28IkQyTeg==",
|
||||||
|
"dev": true
|
||||||
|
},
|
||||||
"v8-compile-cache-lib": {
|
"v8-compile-cache-lib": {
|
||||||
"version": "3.0.1",
|
"version": "3.0.1",
|
||||||
"resolved": "https://registry.npmjs.org/v8-compile-cache-lib/-/v8-compile-cache-lib-3.0.1.tgz",
|
"resolved": "https://registry.npmjs.org/v8-compile-cache-lib/-/v8-compile-cache-lib-3.0.1.tgz",
|
||||||
"integrity": "sha512-wa7YjyUGfNZngI/vtK0UHAN+lgDCxBPCylVXGp0zu59Fz5aiGtNXaq3DhIov063MorB+VfufLh3JlF2KdTK3xg==",
|
"integrity": "sha512-wa7YjyUGfNZngI/vtK0UHAN+lgDCxBPCylVXGp0zu59Fz5aiGtNXaq3DhIov063MorB+VfufLh3JlF2KdTK3xg==",
|
||||||
"dev": true
|
"dev": true
|
||||||
},
|
},
|
||||||
"vectordb-darwin-arm64": {
|
|
||||||
"version": "0.1.14",
|
|
||||||
"resolved": "https://registry.npmjs.org/vectordb-darwin-arm64/-/vectordb-darwin-arm64-0.1.14.tgz",
|
|
||||||
"integrity": "sha512-5doSFMUR4scxseo73thCxScmO3Wpb+cqPsIa7+2uneTEtBSViMbkw/1mGTC+rV4NTCnxhoiqHk9pJzZVeDMkPg==",
|
|
||||||
"optional": true
|
|
||||||
},
|
|
||||||
"vectordb-darwin-x64": {
|
|
||||||
"version": "0.1.14",
|
|
||||||
"resolved": "https://registry.npmjs.org/vectordb-darwin-x64/-/vectordb-darwin-x64-0.1.14.tgz",
|
|
||||||
"integrity": "sha512-x+qVaKNhAG65HdENL6GRJjxl1hZ7erRm3a2rhplyYoQyzuRPPBILeWzxkE01G1fb0+47dehe7Q4f/8BDaghcCQ==",
|
|
||||||
"optional": true
|
|
||||||
},
|
|
||||||
"vectordb-linux-x64-gnu": {
|
|
||||||
"version": "0.1.14",
|
|
||||||
"resolved": "https://registry.npmjs.org/vectordb-linux-x64-gnu/-/vectordb-linux-x64-gnu-0.1.14.tgz",
|
|
||||||
"integrity": "sha512-hvA2YYwTZK92k6nPH99Jn5N0CwagDOdnwMmjtCpzFOEYK7dY/2kcTOoQNlBwwNP9MYvgN6jdFD/Cwkih1X/qjA==",
|
|
||||||
"optional": true
|
|
||||||
},
|
|
||||||
"vscode-oniguruma": {
|
"vscode-oniguruma": {
|
||||||
"version": "1.7.0",
|
"version": "1.7.0",
|
||||||
"resolved": "https://registry.npmjs.org/vscode-oniguruma/-/vscode-oniguruma-1.7.0.tgz",
|
"resolved": "https://registry.npmjs.org/vscode-oniguruma/-/vscode-oniguruma-1.7.0.tgz",
|
||||||
|
|||||||
@@ -1,6 +1,6 @@
|
|||||||
{
|
{
|
||||||
"name": "vectordb",
|
"name": "vectordb",
|
||||||
"version": "0.1.14",
|
"version": "0.2.6",
|
||||||
"description": " Serverless, low-latency vector database for AI applications",
|
"description": " Serverless, low-latency vector database for AI applications",
|
||||||
"main": "dist/index.js",
|
"main": "dist/index.js",
|
||||||
"types": "dist/index.d.ts",
|
"types": "dist/index.d.ts",
|
||||||
@@ -9,7 +9,8 @@
|
|||||||
"build": "cargo-cp-artifact --artifact cdylib vectordb-node index.node -- cargo build --message-format=json",
|
"build": "cargo-cp-artifact --artifact cdylib vectordb-node index.node -- cargo build --message-format=json",
|
||||||
"build-release": "npm run build -- --release",
|
"build-release": "npm run build -- --release",
|
||||||
"test": "npm run tsc && mocha -recursive dist/test",
|
"test": "npm run tsc && mocha -recursive dist/test",
|
||||||
"lint": "eslint src --ext .js,.ts",
|
"integration-test": "npm run tsc && mocha -recursive dist/integration_test",
|
||||||
|
"lint": "eslint native.js src --ext .js,.ts",
|
||||||
"clean": "rm -rf node_modules *.node dist/",
|
"clean": "rm -rf node_modules *.node dist/",
|
||||||
"pack-build": "neon pack-build",
|
"pack-build": "neon pack-build",
|
||||||
"check-npm": "printenv && which node && which npm && npm --version"
|
"check-npm": "printenv && which node && which npm && npm --version"
|
||||||
@@ -27,13 +28,14 @@
|
|||||||
"author": "Lance Devs",
|
"author": "Lance Devs",
|
||||||
"license": "Apache-2.0",
|
"license": "Apache-2.0",
|
||||||
"devDependencies": {
|
"devDependencies": {
|
||||||
"@neon-rs/cli": "^0.0.74",
|
"@neon-rs/cli": "^0.0.160",
|
||||||
"@types/chai": "^4.3.4",
|
"@types/chai": "^4.3.4",
|
||||||
"@types/chai-as-promised": "^7.1.5",
|
"@types/chai-as-promised": "^7.1.5",
|
||||||
"@types/mocha": "^10.0.1",
|
"@types/mocha": "^10.0.1",
|
||||||
"@types/node": "^18.16.2",
|
"@types/node": "^18.16.2",
|
||||||
"@types/sinon": "^10.0.15",
|
"@types/sinon": "^10.0.15",
|
||||||
"@types/temp": "^0.9.1",
|
"@types/temp": "^0.9.1",
|
||||||
|
"@types/uuid": "^9.0.3",
|
||||||
"@typescript-eslint/eslint-plugin": "^5.59.1",
|
"@typescript-eslint/eslint-plugin": "^5.59.1",
|
||||||
"cargo-cp-artifact": "^0.1",
|
"cargo-cp-artifact": "^0.1",
|
||||||
"chai": "^4.3.7",
|
"chai": "^4.3.7",
|
||||||
@@ -51,7 +53,8 @@
|
|||||||
"ts-node-dev": "^2.0.0",
|
"ts-node-dev": "^2.0.0",
|
||||||
"typedoc": "^0.24.7",
|
"typedoc": "^0.24.7",
|
||||||
"typedoc-plugin-markdown": "^3.15.3",
|
"typedoc-plugin-markdown": "^3.15.3",
|
||||||
"typescript": "*"
|
"typescript": "*",
|
||||||
|
"uuid": "^9.0.0"
|
||||||
},
|
},
|
||||||
"dependencies": {
|
"dependencies": {
|
||||||
"@apache-arrow/ts": "^12.0.0",
|
"@apache-arrow/ts": "^12.0.0",
|
||||||
@@ -70,18 +73,18 @@
|
|||||||
],
|
],
|
||||||
"neon": {
|
"neon": {
|
||||||
"targets": {
|
"targets": {
|
||||||
"x86_64-apple-darwin": "vectordb-darwin-x64",
|
"x86_64-apple-darwin": "@lancedb/vectordb-darwin-x64",
|
||||||
"aarch64-apple-darwin": "vectordb-darwin-arm64",
|
"aarch64-apple-darwin": "@lancedb/vectordb-darwin-arm64",
|
||||||
"x86_64-unknown-linux-gnu": "vectordb-linux-x64-gnu",
|
"x86_64-unknown-linux-gnu": "@lancedb/vectordb-linux-x64-gnu",
|
||||||
"aarch64-unknown-linux-gnu": "vectordb-linux-arm64-gnu",
|
"aarch64-unknown-linux-gnu": "@lancedb/vectordb-linux-arm64-gnu",
|
||||||
"x86_64-pc-windows-msvc": "vectordb-win32-x64-msvc"
|
"x86_64-pc-windows-msvc": "@lancedb/vectordb-win32-x64-msvc"
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"optionalDependencies": {
|
"optionalDependencies": {
|
||||||
"vectordb-darwin-arm64": "0.1.14",
|
"@lancedb/vectordb-darwin-arm64": "0.2.6",
|
||||||
"vectordb-darwin-x64": "0.1.14",
|
"@lancedb/vectordb-darwin-x64": "0.2.6",
|
||||||
"vectordb-linux-arm64-gnu": "0.1.14",
|
"@lancedb/vectordb-linux-arm64-gnu": "0.2.6",
|
||||||
"vectordb-linux-x64-gnu": "0.1.14",
|
"@lancedb/vectordb-linux-x64-gnu": "0.2.6",
|
||||||
"vectordb-win32-x64-msvc": "0.1.14"
|
"@lancedb/vectordb-win32-x64-msvc": "0.2.6"
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|||||||
@@ -13,18 +13,19 @@
|
|||||||
// limitations under the License.
|
// limitations under the License.
|
||||||
|
|
||||||
import {
|
import {
|
||||||
Field,
|
Field, type FixedSizeListBuilder,
|
||||||
Float32,
|
Float32,
|
||||||
List, type ListBuilder,
|
|
||||||
makeBuilder,
|
makeBuilder,
|
||||||
RecordBatchFileWriter,
|
RecordBatchFileWriter,
|
||||||
Table, Utf8,
|
Utf8,
|
||||||
type Vector,
|
type Vector,
|
||||||
vectorFromArray
|
FixedSizeList,
|
||||||
|
vectorFromArray, type Schema, Table as ArrowTable
|
||||||
} from 'apache-arrow'
|
} from 'apache-arrow'
|
||||||
import { type EmbeddingFunction } from './index'
|
import { type EmbeddingFunction } from './index'
|
||||||
|
|
||||||
export async function convertToTable<T> (data: Array<Record<string, unknown>>, embeddings?: EmbeddingFunction<T>): Promise<Table> {
|
// Converts an Array of records into an Arrow Table, optionally applying an embeddings function to it.
|
||||||
|
export async function convertToTable<T> (data: Array<Record<string, unknown>>, embeddings?: EmbeddingFunction<T>): Promise<ArrowTable> {
|
||||||
if (data.length === 0) {
|
if (data.length === 0) {
|
||||||
throw new Error('At least one record needs to be provided')
|
throw new Error('At least one record needs to be provided')
|
||||||
}
|
}
|
||||||
@@ -34,8 +35,8 @@ export async function convertToTable<T> (data: Array<Record<string, unknown>>, e
|
|||||||
|
|
||||||
for (const columnsKey of columns) {
|
for (const columnsKey of columns) {
|
||||||
if (columnsKey === 'vector') {
|
if (columnsKey === 'vector') {
|
||||||
const listBuilder = newVectorListBuilder()
|
|
||||||
const vectorSize = (data[0].vector as any[]).length
|
const vectorSize = (data[0].vector as any[]).length
|
||||||
|
const listBuilder = newVectorBuilder(vectorSize)
|
||||||
for (const datum of data) {
|
for (const datum of data) {
|
||||||
if ((datum[columnsKey] as any[]).length !== vectorSize) {
|
if ((datum[columnsKey] as any[]).length !== vectorSize) {
|
||||||
throw new Error(`Invalid vector size, expected ${vectorSize}`)
|
throw new Error(`Invalid vector size, expected ${vectorSize}`)
|
||||||
@@ -52,9 +53,7 @@ export async function convertToTable<T> (data: Array<Record<string, unknown>>, e
|
|||||||
|
|
||||||
if (columnsKey === embeddings?.sourceColumn) {
|
if (columnsKey === embeddings?.sourceColumn) {
|
||||||
const vectors = await embeddings.embed(values as T[])
|
const vectors = await embeddings.embed(values as T[])
|
||||||
const listBuilder = newVectorListBuilder()
|
records.vector = vectorFromArray(vectors, newVectorType(vectors[0].length))
|
||||||
vectors.map(v => listBuilder.append(v))
|
|
||||||
records.vector = listBuilder.finish().toVector()
|
|
||||||
}
|
}
|
||||||
|
|
||||||
if (typeof values[0] === 'string') {
|
if (typeof values[0] === 'string') {
|
||||||
@@ -66,20 +65,47 @@ export async function convertToTable<T> (data: Array<Record<string, unknown>>, e
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
return new Table(records)
|
return new ArrowTable(records)
|
||||||
}
|
}
|
||||||
|
|
||||||
// Creates a new Arrow ListBuilder that stores a Vector column
|
// Creates a new Arrow ListBuilder that stores a Vector column
|
||||||
function newVectorListBuilder (): ListBuilder<Float32, any> {
|
function newVectorBuilder (dim: number): FixedSizeListBuilder<Float32> {
|
||||||
const children = new Field<Float32>('item', new Float32())
|
|
||||||
const list = new List(children)
|
|
||||||
return makeBuilder({
|
return makeBuilder({
|
||||||
type: list
|
type: newVectorType(dim)
|
||||||
})
|
})
|
||||||
}
|
}
|
||||||
|
|
||||||
|
// Creates the Arrow Type for a Vector column with dimension `dim`
|
||||||
|
function newVectorType (dim: number): FixedSizeList<Float32> {
|
||||||
|
const children = new Field<Float32>('item', new Float32())
|
||||||
|
return new FixedSizeList(dim, children)
|
||||||
|
}
|
||||||
|
|
||||||
|
// Converts an Array of records into Arrow IPC format
|
||||||
export async function fromRecordsToBuffer<T> (data: Array<Record<string, unknown>>, embeddings?: EmbeddingFunction<T>): Promise<Buffer> {
|
export async function fromRecordsToBuffer<T> (data: Array<Record<string, unknown>>, embeddings?: EmbeddingFunction<T>): Promise<Buffer> {
|
||||||
const table = await convertToTable(data, embeddings)
|
const table = await convertToTable(data, embeddings)
|
||||||
const writer = RecordBatchFileWriter.writeAll(table)
|
const writer = RecordBatchFileWriter.writeAll(table)
|
||||||
return Buffer.from(await writer.toUint8Array())
|
return Buffer.from(await writer.toUint8Array())
|
||||||
}
|
}
|
||||||
|
|
||||||
|
// Converts an Arrow Table into Arrow IPC format
|
||||||
|
export async function fromTableToBuffer<T> (table: ArrowTable, embeddings?: EmbeddingFunction<T>): Promise<Buffer> {
|
||||||
|
if (embeddings !== undefined) {
|
||||||
|
const source = table.getChild(embeddings.sourceColumn)
|
||||||
|
|
||||||
|
if (source === null) {
|
||||||
|
throw new Error(`The embedding source column ${embeddings.sourceColumn} was not found in the Arrow Table`)
|
||||||
|
}
|
||||||
|
|
||||||
|
const vectors = await embeddings.embed(source.toArray() as T[])
|
||||||
|
const column = vectorFromArray(vectors, newVectorType(vectors[0].length))
|
||||||
|
table = table.assign(new ArrowTable({ vector: column }))
|
||||||
|
}
|
||||||
|
const writer = RecordBatchFileWriter.writeAll(table)
|
||||||
|
return Buffer.from(await writer.toUint8Array())
|
||||||
|
}
|
||||||
|
|
||||||
|
// Creates an empty Arrow Table
|
||||||
|
export function createEmptyTable (schema: Schema): ArrowTable {
|
||||||
|
return new ArrowTable(schema)
|
||||||
|
}
|
||||||
|
|||||||
@@ -26,3 +26,8 @@ export interface EmbeddingFunction<T> {
|
|||||||
*/
|
*/
|
||||||
embed: (data: T[]) => Promise<number[][]>
|
embed: (data: T[]) => Promise<number[][]>
|
||||||
}
|
}
|
||||||
|
|
||||||
|
export function isEmbeddingFunction<T> (value: any): value is EmbeddingFunction<T> {
|
||||||
|
return typeof value.sourceColumn === 'string' &&
|
||||||
|
typeof value.embed === 'function'
|
||||||
|
}
|
||||||
|
|||||||
@@ -13,17 +13,19 @@
|
|||||||
// limitations under the License.
|
// limitations under the License.
|
||||||
|
|
||||||
import {
|
import {
|
||||||
RecordBatchFileWriter,
|
type Schema,
|
||||||
type Table as ArrowTable
|
Table as ArrowTable
|
||||||
} from 'apache-arrow'
|
} from 'apache-arrow'
|
||||||
import { fromRecordsToBuffer } from './arrow'
|
import { createEmptyTable, fromRecordsToBuffer, fromTableToBuffer } from './arrow'
|
||||||
import type { EmbeddingFunction } from './embedding/embedding_function'
|
import type { EmbeddingFunction } from './embedding/embedding_function'
|
||||||
import { RemoteConnection } from './remote'
|
import { RemoteConnection } from './remote'
|
||||||
import { Query } from './query'
|
import { Query } from './query'
|
||||||
|
import { isEmbeddingFunction } from './embedding/embedding_function'
|
||||||
|
|
||||||
// eslint-disable-next-line @typescript-eslint/no-var-requires
|
// eslint-disable-next-line @typescript-eslint/no-var-requires
|
||||||
const { databaseNew, databaseTableNames, databaseOpenTable, databaseDropTable, tableCreate, tableAdd, tableCreateVectorIndex, tableCountRows, tableDelete } = require('../native.js')
|
const { databaseNew, databaseTableNames, databaseOpenTable, databaseDropTable, tableCreate, tableAdd, tableCreateVectorIndex, tableCountRows, tableDelete } = require('../native.js')
|
||||||
|
|
||||||
|
export { Query }
|
||||||
export type { EmbeddingFunction }
|
export type { EmbeddingFunction }
|
||||||
export { OpenAIEmbeddingFunction } from './embedding/openai'
|
export { OpenAIEmbeddingFunction } from './embedding/openai'
|
||||||
|
|
||||||
@@ -40,10 +42,49 @@ export interface ConnectionOptions {
|
|||||||
|
|
||||||
awsCredentials?: AwsCredentials
|
awsCredentials?: AwsCredentials
|
||||||
|
|
||||||
|
awsRegion?: string
|
||||||
|
|
||||||
// API key for the remote connections
|
// API key for the remote connections
|
||||||
apiKey?: string
|
apiKey?: string
|
||||||
// Region to connect
|
// Region to connect
|
||||||
region?: string
|
region?: string
|
||||||
|
|
||||||
|
// override the host for the remote connections
|
||||||
|
hostOverride?: string
|
||||||
|
}
|
||||||
|
|
||||||
|
function getAwsArgs (opts: ConnectionOptions): any[] {
|
||||||
|
const callArgs = []
|
||||||
|
const awsCredentials = opts.awsCredentials
|
||||||
|
if (awsCredentials !== undefined) {
|
||||||
|
callArgs.push(awsCredentials.accessKeyId)
|
||||||
|
callArgs.push(awsCredentials.secretKey)
|
||||||
|
callArgs.push(awsCredentials.sessionToken)
|
||||||
|
} else {
|
||||||
|
callArgs.push(undefined)
|
||||||
|
callArgs.push(undefined)
|
||||||
|
callArgs.push(undefined)
|
||||||
|
}
|
||||||
|
|
||||||
|
callArgs.push(opts.awsRegion)
|
||||||
|
return callArgs
|
||||||
|
}
|
||||||
|
|
||||||
|
export interface CreateTableOptions<T> {
|
||||||
|
// Name of Table
|
||||||
|
name: string
|
||||||
|
|
||||||
|
// Data to insert into the Table
|
||||||
|
data?: Array<Record<string, unknown>> | ArrowTable | undefined
|
||||||
|
|
||||||
|
// Optional Arrow Schema for this table
|
||||||
|
schema?: Schema | undefined
|
||||||
|
|
||||||
|
// Optional embedding function used to create embeddings
|
||||||
|
embeddingFunction?: EmbeddingFunction<T> | undefined
|
||||||
|
|
||||||
|
// WriteOptions for this operation
|
||||||
|
writeOptions?: WriteOptions | undefined
|
||||||
}
|
}
|
||||||
|
|
||||||
/**
|
/**
|
||||||
@@ -92,17 +133,51 @@ export interface Connection {
|
|||||||
*/
|
*/
|
||||||
openTable<T>(name: string, embeddings?: EmbeddingFunction<T>): Promise<Table<T>>
|
openTable<T>(name: string, embeddings?: EmbeddingFunction<T>): Promise<Table<T>>
|
||||||
|
|
||||||
|
/**
|
||||||
|
* Creates a new Table, optionally initializing it with new data.
|
||||||
|
*
|
||||||
|
* @param {string} name - The name of the table.
|
||||||
|
* @param data - Array of Records to be inserted into the table
|
||||||
|
* @param schema - An Arrow Schema that describe this table columns
|
||||||
|
* @param {EmbeddingFunction} embeddings - An embedding function to use on this table
|
||||||
|
* @param {WriteOptions} writeOptions - The write options to use when creating the table.
|
||||||
|
*/
|
||||||
|
createTable<T> ({ name, data, schema, embeddingFunction, writeOptions }: CreateTableOptions<T>): Promise<Table<T>>
|
||||||
|
|
||||||
|
/**
|
||||||
|
* Creates a new Table and initialize it with new data.
|
||||||
|
*
|
||||||
|
* @param {string} name - The name of the table.
|
||||||
|
* @param data - Non-empty Array of Records to be inserted into the table
|
||||||
|
*/
|
||||||
|
createTable (name: string, data: Array<Record<string, unknown>>): Promise<Table>
|
||||||
|
|
||||||
|
/**
|
||||||
|
* Creates a new Table and initialize it with new data.
|
||||||
|
*
|
||||||
|
* @param {string} name - The name of the table.
|
||||||
|
* @param data - Non-empty Array of Records to be inserted into the table
|
||||||
|
* @param {WriteOptions} options - The write options to use when creating the table.
|
||||||
|
*/
|
||||||
|
createTable (name: string, data: Array<Record<string, unknown>>, options: WriteOptions): Promise<Table>
|
||||||
|
|
||||||
/**
|
/**
|
||||||
* Creates a new Table and initialize it with new data.
|
* Creates a new Table and initialize it with new data.
|
||||||
*
|
*
|
||||||
* @param {string} name - The name of the table.
|
* @param {string} name - The name of the table.
|
||||||
* @param data - Non-empty Array of Records to be inserted into the table
|
* @param data - Non-empty Array of Records to be inserted into the table
|
||||||
* @param {WriteMode} mode - The write mode to use when creating the table.
|
|
||||||
* @param {EmbeddingFunction} embeddings - An embedding function to use on this table
|
* @param {EmbeddingFunction} embeddings - An embedding function to use on this table
|
||||||
*/
|
*/
|
||||||
createTable<T>(name: string, data: Array<Record<string, unknown>>, mode?: WriteMode, embeddings?: EmbeddingFunction<T>): Promise<Table<T>>
|
createTable<T> (name: string, data: Array<Record<string, unknown>>, embeddings: EmbeddingFunction<T>): Promise<Table<T>>
|
||||||
|
/**
|
||||||
createTableArrow(name: string, table: ArrowTable): Promise<Table>
|
* Creates a new Table and initialize it with new data.
|
||||||
|
*
|
||||||
|
* @param {string} name - The name of the table.
|
||||||
|
* @param data - Non-empty Array of Records to be inserted into the table
|
||||||
|
* @param {EmbeddingFunction} embeddings - An embedding function to use on this table
|
||||||
|
* @param {WriteOptions} options - The write options to use when creating the table.
|
||||||
|
*/
|
||||||
|
createTable<T> (name: string, data: Array<Record<string, unknown>>, embeddings: EmbeddingFunction<T>, options: WriteOptions): Promise<Table<T>>
|
||||||
|
|
||||||
/**
|
/**
|
||||||
* Drop an existing table.
|
* Drop an existing table.
|
||||||
@@ -191,16 +266,16 @@ export interface Table<T = number[]> {
|
|||||||
* A connection to a LanceDB database.
|
* A connection to a LanceDB database.
|
||||||
*/
|
*/
|
||||||
export class LocalConnection implements Connection {
|
export class LocalConnection implements Connection {
|
||||||
private readonly _options: ConnectionOptions
|
private readonly _options: () => ConnectionOptions
|
||||||
private readonly _db: any
|
private readonly _db: any
|
||||||
|
|
||||||
constructor (db: any, options: ConnectionOptions) {
|
constructor (db: any, options: ConnectionOptions) {
|
||||||
this._options = options
|
this._options = () => options
|
||||||
this._db = db
|
this._db = db
|
||||||
}
|
}
|
||||||
|
|
||||||
get uri (): string {
|
get uri (): string {
|
||||||
return this._options.uri
|
return this._options().uri
|
||||||
}
|
}
|
||||||
|
|
||||||
/**
|
/**
|
||||||
@@ -226,61 +301,66 @@ export class LocalConnection implements Connection {
|
|||||||
async openTable<T> (name: string, embeddings: EmbeddingFunction<T>): Promise<Table<T>>
|
async openTable<T> (name: string, embeddings: EmbeddingFunction<T>): Promise<Table<T>>
|
||||||
async openTable<T> (name: string, embeddings?: EmbeddingFunction<T>): Promise<Table<T>>
|
async openTable<T> (name: string, embeddings?: EmbeddingFunction<T>): Promise<Table<T>>
|
||||||
async openTable<T> (name: string, embeddings?: EmbeddingFunction<T>): Promise<Table<T>> {
|
async openTable<T> (name: string, embeddings?: EmbeddingFunction<T>): Promise<Table<T>> {
|
||||||
const tbl = await databaseOpenTable.call(this._db, name)
|
const tbl = await databaseOpenTable.call(this._db, name, ...getAwsArgs(this._options()))
|
||||||
if (embeddings !== undefined) {
|
if (embeddings !== undefined) {
|
||||||
return new LocalTable(tbl, name, this._options, embeddings)
|
return new LocalTable(tbl, name, this._options(), embeddings)
|
||||||
} else {
|
} else {
|
||||||
return new LocalTable(tbl, name, this._options)
|
return new LocalTable(tbl, name, this._options())
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
/**
|
async createTable<T> (name: string | CreateTableOptions<T>, data?: Array<Record<string, unknown>>, optsOrEmbedding?: WriteOptions | EmbeddingFunction<T>, opt?: WriteOptions): Promise<Table<T>> {
|
||||||
* Creates a new Table and initialize it with new data.
|
if (typeof name === 'string') {
|
||||||
*
|
let writeOptions: WriteOptions = new DefaultWriteOptions()
|
||||||
* @param name The name of the table.
|
if (opt !== undefined && isWriteOptions(opt)) {
|
||||||
* @param data Non-empty Array of Records to be inserted into the Table
|
writeOptions = opt
|
||||||
* @param mode The write mode to use when creating the table.
|
} else if (optsOrEmbedding !== undefined && isWriteOptions(optsOrEmbedding)) {
|
||||||
*/
|
writeOptions = optsOrEmbedding
|
||||||
async createTable (name: string, data: Array<Record<string, unknown>>, mode?: WriteMode): Promise<Table>
|
|
||||||
async createTable (name: string, data: Array<Record<string, unknown>>, mode: WriteMode): Promise<Table>
|
|
||||||
|
|
||||||
/**
|
|
||||||
* Creates a new Table and initialize it with new data.
|
|
||||||
*
|
|
||||||
* @param name The name of the table.
|
|
||||||
* @param data Non-empty Array of Records to be inserted into the Table
|
|
||||||
* @param mode The write mode to use when creating the table.
|
|
||||||
* @param embeddings An embedding function to use on this Table
|
|
||||||
*/
|
|
||||||
async createTable<T> (name: string, data: Array<Record<string, unknown>>, mode: WriteMode, embeddings: EmbeddingFunction<T>): Promise<Table<T>>
|
|
||||||
async createTable<T> (name: string, data: Array<Record<string, unknown>>, mode: WriteMode, embeddings?: EmbeddingFunction<T>): Promise<Table<T>>
|
|
||||||
async createTable<T> (name: string, data: Array<Record<string, unknown>>, mode: WriteMode, embeddings?: EmbeddingFunction<T>): Promise<Table<T>> {
|
|
||||||
if (mode === undefined) {
|
|
||||||
mode = WriteMode.Create
|
|
||||||
}
|
|
||||||
|
|
||||||
const createArgs = [this._db, name, await fromRecordsToBuffer(data, embeddings), mode.toLowerCase()]
|
|
||||||
if (this._options.awsCredentials !== undefined) {
|
|
||||||
createArgs.push(this._options.awsCredentials.accessKeyId)
|
|
||||||
createArgs.push(this._options.awsCredentials.secretKey)
|
|
||||||
if (this._options.awsCredentials.sessionToken !== undefined) {
|
|
||||||
createArgs.push(this._options.awsCredentials.sessionToken)
|
|
||||||
}
|
}
|
||||||
}
|
|
||||||
|
|
||||||
const tbl = await tableCreate.call(...createArgs)
|
let embeddings: undefined | EmbeddingFunction<T>
|
||||||
|
if (optsOrEmbedding !== undefined && isEmbeddingFunction(optsOrEmbedding)) {
|
||||||
if (embeddings !== undefined) {
|
embeddings = optsOrEmbedding
|
||||||
return new LocalTable(tbl, name, this._options, embeddings)
|
}
|
||||||
} else {
|
return await this.createTableImpl({ name, data, embeddingFunction: embeddings, writeOptions })
|
||||||
return new LocalTable(tbl, name, this._options)
|
|
||||||
}
|
}
|
||||||
|
return await this.createTableImpl(name)
|
||||||
}
|
}
|
||||||
|
|
||||||
async createTableArrow (name: string, table: ArrowTable): Promise<Table> {
|
private async createTableImpl<T> ({ name, data, schema, embeddingFunction, writeOptions = new DefaultWriteOptions() }: {
|
||||||
const writer = RecordBatchFileWriter.writeAll(table)
|
name: string
|
||||||
await tableCreate.call(this._db, name, Buffer.from(await writer.toUint8Array()))
|
data?: Array<Record<string, unknown>> | ArrowTable | undefined
|
||||||
return await this.openTable(name)
|
schema?: Schema | undefined
|
||||||
|
embeddingFunction?: EmbeddingFunction<T> | undefined
|
||||||
|
writeOptions?: WriteOptions | undefined
|
||||||
|
}): Promise<Table<T>> {
|
||||||
|
let buffer: Buffer
|
||||||
|
|
||||||
|
function isEmpty (data: Array<Record<string, unknown>> | ArrowTable<any>): boolean {
|
||||||
|
if (data instanceof ArrowTable) {
|
||||||
|
return data.data.length === 0
|
||||||
|
}
|
||||||
|
return data.length === 0
|
||||||
|
}
|
||||||
|
|
||||||
|
if ((data === undefined) || isEmpty(data)) {
|
||||||
|
if (schema === undefined) {
|
||||||
|
throw new Error('Either data or schema needs to defined')
|
||||||
|
}
|
||||||
|
buffer = await fromTableToBuffer(createEmptyTable(schema))
|
||||||
|
} else if (data instanceof ArrowTable) {
|
||||||
|
buffer = await fromTableToBuffer(data, embeddingFunction)
|
||||||
|
} else {
|
||||||
|
// data is Array<Record<...>>
|
||||||
|
buffer = await fromRecordsToBuffer(data, embeddingFunction)
|
||||||
|
}
|
||||||
|
|
||||||
|
const tbl = await tableCreate.call(this._db, name, buffer, writeOptions?.writeMode?.toString(), ...getAwsArgs(this._options()))
|
||||||
|
if (embeddingFunction !== undefined) {
|
||||||
|
return new LocalTable(tbl, name, this._options(), embeddingFunction)
|
||||||
|
} else {
|
||||||
|
return new LocalTable(tbl, name, this._options())
|
||||||
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
/**
|
/**
|
||||||
@@ -293,10 +373,10 @@ export class LocalConnection implements Connection {
|
|||||||
}
|
}
|
||||||
|
|
||||||
export class LocalTable<T = number[]> implements Table<T> {
|
export class LocalTable<T = number[]> implements Table<T> {
|
||||||
private readonly _tbl: any
|
private _tbl: any
|
||||||
private readonly _name: string
|
private readonly _name: string
|
||||||
private readonly _embeddings?: EmbeddingFunction<T>
|
private readonly _embeddings?: EmbeddingFunction<T>
|
||||||
private readonly _options: ConnectionOptions
|
private readonly _options: () => ConnectionOptions
|
||||||
|
|
||||||
constructor (tbl: any, name: string, options: ConnectionOptions)
|
constructor (tbl: any, name: string, options: ConnectionOptions)
|
||||||
/**
|
/**
|
||||||
@@ -310,7 +390,7 @@ export class LocalTable<T = number[]> implements Table<T> {
|
|||||||
this._tbl = tbl
|
this._tbl = tbl
|
||||||
this._name = name
|
this._name = name
|
||||||
this._embeddings = embeddings
|
this._embeddings = embeddings
|
||||||
this._options = options
|
this._options = () => options
|
||||||
}
|
}
|
||||||
|
|
||||||
get name (): string {
|
get name (): string {
|
||||||
@@ -332,15 +412,12 @@ export class LocalTable<T = number[]> implements Table<T> {
|
|||||||
* @return The number of rows added to the table
|
* @return The number of rows added to the table
|
||||||
*/
|
*/
|
||||||
async add (data: Array<Record<string, unknown>>): Promise<number> {
|
async add (data: Array<Record<string, unknown>>): Promise<number> {
|
||||||
const callArgs = [this._tbl, await fromRecordsToBuffer(data, this._embeddings), WriteMode.Append.toString()]
|
return tableAdd.call(
|
||||||
if (this._options.awsCredentials !== undefined) {
|
this._tbl,
|
||||||
callArgs.push(this._options.awsCredentials.accessKeyId)
|
await fromRecordsToBuffer(data, this._embeddings),
|
||||||
callArgs.push(this._options.awsCredentials.secretKey)
|
WriteMode.Append.toString(),
|
||||||
if (this._options.awsCredentials.sessionToken !== undefined) {
|
...getAwsArgs(this._options())
|
||||||
callArgs.push(this._options.awsCredentials.sessionToken)
|
).then((newTable: any) => { this._tbl = newTable })
|
||||||
}
|
|
||||||
}
|
|
||||||
return tableAdd.call(...callArgs)
|
|
||||||
}
|
}
|
||||||
|
|
||||||
/**
|
/**
|
||||||
@@ -350,15 +427,12 @@ export class LocalTable<T = number[]> implements Table<T> {
|
|||||||
* @return The number of rows added to the table
|
* @return The number of rows added to the table
|
||||||
*/
|
*/
|
||||||
async overwrite (data: Array<Record<string, unknown>>): Promise<number> {
|
async overwrite (data: Array<Record<string, unknown>>): Promise<number> {
|
||||||
const callArgs = [this._tbl, await fromRecordsToBuffer(data, this._embeddings), WriteMode.Overwrite.toString()]
|
return tableAdd.call(
|
||||||
if (this._options.awsCredentials !== undefined) {
|
this._tbl,
|
||||||
callArgs.push(this._options.awsCredentials.accessKeyId)
|
await fromRecordsToBuffer(data, this._embeddings),
|
||||||
callArgs.push(this._options.awsCredentials.secretKey)
|
WriteMode.Overwrite.toString(),
|
||||||
if (this._options.awsCredentials.sessionToken !== undefined) {
|
...getAwsArgs(this._options())
|
||||||
callArgs.push(this._options.awsCredentials.sessionToken)
|
).then((newTable: any) => { this._tbl = newTable })
|
||||||
}
|
|
||||||
}
|
|
||||||
return tableAdd.call(this._tbl, await fromRecordsToBuffer(data, this._embeddings), WriteMode.Overwrite.toString())
|
|
||||||
}
|
}
|
||||||
|
|
||||||
/**
|
/**
|
||||||
@@ -367,7 +441,7 @@ export class LocalTable<T = number[]> implements Table<T> {
|
|||||||
* @param indexParams The parameters of this Index, @see VectorIndexParams.
|
* @param indexParams The parameters of this Index, @see VectorIndexParams.
|
||||||
*/
|
*/
|
||||||
async createIndex (indexParams: VectorIndexParams): Promise<any> {
|
async createIndex (indexParams: VectorIndexParams): Promise<any> {
|
||||||
return tableCreateVectorIndex.call(this._tbl, indexParams)
|
return tableCreateVectorIndex.call(this._tbl, indexParams).then((newTable: any) => { this._tbl = newTable })
|
||||||
}
|
}
|
||||||
|
|
||||||
/**
|
/**
|
||||||
@@ -383,7 +457,7 @@ export class LocalTable<T = number[]> implements Table<T> {
|
|||||||
* @param filter A filter in the same format used by a sql WHERE clause.
|
* @param filter A filter in the same format used by a sql WHERE clause.
|
||||||
*/
|
*/
|
||||||
async delete (filter: string): Promise<void> {
|
async delete (filter: string): Promise<void> {
|
||||||
return tableDelete.call(this._tbl, filter)
|
return tableDelete.call(this._tbl, filter).then((newTable: any) => { this._tbl = newTable })
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
@@ -456,6 +530,23 @@ export enum WriteMode {
|
|||||||
Append = 'append'
|
Append = 'append'
|
||||||
}
|
}
|
||||||
|
|
||||||
|
/**
|
||||||
|
* Write options when creating a Table.
|
||||||
|
*/
|
||||||
|
export interface WriteOptions {
|
||||||
|
/** A {@link WriteMode} to use on this operation */
|
||||||
|
writeMode?: WriteMode
|
||||||
|
}
|
||||||
|
|
||||||
|
export class DefaultWriteOptions implements WriteOptions {
|
||||||
|
writeMode = WriteMode.Create
|
||||||
|
}
|
||||||
|
|
||||||
|
export function isWriteOptions (value: any): value is WriteOptions {
|
||||||
|
return Object.keys(value).length === 1 &&
|
||||||
|
(value.writeMode === undefined || typeof value.writeMode === 'string')
|
||||||
|
}
|
||||||
|
|
||||||
/**
|
/**
|
||||||
* Distance metrics type.
|
* Distance metrics type.
|
||||||
*/
|
*/
|
||||||
|
|||||||
43
node/src/integration_test/test.ts
Normal file
43
node/src/integration_test/test.ts
Normal file
@@ -0,0 +1,43 @@
|
|||||||
|
// Copyright 2023 LanceDB Developers.
|
||||||
|
//
|
||||||
|
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
// you may not use this file except in compliance with the License.
|
||||||
|
// You may obtain a copy of the License at
|
||||||
|
//
|
||||||
|
// http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
//
|
||||||
|
// Unless required by applicable law or agreed to in writing, software
|
||||||
|
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
// See the License for the specific language governing permissions and
|
||||||
|
// limitations under the License.
|
||||||
|
|
||||||
|
import { describe } from 'mocha'
|
||||||
|
import * as chai from 'chai'
|
||||||
|
import * as chaiAsPromised from 'chai-as-promised'
|
||||||
|
import { v4 as uuidv4 } from 'uuid'
|
||||||
|
|
||||||
|
import * as lancedb from '../index'
|
||||||
|
|
||||||
|
const assert = chai.assert
|
||||||
|
chai.use(chaiAsPromised)
|
||||||
|
|
||||||
|
describe('LanceDB AWS Integration test', function () {
|
||||||
|
it('s3+ddb schema is processed correctly', async function () {
|
||||||
|
this.timeout(15000)
|
||||||
|
|
||||||
|
// WARNING: specifying engine is NOT a publicly supported feature in lancedb yet
|
||||||
|
// THE API WILL CHANGE
|
||||||
|
const conn = await lancedb.connect('s3://lancedb-integtest?engine=ddb&ddbTableName=lancedb-integtest')
|
||||||
|
const data = [{ vector: Array(128).fill(1.0) }]
|
||||||
|
|
||||||
|
const tableName = uuidv4()
|
||||||
|
let table = await conn.createTable(tableName, data, { writeMode: lancedb.WriteMode.Overwrite })
|
||||||
|
|
||||||
|
const futs = [table.add(data), table.add(data), table.add(data), table.add(data), table.add(data)]
|
||||||
|
await Promise.allSettled(futs)
|
||||||
|
|
||||||
|
table = await conn.openTable(tableName)
|
||||||
|
assert.equal(await table.countRows(), 6)
|
||||||
|
})
|
||||||
|
})
|
||||||
@@ -112,7 +112,8 @@ export class Query<T = number[]> {
|
|||||||
this._queryVector = this._query as number[]
|
this._queryVector = this._query as number[]
|
||||||
}
|
}
|
||||||
|
|
||||||
const buffer = await tableSearch.call(this._tbl, this)
|
const isElectron = this.isElectron()
|
||||||
|
const buffer = await tableSearch.call(this._tbl, this, isElectron)
|
||||||
const data = tableFromIPC(buffer)
|
const data = tableFromIPC(buffer)
|
||||||
|
|
||||||
return data.toArray().map((entry: Record<string, unknown>) => {
|
return data.toArray().map((entry: Record<string, unknown>) => {
|
||||||
@@ -127,4 +128,14 @@ export class Query<T = number[]> {
|
|||||||
return newObject as unknown as T
|
return newObject as unknown as T
|
||||||
})
|
})
|
||||||
}
|
}
|
||||||
|
|
||||||
|
// See https://github.com/electron/electron/issues/2288
|
||||||
|
private isElectron (): boolean {
|
||||||
|
try {
|
||||||
|
// eslint-disable-next-line no-prototype-builtins
|
||||||
|
return (process?.versions?.hasOwnProperty('electron') || navigator?.userAgent?.toLowerCase()?.includes(' electron'))
|
||||||
|
} catch (e) {
|
||||||
|
return false
|
||||||
|
}
|
||||||
|
}
|
||||||
}
|
}
|
||||||
|
|||||||
@@ -18,9 +18,15 @@ import { tableFromIPC, type Table as ArrowTable } from 'apache-arrow'
|
|||||||
|
|
||||||
export class HttpLancedbClient {
|
export class HttpLancedbClient {
|
||||||
private readonly _url: string
|
private readonly _url: string
|
||||||
|
private readonly _apiKey: () => string
|
||||||
|
|
||||||
public constructor (url: string, private readonly _apiKey: string) {
|
public constructor (
|
||||||
|
url: string,
|
||||||
|
apiKey: string,
|
||||||
|
private readonly _dbName?: string
|
||||||
|
) {
|
||||||
this._url = url
|
this._url = url
|
||||||
|
this._apiKey = () => apiKey
|
||||||
}
|
}
|
||||||
|
|
||||||
get uri (): string {
|
get uri (): string {
|
||||||
@@ -37,7 +43,7 @@ export class HttpLancedbClient {
|
|||||||
filter?: string
|
filter?: string
|
||||||
): Promise<ArrowTable<any>> {
|
): Promise<ArrowTable<any>> {
|
||||||
const response = await axios.post(
|
const response = await axios.post(
|
||||||
`${this._url}/v1/table/${tableName}`,
|
`${this._url}/v1/table/${tableName}/query/`,
|
||||||
{
|
{
|
||||||
vector,
|
vector,
|
||||||
k,
|
k,
|
||||||
@@ -49,7 +55,8 @@ export class HttpLancedbClient {
|
|||||||
{
|
{
|
||||||
headers: {
|
headers: {
|
||||||
'Content-Type': 'application/json',
|
'Content-Type': 'application/json',
|
||||||
'x-api-key': this._apiKey
|
'x-api-key': this._apiKey(),
|
||||||
|
...(this._dbName !== undefined ? { 'x-lancedb-database': this._dbName } : {})
|
||||||
},
|
},
|
||||||
responseType: 'arraybuffer',
|
responseType: 'arraybuffer',
|
||||||
timeout: 10000
|
timeout: 10000
|
||||||
@@ -79,7 +86,7 @@ export class HttpLancedbClient {
|
|||||||
{
|
{
|
||||||
headers: {
|
headers: {
|
||||||
'Content-Type': 'application/json',
|
'Content-Type': 'application/json',
|
||||||
'x-api-key': this._apiKey
|
'x-api-key': this._apiKey()
|
||||||
},
|
},
|
||||||
params,
|
params,
|
||||||
timeout: 10000
|
timeout: 10000
|
||||||
@@ -97,4 +104,34 @@ export class HttpLancedbClient {
|
|||||||
}
|
}
|
||||||
return response
|
return response
|
||||||
}
|
}
|
||||||
|
|
||||||
|
/**
|
||||||
|
* Sent POST request.
|
||||||
|
*/
|
||||||
|
public async post (path: string, data?: any, params?: Record<string, string | number>): Promise<AxiosResponse> {
|
||||||
|
const response = await axios.post(
|
||||||
|
`${this._url}${path}`,
|
||||||
|
data,
|
||||||
|
{
|
||||||
|
headers: {
|
||||||
|
'Content-Type': 'application/json',
|
||||||
|
'x-api-key': this._apiKey(),
|
||||||
|
...(this._dbName !== undefined ? { 'x-lancedb-database': this._dbName } : {})
|
||||||
|
},
|
||||||
|
params,
|
||||||
|
timeout: 30000
|
||||||
|
}
|
||||||
|
).catch((err) => {
|
||||||
|
console.error('error: ', err)
|
||||||
|
return err.response
|
||||||
|
})
|
||||||
|
if (response.status !== 200) {
|
||||||
|
const errorData = new TextDecoder().decode(response.data)
|
||||||
|
throw new Error(
|
||||||
|
`Server Error, status: ${response.status as number}, ` +
|
||||||
|
`message: ${response.statusText as string}: ${errorData}`
|
||||||
|
)
|
||||||
|
}
|
||||||
|
return response
|
||||||
|
}
|
||||||
}
|
}
|
||||||
|
|||||||
@@ -14,11 +14,11 @@
|
|||||||
|
|
||||||
import {
|
import {
|
||||||
type EmbeddingFunction, type Table, type VectorIndexParams, type Connection,
|
type EmbeddingFunction, type Table, type VectorIndexParams, type Connection,
|
||||||
type ConnectionOptions
|
type ConnectionOptions, type CreateTableOptions, type WriteOptions
|
||||||
} from '../index'
|
} from '../index'
|
||||||
import { Query } from '../query'
|
import { Query } from '../query'
|
||||||
|
|
||||||
import { type Table as ArrowTable, Vector } from 'apache-arrow'
|
import { Vector } from 'apache-arrow'
|
||||||
import { HttpLancedbClient } from './client'
|
import { HttpLancedbClient } from './client'
|
||||||
|
|
||||||
/**
|
/**
|
||||||
@@ -37,8 +37,13 @@ export class RemoteConnection implements Connection {
|
|||||||
}
|
}
|
||||||
|
|
||||||
this._dbName = opts.uri.slice('db://'.length)
|
this._dbName = opts.uri.slice('db://'.length)
|
||||||
const server = `https://${this._dbName}.${opts.region}.api.lancedb.com`
|
let server: string
|
||||||
this._client = new HttpLancedbClient(server, opts.apiKey)
|
if (opts.hostOverride === undefined) {
|
||||||
|
server = `https://${this._dbName}.${opts.region}.api.lancedb.com`
|
||||||
|
} else {
|
||||||
|
server = opts.hostOverride
|
||||||
|
}
|
||||||
|
this._client = new HttpLancedbClient(server, opts.apiKey, opts.hostOverride === undefined ? undefined : this._dbName)
|
||||||
}
|
}
|
||||||
|
|
||||||
get uri (): string {
|
get uri (): string {
|
||||||
@@ -61,18 +66,12 @@ export class RemoteConnection implements Connection {
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
async createTable (name: string, data: Array<Record<string, unknown>>): Promise<Table>
|
async createTable<T> (name: string | CreateTableOptions<T>, data?: Array<Record<string, unknown>>, optsOrEmbedding?: WriteOptions | EmbeddingFunction<T>, opt?: WriteOptions): Promise<Table<T>> {
|
||||||
async createTable<T> (name: string, data: Array<Record<string, unknown>>, embeddings: EmbeddingFunction<T>): Promise<Table<T>>
|
|
||||||
async createTable<T> (name: string, data: Array<Record<string, unknown>>, embeddings?: EmbeddingFunction<T>): Promise<Table<T>> {
|
|
||||||
throw new Error('Not implemented')
|
|
||||||
}
|
|
||||||
|
|
||||||
async createTableArrow (name: string, table: ArrowTable): Promise<Table> {
|
|
||||||
throw new Error('Not implemented')
|
throw new Error('Not implemented')
|
||||||
}
|
}
|
||||||
|
|
||||||
async dropTable (name: string): Promise<void> {
|
async dropTable (name: string): Promise<void> {
|
||||||
throw new Error('Not implemented')
|
await this._client.post(`/v1/table/${name}/drop/`)
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
|
|||||||
@@ -16,6 +16,7 @@ import { describe } from 'mocha'
|
|||||||
import { assert } from 'chai'
|
import { assert } from 'chai'
|
||||||
|
|
||||||
import { OpenAIEmbeddingFunction } from '../../embedding/openai'
|
import { OpenAIEmbeddingFunction } from '../../embedding/openai'
|
||||||
|
import { isEmbeddingFunction } from '../../embedding/embedding_function'
|
||||||
|
|
||||||
// eslint-disable-next-line @typescript-eslint/no-var-requires
|
// eslint-disable-next-line @typescript-eslint/no-var-requires
|
||||||
const { OpenAIApi } = require('openai')
|
const { OpenAIApi } = require('openai')
|
||||||
@@ -47,4 +48,10 @@ describe('OpenAPIEmbeddings', function () {
|
|||||||
assert.deepEqual(vectors[1], stubValue.data.data[1].embedding)
|
assert.deepEqual(vectors[1], stubValue.data.data[1].embedding)
|
||||||
})
|
})
|
||||||
})
|
})
|
||||||
|
|
||||||
|
describe('isEmbeddingFunction', function () {
|
||||||
|
it('should match the isEmbeddingFunction guard', function () {
|
||||||
|
assert.isTrue(isEmbeddingFunction(new OpenAIEmbeddingFunction('text', 'sk-key')))
|
||||||
|
})
|
||||||
|
})
|
||||||
})
|
})
|
||||||
|
|||||||
@@ -47,7 +47,9 @@ describe('LanceDB S3 client', function () {
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
const table = await createTestDB(opts, 2, 20)
|
const table = await createTestDB(opts, 2, 20)
|
||||||
|
console.log(table)
|
||||||
const con = await lancedb.connect(opts)
|
const con = await lancedb.connect(opts)
|
||||||
|
console.log(con)
|
||||||
assert.equal(con.uri, opts.uri)
|
assert.equal(con.uri, opts.uri)
|
||||||
|
|
||||||
const results = await table.search([0.1, 0.3]).limit(5).execute()
|
const results = await table.search([0.1, 0.3]).limit(5).execute()
|
||||||
@@ -70,5 +72,5 @@ async function createTestDB (opts: ConnectionOptions, numDimensions: number = 2,
|
|||||||
data.push({ id: i + 1, name: `name_${i}`, price: i + 10, is_active: (i % 2 === 0), vector })
|
data.push({ id: i + 1, name: `name_${i}`, price: i + 10, is_active: (i % 2 === 0), vector })
|
||||||
}
|
}
|
||||||
|
|
||||||
return await con.createTable('vectors', data)
|
return await con.createTable('vectors_2', data)
|
||||||
}
|
}
|
||||||
|
|||||||
@@ -18,8 +18,8 @@ import * as chai from 'chai'
|
|||||||
import * as chaiAsPromised from 'chai-as-promised'
|
import * as chaiAsPromised from 'chai-as-promised'
|
||||||
|
|
||||||
import * as lancedb from '../index'
|
import * as lancedb from '../index'
|
||||||
import { type AwsCredentials, type EmbeddingFunction, MetricType, WriteMode } from '../index'
|
import { type AwsCredentials, type EmbeddingFunction, MetricType, Query, WriteMode, DefaultWriteOptions, isWriteOptions } from '../index'
|
||||||
import { Query } from '../query'
|
import { FixedSizeList, Field, Int32, makeVector, Schema, Utf8, Table as ArrowTable, vectorFromArray, Float32 } from 'apache-arrow'
|
||||||
|
|
||||||
const expect = chai.expect
|
const expect = chai.expect
|
||||||
const assert = chai.assert
|
const assert = chai.assert
|
||||||
@@ -108,9 +108,9 @@ describe('LanceDB client', function () {
|
|||||||
const table = await con.openTable('vectors')
|
const table = await con.openTable('vectors')
|
||||||
const results = await table.search([0.1, 0.1]).select(['is_active']).execute()
|
const results = await table.search([0.1, 0.1]).select(['is_active']).execute()
|
||||||
assert.equal(results.length, 2)
|
assert.equal(results.length, 2)
|
||||||
// vector and score are always returned
|
// vector and _distance are always returned
|
||||||
assert.isDefined(results[0].vector)
|
assert.isDefined(results[0].vector)
|
||||||
assert.isDefined(results[0].score)
|
assert.isDefined(results[0]._distance)
|
||||||
assert.isDefined(results[0].is_active)
|
assert.isDefined(results[0].is_active)
|
||||||
|
|
||||||
assert.isUndefined(results[0].id)
|
assert.isUndefined(results[0].id)
|
||||||
@@ -120,6 +120,45 @@ describe('LanceDB client', function () {
|
|||||||
})
|
})
|
||||||
|
|
||||||
describe('when creating a new dataset', function () {
|
describe('when creating a new dataset', function () {
|
||||||
|
it('create an empty table', async function () {
|
||||||
|
const dir = await track().mkdir('lancejs')
|
||||||
|
const con = await lancedb.connect(dir)
|
||||||
|
|
||||||
|
const schema = new Schema(
|
||||||
|
[new Field('id', new Int32()), new Field('name', new Utf8())]
|
||||||
|
)
|
||||||
|
const table = await con.createTable({ name: 'vectors', schema })
|
||||||
|
assert.equal(table.name, 'vectors')
|
||||||
|
assert.deepEqual(await con.tableNames(), ['vectors'])
|
||||||
|
})
|
||||||
|
|
||||||
|
it('create a table with a empty data array', async function () {
|
||||||
|
const dir = await track().mkdir('lancejs')
|
||||||
|
const con = await lancedb.connect(dir)
|
||||||
|
|
||||||
|
const schema = new Schema(
|
||||||
|
[new Field('id', new Int32()), new Field('name', new Utf8())]
|
||||||
|
)
|
||||||
|
const table = await con.createTable({ name: 'vectors', schema, data: [] })
|
||||||
|
assert.equal(table.name, 'vectors')
|
||||||
|
assert.deepEqual(await con.tableNames(), ['vectors'])
|
||||||
|
})
|
||||||
|
|
||||||
|
it('create a table from an Arrow Table', async function () {
|
||||||
|
const dir = await track().mkdir('lancejs')
|
||||||
|
const con = await lancedb.connect(dir)
|
||||||
|
|
||||||
|
const i32s = new Int32Array(new Array<number>(10))
|
||||||
|
const i32 = makeVector(i32s)
|
||||||
|
|
||||||
|
const data = new ArrowTable({ vector: i32 })
|
||||||
|
|
||||||
|
const table = await con.createTable({ name: 'vectors', data })
|
||||||
|
assert.equal(table.name, 'vectors')
|
||||||
|
assert.equal(await table.countRows(), 10)
|
||||||
|
assert.deepEqual(await con.tableNames(), ['vectors'])
|
||||||
|
})
|
||||||
|
|
||||||
it('creates a new table from javascript objects', async function () {
|
it('creates a new table from javascript objects', async function () {
|
||||||
const dir = await track().mkdir('lancejs')
|
const dir = await track().mkdir('lancejs')
|
||||||
const con = await lancedb.connect(dir)
|
const con = await lancedb.connect(dir)
|
||||||
@@ -135,6 +174,18 @@ describe('LanceDB client', function () {
|
|||||||
assert.equal(await table.countRows(), 2)
|
assert.equal(await table.countRows(), 2)
|
||||||
})
|
})
|
||||||
|
|
||||||
|
it('fails to create a new table when the vector column is missing', async function () {
|
||||||
|
const dir = await track().mkdir('lancejs')
|
||||||
|
const con = await lancedb.connect(dir)
|
||||||
|
|
||||||
|
const data = [
|
||||||
|
{ id: 1, price: 10 }
|
||||||
|
]
|
||||||
|
|
||||||
|
const create = con.createTable('missing_vector', data)
|
||||||
|
await expect(create).to.be.rejectedWith(Error, 'column \'vector\' is missing')
|
||||||
|
})
|
||||||
|
|
||||||
it('use overwrite flag to overwrite existing table', async function () {
|
it('use overwrite flag to overwrite existing table', async function () {
|
||||||
const dir = await track().mkdir('lancejs')
|
const dir = await track().mkdir('lancejs')
|
||||||
const con = await lancedb.connect(dir)
|
const con = await lancedb.connect(dir)
|
||||||
@@ -145,7 +196,7 @@ describe('LanceDB client', function () {
|
|||||||
]
|
]
|
||||||
|
|
||||||
const tableName = 'overwrite'
|
const tableName = 'overwrite'
|
||||||
await con.createTable(tableName, data, WriteMode.Create)
|
await con.createTable(tableName, data, { writeMode: WriteMode.Create })
|
||||||
|
|
||||||
const newData = [
|
const newData = [
|
||||||
{ id: 1, vector: [0.1, 0.2], price: 10 },
|
{ id: 1, vector: [0.1, 0.2], price: 10 },
|
||||||
@@ -155,7 +206,7 @@ describe('LanceDB client', function () {
|
|||||||
|
|
||||||
await expect(con.createTable(tableName, newData)).to.be.rejectedWith(Error, 'already exists')
|
await expect(con.createTable(tableName, newData)).to.be.rejectedWith(Error, 'already exists')
|
||||||
|
|
||||||
const table = await con.createTable(tableName, newData, WriteMode.Overwrite)
|
const table = await con.createTable(tableName, newData, { writeMode: WriteMode.Overwrite })
|
||||||
assert.equal(table.name, tableName)
|
assert.equal(table.name, tableName)
|
||||||
assert.equal(await table.countRows(), 3)
|
assert.equal(await table.countRows(), 3)
|
||||||
})
|
})
|
||||||
@@ -207,6 +258,36 @@ describe('LanceDB client', function () {
|
|||||||
})
|
})
|
||||||
})
|
})
|
||||||
|
|
||||||
|
describe('when searching an empty dataset', function () {
|
||||||
|
it('should not fail', async function () {
|
||||||
|
const dir = await track().mkdir('lancejs')
|
||||||
|
const con = await lancedb.connect(dir)
|
||||||
|
|
||||||
|
const schema = new Schema(
|
||||||
|
[new Field('vector', new FixedSizeList(128, new Field('float32', new Float32())))]
|
||||||
|
)
|
||||||
|
const table = await con.createTable({ name: 'vectors', schema })
|
||||||
|
const result = await table.search(Array(128).fill(0.1)).execute()
|
||||||
|
assert.isEmpty(result)
|
||||||
|
})
|
||||||
|
})
|
||||||
|
|
||||||
|
describe('when searching an empty-after-delete dataset', function () {
|
||||||
|
it('should not fail', async function () {
|
||||||
|
const dir = await track().mkdir('lancejs')
|
||||||
|
const con = await lancedb.connect(dir)
|
||||||
|
|
||||||
|
const schema = new Schema(
|
||||||
|
[new Field('vector', new FixedSizeList(128, new Field('float32', new Float32())))]
|
||||||
|
)
|
||||||
|
const table = await con.createTable({ name: 'vectors', schema })
|
||||||
|
await table.add([{ vector: Array(128).fill(0.1) }])
|
||||||
|
await table.delete('vector IS NOT NULL')
|
||||||
|
const result = await table.search(Array(128).fill(0.1)).execute()
|
||||||
|
assert.isEmpty(result)
|
||||||
|
})
|
||||||
|
})
|
||||||
|
|
||||||
describe('when creating a vector index', function () {
|
describe('when creating a vector index', function () {
|
||||||
it('overwrite all records in a table', async function () {
|
it('overwrite all records in a table', async function () {
|
||||||
const uri = await createTestDB(32, 300)
|
const uri = await createTestDB(32, 300)
|
||||||
@@ -231,6 +312,22 @@ describe('LanceDB client', function () {
|
|||||||
// Default replace = true
|
// Default replace = true
|
||||||
await table.createIndex({ type: 'ivf_pq', column: 'vector', num_partitions: 2, max_iters: 2, num_sub_vectors: 2 })
|
await table.createIndex({ type: 'ivf_pq', column: 'vector', num_partitions: 2, max_iters: 2, num_sub_vectors: 2 })
|
||||||
}).timeout(50_000)
|
}).timeout(50_000)
|
||||||
|
|
||||||
|
it('it should fail when the column is not a vector', async function () {
|
||||||
|
const uri = await createTestDB(32, 300)
|
||||||
|
const con = await lancedb.connect(uri)
|
||||||
|
const table = await con.openTable('vectors')
|
||||||
|
const createIndex = table.createIndex({ type: 'ivf_pq', column: 'name', num_partitions: 2, max_iters: 2, num_sub_vectors: 2 })
|
||||||
|
await expect(createIndex).to.be.rejectedWith(/VectorIndex requires the column data type to be fixed size list of float32s/)
|
||||||
|
})
|
||||||
|
|
||||||
|
it('it should fail when the column is not a vector', async function () {
|
||||||
|
const uri = await createTestDB(32, 300)
|
||||||
|
const con = await lancedb.connect(uri)
|
||||||
|
const table = await con.openTable('vectors')
|
||||||
|
const createIndex = table.createIndex({ type: 'ivf_pq', column: 'name', num_partitions: -1, max_iters: 2, num_sub_vectors: 2 })
|
||||||
|
await expect(createIndex).to.be.rejectedWith('num_partitions: must be > 0')
|
||||||
|
})
|
||||||
})
|
})
|
||||||
|
|
||||||
describe('when using a custom embedding function', function () {
|
describe('when using a custom embedding function', function () {
|
||||||
@@ -260,7 +357,21 @@ describe('LanceDB client', function () {
|
|||||||
{ price: 10, name: 'foo' },
|
{ price: 10, name: 'foo' },
|
||||||
{ price: 50, name: 'bar' }
|
{ price: 50, name: 'bar' }
|
||||||
]
|
]
|
||||||
const table = await con.createTable('vectors', data, WriteMode.Create, embeddings)
|
const table = await con.createTable('vectors', data, embeddings, { writeMode: WriteMode.Create })
|
||||||
|
const results = await table.search('foo').execute()
|
||||||
|
assert.equal(results.length, 2)
|
||||||
|
})
|
||||||
|
|
||||||
|
it('should create embeddings for Arrow Table', async function () {
|
||||||
|
const dir = await track().mkdir('lancejs')
|
||||||
|
const con = await lancedb.connect(dir)
|
||||||
|
const embeddingFunction = new TextEmbedding('name')
|
||||||
|
|
||||||
|
const names = vectorFromArray(['foo', 'bar'], new Utf8())
|
||||||
|
const data = new ArrowTable({ name: names })
|
||||||
|
|
||||||
|
const table = await con.createTable({ name: 'vectors', data, embeddingFunction })
|
||||||
|
assert.equal(table.name, 'vectors')
|
||||||
const results = await table.search('foo').execute()
|
const results = await table.search('foo').execute()
|
||||||
assert.equal(results.length, 2)
|
assert.equal(results.length, 2)
|
||||||
})
|
})
|
||||||
@@ -318,3 +429,20 @@ describe('Drop table', function () {
|
|||||||
assert.deepEqual(await con.tableNames(), ['t2'])
|
assert.deepEqual(await con.tableNames(), ['t2'])
|
||||||
})
|
})
|
||||||
})
|
})
|
||||||
|
|
||||||
|
describe('WriteOptions', function () {
|
||||||
|
context('#isWriteOptions', function () {
|
||||||
|
it('should not match empty object', function () {
|
||||||
|
assert.equal(isWriteOptions({}), false)
|
||||||
|
})
|
||||||
|
it('should match write options', function () {
|
||||||
|
assert.equal(isWriteOptions({ writeMode: WriteMode.Create }), true)
|
||||||
|
})
|
||||||
|
it('should match undefined write mode', function () {
|
||||||
|
assert.equal(isWriteOptions({ writeMode: undefined }), true)
|
||||||
|
})
|
||||||
|
it('should match default write options', function () {
|
||||||
|
assert.equal(isWriteOptions(new DefaultWriteOptions()), true)
|
||||||
|
})
|
||||||
|
})
|
||||||
|
})
|
||||||
|
|||||||
@@ -1,5 +1,5 @@
|
|||||||
[bumpversion]
|
[bumpversion]
|
||||||
current_version = 0.1.12
|
current_version = 0.2.5
|
||||||
commit = True
|
commit = True
|
||||||
message = [python] Bump version: {current_version} → {new_version}
|
message = [python] Bump version: {current_version} → {new_version}
|
||||||
tag = True
|
tag = True
|
||||||
|
|||||||
@@ -11,15 +11,22 @@
|
|||||||
# See the License for the specific language governing permissions and
|
# See the License for the specific language governing permissions and
|
||||||
# limitations under the License.
|
# limitations under the License.
|
||||||
|
|
||||||
|
import importlib.metadata
|
||||||
from typing import Optional
|
from typing import Optional
|
||||||
|
|
||||||
from .db import URI, DBConnection, LanceDBConnection
|
from .db import URI, DBConnection, LanceDBConnection
|
||||||
from .remote.db import RemoteDBConnection
|
from .remote.db import RemoteDBConnection
|
||||||
from .schema import vector
|
from .schema import vector
|
||||||
|
|
||||||
|
__version__ = importlib.metadata.version("lancedb")
|
||||||
|
|
||||||
|
|
||||||
def connect(
|
def connect(
|
||||||
uri: URI, *, api_key: Optional[str] = None, region: str = "us-west-2"
|
uri: URI,
|
||||||
|
*,
|
||||||
|
api_key: Optional[str] = None,
|
||||||
|
region: str = "us-west-2",
|
||||||
|
host_override: Optional[str] = None,
|
||||||
) -> DBConnection:
|
) -> DBConnection:
|
||||||
"""Connect to a LanceDB database.
|
"""Connect to a LanceDB database.
|
||||||
|
|
||||||
@@ -27,9 +34,13 @@ def connect(
|
|||||||
----------
|
----------
|
||||||
uri: str or Path
|
uri: str or Path
|
||||||
The uri of the database.
|
The uri of the database.
|
||||||
api_token: str, optional
|
api_key: str, optional
|
||||||
If presented, connect to LanceDB cloud.
|
If presented, connect to LanceDB cloud.
|
||||||
Otherwise, connect to a database on file system or cloud storage.
|
Otherwise, connect to a database on file system or cloud storage.
|
||||||
|
region: str, default "us-west-2"
|
||||||
|
The region to use for LanceDB Cloud.
|
||||||
|
host_override: str, optional
|
||||||
|
The override url for LanceDB Cloud.
|
||||||
|
|
||||||
Examples
|
Examples
|
||||||
--------
|
--------
|
||||||
@@ -55,5 +66,5 @@ def connect(
|
|||||||
if isinstance(uri, str) and uri.startswith("db://"):
|
if isinstance(uri, str) and uri.startswith("db://"):
|
||||||
if api_key is None:
|
if api_key is None:
|
||||||
raise ValueError(f"api_key is required to connected LanceDB cloud: {uri}")
|
raise ValueError(f"api_key is required to connected LanceDB cloud: {uri}")
|
||||||
return RemoteDBConnection(uri, api_key, region)
|
return RemoteDBConnection(uri, api_key, region, host_override)
|
||||||
return LanceDBConnection(uri)
|
return LanceDBConnection(uri)
|
||||||
|
|||||||
@@ -11,17 +11,18 @@
|
|||||||
# See the License for the specific language governing permissions and
|
# See the License for the specific language governing permissions and
|
||||||
# limitations under the License.
|
# limitations under the License.
|
||||||
from pathlib import Path
|
from pathlib import Path
|
||||||
from typing import List, Union
|
from typing import Iterable, List, Union
|
||||||
|
|
||||||
import numpy as np
|
import numpy as np
|
||||||
import pandas as pd
|
|
||||||
import pyarrow as pa
|
import pyarrow as pa
|
||||||
|
|
||||||
|
from .util import safe_import_pandas
|
||||||
|
|
||||||
|
pd = safe_import_pandas()
|
||||||
|
|
||||||
|
DATA = Union[List[dict], dict, "pd.DataFrame", pa.Table, Iterable[pa.RecordBatch]]
|
||||||
VEC = Union[list, np.ndarray, pa.Array, pa.ChunkedArray]
|
VEC = Union[list, np.ndarray, pa.Array, pa.ChunkedArray]
|
||||||
URI = Union[str, Path]
|
URI = Union[str, Path]
|
||||||
|
|
||||||
# TODO support generator
|
|
||||||
DATA = Union[List[dict], dict, pd.DataFrame]
|
|
||||||
VECTOR_COLUMN_NAME = "vector"
|
VECTOR_COLUMN_NAME = "vector"
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
@@ -1,7 +1,10 @@
|
|||||||
import os
|
import os
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
import pytest
|
import pytest
|
||||||
|
|
||||||
|
from .embeddings import EmbeddingFunctionRegistry, TextEmbeddingFunction
|
||||||
|
|
||||||
# import lancedb so we don't have to in every example
|
# import lancedb so we don't have to in every example
|
||||||
|
|
||||||
|
|
||||||
@@ -14,3 +17,24 @@ def doctest_setup(monkeypatch, tmpdir):
|
|||||||
monkeypatch.setitem(os.environ, "COLUMNS", "80")
|
monkeypatch.setitem(os.environ, "COLUMNS", "80")
|
||||||
# Work in a temporary directory
|
# Work in a temporary directory
|
||||||
monkeypatch.chdir(tmpdir)
|
monkeypatch.chdir(tmpdir)
|
||||||
|
|
||||||
|
|
||||||
|
registry = EmbeddingFunctionRegistry.get_instance()
|
||||||
|
|
||||||
|
|
||||||
|
@registry.register("test")
|
||||||
|
class MockTextEmbeddingFunction(TextEmbeddingFunction):
|
||||||
|
"""
|
||||||
|
Return the hash of the first 10 characters
|
||||||
|
"""
|
||||||
|
|
||||||
|
def generate_embeddings(self, texts):
|
||||||
|
return [self._compute_one_embedding(row) for row in texts]
|
||||||
|
|
||||||
|
def _compute_one_embedding(self, row):
|
||||||
|
emb = np.array([float(hash(c)) for c in row[:10]])
|
||||||
|
emb /= np.linalg.norm(emb)
|
||||||
|
return emb
|
||||||
|
|
||||||
|
def ndims(self):
|
||||||
|
return 10
|
||||||
|
|||||||
@@ -12,12 +12,13 @@
|
|||||||
# limitations under the License.
|
# limitations under the License.
|
||||||
from __future__ import annotations
|
from __future__ import annotations
|
||||||
|
|
||||||
import pandas as pd
|
|
||||||
|
|
||||||
from .exceptions import MissingColumnError, MissingValueError
|
from .exceptions import MissingColumnError, MissingValueError
|
||||||
|
from .util import safe_import_pandas
|
||||||
|
|
||||||
|
pd = safe_import_pandas()
|
||||||
|
|
||||||
|
|
||||||
def contextualize(raw_df: pd.DataFrame) -> Contextualizer:
|
def contextualize(raw_df: "pd.DataFrame") -> Contextualizer:
|
||||||
"""Create a Contextualizer object for the given DataFrame.
|
"""Create a Contextualizer object for the given DataFrame.
|
||||||
|
|
||||||
Used to create context windows. Context windows are rolling subsets of text
|
Used to create context windows. Context windows are rolling subsets of text
|
||||||
@@ -175,8 +176,12 @@ class Contextualizer:
|
|||||||
self._min_window_size = min_window_size
|
self._min_window_size = min_window_size
|
||||||
return self
|
return self
|
||||||
|
|
||||||
def to_df(self) -> pd.DataFrame:
|
def to_df(self) -> "pd.DataFrame":
|
||||||
"""Create the context windows and return a DataFrame."""
|
"""Create the context windows and return a DataFrame."""
|
||||||
|
if pd is None:
|
||||||
|
raise ImportError(
|
||||||
|
"pandas is required to create context windows using lancedb"
|
||||||
|
)
|
||||||
|
|
||||||
if self._text_col not in self._raw_df.columns.tolist():
|
if self._text_col not in self._raw_df.columns.tolist():
|
||||||
raise MissingColumnError(self._text_col)
|
raise MissingColumnError(self._text_col)
|
||||||
|
|||||||
@@ -16,13 +16,14 @@ from __future__ import annotations
|
|||||||
import os
|
import os
|
||||||
from abc import ABC, abstractmethod
|
from abc import ABC, abstractmethod
|
||||||
from pathlib import Path
|
from pathlib import Path
|
||||||
from typing import Dict, Iterable, List, Optional, Tuple, Union
|
from typing import List, Optional, Union
|
||||||
|
|
||||||
import pandas as pd
|
|
||||||
import pyarrow as pa
|
import pyarrow as pa
|
||||||
from pyarrow import fs
|
from pyarrow import fs
|
||||||
|
|
||||||
from .common import DATA, URI
|
from .common import DATA, URI
|
||||||
|
from .embeddings import EmbeddingFunctionConfig
|
||||||
|
from .pydantic import LanceModel
|
||||||
from .table import LanceTable, Table
|
from .table import LanceTable, Table
|
||||||
from .util import fs_from_uri, get_uri_location, get_uri_scheme
|
from .util import fs_from_uri, get_uri_location, get_uri_scheme
|
||||||
|
|
||||||
@@ -39,10 +40,8 @@ class DBConnection(ABC):
|
|||||||
def create_table(
|
def create_table(
|
||||||
self,
|
self,
|
||||||
name: str,
|
name: str,
|
||||||
data: Optional[
|
data: Optional[DATA] = None,
|
||||||
Union[List[dict], dict, pd.DataFrame, pa.Table, Iterable[pa.RecordBatch]],
|
schema: Optional[Union[pa.Schema, LanceModel]] = None,
|
||||||
] = None,
|
|
||||||
schema: Optional[pa.Schema] = None,
|
|
||||||
mode: str = "create",
|
mode: str = "create",
|
||||||
on_bad_vectors: str = "error",
|
on_bad_vectors: str = "error",
|
||||||
fill_value: float = 0.0,
|
fill_value: float = 0.0,
|
||||||
@@ -55,7 +54,7 @@ class DBConnection(ABC):
|
|||||||
The name of the table.
|
The name of the table.
|
||||||
data: list, tuple, dict, pd.DataFrame; optional
|
data: list, tuple, dict, pd.DataFrame; optional
|
||||||
The data to initialize the table. User must provide at least one of `data` or `schema`.
|
The data to initialize the table. User must provide at least one of `data` or `schema`.
|
||||||
schema: pyarrow.Schema; optional
|
schema: pyarrow.Schema or LanceModel; optional
|
||||||
The schema of the table.
|
The schema of the table.
|
||||||
mode: str; default "create"
|
mode: str; default "create"
|
||||||
The mode to use when creating the table. Can be either "create" or "overwrite".
|
The mode to use when creating the table. Can be either "create" or "overwrite".
|
||||||
@@ -151,14 +150,14 @@ class DBConnection(ABC):
|
|||||||
... for i in range(5):
|
... for i in range(5):
|
||||||
... yield pa.RecordBatch.from_arrays(
|
... yield pa.RecordBatch.from_arrays(
|
||||||
... [
|
... [
|
||||||
... pa.array([[3.1, 4.1], [5.9, 26.5]]),
|
... pa.array([[3.1, 4.1], [5.9, 26.5]], pa.list_(pa.float32(), 2)),
|
||||||
... pa.array(["foo", "bar"]),
|
... pa.array(["foo", "bar"]),
|
||||||
... pa.array([10.0, 20.0]),
|
... pa.array([10.0, 20.0]),
|
||||||
... ],
|
... ],
|
||||||
... ["vector", "item", "price"],
|
... ["vector", "item", "price"],
|
||||||
... )
|
... )
|
||||||
>>> schema=pa.schema([
|
>>> schema=pa.schema([
|
||||||
... pa.field("vector", pa.list_(pa.float32())),
|
... pa.field("vector", pa.list_(pa.float32(), 2)),
|
||||||
... pa.field("item", pa.utf8()),
|
... pa.field("item", pa.utf8()),
|
||||||
... pa.field("price", pa.float32()),
|
... pa.field("price", pa.float32()),
|
||||||
... ])
|
... ])
|
||||||
@@ -195,6 +194,13 @@ class DBConnection(ABC):
|
|||||||
"""
|
"""
|
||||||
raise NotImplementedError
|
raise NotImplementedError
|
||||||
|
|
||||||
|
def drop_database(self):
|
||||||
|
"""
|
||||||
|
Drop database
|
||||||
|
This is the same thing as dropping all the tables
|
||||||
|
"""
|
||||||
|
raise NotImplementedError
|
||||||
|
|
||||||
|
|
||||||
class LanceDBConnection(DBConnection):
|
class LanceDBConnection(DBConnection):
|
||||||
"""
|
"""
|
||||||
@@ -279,11 +285,12 @@ class LanceDBConnection(DBConnection):
|
|||||||
def create_table(
|
def create_table(
|
||||||
self,
|
self,
|
||||||
name: str,
|
name: str,
|
||||||
data: Optional[Union[List[dict], dict, pd.DataFrame]] = None,
|
data: Optional[DATA] = None,
|
||||||
schema: pa.Schema = None,
|
schema: Optional[Union[pa.Schema, LanceModel]] = None,
|
||||||
mode: str = "create",
|
mode: str = "create",
|
||||||
on_bad_vectors: str = "error",
|
on_bad_vectors: str = "error",
|
||||||
fill_value: float = 0.0,
|
fill_value: float = 0.0,
|
||||||
|
embedding_functions: Optional[List[EmbeddingFunctionConfig]] = None,
|
||||||
) -> LanceTable:
|
) -> LanceTable:
|
||||||
"""Create a table in the database.
|
"""Create a table in the database.
|
||||||
|
|
||||||
@@ -302,6 +309,7 @@ class LanceDBConnection(DBConnection):
|
|||||||
mode=mode,
|
mode=mode,
|
||||||
on_bad_vectors=on_bad_vectors,
|
on_bad_vectors=on_bad_vectors,
|
||||||
fill_value=fill_value,
|
fill_value=fill_value,
|
||||||
|
embedding_functions=embedding_functions,
|
||||||
)
|
)
|
||||||
return tbl
|
return tbl
|
||||||
|
|
||||||
@@ -319,14 +327,24 @@ class LanceDBConnection(DBConnection):
|
|||||||
"""
|
"""
|
||||||
return LanceTable.open(self, name)
|
return LanceTable.open(self, name)
|
||||||
|
|
||||||
def drop_table(self, name: str):
|
def drop_table(self, name: str, ignore_missing: bool = False):
|
||||||
"""Drop a table from the database.
|
"""Drop a table from the database.
|
||||||
|
|
||||||
Parameters
|
Parameters
|
||||||
----------
|
----------
|
||||||
name: str
|
name: str
|
||||||
The name of the table.
|
The name of the table.
|
||||||
|
ignore_missing: bool, default False
|
||||||
|
If True, ignore if the table does not exist.
|
||||||
"""
|
"""
|
||||||
filesystem, path = pa.fs.FileSystem.from_uri(self.uri)
|
try:
|
||||||
table_path = os.path.join(path, name + ".lance")
|
filesystem, path = fs_from_uri(self.uri)
|
||||||
filesystem.delete_dir(table_path)
|
table_path = os.path.join(path, name + ".lance")
|
||||||
|
filesystem.delete_dir(table_path)
|
||||||
|
except FileNotFoundError:
|
||||||
|
if not ignore_missing:
|
||||||
|
raise
|
||||||
|
|
||||||
|
def drop_database(self):
|
||||||
|
filesystem, path = fs_from_uri(self.uri)
|
||||||
|
filesystem.delete_dir(path)
|
||||||
|
|||||||
24
python/lancedb/embeddings/__init__.py
Normal file
24
python/lancedb/embeddings/__init__.py
Normal file
@@ -0,0 +1,24 @@
|
|||||||
|
# Copyright (c) 2023. LanceDB Developers
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
|
||||||
|
|
||||||
|
from .functions import (
|
||||||
|
EmbeddingFunction,
|
||||||
|
EmbeddingFunctionConfig,
|
||||||
|
EmbeddingFunctionRegistry,
|
||||||
|
OpenAIEmbeddings,
|
||||||
|
OpenClipEmbeddings,
|
||||||
|
SentenceTransformerEmbeddings,
|
||||||
|
TextEmbeddingFunction,
|
||||||
|
)
|
||||||
|
from .utils import with_embeddings
|
||||||
577
python/lancedb/embeddings/functions.py
Normal file
577
python/lancedb/embeddings/functions.py
Normal file
@@ -0,0 +1,577 @@
|
|||||||
|
# Copyright (c) 2023. LanceDB Developers
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
import concurrent.futures
|
||||||
|
import importlib
|
||||||
|
import io
|
||||||
|
import json
|
||||||
|
import os
|
||||||
|
import socket
|
||||||
|
import urllib.error
|
||||||
|
import urllib.parse as urlparse
|
||||||
|
import urllib.request
|
||||||
|
from abc import ABC, abstractmethod
|
||||||
|
from typing import Dict, List, Optional, Union
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
|
import pyarrow as pa
|
||||||
|
from cachetools import cached
|
||||||
|
from pydantic import BaseModel, Field, PrivateAttr
|
||||||
|
|
||||||
|
|
||||||
|
class EmbeddingFunctionRegistry:
|
||||||
|
"""
|
||||||
|
This is a singleton class used to register embedding functions
|
||||||
|
and fetch them by name. It also handles serializing and deserializing.
|
||||||
|
You can implement your own embedding function by subclassing EmbeddingFunction
|
||||||
|
or TextEmbeddingFunction and registering it with the registry.
|
||||||
|
|
||||||
|
Examples
|
||||||
|
--------
|
||||||
|
>>> registry = EmbeddingFunctionRegistry.get_instance()
|
||||||
|
>>> @registry.register("my-embedding-function")
|
||||||
|
... class MyEmbeddingFunction(EmbeddingFunction):
|
||||||
|
... def ndims(self) -> int:
|
||||||
|
... return 128
|
||||||
|
...
|
||||||
|
... def compute_query_embeddings(self, query: str, *args, **kwargs) -> List[np.array]:
|
||||||
|
... return self.compute_source_embeddings(query, *args, **kwargs)
|
||||||
|
...
|
||||||
|
... def compute_source_embeddings(self, texts: TEXT, *args, **kwargs) -> List[np.array]:
|
||||||
|
... return [np.random.rand(self.ndims()) for _ in range(len(texts))]
|
||||||
|
...
|
||||||
|
>>> registry.get("my-embedding-function")
|
||||||
|
<class 'lancedb.embeddings.functions.MyEmbeddingFunction'>
|
||||||
|
"""
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def get_instance(cls):
|
||||||
|
return __REGISTRY__
|
||||||
|
|
||||||
|
def __init__(self):
|
||||||
|
self._functions = {}
|
||||||
|
|
||||||
|
def register(self, alias: str = None):
|
||||||
|
"""
|
||||||
|
This creates a decorator that can be used to register
|
||||||
|
an EmbeddingFunction.
|
||||||
|
|
||||||
|
Parameters
|
||||||
|
----------
|
||||||
|
alias : Optional[str]
|
||||||
|
a human friendly name for the embedding function. If not
|
||||||
|
provided, the class name will be used.
|
||||||
|
"""
|
||||||
|
|
||||||
|
# This is a decorator for a class that inherits from BaseModel
|
||||||
|
# It adds the class to the registry
|
||||||
|
def decorator(cls):
|
||||||
|
if not issubclass(cls, EmbeddingFunction):
|
||||||
|
raise TypeError("Must be a subclass of EmbeddingFunction")
|
||||||
|
if cls.__name__ in self._functions:
|
||||||
|
raise KeyError(f"{cls.__name__} was already registered")
|
||||||
|
key = alias or cls.__name__
|
||||||
|
self._functions[key] = cls
|
||||||
|
cls.__embedding_function_registry_alias__ = alias
|
||||||
|
return cls
|
||||||
|
|
||||||
|
return decorator
|
||||||
|
|
||||||
|
def reset(self):
|
||||||
|
"""
|
||||||
|
Reset the registry to its initial state
|
||||||
|
"""
|
||||||
|
self._functions = {}
|
||||||
|
|
||||||
|
def get(self, name: str):
|
||||||
|
"""
|
||||||
|
Fetch an embedding function class by name
|
||||||
|
|
||||||
|
Parameters
|
||||||
|
----------
|
||||||
|
name : str
|
||||||
|
The name of the embedding function to fetch
|
||||||
|
Either the alias or the class name if no alias was provided
|
||||||
|
during registration
|
||||||
|
"""
|
||||||
|
return self._functions[name]
|
||||||
|
|
||||||
|
def parse_functions(
|
||||||
|
self, metadata: Optional[Dict[bytes, bytes]]
|
||||||
|
) -> Dict[str, "EmbeddingFunctionConfig"]:
|
||||||
|
"""
|
||||||
|
Parse the metadata from an arrow table and
|
||||||
|
return a mapping of the vector column to the
|
||||||
|
embedding function and source column
|
||||||
|
|
||||||
|
Parameters
|
||||||
|
----------
|
||||||
|
metadata : Optional[Dict[bytes, bytes]]
|
||||||
|
The metadata from an arrow table. Note that
|
||||||
|
the keys and values are bytes (pyarrow api)
|
||||||
|
|
||||||
|
Returns
|
||||||
|
-------
|
||||||
|
functions : dict
|
||||||
|
A mapping of vector column name to embedding function.
|
||||||
|
An empty dict is returned if input is None or does not
|
||||||
|
contain b"embedding_functions".
|
||||||
|
"""
|
||||||
|
if metadata is None or b"embedding_functions" not in metadata:
|
||||||
|
return {}
|
||||||
|
serialized = metadata[b"embedding_functions"]
|
||||||
|
raw_list = json.loads(serialized.decode("utf-8"))
|
||||||
|
return {
|
||||||
|
obj["vector_column"]: EmbeddingFunctionConfig(
|
||||||
|
vector_column=obj["vector_column"],
|
||||||
|
source_column=obj["source_column"],
|
||||||
|
function=self.get(obj["name"])(**obj["model"]),
|
||||||
|
)
|
||||||
|
for obj in raw_list
|
||||||
|
}
|
||||||
|
|
||||||
|
def function_to_metadata(self, conf: "EmbeddingFunctionConfig"):
|
||||||
|
"""
|
||||||
|
Convert the given embedding function and source / vector column configs
|
||||||
|
into a config dictionary that can be serialized into arrow metadata
|
||||||
|
"""
|
||||||
|
func = conf.function
|
||||||
|
name = getattr(
|
||||||
|
func, "__embedding_function_registry_alias__", func.__class__.__name__
|
||||||
|
)
|
||||||
|
json_data = func.safe_model_dump()
|
||||||
|
return {
|
||||||
|
"name": name,
|
||||||
|
"model": json_data,
|
||||||
|
"source_column": conf.source_column,
|
||||||
|
"vector_column": conf.vector_column,
|
||||||
|
}
|
||||||
|
|
||||||
|
def get_table_metadata(self, func_list):
|
||||||
|
"""
|
||||||
|
Convert a list of embedding functions and source / vector configs
|
||||||
|
into a config dictionary that can be serialized into arrow metadata
|
||||||
|
"""
|
||||||
|
if func_list is None or len(func_list) == 0:
|
||||||
|
return None
|
||||||
|
json_data = [self.function_to_metadata(func) for func in func_list]
|
||||||
|
# Note that metadata dictionary values must be bytes
|
||||||
|
# so we need to json dump then utf8 encode
|
||||||
|
metadata = json.dumps(json_data, indent=2).encode("utf-8")
|
||||||
|
return {"embedding_functions": metadata}
|
||||||
|
|
||||||
|
|
||||||
|
# Global instance
|
||||||
|
__REGISTRY__ = EmbeddingFunctionRegistry()
|
||||||
|
|
||||||
|
|
||||||
|
TEXT = Union[str, List[str], pa.Array, pa.ChunkedArray, np.ndarray]
|
||||||
|
IMAGES = Union[
|
||||||
|
str, bytes, List[str], List[bytes], pa.Array, pa.ChunkedArray, np.ndarray
|
||||||
|
]
|
||||||
|
|
||||||
|
|
||||||
|
class EmbeddingFunction(BaseModel, ABC):
|
||||||
|
"""
|
||||||
|
An ABC for embedding functions.
|
||||||
|
|
||||||
|
All concrete embedding functions must implement the following:
|
||||||
|
1. compute_query_embeddings() which takes a query and returns a list of embeddings
|
||||||
|
2. get_source_embeddings() which returns a list of embeddings for the source column
|
||||||
|
For text data, the two will be the same. For multi-modal data, the source column
|
||||||
|
might be images and the vector column might be text.
|
||||||
|
3. ndims method which returns the number of dimensions of the vector column
|
||||||
|
"""
|
||||||
|
|
||||||
|
_ndims: int = PrivateAttr()
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def create(cls, **kwargs):
|
||||||
|
"""
|
||||||
|
Create an instance of the embedding function
|
||||||
|
"""
|
||||||
|
return cls(**kwargs)
|
||||||
|
|
||||||
|
@abstractmethod
|
||||||
|
def compute_query_embeddings(self, *args, **kwargs) -> List[np.array]:
|
||||||
|
"""
|
||||||
|
Compute the embeddings for a given user query
|
||||||
|
"""
|
||||||
|
pass
|
||||||
|
|
||||||
|
@abstractmethod
|
||||||
|
def compute_source_embeddings(self, *args, **kwargs) -> List[np.array]:
|
||||||
|
"""
|
||||||
|
Compute the embeddings for the source column in the database
|
||||||
|
"""
|
||||||
|
pass
|
||||||
|
|
||||||
|
def sanitize_input(self, texts: TEXT) -> Union[List[str], np.ndarray]:
|
||||||
|
"""
|
||||||
|
Sanitize the input to the embedding function.
|
||||||
|
"""
|
||||||
|
if isinstance(texts, str):
|
||||||
|
texts = [texts]
|
||||||
|
elif isinstance(texts, pa.Array):
|
||||||
|
texts = texts.to_pylist()
|
||||||
|
elif isinstance(texts, pa.ChunkedArray):
|
||||||
|
texts = texts.combine_chunks().to_pylist()
|
||||||
|
return texts
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def safe_import(cls, module: str, mitigation=None):
|
||||||
|
"""
|
||||||
|
Import the specified module. If the module is not installed,
|
||||||
|
raise an ImportError with a helpful message.
|
||||||
|
|
||||||
|
Parameters
|
||||||
|
----------
|
||||||
|
module : str
|
||||||
|
The name of the module to import
|
||||||
|
mitigation : Optional[str]
|
||||||
|
The package(s) to install to mitigate the error.
|
||||||
|
If not provided then the module name will be used.
|
||||||
|
"""
|
||||||
|
try:
|
||||||
|
return importlib.import_module(module)
|
||||||
|
except ImportError:
|
||||||
|
raise ImportError(f"Please install {mitigation or module}")
|
||||||
|
|
||||||
|
def safe_model_dump(self):
|
||||||
|
from ..pydantic import PYDANTIC_VERSION
|
||||||
|
|
||||||
|
if PYDANTIC_VERSION.major < 2:
|
||||||
|
return dict(self)
|
||||||
|
return self.model_dump()
|
||||||
|
|
||||||
|
@abstractmethod
|
||||||
|
def ndims(self):
|
||||||
|
"""
|
||||||
|
Return the dimensions of the vector column
|
||||||
|
"""
|
||||||
|
pass
|
||||||
|
|
||||||
|
def SourceField(self, **kwargs):
|
||||||
|
"""
|
||||||
|
Creates a pydantic Field that can automatically annotate
|
||||||
|
the source column for this embedding function
|
||||||
|
"""
|
||||||
|
return Field(json_schema_extra={"source_column_for": self}, **kwargs)
|
||||||
|
|
||||||
|
def VectorField(self, **kwargs):
|
||||||
|
"""
|
||||||
|
Creates a pydantic Field that can automatically annotate
|
||||||
|
the target vector column for this embedding function
|
||||||
|
"""
|
||||||
|
return Field(json_schema_extra={"vector_column_for": self}, **kwargs)
|
||||||
|
|
||||||
|
|
||||||
|
class EmbeddingFunctionConfig(BaseModel):
|
||||||
|
"""
|
||||||
|
This model encapsulates the configuration for a embedding function
|
||||||
|
in a lancedb table. It holds the embedding function, the source column,
|
||||||
|
and the vector column
|
||||||
|
"""
|
||||||
|
|
||||||
|
vector_column: str
|
||||||
|
source_column: str
|
||||||
|
function: EmbeddingFunction
|
||||||
|
|
||||||
|
|
||||||
|
class TextEmbeddingFunction(EmbeddingFunction):
|
||||||
|
"""
|
||||||
|
A callable ABC for embedding functions that take text as input
|
||||||
|
"""
|
||||||
|
|
||||||
|
def compute_query_embeddings(self, query: str, *args, **kwargs) -> List[np.array]:
|
||||||
|
return self.compute_source_embeddings(query, *args, **kwargs)
|
||||||
|
|
||||||
|
def compute_source_embeddings(self, texts: TEXT, *args, **kwargs) -> List[np.array]:
|
||||||
|
texts = self.sanitize_input(texts)
|
||||||
|
return self.generate_embeddings(texts)
|
||||||
|
|
||||||
|
@abstractmethod
|
||||||
|
def generate_embeddings(
|
||||||
|
self, texts: Union[List[str], np.ndarray]
|
||||||
|
) -> List[np.array]:
|
||||||
|
"""
|
||||||
|
Generate the embeddings for the given texts
|
||||||
|
"""
|
||||||
|
pass
|
||||||
|
|
||||||
|
|
||||||
|
# @EmbeddingFunctionRegistry.get_instance().register(name) doesn't work in 3.8
|
||||||
|
register = lambda name: EmbeddingFunctionRegistry.get_instance().register(name)
|
||||||
|
|
||||||
|
|
||||||
|
@register("sentence-transformers")
|
||||||
|
class SentenceTransformerEmbeddings(TextEmbeddingFunction):
|
||||||
|
"""
|
||||||
|
An embedding function that uses the sentence-transformers library
|
||||||
|
|
||||||
|
https://huggingface.co/sentence-transformers
|
||||||
|
"""
|
||||||
|
|
||||||
|
name: str = "all-MiniLM-L6-v2"
|
||||||
|
device: str = "cpu"
|
||||||
|
normalize: bool = True
|
||||||
|
|
||||||
|
def __init__(self, **kwargs):
|
||||||
|
super().__init__(**kwargs)
|
||||||
|
self._ndims = None
|
||||||
|
|
||||||
|
@property
|
||||||
|
def embedding_model(self):
|
||||||
|
"""
|
||||||
|
Get the sentence-transformers embedding model specified by the
|
||||||
|
name and device. This is cached so that the model is only loaded
|
||||||
|
once per process.
|
||||||
|
"""
|
||||||
|
return self.__class__.get_embedding_model(self.name, self.device)
|
||||||
|
|
||||||
|
def ndims(self):
|
||||||
|
if self._ndims is None:
|
||||||
|
self._ndims = len(self.generate_embeddings("foo")[0])
|
||||||
|
return self._ndims
|
||||||
|
|
||||||
|
def generate_embeddings(
|
||||||
|
self, texts: Union[List[str], np.ndarray]
|
||||||
|
) -> List[np.array]:
|
||||||
|
"""
|
||||||
|
Get the embeddings for the given texts
|
||||||
|
|
||||||
|
Parameters
|
||||||
|
----------
|
||||||
|
texts: list[str] or np.ndarray (of str)
|
||||||
|
The texts to embed
|
||||||
|
"""
|
||||||
|
return self.embedding_model.encode(
|
||||||
|
list(texts),
|
||||||
|
convert_to_numpy=True,
|
||||||
|
normalize_embeddings=self.normalize,
|
||||||
|
).tolist()
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
@cached(cache={})
|
||||||
|
def get_embedding_model(cls, name, device):
|
||||||
|
"""
|
||||||
|
Get the sentence-transformers embedding model specified by the
|
||||||
|
name and device. This is cached so that the model is only loaded
|
||||||
|
once per process.
|
||||||
|
|
||||||
|
Parameters
|
||||||
|
----------
|
||||||
|
name : str
|
||||||
|
The name of the model to load
|
||||||
|
device : str
|
||||||
|
The device to load the model on
|
||||||
|
|
||||||
|
TODO: use lru_cache instead with a reasonable/configurable maxsize
|
||||||
|
"""
|
||||||
|
sentence_transformers = cls.safe_import(
|
||||||
|
"sentence_transformers", "sentence-transformers"
|
||||||
|
)
|
||||||
|
return sentence_transformers.SentenceTransformer(name, device=device)
|
||||||
|
|
||||||
|
|
||||||
|
@register("openai")
|
||||||
|
class OpenAIEmbeddings(TextEmbeddingFunction):
|
||||||
|
"""
|
||||||
|
An embedding function that uses the OpenAI API
|
||||||
|
|
||||||
|
https://platform.openai.com/docs/guides/embeddings
|
||||||
|
"""
|
||||||
|
|
||||||
|
name: str = "text-embedding-ada-002"
|
||||||
|
|
||||||
|
def ndims(self):
|
||||||
|
# TODO don't hardcode this
|
||||||
|
return 1536
|
||||||
|
|
||||||
|
def generate_embeddings(
|
||||||
|
self, texts: Union[List[str], np.ndarray]
|
||||||
|
) -> List[np.array]:
|
||||||
|
"""
|
||||||
|
Get the embeddings for the given texts
|
||||||
|
|
||||||
|
Parameters
|
||||||
|
----------
|
||||||
|
texts: list[str] or np.ndarray (of str)
|
||||||
|
The texts to embed
|
||||||
|
"""
|
||||||
|
# TODO retry, rate limit, token limit
|
||||||
|
openai = self.safe_import("openai")
|
||||||
|
rs = openai.Embedding.create(input=texts, model=self.name)["data"]
|
||||||
|
return [v["embedding"] for v in rs]
|
||||||
|
|
||||||
|
|
||||||
|
@register("open-clip")
|
||||||
|
class OpenClipEmbeddings(EmbeddingFunction):
|
||||||
|
"""
|
||||||
|
An embedding function that uses the OpenClip API
|
||||||
|
For multi-modal text-to-image search
|
||||||
|
|
||||||
|
https://github.com/mlfoundations/open_clip
|
||||||
|
"""
|
||||||
|
|
||||||
|
name: str = "ViT-B-32"
|
||||||
|
pretrained: str = "laion2b_s34b_b79k"
|
||||||
|
device: str = "cpu"
|
||||||
|
batch_size: int = 64
|
||||||
|
normalize: bool = True
|
||||||
|
_model = PrivateAttr()
|
||||||
|
_preprocess = PrivateAttr()
|
||||||
|
_tokenizer = PrivateAttr()
|
||||||
|
|
||||||
|
def __init__(self, *args, **kwargs):
|
||||||
|
super().__init__(*args, **kwargs)
|
||||||
|
open_clip = self.safe_import("open_clip", "open-clip")
|
||||||
|
model, _, preprocess = open_clip.create_model_and_transforms(
|
||||||
|
self.name, pretrained=self.pretrained
|
||||||
|
)
|
||||||
|
model.to(self.device)
|
||||||
|
self._model, self._preprocess = model, preprocess
|
||||||
|
self._tokenizer = open_clip.get_tokenizer(self.name)
|
||||||
|
self._ndims = None
|
||||||
|
|
||||||
|
def ndims(self):
|
||||||
|
if self._ndims is None:
|
||||||
|
self._ndims = self.generate_text_embeddings("foo").shape[0]
|
||||||
|
return self._ndims
|
||||||
|
|
||||||
|
def compute_query_embeddings(
|
||||||
|
self, query: Union[str, "PIL.Image.Image"], *args, **kwargs
|
||||||
|
) -> List[np.ndarray]:
|
||||||
|
"""
|
||||||
|
Compute the embeddings for a given user query
|
||||||
|
|
||||||
|
Parameters
|
||||||
|
----------
|
||||||
|
query : Union[str, PIL.Image.Image]
|
||||||
|
The query to embed. A query can be either text or an image.
|
||||||
|
"""
|
||||||
|
if isinstance(query, str):
|
||||||
|
return [self.generate_text_embeddings(query)]
|
||||||
|
else:
|
||||||
|
PIL = self.safe_import("PIL", "pillow")
|
||||||
|
if isinstance(query, PIL.Image.Image):
|
||||||
|
return [self.generate_image_embedding(query)]
|
||||||
|
else:
|
||||||
|
raise TypeError("OpenClip supports str or PIL Image as query")
|
||||||
|
|
||||||
|
def generate_text_embeddings(self, text: str) -> np.ndarray:
|
||||||
|
torch = self.safe_import("torch")
|
||||||
|
text = self.sanitize_input(text)
|
||||||
|
text = self._tokenizer(text)
|
||||||
|
text.to(self.device)
|
||||||
|
with torch.no_grad():
|
||||||
|
text_features = self._model.encode_text(text.to(self.device))
|
||||||
|
if self.normalize:
|
||||||
|
text_features /= text_features.norm(dim=-1, keepdim=True)
|
||||||
|
return text_features.cpu().numpy().squeeze()
|
||||||
|
|
||||||
|
def sanitize_input(self, images: IMAGES) -> Union[List[bytes], np.ndarray]:
|
||||||
|
"""
|
||||||
|
Sanitize the input to the embedding function.
|
||||||
|
"""
|
||||||
|
if isinstance(images, (str, bytes)):
|
||||||
|
images = [images]
|
||||||
|
elif isinstance(images, pa.Array):
|
||||||
|
images = images.to_pylist()
|
||||||
|
elif isinstance(images, pa.ChunkedArray):
|
||||||
|
images = images.combine_chunks().to_pylist()
|
||||||
|
return images
|
||||||
|
|
||||||
|
def compute_source_embeddings(
|
||||||
|
self, images: IMAGES, *args, **kwargs
|
||||||
|
) -> List[np.array]:
|
||||||
|
"""
|
||||||
|
Get the embeddings for the given images
|
||||||
|
"""
|
||||||
|
images = self.sanitize_input(images)
|
||||||
|
embeddings = []
|
||||||
|
for i in range(0, len(images), self.batch_size):
|
||||||
|
j = min(i + self.batch_size, len(images))
|
||||||
|
batch = images[i:j]
|
||||||
|
embeddings.extend(self._parallel_get(batch))
|
||||||
|
return embeddings
|
||||||
|
|
||||||
|
def _parallel_get(self, images: Union[List[str], List[bytes]]) -> List[np.ndarray]:
|
||||||
|
"""
|
||||||
|
Issue concurrent requests to retrieve the image data
|
||||||
|
"""
|
||||||
|
with concurrent.futures.ThreadPoolExecutor() as executor:
|
||||||
|
futures = [
|
||||||
|
executor.submit(self.generate_image_embedding, image)
|
||||||
|
for image in images
|
||||||
|
]
|
||||||
|
return [future.result() for future in futures]
|
||||||
|
|
||||||
|
def generate_image_embedding(
|
||||||
|
self, image: Union[str, bytes, "PIL.Image.Image"]
|
||||||
|
) -> np.ndarray:
|
||||||
|
"""
|
||||||
|
Generate the embedding for a single image
|
||||||
|
|
||||||
|
Parameters
|
||||||
|
----------
|
||||||
|
image : Union[str, bytes, PIL.Image.Image]
|
||||||
|
The image to embed. If the image is a str, it is treated as a uri.
|
||||||
|
If the image is bytes, it is treated as the raw image bytes.
|
||||||
|
"""
|
||||||
|
torch = self.safe_import("torch")
|
||||||
|
# TODO handle retry and errors for https
|
||||||
|
image = self._to_pil(image)
|
||||||
|
image = self._preprocess(image).unsqueeze(0)
|
||||||
|
with torch.no_grad():
|
||||||
|
return self._encode_and_normalize_image(image)
|
||||||
|
|
||||||
|
def _to_pil(self, image: Union[str, bytes]):
|
||||||
|
PIL = self.safe_import("PIL", "pillow")
|
||||||
|
if isinstance(image, bytes):
|
||||||
|
return PIL.Image.open(io.BytesIO(image))
|
||||||
|
if isinstance(image, PIL.Image.Image):
|
||||||
|
return image
|
||||||
|
elif isinstance(image, str):
|
||||||
|
parsed = urlparse.urlparse(image)
|
||||||
|
# TODO handle drive letter on windows.
|
||||||
|
if parsed.scheme == "file":
|
||||||
|
return PIL.Image.open(parsed.path)
|
||||||
|
elif parsed.scheme == "":
|
||||||
|
return PIL.Image.open(image if os.name == "nt" else parsed.path)
|
||||||
|
elif parsed.scheme.startswith("http"):
|
||||||
|
return PIL.Image.open(io.BytesIO(url_retrieve(image)))
|
||||||
|
else:
|
||||||
|
raise NotImplementedError("Only local and http(s) urls are supported")
|
||||||
|
|
||||||
|
def _encode_and_normalize_image(self, image_tensor: "torch.Tensor"):
|
||||||
|
"""
|
||||||
|
encode a single image tensor and optionally normalize the output
|
||||||
|
"""
|
||||||
|
image_features = self._model.encode_image(image_tensor)
|
||||||
|
if self.normalize:
|
||||||
|
image_features /= image_features.norm(dim=-1, keepdim=True)
|
||||||
|
return image_features.cpu().numpy().squeeze()
|
||||||
|
|
||||||
|
|
||||||
|
def url_retrieve(url: str):
|
||||||
|
"""
|
||||||
|
Parameters
|
||||||
|
----------
|
||||||
|
url: str
|
||||||
|
URL to download from
|
||||||
|
"""
|
||||||
|
try:
|
||||||
|
with urllib.request.urlopen(url) as conn:
|
||||||
|
return conn.read()
|
||||||
|
except (socket.gaierror, urllib.error.URLError) as err:
|
||||||
|
raise ConnectionError("could not download {} due to {}".format(url, err))
|
||||||
@@ -1,4 +1,4 @@
|
|||||||
# Copyright 2023 LanceDB Developers
|
# Copyright (c) 2023. LanceDB Developers
|
||||||
#
|
#
|
||||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
# you may not use this file except in compliance with the License.
|
# you may not use this file except in compliance with the License.
|
||||||
@@ -16,15 +16,19 @@ import sys
|
|||||||
from typing import Callable, Union
|
from typing import Callable, Union
|
||||||
|
|
||||||
import numpy as np
|
import numpy as np
|
||||||
import pandas as pd
|
|
||||||
import pyarrow as pa
|
import pyarrow as pa
|
||||||
from lance.vector import vec_to_table
|
from lance.vector import vec_to_table
|
||||||
from retry import retry
|
from retry import retry
|
||||||
|
|
||||||
|
from ..util import safe_import_pandas
|
||||||
|
|
||||||
|
pd = safe_import_pandas()
|
||||||
|
DATA = Union[pa.Table, "pd.DataFrame"]
|
||||||
|
|
||||||
|
|
||||||
def with_embeddings(
|
def with_embeddings(
|
||||||
func: Callable,
|
func: Callable,
|
||||||
data: Union[pa.Table, pd.DataFrame],
|
data: DATA,
|
||||||
column: str = "text",
|
column: str = "text",
|
||||||
wrap_api: bool = True,
|
wrap_api: bool = True,
|
||||||
show_progress: bool = False,
|
show_progress: bool = False,
|
||||||
@@ -54,20 +58,24 @@ def with_embeddings(
|
|||||||
pa.Table
|
pa.Table
|
||||||
The input table with a new column called "vector" containing the embeddings.
|
The input table with a new column called "vector" containing the embeddings.
|
||||||
"""
|
"""
|
||||||
func = EmbeddingFunction(func)
|
func = FunctionWrapper(func)
|
||||||
if wrap_api:
|
if wrap_api:
|
||||||
func = func.retry().rate_limit()
|
func = func.retry().rate_limit()
|
||||||
func = func.batch_size(batch_size)
|
func = func.batch_size(batch_size)
|
||||||
if show_progress:
|
if show_progress:
|
||||||
func = func.show_progress()
|
func = func.show_progress()
|
||||||
if isinstance(data, pd.DataFrame):
|
if pd is not None and isinstance(data, pd.DataFrame):
|
||||||
data = pa.Table.from_pandas(data, preserve_index=False)
|
data = pa.Table.from_pandas(data, preserve_index=False)
|
||||||
embeddings = func(data[column].to_numpy())
|
embeddings = func(data[column].to_numpy())
|
||||||
table = vec_to_table(np.array(embeddings))
|
table = vec_to_table(np.array(embeddings))
|
||||||
return data.append_column("vector", table["vector"])
|
return data.append_column("vector", table["vector"])
|
||||||
|
|
||||||
|
|
||||||
class EmbeddingFunction:
|
class FunctionWrapper:
|
||||||
|
"""
|
||||||
|
A wrapper for embedding functions that adds rate limiting, retries, and batching.
|
||||||
|
"""
|
||||||
|
|
||||||
def __init__(self, func: Callable):
|
def __init__(self, func: Callable):
|
||||||
self.func = func
|
self.func = func
|
||||||
self.rate_limiter_kwargs = {}
|
self.rate_limiter_kwargs = {}
|
||||||
@@ -11,7 +11,7 @@
|
|||||||
# See the License for the specific language governing permissions and
|
# See the License for the specific language governing permissions and
|
||||||
# limitations under the License.
|
# limitations under the License.
|
||||||
|
|
||||||
"""Pydantic adapter for LanceDB"""
|
"""Pydantic (v1 / v2) adapter for LanceDB"""
|
||||||
|
|
||||||
from __future__ import annotations
|
from __future__ import annotations
|
||||||
|
|
||||||
@@ -19,11 +19,21 @@ import inspect
|
|||||||
import sys
|
import sys
|
||||||
import types
|
import types
|
||||||
from abc import ABC, abstractmethod
|
from abc import ABC, abstractmethod
|
||||||
from typing import Any, List, Type, Union, _GenericAlias
|
from typing import Any, Callable, Dict, Generator, List, Type, Union, _GenericAlias
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
import pyarrow as pa
|
import pyarrow as pa
|
||||||
import pydantic
|
import pydantic
|
||||||
from pydantic_core import CoreSchema, core_schema
|
import semver
|
||||||
|
|
||||||
|
from .embeddings import EmbeddingFunctionRegistry
|
||||||
|
|
||||||
|
PYDANTIC_VERSION = semver.Version.parse(pydantic.__version__)
|
||||||
|
try:
|
||||||
|
from pydantic_core import CoreSchema, core_schema
|
||||||
|
except ImportError:
|
||||||
|
if PYDANTIC_VERSION >= (2,):
|
||||||
|
raise
|
||||||
|
|
||||||
|
|
||||||
class FixedSizeListMixin(ABC):
|
class FixedSizeListMixin(ABC):
|
||||||
@@ -38,7 +48,19 @@ class FixedSizeListMixin(ABC):
|
|||||||
raise NotImplementedError
|
raise NotImplementedError
|
||||||
|
|
||||||
|
|
||||||
def vector(
|
def vector(dim: int, value_type: pa.DataType = pa.float32()):
|
||||||
|
# TODO: remove in future release
|
||||||
|
from warnings import warn
|
||||||
|
|
||||||
|
warn(
|
||||||
|
"lancedb.pydantic.vector() is deprecated, use lancedb.pydantic.Vector instead."
|
||||||
|
"This function will be removed in future release",
|
||||||
|
DeprecationWarning,
|
||||||
|
)
|
||||||
|
return Vector(dim, value_type)
|
||||||
|
|
||||||
|
|
||||||
|
def Vector(
|
||||||
dim: int, value_type: pa.DataType = pa.float32()
|
dim: int, value_type: pa.DataType = pa.float32()
|
||||||
) -> Type[FixedSizeListMixin]:
|
) -> Type[FixedSizeListMixin]:
|
||||||
"""Pydantic Vector Type.
|
"""Pydantic Vector Type.
|
||||||
@@ -57,12 +79,12 @@ def vector(
|
|||||||
--------
|
--------
|
||||||
|
|
||||||
>>> import pydantic
|
>>> import pydantic
|
||||||
>>> from lancedb.pydantic import vector
|
>>> from lancedb.pydantic import Vector
|
||||||
...
|
...
|
||||||
>>> class MyModel(pydantic.BaseModel):
|
>>> class MyModel(pydantic.BaseModel):
|
||||||
... id: int
|
... id: int
|
||||||
... url: str
|
... url: str
|
||||||
... embeddings: vector(768)
|
... embeddings: Vector(768)
|
||||||
>>> schema = pydantic_to_schema(MyModel)
|
>>> schema = pydantic_to_schema(MyModel)
|
||||||
>>> assert schema == pa.schema([
|
>>> assert schema == pa.schema([
|
||||||
... pa.field("id", pa.int64(), False),
|
... pa.field("id", pa.int64(), False),
|
||||||
@@ -73,6 +95,9 @@ def vector(
|
|||||||
|
|
||||||
# TODO: make a public parameterized type.
|
# TODO: make a public parameterized type.
|
||||||
class FixedSizeList(list, FixedSizeListMixin):
|
class FixedSizeList(list, FixedSizeListMixin):
|
||||||
|
def __repr__(self):
|
||||||
|
return f"FixedSizeList(dim={dim})"
|
||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
def dim() -> int:
|
def dim() -> int:
|
||||||
return dim
|
return dim
|
||||||
@@ -94,6 +119,25 @@ def vector(
|
|||||||
),
|
),
|
||||||
)
|
)
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def __get_validators__(cls) -> Generator[Callable, None, None]:
|
||||||
|
yield cls.validate
|
||||||
|
|
||||||
|
# For pydantic v1
|
||||||
|
@classmethod
|
||||||
|
def validate(cls, v):
|
||||||
|
if not isinstance(v, (list, range, np.ndarray)) or len(v) != dim:
|
||||||
|
raise TypeError("A list of numbers or numpy.ndarray is needed")
|
||||||
|
return cls(v)
|
||||||
|
|
||||||
|
if PYDANTIC_VERSION < (2, 0):
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def __modify_schema__(cls, field_schema: Dict[str, Any]):
|
||||||
|
field_schema["items"] = {"type": "number"}
|
||||||
|
field_schema["maxItems"] = dim
|
||||||
|
field_schema["minItems"] = dim
|
||||||
|
|
||||||
return FixedSizeList
|
return FixedSizeList
|
||||||
|
|
||||||
|
|
||||||
@@ -120,11 +164,20 @@ def _py_type_to_arrow_type(py_type: Type[Any]) -> pa.DataType:
|
|||||||
)
|
)
|
||||||
|
|
||||||
|
|
||||||
def _pydantic_model_to_fields(model: pydantic.BaseModel) -> List[pa.Field]:
|
if PYDANTIC_VERSION.major < 2:
|
||||||
fields = []
|
|
||||||
for name, field in model.model_fields.items():
|
def _pydantic_model_to_fields(model: pydantic.BaseModel) -> List[pa.Field]:
|
||||||
fields.append(_pydantic_to_field(name, field))
|
return [
|
||||||
return fields
|
_pydantic_to_field(name, field) for name, field in model.__fields__.items()
|
||||||
|
]
|
||||||
|
|
||||||
|
else:
|
||||||
|
|
||||||
|
def _pydantic_model_to_fields(model: pydantic.BaseModel) -> List[pa.Field]:
|
||||||
|
return [
|
||||||
|
_pydantic_to_field(name, field)
|
||||||
|
for name, field in model.model_fields.items()
|
||||||
|
]
|
||||||
|
|
||||||
|
|
||||||
def _pydantic_to_arrow_type(field: pydantic.fields.FieldInfo) -> pa.DataType:
|
def _pydantic_to_arrow_type(field: pydantic.fields.FieldInfo) -> pa.DataType:
|
||||||
@@ -185,28 +238,103 @@ def pydantic_to_schema(model: Type[pydantic.BaseModel]) -> pa.Schema:
|
|||||||
>>> from typing import List, Optional
|
>>> from typing import List, Optional
|
||||||
>>> import pydantic
|
>>> import pydantic
|
||||||
>>> from lancedb.pydantic import pydantic_to_schema
|
>>> from lancedb.pydantic import pydantic_to_schema
|
||||||
...
|
|
||||||
>>> class InnerModel(pydantic.BaseModel):
|
|
||||||
... a: str
|
|
||||||
... b: Optional[float]
|
|
||||||
>>>
|
|
||||||
>>> class FooModel(pydantic.BaseModel):
|
>>> class FooModel(pydantic.BaseModel):
|
||||||
... id: int
|
... id: int
|
||||||
... s: Optional[str] = None
|
... s: str
|
||||||
... vec: List[float]
|
... vec: List[float]
|
||||||
... li: List[int]
|
... li: List[int]
|
||||||
... inner: InnerModel
|
...
|
||||||
>>> schema = pydantic_to_schema(FooModel)
|
>>> schema = pydantic_to_schema(FooModel)
|
||||||
>>> assert schema == pa.schema([
|
>>> assert schema == pa.schema([
|
||||||
... pa.field("id", pa.int64(), False),
|
... pa.field("id", pa.int64(), False),
|
||||||
... pa.field("s", pa.utf8(), True),
|
... pa.field("s", pa.utf8(), False),
|
||||||
... pa.field("vec", pa.list_(pa.float64()), False),
|
... pa.field("vec", pa.list_(pa.float64()), False),
|
||||||
... pa.field("li", pa.list_(pa.int64()), False),
|
... pa.field("li", pa.list_(pa.int64()), False),
|
||||||
... pa.field("inner", pa.struct([
|
|
||||||
... pa.field("a", pa.utf8(), False),
|
|
||||||
... pa.field("b", pa.float64(), True),
|
|
||||||
... ]), False),
|
|
||||||
... ])
|
... ])
|
||||||
"""
|
"""
|
||||||
fields = _pydantic_model_to_fields(model)
|
fields = _pydantic_model_to_fields(model)
|
||||||
return pa.schema(fields)
|
return pa.schema(fields)
|
||||||
|
|
||||||
|
|
||||||
|
class LanceModel(pydantic.BaseModel):
|
||||||
|
"""
|
||||||
|
A Pydantic Model base class that can be converted to a LanceDB Table.
|
||||||
|
|
||||||
|
Examples
|
||||||
|
--------
|
||||||
|
>>> import lancedb
|
||||||
|
>>> from lancedb.pydantic import LanceModel, Vector
|
||||||
|
>>>
|
||||||
|
>>> class TestModel(LanceModel):
|
||||||
|
... name: str
|
||||||
|
... vector: Vector(2)
|
||||||
|
...
|
||||||
|
>>> db = lancedb.connect("/tmp")
|
||||||
|
>>> table = db.create_table("test", schema=TestModel.to_arrow_schema())
|
||||||
|
>>> table.add([
|
||||||
|
... TestModel(name="test", vector=[1.0, 2.0])
|
||||||
|
... ])
|
||||||
|
>>> table.search([0., 0.]).limit(1).to_pydantic(TestModel)
|
||||||
|
[TestModel(name='test', vector=FixedSizeList(dim=2))]
|
||||||
|
"""
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def to_arrow_schema(cls):
|
||||||
|
"""
|
||||||
|
Get the Arrow Schema for this model.
|
||||||
|
"""
|
||||||
|
schema = pydantic_to_schema(cls)
|
||||||
|
functions = cls.parse_embedding_functions()
|
||||||
|
if len(functions) > 0:
|
||||||
|
metadata = EmbeddingFunctionRegistry.get_instance().get_table_metadata(
|
||||||
|
functions
|
||||||
|
)
|
||||||
|
schema = schema.with_metadata(metadata)
|
||||||
|
return schema
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def field_names(cls) -> List[str]:
|
||||||
|
"""
|
||||||
|
Get the field names of this model.
|
||||||
|
"""
|
||||||
|
return list(cls.safe_get_fields().keys())
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def safe_get_fields(cls):
|
||||||
|
if PYDANTIC_VERSION.major < 2:
|
||||||
|
return cls.__fields__
|
||||||
|
return cls.model_fields
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def parse_embedding_functions(cls) -> List["EmbeddingFunctionConfig"]:
|
||||||
|
"""
|
||||||
|
Parse the embedding functions from this model.
|
||||||
|
"""
|
||||||
|
from .embeddings import EmbeddingFunctionConfig
|
||||||
|
|
||||||
|
vec_and_function = []
|
||||||
|
for name, field_info in cls.safe_get_fields().items():
|
||||||
|
func = get_extras(field_info, "vector_column_for")
|
||||||
|
if func is not None:
|
||||||
|
vec_and_function.append([name, func])
|
||||||
|
|
||||||
|
configs = []
|
||||||
|
for vec, func in vec_and_function:
|
||||||
|
for source, field_info in cls.safe_get_fields().items():
|
||||||
|
src_func = get_extras(field_info, "source_column_for")
|
||||||
|
if src_func == func:
|
||||||
|
configs.append(
|
||||||
|
EmbeddingFunctionConfig(
|
||||||
|
source_column=source, vector_column=vec, function=func
|
||||||
|
)
|
||||||
|
)
|
||||||
|
return configs
|
||||||
|
|
||||||
|
|
||||||
|
def get_extras(field_info: pydantic.fields.FieldInfo, key: str) -> Any:
|
||||||
|
"""
|
||||||
|
Get the extra metadata from a Pydantic FieldInfo.
|
||||||
|
"""
|
||||||
|
if PYDANTIC_VERSION.major >= 2:
|
||||||
|
return (field_info.json_schema_extra or {}).get(key)
|
||||||
|
return (field_info.field_info.extra or {}).get("json_schema_extra", {}).get(key)
|
||||||
|
|||||||
@@ -13,17 +13,21 @@
|
|||||||
|
|
||||||
from __future__ import annotations
|
from __future__ import annotations
|
||||||
|
|
||||||
from typing import List, Literal, Optional, Union
|
from abc import ABC, abstractmethod
|
||||||
|
from typing import List, Literal, Optional, Type, Union
|
||||||
|
|
||||||
import numpy as np
|
import numpy as np
|
||||||
import pandas as pd
|
|
||||||
import pyarrow as pa
|
import pyarrow as pa
|
||||||
from pydantic import BaseModel
|
import pydantic
|
||||||
|
|
||||||
from .common import VECTOR_COLUMN_NAME
|
from .common import VECTOR_COLUMN_NAME
|
||||||
|
from .pydantic import LanceModel
|
||||||
|
from .util import safe_import_pandas
|
||||||
|
|
||||||
|
pd = safe_import_pandas()
|
||||||
|
|
||||||
|
|
||||||
class Query(BaseModel):
|
class Query(pydantic.BaseModel):
|
||||||
"""A Query"""
|
"""A Query"""
|
||||||
|
|
||||||
vector_column: str = VECTOR_COLUMN_NAME
|
vector_column: str = VECTOR_COLUMN_NAME
|
||||||
@@ -51,7 +55,163 @@ class Query(BaseModel):
|
|||||||
refine_factor: Optional[int] = None
|
refine_factor: Optional[int] = None
|
||||||
|
|
||||||
|
|
||||||
class LanceQueryBuilder:
|
class LanceQueryBuilder(ABC):
|
||||||
|
@classmethod
|
||||||
|
def create(
|
||||||
|
cls,
|
||||||
|
table: "lancedb.table.Table",
|
||||||
|
query: Optional[Union[np.ndarray, str, "PIL.Image.Image"]],
|
||||||
|
query_type: str,
|
||||||
|
vector_column_name: str,
|
||||||
|
) -> LanceQueryBuilder:
|
||||||
|
if query is None:
|
||||||
|
return LanceEmptyQueryBuilder(table)
|
||||||
|
|
||||||
|
# convert "auto" query_type to "vector" or "fts"
|
||||||
|
# and convert the query to vector if needed
|
||||||
|
query, query_type = cls._resolve_query(
|
||||||
|
table, query, query_type, vector_column_name
|
||||||
|
)
|
||||||
|
|
||||||
|
if isinstance(query, str):
|
||||||
|
# fts
|
||||||
|
return LanceFtsQueryBuilder(table, query)
|
||||||
|
|
||||||
|
if isinstance(query, list):
|
||||||
|
query = np.array(query, dtype=np.float32)
|
||||||
|
elif isinstance(query, np.ndarray):
|
||||||
|
query = query.astype(np.float32)
|
||||||
|
else:
|
||||||
|
raise TypeError(f"Unsupported query type: {type(query)}")
|
||||||
|
|
||||||
|
return LanceVectorQueryBuilder(table, query, vector_column_name)
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def _resolve_query(cls, table, query, query_type, vector_column_name):
|
||||||
|
# If query_type is fts, then query must be a string.
|
||||||
|
# otherwise raise TypeError
|
||||||
|
if query_type == "fts":
|
||||||
|
if not isinstance(query, str):
|
||||||
|
raise TypeError(f"'fts' queries must be a string: {type(query)}")
|
||||||
|
return query, query_type
|
||||||
|
elif query_type == "vector":
|
||||||
|
if not isinstance(query, (list, np.ndarray)):
|
||||||
|
conf = table.embedding_functions.get(vector_column_name)
|
||||||
|
if conf is not None:
|
||||||
|
query = conf.function.compute_query_embeddings(query)[0]
|
||||||
|
else:
|
||||||
|
msg = f"No embedding function for {vector_column_name}"
|
||||||
|
raise ValueError(msg)
|
||||||
|
return query, query_type
|
||||||
|
elif query_type == "auto":
|
||||||
|
if isinstance(query, (list, np.ndarray)):
|
||||||
|
return query, "vector"
|
||||||
|
else:
|
||||||
|
conf = table.embedding_functions.get(vector_column_name)
|
||||||
|
if conf is not None:
|
||||||
|
query = conf.function.compute_query_embeddings(query)[0]
|
||||||
|
return query, "vector"
|
||||||
|
else:
|
||||||
|
return query, "fts"
|
||||||
|
else:
|
||||||
|
raise ValueError(
|
||||||
|
f"Invalid query_type, must be 'vector', 'fts', or 'auto': {query_type}"
|
||||||
|
)
|
||||||
|
|
||||||
|
def __init__(self, table: "lancedb.table.Table"):
|
||||||
|
self._table = table
|
||||||
|
self._limit = 10
|
||||||
|
self._columns = None
|
||||||
|
self._where = None
|
||||||
|
|
||||||
|
def to_df(self) -> "pd.DataFrame":
|
||||||
|
"""
|
||||||
|
Execute the query and return the results as a pandas DataFrame.
|
||||||
|
In addition to the selected columns, LanceDB also returns a vector
|
||||||
|
and also the "_distance" column which is the distance between the query
|
||||||
|
vector and the returned vector.
|
||||||
|
"""
|
||||||
|
return self.to_arrow().to_pandas()
|
||||||
|
|
||||||
|
@abstractmethod
|
||||||
|
def to_arrow(self) -> pa.Table:
|
||||||
|
"""
|
||||||
|
Execute the query and return the results as an
|
||||||
|
[Apache Arrow Table](https://arrow.apache.org/docs/python/generated/pyarrow.Table.html#pyarrow.Table).
|
||||||
|
|
||||||
|
In addition to the selected columns, LanceDB also returns a vector
|
||||||
|
and also the "_distance" column which is the distance between the query
|
||||||
|
vector and the returned vectors.
|
||||||
|
"""
|
||||||
|
raise NotImplementedError
|
||||||
|
|
||||||
|
def to_pydantic(self, model: Type[LanceModel]) -> List[LanceModel]:
|
||||||
|
"""Return the table as a list of pydantic models.
|
||||||
|
|
||||||
|
Parameters
|
||||||
|
----------
|
||||||
|
model: Type[LanceModel]
|
||||||
|
The pydantic model to use.
|
||||||
|
|
||||||
|
Returns
|
||||||
|
-------
|
||||||
|
List[LanceModel]
|
||||||
|
"""
|
||||||
|
return [
|
||||||
|
model(**{k: v for k, v in row.items() if k in model.field_names()})
|
||||||
|
for row in self.to_arrow().to_pylist()
|
||||||
|
]
|
||||||
|
|
||||||
|
def limit(self, limit: int) -> LanceVectorQueryBuilder:
|
||||||
|
"""Set the maximum number of results to return.
|
||||||
|
|
||||||
|
Parameters
|
||||||
|
----------
|
||||||
|
limit: int
|
||||||
|
The maximum number of results to return.
|
||||||
|
|
||||||
|
Returns
|
||||||
|
-------
|
||||||
|
LanceVectorQueryBuilder
|
||||||
|
The LanceQueryBuilder object.
|
||||||
|
"""
|
||||||
|
self._limit = limit
|
||||||
|
return self
|
||||||
|
|
||||||
|
def select(self, columns: list) -> LanceVectorQueryBuilder:
|
||||||
|
"""Set the columns to return.
|
||||||
|
|
||||||
|
Parameters
|
||||||
|
----------
|
||||||
|
columns: list
|
||||||
|
The columns to return.
|
||||||
|
|
||||||
|
Returns
|
||||||
|
-------
|
||||||
|
LanceVectorQueryBuilder
|
||||||
|
The LanceQueryBuilder object.
|
||||||
|
"""
|
||||||
|
self._columns = columns
|
||||||
|
return self
|
||||||
|
|
||||||
|
def where(self, where: str) -> LanceVectorQueryBuilder:
|
||||||
|
"""Set the where clause.
|
||||||
|
|
||||||
|
Parameters
|
||||||
|
----------
|
||||||
|
where: str
|
||||||
|
The where clause.
|
||||||
|
|
||||||
|
Returns
|
||||||
|
-------
|
||||||
|
LanceVectorQueryBuilder
|
||||||
|
The LanceQueryBuilder object.
|
||||||
|
"""
|
||||||
|
self._where = where
|
||||||
|
return self
|
||||||
|
|
||||||
|
|
||||||
|
class LanceVectorQueryBuilder(LanceQueryBuilder):
|
||||||
"""
|
"""
|
||||||
A builder for nearest neighbor queries for LanceDB.
|
A builder for nearest neighbor queries for LanceDB.
|
||||||
|
|
||||||
@@ -70,75 +230,24 @@ class LanceQueryBuilder:
|
|||||||
... .select(["b"])
|
... .select(["b"])
|
||||||
... .limit(2)
|
... .limit(2)
|
||||||
... .to_df())
|
... .to_df())
|
||||||
b vector score
|
b vector _distance
|
||||||
0 6 [0.4, 0.4] 0.0
|
0 6 [0.4, 0.4] 0.0
|
||||||
"""
|
"""
|
||||||
|
|
||||||
def __init__(
|
def __init__(
|
||||||
self,
|
self,
|
||||||
table: "lancedb.table.Table",
|
table: "lancedb.table.Table",
|
||||||
query: Union[np.ndarray, str],
|
query: Union[np.ndarray, list, "PIL.Image.Image"],
|
||||||
vector_column: str = VECTOR_COLUMN_NAME,
|
vector_column: str = VECTOR_COLUMN_NAME,
|
||||||
):
|
):
|
||||||
|
super().__init__(table)
|
||||||
|
self._query = query
|
||||||
self._metric = "L2"
|
self._metric = "L2"
|
||||||
self._nprobes = 20
|
self._nprobes = 20
|
||||||
self._refine_factor = None
|
self._refine_factor = None
|
||||||
self._table = table
|
|
||||||
self._query = query
|
|
||||||
self._limit = 10
|
|
||||||
self._columns = None
|
|
||||||
self._where = None
|
|
||||||
self._vector_column = vector_column
|
self._vector_column = vector_column
|
||||||
|
|
||||||
def limit(self, limit: int) -> LanceQueryBuilder:
|
def metric(self, metric: Literal["L2", "cosine"]) -> LanceVectorQueryBuilder:
|
||||||
"""Set the maximum number of results to return.
|
|
||||||
|
|
||||||
Parameters
|
|
||||||
----------
|
|
||||||
limit: int
|
|
||||||
The maximum number of results to return.
|
|
||||||
|
|
||||||
Returns
|
|
||||||
-------
|
|
||||||
LanceQueryBuilder
|
|
||||||
The LanceQueryBuilder object.
|
|
||||||
"""
|
|
||||||
self._limit = limit
|
|
||||||
return self
|
|
||||||
|
|
||||||
def select(self, columns: list) -> LanceQueryBuilder:
|
|
||||||
"""Set the columns to return.
|
|
||||||
|
|
||||||
Parameters
|
|
||||||
----------
|
|
||||||
columns: list
|
|
||||||
The columns to return.
|
|
||||||
|
|
||||||
Returns
|
|
||||||
-------
|
|
||||||
LanceQueryBuilder
|
|
||||||
The LanceQueryBuilder object.
|
|
||||||
"""
|
|
||||||
self._columns = columns
|
|
||||||
return self
|
|
||||||
|
|
||||||
def where(self, where: str) -> LanceQueryBuilder:
|
|
||||||
"""Set the where clause.
|
|
||||||
|
|
||||||
Parameters
|
|
||||||
----------
|
|
||||||
where: str
|
|
||||||
The where clause.
|
|
||||||
|
|
||||||
Returns
|
|
||||||
-------
|
|
||||||
LanceQueryBuilder
|
|
||||||
The LanceQueryBuilder object.
|
|
||||||
"""
|
|
||||||
self._where = where
|
|
||||||
return self
|
|
||||||
|
|
||||||
def metric(self, metric: Literal["L2", "cosine"]) -> LanceQueryBuilder:
|
|
||||||
"""Set the distance metric to use.
|
"""Set the distance metric to use.
|
||||||
|
|
||||||
Parameters
|
Parameters
|
||||||
@@ -148,13 +257,13 @@ class LanceQueryBuilder:
|
|||||||
|
|
||||||
Returns
|
Returns
|
||||||
-------
|
-------
|
||||||
LanceQueryBuilder
|
LanceVectorQueryBuilder
|
||||||
The LanceQueryBuilder object.
|
The LanceQueryBuilder object.
|
||||||
"""
|
"""
|
||||||
self._metric = metric
|
self._metric = metric
|
||||||
return self
|
return self
|
||||||
|
|
||||||
def nprobes(self, nprobes: int) -> LanceQueryBuilder:
|
def nprobes(self, nprobes: int) -> LanceVectorQueryBuilder:
|
||||||
"""Set the number of probes to use.
|
"""Set the number of probes to use.
|
||||||
|
|
||||||
Higher values will yield better recall (more likely to find vectors if
|
Higher values will yield better recall (more likely to find vectors if
|
||||||
@@ -170,13 +279,13 @@ class LanceQueryBuilder:
|
|||||||
|
|
||||||
Returns
|
Returns
|
||||||
-------
|
-------
|
||||||
LanceQueryBuilder
|
LanceVectorQueryBuilder
|
||||||
The LanceQueryBuilder object.
|
The LanceQueryBuilder object.
|
||||||
"""
|
"""
|
||||||
self._nprobes = nprobes
|
self._nprobes = nprobes
|
||||||
return self
|
return self
|
||||||
|
|
||||||
def refine_factor(self, refine_factor: int) -> LanceQueryBuilder:
|
def refine_factor(self, refine_factor: int) -> LanceVectorQueryBuilder:
|
||||||
"""Set the refine factor to use, increasing the number of vectors sampled.
|
"""Set the refine factor to use, increasing the number of vectors sampled.
|
||||||
|
|
||||||
As an example, a refine factor of 2 will sample 2x as many vectors as
|
As an example, a refine factor of 2 will sample 2x as many vectors as
|
||||||
@@ -192,29 +301,19 @@ class LanceQueryBuilder:
|
|||||||
|
|
||||||
Returns
|
Returns
|
||||||
-------
|
-------
|
||||||
LanceQueryBuilder
|
LanceVectorQueryBuilder
|
||||||
The LanceQueryBuilder object.
|
The LanceQueryBuilder object.
|
||||||
"""
|
"""
|
||||||
self._refine_factor = refine_factor
|
self._refine_factor = refine_factor
|
||||||
return self
|
return self
|
||||||
|
|
||||||
def to_df(self) -> pd.DataFrame:
|
|
||||||
"""
|
|
||||||
Execute the query and return the results as a pandas DataFrame.
|
|
||||||
In addition to the selected columns, LanceDB also returns a vector
|
|
||||||
and also the "score" column which is the distance between the query
|
|
||||||
vector and the returned vector.
|
|
||||||
"""
|
|
||||||
|
|
||||||
return self.to_arrow().to_pandas()
|
|
||||||
|
|
||||||
def to_arrow(self) -> pa.Table:
|
def to_arrow(self) -> pa.Table:
|
||||||
"""
|
"""
|
||||||
Execute the query and return the results as an
|
Execute the query and return the results as an
|
||||||
[Apache Arrow Table](https://arrow.apache.org/docs/python/generated/pyarrow.Table.html#pyarrow.Table).
|
[Apache Arrow Table](https://arrow.apache.org/docs/python/generated/pyarrow.Table.html#pyarrow.Table).
|
||||||
|
|
||||||
In addition to the selected columns, LanceDB also returns a vector
|
In addition to the selected columns, LanceDB also returns a vector
|
||||||
and also the "score" column which is the distance between the query
|
and also the "_distance" column which is the distance between the query
|
||||||
vector and the returned vectors.
|
vector and the returned vectors.
|
||||||
"""
|
"""
|
||||||
vector = self._query if isinstance(self._query, list) else self._query.tolist()
|
vector = self._query if isinstance(self._query, list) else self._query.tolist()
|
||||||
@@ -232,7 +331,11 @@ class LanceQueryBuilder:
|
|||||||
|
|
||||||
|
|
||||||
class LanceFtsQueryBuilder(LanceQueryBuilder):
|
class LanceFtsQueryBuilder(LanceQueryBuilder):
|
||||||
def to_arrow(self) -> pd.Table:
|
def __init__(self, table: "lancedb.table.Table", query: str):
|
||||||
|
super().__init__(table)
|
||||||
|
self._query = query
|
||||||
|
|
||||||
|
def to_arrow(self) -> pa.Table:
|
||||||
try:
|
try:
|
||||||
import tantivy
|
import tantivy
|
||||||
except ImportError:
|
except ImportError:
|
||||||
@@ -255,3 +358,13 @@ class LanceFtsQueryBuilder(LanceQueryBuilder):
|
|||||||
output_tbl = self._table.to_lance().take(row_ids, columns=self._columns)
|
output_tbl = self._table.to_lance().take(row_ids, columns=self._columns)
|
||||||
output_tbl = output_tbl.append_column("score", scores)
|
output_tbl = output_tbl.append_column("score", scores)
|
||||||
return output_tbl
|
return output_tbl
|
||||||
|
|
||||||
|
|
||||||
|
class LanceEmptyQueryBuilder(LanceQueryBuilder):
|
||||||
|
def to_arrow(self) -> pa.Table:
|
||||||
|
ds = self._table.to_lance()
|
||||||
|
return ds.to_table(
|
||||||
|
columns=self._columns,
|
||||||
|
filter=self._where,
|
||||||
|
limit=self._limit,
|
||||||
|
)
|
||||||
|
|||||||
@@ -48,11 +48,16 @@ class RestfulLanceDBClient:
|
|||||||
db_name: str
|
db_name: str
|
||||||
region: str
|
region: str
|
||||||
api_key: Credential
|
api_key: Credential
|
||||||
|
host_override: Optional[str] = attr.field(default=None)
|
||||||
|
|
||||||
closed: bool = attr.field(default=False, init=False)
|
closed: bool = attr.field(default=False, init=False)
|
||||||
|
|
||||||
@functools.cached_property
|
@functools.cached_property
|
||||||
def session(self) -> aiohttp.ClientSession:
|
def session(self) -> aiohttp.ClientSession:
|
||||||
url = f"https://{self.db_name}.{self.region}.api.lancedb.com"
|
url = (
|
||||||
|
self.host_override
|
||||||
|
or f"https://{self.db_name}.{self.region}.api.lancedb.com"
|
||||||
|
)
|
||||||
return aiohttp.ClientSession(url)
|
return aiohttp.ClientSession(url)
|
||||||
|
|
||||||
async def close(self):
|
async def close(self):
|
||||||
@@ -66,6 +71,8 @@ class RestfulLanceDBClient:
|
|||||||
}
|
}
|
||||||
if self.region == "local": # Local test mode
|
if self.region == "local": # Local test mode
|
||||||
headers["Host"] = f"{self.db_name}.{self.region}.api.lancedb.com"
|
headers["Host"] = f"{self.db_name}.{self.region}.api.lancedb.com"
|
||||||
|
if self.host_override:
|
||||||
|
headers["x-lancedb-database"] = self.db_name
|
||||||
return headers
|
return headers
|
||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
@@ -90,7 +97,12 @@ class RestfulLanceDBClient:
|
|||||||
"""Send a GET request and returns the deserialized response payload."""
|
"""Send a GET request and returns the deserialized response payload."""
|
||||||
if isinstance(params, BaseModel):
|
if isinstance(params, BaseModel):
|
||||||
params: Dict[str, Any] = params.dict(exclude_none=True)
|
params: Dict[str, Any] = params.dict(exclude_none=True)
|
||||||
async with self.session.get(uri, params=params, headers=self.headers) as resp:
|
async with self.session.get(
|
||||||
|
uri,
|
||||||
|
params=params,
|
||||||
|
headers=self.headers,
|
||||||
|
timeout=aiohttp.ClientTimeout(total=30),
|
||||||
|
) as resp:
|
||||||
await self._check_status(resp)
|
await self._check_status(resp)
|
||||||
return await resp.json()
|
return await resp.json()
|
||||||
|
|
||||||
@@ -98,10 +110,11 @@ class RestfulLanceDBClient:
|
|||||||
async def post(
|
async def post(
|
||||||
self,
|
self,
|
||||||
uri: str,
|
uri: str,
|
||||||
data: Union[Dict[str, Any], BaseModel, bytes],
|
data: Optional[Union[Dict[str, Any], BaseModel, bytes]] = None,
|
||||||
params: Optional[Dict[str, Any]] = None,
|
params: Optional[Dict[str, Any]] = None,
|
||||||
content_type: Optional[str] = None,
|
content_type: Optional[str] = None,
|
||||||
deserialize: Callable = lambda resp: resp.json(),
|
deserialize: Callable = lambda resp: resp.json(),
|
||||||
|
request_id: Optional[str] = None,
|
||||||
) -> Dict[str, Any]:
|
) -> Dict[str, Any]:
|
||||||
"""Send a POST request and returns the deserialized response payload.
|
"""Send a POST request and returns the deserialized response payload.
|
||||||
|
|
||||||
@@ -110,6 +123,8 @@ class RestfulLanceDBClient:
|
|||||||
uri : str
|
uri : str
|
||||||
The uri to send the POST request to.
|
The uri to send the POST request to.
|
||||||
data: Union[Dict[str, Any], BaseModel]
|
data: Union[Dict[str, Any], BaseModel]
|
||||||
|
request_id: Optional[str]
|
||||||
|
Optional client side request id to be sent in the request headers.
|
||||||
|
|
||||||
"""
|
"""
|
||||||
if isinstance(data, BaseModel):
|
if isinstance(data, BaseModel):
|
||||||
@@ -122,10 +137,13 @@ class RestfulLanceDBClient:
|
|||||||
headers = self.headers.copy()
|
headers = self.headers.copy()
|
||||||
if content_type is not None:
|
if content_type is not None:
|
||||||
headers["content-type"] = content_type
|
headers["content-type"] = content_type
|
||||||
|
if request_id is not None:
|
||||||
|
headers["x-request-id"] = request_id
|
||||||
async with self.session.post(
|
async with self.session.post(
|
||||||
uri,
|
uri,
|
||||||
headers=headers,
|
headers=headers,
|
||||||
params=params,
|
params=params,
|
||||||
|
timeout=aiohttp.ClientTimeout(total=30),
|
||||||
**req_kwargs,
|
**req_kwargs,
|
||||||
) as resp:
|
) as resp:
|
||||||
resp: aiohttp.ClientResponse = resp
|
resp: aiohttp.ClientResponse = resp
|
||||||
@@ -141,5 +159,7 @@ class RestfulLanceDBClient:
|
|||||||
@_check_not_closed
|
@_check_not_closed
|
||||||
async def query(self, table_name: str, query: VectorQuery) -> VectorQueryResult:
|
async def query(self, table_name: str, query: VectorQuery) -> VectorQueryResult:
|
||||||
"""Query a table."""
|
"""Query a table."""
|
||||||
tbl = await self.post(f"/v1/table/{table_name}/", query, deserialize=_read_ipc)
|
tbl = await self.post(
|
||||||
|
f"/v1/table/{table_name}/query/", query, deserialize=_read_ipc
|
||||||
|
)
|
||||||
return VectorQueryResult(tbl)
|
return VectorQueryResult(tbl)
|
||||||
|
|||||||
@@ -13,16 +13,14 @@
|
|||||||
|
|
||||||
import asyncio
|
import asyncio
|
||||||
import uuid
|
import uuid
|
||||||
from typing import List
|
from typing import List, Optional
|
||||||
from urllib.parse import urlparse
|
from urllib.parse import urlparse
|
||||||
|
|
||||||
import pyarrow as pa
|
import pyarrow as pa
|
||||||
|
|
||||||
from lancedb.common import DATA
|
from ..common import DATA
|
||||||
from lancedb.db import DBConnection
|
from ..db import DBConnection
|
||||||
from lancedb.schema import schema_to_json
|
from ..table import Table, _sanitize_data
|
||||||
from lancedb.table import Table, _sanitize_data
|
|
||||||
|
|
||||||
from .arrow import to_ipc_binary
|
from .arrow import to_ipc_binary
|
||||||
from .client import ARROW_STREAM_CONTENT_TYPE, RestfulLanceDBClient
|
from .client import ARROW_STREAM_CONTENT_TYPE, RestfulLanceDBClient
|
||||||
|
|
||||||
@@ -30,14 +28,22 @@ from .client import ARROW_STREAM_CONTENT_TYPE, RestfulLanceDBClient
|
|||||||
class RemoteDBConnection(DBConnection):
|
class RemoteDBConnection(DBConnection):
|
||||||
"""A connection to a remote LanceDB database."""
|
"""A connection to a remote LanceDB database."""
|
||||||
|
|
||||||
def __init__(self, db_url: str, api_key: str, region: str):
|
def __init__(
|
||||||
|
self,
|
||||||
|
db_url: str,
|
||||||
|
api_key: str,
|
||||||
|
region: str,
|
||||||
|
host_override: Optional[str] = None,
|
||||||
|
):
|
||||||
"""Connect to a remote LanceDB database."""
|
"""Connect to a remote LanceDB database."""
|
||||||
parsed = urlparse(db_url)
|
parsed = urlparse(db_url)
|
||||||
if parsed.scheme != "db":
|
if parsed.scheme != "db":
|
||||||
raise ValueError(f"Invalid scheme: {parsed.scheme}, only accepts db://")
|
raise ValueError(f"Invalid scheme: {parsed.scheme}, only accepts db://")
|
||||||
self.db_name = parsed.netloc
|
self.db_name = parsed.netloc
|
||||||
self.api_key = api_key
|
self.api_key = api_key
|
||||||
self._client = RestfulLanceDBClient(self.db_name, region, api_key)
|
self._client = RestfulLanceDBClient(
|
||||||
|
self.db_name, region, api_key, host_override
|
||||||
|
)
|
||||||
try:
|
try:
|
||||||
self._loop = asyncio.get_running_loop()
|
self._loop = asyncio.get_running_loop()
|
||||||
except RuntimeError:
|
except RuntimeError:
|
||||||
@@ -95,10 +101,24 @@ class RemoteDBConnection(DBConnection):
|
|||||||
|
|
||||||
self._loop.run_until_complete(
|
self._loop.run_until_complete(
|
||||||
self._client.post(
|
self._client.post(
|
||||||
f"/v1/table/{name}/create",
|
f"/v1/table/{name}/create/",
|
||||||
data=data,
|
data=data,
|
||||||
params={"request_id": request_id},
|
request_id=request_id,
|
||||||
content_type=ARROW_STREAM_CONTENT_TYPE,
|
content_type=ARROW_STREAM_CONTENT_TYPE,
|
||||||
)
|
)
|
||||||
)
|
)
|
||||||
return RemoteTable(self, name)
|
return RemoteTable(self, name)
|
||||||
|
|
||||||
|
def drop_table(self, name: str):
|
||||||
|
"""Drop a table from the database.
|
||||||
|
|
||||||
|
Parameters
|
||||||
|
----------
|
||||||
|
name: str
|
||||||
|
The name of the table.
|
||||||
|
"""
|
||||||
|
self._loop.run_until_complete(
|
||||||
|
self._client.post(
|
||||||
|
f"/v1/table/{name}/drop/",
|
||||||
|
)
|
||||||
|
)
|
||||||
|
|||||||
@@ -16,11 +16,11 @@ from functools import cached_property
|
|||||||
from typing import Union
|
from typing import Union
|
||||||
|
|
||||||
import pyarrow as pa
|
import pyarrow as pa
|
||||||
|
from lance import json_to_schema
|
||||||
|
|
||||||
from lancedb.common import DATA, VEC, VECTOR_COLUMN_NAME
|
from lancedb.common import DATA, VEC, VECTOR_COLUMN_NAME
|
||||||
|
|
||||||
from ..query import LanceQueryBuilder, Query
|
from ..query import LanceVectorQueryBuilder
|
||||||
from ..schema import json_to_schema
|
|
||||||
from ..table import Query, Table, _sanitize_data
|
from ..table import Query, Table, _sanitize_data
|
||||||
from .arrow import to_ipc_binary
|
from .arrow import to_ipc_binary
|
||||||
from .client import ARROW_STREAM_CONTENT_TYPE
|
from .client import ARROW_STREAM_CONTENT_TYPE
|
||||||
@@ -33,19 +33,27 @@ class RemoteTable(Table):
|
|||||||
self._name = name
|
self._name = name
|
||||||
|
|
||||||
def __repr__(self) -> str:
|
def __repr__(self) -> str:
|
||||||
return f"RemoteTable({self._conn.db_name}.{self.name})"
|
return f"RemoteTable({self._conn.db_name}.{self._name})"
|
||||||
|
|
||||||
@cached_property
|
@cached_property
|
||||||
def schema(self) -> pa.Schema:
|
def schema(self) -> pa.Schema:
|
||||||
"""Return the schema of the table."""
|
"""Return the schema of the table."""
|
||||||
resp = self._conn._loop.run_until_complete(
|
resp = self._conn._loop.run_until_complete(
|
||||||
self._conn._client.get(f"/v1/table/{self._name}/describe")
|
self._conn._client.post(f"/v1/table/{self._name}/describe/")
|
||||||
)
|
)
|
||||||
schema = json_to_schema(resp["schema"])
|
schema = json_to_schema(resp["schema"])
|
||||||
return schema
|
return schema
|
||||||
|
|
||||||
def to_arrow(self) -> pa.Table:
|
def to_arrow(self) -> pa.Table:
|
||||||
raise NotImplementedError
|
"""Return the table as an Arrow table."""
|
||||||
|
raise NotImplementedError("to_arrow() is not supported on the LanceDB cloud")
|
||||||
|
|
||||||
|
def to_pandas(self):
|
||||||
|
"""Return the table as a Pandas DataFrame.
|
||||||
|
|
||||||
|
Intercept `to_arrow()` for better error message.
|
||||||
|
"""
|
||||||
|
return NotImplementedError("to_pandas() is not supported on the LanceDB cloud")
|
||||||
|
|
||||||
def create_index(
|
def create_index(
|
||||||
self,
|
self,
|
||||||
@@ -65,7 +73,11 @@ class RemoteTable(Table):
|
|||||||
fill_value: float = 0.0,
|
fill_value: float = 0.0,
|
||||||
) -> int:
|
) -> int:
|
||||||
data = _sanitize_data(
|
data = _sanitize_data(
|
||||||
data, self.schema, on_bad_vectors=on_bad_vectors, fill_value=fill_value
|
data,
|
||||||
|
self.schema,
|
||||||
|
metadata=None,
|
||||||
|
on_bad_vectors=on_bad_vectors,
|
||||||
|
fill_value=fill_value,
|
||||||
)
|
)
|
||||||
payload = to_ipc_binary(data)
|
payload = to_ipc_binary(data)
|
||||||
|
|
||||||
@@ -73,7 +85,7 @@ class RemoteTable(Table):
|
|||||||
|
|
||||||
self._conn._loop.run_until_complete(
|
self._conn._loop.run_until_complete(
|
||||||
self._conn._client.post(
|
self._conn._client.post(
|
||||||
f"/v1/table/{self._name}/insert",
|
f"/v1/table/{self._name}/insert/",
|
||||||
data=payload,
|
data=payload,
|
||||||
params={"request_id": request_id, "mode": mode},
|
params={"request_id": request_id, "mode": mode},
|
||||||
content_type=ARROW_STREAM_CONTENT_TYPE,
|
content_type=ARROW_STREAM_CONTENT_TYPE,
|
||||||
@@ -81,9 +93,9 @@ class RemoteTable(Table):
|
|||||||
)
|
)
|
||||||
|
|
||||||
def search(
|
def search(
|
||||||
self, query: Union[VEC, str], vector_column: str = VECTOR_COLUMN_NAME
|
self, query: Union[VEC, str], vector_column_name: str = VECTOR_COLUMN_NAME
|
||||||
) -> LanceQueryBuilder:
|
) -> LanceVectorQueryBuilder:
|
||||||
return LanceQueryBuilder(self, query, vector_column)
|
return LanceVectorQueryBuilder(self, query, vector_column_name)
|
||||||
|
|
||||||
def _execute_query(self, query: Query) -> pa.Table:
|
def _execute_query(self, query: Query) -> pa.Table:
|
||||||
result = self._conn._client.query(self._name, query)
|
result = self._conn._client.query(self._name, query)
|
||||||
|
|||||||
@@ -12,11 +12,7 @@
|
|||||||
# limitations under the License.
|
# limitations under the License.
|
||||||
|
|
||||||
"""Schema related utilities."""
|
"""Schema related utilities."""
|
||||||
|
|
||||||
from typing import Any, Dict, Type
|
|
||||||
|
|
||||||
import pyarrow as pa
|
import pyarrow as pa
|
||||||
from lance import json_to_schema, schema_to_json
|
|
||||||
|
|
||||||
|
|
||||||
def vector(dimension: int, value_type: pa.DataType = pa.float32()) -> pa.DataType:
|
def vector(dimension: int, value_type: pa.DataType = pa.float32()) -> pa.DataType:
|
||||||
|
|||||||
@@ -13,45 +13,104 @@
|
|||||||
|
|
||||||
from __future__ import annotations
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import inspect
|
||||||
import os
|
import os
|
||||||
from abc import ABC, abstractmethod
|
from abc import ABC, abstractmethod
|
||||||
from functools import cached_property
|
from functools import cached_property
|
||||||
from typing import Iterable, List, Union
|
from typing import Any, Iterable, List, Optional, Union
|
||||||
|
|
||||||
import lance
|
import lance
|
||||||
import numpy as np
|
import numpy as np
|
||||||
import pandas as pd
|
|
||||||
import pyarrow as pa
|
import pyarrow as pa
|
||||||
import pyarrow.compute as pc
|
import pyarrow.compute as pc
|
||||||
import pyarrow.fs
|
|
||||||
from lance import LanceDataset
|
from lance import LanceDataset
|
||||||
|
from lance.dataset import ReaderLike
|
||||||
from lance.vector import vec_to_table
|
from lance.vector import vec_to_table
|
||||||
|
|
||||||
from .common import DATA, VEC, VECTOR_COLUMN_NAME
|
from .common import DATA, VEC, VECTOR_COLUMN_NAME
|
||||||
from .query import LanceFtsQueryBuilder, LanceQueryBuilder, Query
|
from .embeddings import EmbeddingFunctionRegistry
|
||||||
|
from .embeddings.functions import EmbeddingFunctionConfig
|
||||||
|
from .pydantic import LanceModel
|
||||||
|
from .query import LanceQueryBuilder, Query
|
||||||
|
from .util import fs_from_uri, safe_import_pandas
|
||||||
|
|
||||||
|
pd = safe_import_pandas()
|
||||||
|
|
||||||
|
|
||||||
def _sanitize_data(data, schema, on_bad_vectors, fill_value):
|
def _sanitize_data(
|
||||||
|
data,
|
||||||
|
schema: Optional[pa.Schema],
|
||||||
|
metadata: Optional[dict],
|
||||||
|
on_bad_vectors: str,
|
||||||
|
fill_value: Any,
|
||||||
|
):
|
||||||
if isinstance(data, list):
|
if isinstance(data, list):
|
||||||
|
# convert to list of dict if data is a bunch of LanceModels
|
||||||
|
if isinstance(data[0], LanceModel):
|
||||||
|
schema = data[0].__class__.to_arrow_schema()
|
||||||
|
data = [dict(d) for d in data]
|
||||||
data = pa.Table.from_pylist(data)
|
data = pa.Table.from_pylist(data)
|
||||||
data = _sanitize_schema(
|
elif isinstance(data, dict):
|
||||||
data, schema=schema, on_bad_vectors=on_bad_vectors, fill_value=fill_value
|
|
||||||
)
|
|
||||||
if isinstance(data, dict):
|
|
||||||
data = vec_to_table(data)
|
data = vec_to_table(data)
|
||||||
if isinstance(data, pd.DataFrame):
|
elif pd is not None and isinstance(data, pd.DataFrame):
|
||||||
data = pa.Table.from_pandas(data)
|
data = pa.Table.from_pandas(data, preserve_index=False)
|
||||||
|
# Do not serialize Pandas metadata
|
||||||
|
meta = data.schema.metadata if data.schema.metadata is not None else {}
|
||||||
|
meta = {k: v for k, v in meta.items() if k != b"pandas"}
|
||||||
|
data = data.replace_schema_metadata(meta)
|
||||||
|
|
||||||
|
if isinstance(data, pa.Table):
|
||||||
|
if metadata:
|
||||||
|
data = _append_vector_col(data, metadata, schema)
|
||||||
|
metadata.update(data.schema.metadata or {})
|
||||||
|
data = data.replace_schema_metadata(metadata)
|
||||||
data = _sanitize_schema(
|
data = _sanitize_schema(
|
||||||
data, schema=schema, on_bad_vectors=on_bad_vectors, fill_value=fill_value
|
data, schema=schema, on_bad_vectors=on_bad_vectors, fill_value=fill_value
|
||||||
)
|
)
|
||||||
if not isinstance(data, (pa.Table, Iterable)):
|
elif isinstance(data, Iterable):
|
||||||
|
data = _to_record_batch_generator(
|
||||||
|
data, schema, metadata, on_bad_vectors, fill_value
|
||||||
|
)
|
||||||
|
else:
|
||||||
raise TypeError(f"Unsupported data type: {type(data)}")
|
raise TypeError(f"Unsupported data type: {type(data)}")
|
||||||
return data
|
return data
|
||||||
|
|
||||||
|
|
||||||
|
def _append_vector_col(data: pa.Table, metadata: dict, schema: Optional[pa.Schema]):
|
||||||
|
"""
|
||||||
|
Use the embedding function to automatically embed the source column and add the
|
||||||
|
vector column to the table.
|
||||||
|
"""
|
||||||
|
functions = EmbeddingFunctionRegistry.get_instance().parse_functions(metadata)
|
||||||
|
for vector_column, conf in functions.items():
|
||||||
|
func = conf.function
|
||||||
|
if vector_column not in data.column_names:
|
||||||
|
col_data = func.compute_source_embeddings(data[conf.source_column])
|
||||||
|
if schema is not None:
|
||||||
|
dtype = schema.field(vector_column).type
|
||||||
|
else:
|
||||||
|
dtype = pa.list_(pa.float32(), len(col_data[0]))
|
||||||
|
data = data.append_column(
|
||||||
|
pa.field(vector_column, type=dtype), pa.array(col_data, type=dtype)
|
||||||
|
)
|
||||||
|
return data
|
||||||
|
|
||||||
|
|
||||||
|
def _to_record_batch_generator(
|
||||||
|
data: Iterable, schema, metadata, on_bad_vectors, fill_value
|
||||||
|
):
|
||||||
|
for batch in data:
|
||||||
|
if not isinstance(batch, pa.RecordBatch):
|
||||||
|
table = _sanitize_data(batch, schema, metadata, on_bad_vectors, fill_value)
|
||||||
|
for batch in table.to_batches():
|
||||||
|
yield batch
|
||||||
|
else:
|
||||||
|
yield batch
|
||||||
|
|
||||||
|
|
||||||
class Table(ABC):
|
class Table(ABC):
|
||||||
"""
|
"""
|
||||||
A [Table](Table) is a collection of Records in a LanceDB [Database](Database).
|
A Table is a collection of Records in a LanceDB Database.
|
||||||
|
|
||||||
Examples
|
Examples
|
||||||
--------
|
--------
|
||||||
@@ -78,23 +137,24 @@ class Table(ABC):
|
|||||||
Can query the table with [Table.search][lancedb.table.Table.search].
|
Can query the table with [Table.search][lancedb.table.Table.search].
|
||||||
|
|
||||||
>>> table.search([0.4, 0.4]).select(["b"]).to_df()
|
>>> table.search([0.4, 0.4]).select(["b"]).to_df()
|
||||||
b vector score
|
b vector _distance
|
||||||
0 4 [0.5, 1.3] 0.82
|
0 4 [0.5, 1.3] 0.82
|
||||||
1 2 [1.1, 1.2] 1.13
|
1 2 [1.1, 1.2] 1.13
|
||||||
|
|
||||||
Search queries are much faster when an index is created. See
|
Search queries are much faster when an index is created. See
|
||||||
[Table.create_index][lancedb.table.Table.create_index].
|
[Table.create_index][lancedb.table.Table.create_index].
|
||||||
"""
|
"""
|
||||||
|
|
||||||
|
@property
|
||||||
@abstractmethod
|
@abstractmethod
|
||||||
def schema(self) -> pa.Schema:
|
def schema(self) -> pa.Schema:
|
||||||
"""Return the [Arrow Schema](https://arrow.apache.org/docs/python/api/datatypes.html#) of
|
"""The [Arrow Schema](https://arrow.apache.org/docs/python/api/datatypes.html#) of
|
||||||
this [Table](Table)
|
this [Table](Table)
|
||||||
|
|
||||||
"""
|
"""
|
||||||
raise NotImplementedError
|
raise NotImplementedError
|
||||||
|
|
||||||
def to_pandas(self) -> pd.DataFrame:
|
def to_pandas(self):
|
||||||
"""Return the table as a pandas DataFrame.
|
"""Return the table as a pandas DataFrame.
|
||||||
|
|
||||||
Returns
|
Returns
|
||||||
@@ -171,24 +231,37 @@ class Table(ABC):
|
|||||||
|
|
||||||
@abstractmethod
|
@abstractmethod
|
||||||
def search(
|
def search(
|
||||||
self, query: Union[VEC, str], vector_column: str = VECTOR_COLUMN_NAME
|
self,
|
||||||
|
query: Optional[Union[VEC, str, "PIL.Image.Image"]] = None,
|
||||||
|
vector_column_name: str = VECTOR_COLUMN_NAME,
|
||||||
|
query_type: str = "auto",
|
||||||
) -> LanceQueryBuilder:
|
) -> LanceQueryBuilder:
|
||||||
"""Create a search query to find the nearest neighbors
|
"""Create a search query to find the nearest neighbors
|
||||||
of the given query vector.
|
of the given query vector.
|
||||||
|
|
||||||
Parameters
|
Parameters
|
||||||
----------
|
----------
|
||||||
query: list, np.ndarray
|
query: str, list, np.ndarray, PIL.Image.Image, default None
|
||||||
The query vector.
|
The query to search for. If None then
|
||||||
vector_column: str, default "vector"
|
the select/where/limit clauses are applied to filter
|
||||||
|
the table
|
||||||
|
vector_column_name: str, default "vector"
|
||||||
The name of the vector column to search.
|
The name of the vector column to search.
|
||||||
|
query_type: str, default "auto"
|
||||||
|
"vector", "fts", or "auto"
|
||||||
|
If "auto" then the query type is inferred from the query;
|
||||||
|
If `query` is a list/np.ndarray then the query type is "vector";
|
||||||
|
If `query` is a PIL.Image.Image then either do vector search
|
||||||
|
or raise an error if no corresponding embedding function is found.
|
||||||
|
If `query` is a string, then the query type is "vector" if the
|
||||||
|
table has embedding functions else the query type is "fts"
|
||||||
|
|
||||||
Returns
|
Returns
|
||||||
-------
|
-------
|
||||||
LanceQueryBuilder
|
LanceQueryBuilder
|
||||||
A query builder object representing the query.
|
A query builder object representing the query.
|
||||||
Once executed, the query returns selected columns, the vector,
|
Once executed, the query returns selected columns, the vector,
|
||||||
and also the "score" column which is the distance between the query
|
and also the "_distance" column which is the distance between the query
|
||||||
vector and the returned vector.
|
vector and the returned vector.
|
||||||
"""
|
"""
|
||||||
raise NotImplementedError
|
raise NotImplementedError
|
||||||
@@ -255,10 +328,11 @@ class LanceTable(Table):
|
|||||||
self.name = name
|
self.name = name
|
||||||
self._version = version
|
self._version = version
|
||||||
|
|
||||||
def _reset_dataset(self):
|
def _reset_dataset(self, version=None):
|
||||||
try:
|
try:
|
||||||
if "_dataset" in self.__dict__:
|
if "_dataset" in self.__dict__:
|
||||||
del self.__dict__["_dataset"]
|
del self.__dict__["_dataset"]
|
||||||
|
self._version = version
|
||||||
except AttributeError:
|
except AttributeError:
|
||||||
pass
|
pass
|
||||||
|
|
||||||
@@ -284,7 +358,9 @@ class LanceTable(Table):
|
|||||||
def checkout(self, version: int):
|
def checkout(self, version: int):
|
||||||
"""Checkout a version of the table. This is an in-place operation.
|
"""Checkout a version of the table. This is an in-place operation.
|
||||||
|
|
||||||
This allows viewing previous versions of the table.
|
This allows viewing previous versions of the table. If you wish to
|
||||||
|
keep writing to the dataset starting from an old version, then use
|
||||||
|
the `restore` function.
|
||||||
|
|
||||||
Parameters
|
Parameters
|
||||||
----------
|
----------
|
||||||
@@ -297,14 +373,14 @@ class LanceTable(Table):
|
|||||||
>>> db = lancedb.connect("./.lancedb")
|
>>> db = lancedb.connect("./.lancedb")
|
||||||
>>> table = db.create_table("my_table", [{"vector": [1.1, 0.9], "type": "vector"}])
|
>>> table = db.create_table("my_table", [{"vector": [1.1, 0.9], "type": "vector"}])
|
||||||
>>> table.version
|
>>> table.version
|
||||||
1
|
2
|
||||||
>>> table.to_pandas()
|
>>> table.to_pandas()
|
||||||
vector type
|
vector type
|
||||||
0 [1.1, 0.9] vector
|
0 [1.1, 0.9] vector
|
||||||
>>> table.add([{"vector": [0.5, 0.2], "type": "vector"}])
|
>>> table.add([{"vector": [0.5, 0.2], "type": "vector"}])
|
||||||
>>> table.version
|
>>> table.version
|
||||||
2
|
3
|
||||||
>>> table.checkout(1)
|
>>> table.checkout(2)
|
||||||
>>> table.to_pandas()
|
>>> table.to_pandas()
|
||||||
vector type
|
vector type
|
||||||
0 [1.1, 0.9] vector
|
0 [1.1, 0.9] vector
|
||||||
@@ -312,7 +388,54 @@ class LanceTable(Table):
|
|||||||
max_ver = max([v["version"] for v in self._dataset.versions()])
|
max_ver = max([v["version"] for v in self._dataset.versions()])
|
||||||
if version < 1 or version > max_ver:
|
if version < 1 or version > max_ver:
|
||||||
raise ValueError(f"Invalid version {version}")
|
raise ValueError(f"Invalid version {version}")
|
||||||
self._version = version
|
self._reset_dataset(version=version)
|
||||||
|
|
||||||
|
def restore(self, version: int = None):
|
||||||
|
"""Restore a version of the table. This is an in-place operation.
|
||||||
|
|
||||||
|
This creates a new version where the data is equivalent to the
|
||||||
|
specified previous version. Data is not copied (as of python-v0.2.1).
|
||||||
|
|
||||||
|
Parameters
|
||||||
|
----------
|
||||||
|
version : int, default None
|
||||||
|
The version to restore. If unspecified then restores the currently
|
||||||
|
checked out version. If the currently checked out version is the
|
||||||
|
latest version then this is a no-op.
|
||||||
|
|
||||||
|
Examples
|
||||||
|
--------
|
||||||
|
>>> import lancedb
|
||||||
|
>>> db = lancedb.connect("./.lancedb")
|
||||||
|
>>> table = db.create_table("my_table", [{"vector": [1.1, 0.9], "type": "vector"}])
|
||||||
|
>>> table.version
|
||||||
|
2
|
||||||
|
>>> table.to_pandas()
|
||||||
|
vector type
|
||||||
|
0 [1.1, 0.9] vector
|
||||||
|
>>> table.add([{"vector": [0.5, 0.2], "type": "vector"}])
|
||||||
|
>>> table.version
|
||||||
|
3
|
||||||
|
>>> table.restore(2)
|
||||||
|
>>> table.to_pandas()
|
||||||
|
vector type
|
||||||
|
0 [1.1, 0.9] vector
|
||||||
|
>>> len(table.list_versions())
|
||||||
|
4
|
||||||
|
"""
|
||||||
|
max_ver = max([v["version"] for v in self._dataset.versions()])
|
||||||
|
if version is None:
|
||||||
|
version = self.version
|
||||||
|
elif version < 1 or version > max_ver:
|
||||||
|
raise ValueError(f"Invalid version {version}")
|
||||||
|
else:
|
||||||
|
self.checkout(version)
|
||||||
|
|
||||||
|
if version == max_ver:
|
||||||
|
# no-op if restoring the latest version
|
||||||
|
return
|
||||||
|
|
||||||
|
self._dataset.restore()
|
||||||
self._reset_dataset()
|
self._reset_dataset()
|
||||||
|
|
||||||
def __len__(self):
|
def __len__(self):
|
||||||
@@ -328,7 +451,7 @@ class LanceTable(Table):
|
|||||||
"""Return the first n rows of the table."""
|
"""Return the first n rows of the table."""
|
||||||
return self._dataset.head(n)
|
return self._dataset.head(n)
|
||||||
|
|
||||||
def to_pandas(self) -> pd.DataFrame:
|
def to_pandas(self) -> "pd.DataFrame":
|
||||||
"""Return the table as a pandas DataFrame.
|
"""Return the table as a pandas DataFrame.
|
||||||
|
|
||||||
Returns
|
Returns
|
||||||
@@ -405,6 +528,9 @@ class LanceTable(Table):
|
|||||||
fill_value: float = 0.0,
|
fill_value: float = 0.0,
|
||||||
):
|
):
|
||||||
"""Add data to the table.
|
"""Add data to the table.
|
||||||
|
If vector columns are missing and the table
|
||||||
|
has embedding functions, then the vector columns
|
||||||
|
are automatically computed and added.
|
||||||
|
|
||||||
Parameters
|
Parameters
|
||||||
----------
|
----------
|
||||||
@@ -426,43 +552,130 @@ class LanceTable(Table):
|
|||||||
"""
|
"""
|
||||||
# TODO: manage table listing and metadata separately
|
# TODO: manage table listing and metadata separately
|
||||||
data = _sanitize_data(
|
data = _sanitize_data(
|
||||||
data, self.schema, on_bad_vectors=on_bad_vectors, fill_value=fill_value
|
data,
|
||||||
|
self.schema,
|
||||||
|
metadata=self.schema.metadata,
|
||||||
|
on_bad_vectors=on_bad_vectors,
|
||||||
|
fill_value=fill_value,
|
||||||
)
|
)
|
||||||
lance.write_dataset(data, self._dataset_uri, mode=mode)
|
lance.write_dataset(data, self._dataset_uri, schema=self.schema, mode=mode)
|
||||||
self._reset_dataset()
|
self._reset_dataset()
|
||||||
|
|
||||||
|
def merge(
|
||||||
|
self,
|
||||||
|
other_table: Union[LanceTable, ReaderLike],
|
||||||
|
left_on: str,
|
||||||
|
right_on: Optional[str] = None,
|
||||||
|
schema: Optional[Union[pa.Schema, LanceModel]] = None,
|
||||||
|
):
|
||||||
|
"""Merge another table into this table.
|
||||||
|
|
||||||
|
Performs a left join, where the dataset is the left side and other_table
|
||||||
|
is the right side. Rows existing in the dataset but not on the left will
|
||||||
|
be filled with null values, unless Lance doesn't support null values for
|
||||||
|
some types, in which case an error will be raised. The only overlapping
|
||||||
|
column allowed is the join column. If other overlapping columns exist,
|
||||||
|
an error will be raised.
|
||||||
|
|
||||||
|
Parameters
|
||||||
|
----------
|
||||||
|
other_table: LanceTable or Reader-like
|
||||||
|
The data to be merged. Acceptable types are:
|
||||||
|
- Pandas DataFrame, Pyarrow Table, Dataset, Scanner,
|
||||||
|
Iterator[RecordBatch], or RecordBatchReader
|
||||||
|
- LanceTable
|
||||||
|
left_on: str
|
||||||
|
The name of the column in the dataset to join on.
|
||||||
|
right_on: str or None
|
||||||
|
The name of the column in other_table to join on. If None, defaults to
|
||||||
|
left_on.
|
||||||
|
schema: pa.Schema or LanceModel, optional
|
||||||
|
The schema of the other_table.
|
||||||
|
If not provided, the schema is inferred from the data.
|
||||||
|
|
||||||
|
Examples
|
||||||
|
--------
|
||||||
|
>>> import lancedb
|
||||||
|
>>> import pyarrow as pa
|
||||||
|
>>> df = pa.table({'x': [1, 2, 3], 'y': ['a', 'b', 'c']})
|
||||||
|
>>> db = lancedb.connect("./.lancedb")
|
||||||
|
>>> table = db.create_table("dataset", df)
|
||||||
|
>>> table.to_pandas()
|
||||||
|
x y
|
||||||
|
0 1 a
|
||||||
|
1 2 b
|
||||||
|
2 3 c
|
||||||
|
>>> new_df = pa.table({'x': [1, 2, 3], 'z': ['d', 'e', 'f']})
|
||||||
|
>>> table.merge(new_df, 'x')
|
||||||
|
>>> table.to_pandas()
|
||||||
|
x y z
|
||||||
|
0 1 a d
|
||||||
|
1 2 b e
|
||||||
|
2 3 c f
|
||||||
|
"""
|
||||||
|
if isinstance(schema, LanceModel):
|
||||||
|
schema = schema.to_arrow_schema()
|
||||||
|
if isinstance(other_table, LanceTable):
|
||||||
|
other_table = other_table.to_lance()
|
||||||
|
if isinstance(other_table, LanceDataset):
|
||||||
|
other_table = other_table.to_table()
|
||||||
|
self._dataset.merge(
|
||||||
|
other_table, left_on=left_on, right_on=right_on, schema=schema
|
||||||
|
)
|
||||||
|
self._reset_dataset()
|
||||||
|
|
||||||
|
@cached_property
|
||||||
|
def embedding_functions(self) -> dict:
|
||||||
|
"""
|
||||||
|
Get the embedding functions for the table
|
||||||
|
|
||||||
|
Returns
|
||||||
|
-------
|
||||||
|
funcs: dict
|
||||||
|
A mapping of the vector column to the embedding function
|
||||||
|
or empty dict if not configured.
|
||||||
|
"""
|
||||||
|
return EmbeddingFunctionRegistry.get_instance().parse_functions(
|
||||||
|
self.schema.metadata
|
||||||
|
)
|
||||||
|
|
||||||
def search(
|
def search(
|
||||||
self, query: Union[VEC, str], vector_column_name=VECTOR_COLUMN_NAME
|
self,
|
||||||
|
query: Optional[Union[VEC, str, "PIL.Image.Image"]] = None,
|
||||||
|
vector_column_name: str = VECTOR_COLUMN_NAME,
|
||||||
|
query_type: str = "auto",
|
||||||
) -> LanceQueryBuilder:
|
) -> LanceQueryBuilder:
|
||||||
"""Create a search query to find the nearest neighbors
|
"""Create a search query to find the nearest neighbors
|
||||||
of the given query vector.
|
of the given query vector.
|
||||||
|
|
||||||
Parameters
|
Parameters
|
||||||
----------
|
----------
|
||||||
query: list, np.ndarray
|
query: str, list, np.ndarray, a PIL Image or None
|
||||||
The query vector.
|
The query to search for. If None then
|
||||||
|
the select/where/limit clauses are applied to filter
|
||||||
|
the table
|
||||||
vector_column_name: str, default "vector"
|
vector_column_name: str, default "vector"
|
||||||
The name of the vector column to search.
|
The name of the vector column to search.
|
||||||
|
query_type: str, default "auto"
|
||||||
|
"vector", "fts", or "auto"
|
||||||
|
If "auto" then the query type is inferred from the query;
|
||||||
|
If `query` is a list/np.ndarray then the query type is "vector";
|
||||||
|
If `query` is a PIL.Image.Image then either do vector search
|
||||||
|
or raise an error if no corresponding embedding function is found.
|
||||||
|
If the query is a string, then the query type is "vector" if the
|
||||||
|
table has embedding functions, else the query type is "fts"
|
||||||
|
|
||||||
Returns
|
Returns
|
||||||
-------
|
-------
|
||||||
LanceQueryBuilder
|
LanceQueryBuilder
|
||||||
A query builder object representing the query.
|
A query builder object representing the query.
|
||||||
Once executed, the query returns selected columns, the vector,
|
Once executed, the query returns selected columns, the vector,
|
||||||
and also the "score" column which is the distance between the query
|
and also the "_distance" column which is the distance between the query
|
||||||
vector and the returned vector.
|
vector and the returned vector.
|
||||||
"""
|
"""
|
||||||
if isinstance(query, str):
|
return LanceQueryBuilder.create(
|
||||||
# fts
|
self, query, query_type, vector_column_name=vector_column_name
|
||||||
return LanceFtsQueryBuilder(self, query, vector_column_name)
|
)
|
||||||
|
|
||||||
if isinstance(query, list):
|
|
||||||
query = np.array(query)
|
|
||||||
if isinstance(query, np.ndarray):
|
|
||||||
query = query.astype(np.float32)
|
|
||||||
else:
|
|
||||||
raise TypeError(f"Unsupported query type: {type(query)}")
|
|
||||||
return LanceQueryBuilder(self, query, vector_column_name)
|
|
||||||
|
|
||||||
@classmethod
|
@classmethod
|
||||||
def create(
|
def create(
|
||||||
@@ -474,6 +687,7 @@ class LanceTable(Table):
|
|||||||
mode="create",
|
mode="create",
|
||||||
on_bad_vectors: str = "error",
|
on_bad_vectors: str = "error",
|
||||||
fill_value: float = 0.0,
|
fill_value: float = 0.0,
|
||||||
|
embedding_functions: List[EmbeddingFunctionConfig] = None,
|
||||||
):
|
):
|
||||||
"""
|
"""
|
||||||
Create a new table.
|
Create a new table.
|
||||||
@@ -500,7 +714,7 @@ class LanceTable(Table):
|
|||||||
data: list-of-dict, dict, pd.DataFrame, default None
|
data: list-of-dict, dict, pd.DataFrame, default None
|
||||||
The data to insert into the table.
|
The data to insert into the table.
|
||||||
At least one of `data` or `schema` must be provided.
|
At least one of `data` or `schema` must be provided.
|
||||||
schema: dict, optional
|
schema: pa.Schema or LanceModel, optional
|
||||||
The schema of the table. If not provided, the schema is inferred from the data.
|
The schema of the table. If not provided, the schema is inferred from the data.
|
||||||
At least one of `data` or `schema` must be provided.
|
At least one of `data` or `schema` must be provided.
|
||||||
mode: str, default "create"
|
mode: str, default "create"
|
||||||
@@ -511,23 +725,63 @@ class LanceTable(Table):
|
|||||||
One of "error", "drop", "fill".
|
One of "error", "drop", "fill".
|
||||||
fill_value: float, default 0.
|
fill_value: float, default 0.
|
||||||
The value to use when filling vectors. Only used if on_bad_vectors="fill".
|
The value to use when filling vectors. Only used if on_bad_vectors="fill".
|
||||||
|
embedding_functions: list of EmbeddingFunctionModel, default None
|
||||||
|
The embedding functions to use when creating the table.
|
||||||
"""
|
"""
|
||||||
tbl = LanceTable(db, name)
|
tbl = LanceTable(db, name)
|
||||||
|
if inspect.isclass(schema) and issubclass(schema, LanceModel):
|
||||||
|
# convert LanceModel to pyarrow schema
|
||||||
|
# note that it's possible this contains
|
||||||
|
# embedding function metadata already
|
||||||
|
schema = schema.to_arrow_schema()
|
||||||
|
|
||||||
|
metadata = None
|
||||||
|
if embedding_functions is not None:
|
||||||
|
# If we passed in embedding functions explicitly
|
||||||
|
# then we'll override any schema metadata that
|
||||||
|
# may was implicitly specified by the LanceModel schema
|
||||||
|
registry = EmbeddingFunctionRegistry.get_instance()
|
||||||
|
metadata = registry.get_table_metadata(embedding_functions)
|
||||||
|
|
||||||
if data is not None:
|
if data is not None:
|
||||||
data = _sanitize_data(
|
data = _sanitize_data(
|
||||||
data, schema, on_bad_vectors=on_bad_vectors, fill_value=fill_value
|
data,
|
||||||
|
schema,
|
||||||
|
metadata=metadata,
|
||||||
|
on_bad_vectors=on_bad_vectors,
|
||||||
|
fill_value=fill_value,
|
||||||
)
|
)
|
||||||
else:
|
|
||||||
if schema is None:
|
if schema is None:
|
||||||
|
if data is None:
|
||||||
raise ValueError("Either data or schema must be provided")
|
raise ValueError("Either data or schema must be provided")
|
||||||
data = pa.Table.from_pylist([], schema=schema)
|
elif hasattr(data, "schema"):
|
||||||
lance.write_dataset(data, tbl._dataset_uri, schema=schema, mode=mode)
|
schema = data.schema
|
||||||
return LanceTable(db, name)
|
elif isinstance(data, Iterable):
|
||||||
|
if metadata:
|
||||||
|
raise TypeError(
|
||||||
|
(
|
||||||
|
"Persistent embedding functions not yet "
|
||||||
|
"supported for generator data input"
|
||||||
|
)
|
||||||
|
)
|
||||||
|
|
||||||
|
if metadata:
|
||||||
|
schema = schema.with_metadata(metadata)
|
||||||
|
|
||||||
|
empty = pa.Table.from_pylist([], schema=schema)
|
||||||
|
lance.write_dataset(empty, tbl._dataset_uri, schema=schema, mode=mode)
|
||||||
|
table = LanceTable(db, name)
|
||||||
|
|
||||||
|
if data is not None:
|
||||||
|
table.add(data)
|
||||||
|
|
||||||
|
return table
|
||||||
|
|
||||||
@classmethod
|
@classmethod
|
||||||
def open(cls, db, name):
|
def open(cls, db, name):
|
||||||
tbl = cls(db, name)
|
tbl = cls(db, name)
|
||||||
fs, path = pa.fs.FileSystem.from_uri(tbl._dataset_uri)
|
fs, path = fs_from_uri(tbl._dataset_uri)
|
||||||
file_info = fs.get_file_info(path)
|
file_info = fs.get_file_info(path)
|
||||||
if file_info.type != pa.fs.FileType.Directory:
|
if file_info.type != pa.fs.FileType.Directory:
|
||||||
raise FileNotFoundError(
|
raise FileNotFoundError(
|
||||||
@@ -538,6 +792,56 @@ class LanceTable(Table):
|
|||||||
def delete(self, where: str):
|
def delete(self, where: str):
|
||||||
self._dataset.delete(where)
|
self._dataset.delete(where)
|
||||||
|
|
||||||
|
def update(self, where: str, values: dict):
|
||||||
|
"""
|
||||||
|
EXPERIMENTAL: Update rows in the table (not threadsafe).
|
||||||
|
|
||||||
|
This can be used to update zero to all rows depending on how many
|
||||||
|
rows match the where clause.
|
||||||
|
|
||||||
|
Parameters
|
||||||
|
----------
|
||||||
|
where: str
|
||||||
|
The SQL where clause to use when updating rows. For example, 'x = 2'
|
||||||
|
or 'x IN (1, 2, 3)'. The filter must not be empty, or it will error.
|
||||||
|
values: dict
|
||||||
|
The values to update. The keys are the column names and the values
|
||||||
|
are the values to set.
|
||||||
|
|
||||||
|
Examples
|
||||||
|
--------
|
||||||
|
>>> import lancedb
|
||||||
|
>>> import pandas as pd
|
||||||
|
>>> data = pd.DataFrame({"x": [1, 2, 3], "vector": [[1, 2], [3, 4], [5, 6]]})
|
||||||
|
>>> db = lancedb.connect("./.lancedb")
|
||||||
|
>>> table = db.create_table("my_table", data)
|
||||||
|
>>> table.to_pandas()
|
||||||
|
x vector
|
||||||
|
0 1 [1.0, 2.0]
|
||||||
|
1 2 [3.0, 4.0]
|
||||||
|
2 3 [5.0, 6.0]
|
||||||
|
>>> table.update(where="x = 2", values={"vector": [10, 10]})
|
||||||
|
>>> table.to_pandas()
|
||||||
|
x vector
|
||||||
|
0 1 [1.0, 2.0]
|
||||||
|
1 3 [5.0, 6.0]
|
||||||
|
2 2 [10.0, 10.0]
|
||||||
|
|
||||||
|
"""
|
||||||
|
orig_data = self._dataset.to_table(filter=where).combine_chunks()
|
||||||
|
if len(orig_data) == 0:
|
||||||
|
return
|
||||||
|
for col, val in values.items():
|
||||||
|
i = orig_data.column_names.index(col)
|
||||||
|
if i < 0:
|
||||||
|
raise ValueError(f"Column {col} does not exist")
|
||||||
|
orig_data = orig_data.set_column(
|
||||||
|
i, col, pa.array([val] * len(orig_data), type=orig_data[col].type)
|
||||||
|
)
|
||||||
|
self.delete(where)
|
||||||
|
self.add(orig_data, mode="append")
|
||||||
|
self._reset_dataset()
|
||||||
|
|
||||||
def _execute_query(self, query: Query) -> pa.Table:
|
def _execute_query(self, query: Query) -> pa.Table:
|
||||||
ds = self.to_lance()
|
ds = self.to_lance()
|
||||||
return ds.to_table(
|
return ds.to_table(
|
||||||
@@ -580,22 +884,38 @@ def _sanitize_schema(
|
|||||||
return data
|
return data
|
||||||
# cast the columns to the expected types
|
# cast the columns to the expected types
|
||||||
data = data.combine_chunks()
|
data = data.combine_chunks()
|
||||||
data = _sanitize_vector_column(
|
for field in schema:
|
||||||
|
# TODO: we're making an assumption that fixed size list of 10 or more
|
||||||
|
# is a vector column. This is definitely a bit hacky.
|
||||||
|
likely_vector_col = (
|
||||||
|
pa.types.is_fixed_size_list(field.type)
|
||||||
|
and pa.types.is_float32(field.type.value_type)
|
||||||
|
and field.type.list_size >= 10
|
||||||
|
)
|
||||||
|
is_default_vector_col = field.name == VECTOR_COLUMN_NAME
|
||||||
|
if field.name in data.column_names and (
|
||||||
|
likely_vector_col or is_default_vector_col
|
||||||
|
):
|
||||||
|
data = _sanitize_vector_column(
|
||||||
|
data,
|
||||||
|
vector_column_name=field.name,
|
||||||
|
on_bad_vectors=on_bad_vectors,
|
||||||
|
fill_value=fill_value,
|
||||||
|
)
|
||||||
|
return pa.Table.from_arrays(
|
||||||
|
[data[name] for name in schema.names], schema=schema
|
||||||
|
)
|
||||||
|
|
||||||
|
# just check the vector column
|
||||||
|
if VECTOR_COLUMN_NAME in data.column_names:
|
||||||
|
return _sanitize_vector_column(
|
||||||
data,
|
data,
|
||||||
vector_column_name=VECTOR_COLUMN_NAME,
|
vector_column_name=VECTOR_COLUMN_NAME,
|
||||||
on_bad_vectors=on_bad_vectors,
|
on_bad_vectors=on_bad_vectors,
|
||||||
fill_value=fill_value,
|
fill_value=fill_value,
|
||||||
)
|
)
|
||||||
return pa.Table.from_arrays(
|
|
||||||
[data[name] for name in schema.names], schema=schema
|
return data
|
||||||
)
|
|
||||||
# just check the vector column
|
|
||||||
return _sanitize_vector_column(
|
|
||||||
data,
|
|
||||||
vector_column_name=VECTOR_COLUMN_NAME,
|
|
||||||
on_bad_vectors=on_bad_vectors,
|
|
||||||
fill_value=fill_value,
|
|
||||||
)
|
|
||||||
|
|
||||||
|
|
||||||
def _sanitize_vector_column(
|
def _sanitize_vector_column(
|
||||||
@@ -619,8 +939,6 @@ def _sanitize_vector_column(
|
|||||||
fill_value: float, default 0.0
|
fill_value: float, default 0.0
|
||||||
The value to use when filling vectors. Only used if on_bad_vectors="fill".
|
The value to use when filling vectors. Only used if on_bad_vectors="fill".
|
||||||
"""
|
"""
|
||||||
if vector_column_name not in data.column_names:
|
|
||||||
raise ValueError(f"Missing vector column: {vector_column_name}")
|
|
||||||
# ChunkedArray is annoying to work with, so we combine chunks here
|
# ChunkedArray is annoying to work with, so we combine chunks here
|
||||||
vec_arr = data[vector_column_name].combine_chunks()
|
vec_arr = data[vector_column_name].combine_chunks()
|
||||||
if pa.types.is_list(data[vector_column_name].type):
|
if pa.types.is_list(data[vector_column_name].type):
|
||||||
|
|||||||
@@ -15,7 +15,6 @@ import os
|
|||||||
from typing import Tuple
|
from typing import Tuple
|
||||||
from urllib.parse import urlparse
|
from urllib.parse import urlparse
|
||||||
|
|
||||||
import pyarrow as pa
|
|
||||||
import pyarrow.fs as pa_fs
|
import pyarrow.fs as pa_fs
|
||||||
|
|
||||||
|
|
||||||
@@ -71,7 +70,21 @@ def fs_from_uri(uri: str) -> Tuple[pa_fs.FileSystem, str]:
|
|||||||
Get a PyArrow FileSystem from a URI, handling extra environment variables.
|
Get a PyArrow FileSystem from a URI, handling extra environment variables.
|
||||||
"""
|
"""
|
||||||
if get_uri_scheme(uri) == "s3":
|
if get_uri_scheme(uri) == "s3":
|
||||||
if os.environ["AWS_ENDPOINT"]:
|
fs = pa_fs.S3FileSystem(
|
||||||
uri += "?endpoint_override=" + os.environ["AWS_ENDPOINT"]
|
endpoint_override=os.environ.get("AWS_ENDPOINT"),
|
||||||
|
request_timeout=30,
|
||||||
|
connect_timeout=30,
|
||||||
|
)
|
||||||
|
path = get_uri_location(uri)
|
||||||
|
return fs, path
|
||||||
|
|
||||||
return pa_fs.FileSystem.from_uri(uri)
|
return pa_fs.FileSystem.from_uri(uri)
|
||||||
|
|
||||||
|
|
||||||
|
def safe_import_pandas():
|
||||||
|
try:
|
||||||
|
import pandas as pd
|
||||||
|
|
||||||
|
return pd
|
||||||
|
except ImportError:
|
||||||
|
return None
|
||||||
|
|||||||
@@ -1,11 +1,19 @@
|
|||||||
[project]
|
[project]
|
||||||
name = "lancedb"
|
name = "lancedb"
|
||||||
version = "0.1.12"
|
version = "0.2.5"
|
||||||
dependencies = ["pylance~=0.5.8", "ratelimiter", "retry", "tqdm", "aiohttp", "pydantic>=2", "attr"]
|
dependencies = [
|
||||||
description = "lancedb"
|
"pylance==0.7.4",
|
||||||
authors = [
|
"ratelimiter",
|
||||||
{ name = "LanceDB Devs", email = "dev@lancedb.com" },
|
"retry",
|
||||||
|
"tqdm",
|
||||||
|
"aiohttp",
|
||||||
|
"pydantic",
|
||||||
|
"attr",
|
||||||
|
"semver>=3.0",
|
||||||
|
"cachetools"
|
||||||
]
|
]
|
||||||
|
description = "lancedb"
|
||||||
|
authors = [{ name = "LanceDB Devs", email = "dev@lancedb.com" }]
|
||||||
license = { file = "LICENSE" }
|
license = { file = "LICENSE" }
|
||||||
readme = "README.md"
|
readme = "README.md"
|
||||||
requires-python = ">=3.8"
|
requires-python = ">=3.8"
|
||||||
@@ -36,19 +44,22 @@ classifiers = [
|
|||||||
repository = "https://github.com/lancedb/lancedb"
|
repository = "https://github.com/lancedb/lancedb"
|
||||||
|
|
||||||
[project.optional-dependencies]
|
[project.optional-dependencies]
|
||||||
tests = [
|
tests = ["pandas>=1.4", "pytest", "pytest-mock", "pytest-asyncio", "requests"]
|
||||||
"pytest", "pytest-mock", "pytest-asyncio"
|
dev = ["ruff", "pre-commit", "black"]
|
||||||
]
|
docs = ["mkdocs", "mkdocs-jupyter", "mkdocs-material", "mkdocstrings[python]"]
|
||||||
dev = [
|
clip = ["torch", "pillow", "open-clip"]
|
||||||
"ruff", "pre-commit", "black"
|
embeddings = ["openai", "sentence-transformers", "torch", "pillow", "open-clip"]
|
||||||
]
|
|
||||||
docs = [
|
|
||||||
"mkdocs", "mkdocs-jupyter", "mkdocs-material", "mkdocstrings[python]"
|
|
||||||
]
|
|
||||||
|
|
||||||
[build-system]
|
[build-system]
|
||||||
requires = [
|
requires = ["setuptools", "wheel"]
|
||||||
"setuptools",
|
|
||||||
"wheel",
|
|
||||||
]
|
|
||||||
build-backend = "setuptools.build_meta"
|
build-backend = "setuptools.build_meta"
|
||||||
|
|
||||||
|
[tool.isort]
|
||||||
|
profile = "black"
|
||||||
|
|
||||||
|
[tool.pytest.ini_options]
|
||||||
|
addopts = "--strict-markers"
|
||||||
|
markers = [
|
||||||
|
"slow: marks tests as slow (deselect with '-m \"not slow\"')",
|
||||||
|
"asyncio"
|
||||||
|
]
|
||||||
@@ -17,6 +17,7 @@ import pyarrow as pa
|
|||||||
import pytest
|
import pytest
|
||||||
|
|
||||||
import lancedb
|
import lancedb
|
||||||
|
from lancedb.pydantic import LanceModel, Vector
|
||||||
|
|
||||||
|
|
||||||
def test_basic(tmp_path):
|
def test_basic(tmp_path):
|
||||||
@@ -76,31 +77,78 @@ def test_ingest_pd(tmp_path):
|
|||||||
assert db.open_table("test").name == db["test"].name
|
assert db.open_table("test").name == db["test"].name
|
||||||
|
|
||||||
|
|
||||||
def test_ingest_record_batch_iterator(tmp_path):
|
def test_ingest_iterator(tmp_path):
|
||||||
def batch_reader():
|
class PydanticSchema(LanceModel):
|
||||||
for i in range(5):
|
vector: Vector(2)
|
||||||
yield pa.RecordBatch.from_arrays(
|
item: str
|
||||||
[
|
price: float
|
||||||
pa.array([[3.1, 4.1], [5.9, 26.5]]),
|
|
||||||
pa.array(["foo", "bar"]),
|
|
||||||
pa.array([10.0, 20.0]),
|
|
||||||
],
|
|
||||||
["vector", "item", "price"],
|
|
||||||
)
|
|
||||||
|
|
||||||
db = lancedb.connect(tmp_path)
|
arrow_schema = pa.schema(
|
||||||
tbl = db.create_table(
|
[
|
||||||
"test",
|
pa.field("vector", pa.list_(pa.float32(), 2)),
|
||||||
batch_reader(),
|
pa.field("item", pa.utf8()),
|
||||||
schema=pa.schema(
|
pa.field("price", pa.float32()),
|
||||||
[
|
]
|
||||||
pa.field("vector", pa.list_(pa.float32())),
|
|
||||||
pa.field("item", pa.utf8()),
|
|
||||||
pa.field("price", pa.float32()),
|
|
||||||
]
|
|
||||||
),
|
|
||||||
)
|
)
|
||||||
|
|
||||||
|
def make_batches():
|
||||||
|
for _ in range(5):
|
||||||
|
yield from [
|
||||||
|
# pandas
|
||||||
|
pd.DataFrame(
|
||||||
|
{
|
||||||
|
"vector": [[3.1, 4.1], [1, 1]],
|
||||||
|
"item": ["foo", "bar"],
|
||||||
|
"price": [10.0, 20.0],
|
||||||
|
}
|
||||||
|
),
|
||||||
|
# pylist
|
||||||
|
[
|
||||||
|
{"vector": [3.1, 4.1], "item": "foo", "price": 10.0},
|
||||||
|
{"vector": [5.9, 26.5], "item": "bar", "price": 20.0},
|
||||||
|
],
|
||||||
|
# recordbatch
|
||||||
|
pa.RecordBatch.from_arrays(
|
||||||
|
[
|
||||||
|
pa.array([[3.1, 4.1], [5.9, 26.5]], pa.list_(pa.float32(), 2)),
|
||||||
|
pa.array(["foo", "bar"]),
|
||||||
|
pa.array([10.0, 20.0]),
|
||||||
|
],
|
||||||
|
["vector", "item", "price"],
|
||||||
|
),
|
||||||
|
# pa Table
|
||||||
|
pa.Table.from_arrays(
|
||||||
|
[
|
||||||
|
pa.array([[3.1, 4.1], [5.9, 26.5]], pa.list_(pa.float32(), 2)),
|
||||||
|
pa.array(["foo", "bar"]),
|
||||||
|
pa.array([10.0, 20.0]),
|
||||||
|
],
|
||||||
|
["vector", "item", "price"],
|
||||||
|
),
|
||||||
|
# pydantic list
|
||||||
|
[
|
||||||
|
PydanticSchema(vector=[3.1, 4.1], item="foo", price=10.0),
|
||||||
|
PydanticSchema(vector=[5.9, 26.5], item="bar", price=20.0),
|
||||||
|
]
|
||||||
|
# TODO: test pydict separately. it is unique column number and names contraint
|
||||||
|
]
|
||||||
|
|
||||||
|
def run_tests(schema):
|
||||||
|
db = lancedb.connect(tmp_path)
|
||||||
|
tbl = db.create_table("table2", make_batches(), schema=schema, mode="overwrite")
|
||||||
|
tbl.to_pandas()
|
||||||
|
assert tbl.search([3.1, 4.1]).limit(1).to_df()["_distance"][0] == 0.0
|
||||||
|
assert tbl.search([5.9, 26.5]).limit(1).to_df()["_distance"][0] == 0.0
|
||||||
|
tbl_len = len(tbl)
|
||||||
|
tbl.add(make_batches())
|
||||||
|
assert tbl_len == 50
|
||||||
|
assert len(tbl) == tbl_len * 2
|
||||||
|
assert len(tbl.list_versions()) == 3
|
||||||
|
db.drop_database()
|
||||||
|
|
||||||
|
run_tests(arrow_schema)
|
||||||
|
run_tests(PydanticSchema)
|
||||||
|
|
||||||
|
|
||||||
def test_create_mode(tmp_path):
|
def test_create_mode(tmp_path):
|
||||||
db = lancedb.connect(tmp_path)
|
db = lancedb.connect(tmp_path)
|
||||||
@@ -149,6 +197,51 @@ def test_delete_table(tmp_path):
|
|||||||
db.create_table("test", data=data)
|
db.create_table("test", data=data)
|
||||||
assert db.table_names() == ["test"]
|
assert db.table_names() == ["test"]
|
||||||
|
|
||||||
|
# dropping a table that does not exist should pass
|
||||||
|
# if ignore_missing=True
|
||||||
|
db.drop_table("does_not_exist", ignore_missing=True)
|
||||||
|
|
||||||
|
|
||||||
|
def test_drop_database(tmp_path):
|
||||||
|
db = lancedb.connect(tmp_path)
|
||||||
|
data = pd.DataFrame(
|
||||||
|
{
|
||||||
|
"vector": [[3.1, 4.1], [5.9, 26.5]],
|
||||||
|
"item": ["foo", "bar"],
|
||||||
|
"price": [10.0, 20.0],
|
||||||
|
}
|
||||||
|
)
|
||||||
|
new_data = pd.DataFrame(
|
||||||
|
{
|
||||||
|
"vector": [[5.1, 4.1], [5.9, 10.5]],
|
||||||
|
"item": ["kiwi", "avocado"],
|
||||||
|
"price": [12.0, 17.0],
|
||||||
|
}
|
||||||
|
)
|
||||||
|
db.create_table("test", data=data)
|
||||||
|
with pytest.raises(Exception):
|
||||||
|
db.create_table("test", data=data)
|
||||||
|
|
||||||
|
assert db.table_names() == ["test"]
|
||||||
|
|
||||||
|
db.create_table("new_test", data=new_data)
|
||||||
|
db.drop_database()
|
||||||
|
assert db.table_names() == []
|
||||||
|
|
||||||
|
# it should pass when no tables are present
|
||||||
|
db.create_table("test", data=new_data)
|
||||||
|
db.drop_table("test")
|
||||||
|
assert db.table_names() == []
|
||||||
|
db.drop_database()
|
||||||
|
assert db.table_names() == []
|
||||||
|
|
||||||
|
# creating an empty database with schema
|
||||||
|
schema = pa.schema([pa.field("vector", pa.list_(pa.float32(), list_size=2))])
|
||||||
|
db.create_table("empty_table", schema=schema)
|
||||||
|
# dropping a empty database should pass
|
||||||
|
db.drop_database()
|
||||||
|
assert db.table_names() == []
|
||||||
|
|
||||||
|
|
||||||
def test_empty_or_nonexistent_table(tmp_path):
|
def test_empty_or_nonexistent_table(tmp_path):
|
||||||
db = lancedb.connect(tmp_path)
|
db = lancedb.connect(tmp_path)
|
||||||
@@ -158,8 +251,14 @@ def test_empty_or_nonexistent_table(tmp_path):
|
|||||||
with pytest.raises(Exception):
|
with pytest.raises(Exception):
|
||||||
db.open_table("does_not_exist")
|
db.open_table("does_not_exist")
|
||||||
|
|
||||||
schema = pa.schema([pa.field("a", pa.int32())])
|
schema = pa.schema([pa.field("a", pa.int64(), nullable=False)])
|
||||||
db.create_table("test", schema=schema)
|
test = db.create_table("test", schema=schema)
|
||||||
|
|
||||||
|
class TestModel(LanceModel):
|
||||||
|
a: int
|
||||||
|
|
||||||
|
test2 = db.create_table("test2", schema=TestModel)
|
||||||
|
assert test.schema == test2.schema
|
||||||
|
|
||||||
|
|
||||||
def test_replace_index(tmp_path):
|
def test_replace_index(tmp_path):
|
||||||
|
|||||||
@@ -12,10 +12,16 @@
|
|||||||
# limitations under the License.
|
# limitations under the License.
|
||||||
import sys
|
import sys
|
||||||
|
|
||||||
|
import lance
|
||||||
import numpy as np
|
import numpy as np
|
||||||
import pyarrow as pa
|
import pyarrow as pa
|
||||||
|
|
||||||
from lancedb.embeddings import with_embeddings
|
from lancedb.conftest import MockTextEmbeddingFunction
|
||||||
|
from lancedb.embeddings import (
|
||||||
|
EmbeddingFunctionConfig,
|
||||||
|
EmbeddingFunctionRegistry,
|
||||||
|
with_embeddings,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
def mock_embed_func(input_data):
|
def mock_embed_func(input_data):
|
||||||
@@ -40,3 +46,40 @@ def test_with_embeddings():
|
|||||||
assert data.column_names == ["text", "price", "vector"]
|
assert data.column_names == ["text", "price", "vector"]
|
||||||
assert data.column("text").to_pylist() == ["foo", "bar"]
|
assert data.column("text").to_pylist() == ["foo", "bar"]
|
||||||
assert data.column("price").to_pylist() == [10.0, 20.0]
|
assert data.column("price").to_pylist() == [10.0, 20.0]
|
||||||
|
|
||||||
|
|
||||||
|
def test_embedding_function(tmp_path):
|
||||||
|
registry = EmbeddingFunctionRegistry.get_instance()
|
||||||
|
|
||||||
|
# let's create a table
|
||||||
|
table = pa.table(
|
||||||
|
{
|
||||||
|
"text": pa.array(["hello world", "goodbye world"]),
|
||||||
|
"vector": [np.random.randn(10), np.random.randn(10)],
|
||||||
|
}
|
||||||
|
)
|
||||||
|
conf = EmbeddingFunctionConfig(
|
||||||
|
source_column="text",
|
||||||
|
vector_column="vector",
|
||||||
|
function=MockTextEmbeddingFunction(),
|
||||||
|
)
|
||||||
|
metadata = registry.get_table_metadata([conf])
|
||||||
|
table = table.replace_schema_metadata(metadata)
|
||||||
|
|
||||||
|
# Write it to disk
|
||||||
|
lance.write_dataset(table, tmp_path / "test.lance")
|
||||||
|
|
||||||
|
# Load this back
|
||||||
|
ds = lance.dataset(tmp_path / "test.lance")
|
||||||
|
|
||||||
|
# can we get the serialized version back out?
|
||||||
|
configs = registry.parse_functions(ds.schema.metadata)
|
||||||
|
|
||||||
|
conf = configs["vector"]
|
||||||
|
func = conf.function
|
||||||
|
actual = func.compute_query_embeddings("hello world")
|
||||||
|
|
||||||
|
# And we make sure we can call it
|
||||||
|
expected = func.compute_query_embeddings("hello world")
|
||||||
|
|
||||||
|
assert np.allclose(actual, expected)
|
||||||
|
|||||||
125
python/tests/test_embeddings_slow.py
Normal file
125
python/tests/test_embeddings_slow.py
Normal file
@@ -0,0 +1,125 @@
|
|||||||
|
# Copyright (c) 2023. LanceDB Developers
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
import io
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
|
import pandas as pd
|
||||||
|
import pytest
|
||||||
|
import requests
|
||||||
|
|
||||||
|
import lancedb
|
||||||
|
from lancedb.embeddings import EmbeddingFunctionRegistry
|
||||||
|
from lancedb.pydantic import LanceModel, Vector
|
||||||
|
|
||||||
|
# These are integration tests for embedding functions.
|
||||||
|
# They are slow because they require downloading models
|
||||||
|
# or connection to external api
|
||||||
|
|
||||||
|
|
||||||
|
@pytest.mark.slow
|
||||||
|
@pytest.mark.parametrize("alias", ["sentence-transformers", "openai"])
|
||||||
|
def test_sentence_transformer(alias, tmp_path):
|
||||||
|
db = lancedb.connect(tmp_path)
|
||||||
|
registry = EmbeddingFunctionRegistry.get_instance()
|
||||||
|
func = registry.get(alias).create()
|
||||||
|
|
||||||
|
class Words(LanceModel):
|
||||||
|
text: str = func.SourceField()
|
||||||
|
vector: Vector(func.ndims()) = func.VectorField()
|
||||||
|
|
||||||
|
table = db.create_table("words", schema=Words)
|
||||||
|
table.add(
|
||||||
|
pd.DataFrame(
|
||||||
|
{
|
||||||
|
"text": [
|
||||||
|
"hello world",
|
||||||
|
"goodbye world",
|
||||||
|
"fizz",
|
||||||
|
"buzz",
|
||||||
|
"foo",
|
||||||
|
"bar",
|
||||||
|
"baz",
|
||||||
|
]
|
||||||
|
}
|
||||||
|
)
|
||||||
|
)
|
||||||
|
|
||||||
|
query = "greetings"
|
||||||
|
actual = table.search(query).limit(1).to_pydantic(Words)[0]
|
||||||
|
|
||||||
|
vec = func.compute_query_embeddings(query)[0]
|
||||||
|
expected = table.search(vec).limit(1).to_pydantic(Words)[0]
|
||||||
|
assert actual.text == expected.text
|
||||||
|
assert actual.text == "hello world"
|
||||||
|
|
||||||
|
|
||||||
|
@pytest.mark.slow
|
||||||
|
def test_openclip(tmp_path):
|
||||||
|
from PIL import Image
|
||||||
|
|
||||||
|
db = lancedb.connect(tmp_path)
|
||||||
|
registry = EmbeddingFunctionRegistry.get_instance()
|
||||||
|
func = registry.get("open-clip").create()
|
||||||
|
|
||||||
|
class Images(LanceModel):
|
||||||
|
label: str
|
||||||
|
image_uri: str = func.SourceField()
|
||||||
|
image_bytes: bytes = func.SourceField()
|
||||||
|
vector: Vector(func.ndims()) = func.VectorField()
|
||||||
|
vec_from_bytes: Vector(func.ndims()) = func.VectorField()
|
||||||
|
|
||||||
|
table = db.create_table("images", schema=Images)
|
||||||
|
labels = ["cat", "cat", "dog", "dog", "horse", "horse"]
|
||||||
|
uris = [
|
||||||
|
"http://farm1.staticflickr.com/53/167798175_7c7845bbbd_z.jpg",
|
||||||
|
"http://farm1.staticflickr.com/134/332220238_da527d8140_z.jpg",
|
||||||
|
"http://farm9.staticflickr.com/8387/8602747737_2e5c2a45d4_z.jpg",
|
||||||
|
"http://farm5.staticflickr.com/4092/5017326486_1f46057f5f_z.jpg",
|
||||||
|
"http://farm9.staticflickr.com/8216/8434969557_d37882c42d_z.jpg",
|
||||||
|
"http://farm6.staticflickr.com/5142/5835678453_4f3a4edb45_z.jpg",
|
||||||
|
]
|
||||||
|
# get each uri as bytes
|
||||||
|
image_bytes = [requests.get(uri).content for uri in uris]
|
||||||
|
table.add(
|
||||||
|
pd.DataFrame({"label": labels, "image_uri": uris, "image_bytes": image_bytes})
|
||||||
|
)
|
||||||
|
|
||||||
|
# text search
|
||||||
|
actual = table.search("man's best friend").limit(1).to_pydantic(Images)[0]
|
||||||
|
assert actual.label == "dog"
|
||||||
|
frombytes = (
|
||||||
|
table.search("man's best friend", vector_column_name="vec_from_bytes")
|
||||||
|
.limit(1)
|
||||||
|
.to_pydantic(Images)[0]
|
||||||
|
)
|
||||||
|
assert actual.label == frombytes.label
|
||||||
|
assert np.allclose(actual.vector, frombytes.vector)
|
||||||
|
|
||||||
|
# image search
|
||||||
|
query_image_uri = "http://farm1.staticflickr.com/200/467715466_ed4a31801f_z.jpg"
|
||||||
|
image_bytes = requests.get(query_image_uri).content
|
||||||
|
query_image = Image.open(io.BytesIO(image_bytes))
|
||||||
|
actual = table.search(query_image).limit(1).to_pydantic(Images)[0]
|
||||||
|
assert actual.label == "dog"
|
||||||
|
other = (
|
||||||
|
table.search(query_image, vector_column_name="vec_from_bytes")
|
||||||
|
.limit(1)
|
||||||
|
.to_pydantic(Images)[0]
|
||||||
|
)
|
||||||
|
assert actual.label == other.label
|
||||||
|
|
||||||
|
arrow_table = table.search().select(["vector", "vec_from_bytes"]).to_arrow()
|
||||||
|
assert np.allclose(
|
||||||
|
arrow_table["vector"].combine_chunks().values.to_numpy(),
|
||||||
|
arrow_table["vec_from_bytes"].combine_chunks().values.to_numpy(),
|
||||||
|
)
|
||||||
@@ -66,7 +66,7 @@ def test_search_index(tmp_path, table):
|
|||||||
results = ldb.fts.search_index(index, query="puppy", limit=10)
|
results = ldb.fts.search_index(index, query="puppy", limit=10)
|
||||||
assert len(results) == 2
|
assert len(results) == 2
|
||||||
assert len(results[0]) == 10 # row_ids
|
assert len(results[0]) == 10 # row_ids
|
||||||
assert len(results[1]) == 10 # scores
|
assert len(results[1]) == 10 # _distance
|
||||||
|
|
||||||
|
|
||||||
def test_create_index_from_table(tmp_path, table):
|
def test_create_index_from_table(tmp_path, table):
|
||||||
|
|||||||
@@ -19,8 +19,9 @@ from typing import List, Optional
|
|||||||
import pyarrow as pa
|
import pyarrow as pa
|
||||||
import pydantic
|
import pydantic
|
||||||
import pytest
|
import pytest
|
||||||
|
from pydantic import Field
|
||||||
|
|
||||||
from lancedb.pydantic import pydantic_to_schema, vector
|
from lancedb.pydantic import PYDANTIC_VERSION, LanceModel, Vector, pydantic_to_schema
|
||||||
|
|
||||||
|
|
||||||
@pytest.mark.skipif(
|
@pytest.mark.skipif(
|
||||||
@@ -107,14 +108,20 @@ def test_pydantic_to_arrow_py38():
|
|||||||
|
|
||||||
def test_fixed_size_list_field():
|
def test_fixed_size_list_field():
|
||||||
class TestModel(pydantic.BaseModel):
|
class TestModel(pydantic.BaseModel):
|
||||||
vec: vector(16)
|
vec: Vector(16)
|
||||||
li: List[int]
|
li: List[int]
|
||||||
|
|
||||||
data = TestModel(vec=list(range(16)), li=[1, 2, 3])
|
data = TestModel(vec=list(range(16)), li=[1, 2, 3])
|
||||||
assert json.loads(data.model_dump_json()) == {
|
if PYDANTIC_VERSION >= (2,):
|
||||||
"vec": list(range(16)),
|
assert json.loads(data.model_dump_json()) == {
|
||||||
"li": [1, 2, 3],
|
"vec": list(range(16)),
|
||||||
}
|
"li": [1, 2, 3],
|
||||||
|
}
|
||||||
|
else:
|
||||||
|
assert data.dict() == {
|
||||||
|
"vec": list(range(16)),
|
||||||
|
"li": [1, 2, 3],
|
||||||
|
}
|
||||||
|
|
||||||
schema = pydantic_to_schema(TestModel)
|
schema = pydantic_to_schema(TestModel)
|
||||||
assert schema == pa.schema(
|
assert schema == pa.schema(
|
||||||
@@ -124,7 +131,11 @@ def test_fixed_size_list_field():
|
|||||||
]
|
]
|
||||||
)
|
)
|
||||||
|
|
||||||
json_schema = TestModel.model_json_schema()
|
if PYDANTIC_VERSION >= (2,):
|
||||||
|
json_schema = TestModel.model_json_schema()
|
||||||
|
else:
|
||||||
|
json_schema = TestModel.schema()
|
||||||
|
|
||||||
assert json_schema == {
|
assert json_schema == {
|
||||||
"properties": {
|
"properties": {
|
||||||
"vec": {
|
"vec": {
|
||||||
@@ -144,7 +155,7 @@ def test_fixed_size_list_field():
|
|||||||
|
|
||||||
def test_fixed_size_list_validation():
|
def test_fixed_size_list_validation():
|
||||||
class TestModel(pydantic.BaseModel):
|
class TestModel(pydantic.BaseModel):
|
||||||
vec: vector(8)
|
vec: Vector(8)
|
||||||
|
|
||||||
with pytest.raises(pydantic.ValidationError):
|
with pytest.raises(pydantic.ValidationError):
|
||||||
TestModel(vec=range(9))
|
TestModel(vec=range(9))
|
||||||
@@ -153,3 +164,16 @@ def test_fixed_size_list_validation():
|
|||||||
TestModel(vec=range(7))
|
TestModel(vec=range(7))
|
||||||
|
|
||||||
TestModel(vec=range(8))
|
TestModel(vec=range(8))
|
||||||
|
|
||||||
|
|
||||||
|
def test_lance_model():
|
||||||
|
class TestModel(LanceModel):
|
||||||
|
vector: Vector(16) = Field(default=[0.0] * 16)
|
||||||
|
li: List[int] = Field(default=[1, 2, 3])
|
||||||
|
|
||||||
|
schema = pydantic_to_schema(TestModel)
|
||||||
|
assert schema == TestModel.to_arrow_schema()
|
||||||
|
assert TestModel.field_names() == ["vector", "li"]
|
||||||
|
|
||||||
|
t = TestModel()
|
||||||
|
assert t == TestModel(vec=[0.0] * 16, li=[1, 2, 3])
|
||||||
|
|||||||
@@ -20,7 +20,8 @@ import pyarrow as pa
|
|||||||
import pytest
|
import pytest
|
||||||
|
|
||||||
from lancedb.db import LanceDBConnection
|
from lancedb.db import LanceDBConnection
|
||||||
from lancedb.query import LanceQueryBuilder, Query
|
from lancedb.pydantic import LanceModel, Vector
|
||||||
|
from lancedb.query import LanceVectorQueryBuilder, Query
|
||||||
from lancedb.table import LanceTable
|
from lancedb.table import LanceTable
|
||||||
|
|
||||||
|
|
||||||
@@ -64,14 +65,34 @@ def table(tmp_path) -> MockTable:
|
|||||||
return MockTable(tmp_path)
|
return MockTable(tmp_path)
|
||||||
|
|
||||||
|
|
||||||
|
def test_cast(table):
|
||||||
|
class TestModel(LanceModel):
|
||||||
|
vector: Vector(2)
|
||||||
|
id: int
|
||||||
|
str_field: str
|
||||||
|
float_field: float
|
||||||
|
|
||||||
|
q = LanceVectorQueryBuilder(table, [0, 0], "vector").limit(1)
|
||||||
|
results = q.to_pydantic(TestModel)
|
||||||
|
assert len(results) == 1
|
||||||
|
r0 = results[0]
|
||||||
|
assert isinstance(r0, TestModel)
|
||||||
|
assert r0.id == 1
|
||||||
|
assert r0.vector == [1, 2]
|
||||||
|
assert r0.str_field == "a"
|
||||||
|
assert r0.float_field == 1.0
|
||||||
|
|
||||||
|
|
||||||
def test_query_builder(table):
|
def test_query_builder(table):
|
||||||
df = LanceQueryBuilder(table, [0, 0], "vector").limit(1).select(["id"]).to_df()
|
df = (
|
||||||
|
LanceVectorQueryBuilder(table, [0, 0], "vector").limit(1).select(["id"]).to_df()
|
||||||
|
)
|
||||||
assert df["id"].values[0] == 1
|
assert df["id"].values[0] == 1
|
||||||
assert all(df["vector"].values[0] == [1, 2])
|
assert all(df["vector"].values[0] == [1, 2])
|
||||||
|
|
||||||
|
|
||||||
def test_query_builder_with_filter(table):
|
def test_query_builder_with_filter(table):
|
||||||
df = LanceQueryBuilder(table, [0, 0], "vector").where("id = 2").to_df()
|
df = LanceVectorQueryBuilder(table, [0, 0], "vector").where("id = 2").to_df()
|
||||||
assert df["id"].values[0] == 2
|
assert df["id"].values[0] == 2
|
||||||
assert all(df["vector"].values[0] == [3, 4])
|
assert all(df["vector"].values[0] == [3, 4])
|
||||||
|
|
||||||
@@ -79,21 +100,23 @@ def test_query_builder_with_filter(table):
|
|||||||
def test_query_builder_with_metric(table):
|
def test_query_builder_with_metric(table):
|
||||||
query = [4, 8]
|
query = [4, 8]
|
||||||
vector_column_name = "vector"
|
vector_column_name = "vector"
|
||||||
df_default = LanceQueryBuilder(table, query, vector_column_name).to_df()
|
df_default = LanceVectorQueryBuilder(table, query, vector_column_name).to_df()
|
||||||
df_l2 = LanceQueryBuilder(table, query, vector_column_name).metric("L2").to_df()
|
df_l2 = (
|
||||||
|
LanceVectorQueryBuilder(table, query, vector_column_name).metric("L2").to_df()
|
||||||
|
)
|
||||||
tm.assert_frame_equal(df_default, df_l2)
|
tm.assert_frame_equal(df_default, df_l2)
|
||||||
|
|
||||||
df_cosine = (
|
df_cosine = (
|
||||||
LanceQueryBuilder(table, query, vector_column_name)
|
LanceVectorQueryBuilder(table, query, vector_column_name)
|
||||||
.metric("cosine")
|
.metric("cosine")
|
||||||
.limit(1)
|
.limit(1)
|
||||||
.to_df()
|
.to_df()
|
||||||
)
|
)
|
||||||
assert df_cosine.score[0] == pytest.approx(
|
assert df_cosine._distance[0] == pytest.approx(
|
||||||
cosine_distance(query, df_cosine.vector[0]),
|
cosine_distance(query, df_cosine.vector[0]),
|
||||||
abs=1e-6,
|
abs=1e-6,
|
||||||
)
|
)
|
||||||
assert 0 <= df_cosine.score[0] <= 1
|
assert 0 <= df_cosine._distance[0] <= 1
|
||||||
|
|
||||||
|
|
||||||
def test_query_builder_with_different_vector_column():
|
def test_query_builder_with_different_vector_column():
|
||||||
@@ -101,7 +124,7 @@ def test_query_builder_with_different_vector_column():
|
|||||||
query = [4, 8]
|
query = [4, 8]
|
||||||
vector_column_name = "foo_vector"
|
vector_column_name = "foo_vector"
|
||||||
builder = (
|
builder = (
|
||||||
LanceQueryBuilder(table, query, vector_column_name)
|
LanceVectorQueryBuilder(table, query, vector_column_name)
|
||||||
.metric("cosine")
|
.metric("cosine")
|
||||||
.where("b < 10")
|
.where("b < 10")
|
||||||
.select(["b"])
|
.select(["b"])
|
||||||
|
|||||||
@@ -13,15 +13,19 @@
|
|||||||
|
|
||||||
import functools
|
import functools
|
||||||
from pathlib import Path
|
from pathlib import Path
|
||||||
|
from typing import List
|
||||||
from unittest.mock import PropertyMock, patch
|
from unittest.mock import PropertyMock, patch
|
||||||
|
|
||||||
|
import lance
|
||||||
import numpy as np
|
import numpy as np
|
||||||
import pandas as pd
|
import pandas as pd
|
||||||
import pyarrow as pa
|
import pyarrow as pa
|
||||||
import pytest
|
import pytest
|
||||||
from lance.vector import vec_to_table
|
|
||||||
|
|
||||||
|
from lancedb.conftest import MockTextEmbeddingFunction
|
||||||
from lancedb.db import LanceDBConnection
|
from lancedb.db import LanceDBConnection
|
||||||
|
from lancedb.embeddings import EmbeddingFunctionConfig, EmbeddingFunctionRegistry
|
||||||
|
from lancedb.pydantic import LanceModel, Vector
|
||||||
from lancedb.table import LanceTable
|
from lancedb.table import LanceTable
|
||||||
|
|
||||||
|
|
||||||
@@ -135,6 +139,17 @@ def test_add(db):
|
|||||||
_add(table, schema)
|
_add(table, schema)
|
||||||
|
|
||||||
|
|
||||||
|
def test_add_pydantic_model(db):
|
||||||
|
class TestModel(LanceModel):
|
||||||
|
vector: Vector(16)
|
||||||
|
li: List[int]
|
||||||
|
|
||||||
|
data = TestModel(vector=list(range(16)), li=[1, 2, 3])
|
||||||
|
table = LanceTable.create(db, "test", data=[data])
|
||||||
|
assert len(table) == 1
|
||||||
|
assert table.schema == TestModel.to_arrow_schema()
|
||||||
|
|
||||||
|
|
||||||
def _add(table, schema):
|
def _add(table, schema):
|
||||||
# table = LanceTable(db, "test")
|
# table = LanceTable(db, "test")
|
||||||
assert len(table) == 2
|
assert len(table) == 2
|
||||||
@@ -165,16 +180,16 @@ def test_versioning(db):
|
|||||||
],
|
],
|
||||||
)
|
)
|
||||||
|
|
||||||
assert len(table.list_versions()) == 1
|
|
||||||
assert table.version == 1
|
|
||||||
|
|
||||||
table.add([{"vector": [6.3, 100.5], "item": "new", "price": 30.0}])
|
|
||||||
assert len(table.list_versions()) == 2
|
assert len(table.list_versions()) == 2
|
||||||
assert table.version == 2
|
assert table.version == 2
|
||||||
|
|
||||||
|
table.add([{"vector": [6.3, 100.5], "item": "new", "price": 30.0}])
|
||||||
|
assert len(table.list_versions()) == 3
|
||||||
|
assert table.version == 3
|
||||||
assert len(table) == 3
|
assert len(table) == 3
|
||||||
|
|
||||||
table.checkout(1)
|
table.checkout(2)
|
||||||
assert table.version == 1
|
assert table.version == 2
|
||||||
assert len(table) == 2
|
assert len(table) == 2
|
||||||
|
|
||||||
|
|
||||||
@@ -256,3 +271,173 @@ def test_add_with_nans(db):
|
|||||||
arrow_tbl = table.to_lance().to_table(filter="item == 'bar'")
|
arrow_tbl = table.to_lance().to_table(filter="item == 'bar'")
|
||||||
v = arrow_tbl["vector"].to_pylist()[0]
|
v = arrow_tbl["vector"].to_pylist()[0]
|
||||||
assert np.allclose(v, np.array([0.0, 0.0]))
|
assert np.allclose(v, np.array([0.0, 0.0]))
|
||||||
|
|
||||||
|
|
||||||
|
def test_restore(db):
|
||||||
|
table = LanceTable.create(
|
||||||
|
db,
|
||||||
|
"my_table",
|
||||||
|
data=[{"vector": [1.1, 0.9], "type": "vector"}],
|
||||||
|
)
|
||||||
|
table.add([{"vector": [0.5, 0.2], "type": "vector"}])
|
||||||
|
table.restore(2)
|
||||||
|
assert len(table.list_versions()) == 4
|
||||||
|
assert len(table) == 1
|
||||||
|
|
||||||
|
expected = table.to_arrow()
|
||||||
|
table.checkout(2)
|
||||||
|
table.restore()
|
||||||
|
assert len(table.list_versions()) == 5
|
||||||
|
assert table.to_arrow() == expected
|
||||||
|
|
||||||
|
table.restore(5) # latest version should be no-op
|
||||||
|
assert len(table.list_versions()) == 5
|
||||||
|
|
||||||
|
with pytest.raises(ValueError):
|
||||||
|
table.restore(6)
|
||||||
|
|
||||||
|
with pytest.raises(ValueError):
|
||||||
|
table.restore(0)
|
||||||
|
|
||||||
|
|
||||||
|
def test_merge(db, tmp_path):
|
||||||
|
table = LanceTable.create(
|
||||||
|
db,
|
||||||
|
"my_table",
|
||||||
|
data=[{"vector": [1.1, 0.9], "id": 0}, {"vector": [1.2, 1.9], "id": 1}],
|
||||||
|
)
|
||||||
|
other_table = pa.table({"document": ["foo", "bar"], "id": [0, 1]})
|
||||||
|
table.merge(other_table, left_on="id")
|
||||||
|
assert len(table.list_versions()) == 3
|
||||||
|
expected = pa.table(
|
||||||
|
{"vector": [[1.1, 0.9], [1.2, 1.9]], "id": [0, 1], "document": ["foo", "bar"]},
|
||||||
|
schema=table.schema,
|
||||||
|
)
|
||||||
|
assert table.to_arrow() == expected
|
||||||
|
|
||||||
|
other_dataset = lance.write_dataset(other_table, tmp_path / "other_table.lance")
|
||||||
|
table.restore(1)
|
||||||
|
table.merge(other_dataset, left_on="id")
|
||||||
|
|
||||||
|
|
||||||
|
def test_delete(db):
|
||||||
|
table = LanceTable.create(
|
||||||
|
db,
|
||||||
|
"my_table",
|
||||||
|
data=[{"vector": [1.1, 0.9], "id": 0}, {"vector": [1.2, 1.9], "id": 1}],
|
||||||
|
)
|
||||||
|
assert len(table) == 2
|
||||||
|
assert len(table.list_versions()) == 2
|
||||||
|
table.delete("id=0")
|
||||||
|
assert len(table.list_versions()) == 3
|
||||||
|
assert table.version == 3
|
||||||
|
assert len(table) == 1
|
||||||
|
assert table.to_pandas()["id"].tolist() == [1]
|
||||||
|
|
||||||
|
|
||||||
|
def test_update(db):
|
||||||
|
table = LanceTable.create(
|
||||||
|
db,
|
||||||
|
"my_table",
|
||||||
|
data=[{"vector": [1.1, 0.9], "id": 0}, {"vector": [1.2, 1.9], "id": 1}],
|
||||||
|
)
|
||||||
|
assert len(table) == 2
|
||||||
|
assert len(table.list_versions()) == 2
|
||||||
|
table.update(where="id=0", values={"vector": [1.1, 1.1]})
|
||||||
|
assert len(table.list_versions()) == 4
|
||||||
|
assert table.version == 4
|
||||||
|
assert len(table) == 2
|
||||||
|
v = table.to_arrow()["vector"].combine_chunks()
|
||||||
|
v = v.values.to_numpy().reshape(2, 2)
|
||||||
|
assert np.allclose(v, np.array([[1.2, 1.9], [1.1, 1.1]]))
|
||||||
|
|
||||||
|
|
||||||
|
def test_create_with_embedding_function(db):
|
||||||
|
class MyTable(LanceModel):
|
||||||
|
text: str
|
||||||
|
vector: Vector(10)
|
||||||
|
|
||||||
|
func = MockTextEmbeddingFunction()
|
||||||
|
texts = ["hello world", "goodbye world", "foo bar baz fizz buzz"]
|
||||||
|
df = pd.DataFrame({"text": texts, "vector": func.compute_source_embeddings(texts)})
|
||||||
|
|
||||||
|
conf = EmbeddingFunctionConfig(
|
||||||
|
source_column="text", vector_column="vector", function=func
|
||||||
|
)
|
||||||
|
table = LanceTable.create(
|
||||||
|
db,
|
||||||
|
"my_table",
|
||||||
|
schema=MyTable,
|
||||||
|
embedding_functions=[conf],
|
||||||
|
)
|
||||||
|
table.add(df)
|
||||||
|
|
||||||
|
query_str = "hi how are you?"
|
||||||
|
query_vector = func.compute_query_embeddings(query_str)[0]
|
||||||
|
expected = table.search(query_vector).limit(2).to_arrow()
|
||||||
|
|
||||||
|
actual = table.search(query_str).limit(2).to_arrow()
|
||||||
|
assert actual == expected
|
||||||
|
|
||||||
|
|
||||||
|
def test_add_with_embedding_function(db):
|
||||||
|
emb = EmbeddingFunctionRegistry.get_instance().get("test")()
|
||||||
|
|
||||||
|
class MyTable(LanceModel):
|
||||||
|
text: str = emb.SourceField()
|
||||||
|
vector: Vector(emb.ndims()) = emb.VectorField()
|
||||||
|
|
||||||
|
table = LanceTable.create(db, "my_table", schema=MyTable)
|
||||||
|
|
||||||
|
texts = ["hello world", "goodbye world", "foo bar baz fizz buzz"]
|
||||||
|
df = pd.DataFrame({"text": texts})
|
||||||
|
table.add(df)
|
||||||
|
|
||||||
|
texts = ["the quick brown fox", "jumped over the lazy dog"]
|
||||||
|
table.add([{"text": t} for t in texts])
|
||||||
|
|
||||||
|
query_str = "hi how are you?"
|
||||||
|
query_vector = emb.compute_query_embeddings(query_str)[0]
|
||||||
|
expected = table.search(query_vector).limit(2).to_arrow()
|
||||||
|
|
||||||
|
actual = table.search(query_str).limit(2).to_arrow()
|
||||||
|
assert actual == expected
|
||||||
|
|
||||||
|
|
||||||
|
def test_multiple_vector_columns(db):
|
||||||
|
class MyTable(LanceModel):
|
||||||
|
text: str
|
||||||
|
vector1: Vector(10)
|
||||||
|
vector2: Vector(10)
|
||||||
|
|
||||||
|
table = LanceTable.create(
|
||||||
|
db,
|
||||||
|
"my_table",
|
||||||
|
schema=MyTable,
|
||||||
|
)
|
||||||
|
|
||||||
|
v1 = np.random.randn(10)
|
||||||
|
v2 = np.random.randn(10)
|
||||||
|
data = [
|
||||||
|
{"vector1": v1, "vector2": v2, "text": "foo"},
|
||||||
|
{"vector1": v2, "vector2": v1, "text": "bar"},
|
||||||
|
]
|
||||||
|
df = pd.DataFrame(data)
|
||||||
|
table.add(df)
|
||||||
|
|
||||||
|
q = np.random.randn(10)
|
||||||
|
result1 = table.search(q, vector_column_name="vector1").limit(1).to_df()
|
||||||
|
result2 = table.search(q, vector_column_name="vector2").limit(1).to_df()
|
||||||
|
|
||||||
|
assert result1["text"].iloc[0] != result2["text"].iloc[0]
|
||||||
|
|
||||||
|
|
||||||
|
def test_empty_query(db):
|
||||||
|
table = LanceTable.create(
|
||||||
|
db,
|
||||||
|
"my_table",
|
||||||
|
data=[{"text": "foo", "id": 0}, {"text": "bar", "id": 1}],
|
||||||
|
)
|
||||||
|
df = table.search().select(["id"]).where("text='bar'").limit(1).to_df()
|
||||||
|
val = df.id.iloc[0]
|
||||||
|
assert val == 1
|
||||||
|
|||||||
@@ -1,6 +1,6 @@
|
|||||||
[package]
|
[package]
|
||||||
name = "vectordb-node"
|
name = "vectordb-node"
|
||||||
version = "0.1.14"
|
version = "0.2.6"
|
||||||
description = "Serverless, low-latency vector database for AI applications"
|
description = "Serverless, low-latency vector database for AI applications"
|
||||||
license = "Apache-2.0"
|
license = "Apache-2.0"
|
||||||
edition = "2018"
|
edition = "2018"
|
||||||
@@ -13,13 +13,16 @@ crate-type = ["cdylib"]
|
|||||||
arrow-array = { workspace = true }
|
arrow-array = { workspace = true }
|
||||||
arrow-ipc = { workspace = true }
|
arrow-ipc = { workspace = true }
|
||||||
arrow-schema = { workspace = true }
|
arrow-schema = { workspace = true }
|
||||||
|
conv = "0.3.3"
|
||||||
once_cell = "1"
|
once_cell = "1"
|
||||||
futures = "0.3"
|
futures = "0.3"
|
||||||
half = { workspace = true }
|
half = { workspace = true }
|
||||||
lance = { workspace = true }
|
lance = { workspace = true }
|
||||||
|
lance-linalg = { workspace = true }
|
||||||
vectordb = { path = "../../vectordb" }
|
vectordb = { path = "../../vectordb" }
|
||||||
tokio = { version = "1.23", features = ["rt-multi-thread"] }
|
tokio = { version = "1.23", features = ["rt-multi-thread"] }
|
||||||
neon = {version = "0.10.1", default-features = false, features = ["channel-api", "napi-6", "promise-api", "task-api"] }
|
neon = {version = "0.10.1", default-features = false, features = ["channel-api", "napi-6", "promise-api", "task-api"] }
|
||||||
object_store = { workspace = true, features = ["aws"] }
|
object_store = { workspace = true, features = ["aws"] }
|
||||||
|
snafu = { workspace = true }
|
||||||
async-trait = "0"
|
async-trait = "0"
|
||||||
env_logger = "0"
|
env_logger = "0"
|
||||||
|
|||||||
@@ -13,50 +13,48 @@
|
|||||||
// limitations under the License.
|
// limitations under the License.
|
||||||
|
|
||||||
use std::io::Cursor;
|
use std::io::Cursor;
|
||||||
use std::sync::Arc;
|
use std::ops::Deref;
|
||||||
|
|
||||||
use arrow_array::cast::as_list_array;
|
use arrow_array::RecordBatch;
|
||||||
use arrow_array::{Array, FixedSizeListArray, RecordBatch};
|
|
||||||
use arrow_ipc::reader::FileReader;
|
use arrow_ipc::reader::FileReader;
|
||||||
use arrow_schema::{DataType, Field, Schema};
|
use arrow_ipc::writer::FileWriter;
|
||||||
use lance::arrow::{FixedSizeListArrayExt, RecordBatchExt};
|
use arrow_schema::SchemaRef;
|
||||||
|
use vectordb::table::VECTOR_COLUMN_NAME;
|
||||||
|
|
||||||
pub(crate) fn convert_record_batch(record_batch: RecordBatch) -> RecordBatch {
|
use crate::error::{MissingColumnSnafu, Result};
|
||||||
let column = record_batch
|
use snafu::prelude::*;
|
||||||
.column_by_name("vector")
|
|
||||||
.cloned()
|
|
||||||
.expect("vector column is missing");
|
|
||||||
// TODO: we should just consume the underlaying js buffer in the future instead of this arrow around a bunch of times
|
|
||||||
let arr = as_list_array(column.as_ref());
|
|
||||||
let list_size = arr.values().len() / record_batch.num_rows();
|
|
||||||
let r =
|
|
||||||
FixedSizeListArray::try_new_from_values(arr.values().to_owned(), list_size as i32).unwrap();
|
|
||||||
|
|
||||||
let schema = Arc::new(Schema::new(vec![Field::new(
|
fn validate_vector_column(record_batch: &RecordBatch) -> Result<()> {
|
||||||
"vector",
|
record_batch
|
||||||
DataType::FixedSizeList(
|
.column_by_name(VECTOR_COLUMN_NAME)
|
||||||
Arc::new(Field::new("item", DataType::Float32, true)),
|
.map(|_| ())
|
||||||
list_size as i32,
|
.context(MissingColumnSnafu {
|
||||||
),
|
name: VECTOR_COLUMN_NAME,
|
||||||
true,
|
})
|
||||||
)]));
|
|
||||||
|
|
||||||
let mut new_batch = RecordBatch::try_new(schema.clone(), vec![Arc::new(r)]).unwrap();
|
|
||||||
|
|
||||||
if record_batch.num_columns() > 1 {
|
|
||||||
let rb = record_batch.drop_column("vector").unwrap();
|
|
||||||
new_batch = new_batch.merge(&rb).unwrap();
|
|
||||||
}
|
|
||||||
new_batch
|
|
||||||
}
|
}
|
||||||
|
|
||||||
pub(crate) fn arrow_buffer_to_record_batch(slice: &[u8]) -> Vec<RecordBatch> {
|
pub(crate) fn arrow_buffer_to_record_batch(slice: &[u8]) -> Result<(Vec<RecordBatch>, SchemaRef)> {
|
||||||
let mut batches: Vec<RecordBatch> = Vec::new();
|
let mut batches: Vec<RecordBatch> = Vec::new();
|
||||||
let fr = FileReader::try_new(Cursor::new(slice), None);
|
let file_reader = FileReader::try_new(Cursor::new(slice), None)?;
|
||||||
let file_reader = fr.unwrap();
|
let schema = file_reader.schema().clone();
|
||||||
for b in file_reader {
|
for b in file_reader {
|
||||||
let record_batch = convert_record_batch(b.unwrap());
|
let record_batch = b?;
|
||||||
|
validate_vector_column(&record_batch)?;
|
||||||
batches.push(record_batch);
|
batches.push(record_batch);
|
||||||
}
|
}
|
||||||
batches
|
Ok((batches, schema))
|
||||||
|
}
|
||||||
|
|
||||||
|
pub(crate) fn record_batch_to_buffer(batches: Vec<RecordBatch>) -> Result<Vec<u8>> {
|
||||||
|
if batches.is_empty() {
|
||||||
|
return Ok(Vec::new());
|
||||||
|
}
|
||||||
|
|
||||||
|
let schema = batches.get(0).unwrap().schema();
|
||||||
|
let mut fr = FileWriter::try_new(Vec::new(), schema.deref())?;
|
||||||
|
for batch in batches.iter() {
|
||||||
|
fr.write(batch)?
|
||||||
|
}
|
||||||
|
fr.finish()?;
|
||||||
|
Ok(fr.into_inner()?)
|
||||||
}
|
}
|
||||||
|
|||||||
96
rust/ffi/node/src/error.rs
Normal file
96
rust/ffi/node/src/error.rs
Normal file
@@ -0,0 +1,96 @@
|
|||||||
|
// Copyright 2023 Lance Developers.
|
||||||
|
//
|
||||||
|
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
// you may not use this file except in compliance with the License.
|
||||||
|
// You may obtain a copy of the License at
|
||||||
|
//
|
||||||
|
// http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
//
|
||||||
|
// Unless required by applicable law or agreed to in writing, software
|
||||||
|
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
// See the License for the specific language governing permissions and
|
||||||
|
// limitations under the License.
|
||||||
|
|
||||||
|
use arrow_schema::ArrowError;
|
||||||
|
use neon::context::Context;
|
||||||
|
use neon::prelude::NeonResult;
|
||||||
|
use snafu::Snafu;
|
||||||
|
|
||||||
|
#[derive(Debug, Snafu)]
|
||||||
|
#[snafu(visibility(pub(crate)))]
|
||||||
|
pub enum Error {
|
||||||
|
#[snafu(display("column '{name}' is missing"))]
|
||||||
|
MissingColumn { name: String },
|
||||||
|
#[snafu(display("{name}: {message}"))]
|
||||||
|
RangeError { name: String, message: String },
|
||||||
|
#[snafu(display("{index_type} is not a valid index type"))]
|
||||||
|
InvalidIndexType { index_type: String },
|
||||||
|
|
||||||
|
#[snafu(display("{message}"))]
|
||||||
|
LanceDB { message: String },
|
||||||
|
#[snafu(display("{message}"))]
|
||||||
|
Neon { message: String },
|
||||||
|
}
|
||||||
|
|
||||||
|
pub type Result<T> = std::result::Result<T, Error>;
|
||||||
|
|
||||||
|
impl From<vectordb::error::Error> for Error {
|
||||||
|
fn from(e: vectordb::error::Error) -> Self {
|
||||||
|
Self::LanceDB {
|
||||||
|
message: e.to_string(),
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
impl From<lance::Error> for Error {
|
||||||
|
fn from(e: lance::Error) -> Self {
|
||||||
|
Self::LanceDB {
|
||||||
|
message: e.to_string(),
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
impl From<ArrowError> for Error {
|
||||||
|
fn from(value: ArrowError) -> Self {
|
||||||
|
Self::LanceDB {
|
||||||
|
message: value.to_string(),
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
impl From<neon::result::Throw> for Error {
|
||||||
|
fn from(value: neon::result::Throw) -> Self {
|
||||||
|
Self::Neon {
|
||||||
|
message: value.to_string(),
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
impl<T> From<std::sync::mpsc::SendError<T>> for Error {
|
||||||
|
fn from(value: std::sync::mpsc::SendError<T>) -> Self {
|
||||||
|
Self::Neon {
|
||||||
|
message: value.to_string(),
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
/// ResultExt is used to transform a [`Result`] into a [`NeonResult`],
|
||||||
|
/// so it can be returned as a JavaScript error
|
||||||
|
/// Copied from [Neon](https://github.com/neon-bindings/neon/blob/4c2e455a9e6814f1ba0178616d63caec7f4df317/crates/neon/src/result/mod.rs#L88)
|
||||||
|
pub trait ResultExt<T> {
|
||||||
|
fn or_throw<'a, C: Context<'a>>(self, cx: &mut C) -> NeonResult<T>;
|
||||||
|
}
|
||||||
|
|
||||||
|
/// Implement ResultExt for the std Result so it can be used any Result type
|
||||||
|
impl<T, E> ResultExt<T> for std::result::Result<T, E>
|
||||||
|
where
|
||||||
|
E: std::fmt::Display,
|
||||||
|
{
|
||||||
|
fn or_throw<'a, C: Context<'a>>(self, cx: &mut C) -> NeonResult<T> {
|
||||||
|
match self {
|
||||||
|
Ok(value) => Ok(value),
|
||||||
|
Err(error) => cx.throw_error(error.to_string()),
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
@@ -12,40 +12,38 @@
|
|||||||
// See the License for the specific language governing permissions and
|
// See the License for the specific language governing permissions and
|
||||||
// limitations under the License.
|
// limitations under the License.
|
||||||
|
|
||||||
use std::convert::TryFrom;
|
|
||||||
|
|
||||||
use lance::index::vector::ivf::IvfBuildParams;
|
use lance::index::vector::ivf::IvfBuildParams;
|
||||||
use lance::index::vector::pq::PQBuildParams;
|
use lance::index::vector::pq::PQBuildParams;
|
||||||
use lance::index::vector::MetricType;
|
use lance_linalg::distance::MetricType;
|
||||||
use neon::context::FunctionContext;
|
use neon::context::FunctionContext;
|
||||||
use neon::prelude::*;
|
use neon::prelude::*;
|
||||||
|
use std::convert::TryFrom;
|
||||||
|
|
||||||
use vectordb::index::vector::{IvfPQIndexBuilder, VectorIndexBuilder};
|
use vectordb::index::vector::{IvfPQIndexBuilder, VectorIndexBuilder};
|
||||||
|
|
||||||
use crate::{runtime, JsTable};
|
use crate::error::Error::InvalidIndexType;
|
||||||
|
use crate::error::ResultExt;
|
||||||
|
use crate::neon_ext::js_object_ext::JsObjectExt;
|
||||||
|
use crate::runtime;
|
||||||
|
use crate::table::JsTable;
|
||||||
|
|
||||||
pub(crate) fn table_create_vector_index(mut cx: FunctionContext) -> JsResult<JsPromise> {
|
pub(crate) fn table_create_vector_index(mut cx: FunctionContext) -> JsResult<JsPromise> {
|
||||||
let js_table = cx.this().downcast_or_throw::<JsBox<JsTable>, _>(&mut cx)?;
|
let js_table = cx.this().downcast_or_throw::<JsBox<JsTable>, _>(&mut cx)?;
|
||||||
let index_params = cx.argument::<JsObject>(0)?;
|
let index_params = cx.argument::<JsObject>(0)?;
|
||||||
let index_params_builder = get_index_params_builder(&mut cx, index_params).unwrap();
|
let index_params_builder = get_index_params_builder(&mut cx, index_params).or_throw(&mut cx)?;
|
||||||
|
|
||||||
let rt = runtime(&mut cx)?;
|
let rt = runtime(&mut cx)?;
|
||||||
let channel = cx.channel();
|
|
||||||
|
|
||||||
let (deferred, promise) = cx.promise();
|
let (deferred, promise) = cx.promise();
|
||||||
let table = js_table.table.clone();
|
let channel = cx.channel();
|
||||||
|
let mut table = js_table.table.clone();
|
||||||
|
|
||||||
rt.block_on(async move {
|
rt.spawn(async move {
|
||||||
let add_result = table
|
let idx_result = table.create_index(&index_params_builder).await;
|
||||||
.lock()
|
|
||||||
.unwrap()
|
|
||||||
.create_index(&index_params_builder)
|
|
||||||
.await;
|
|
||||||
|
|
||||||
deferred.settle_with(&channel, move |mut cx| {
|
deferred.settle_with(&channel, move |mut cx| {
|
||||||
add_result
|
idx_result.or_throw(&mut cx)?;
|
||||||
.map(|_| cx.undefined())
|
Ok(cx.boxed(JsTable::from(table)))
|
||||||
.or_else(|err| cx.throw_error(err.to_string()))
|
|
||||||
});
|
});
|
||||||
});
|
});
|
||||||
Ok(promise)
|
Ok(promise)
|
||||||
@@ -54,27 +52,21 @@ pub(crate) fn table_create_vector_index(mut cx: FunctionContext) -> JsResult<JsP
|
|||||||
fn get_index_params_builder(
|
fn get_index_params_builder(
|
||||||
cx: &mut FunctionContext,
|
cx: &mut FunctionContext,
|
||||||
obj: Handle<JsObject>,
|
obj: Handle<JsObject>,
|
||||||
) -> Result<impl VectorIndexBuilder, String> {
|
) -> crate::error::Result<impl VectorIndexBuilder> {
|
||||||
let idx_type = obj
|
let idx_type = obj.get::<JsString, _, _>(cx, "type")?.value(cx);
|
||||||
.get::<JsString, _, _>(cx, "type")
|
|
||||||
.map_err(|t| t.to_string())?
|
|
||||||
.value(cx);
|
|
||||||
|
|
||||||
match idx_type.as_str() {
|
match idx_type.as_str() {
|
||||||
"ivf_pq" => {
|
"ivf_pq" => {
|
||||||
let mut index_builder: IvfPQIndexBuilder = IvfPQIndexBuilder::new();
|
let mut index_builder: IvfPQIndexBuilder = IvfPQIndexBuilder::new();
|
||||||
let mut pq_params = PQBuildParams::default();
|
let mut pq_params = PQBuildParams::default();
|
||||||
|
|
||||||
obj.get_opt::<JsString, _, _>(cx, "column")
|
obj.get_opt::<JsString, _, _>(cx, "column")?
|
||||||
.map_err(|t| t.to_string())?
|
|
||||||
.map(|s| index_builder.column(s.value(cx)));
|
.map(|s| index_builder.column(s.value(cx)));
|
||||||
|
|
||||||
obj.get_opt::<JsString, _, _>(cx, "index_name")
|
obj.get_opt::<JsString, _, _>(cx, "index_name")?
|
||||||
.map_err(|t| t.to_string())?
|
|
||||||
.map(|s| index_builder.index_name(s.value(cx)));
|
.map(|s| index_builder.index_name(s.value(cx)));
|
||||||
|
|
||||||
obj.get_opt::<JsString, _, _>(cx, "metric_type")
|
obj.get_opt::<JsString, _, _>(cx, "metric_type")?
|
||||||
.map_err(|t| t.to_string())?
|
|
||||||
.map(|s| MetricType::try_from(s.value(cx).as_str()))
|
.map(|s| MetricType::try_from(s.value(cx).as_str()))
|
||||||
.map(|mt| {
|
.map(|mt| {
|
||||||
let metric_type = mt.unwrap();
|
let metric_type = mt.unwrap();
|
||||||
@@ -82,15 +74,8 @@ fn get_index_params_builder(
|
|||||||
pq_params.metric_type = metric_type;
|
pq_params.metric_type = metric_type;
|
||||||
});
|
});
|
||||||
|
|
||||||
let num_partitions = obj
|
let num_partitions = obj.get_opt_usize(cx, "num_partitions")?;
|
||||||
.get_opt::<JsNumber, _, _>(cx, "num_partitions")
|
let max_iters = obj.get_opt_usize(cx, "max_iters")?;
|
||||||
.map_err(|t| t.to_string())?
|
|
||||||
.map(|s| s.value(cx) as usize);
|
|
||||||
|
|
||||||
let max_iters = obj
|
|
||||||
.get_opt::<JsNumber, _, _>(cx, "max_iters")
|
|
||||||
.map_err(|t| t.to_string())?
|
|
||||||
.map(|s| s.value(cx) as usize);
|
|
||||||
|
|
||||||
num_partitions.map(|np| {
|
num_partitions.map(|np| {
|
||||||
let max_iters = max_iters.unwrap_or(50);
|
let max_iters = max_iters.unwrap_or(50);
|
||||||
@@ -102,32 +87,28 @@ fn get_index_params_builder(
|
|||||||
index_builder.ivf_params(ivf_params)
|
index_builder.ivf_params(ivf_params)
|
||||||
});
|
});
|
||||||
|
|
||||||
obj.get_opt::<JsBoolean, _, _>(cx, "use_opq")
|
obj.get_opt::<JsBoolean, _, _>(cx, "use_opq")?
|
||||||
.map_err(|t| t.to_string())?
|
|
||||||
.map(|s| pq_params.use_opq = s.value(cx));
|
.map(|s| pq_params.use_opq = s.value(cx));
|
||||||
|
|
||||||
obj.get_opt::<JsNumber, _, _>(cx, "num_sub_vectors")
|
obj.get_opt_usize(cx, "num_sub_vectors")?
|
||||||
.map_err(|t| t.to_string())?
|
.map(|s| pq_params.num_sub_vectors = s);
|
||||||
.map(|s| pq_params.num_sub_vectors = s.value(cx) as usize);
|
|
||||||
|
|
||||||
obj.get_opt::<JsNumber, _, _>(cx, "num_bits")
|
obj.get_opt_usize(cx, "num_bits")?
|
||||||
.map_err(|t| t.to_string())?
|
.map(|s| pq_params.num_bits = s);
|
||||||
.map(|s| pq_params.num_bits = s.value(cx) as usize);
|
|
||||||
|
|
||||||
obj.get_opt::<JsNumber, _, _>(cx, "max_iters")
|
obj.get_opt_usize(cx, "max_iters")?
|
||||||
.map_err(|t| t.to_string())?
|
.map(|s| pq_params.max_iters = s);
|
||||||
.map(|s| pq_params.max_iters = s.value(cx) as usize);
|
|
||||||
|
|
||||||
obj.get_opt::<JsNumber, _, _>(cx, "max_opq_iters")
|
obj.get_opt_usize(cx, "max_opq_iters")?
|
||||||
.map_err(|t| t.to_string())?
|
.map(|s| pq_params.max_opq_iters = s);
|
||||||
.map(|s| pq_params.max_opq_iters = s.value(cx) as usize);
|
|
||||||
|
|
||||||
obj.get_opt::<JsBoolean, _, _>(cx, "replace")
|
obj.get_opt::<JsBoolean, _, _>(cx, "replace")?
|
||||||
.map_err(|t| t.to_string())?
|
|
||||||
.map(|s| index_builder.replace(s.value(cx)));
|
.map(|s| index_builder.replace(s.value(cx)));
|
||||||
|
|
||||||
Ok(index_builder)
|
Ok(index_builder)
|
||||||
}
|
}
|
||||||
t => Err(format!("{} is not a valid index type", t).to_string()),
|
index_type => Err(InvalidIndexType {
|
||||||
|
index_type: index_type.into(),
|
||||||
|
}),
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|||||||
@@ -12,34 +12,30 @@
|
|||||||
// See the License for the specific language governing permissions and
|
// See the License for the specific language governing permissions and
|
||||||
// limitations under the License.
|
// limitations under the License.
|
||||||
|
|
||||||
use std::collections::HashMap;
|
use std::sync::Arc;
|
||||||
use std::convert::TryFrom;
|
|
||||||
use std::ops::Deref;
|
|
||||||
use std::sync::{Arc, Mutex};
|
|
||||||
|
|
||||||
use arrow_array::{Float32Array, RecordBatchIterator};
|
|
||||||
use arrow_ipc::writer::FileWriter;
|
|
||||||
use async_trait::async_trait;
|
use async_trait::async_trait;
|
||||||
use futures::{TryFutureExt, TryStreamExt};
|
|
||||||
use lance::dataset::{WriteMode, WriteParams};
|
|
||||||
use lance::index::vector::MetricType;
|
|
||||||
use lance::io::object_store::ObjectStoreParams;
|
use lance::io::object_store::ObjectStoreParams;
|
||||||
use neon::prelude::*;
|
use neon::prelude::*;
|
||||||
use neon::types::buffer::TypedArray;
|
|
||||||
use object_store::aws::{AwsCredential, AwsCredentialProvider};
|
use object_store::aws::{AwsCredential, AwsCredentialProvider};
|
||||||
use object_store::CredentialProvider;
|
use object_store::CredentialProvider;
|
||||||
use once_cell::sync::OnceCell;
|
use once_cell::sync::OnceCell;
|
||||||
use tokio::runtime::Runtime;
|
use tokio::runtime::Runtime;
|
||||||
|
|
||||||
use vectordb::database::Database;
|
use vectordb::database::Database;
|
||||||
use vectordb::error::Error;
|
use vectordb::table::ReadParams;
|
||||||
use vectordb::table::{ReadParams, Table};
|
|
||||||
|
|
||||||
use crate::arrow::arrow_buffer_to_record_batch;
|
use crate::error::ResultExt;
|
||||||
|
use crate::query::JsQuery;
|
||||||
|
use crate::table::JsTable;
|
||||||
|
|
||||||
mod arrow;
|
mod arrow;
|
||||||
mod convert;
|
mod convert;
|
||||||
|
mod error;
|
||||||
mod index;
|
mod index;
|
||||||
|
mod neon_ext;
|
||||||
|
mod query;
|
||||||
|
mod table;
|
||||||
|
|
||||||
struct JsDatabase {
|
struct JsDatabase {
|
||||||
database: Arc<Database>,
|
database: Arc<Database>,
|
||||||
@@ -47,14 +43,8 @@ struct JsDatabase {
|
|||||||
|
|
||||||
impl Finalize for JsDatabase {}
|
impl Finalize for JsDatabase {}
|
||||||
|
|
||||||
struct JsTable {
|
|
||||||
table: Arc<Mutex<Table>>,
|
|
||||||
}
|
|
||||||
|
|
||||||
impl Finalize for JsTable {}
|
|
||||||
|
|
||||||
// TODO: object_store didn't export this type so I copied it.
|
// TODO: object_store didn't export this type so I copied it.
|
||||||
// Make a requiest to object_store to export this type
|
// Make a request to object_store to export this type
|
||||||
#[derive(Debug)]
|
#[derive(Debug)]
|
||||||
pub struct StaticCredentialProvider<T> {
|
pub struct StaticCredentialProvider<T> {
|
||||||
credential: Arc<T>,
|
credential: Arc<T>,
|
||||||
@@ -86,7 +76,7 @@ fn runtime<'a, C: Context<'a>>(cx: &mut C) -> NeonResult<&'static Runtime> {
|
|||||||
|
|
||||||
LOG.get_or_init(|| env_logger::init());
|
LOG.get_or_init(|| env_logger::init());
|
||||||
|
|
||||||
RUNTIME.get_or_try_init(|| Runtime::new().or_else(|err| cx.throw_error(err.to_string())))
|
RUNTIME.get_or_try_init(|| Runtime::new().or_throw(cx))
|
||||||
}
|
}
|
||||||
|
|
||||||
fn database_new(mut cx: FunctionContext) -> JsResult<JsPromise> {
|
fn database_new(mut cx: FunctionContext) -> JsResult<JsPromise> {
|
||||||
@@ -101,7 +91,7 @@ fn database_new(mut cx: FunctionContext) -> JsResult<JsPromise> {
|
|||||||
|
|
||||||
deferred.settle_with(&channel, move |mut cx| {
|
deferred.settle_with(&channel, move |mut cx| {
|
||||||
let db = JsDatabase {
|
let db = JsDatabase {
|
||||||
database: Arc::new(database.or_else(|err| cx.throw_error(err.to_string()))?),
|
database: Arc::new(database.or_throw(&mut cx)?),
|
||||||
};
|
};
|
||||||
Ok(cx.boxed(db))
|
Ok(cx.boxed(db))
|
||||||
});
|
});
|
||||||
@@ -123,7 +113,7 @@ fn database_table_names(mut cx: FunctionContext) -> JsResult<JsPromise> {
|
|||||||
let tables_rst = database.table_names().await;
|
let tables_rst = database.table_names().await;
|
||||||
|
|
||||||
deferred.settle_with(&channel, move |mut cx| {
|
deferred.settle_with(&channel, move |mut cx| {
|
||||||
let tables = tables_rst.or_else(|err| cx.throw_error(err.to_string()))?;
|
let tables = tables_rst.or_throw(&mut cx)?;
|
||||||
let table_names = convert::vec_str_to_array(&tables, &mut cx);
|
let table_names = convert::vec_str_to_array(&tables, &mut cx);
|
||||||
table_names
|
table_names
|
||||||
});
|
});
|
||||||
@@ -131,26 +121,28 @@ fn database_table_names(mut cx: FunctionContext) -> JsResult<JsPromise> {
|
|||||||
Ok(promise)
|
Ok(promise)
|
||||||
}
|
}
|
||||||
|
|
||||||
fn get_aws_creds<T>(
|
/// Get AWS creds arguments from the context
|
||||||
|
/// Consumes 3 arguments
|
||||||
|
fn get_aws_creds(
|
||||||
cx: &mut FunctionContext,
|
cx: &mut FunctionContext,
|
||||||
arg_starting_location: i32,
|
arg_starting_location: i32,
|
||||||
) -> Result<Option<AwsCredentialProvider>, NeonResult<T>> {
|
) -> NeonResult<Option<AwsCredentialProvider>> {
|
||||||
let secret_key_id = cx
|
let secret_key_id = cx
|
||||||
.argument_opt(arg_starting_location)
|
.argument_opt(arg_starting_location)
|
||||||
.map(|arg| arg.downcast_or_throw::<JsString, FunctionContext>(cx).ok())
|
.filter(|arg| arg.is_a::<JsString, _>(cx))
|
||||||
.flatten()
|
.and_then(|arg| arg.downcast_or_throw::<JsString, FunctionContext>(cx).ok())
|
||||||
.map(|v| v.value(cx));
|
.map(|v| v.value(cx));
|
||||||
|
|
||||||
let secret_key = cx
|
let secret_key = cx
|
||||||
.argument_opt(arg_starting_location + 1)
|
.argument_opt(arg_starting_location + 1)
|
||||||
.map(|arg| arg.downcast_or_throw::<JsString, FunctionContext>(cx).ok())
|
.filter(|arg| arg.is_a::<JsString, _>(cx))
|
||||||
.flatten()
|
.and_then(|arg| arg.downcast_or_throw::<JsString, FunctionContext>(cx).ok())
|
||||||
.map(|v| v.value(cx));
|
.map(|v| v.value(cx));
|
||||||
|
|
||||||
let temp_token = cx
|
let temp_token = cx
|
||||||
.argument_opt(arg_starting_location + 2)
|
.argument_opt(arg_starting_location + 2)
|
||||||
.map(|arg| arg.downcast_or_throw::<JsString, FunctionContext>(cx).ok())
|
.filter(|arg| arg.is_a::<JsString, _>(cx))
|
||||||
.flatten()
|
.and_then(|arg| arg.downcast_or_throw::<JsString, FunctionContext>(cx).ok())
|
||||||
.map(|v| v.value(cx));
|
.map(|v| v.value(cx));
|
||||||
|
|
||||||
match (secret_key_id, secret_key, temp_token) {
|
match (secret_key_id, secret_key, temp_token) {
|
||||||
@@ -162,7 +154,21 @@ fn get_aws_creds<T>(
|
|||||||
}),
|
}),
|
||||||
))),
|
))),
|
||||||
(None, None, None) => Ok(None),
|
(None, None, None) => Ok(None),
|
||||||
_ => Err(cx.throw_error("Invalid credentials configuration")),
|
_ => cx.throw_error("Invalid credentials configuration"),
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
/// Get AWS region arguments from the context
|
||||||
|
fn get_aws_region(cx: &mut FunctionContext, arg_location: i32) -> NeonResult<Option<String>> {
|
||||||
|
let region = cx
|
||||||
|
.argument_opt(arg_location)
|
||||||
|
.filter(|arg| arg.is_a::<JsString, _>(cx))
|
||||||
|
.map(|arg| arg.downcast_or_throw::<JsString, FunctionContext>(cx));
|
||||||
|
|
||||||
|
match region {
|
||||||
|
Some(Ok(region)) => Ok(Some(region.value(cx))),
|
||||||
|
None => Ok(None),
|
||||||
|
Some(Err(e)) => Err(e),
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
@@ -172,16 +178,14 @@ fn database_open_table(mut cx: FunctionContext) -> JsResult<JsPromise> {
|
|||||||
.downcast_or_throw::<JsBox<JsDatabase>, _>(&mut cx)?;
|
.downcast_or_throw::<JsBox<JsDatabase>, _>(&mut cx)?;
|
||||||
let table_name = cx.argument::<JsString>(0)?.value(&mut cx);
|
let table_name = cx.argument::<JsString>(0)?.value(&mut cx);
|
||||||
|
|
||||||
let aws_creds = match get_aws_creds(&mut cx, 1) {
|
let aws_creds = get_aws_creds(&mut cx, 1)?;
|
||||||
Ok(creds) => creds,
|
|
||||||
Err(err) => return err,
|
let aws_region = get_aws_region(&mut cx, 4)?;
|
||||||
};
|
|
||||||
|
|
||||||
let params = ReadParams {
|
let params = ReadParams {
|
||||||
store_options: Some(ObjectStoreParams {
|
store_options: Some(ObjectStoreParams::with_aws_credentials(
|
||||||
aws_credentials: aws_creds,
|
aws_creds, aws_region,
|
||||||
..ObjectStoreParams::default()
|
)),
|
||||||
}),
|
|
||||||
..ReadParams::default()
|
..ReadParams::default()
|
||||||
};
|
};
|
||||||
|
|
||||||
@@ -194,10 +198,8 @@ fn database_open_table(mut cx: FunctionContext) -> JsResult<JsPromise> {
|
|||||||
let table_rst = database.open_table_with_params(&table_name, ¶ms).await;
|
let table_rst = database.open_table_with_params(&table_name, ¶ms).await;
|
||||||
|
|
||||||
deferred.settle_with(&channel, move |mut cx| {
|
deferred.settle_with(&channel, move |mut cx| {
|
||||||
let table = Arc::new(Mutex::new(
|
let js_table = JsTable::from(table_rst.or_throw(&mut cx)?);
|
||||||
table_rst.or_else(|err| cx.throw_error(err.to_string()))?,
|
Ok(cx.boxed(js_table))
|
||||||
));
|
|
||||||
Ok(cx.boxed(JsTable { table }))
|
|
||||||
});
|
});
|
||||||
});
|
});
|
||||||
Ok(promise)
|
Ok(promise)
|
||||||
@@ -217,245 +219,24 @@ fn database_drop_table(mut cx: FunctionContext) -> JsResult<JsPromise> {
|
|||||||
rt.spawn(async move {
|
rt.spawn(async move {
|
||||||
let result = database.drop_table(&table_name).await;
|
let result = database.drop_table(&table_name).await;
|
||||||
deferred.settle_with(&channel, move |mut cx| {
|
deferred.settle_with(&channel, move |mut cx| {
|
||||||
result.or_else(|err| cx.throw_error(err.to_string()))?;
|
result.or_throw(&mut cx)?;
|
||||||
Ok(cx.null())
|
Ok(cx.null())
|
||||||
});
|
});
|
||||||
});
|
});
|
||||||
Ok(promise)
|
Ok(promise)
|
||||||
}
|
}
|
||||||
|
|
||||||
fn table_search(mut cx: FunctionContext) -> JsResult<JsPromise> {
|
|
||||||
let js_table = cx.this().downcast_or_throw::<JsBox<JsTable>, _>(&mut cx)?;
|
|
||||||
let query_obj = cx.argument::<JsObject>(0)?;
|
|
||||||
|
|
||||||
let limit = query_obj
|
|
||||||
.get::<JsNumber, _, _>(&mut cx, "_limit")?
|
|
||||||
.value(&mut cx);
|
|
||||||
let select = query_obj
|
|
||||||
.get_opt::<JsArray, _, _>(&mut cx, "_select")?
|
|
||||||
.map(|arr| {
|
|
||||||
let js_array = arr.deref();
|
|
||||||
let mut projection_vec: Vec<String> = Vec::new();
|
|
||||||
for i in 0..js_array.len(&mut cx) {
|
|
||||||
let entry: Handle<JsString> = js_array.get(&mut cx, i).unwrap();
|
|
||||||
projection_vec.push(entry.value(&mut cx));
|
|
||||||
}
|
|
||||||
projection_vec
|
|
||||||
});
|
|
||||||
let filter = query_obj
|
|
||||||
.get_opt::<JsString, _, _>(&mut cx, "_filter")?
|
|
||||||
.map(|s| s.value(&mut cx));
|
|
||||||
let refine_factor = query_obj
|
|
||||||
.get_opt::<JsNumber, _, _>(&mut cx, "_refineFactor")?
|
|
||||||
.map(|s| s.value(&mut cx))
|
|
||||||
.map(|i| i as u32);
|
|
||||||
let nprobes = query_obj
|
|
||||||
.get::<JsNumber, _, _>(&mut cx, "_nprobes")?
|
|
||||||
.value(&mut cx) as usize;
|
|
||||||
let metric_type = query_obj
|
|
||||||
.get_opt::<JsString, _, _>(&mut cx, "_metricType")?
|
|
||||||
.map(|s| s.value(&mut cx))
|
|
||||||
.map(|s| MetricType::try_from(s.as_str()).unwrap());
|
|
||||||
|
|
||||||
let rt = runtime(&mut cx)?;
|
|
||||||
let channel = cx.channel();
|
|
||||||
|
|
||||||
let (deferred, promise) = cx.promise();
|
|
||||||
let table = js_table.table.clone();
|
|
||||||
let query_vector = query_obj.get::<JsArray, _, _>(&mut cx, "_queryVector")?;
|
|
||||||
let query = convert::js_array_to_vec(query_vector.deref(), &mut cx);
|
|
||||||
|
|
||||||
rt.spawn(async move {
|
|
||||||
let builder = table
|
|
||||||
.lock()
|
|
||||||
.unwrap()
|
|
||||||
.search(Float32Array::from(query))
|
|
||||||
.limit(limit as usize)
|
|
||||||
.refine_factor(refine_factor)
|
|
||||||
.nprobes(nprobes)
|
|
||||||
.filter(filter)
|
|
||||||
.metric_type(metric_type)
|
|
||||||
.select(select);
|
|
||||||
let record_batch_stream = builder.execute();
|
|
||||||
let results = record_batch_stream
|
|
||||||
.and_then(|stream| stream.try_collect::<Vec<_>>().map_err(Error::from))
|
|
||||||
.await;
|
|
||||||
|
|
||||||
deferred.settle_with(&channel, move |mut cx| {
|
|
||||||
let results = results.or_else(|err| cx.throw_error(err.to_string()))?;
|
|
||||||
let vector: Vec<u8> = Vec::new();
|
|
||||||
|
|
||||||
if results.is_empty() {
|
|
||||||
return cx.buffer(0);
|
|
||||||
}
|
|
||||||
|
|
||||||
let schema = results.get(0).unwrap().schema();
|
|
||||||
let mut fr = FileWriter::try_new(vector, schema.deref())
|
|
||||||
.or_else(|err| cx.throw_error(err.to_string()))?;
|
|
||||||
|
|
||||||
for batch in results.iter() {
|
|
||||||
fr.write(batch)
|
|
||||||
.or_else(|err| cx.throw_error(err.to_string()))?;
|
|
||||||
}
|
|
||||||
fr.finish().or_else(|err| cx.throw_error(err.to_string()))?;
|
|
||||||
let buf = fr
|
|
||||||
.into_inner()
|
|
||||||
.or_else(|err| cx.throw_error(err.to_string()))?;
|
|
||||||
Ok(JsBuffer::external(&mut cx, buf))
|
|
||||||
});
|
|
||||||
});
|
|
||||||
Ok(promise)
|
|
||||||
}
|
|
||||||
|
|
||||||
fn table_create(mut cx: FunctionContext) -> JsResult<JsPromise> {
|
|
||||||
let db = cx
|
|
||||||
.this()
|
|
||||||
.downcast_or_throw::<JsBox<JsDatabase>, _>(&mut cx)?;
|
|
||||||
let table_name = cx.argument::<JsString>(0)?.value(&mut cx);
|
|
||||||
let buffer = cx.argument::<JsBuffer>(1)?;
|
|
||||||
let batches = arrow_buffer_to_record_batch(buffer.as_slice(&mut cx));
|
|
||||||
let schema = batches[0].schema();
|
|
||||||
|
|
||||||
// Write mode
|
|
||||||
let mode = match cx.argument::<JsString>(2)?.value(&mut cx).as_str() {
|
|
||||||
"overwrite" => WriteMode::Overwrite,
|
|
||||||
"append" => WriteMode::Append,
|
|
||||||
"create" => WriteMode::Create,
|
|
||||||
_ => return cx.throw_error("Table::create only supports 'overwrite' and 'create' modes"),
|
|
||||||
};
|
|
||||||
|
|
||||||
let rt = runtime(&mut cx)?;
|
|
||||||
let channel = cx.channel();
|
|
||||||
|
|
||||||
let (deferred, promise) = cx.promise();
|
|
||||||
let database = db.database.clone();
|
|
||||||
|
|
||||||
let aws_creds = match get_aws_creds(&mut cx, 3) {
|
|
||||||
Ok(creds) => creds,
|
|
||||||
Err(err) => return err,
|
|
||||||
};
|
|
||||||
|
|
||||||
let params = WriteParams {
|
|
||||||
store_params: Some(ObjectStoreParams {
|
|
||||||
aws_credentials: aws_creds,
|
|
||||||
..ObjectStoreParams::default()
|
|
||||||
}),
|
|
||||||
mode: mode,
|
|
||||||
..WriteParams::default()
|
|
||||||
};
|
|
||||||
|
|
||||||
rt.block_on(async move {
|
|
||||||
let batch_reader = RecordBatchIterator::new(batches.into_iter().map(Ok), schema);
|
|
||||||
let table_rst = database
|
|
||||||
.create_table(&table_name, batch_reader, Some(params))
|
|
||||||
.await;
|
|
||||||
|
|
||||||
deferred.settle_with(&channel, move |mut cx| {
|
|
||||||
let table = Arc::new(Mutex::new(
|
|
||||||
table_rst.or_else(|err| cx.throw_error(err.to_string()))?,
|
|
||||||
));
|
|
||||||
Ok(cx.boxed(JsTable { table }))
|
|
||||||
});
|
|
||||||
});
|
|
||||||
Ok(promise)
|
|
||||||
}
|
|
||||||
|
|
||||||
fn table_add(mut cx: FunctionContext) -> JsResult<JsPromise> {
|
|
||||||
let write_mode_map: HashMap<&str, WriteMode> = HashMap::from([
|
|
||||||
("create", WriteMode::Create),
|
|
||||||
("append", WriteMode::Append),
|
|
||||||
("overwrite", WriteMode::Overwrite),
|
|
||||||
]);
|
|
||||||
|
|
||||||
let js_table = cx.this().downcast_or_throw::<JsBox<JsTable>, _>(&mut cx)?;
|
|
||||||
let buffer = cx.argument::<JsBuffer>(0)?;
|
|
||||||
let write_mode = cx.argument::<JsString>(1)?.value(&mut cx);
|
|
||||||
let batches = arrow_buffer_to_record_batch(buffer.as_slice(&mut cx));
|
|
||||||
let schema = batches[0].schema();
|
|
||||||
|
|
||||||
let rt = runtime(&mut cx)?;
|
|
||||||
let channel = cx.channel();
|
|
||||||
|
|
||||||
let (deferred, promise) = cx.promise();
|
|
||||||
let table = js_table.table.clone();
|
|
||||||
let write_mode = write_mode_map.get(write_mode.as_str()).cloned();
|
|
||||||
|
|
||||||
let aws_creds = match get_aws_creds(&mut cx, 2) {
|
|
||||||
Ok(creds) => creds,
|
|
||||||
Err(err) => return err,
|
|
||||||
};
|
|
||||||
|
|
||||||
let params = WriteParams {
|
|
||||||
store_params: Some(ObjectStoreParams {
|
|
||||||
aws_credentials: aws_creds,
|
|
||||||
..ObjectStoreParams::default()
|
|
||||||
}),
|
|
||||||
mode: write_mode.unwrap_or(WriteMode::Append),
|
|
||||||
..WriteParams::default()
|
|
||||||
};
|
|
||||||
|
|
||||||
rt.block_on(async move {
|
|
||||||
let batch_reader = RecordBatchIterator::new(batches.into_iter().map(Ok), schema);
|
|
||||||
let add_result = table.lock().unwrap().add(batch_reader, Some(params)).await;
|
|
||||||
|
|
||||||
deferred.settle_with(&channel, move |mut cx| {
|
|
||||||
let _added = add_result.or_else(|err| cx.throw_error(err.to_string()))?;
|
|
||||||
Ok(cx.boolean(true))
|
|
||||||
});
|
|
||||||
});
|
|
||||||
Ok(promise)
|
|
||||||
}
|
|
||||||
|
|
||||||
fn table_count_rows(mut cx: FunctionContext) -> JsResult<JsPromise> {
|
|
||||||
let js_table = cx.this().downcast_or_throw::<JsBox<JsTable>, _>(&mut cx)?;
|
|
||||||
let rt = runtime(&mut cx)?;
|
|
||||||
let channel = cx.channel();
|
|
||||||
|
|
||||||
let (deferred, promise) = cx.promise();
|
|
||||||
let table = js_table.table.clone();
|
|
||||||
|
|
||||||
rt.block_on(async move {
|
|
||||||
let num_rows_result = table.lock().unwrap().count_rows().await;
|
|
||||||
|
|
||||||
deferred.settle_with(&channel, move |mut cx| {
|
|
||||||
let num_rows = num_rows_result.or_else(|err| cx.throw_error(err.to_string()))?;
|
|
||||||
Ok(cx.number(num_rows as f64))
|
|
||||||
});
|
|
||||||
});
|
|
||||||
Ok(promise)
|
|
||||||
}
|
|
||||||
|
|
||||||
fn table_delete(mut cx: FunctionContext) -> JsResult<JsPromise> {
|
|
||||||
let js_table = cx.this().downcast_or_throw::<JsBox<JsTable>, _>(&mut cx)?;
|
|
||||||
let rt = runtime(&mut cx)?;
|
|
||||||
let channel = cx.channel();
|
|
||||||
|
|
||||||
let (deferred, promise) = cx.promise();
|
|
||||||
let table = js_table.table.clone();
|
|
||||||
|
|
||||||
let predicate = cx.argument::<JsString>(0)?.value(&mut cx);
|
|
||||||
|
|
||||||
let delete_result = rt.block_on(async move { table.lock().unwrap().delete(&predicate).await });
|
|
||||||
|
|
||||||
deferred.settle_with(&channel, move |mut cx| {
|
|
||||||
delete_result.or_else(|err| cx.throw_error(err.to_string()))?;
|
|
||||||
Ok(cx.undefined())
|
|
||||||
});
|
|
||||||
|
|
||||||
Ok(promise)
|
|
||||||
}
|
|
||||||
|
|
||||||
#[neon::main]
|
#[neon::main]
|
||||||
fn main(mut cx: ModuleContext) -> NeonResult<()> {
|
fn main(mut cx: ModuleContext) -> NeonResult<()> {
|
||||||
cx.export_function("databaseNew", database_new)?;
|
cx.export_function("databaseNew", database_new)?;
|
||||||
cx.export_function("databaseTableNames", database_table_names)?;
|
cx.export_function("databaseTableNames", database_table_names)?;
|
||||||
cx.export_function("databaseOpenTable", database_open_table)?;
|
cx.export_function("databaseOpenTable", database_open_table)?;
|
||||||
cx.export_function("databaseDropTable", database_drop_table)?;
|
cx.export_function("databaseDropTable", database_drop_table)?;
|
||||||
cx.export_function("tableSearch", table_search)?;
|
cx.export_function("tableSearch", JsQuery::js_search)?;
|
||||||
cx.export_function("tableCreate", table_create)?;
|
cx.export_function("tableCreate", JsTable::js_create)?;
|
||||||
cx.export_function("tableAdd", table_add)?;
|
cx.export_function("tableAdd", JsTable::js_add)?;
|
||||||
cx.export_function("tableCountRows", table_count_rows)?;
|
cx.export_function("tableCountRows", JsTable::js_count_rows)?;
|
||||||
cx.export_function("tableDelete", table_delete)?;
|
cx.export_function("tableDelete", JsTable::js_delete)?;
|
||||||
cx.export_function(
|
cx.export_function(
|
||||||
"tableCreateVectorIndex",
|
"tableCreateVectorIndex",
|
||||||
index::vector::table_create_vector_index,
|
index::vector::table_create_vector_index,
|
||||||
|
|||||||
15
rust/ffi/node/src/neon_ext.rs
Normal file
15
rust/ffi/node/src/neon_ext.rs
Normal file
@@ -0,0 +1,15 @@
|
|||||||
|
// Copyright 2023 Lance Developers.
|
||||||
|
//
|
||||||
|
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
// you may not use this file except in compliance with the License.
|
||||||
|
// You may obtain a copy of the License at
|
||||||
|
//
|
||||||
|
// http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
//
|
||||||
|
// Unless required by applicable law or agreed to in writing, software
|
||||||
|
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
// See the License for the specific language governing permissions and
|
||||||
|
// limitations under the License.
|
||||||
|
|
||||||
|
pub mod js_object_ext;
|
||||||
82
rust/ffi/node/src/neon_ext/js_object_ext.rs
Normal file
82
rust/ffi/node/src/neon_ext/js_object_ext.rs
Normal file
@@ -0,0 +1,82 @@
|
|||||||
|
// Copyright 2023 Lance Developers.
|
||||||
|
//
|
||||||
|
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
// you may not use this file except in compliance with the License.
|
||||||
|
// You may obtain a copy of the License at
|
||||||
|
//
|
||||||
|
// http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
//
|
||||||
|
// Unless required by applicable law or agreed to in writing, software
|
||||||
|
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
// See the License for the specific language governing permissions and
|
||||||
|
// limitations under the License.
|
||||||
|
|
||||||
|
use crate::error::{Error, Result};
|
||||||
|
use neon::prelude::*;
|
||||||
|
|
||||||
|
// extends neon's [JsObject] with helper functions to extract properties
|
||||||
|
pub trait JsObjectExt {
|
||||||
|
fn get_opt_u32(&self, cx: &mut FunctionContext, key: &str) -> Result<Option<u32>>;
|
||||||
|
fn get_usize(&self, cx: &mut FunctionContext, key: &str) -> Result<usize>;
|
||||||
|
fn get_opt_usize(&self, cx: &mut FunctionContext, key: &str) -> Result<Option<usize>>;
|
||||||
|
}
|
||||||
|
|
||||||
|
impl JsObjectExt for JsObject {
|
||||||
|
fn get_opt_u32(&self, cx: &mut FunctionContext, key: &str) -> Result<Option<u32>> {
|
||||||
|
let val_opt = self
|
||||||
|
.get_opt::<JsNumber, _, _>(cx, key)?
|
||||||
|
.map(|s| f64_to_u32_safe(s.value(cx), key));
|
||||||
|
val_opt.transpose()
|
||||||
|
}
|
||||||
|
|
||||||
|
fn get_usize(&self, cx: &mut FunctionContext, key: &str) -> Result<usize> {
|
||||||
|
let val = self.get::<JsNumber, _, _>(cx, key)?.value(cx);
|
||||||
|
f64_to_usize_safe(val, key)
|
||||||
|
}
|
||||||
|
|
||||||
|
fn get_opt_usize(&self, cx: &mut FunctionContext, key: &str) -> Result<Option<usize>> {
|
||||||
|
let val_opt = self
|
||||||
|
.get_opt::<JsNumber, _, _>(cx, key)?
|
||||||
|
.map(|s| f64_to_usize_safe(s.value(cx), key));
|
||||||
|
val_opt.transpose()
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
fn f64_to_u32_safe(n: f64, key: &str) -> Result<u32> {
|
||||||
|
use conv::*;
|
||||||
|
|
||||||
|
n.approx_as::<u32>().map_err(|e| match e {
|
||||||
|
FloatError::NegOverflow(_) => Error::RangeError {
|
||||||
|
name: key.into(),
|
||||||
|
message: "must be > 0".to_string(),
|
||||||
|
},
|
||||||
|
FloatError::PosOverflow(_) => Error::RangeError {
|
||||||
|
name: key.into(),
|
||||||
|
message: format!("must be < {}", u32::MAX),
|
||||||
|
},
|
||||||
|
FloatError::NotANumber(_) => Error::RangeError {
|
||||||
|
name: key.into(),
|
||||||
|
message: "not a valid number".to_string(),
|
||||||
|
},
|
||||||
|
})
|
||||||
|
}
|
||||||
|
|
||||||
|
fn f64_to_usize_safe(n: f64, key: &str) -> Result<usize> {
|
||||||
|
use conv::*;
|
||||||
|
|
||||||
|
n.approx_as::<usize>().map_err(|e| match e {
|
||||||
|
FloatError::NegOverflow(_) => Error::RangeError {
|
||||||
|
name: key.into(),
|
||||||
|
message: "must be > 0".to_string(),
|
||||||
|
},
|
||||||
|
FloatError::PosOverflow(_) => Error::RangeError {
|
||||||
|
name: key.into(),
|
||||||
|
message: format!("must be < {}", usize::MAX),
|
||||||
|
},
|
||||||
|
FloatError::NotANumber(_) => Error::RangeError {
|
||||||
|
name: key.into(),
|
||||||
|
message: "not a valid number".to_string(),
|
||||||
|
},
|
||||||
|
})
|
||||||
|
}
|
||||||
107
rust/ffi/node/src/query.rs
Normal file
107
rust/ffi/node/src/query.rs
Normal file
@@ -0,0 +1,107 @@
|
|||||||
|
use std::convert::TryFrom;
|
||||||
|
use std::ops::Deref;
|
||||||
|
|
||||||
|
use arrow_array::Float32Array;
|
||||||
|
use futures::{TryFutureExt, TryStreamExt};
|
||||||
|
use lance_linalg::distance::MetricType;
|
||||||
|
use neon::context::FunctionContext;
|
||||||
|
use neon::handle::Handle;
|
||||||
|
use neon::prelude::*;
|
||||||
|
use neon::types::buffer::TypedArray;
|
||||||
|
|
||||||
|
use crate::arrow::record_batch_to_buffer;
|
||||||
|
use crate::error::ResultExt;
|
||||||
|
use crate::neon_ext::js_object_ext::JsObjectExt;
|
||||||
|
use crate::table::JsTable;
|
||||||
|
use crate::{convert, runtime};
|
||||||
|
|
||||||
|
pub(crate) struct JsQuery {}
|
||||||
|
|
||||||
|
impl JsQuery {
|
||||||
|
pub(crate) fn js_search(mut cx: FunctionContext) -> JsResult<JsPromise> {
|
||||||
|
let js_table = cx.this().downcast_or_throw::<JsBox<JsTable>, _>(&mut cx)?;
|
||||||
|
let query_obj = cx.argument::<JsObject>(0)?;
|
||||||
|
|
||||||
|
let limit = query_obj
|
||||||
|
.get::<JsNumber, _, _>(&mut cx, "_limit")?
|
||||||
|
.value(&mut cx);
|
||||||
|
let select = query_obj
|
||||||
|
.get_opt::<JsArray, _, _>(&mut cx, "_select")?
|
||||||
|
.map(|arr| {
|
||||||
|
let js_array = arr.deref();
|
||||||
|
let mut projection_vec: Vec<String> = Vec::new();
|
||||||
|
for i in 0..js_array.len(&mut cx) {
|
||||||
|
let entry: Handle<JsString> = js_array.get(&mut cx, i).unwrap();
|
||||||
|
projection_vec.push(entry.value(&mut cx));
|
||||||
|
}
|
||||||
|
projection_vec
|
||||||
|
});
|
||||||
|
let filter = query_obj
|
||||||
|
.get_opt::<JsString, _, _>(&mut cx, "_filter")?
|
||||||
|
.map(|s| s.value(&mut cx));
|
||||||
|
let refine_factor = query_obj
|
||||||
|
.get_opt_u32(&mut cx, "_refineFactor")
|
||||||
|
.or_throw(&mut cx)?;
|
||||||
|
let nprobes = query_obj.get_usize(&mut cx, "_nprobes").or_throw(&mut cx)?;
|
||||||
|
let metric_type = query_obj
|
||||||
|
.get_opt::<JsString, _, _>(&mut cx, "_metricType")?
|
||||||
|
.map(|s| s.value(&mut cx))
|
||||||
|
.map(|s| MetricType::try_from(s.as_str()).unwrap());
|
||||||
|
|
||||||
|
let is_electron = cx
|
||||||
|
.argument::<JsBoolean>(1)
|
||||||
|
.or_throw(&mut cx)?
|
||||||
|
.value(&mut cx);
|
||||||
|
|
||||||
|
let rt = runtime(&mut cx)?;
|
||||||
|
|
||||||
|
let (deferred, promise) = cx.promise();
|
||||||
|
let channel = cx.channel();
|
||||||
|
let query_vector = query_obj.get::<JsArray, _, _>(&mut cx, "_queryVector")?;
|
||||||
|
let query = convert::js_array_to_vec(query_vector.deref(), &mut cx);
|
||||||
|
let table = js_table.table.clone();
|
||||||
|
|
||||||
|
rt.spawn(async move {
|
||||||
|
let builder = table
|
||||||
|
.search(Float32Array::from(query))
|
||||||
|
.limit(limit as usize)
|
||||||
|
.refine_factor(refine_factor)
|
||||||
|
.nprobes(nprobes)
|
||||||
|
.filter(filter)
|
||||||
|
.metric_type(metric_type)
|
||||||
|
.select(select);
|
||||||
|
let record_batch_stream = builder.execute();
|
||||||
|
let results = record_batch_stream
|
||||||
|
.and_then(|stream| {
|
||||||
|
stream
|
||||||
|
.try_collect::<Vec<_>>()
|
||||||
|
.map_err(vectordb::error::Error::from)
|
||||||
|
})
|
||||||
|
.await;
|
||||||
|
|
||||||
|
deferred.settle_with(&channel, move |mut cx| {
|
||||||
|
let results = results.or_throw(&mut cx)?;
|
||||||
|
let buffer = record_batch_to_buffer(results).or_throw(&mut cx)?;
|
||||||
|
Self::new_js_buffer(buffer, &mut cx, is_electron)
|
||||||
|
});
|
||||||
|
});
|
||||||
|
Ok(promise)
|
||||||
|
}
|
||||||
|
|
||||||
|
// Creates a new JsBuffer from a rust buffer with a special logic for electron
|
||||||
|
fn new_js_buffer<'a>(
|
||||||
|
buffer: Vec<u8>,
|
||||||
|
cx: &mut TaskContext<'a>,
|
||||||
|
is_electron: bool,
|
||||||
|
) -> NeonResult<Handle<'a, JsBuffer>> {
|
||||||
|
if is_electron {
|
||||||
|
// Electron does not support `external`: https://github.com/neon-bindings/neon/pull/937
|
||||||
|
let mut js_buffer = JsBuffer::new(cx, buffer.len()).or_throw(cx)?;
|
||||||
|
let buffer_data = js_buffer.as_mut_slice(cx);
|
||||||
|
buffer_data.copy_from_slice(buffer.as_slice());
|
||||||
|
Ok(js_buffer)
|
||||||
|
} else {
|
||||||
|
Ok(JsBuffer::external(cx, buffer))
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
166
rust/ffi/node/src/table.rs
Normal file
166
rust/ffi/node/src/table.rs
Normal file
@@ -0,0 +1,166 @@
|
|||||||
|
// Copyright 2023 Lance Developers.
|
||||||
|
//
|
||||||
|
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
// you may not use this file except in compliance with the License.
|
||||||
|
// You may obtain a copy of the License at
|
||||||
|
//
|
||||||
|
// http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
//
|
||||||
|
// Unless required by applicable law or agreed to in writing, software
|
||||||
|
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
// See the License for the specific language governing permissions and
|
||||||
|
// limitations under the License.
|
||||||
|
|
||||||
|
use arrow_array::RecordBatchIterator;
|
||||||
|
use lance::dataset::{WriteMode, WriteParams};
|
||||||
|
use lance::io::object_store::ObjectStoreParams;
|
||||||
|
|
||||||
|
use crate::arrow::arrow_buffer_to_record_batch;
|
||||||
|
use neon::prelude::*;
|
||||||
|
use neon::types::buffer::TypedArray;
|
||||||
|
use vectordb::Table;
|
||||||
|
|
||||||
|
use crate::error::ResultExt;
|
||||||
|
use crate::{get_aws_creds, get_aws_region, runtime, JsDatabase};
|
||||||
|
|
||||||
|
pub(crate) struct JsTable {
|
||||||
|
pub table: Table,
|
||||||
|
}
|
||||||
|
|
||||||
|
impl Finalize for JsTable {}
|
||||||
|
|
||||||
|
impl From<Table> for JsTable {
|
||||||
|
fn from(table: Table) -> Self {
|
||||||
|
JsTable { table }
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
impl JsTable {
|
||||||
|
pub(crate) fn js_create(mut cx: FunctionContext) -> JsResult<JsPromise> {
|
||||||
|
let db = cx
|
||||||
|
.this()
|
||||||
|
.downcast_or_throw::<JsBox<JsDatabase>, _>(&mut cx)?;
|
||||||
|
let table_name = cx.argument::<JsString>(0)?.value(&mut cx);
|
||||||
|
let buffer = cx.argument::<JsBuffer>(1)?;
|
||||||
|
let (batches, schema) =
|
||||||
|
arrow_buffer_to_record_batch(buffer.as_slice(&mut cx)).or_throw(&mut cx)?;
|
||||||
|
|
||||||
|
// Write mode
|
||||||
|
let mode = match cx.argument::<JsString>(2)?.value(&mut cx).as_str() {
|
||||||
|
"overwrite" => WriteMode::Overwrite,
|
||||||
|
"append" => WriteMode::Append,
|
||||||
|
"create" => WriteMode::Create,
|
||||||
|
_ => {
|
||||||
|
return cx.throw_error("Table::create only supports 'overwrite' and 'create' modes")
|
||||||
|
}
|
||||||
|
};
|
||||||
|
|
||||||
|
let rt = runtime(&mut cx)?;
|
||||||
|
let channel = cx.channel();
|
||||||
|
|
||||||
|
let (deferred, promise) = cx.promise();
|
||||||
|
let database = db.database.clone();
|
||||||
|
|
||||||
|
let aws_creds = get_aws_creds(&mut cx, 3)?;
|
||||||
|
let aws_region = get_aws_region(&mut cx, 6)?;
|
||||||
|
|
||||||
|
let params = WriteParams {
|
||||||
|
store_params: Some(ObjectStoreParams::with_aws_credentials(
|
||||||
|
aws_creds, aws_region,
|
||||||
|
)),
|
||||||
|
mode: mode,
|
||||||
|
..WriteParams::default()
|
||||||
|
};
|
||||||
|
|
||||||
|
rt.spawn(async move {
|
||||||
|
let batch_reader = RecordBatchIterator::new(batches.into_iter().map(Ok), schema);
|
||||||
|
let table_rst = database
|
||||||
|
.create_table(&table_name, batch_reader, Some(params))
|
||||||
|
.await;
|
||||||
|
|
||||||
|
deferred.settle_with(&channel, move |mut cx| {
|
||||||
|
let table = table_rst.or_throw(&mut cx)?;
|
||||||
|
Ok(cx.boxed(JsTable::from(table)))
|
||||||
|
});
|
||||||
|
});
|
||||||
|
Ok(promise)
|
||||||
|
}
|
||||||
|
|
||||||
|
pub(crate) fn js_add(mut cx: FunctionContext) -> JsResult<JsPromise> {
|
||||||
|
let js_table = cx.this().downcast_or_throw::<JsBox<JsTable>, _>(&mut cx)?;
|
||||||
|
let buffer = cx.argument::<JsBuffer>(0)?;
|
||||||
|
let write_mode = cx.argument::<JsString>(1)?.value(&mut cx);
|
||||||
|
let (batches, schema) =
|
||||||
|
arrow_buffer_to_record_batch(buffer.as_slice(&mut cx)).or_throw(&mut cx)?;
|
||||||
|
let rt = runtime(&mut cx)?;
|
||||||
|
let channel = cx.channel();
|
||||||
|
let mut table = js_table.table.clone();
|
||||||
|
|
||||||
|
let (deferred, promise) = cx.promise();
|
||||||
|
let write_mode = match write_mode.as_str() {
|
||||||
|
"create" => WriteMode::Create,
|
||||||
|
"append" => WriteMode::Append,
|
||||||
|
"overwrite" => WriteMode::Overwrite,
|
||||||
|
s => return cx.throw_error(format!("invalid write mode {}", s)),
|
||||||
|
};
|
||||||
|
let aws_creds = get_aws_creds(&mut cx, 2)?;
|
||||||
|
let aws_region = get_aws_region(&mut cx, 5)?;
|
||||||
|
|
||||||
|
let params = WriteParams {
|
||||||
|
store_params: Some(ObjectStoreParams::with_aws_credentials(
|
||||||
|
aws_creds, aws_region,
|
||||||
|
)),
|
||||||
|
mode: write_mode,
|
||||||
|
..WriteParams::default()
|
||||||
|
};
|
||||||
|
|
||||||
|
rt.spawn(async move {
|
||||||
|
let batch_reader = RecordBatchIterator::new(batches.into_iter().map(Ok), schema);
|
||||||
|
let add_result = table.add(batch_reader, Some(params)).await;
|
||||||
|
|
||||||
|
deferred.settle_with(&channel, move |mut cx| {
|
||||||
|
let _added = add_result.or_throw(&mut cx)?;
|
||||||
|
Ok(cx.boxed(JsTable::from(table)))
|
||||||
|
});
|
||||||
|
});
|
||||||
|
Ok(promise)
|
||||||
|
}
|
||||||
|
|
||||||
|
pub(crate) fn js_count_rows(mut cx: FunctionContext) -> JsResult<JsPromise> {
|
||||||
|
let js_table = cx.this().downcast_or_throw::<JsBox<JsTable>, _>(&mut cx)?;
|
||||||
|
let rt = runtime(&mut cx)?;
|
||||||
|
let (deferred, promise) = cx.promise();
|
||||||
|
let channel = cx.channel();
|
||||||
|
let table = js_table.table.clone();
|
||||||
|
|
||||||
|
rt.spawn(async move {
|
||||||
|
let num_rows_result = table.count_rows().await;
|
||||||
|
|
||||||
|
deferred.settle_with(&channel, move |mut cx| {
|
||||||
|
let num_rows = num_rows_result.or_throw(&mut cx)?;
|
||||||
|
Ok(cx.number(num_rows as f64))
|
||||||
|
});
|
||||||
|
});
|
||||||
|
Ok(promise)
|
||||||
|
}
|
||||||
|
|
||||||
|
pub(crate) fn js_delete(mut cx: FunctionContext) -> JsResult<JsPromise> {
|
||||||
|
let js_table = cx.this().downcast_or_throw::<JsBox<JsTable>, _>(&mut cx)?;
|
||||||
|
let rt = runtime(&mut cx)?;
|
||||||
|
let (deferred, promise) = cx.promise();
|
||||||
|
let predicate = cx.argument::<JsString>(0)?.value(&mut cx);
|
||||||
|
let channel = cx.channel();
|
||||||
|
let mut table = js_table.table.clone();
|
||||||
|
|
||||||
|
rt.spawn(async move {
|
||||||
|
let delete_result = table.delete(&predicate).await;
|
||||||
|
|
||||||
|
deferred.settle_with(&channel, move |mut cx| {
|
||||||
|
delete_result.or_throw(&mut cx)?;
|
||||||
|
Ok(cx.boxed(JsTable::from(table)))
|
||||||
|
})
|
||||||
|
});
|
||||||
|
Ok(promise)
|
||||||
|
}
|
||||||
|
}
|
||||||
@@ -1,21 +1,30 @@
|
|||||||
[package]
|
[package]
|
||||||
name = "vectordb"
|
name = "vectordb"
|
||||||
version = "0.1.14"
|
version = "0.2.6"
|
||||||
edition = "2021"
|
edition = "2021"
|
||||||
description = "Serverless, low-latency vector database for AI applications"
|
description = "LanceDB: A serverless, low-latency vector database for AI applications"
|
||||||
license = "Apache-2.0"
|
license = "Apache-2.0"
|
||||||
repository = "https://github.com/lancedb/lancedb"
|
repository = "https://github.com/lancedb/lancedb"
|
||||||
|
keywords = ["lancedb", "lance", "database", "search"]
|
||||||
|
categories = ["database-implementations"]
|
||||||
|
|
||||||
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
|
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
|
||||||
[dependencies]
|
[dependencies]
|
||||||
|
arrow = { workspace = true }
|
||||||
arrow-array = { workspace = true }
|
arrow-array = { workspace = true }
|
||||||
arrow-data = { workspace = true }
|
arrow-data = { workspace = true }
|
||||||
arrow-schema = { workspace = true }
|
arrow-schema = { workspace = true }
|
||||||
|
arrow-ord = { workspace = true }
|
||||||
|
arrow-cast = { workspace = true }
|
||||||
object_store = { workspace = true }
|
object_store = { workspace = true }
|
||||||
snafu = "0.7.4"
|
snafu = { workspace = true }
|
||||||
half = { workspace = true }
|
half = { workspace = true }
|
||||||
lance = { workspace = true }
|
lance = { workspace = true }
|
||||||
|
lance-linalg = { workspace = true }
|
||||||
tokio = { version = "1.23", features = ["rt-multi-thread"] }
|
tokio = { version = "1.23", features = ["rt-multi-thread"] }
|
||||||
|
log = { workspace = true }
|
||||||
|
num-traits = "0"
|
||||||
|
url = { workspace = true }
|
||||||
|
|
||||||
[dev-dependencies]
|
[dev-dependencies]
|
||||||
tempfile = "3.5.0"
|
tempfile = "3.5.0"
|
||||||
|
|||||||
3
rust/vectordb/README.md
Normal file
3
rust/vectordb/README.md
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
# LanceDB Rust
|
||||||
|
|
||||||
|
Rust client for LanceDB, a serverless vector database. Read more at: https://lancedb.com/
|
||||||
15
rust/vectordb/src/arrow.rs
Normal file
15
rust/vectordb/src/arrow.rs
Normal file
@@ -0,0 +1,15 @@
|
|||||||
|
// Copyright 2023 Lance Developers.
|
||||||
|
//
|
||||||
|
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
// you may not use this file except in compliance with the License.
|
||||||
|
// You may obtain a copy of the License at
|
||||||
|
//
|
||||||
|
// http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
//
|
||||||
|
// Unless required by applicable law or agreed to in writing, software
|
||||||
|
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
// See the License for the specific language governing permissions and
|
||||||
|
// limitations under the License.
|
||||||
|
|
||||||
|
pub use lance::arrow::*;
|
||||||
18
rust/vectordb/src/data.rs
Normal file
18
rust/vectordb/src/data.rs
Normal file
@@ -0,0 +1,18 @@
|
|||||||
|
// Copyright 2023 Lance Developers.
|
||||||
|
//
|
||||||
|
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
// you may not use this file except in compliance with the License.
|
||||||
|
// You may obtain a copy of the License at
|
||||||
|
//
|
||||||
|
// http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
//
|
||||||
|
// Unless required by applicable law or agreed to in writing, software
|
||||||
|
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
// See the License for the specific language governing permissions and
|
||||||
|
// limitations under the License.
|
||||||
|
|
||||||
|
//! Data types, schema coercion, and data cleaning and etc.
|
||||||
|
|
||||||
|
pub mod inspect;
|
||||||
|
pub mod sanitize;
|
||||||
180
rust/vectordb/src/data/inspect.rs
Normal file
180
rust/vectordb/src/data/inspect.rs
Normal file
@@ -0,0 +1,180 @@
|
|||||||
|
// Copyright 2023 Lance Developers.
|
||||||
|
//
|
||||||
|
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
// you may not use this file except in compliance with the License.
|
||||||
|
// You may obtain a copy of the License at
|
||||||
|
//
|
||||||
|
// http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
//
|
||||||
|
// Unless required by applicable law or agreed to in writing, software
|
||||||
|
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
// See the License for the specific language governing permissions and
|
||||||
|
// limitations under the License.
|
||||||
|
|
||||||
|
use std::collections::HashMap;
|
||||||
|
|
||||||
|
use arrow::compute::kernels::{aggregate::bool_and, length::length};
|
||||||
|
use arrow_array::{
|
||||||
|
cast::AsArray,
|
||||||
|
types::{ArrowPrimitiveType, Int32Type, Int64Type},
|
||||||
|
Array, GenericListArray, OffsetSizeTrait, RecordBatchReader,
|
||||||
|
};
|
||||||
|
use arrow_ord::comparison::eq_dyn_scalar;
|
||||||
|
use arrow_schema::DataType;
|
||||||
|
use num_traits::{ToPrimitive, Zero};
|
||||||
|
|
||||||
|
use crate::error::{Error, Result};
|
||||||
|
|
||||||
|
pub(crate) fn infer_dimension<T: ArrowPrimitiveType>(
|
||||||
|
list_arr: &GenericListArray<T::Native>,
|
||||||
|
) -> Result<Option<T::Native>>
|
||||||
|
where
|
||||||
|
T::Native: OffsetSizeTrait + ToPrimitive,
|
||||||
|
{
|
||||||
|
let len_arr = length(list_arr)?;
|
||||||
|
if len_arr.is_empty() {
|
||||||
|
return Ok(Some(Zero::zero()));
|
||||||
|
}
|
||||||
|
|
||||||
|
let dim = len_arr.as_primitive::<T>().value(0);
|
||||||
|
if bool_and(&eq_dyn_scalar(len_arr.as_primitive::<T>(), dim)?) != Some(true) {
|
||||||
|
Ok(None)
|
||||||
|
} else {
|
||||||
|
Ok(Some(dim))
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
/// Infer the vector columns from a dataset.
|
||||||
|
///
|
||||||
|
/// Parameters
|
||||||
|
/// ----------
|
||||||
|
/// - reader: RecordBatchReader
|
||||||
|
/// - strict: if set true, only fixed_size_list<float> is considered as vector column. If set to false,
|
||||||
|
/// a list<float> column with same length is also considered as vector column.
|
||||||
|
pub fn infer_vector_columns(
|
||||||
|
reader: impl RecordBatchReader + Send,
|
||||||
|
strict: bool,
|
||||||
|
) -> Result<Vec<String>> {
|
||||||
|
let mut columns = vec![];
|
||||||
|
|
||||||
|
let mut columns_to_infer: HashMap<String, Option<i64>> = HashMap::new();
|
||||||
|
for field in reader.schema().fields() {
|
||||||
|
match field.data_type() {
|
||||||
|
DataType::FixedSizeList(sub_field, _) if sub_field.data_type().is_floating() => {
|
||||||
|
columns.push(field.name().to_string());
|
||||||
|
}
|
||||||
|
DataType::List(sub_field) if sub_field.data_type().is_floating() && !strict => {
|
||||||
|
columns_to_infer.insert(field.name().to_string(), None);
|
||||||
|
}
|
||||||
|
DataType::LargeList(sub_field) if sub_field.data_type().is_floating() && !strict => {
|
||||||
|
columns_to_infer.insert(field.name().to_string(), None);
|
||||||
|
}
|
||||||
|
_ => {}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
for batch in reader {
|
||||||
|
let batch = batch?;
|
||||||
|
let col_names = columns_to_infer.keys().cloned().collect::<Vec<_>>();
|
||||||
|
for col_name in col_names {
|
||||||
|
let col = batch.column_by_name(&col_name).ok_or(Error::Schema {
|
||||||
|
message: format!("Column {} not found", col_name),
|
||||||
|
})?;
|
||||||
|
if let Some(dim) = match *col.data_type() {
|
||||||
|
DataType::List(_) => {
|
||||||
|
infer_dimension::<Int32Type>(col.as_list::<i32>())?.map(|d| d as i64)
|
||||||
|
}
|
||||||
|
DataType::LargeList(_) => infer_dimension::<Int64Type>(col.as_list::<i64>())?,
|
||||||
|
_ => {
|
||||||
|
return Err(Error::Schema {
|
||||||
|
message: format!("Column {} is not a list", col_name),
|
||||||
|
})
|
||||||
|
}
|
||||||
|
} {
|
||||||
|
if let Some(Some(prev_dim)) = columns_to_infer.get(&col_name) {
|
||||||
|
if prev_dim != &dim {
|
||||||
|
columns_to_infer.remove(&col_name);
|
||||||
|
}
|
||||||
|
} else {
|
||||||
|
columns_to_infer.insert(col_name, Some(dim));
|
||||||
|
}
|
||||||
|
} else {
|
||||||
|
columns_to_infer.remove(&col_name);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
columns.extend(columns_to_infer.keys().cloned());
|
||||||
|
Ok(columns)
|
||||||
|
}
|
||||||
|
|
||||||
|
#[cfg(test)]
|
||||||
|
mod tests {
|
||||||
|
use super::*;
|
||||||
|
|
||||||
|
use arrow_array::{
|
||||||
|
types::{Float32Type, Float64Type},
|
||||||
|
FixedSizeListArray, Float32Array, ListArray, RecordBatch, RecordBatchIterator, StringArray,
|
||||||
|
};
|
||||||
|
use arrow_schema::{DataType, Field, Schema};
|
||||||
|
use std::{sync::Arc, vec};
|
||||||
|
|
||||||
|
#[test]
|
||||||
|
fn test_infer_vector_columns() {
|
||||||
|
let schema = Arc::new(Schema::new(vec![
|
||||||
|
Field::new("f", DataType::Float32, false),
|
||||||
|
Field::new("s", DataType::Utf8, false),
|
||||||
|
Field::new(
|
||||||
|
"l1",
|
||||||
|
DataType::List(Arc::new(Field::new("item", DataType::Float32, true))),
|
||||||
|
false,
|
||||||
|
),
|
||||||
|
Field::new(
|
||||||
|
"l2",
|
||||||
|
DataType::List(Arc::new(Field::new("item", DataType::Float64, true))),
|
||||||
|
false,
|
||||||
|
),
|
||||||
|
Field::new(
|
||||||
|
"fl",
|
||||||
|
DataType::FixedSizeList(Arc::new(Field::new("item", DataType::Float32, true)), 32),
|
||||||
|
true,
|
||||||
|
),
|
||||||
|
]));
|
||||||
|
|
||||||
|
let batch = RecordBatch::try_new(
|
||||||
|
schema.clone(),
|
||||||
|
vec![
|
||||||
|
Arc::new(Float32Array::from(vec![1.0, 2.0, 3.0])),
|
||||||
|
Arc::new(StringArray::from(vec!["a", "b", "c"])),
|
||||||
|
Arc::new(ListArray::from_iter_primitive::<Float32Type, _, _>(
|
||||||
|
(0..3).map(|_| Some(vec![Some(1.0), Some(2.0), Some(3.0), Some(4.0)])),
|
||||||
|
)),
|
||||||
|
// Var-length list
|
||||||
|
Arc::new(ListArray::from_iter_primitive::<Float64Type, _, _>(vec![
|
||||||
|
Some(vec![Some(1.0_f64)]),
|
||||||
|
Some(vec![Some(2.0_f64), Some(3.0_f64)]),
|
||||||
|
Some(vec![Some(4.0_f64), Some(5.0_f64), Some(6.0_f64)]),
|
||||||
|
])),
|
||||||
|
Arc::new(
|
||||||
|
FixedSizeListArray::from_iter_primitive::<Float32Type, _, _>(
|
||||||
|
vec![
|
||||||
|
Some(vec![Some(1.0); 32]),
|
||||||
|
Some(vec![Some(2.0); 32]),
|
||||||
|
Some(vec![Some(3.0); 32]),
|
||||||
|
],
|
||||||
|
32,
|
||||||
|
),
|
||||||
|
),
|
||||||
|
],
|
||||||
|
)
|
||||||
|
.unwrap();
|
||||||
|
let reader =
|
||||||
|
RecordBatchIterator::new(vec![batch.clone()].into_iter().map(Ok), schema.clone());
|
||||||
|
|
||||||
|
let cols = infer_vector_columns(reader, false).unwrap();
|
||||||
|
assert_eq!(cols, vec!["fl", "l1"]);
|
||||||
|
|
||||||
|
let reader = RecordBatchIterator::new(vec![batch].into_iter().map(Ok), schema);
|
||||||
|
let cols = infer_vector_columns(reader, true).unwrap();
|
||||||
|
assert_eq!(cols, vec!["fl"]);
|
||||||
|
}
|
||||||
|
}
|
||||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user