mirror of
https://github.com/lancedb/lancedb.git
synced 2026-06-23 14:10:39 +00:00
Compare commits
35 Commits
python-v0.
...
yang/upgra
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
d8d3d712d6 | ||
|
|
a98ea8bb53 | ||
|
|
aaff43d304 | ||
|
|
d4c3a8ca87 | ||
|
|
ff5bbfdd4c | ||
|
|
694ca30c7c | ||
|
|
b2317c904d | ||
|
|
613f3063b9 | ||
|
|
5d2cd7fb2e | ||
|
|
a88e9bb134 | ||
|
|
9c1adff426 | ||
|
|
f9d5fa88a1 | ||
|
|
4db554eea5 | ||
|
|
101066788d | ||
|
|
c4135d9d30 | ||
|
|
ec39d98571 | ||
|
|
0cb37f0e5e | ||
|
|
24e3507ee2 | ||
|
|
2bdf0a02f9 | ||
|
|
32123713fd | ||
|
|
d5a01ffe7b | ||
|
|
e01045692c | ||
|
|
a62f661d90 | ||
|
|
4769d8eb76 | ||
|
|
d07d7a5980 | ||
|
|
8d2ff7b210 | ||
|
|
61c05b51a0 | ||
|
|
7801ab9b8b | ||
|
|
d297da5a7e | ||
|
|
6af69b57ad | ||
|
|
a062a92f6b | ||
|
|
277b753fd8 | ||
|
|
f78b7863f6 | ||
|
|
e7d824af2b | ||
|
|
02f1ec775f |
@@ -1,5 +1,5 @@
|
||||
[tool.bumpversion]
|
||||
current_version = "0.7.2"
|
||||
current_version = "0.10.0-beta.0"
|
||||
parse = """(?x)
|
||||
(?P<major>0|[1-9]\\d*)\\.
|
||||
(?P<minor>0|[1-9]\\d*)\\.
|
||||
|
||||
48
.github/workflows/java.yml
vendored
48
.github/workflows/java.yml
vendored
@@ -3,6 +3,8 @@ on:
|
||||
push:
|
||||
branches:
|
||||
- main
|
||||
paths:
|
||||
- java/**
|
||||
pull_request:
|
||||
paths:
|
||||
- java/**
|
||||
@@ -21,9 +23,42 @@ env:
|
||||
CARGO_INCREMENTAL: "0"
|
||||
CARGO_BUILD_JOBS: "1"
|
||||
jobs:
|
||||
linux-build:
|
||||
linux-build-java-11:
|
||||
runs-on: ubuntu-22.04
|
||||
name: ubuntu-22.04 + Java 11 & 17
|
||||
name: ubuntu-22.04 + Java 11
|
||||
defaults:
|
||||
run:
|
||||
working-directory: ./java
|
||||
steps:
|
||||
- name: Checkout repository
|
||||
uses: actions/checkout@v4
|
||||
- uses: Swatinem/rust-cache@v2
|
||||
with:
|
||||
workspaces: java/core/lancedb-jni
|
||||
- name: Run cargo fmt
|
||||
run: cargo fmt --check
|
||||
working-directory: ./java/core/lancedb-jni
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
sudo apt update
|
||||
sudo apt install -y protobuf-compiler libssl-dev
|
||||
- name: Install Java 11
|
||||
uses: actions/setup-java@v4
|
||||
with:
|
||||
distribution: temurin
|
||||
java-version: 11
|
||||
cache: "maven"
|
||||
- name: Java Style Check
|
||||
run: mvn checkstyle:check
|
||||
# Disable because of issues in lancedb rust core code
|
||||
# - name: Rust Clippy
|
||||
# working-directory: java/core/lancedb-jni
|
||||
# run: cargo clippy --all-targets -- -D warnings
|
||||
- name: Running tests with Java 11
|
||||
run: mvn clean test
|
||||
linux-build-java-17:
|
||||
runs-on: ubuntu-22.04
|
||||
name: ubuntu-22.04 + Java 17
|
||||
defaults:
|
||||
run:
|
||||
working-directory: ./java
|
||||
@@ -47,20 +82,12 @@ jobs:
|
||||
java-version: 17
|
||||
cache: "maven"
|
||||
- run: echo "JAVA_17=$JAVA_HOME" >> $GITHUB_ENV
|
||||
- name: Install Java 11
|
||||
uses: actions/setup-java@v4
|
||||
with:
|
||||
distribution: temurin
|
||||
java-version: 11
|
||||
cache: "maven"
|
||||
- name: Java Style Check
|
||||
run: mvn checkstyle:check
|
||||
# Disable because of issues in lancedb rust core code
|
||||
# - name: Rust Clippy
|
||||
# working-directory: java/core/lancedb-jni
|
||||
# run: cargo clippy --all-targets -- -D warnings
|
||||
- name: Running tests with Java 11
|
||||
run: mvn clean test
|
||||
- name: Running tests with Java 17
|
||||
run: |
|
||||
export JAVA_TOOL_OPTIONS="$JAVA_TOOL_OPTIONS \
|
||||
@@ -83,3 +110,4 @@ jobs:
|
||||
-Djdk.reflect.useDirectMethodHandle=false \
|
||||
-Dio.netty.tryReflectionSetAccessible=true"
|
||||
JAVA_HOME=$JAVA_17 mvn clean test
|
||||
|
||||
|
||||
31
Cargo.toml
31
Cargo.toml
@@ -20,20 +20,23 @@ keywords = ["lancedb", "lance", "database", "vector", "search"]
|
||||
categories = ["database-implementations"]
|
||||
|
||||
[workspace.dependencies]
|
||||
lance = { "version" = "=0.15.0", "features" = ["dynamodb"] }
|
||||
lance-index = { "version" = "=0.15.0" }
|
||||
lance-linalg = { "version" = "=0.15.0" }
|
||||
lance-testing = { "version" = "=0.15.0" }
|
||||
lance-datafusion = { "version" = "=0.15.0" }
|
||||
lance = { "version" = "=0.17.0", "features" = [
|
||||
"dynamodb",
|
||||
], git = "https://github.com/lancedb/lance.git", tag = "v0.17.0-beta.2" }
|
||||
lance-index = { "version" = "=0.17.0", git = "https://github.com/lancedb/lance.git", tag = "v0.17.0-beta.2" }
|
||||
lance-linalg = { "version" = "=0.17.0", git = "https://github.com/lancedb/lance.git", tag = "v0.17.0-beta.2" }
|
||||
lance-testing = { "version" = "=0.17.0", git = "https://github.com/lancedb/lance.git", tag = "v0.17.0-beta.2" }
|
||||
lance-datafusion = { "version" = "=0.17.0", git = "https://github.com/lancedb/lance.git", tag = "v0.17.0-beta.2" }
|
||||
lance-encoding = { "version" = "=0.17.0", git = "https://github.com/lancedb/lance.git", tag = "v0.17.0-beta.2" }
|
||||
# Note that this one does not include pyarrow
|
||||
arrow = { version = "52.1", optional = false }
|
||||
arrow-array = "52.1"
|
||||
arrow-data = "52.1"
|
||||
arrow-ipc = "52.1"
|
||||
arrow-ord = "52.1"
|
||||
arrow-schema = "52.1"
|
||||
arrow-arith = "52.1"
|
||||
arrow-cast = "52.1"
|
||||
arrow = { version = "52.2", optional = false }
|
||||
arrow-array = "52.2"
|
||||
arrow-data = "52.2"
|
||||
arrow-ipc = "52.2"
|
||||
arrow-ord = "52.2"
|
||||
arrow-schema = "52.2"
|
||||
arrow-arith = "52.2"
|
||||
arrow-cast = "52.2"
|
||||
async-trait = "0"
|
||||
chrono = "0.4.35"
|
||||
datafusion-physical-plan = "40.0"
|
||||
@@ -42,7 +45,7 @@ half = { "version" = "=2.4.1", default-features = false, features = [
|
||||
] }
|
||||
futures = "0"
|
||||
log = "0.4"
|
||||
object_store = "0.10.1"
|
||||
object_store = "0.10.2"
|
||||
pin-project = "1.0.7"
|
||||
snafu = "0.7.4"
|
||||
url = "2"
|
||||
|
||||
@@ -18,4 +18,4 @@ docker run \
|
||||
-v $(pwd):/io -w /io \
|
||||
--memory-swap=-1 \
|
||||
lancedb-node-manylinux \
|
||||
bash ci/manylinux_node/build.sh $ARCH
|
||||
bash ci/manylinux_node/build_vectordb.sh $ARCH
|
||||
|
||||
@@ -4,9 +4,9 @@ ARCH=${1:-x86_64}
|
||||
|
||||
# We pass down the current user so that when we later mount the local files
|
||||
# into the container, the files are accessible by the current user.
|
||||
pushd ci/manylinux_nodejs
|
||||
pushd ci/manylinux_node
|
||||
docker build \
|
||||
-t lancedb-nodejs-manylinux \
|
||||
-t lancedb-node-manylinux-$ARCH \
|
||||
--build-arg="ARCH=$ARCH" \
|
||||
--build-arg="DOCKER_USER=$(id -u)" \
|
||||
--progress=plain \
|
||||
@@ -17,5 +17,5 @@ popd
|
||||
docker run \
|
||||
-v $(pwd):/io -w /io \
|
||||
--memory-swap=-1 \
|
||||
lancedb-nodejs-manylinux \
|
||||
bash ci/manylinux_nodejs/build.sh $ARCH
|
||||
lancedb-node-manylinux-$ARCH \
|
||||
bash ci/manylinux_node/build_lancedb.sh $ARCH
|
||||
|
||||
@@ -4,7 +4,7 @@
|
||||
# range of linux distributions.
|
||||
ARG ARCH=x86_64
|
||||
|
||||
FROM quay.io/pypa/manylinux2014_${ARCH}
|
||||
FROM quay.io/pypa/manylinux_2_28_${ARCH}
|
||||
|
||||
ARG ARCH=x86_64
|
||||
ARG DOCKER_USER=default_user
|
||||
|
||||
0
ci/manylinux_nodejs/build.sh → ci/manylinux_node/build_lancedb.sh
Executable file → Normal file
0
ci/manylinux_nodejs/build.sh → ci/manylinux_node/build_lancedb.sh
Executable file → Normal file
@@ -6,7 +6,7 @@
|
||||
# /usr/bin/ld: failed to set dynamic section sizes: Bad value
|
||||
set -e
|
||||
|
||||
git clone -b OpenSSL_1_1_1u \
|
||||
git clone -b OpenSSL_1_1_1v \
|
||||
--single-branch \
|
||||
https://github.com/openssl/openssl.git
|
||||
|
||||
|
||||
@@ -8,7 +8,7 @@ install_node() {
|
||||
|
||||
source "$HOME"/.bashrc
|
||||
|
||||
nvm install --no-progress 16
|
||||
nvm install --no-progress 18
|
||||
}
|
||||
|
||||
install_rust() {
|
||||
|
||||
@@ -1,31 +0,0 @@
|
||||
# Many linux dockerfile with Rust, Node, and Lance dependencies installed.
|
||||
# This container allows building the node modules native libraries in an
|
||||
# environment with a very old glibc, so that we are compatible with a wide
|
||||
# range of linux distributions.
|
||||
ARG ARCH=x86_64
|
||||
|
||||
FROM quay.io/pypa/manylinux2014_${ARCH}
|
||||
|
||||
ARG ARCH=x86_64
|
||||
ARG DOCKER_USER=default_user
|
||||
|
||||
# Install static openssl
|
||||
COPY install_openssl.sh install_openssl.sh
|
||||
RUN ./install_openssl.sh ${ARCH} > /dev/null
|
||||
|
||||
# Protobuf is also installed as root.
|
||||
COPY install_protobuf.sh install_protobuf.sh
|
||||
RUN ./install_protobuf.sh ${ARCH}
|
||||
|
||||
ENV DOCKER_USER=${DOCKER_USER}
|
||||
# Create a group and user
|
||||
RUN echo ${ARCH} && adduser --user-group --create-home --uid ${DOCKER_USER} build_user
|
||||
|
||||
# We switch to the user to install Rust and Node, since those like to be
|
||||
# installed at the user level.
|
||||
USER ${DOCKER_USER}
|
||||
|
||||
COPY prepare_manylinux_node.sh prepare_manylinux_node.sh
|
||||
RUN cp /prepare_manylinux_node.sh $HOME/ && \
|
||||
cd $HOME && \
|
||||
./prepare_manylinux_node.sh ${ARCH}
|
||||
@@ -1,26 +0,0 @@
|
||||
#!/bin/bash
|
||||
# Builds openssl from source so we can statically link to it
|
||||
|
||||
# this is to avoid the error we get with the system installation:
|
||||
# /usr/bin/ld: <library>: version node not found for symbol SSLeay@@OPENSSL_1.0.1
|
||||
# /usr/bin/ld: failed to set dynamic section sizes: Bad value
|
||||
set -e
|
||||
|
||||
git clone -b OpenSSL_1_1_1u \
|
||||
--single-branch \
|
||||
https://github.com/openssl/openssl.git
|
||||
|
||||
pushd openssl
|
||||
|
||||
if [[ $1 == x86_64* ]]; then
|
||||
ARCH=linux-x86_64
|
||||
else
|
||||
# gnu target
|
||||
ARCH=linux-aarch64
|
||||
fi
|
||||
|
||||
./Configure no-shared $ARCH
|
||||
|
||||
make
|
||||
|
||||
make install
|
||||
@@ -1,15 +0,0 @@
|
||||
#!/bin/bash
|
||||
# Installs protobuf compiler. Should be run as root.
|
||||
set -e
|
||||
|
||||
if [[ $1 == x86_64* ]]; then
|
||||
ARCH=x86_64
|
||||
else
|
||||
# gnu target
|
||||
ARCH=aarch_64
|
||||
fi
|
||||
|
||||
PB_REL=https://github.com/protocolbuffers/protobuf/releases
|
||||
PB_VERSION=23.1
|
||||
curl -LO $PB_REL/download/v$PB_VERSION/protoc-$PB_VERSION-linux-$ARCH.zip
|
||||
unzip protoc-$PB_VERSION-linux-$ARCH.zip -d /usr/local
|
||||
@@ -1,21 +0,0 @@
|
||||
#!/bin/bash
|
||||
set -e
|
||||
|
||||
install_node() {
|
||||
echo "Installing node..."
|
||||
|
||||
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.34.0/install.sh | bash
|
||||
|
||||
source "$HOME"/.bashrc
|
||||
|
||||
nvm install --no-progress 16
|
||||
}
|
||||
|
||||
install_rust() {
|
||||
echo "Installing rust..."
|
||||
curl https://sh.rustup.rs -sSf | bash -s -- -y
|
||||
export PATH="$PATH:/root/.cargo/bin"
|
||||
}
|
||||
|
||||
install_node
|
||||
install_rust
|
||||
@@ -141,12 +141,15 @@ nav:
|
||||
- Overview: examples/index.md
|
||||
- 🐍 Python:
|
||||
- Overview: examples/examples_python.md
|
||||
- YouTube Transcript Search: notebooks/youtube_transcript_search.ipynb
|
||||
- Documentation QA Bot using LangChain: notebooks/code_qa_bot.ipynb
|
||||
- Multimodal search using CLIP: notebooks/multimodal_search.ipynb
|
||||
- Example - Calculate CLIP Embeddings with Roboflow Inference: examples/image_embeddings_roboflow.md
|
||||
- Serverless QA Bot with S3 and Lambda: examples/serverless_lancedb_with_s3_and_lambda.md
|
||||
- Serverless QA Bot with Modal: examples/serverless_qa_bot_with_modal_and_langchain.md
|
||||
- Build From Scratch: examples/python_examples/build_from_scratch.md
|
||||
- Multimodal: examples/python_examples/multimodal.md
|
||||
- Rag: examples/python_examples/rag.md
|
||||
- Miscellaneous:
|
||||
- YouTube Transcript Search: notebooks/youtube_transcript_search.ipynb
|
||||
- Documentation QA Bot using LangChain: notebooks/code_qa_bot.ipynb
|
||||
- Multimodal search using CLIP: notebooks/multimodal_search.ipynb
|
||||
- Serverless QA Bot with S3 and Lambda: examples/serverless_lancedb_with_s3_and_lambda.md
|
||||
- Serverless QA Bot with Modal: examples/serverless_qa_bot_with_modal_and_langchain.md
|
||||
- 👾 JavaScript:
|
||||
- Overview: examples/examples_js.md
|
||||
- Serverless Website Chatbot: examples/serverless_website_chatbot.md
|
||||
@@ -221,14 +224,24 @@ nav:
|
||||
- PromptTools: integrations/prompttools.md
|
||||
- Examples:
|
||||
- examples/index.md
|
||||
- YouTube Transcript Search: notebooks/youtube_transcript_search.ipynb
|
||||
- Documentation QA Bot using LangChain: notebooks/code_qa_bot.ipynb
|
||||
- Multimodal search using CLIP: notebooks/multimodal_search.ipynb
|
||||
- Serverless QA Bot with S3 and Lambda: examples/serverless_lancedb_with_s3_and_lambda.md
|
||||
- Serverless QA Bot with Modal: examples/serverless_qa_bot_with_modal_and_langchain.md
|
||||
- YouTube Transcript Search (JS): examples/youtube_transcript_bot_with_nodejs.md
|
||||
- Serverless Chatbot from any website: examples/serverless_website_chatbot.md
|
||||
- TransformersJS Embedding Search: examples/transformerjs_embedding_search_nodejs.md
|
||||
- 🐍 Python:
|
||||
- Overview: examples/examples_python.md
|
||||
- Build From Scratch: examples/python_examples/build_from_scratch.md
|
||||
- Multimodal: examples/python_examples/multimodal.md
|
||||
- Rag: examples/python_examples/rag.md
|
||||
- Miscellaneous:
|
||||
- YouTube Transcript Search: notebooks/youtube_transcript_search.ipynb
|
||||
- Documentation QA Bot using LangChain: notebooks/code_qa_bot.ipynb
|
||||
- Multimodal search using CLIP: notebooks/multimodal_search.ipynb
|
||||
- Serverless QA Bot with S3 and Lambda: examples/serverless_lancedb_with_s3_and_lambda.md
|
||||
- Serverless QA Bot with Modal: examples/serverless_qa_bot_with_modal_and_langchain.md
|
||||
- 👾 JavaScript:
|
||||
- Overview: examples/examples_js.md
|
||||
- Serverless Website Chatbot: examples/serverless_website_chatbot.md
|
||||
- YouTube Transcript Search: examples/youtube_transcript_bot_with_nodejs.md
|
||||
- TransformersJS Embedding Search: examples/transformerjs_embedding_search_nodejs.md
|
||||
- 🦀 Rust:
|
||||
- Overview: examples/examples_rust.md
|
||||
- API reference:
|
||||
- Overview: api_reference.md
|
||||
- Python: python/python.md
|
||||
|
||||
1
docs/src/assets/colab.svg
Normal file
1
docs/src/assets/colab.svg
Normal file
{kind=link}
@@ -0,0 +1 @@
|
||||
<svg xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" width="117" height="20"><linearGradient id="b" x2="0" y2="100%"><stop offset="0" stop-color="#bbb" stop-opacity=".1"/><stop offset="1" stop-opacity=".1"/></linearGradient><clipPath id="a"><rect width="117" height="20" rx="3" fill="#fff"/></clipPath><g clip-path="url(#a)"><path fill="#555" d="M0 0h30v20H0z"/><path fill="#007ec6" d="M30 0h87v20H30z"/><path fill="url(#b)" d="M0 0h117v20H0z"/></g><g fill="#fff" text-anchor="middle" font-family="DejaVu Sans,Verdana,Geneva,sans-serif" font-size="110"><svg x="4px" y="0px" width="22px" height="20px" viewBox="-2 0 28 24" style="background-color: #fff;border-radius: 1px;"><path style="fill:#e8710a;" d="M1.977,16.77c-2.667-2.277-2.605-7.079,0-9.357C2.919,8.057,3.522,9.075,4.49,9.691c-1.152,1.6-1.146,3.201-0.004,4.803C3.522,15.111,2.918,16.126,1.977,16.77z"/><path style="fill:#f9ab00;" d="M12.257,17.114c-1.767-1.633-2.485-3.658-2.118-6.02c0.451-2.91,2.139-4.893,4.946-5.678c2.565-0.718,4.964-0.217,6.878,1.819c-0.884,0.743-1.707,1.547-2.434,2.446C18.488,8.827,17.319,8.435,16,8.856c-2.404,0.767-3.046,3.241-1.494,5.644c-0.241,0.275-0.493,0.541-0.721,0.826C13.295,15.939,12.511,16.3,12.257,17.114z"/><path style="fill:#e8710a;" d="M19.529,9.682c0.727-0.899,1.55-1.703,2.434-2.446c2.703,2.783,2.701,7.031-0.005,9.764c-2.648,2.674-6.936,2.725-9.701,0.115c0.254-0.814,1.038-1.175,1.528-1.788c0.228-0.285,0.48-0.552,0.721-0.826c1.053,0.916,2.254,1.268,3.6,0.83C20.502,14.551,21.151,11.927,19.529,9.682z"/><path style="fill:#f9ab00;" d="M4.49,9.691C3.522,9.075,2.919,8.057,1.977,7.413c2.209-2.398,5.721-2.942,8.476-1.355c0.555,0.32,0.719,0.606,0.285,1.128c-0.157,0.188-0.258,0.422-0.391,0.631c-0.299,0.47-0.509,1.067-0.929,1.371C8.933,9.539,8.523,8.847,8.021,8.746C6.673,8.475,5.509,8.787,4.49,9.691z"/><path style="fill:#f9ab00;" d="M1.977,16.77c0.941-0.644,1.545-1.659,2.509-2.277c1.373,1.152,2.85,1.433,4.45,0.499c0.332-0.194,0.503-0.088,0.673,0.19c0.386,0.635,0.753,1.285,1.181,1.89c0.34,0.48,0.222,0.715-0.253,1.006C7.84,19.73,4.205,19.188,1.977,16.77z"/></svg><text x="245" y="140" transform="scale(.1)" textLength="30"> </text><text x="725" y="150" fill="#010101" fill-opacity=".3" transform="scale(.1)" textLength="770">Open in Colab</text><text x="725" y="140" transform="scale(.1)" textLength="770">Open in Colab</text></g> </svg>
|
||||
|
After Width: | Height: | Size: 2.3 KiB |
1
docs/src/assets/ghost.svg
Normal file
1
docs/src/assets/ghost.svg
Normal file
{kind=link}
@@ -0,0 +1 @@
|
||||
<svg xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" width="88.25" height="28" role="img" aria-label="GHOST"><title>GHOST</title><g shape-rendering="crispEdges"><rect width="88.25" height="28" fill="#000"/></g><g fill="#fff" text-anchor="middle" font-family="Verdana,Geneva,DejaVu Sans,sans-serif" text-rendering="geometricPrecision" font-size="100"><image x="9" y="7" width="14" height="14" xlink:href="data:image/svg+xml;base64,PHN2ZyBmaWxsPSIjZjdkZjFlIiByb2xlPSJpbWciIHZpZXdCb3g9IjAgMCAyNCAyNCIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj48dGl0bGU+R2hvc3Q8L3RpdGxlPjxwYXRoIGQ9Ik0xMiAwQzUuMzczIDAgMCA1LjM3MyAwIDEyczUuMzczIDEyIDEyIDEyIDEyLTUuMzczIDEyLTEyUzE4LjYyNyAwIDEyIDB6bS4yNTYgMi4zMTNjMi40Ny4wMDUgNS4xMTYgMi4wMDggNS44OTggMi45NjJsLjI0NC4zYzEuNjQgMS45OTQgMy41NjkgNC4zNCAzLjU2OSA2Ljk2NiAwIDMuNzE5LTIuOTggNS44MDgtNi4xNTggNy41MDgtMS40MzMuNzY2LTIuOTggMS41MDgtNC43NDggMS41MDgtNC41NDMgMC04LjM2Ni0zLjU2OS04LjM2Ni04LjExMiAwLS43MDYuMTctMS40MjUuMzQyLTIuMTUuMTIyLS41MTUuMjQ0LTEuMDMzLjMwNy0xLjU0OS41NDgtNC41MzkgMi45NjctNi43OTUgOC40MjItNy40MDhhNC4yOSA0LjI5IDAgMDEuNDktLjAyNloiLz48L3N2Zz4="/><text transform="scale(.1)" x="541.25" y="175" textLength="442.5" fill="#fff" font-weight="bold">GHOST</text></g></svg>
|
||||
|
After Width: | Height: | Size: 1.2 KiB |
1
docs/src/assets/github.svg
Normal file
1
docs/src/assets/github.svg
Normal file
{kind=link}
@@ -0,0 +1 @@
|
||||
<svg xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" width="95.5" height="28" role="img" aria-label="GITHUB"><title>GITHUB</title><g shape-rendering="crispEdges"><rect width="95.5" height="28" fill="#121011"/></g><g fill="#fff" text-anchor="middle" font-family="Verdana,Geneva,DejaVu Sans,sans-serif" text-rendering="geometricPrecision" font-size="100"><image x="9" y="7" width="14" height="14" xlink:href="data:image/svg+xml;base64,PHN2ZyBmaWxsPSJ3aGl0ZSIgcm9sZT0iaW1nIiB2aWV3Qm94PSIwIDAgMjQgMjQiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+PHRpdGxlPkdpdEh1YjwvdGl0bGU+PHBhdGggZD0iTTEyIC4yOTdjLTYuNjMgMC0xMiA1LjM3My0xMiAxMiAwIDUuMzAzIDMuNDM4IDkuOCA4LjIwNSAxMS4zODUuNi4xMTMuODItLjI1OC44Mi0uNTc3IDAtLjI4NS0uMDEtMS4wNC0uMDE1LTIuMDQtMy4zMzguNzI0LTQuMDQyLTEuNjEtNC4wNDItMS42MUM0LjQyMiAxOC4wNyAzLjYzMyAxNy43IDMuNjMzIDE3LjdjLTEuMDg3LS43NDQuMDg0LS43MjkuMDg0LS43MjkgMS4yMDUuMDg0IDEuODM4IDEuMjM2IDEuODM4IDEuMjM2IDEuMDcgMS44MzUgMi44MDkgMS4zMDUgMy40OTUuOTk4LjEwOC0uNzc2LjQxNy0xLjMwNS43Ni0xLjYwNS0yLjY2NS0uMy01LjQ2Ni0xLjMzMi01LjQ2Ni01LjkzIDAtMS4zMS40NjUtMi4zOCAxLjIzNS0zLjIyLS4xMzUtLjMwMy0uNTQtMS41MjMuMTA1LTMuMTc2IDAgMCAxLjAwNS0uMzIyIDMuMyAxLjIzLjk2LS4yNjcgMS45OC0uMzk5IDMtLjQwNSAxLjAyLjAwNiAyLjA0LjEzOCAzIC40MDUgMi4yOC0xLjU1MiAzLjI4NS0xLjIzIDMuMjg1LTEuMjMuNjQ1IDEuNjUzLjI0IDIuODczLjEyIDMuMTc2Ljc2NS44NCAxLjIzIDEuOTEgMS4yMyAzLjIyIDAgNC42MS0yLjgwNSA1LjYyNS01LjQ3NSA1LjkyLjQyLjM2LjgxIDEuMDk2LjgxIDIuMjIgMCAxLjYwNi0uMDE1IDIuODk2LS4wMTUgMy4yODYgMCAuMzE1LjIxLjY5LjgyNS41N0MyMC41NjUgMjIuMDkyIDI0IDE3LjU5MiAyNCAxMi4yOTdjMC02LjYyNy01LjM3My0xMi0xMi0xMiIvPjwvc3ZnPg=="/><text transform="scale(.1)" x="577.5" y="175" textLength="515" fill="#fff" font-weight="bold">GITHUB</text></g></svg>
|
||||
|
After Width: | Height: | Size: 1.7 KiB |
1
docs/src/assets/python.svg
Normal file
1
docs/src/assets/python.svg
Normal file
{kind=link}
@@ -0,0 +1 @@
|
||||
<svg xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" width="97.5" height="28" role="img" aria-label="PYTHON"><title>PYTHON</title><g shape-rendering="crispEdges"><rect width="97.5" height="28" fill="#3670a0"/></g><g fill="#fff" text-anchor="middle" font-family="Verdana,Geneva,DejaVu Sans,sans-serif" text-rendering="geometricPrecision" font-size="100"><image x="9" y="7" width="14" height="14" xlink:href="data:image/svg+xml;base64,PHN2ZyBmaWxsPSIjZmZkZDU0IiByb2xlPSJpbWciIHZpZXdCb3g9IjAgMCAyNCAyNCIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj48dGl0bGU+UHl0aG9uPC90aXRsZT48cGF0aCBkPSJNMTQuMjUuMThsLjkuMi43My4yNi41OS4zLjQ1LjMyLjM0LjM0LjI1LjM0LjE2LjMzLjEuMy4wNC4yNi4wMi4yLS4wMS4xM1Y4LjVsLS4wNS42My0uMTMuNTUtLjIxLjQ2LS4yNi4zOC0uMy4zMS0uMzMuMjUtLjM1LjE5LS4zNS4xNC0uMzMuMS0uMy4wNy0uMjYuMDQtLjIxLjAySDguNzdsLS42OS4wNS0uNTkuMTQtLjUuMjItLjQxLjI3LS4zMy4zMi0uMjcuMzUtLjIuMzYtLjE1LjM3LS4xLjM1LS4wNy4zMi0uMDQuMjctLjAyLjIxdjMuMDZIMy4xN2wtLjIxLS4wMy0uMjgtLjA3LS4zMi0uMTItLjM1LS4xOC0uMzYtLjI2LS4zNi0uMzYtLjM1LS40Ni0uMzItLjU5LS4yOC0uNzMtLjIxLS44OC0uMTQtMS4wNS0uMDUtMS4yMy4wNi0xLjIyLjE2LTEuMDQuMjQtLjg3LjMyLS43MS4zNi0uNTcuNC0uNDQuNDItLjMzLjQyLS4yNC40LS4xNi4zNi0uMS4zMi0uMDUuMjQtLjAxaC4xNmwuMDYuMDFoOC4xNnYtLjgzSDYuMThsLS4wMS0yLjc1LS4wMi0uMzcuMDUtLjM0LjExLS4zMS4xNy0uMjguMjUtLjI2LjMxLS4yMy4zOC0uMi40NC0uMTguNTEtLjE1LjU4LS4xMi42NC0uMS43MS0uMDYuNzctLjA0Ljg0LS4wMiAxLjI3LjA1em0tNi4zIDEuOThsLS4yMy4zMy0uMDguNDEuMDguNDEuMjMuMzQuMzMuMjIuNDEuMDkuNDEtLjA5LjMzLS4yMi4yMy0uMzQuMDgtLjQxLS4wOC0uNDEtLjIzLS4zMy0uMzMtLjIyLS40MS0uMDktLjQxLjA5em0xMy4wOSAzLjk1bC4yOC4wNi4zMi4xMi4zNS4xOC4zNi4yNy4zNi4zNS4zNS40Ny4zMi41OS4yOC43My4yMS44OC4xNCAxLjA0LjA1IDEuMjMtLjA2IDEuMjMtLjE2IDEuMDQtLjI0Ljg2LS4zMi43MS0uMzYuNTctLjQuNDUtLjQyLjMzLS40Mi4yNC0uNC4xNi0uMzYuMDktLjMyLjA1LS4yNC4wMi0uMTYtLjAxaC04LjIydi44Mmg1Ljg0bC4wMSAyLjc2LjAyLjM2LS4wNS4zNC0uMTEuMzEtLjE3LjI5LS4yNS4yNS0uMzEuMjQtLjM4LjItLjQ0LjE3LS41MS4xNS0uNTguMTMtLjY0LjA5LS43MS4wNy0uNzcuMDQtLjg0LjAxLTEuMjctLjA0LTEuMDctLjE0LS45LS4yLS43My0uMjUtLjU5LS4zLS40NS0uMzMtLjM0LS4zNC0uMjUtLjM0LS4xNi0uMzMtLjEtLjMtLjA0LS4yNS0uMDItLjIuMDEtLjEzdi01LjM0bC4wNS0uNjQuMTMtLjU0LjIxLS40Ni4yNi0uMzguMy0uMzIuMzMtLjI0LjM1LS4yLjM1LS4xNC4zMy0uMS4zLS4wNi4yNi0uMDQuMjEtLjAyLjEzLS4wMWg1Ljg0bC42OS0uMDUuNTktLjE0LjUtLjIxLjQxLS4yOC4zMy0uMzIuMjctLjM1LjItLjM2LjE1LS4zNi4xLS4zNS4wNy0uMzIuMDQtLjI4LjAyLS4yMVY2LjA3aDIuMDlsLjE0LjAxem0tNi40NyAxNC4yNWwtLjIzLjMzLS4wOC40MS4wOC40MS4yMy4zMy4zMy4yMy40MS4wOC40MS0uMDguMzMtLjIzLjIzLS4zMy4wOC0uNDEtLjA4LS40MS0uMjMtLjMzLS4zMy0uMjMtLjQxLS4wOC0uNDEuMDh6Ii8+PC9zdmc+"/><text transform="scale(.1)" x="587.5" y="175" textLength="535" fill="#fff" font-weight="bold">PYTHON</text></g></svg>
|
||||
|
After Width: | Height: | Size: 2.6 KiB |
@@ -15,198 +15,226 @@ There is another optional layer of abstraction available: `TextEmbeddingFunction
|
||||
|
||||
Let's implement `SentenceTransformerEmbeddings` class. All you need to do is implement the `generate_embeddings()` and `ndims` function to handle the input types you expect and register the class in the global `EmbeddingFunctionRegistry`
|
||||
|
||||
```python
|
||||
from lancedb.embeddings import register
|
||||
from lancedb.util import attempt_import_or_raise
|
||||
|
||||
@register("sentence-transformers")
|
||||
class SentenceTransformerEmbeddings(TextEmbeddingFunction):
|
||||
name: str = "all-MiniLM-L6-v2"
|
||||
# set more default instance vars like device, etc.
|
||||
=== "Python"
|
||||
|
||||
def __init__(self, **kwargs):
|
||||
super().__init__(**kwargs)
|
||||
self._ndims = None
|
||||
|
||||
def generate_embeddings(self, texts):
|
||||
return self._embedding_model().encode(list(texts), ...).tolist()
|
||||
```python
|
||||
from lancedb.embeddings import register
|
||||
from lancedb.util import attempt_import_or_raise
|
||||
|
||||
def ndims(self):
|
||||
if self._ndims is None:
|
||||
self._ndims = len(self.generate_embeddings("foo")[0])
|
||||
return self._ndims
|
||||
@register("sentence-transformers")
|
||||
class SentenceTransformerEmbeddings(TextEmbeddingFunction):
|
||||
name: str = "all-MiniLM-L6-v2"
|
||||
# set more default instance vars like device, etc.
|
||||
|
||||
@cached(cache={})
|
||||
def _embedding_model(self):
|
||||
return sentence_transformers.SentenceTransformer(name)
|
||||
```
|
||||
def __init__(self, **kwargs):
|
||||
super().__init__(**kwargs)
|
||||
self._ndims = None
|
||||
|
||||
This is a stripped down version of our implementation of `SentenceTransformerEmbeddings` that removes certain optimizations and defaul settings.
|
||||
def generate_embeddings(self, texts):
|
||||
return self._embedding_model().encode(list(texts), ...).tolist()
|
||||
|
||||
def ndims(self):
|
||||
if self._ndims is None:
|
||||
self._ndims = len(self.generate_embeddings("foo")[0])
|
||||
return self._ndims
|
||||
|
||||
@cached(cache={})
|
||||
def _embedding_model(self):
|
||||
return sentence_transformers.SentenceTransformer(name)
|
||||
```
|
||||
|
||||
=== "TypeScript"
|
||||
|
||||
```ts
|
||||
--8<--- "nodejs/examples/custom_embedding_function.ts:imports"
|
||||
|
||||
--8<--- "nodejs/examples/custom_embedding_function.ts:embedding_impl"
|
||||
```
|
||||
|
||||
|
||||
This is a stripped down version of our implementation of `SentenceTransformerEmbeddings` that removes certain optimizations and default settings.
|
||||
|
||||
Now you can use this embedding function to create your table schema and that's it! you can then ingest data and run queries without manually vectorizing the inputs.
|
||||
|
||||
```python
|
||||
from lancedb.pydantic import LanceModel, Vector
|
||||
=== "Python"
|
||||
|
||||
registry = EmbeddingFunctionRegistry.get_instance()
|
||||
stransformer = registry.get("sentence-transformers").create()
|
||||
```python
|
||||
from lancedb.pydantic import LanceModel, Vector
|
||||
|
||||
class TextModelSchema(LanceModel):
|
||||
vector: Vector(stransformer.ndims) = stransformer.VectorField()
|
||||
text: str = stransformer.SourceField()
|
||||
registry = EmbeddingFunctionRegistry.get_instance()
|
||||
stransformer = registry.get("sentence-transformers").create()
|
||||
|
||||
tbl = db.create_table("table", schema=TextModelSchema)
|
||||
class TextModelSchema(LanceModel):
|
||||
vector: Vector(stransformer.ndims) = stransformer.VectorField()
|
||||
text: str = stransformer.SourceField()
|
||||
|
||||
tbl.add(pd.DataFrame({"text": ["halo", "world"]}))
|
||||
result = tbl.search("world").limit(5)
|
||||
```
|
||||
tbl = db.create_table("table", schema=TextModelSchema)
|
||||
|
||||
NOTE:
|
||||
tbl.add(pd.DataFrame({"text": ["halo", "world"]}))
|
||||
result = tbl.search("world").limit(5)
|
||||
```
|
||||
|
||||
You can always implement the `EmbeddingFunction` interface directly if you want or need to, `TextEmbeddingFunction` just makes it much simpler and faster for you to do so, by setting up the boiler plat for text-specific use case
|
||||
=== "TypeScript"
|
||||
|
||||
```ts
|
||||
--8<--- "nodejs/examples/custom_embedding_function.ts:call_custom_function"
|
||||
```
|
||||
|
||||
!!! note
|
||||
|
||||
You can always implement the `EmbeddingFunction` interface directly if you want or need to, `TextEmbeddingFunction` just makes it much simpler and faster for you to do so, by setting up the boiler plat for text-specific use case
|
||||
|
||||
## Multi-modal embedding function example
|
||||
You can also use the `EmbeddingFunction` interface to implement more complex workflows such as multi-modal embedding function support. LanceDB implements `OpenClipEmeddingFunction` class that suppports multi-modal seach. Here's the implementation that you can use as a reference to build your own multi-modal embedding functions.
|
||||
You can also use the `EmbeddingFunction` interface to implement more complex workflows such as multi-modal embedding function support.
|
||||
|
||||
```python
|
||||
@register("open-clip")
|
||||
class OpenClipEmbeddings(EmbeddingFunction):
|
||||
name: str = "ViT-B-32"
|
||||
pretrained: str = "laion2b_s34b_b79k"
|
||||
device: str = "cpu"
|
||||
batch_size: int = 64
|
||||
normalize: bool = True
|
||||
_model = PrivateAttr()
|
||||
_preprocess = PrivateAttr()
|
||||
_tokenizer = PrivateAttr()
|
||||
=== "Python"
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
super().__init__(*args, **kwargs)
|
||||
open_clip = attempt_import_or_raise("open_clip", "open-clip") # EmbeddingFunction util to import external libs and raise if not found
|
||||
model, _, preprocess = open_clip.create_model_and_transforms(
|
||||
self.name, pretrained=self.pretrained
|
||||
)
|
||||
model.to(self.device)
|
||||
self._model, self._preprocess = model, preprocess
|
||||
self._tokenizer = open_clip.get_tokenizer(self.name)
|
||||
self._ndims = None
|
||||
LanceDB implements `OpenClipEmeddingFunction` class that suppports multi-modal seach. Here's the implementation that you can use as a reference to build your own multi-modal embedding functions.
|
||||
|
||||
def ndims(self):
|
||||
if self._ndims is None:
|
||||
self._ndims = self.generate_text_embeddings("foo").shape[0]
|
||||
return self._ndims
|
||||
```python
|
||||
@register("open-clip")
|
||||
class OpenClipEmbeddings(EmbeddingFunction):
|
||||
name: str = "ViT-B-32"
|
||||
pretrained: str = "laion2b_s34b_b79k"
|
||||
device: str = "cpu"
|
||||
batch_size: int = 64
|
||||
normalize: bool = True
|
||||
_model = PrivateAttr()
|
||||
_preprocess = PrivateAttr()
|
||||
_tokenizer = PrivateAttr()
|
||||
|
||||
def compute_query_embeddings(
|
||||
self, query: Union[str, "PIL.Image.Image"], *args, **kwargs
|
||||
) -> List[np.ndarray]:
|
||||
"""
|
||||
Compute the embeddings for a given user query
|
||||
def __init__(self, *args, **kwargs):
|
||||
super().__init__(*args, **kwargs)
|
||||
open_clip = attempt_import_or_raise("open_clip", "open-clip") # EmbeddingFunction util to import external libs and raise if not found
|
||||
model, _, preprocess = open_clip.create_model_and_transforms(
|
||||
self.name, pretrained=self.pretrained
|
||||
)
|
||||
model.to(self.device)
|
||||
self._model, self._preprocess = model, preprocess
|
||||
self._tokenizer = open_clip.get_tokenizer(self.name)
|
||||
self._ndims = None
|
||||
|
||||
Parameters
|
||||
----------
|
||||
query : Union[str, PIL.Image.Image]
|
||||
The query to embed. A query can be either text or an image.
|
||||
"""
|
||||
if isinstance(query, str):
|
||||
return [self.generate_text_embeddings(query)]
|
||||
else:
|
||||
def ndims(self):
|
||||
if self._ndims is None:
|
||||
self._ndims = self.generate_text_embeddings("foo").shape[0]
|
||||
return self._ndims
|
||||
|
||||
def compute_query_embeddings(
|
||||
self, query: Union[str, "PIL.Image.Image"], *args, **kwargs
|
||||
) -> List[np.ndarray]:
|
||||
"""
|
||||
Compute the embeddings for a given user query
|
||||
|
||||
Parameters
|
||||
----------
|
||||
query : Union[str, PIL.Image.Image]
|
||||
The query to embed. A query can be either text or an image.
|
||||
"""
|
||||
if isinstance(query, str):
|
||||
return [self.generate_text_embeddings(query)]
|
||||
else:
|
||||
PIL = attempt_import_or_raise("PIL", "pillow")
|
||||
if isinstance(query, PIL.Image.Image):
|
||||
return [self.generate_image_embedding(query)]
|
||||
else:
|
||||
raise TypeError("OpenClip supports str or PIL Image as query")
|
||||
|
||||
def generate_text_embeddings(self, text: str) -> np.ndarray:
|
||||
torch = attempt_import_or_raise("torch")
|
||||
text = self.sanitize_input(text)
|
||||
text = self._tokenizer(text)
|
||||
text.to(self.device)
|
||||
with torch.no_grad():
|
||||
text_features = self._model.encode_text(text.to(self.device))
|
||||
if self.normalize:
|
||||
text_features /= text_features.norm(dim=-1, keepdim=True)
|
||||
return text_features.cpu().numpy().squeeze()
|
||||
|
||||
def sanitize_input(self, images: IMAGES) -> Union[List[bytes], np.ndarray]:
|
||||
"""
|
||||
Sanitize the input to the embedding function.
|
||||
"""
|
||||
if isinstance(images, (str, bytes)):
|
||||
images = [images]
|
||||
elif isinstance(images, pa.Array):
|
||||
images = images.to_pylist()
|
||||
elif isinstance(images, pa.ChunkedArray):
|
||||
images = images.combine_chunks().to_pylist()
|
||||
return images
|
||||
|
||||
def compute_source_embeddings(
|
||||
self, images: IMAGES, *args, **kwargs
|
||||
) -> List[np.array]:
|
||||
"""
|
||||
Get the embeddings for the given images
|
||||
"""
|
||||
images = self.sanitize_input(images)
|
||||
embeddings = []
|
||||
for i in range(0, len(images), self.batch_size):
|
||||
j = min(i + self.batch_size, len(images))
|
||||
batch = images[i:j]
|
||||
embeddings.extend(self._parallel_get(batch))
|
||||
return embeddings
|
||||
|
||||
def _parallel_get(self, images: Union[List[str], List[bytes]]) -> List[np.ndarray]:
|
||||
"""
|
||||
Issue concurrent requests to retrieve the image data
|
||||
"""
|
||||
with concurrent.futures.ThreadPoolExecutor() as executor:
|
||||
futures = [
|
||||
executor.submit(self.generate_image_embedding, image)
|
||||
for image in images
|
||||
]
|
||||
return [future.result() for future in futures]
|
||||
|
||||
def generate_image_embedding(
|
||||
self, image: Union[str, bytes, "PIL.Image.Image"]
|
||||
) -> np.ndarray:
|
||||
"""
|
||||
Generate the embedding for a single image
|
||||
|
||||
Parameters
|
||||
----------
|
||||
image : Union[str, bytes, PIL.Image.Image]
|
||||
The image to embed. If the image is a str, it is treated as a uri.
|
||||
If the image is bytes, it is treated as the raw image bytes.
|
||||
"""
|
||||
torch = attempt_import_or_raise("torch")
|
||||
# TODO handle retry and errors for https
|
||||
image = self._to_pil(image)
|
||||
image = self._preprocess(image).unsqueeze(0)
|
||||
with torch.no_grad():
|
||||
return self._encode_and_normalize_image(image)
|
||||
|
||||
def _to_pil(self, image: Union[str, bytes]):
|
||||
PIL = attempt_import_or_raise("PIL", "pillow")
|
||||
if isinstance(query, PIL.Image.Image):
|
||||
return [self.generate_image_embedding(query)]
|
||||
else:
|
||||
raise TypeError("OpenClip supports str or PIL Image as query")
|
||||
if isinstance(image, bytes):
|
||||
return PIL.Image.open(io.BytesIO(image))
|
||||
if isinstance(image, PIL.Image.Image):
|
||||
return image
|
||||
elif isinstance(image, str):
|
||||
parsed = urlparse.urlparse(image)
|
||||
# TODO handle drive letter on windows.
|
||||
if parsed.scheme == "file":
|
||||
return PIL.Image.open(parsed.path)
|
||||
elif parsed.scheme == "":
|
||||
return PIL.Image.open(image if os.name == "nt" else parsed.path)
|
||||
elif parsed.scheme.startswith("http"):
|
||||
return PIL.Image.open(io.BytesIO(url_retrieve(image)))
|
||||
else:
|
||||
raise NotImplementedError("Only local and http(s) urls are supported")
|
||||
|
||||
def generate_text_embeddings(self, text: str) -> np.ndarray:
|
||||
torch = attempt_import_or_raise("torch")
|
||||
text = self.sanitize_input(text)
|
||||
text = self._tokenizer(text)
|
||||
text.to(self.device)
|
||||
with torch.no_grad():
|
||||
text_features = self._model.encode_text(text.to(self.device))
|
||||
def _encode_and_normalize_image(self, image_tensor: "torch.Tensor"):
|
||||
"""
|
||||
encode a single image tensor and optionally normalize the output
|
||||
"""
|
||||
image_features = self._model.encode_image(image_tensor)
|
||||
if self.normalize:
|
||||
text_features /= text_features.norm(dim=-1, keepdim=True)
|
||||
return text_features.cpu().numpy().squeeze()
|
||||
image_features /= image_features.norm(dim=-1, keepdim=True)
|
||||
return image_features.cpu().numpy().squeeze()
|
||||
```
|
||||
|
||||
def sanitize_input(self, images: IMAGES) -> Union[List[bytes], np.ndarray]:
|
||||
"""
|
||||
Sanitize the input to the embedding function.
|
||||
"""
|
||||
if isinstance(images, (str, bytes)):
|
||||
images = [images]
|
||||
elif isinstance(images, pa.Array):
|
||||
images = images.to_pylist()
|
||||
elif isinstance(images, pa.ChunkedArray):
|
||||
images = images.combine_chunks().to_pylist()
|
||||
return images
|
||||
=== "TypeScript"
|
||||
|
||||
def compute_source_embeddings(
|
||||
self, images: IMAGES, *args, **kwargs
|
||||
) -> List[np.array]:
|
||||
"""
|
||||
Get the embeddings for the given images
|
||||
"""
|
||||
images = self.sanitize_input(images)
|
||||
embeddings = []
|
||||
for i in range(0, len(images), self.batch_size):
|
||||
j = min(i + self.batch_size, len(images))
|
||||
batch = images[i:j]
|
||||
embeddings.extend(self._parallel_get(batch))
|
||||
return embeddings
|
||||
|
||||
def _parallel_get(self, images: Union[List[str], List[bytes]]) -> List[np.ndarray]:
|
||||
"""
|
||||
Issue concurrent requests to retrieve the image data
|
||||
"""
|
||||
with concurrent.futures.ThreadPoolExecutor() as executor:
|
||||
futures = [
|
||||
executor.submit(self.generate_image_embedding, image)
|
||||
for image in images
|
||||
]
|
||||
return [future.result() for future in futures]
|
||||
|
||||
def generate_image_embedding(
|
||||
self, image: Union[str, bytes, "PIL.Image.Image"]
|
||||
) -> np.ndarray:
|
||||
"""
|
||||
Generate the embedding for a single image
|
||||
|
||||
Parameters
|
||||
----------
|
||||
image : Union[str, bytes, PIL.Image.Image]
|
||||
The image to embed. If the image is a str, it is treated as a uri.
|
||||
If the image is bytes, it is treated as the raw image bytes.
|
||||
"""
|
||||
torch = attempt_import_or_raise("torch")
|
||||
# TODO handle retry and errors for https
|
||||
image = self._to_pil(image)
|
||||
image = self._preprocess(image).unsqueeze(0)
|
||||
with torch.no_grad():
|
||||
return self._encode_and_normalize_image(image)
|
||||
|
||||
def _to_pil(self, image: Union[str, bytes]):
|
||||
PIL = attempt_import_or_raise("PIL", "pillow")
|
||||
if isinstance(image, bytes):
|
||||
return PIL.Image.open(io.BytesIO(image))
|
||||
if isinstance(image, PIL.Image.Image):
|
||||
return image
|
||||
elif isinstance(image, str):
|
||||
parsed = urlparse.urlparse(image)
|
||||
# TODO handle drive letter on windows.
|
||||
if parsed.scheme == "file":
|
||||
return PIL.Image.open(parsed.path)
|
||||
elif parsed.scheme == "":
|
||||
return PIL.Image.open(image if os.name == "nt" else parsed.path)
|
||||
elif parsed.scheme.startswith("http"):
|
||||
return PIL.Image.open(io.BytesIO(url_retrieve(image)))
|
||||
else:
|
||||
raise NotImplementedError("Only local and http(s) urls are supported")
|
||||
|
||||
def _encode_and_normalize_image(self, image_tensor: "torch.Tensor"):
|
||||
"""
|
||||
encode a single image tensor and optionally normalize the output
|
||||
"""
|
||||
image_features = self._model.encode_image(image_tensor)
|
||||
if self.normalize:
|
||||
image_features /= image_features.norm(dim=-1, keepdim=True)
|
||||
return image_features.cpu().numpy().squeeze()
|
||||
```
|
||||
Coming Soon! See this [issue](https://github.com/lancedb/lancedb/issues/1482) to track the status!
|
||||
|
||||
@@ -518,6 +518,82 @@ tbl.add(df)
|
||||
rs = tbl.search("hello").limit(1).to_pandas()
|
||||
```
|
||||
|
||||
# IBM watsonx.ai Embeddings
|
||||
|
||||
Generate text embeddings using IBM's watsonx.ai platform.
|
||||
|
||||
## Supported Models
|
||||
|
||||
You can find a list of supported models at [IBM watsonx.ai Documentation](https://dataplatform.cloud.ibm.com/docs/content/wsj/analyze-data/fm-models-embed.html?context=wx). The currently supported model names are:
|
||||
|
||||
- `ibm/slate-125m-english-rtrvr`
|
||||
- `ibm/slate-30m-english-rtrvr`
|
||||
- `sentence-transformers/all-minilm-l12-v2`
|
||||
- `intfloat/multilingual-e5-large`
|
||||
|
||||
## Parameters
|
||||
|
||||
The following parameters can be passed to the `create` method:
|
||||
|
||||
| Parameter | Type | Default Value | Description |
|
||||
|------------|----------|----------------------------------|-----------------------------------------------------------|
|
||||
| name | str | "ibm/slate-125m-english-rtrvr" | The model ID of the watsonx.ai model to use |
|
||||
| api_key | str | None | Optional IBM Cloud API key (or set `WATSONX_API_KEY`) |
|
||||
| project_id | str | None | Optional watsonx project ID (or set `WATSONX_PROJECT_ID`) |
|
||||
| url | str | None | Optional custom URL for the watsonx.ai instance |
|
||||
| params | dict | None | Optional additional parameters for the embedding model |
|
||||
|
||||
## Usage Example
|
||||
|
||||
First, the watsonx.ai library is an optional dependency, so must be installed seperately:
|
||||
|
||||
```
|
||||
pip install ibm-watsonx-ai
|
||||
```
|
||||
|
||||
Optionally set environment variables (if not passing credentials to `create` directly):
|
||||
|
||||
```sh
|
||||
export WATSONX_API_KEY="YOUR_WATSONX_API_KEY"
|
||||
export WATSONX_PROJECT_ID="YOUR_WATSONX_PROJECT_ID"
|
||||
```
|
||||
|
||||
```python
|
||||
import os
|
||||
import lancedb
|
||||
from lancedb.pydantic import LanceModel, Vector
|
||||
from lancedb.embeddings import EmbeddingFunctionRegistry
|
||||
|
||||
watsonx_embed = EmbeddingFunctionRegistry
|
||||
.get_instance()
|
||||
.get("watsonx")
|
||||
.create(
|
||||
name="ibm/slate-125m-english-rtrvr",
|
||||
# Uncomment and set these if not using environment variables
|
||||
# api_key="your_api_key_here",
|
||||
# project_id="your_project_id_here",
|
||||
# url="your_watsonx_url_here",
|
||||
# params={...},
|
||||
)
|
||||
|
||||
class TextModel(LanceModel):
|
||||
text: str = watsonx_embed.SourceField()
|
||||
vector: Vector(watsonx_embed.ndims()) = watsonx_embed.VectorField()
|
||||
|
||||
data = [
|
||||
{"text": "hello world"},
|
||||
{"text": "goodbye world"},
|
||||
]
|
||||
|
||||
db = lancedb.connect("~/.lancedb")
|
||||
tbl = db.create_table("watsonx_test", schema=TextModel, mode="overwrite")
|
||||
|
||||
tbl.add(data)
|
||||
|
||||
rs = tbl.search("hello").limit(1).to_pandas()
|
||||
print(rs)
|
||||
```
|
||||
|
||||
## Multi-modal embedding functions
|
||||
Multi-modal embedding functions allow you to query your table using both images and text.
|
||||
|
||||
@@ -721,4 +797,4 @@ Usage Example:
|
||||
table.add(
|
||||
pd.DataFrame({"label": labels, "image_uri": uris, "image_bytes": image_bytes})
|
||||
)
|
||||
```
|
||||
```
|
||||
|
||||
@@ -2,8 +2,8 @@ Representing multi-modal data as vector embeddings is becoming a standard practi
|
||||
|
||||
For this purpose, LanceDB introduces an **embedding functions API**, that allow you simply set up once, during the configuration stage of your project. After this, the table remembers it, effectively making the embedding functions *disappear in the background* so you don't have to worry about manually passing callables, and instead, simply focus on the rest of your data engineering pipeline.
|
||||
|
||||
!!! Note "LanceDB cloud doesn't support embedding functions yet"
|
||||
LanceDB Cloud does not support embedding functions yet. You need to generate embeddings before ingesting into the table or querying.
|
||||
!!! Note "Embedding functions on LanceDB cloud"
|
||||
When using embedding functions with LanceDB cloud, the embeddings will be generated on the source device and sent to the cloud. This means that the source device must have the necessary resources to generate the embeddings.
|
||||
|
||||
!!! warning
|
||||
Using the embedding function registry means that you don't have to explicitly generate the embeddings yourself.
|
||||
|
||||
@@ -99,28 +99,28 @@ LanceDB registers the Sentence Transformers embeddings function in the registry
|
||||
|
||||
Coming Soon!
|
||||
|
||||
### Jina Embeddings
|
||||
|
||||
LanceDB registers the JinaAI embeddings function in the registry as `jina`. You can pass any supported model name to the `create`. By default it uses `"jina-clip-v1"`.
|
||||
`jina-clip-v1` can handle both text and images and other models only support `text`.
|
||||
|
||||
You need to pass `JINA_API_KEY` in the environment variable or pass it as `api_key` to `create` method.
|
||||
### Embedding function with LanceDB cloud
|
||||
Embedding functions are now supported on LanceDB cloud. The embeddings will be generated on the source device and sent to the cloud. This means that the source device must have the necessary resources to generate the embeddings. Here's an example using the OpenAI embedding function:
|
||||
|
||||
```python
|
||||
import os
|
||||
import lancedb
|
||||
from lancedb.pydantic import LanceModel, Vector
|
||||
from lancedb.embeddings import get_registry
|
||||
os.environ['JINA_API_KEY'] = "jina_*"
|
||||
os.environ['OPENAI_API_KEY'] = "..."
|
||||
|
||||
db = lancedb.connect("/tmp/db")
|
||||
func = get_registry().get("jina").create(name="jina-clip-v1")
|
||||
db = lancedb.connect(
|
||||
uri="db://....",
|
||||
api_key="sk_...",
|
||||
region="us-east-1"
|
||||
)
|
||||
func = get_registry().get("openai").create()
|
||||
|
||||
class Words(LanceModel):
|
||||
text: str = func.SourceField()
|
||||
vector: Vector(func.ndims()) = func.VectorField()
|
||||
|
||||
table = db.create_table("words", schema=Words, mode="overwrite")
|
||||
table = db.create_table("words", schema=Words)
|
||||
table.add(
|
||||
[
|
||||
{"text": "hello world"},
|
||||
|
||||
@@ -10,7 +10,7 @@ LanceDB provides language APIs, allowing you to embed a database in your languag
|
||||
|
||||
## Applications powered by LanceDB
|
||||
|
||||
| Project Name | Description | Screenshot |
|
||||
|-----------------------------------------------------|----------------------------------------------------------------------------------------------------------------------|-------------------------------------------|
|
||||
| [YOLOExplorer](https://github.com/lancedb/yoloexplorer) | Iterate on your YOLO / CV datasets using SQL, Vector semantic search, and more within seconds | 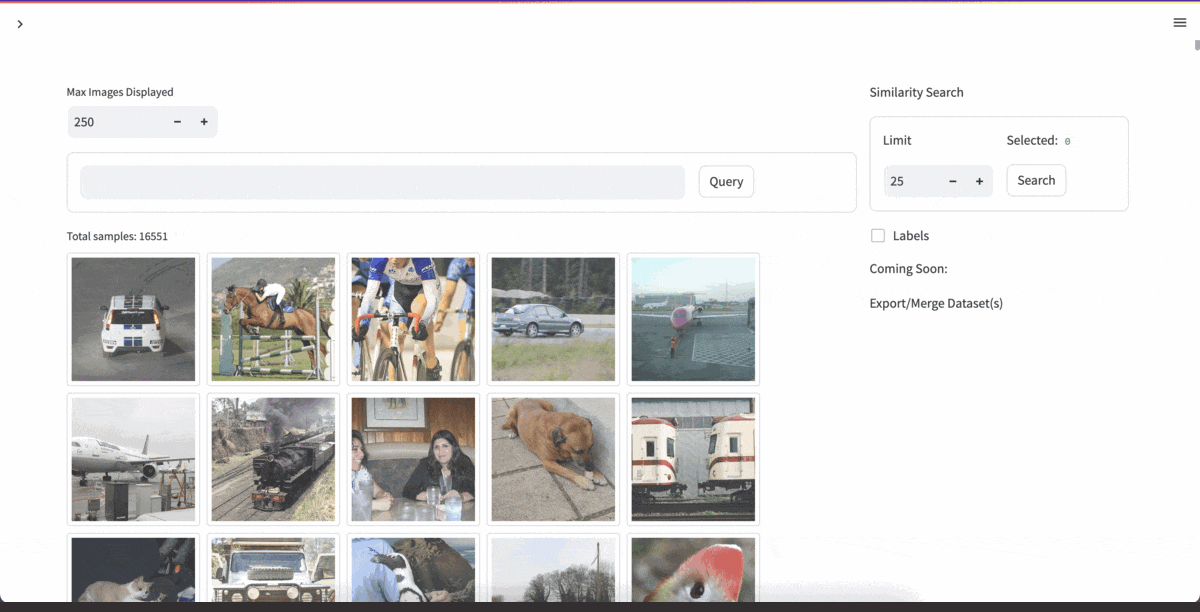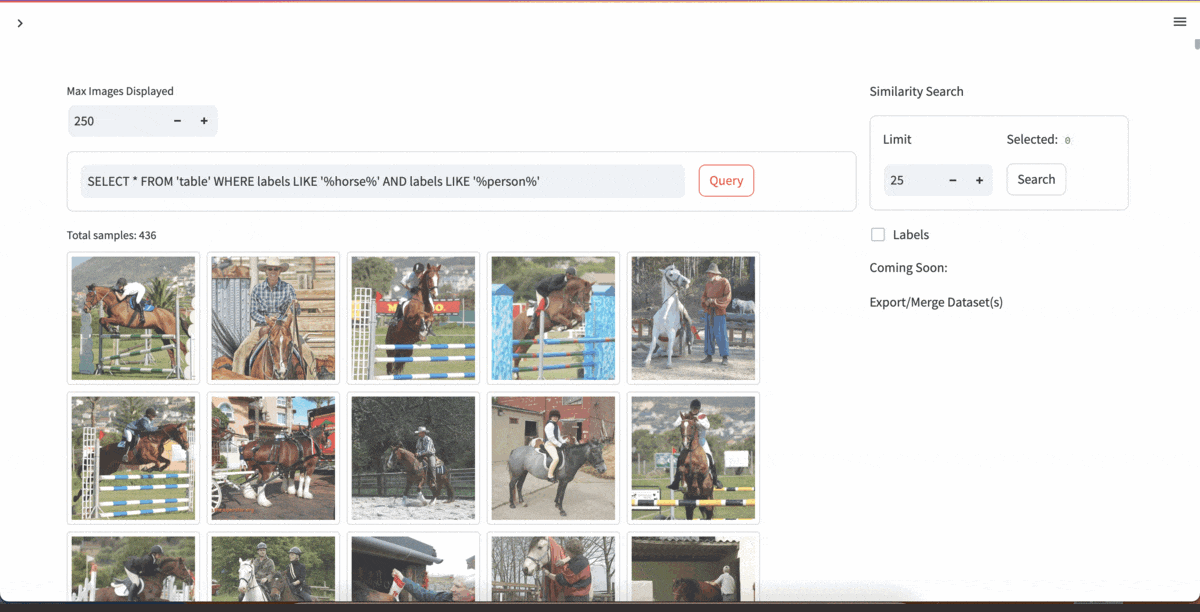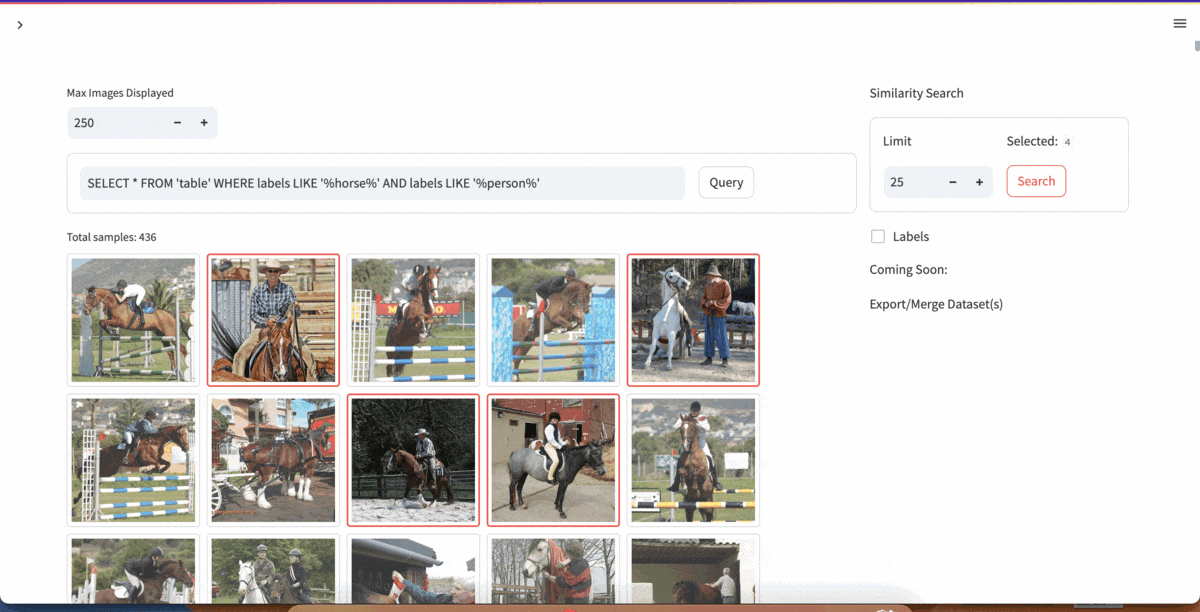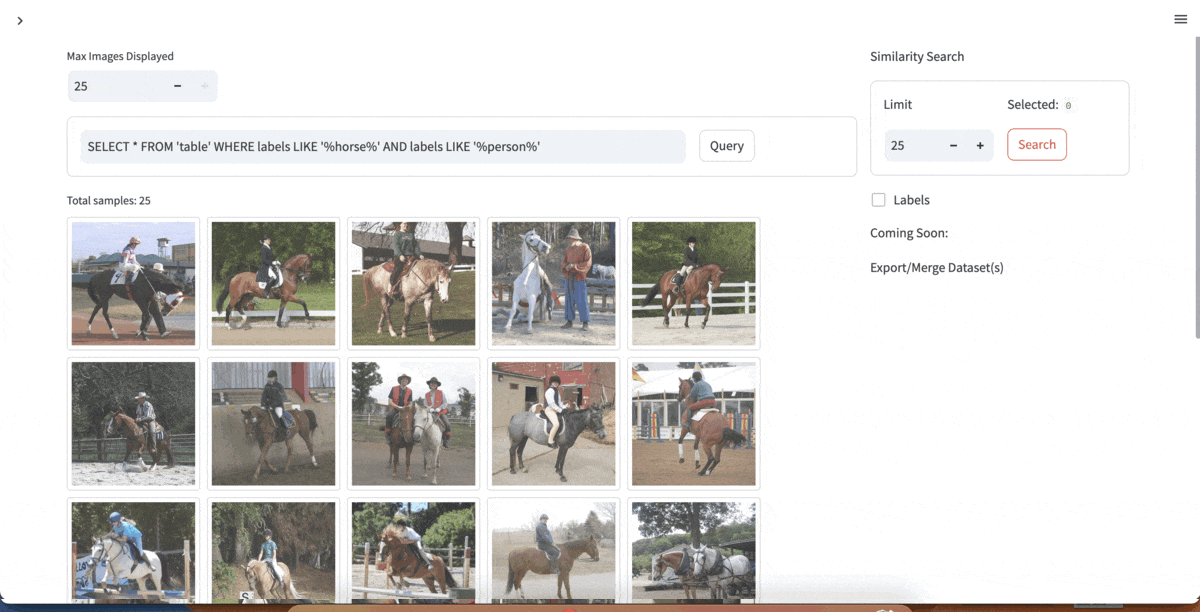 |
|
||||
| [Website Chatbot (Deployable Vercel Template)](https://github.com/lancedb/lancedb-vercel-chatbot) | Create a chatbot from the sitemap of any website/docs of your choice. Built using vectorDB serverless native javascript package. |  |
|
||||
| Project Name | Description |
|
||||
| --- | --- |
|
||||
| **Ultralytics Explorer 🚀**<br>[](https://docs.ultralytics.com/datasets/explorer/)<br>[](https://colab.research.google.com/github/ultralytics/ultralytics/blob/main/docs/en/datasets/explorer/explorer.ipynb) | - 🔍 **Explore CV Datasets**: Semantic search, SQL queries, vector similarity, natural language.<br>- 🖥️ **GUI & Python API**: Seamless dataset interaction.<br>- ⚡ **Efficient & Scalable**: Leverages LanceDB for large datasets.<br>- 📊 **Detailed Analysis**: Easily analyze data patterns.<br>- 🌐 **Browser GUI Demo**: Create embeddings, search images, run queries. |
|
||||
| **Website Chatbot🤖**<br>[](https://github.com/lancedb/lancedb-vercel-chatbot)<br>[](https://vercel.com/new/clone?repository-url=https%3A%2F%2Fgithub.com%2Flancedb%2Flancedb-vercel-chatbot&env=OPENAI_API_KEY&envDescription=OpenAI%20API%20Key%20for%20chat%20completion.&project-name=lancedb-vercel-chatbot&repository-name=lancedb-vercel-chatbot&demo-title=LanceDB%20Chatbot%20Demo&demo-description=Demo%20website%20chatbot%20with%20LanceDB.&demo-url=https%3A%2F%2Flancedb.vercel.app&demo-image=https%3A%2F%2Fi.imgur.com%2FazVJtvr.png) | - 🌐 **Chatbot from Sitemap/Docs**: Create a chatbot using site or document context.<br>- 🚀 **Embed LanceDB in Next.js**: Lightweight, on-prem storage.<br>- 🧠 **AI-Powered Context Retrieval**: Efficiently access relevant data.<br>- 🔧 **Serverless & Native JS**: Seamless integration with Next.js.<br>- ⚡ **One-Click Deploy on Vercel**: Quick and easy setup.. |
|
||||
|
||||
13
docs/src/examples/python_examples/build_from_scratch.md
Normal file
13
docs/src/examples/python_examples/build_from_scratch.md
Normal file
@@ -0,0 +1,13 @@
|
||||
# Build from Scratch with LanceDB 🚀
|
||||
|
||||
Start building your GenAI applications from the ground up using LanceDB's efficient vector-based document retrieval capabilities! 📄
|
||||
|
||||
#### Get Started in Minutes ⏱️
|
||||
|
||||
These examples provide a solid foundation for building your own GenAI applications using LanceDB. Jump from idea to proof of concept quickly with applied examples. Get started and see what you can create! 💻
|
||||
|
||||
| **Build From Scratch** | **Description** | **Links** |
|
||||
|:-------------------------------------------|:-------------------------------------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| **Build RAG from Scratch🚀💻** | 📝 Create a **Retrieval-Augmented Generation** (RAG) model from scratch using LanceDB. | [](https://github.com/lancedb/vectordb-recipes/tree/main/tutorials/RAG-from-Scratch)<br>[]() |
|
||||
| **Local RAG from Scratch with Llama3🔥💡** | 🐫 Build a local RAG model using **Llama3** and **LanceDB** for fast and efficient text generation. | [](https://github.com/lancedb/vectordb-recipes/tree/main/tutorials/Local-RAG-from-Scratch)<br>[](https://github.com/lancedb/vectordb-recipes/blob/main/tutorials/Local-RAG-from-Scratch/rag.py) |
|
||||
| **Multi-Head RAG from Scratch📚💻** | 🤯 Develop a **Multi-Head RAG model** from scratch, enabling generation of text based on multiple documents. | [](https://github.com/lancedb/vectordb-recipes/tree/main/tutorials/Multi-Head-RAG-from-Scratch)<br>[](https://github.com/lancedb/vectordb-recipes/tree/main/tutorials/Multi-Head-RAG-from-Scratch) |
|
||||
28
docs/src/examples/python_examples/multimodal.md
Normal file
28
docs/src/examples/python_examples/multimodal.md
Normal file
@@ -0,0 +1,28 @@
|
||||
# Multimodal Search with LanceDB 🔍💡
|
||||
|
||||
Experience the future of search with LanceDB's multimodal capabilities. Combine text and image queries to find the most relevant results in your corpus and unlock new possibilities! 🔓💡
|
||||
|
||||
#### Explore the Future of Search 🚀
|
||||
|
||||
Unlock the power of multimodal search with LanceDB, enabling efficient vector-based retrieval of text and image data! 📊💻
|
||||
|
||||
|
||||
|
||||
| **Multimodal** | **Description** | **Links** |
|
||||
|:----------------|:-----------------|:-----------|
|
||||
| **Multimodal CLIP: DiffusionDB 🌐💥** | Revolutionize search with Multimodal CLIP and DiffusionDB, combining text and image understanding for a new dimension of discovery! 🔓 | [][Clip_diffusionDB_github] <br>[][Clip_diffusionDB_colab] <br>[][Clip_diffusionDB_python] <br>[][Clip_diffusionDB_ghost] |
|
||||
| **Multimodal CLIP: Youtube Videos 📹👀** | Search Youtube videos using Multimodal CLIP, finding relevant content with ease and accuracy! 🎯 | [][Clip_youtube_github] <br>[][Clip_youtube_colab] <br> [][Clip_youtube_python] <br>[][Clip_youtube_python] |
|
||||
| **Multimodal Image + Text Search 📸🔍** | Discover relevant documents and images with a single query, using LanceDB's multimodal search capabilities to bridge the gap between text and visuals! 🌉 | [](https://github.com/lancedb/vectordb-recipes/blob/main/examples/multimodal_search) <br>[](https://colab.research.google.com/github/lancedb/vectordb-recipes/blob/main/examples/multimodal_search/main.ipynb) <br> [](https://github.com/lancedb/vectordb-recipes/blob/main/examples/multimodal_search/main.py)<br> [](https://blog.lancedb.com/multi-modal-ai-made-easy-with-lancedb-clip-5aaf8801c939/) |
|
||||
| **Cambrian-1: Vision-Centric Image Exploration 🔍👀** | Dive into vision-centric exploration of images with Cambrian-1, powered by LanceDB's multimodal search to uncover new insights! 🔎 | [](https://www.kaggle.com/code/prasantdixit/cambrian-1-vision-centric-exploration-of-images/)<br>[]() <br> []() <br> [](https://blog.lancedb.com/cambrian-1-vision-centric-exploration/) |
|
||||
|
||||
|
||||
[Clip_diffusionDB_github]: https://github.com/lancedb/vectordb-recipes/blob/main/examples/multimodal_clip_diffusiondb
|
||||
[Clip_diffusionDB_colab]: https://colab.research.google.com/github/lancedb/vectordb-recipes/blob/main/examples/multimodal_clip_diffusiondb/main.ipynb
|
||||
[Clip_diffusionDB_python]: https://github.com/lancedb/vectordb-recipes/blob/main/examples/multimodal_clip_diffusiondb/main.py
|
||||
[Clip_diffusionDB_ghost]: https://blog.lancedb.com/multi-modal-ai-made-easy-with-lancedb-clip-5aaf8801c939/
|
||||
|
||||
|
||||
[Clip_youtube_github]: https://github.com/lancedb/vectordb-recipes/blob/main/examples/multimodal_video_search
|
||||
[Clip_youtube_colab]: https://colab.research.google.com/github/lancedb/vectordb-recipes/blob/main/examples/multimodal_video_search/main.ipynb
|
||||
[Clip_youtube_python]: https://github.com/lancedb/vectordb-recipes/blob/main/examples/multimodal_video_search/main.py
|
||||
[Clip_youtube_ghost]: https://blog.lancedb.com/multi-modal-ai-made-easy-with-lancedb-clip-5aaf8801c939/
|
||||
85
docs/src/examples/python_examples/rag.md
Normal file
85
docs/src/examples/python_examples/rag.md
Normal file
@@ -0,0 +1,85 @@
|
||||
|
||||
**🔍💡 RAG: Revolutionize Information Retrieval with LanceDB 🔓**
|
||||
====================================================================
|
||||
|
||||
Unlock the full potential of Retrieval-Augmented Generation (RAG) with LanceDB, the ultimate solution for efficient vector-based information retrieval 📊. Input text queries and retrieve relevant documents with lightning-fast speed ⚡️ and accuracy ✅. Generate comprehensive answers by combining retrieved information, uncovering new insights 🔍 and connections.
|
||||
|
||||
### Experience the Future of Search 🔄
|
||||
|
||||
Experience the future of search with RAG, transforming information retrieval and answer generation. Apply RAG to various industries, streamlining processes 📈, saving time ⏰, and resources 💰. Stay ahead of the curve with innovative technology 🔝, powered by LanceDB. Discover the power of RAG with LanceDB and transform your industry with innovative solutions 💡.
|
||||
|
||||
|
||||
| **RAG** | **Description** | **Links** |
|
||||
|----------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------------------------|
|
||||
| **RAG with Matryoshka Embeddings and LlamaIndex** 🪆🔗 | Utilize **Matryoshka embeddings** and **LlamaIndex** to improve the efficiency and accuracy of your RAG models. 📈✨ | [][matryoshka_github] <br>[][matryoshka_colab] |
|
||||
| **Improve RAG with Re-ranking** 📈🔄 | Enhance your RAG applications by implementing **re-ranking strategies** for more relevant document retrieval. 📚🔍 | [][rag_reranking_github] <br>[][rag_reranking_colab] <br>[][rag_reranking_ghost] |
|
||||
| **Instruct-Multitask** 🧠🎯 | Integrate the **Instruct Embedding Model** with LanceDB to streamline your embedding API, reducing redundant code and overhead. 🌐📊 | [][instruct_multitask_github] <br>[][instruct_multitask_colab] <br>[][instruct_multitask_python] <br>[][instruct_multitask_ghost] |
|
||||
| **Improve RAG with HyDE** 🌌🔍 | Use **Hypothetical Document Embeddings** for efficient, accurate, and unsupervised dense retrieval. 📄🔍 | [][hyde_github] <br>[][hyde_colab]<br>[][hyde_ghost] |
|
||||
| **Improve RAG with LOTR** 🧙♂️📜 | Enhance RAG with **Lord of the Retriever (LOTR)** to address 'Lost in the Middle' challenges, especially in medical data. 🌟📜 | [][lotr_github] <br>[][lotr_colab] <br>[][lotr_ghost] |
|
||||
| **Advanced RAG: Parent Document Retriever** 📑🔗 | Use **Parent Document & Bigger Chunk Retriever** to maintain context and relevance when generating related content. 🎵📄 | [][parent_doc_retriever_github] <br>[][parent_doc_retriever_colab] <br>[][parent_doc_retriever_ghost] |
|
||||
| **Corrective RAG with Langgraph** 🔧📊 | Enhance RAG reliability with **Corrective RAG (CRAG)** by self-reflecting and fact-checking for accurate and trustworthy results. ✅🔍 |[][corrective_rag_github] <br>[][corrective_rag_colab] <br>[][corrective_rag_ghost] |
|
||||
| **Contextual Compression with RAG** 🗜️🧠 | Apply **contextual compression techniques** to condense large documents while retaining essential information. 📄🗜️ | [][compression_rag_github] <br>[][compression_rag_colab] <br>[][compression_rag_ghost] |
|
||||
| **Improve RAG with FLARE** 🔥| Enable users to ask questions directly to academic papers, focusing on ArXiv papers, with Forward-Looking Active REtrieval augmented generation.🚀🌟 | [][flare_github] <br>[][flare_colab] <br>[][flare_ghost] |
|
||||
| **Query Expansion and Reranker** 🔍🔄 | Enhance RAG with query expansion using Large Language Models and advanced **reranking methods** like Cross Encoders, ColBERT v2, and FlashRank for improved document retrieval precision and recall 🔍📈 | [][query_github] <br>[][query_colab] |
|
||||
| **RAG Fusion** ⚡🌐 | Revolutionize search with RAG Fusion, utilizing the **RRF algorithm** to rerank documents based on user queries, and leveraging LanceDB and OPENAI Embeddings for efficient information retrieval ⚡🌐 | [][fusion_github] <br>[][fusion_colab] |
|
||||
| **Agentic RAG** 🤖📚 | Unlock autonomous information retrieval with **Agentic RAG**, a framework of **intelligent agents** that collaborate to synthesize, summarize, and compare data across sources, enabling proactive and informed decision-making 🤖📚 | [][agentic_github] <br>[][agentic_colab] |
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
[matryoshka_github]: https://github.com/lancedb/vectordb-recipes/blob/main/tutorials/RAG-with_MatryoshkaEmbed-Llamaindex
|
||||
[matryoshka_colab]: https://colab.research.google.com/github/lancedb/vectordb-recipes/blob/main/tutorials/RAG-with_MatryoshkaEmbed-Llamaindex/RAG_with_MatryoshkaEmbedding_and_Llamaindex.ipynb
|
||||
|
||||
[rag_reranking_github]: https://github.com/lancedb/vectordb-recipes/blob/main/examples/RAG_Reranking
|
||||
[rag_reranking_colab]: https://colab.research.google.com/github/lancedb/vectordb-recipes/blob/main/examples/RAG_Reranking/main.ipynb
|
||||
[rag_reranking_ghost]: https://blog.lancedb.com/simplest-method-to-improve-rag-pipeline-re-ranking-cf6eaec6d544
|
||||
|
||||
|
||||
[instruct_multitask_github]: https://github.com/lancedb/vectordb-recipes/blob/main/examples/instruct-multitask
|
||||
[instruct_multitask_colab]: https://colab.research.google.com/github/lancedb/vectordb-recipes/blob/main/examples/instruct-multitask/main.ipynb
|
||||
[instruct_multitask_python]: https://github.com/lancedb/vectordb-recipes/blob/main/examples/instruct-multitask/main.py
|
||||
[instruct_multitask_ghost]: https://blog.lancedb.com/multitask-embedding-with-lancedb-be18ec397543
|
||||
|
||||
[hyde_github]: https://github.com/lancedb/vectordb-recipes/blob/main/examples/Advance-RAG-with-HyDE
|
||||
[hyde_colab]: https://colab.research.google.com/github/lancedb/vectordb-recipes/blob/main/examples/Advance-RAG-with-HyDE/main.ipynb
|
||||
[hyde_ghost]: https://blog.lancedb.com/advanced-rag-precise-zero-shot-dense-retrieval-with-hyde-0946c54dfdcb
|
||||
|
||||
[lotr_github]: https://github.com/lancedb/vectordb-recipes/blob/main/examples/Advance_RAG_LOTR
|
||||
[lotr_colab]: https://colab.research.google.com/github/lancedb/vectordb-recipes/blob/main/examples/Advance_RAG_LOTR/main.ipynb
|
||||
[lotr_ghost]: https://blog.lancedb.com/better-rag-with-lotr-lord-of-retriever-23c8336b9a35
|
||||
|
||||
[parent_doc_retriever_github]: https://github.com/lancedb/vectordb-recipes/blob/main/examples/parent_document_retriever
|
||||
[parent_doc_retriever_colab]: https://colab.research.google.com/github/lancedb/vectordb-recipes/blob/main/examples/parent_document_retriever/main.ipynb
|
||||
[parent_doc_retriever_ghost]: https://blog.lancedb.com/modified-rag-parent-document-bigger-chunk-retriever-62b3d1e79bc6
|
||||
|
||||
[corrective_rag_github]: https://github.com/lancedb/vectordb-recipes/blob/main/tutorials/Corrective-RAG-with_Langgraph
|
||||
[corrective_rag_colab]: https://colab.research.google.com/github/lancedb/vectordb-recipes/blob/main/tutorials/Corrective-RAG-with_Langgraph/CRAG_with_Langgraph.ipynb
|
||||
[corrective_rag_ghost]: https://blog.lancedb.com/implementing-corrective-rag-in-the-easiest-way-2/
|
||||
|
||||
[compression_rag_github]: https://github.com/lancedb/vectordb-recipes/blob/main/examples/Contextual-Compression-with-RAG
|
||||
[compression_rag_colab]: https://colab.research.google.com/github/lancedb/vectordb-recipes/blob/main/examples/Contextual-Compression-with-RAG/main.ipynb
|
||||
[compression_rag_ghost]: https://blog.lancedb.com/enhance-rag-integrate-contextual-compression-and-filtering-for-precision-a29d4a810301/
|
||||
|
||||
[flare_github]: https://github.com/lancedb/vectordb-recipes/blob/main/examples/better-rag-FLAIR
|
||||
[flare_colab]: https://colab.research.google.com/github/lancedb/vectordb-recipes/blob/main/examples/better-rag-FLAIR/main.ipynb
|
||||
[flare_ghost]: https://blog.lancedb.com/better-rag-with-active-retrieval-augmented-generation-flare-3b66646e2a9f/
|
||||
|
||||
[query_github]: https://github.com/lancedb/vectordb-recipes/blob/main/examples/QueryExpansion&Reranker
|
||||
[query_colab]: https://colab.research.google.com/github/lancedb/vectordb-recipes/blob/main/examples/QueryExpansion&Reranker/main.ipynb
|
||||
|
||||
|
||||
[fusion_github]: https://github.com/lancedb/vectordb-recipes/blob/main/examples/RAG_Fusion
|
||||
[fusion_colab]: https://colab.research.google.com/github/lancedb/vectordb-recipes/blob/main/examples/RAG_Fusion/main.ipynb
|
||||
|
||||
[agentic_github]: https://github.com/lancedb/vectordb-recipes/blob/main/tutorials/Agentic_RAG
|
||||
[agentic_colab]: https://colab.research.google.com/github/lancedb/vectordb-recipes/blob/main/tutorials/Agentic_RAG/main.ipynb
|
||||
|
||||
|
||||
183
docs/src/fts.md
183
docs/src/fts.md
@@ -1,9 +1,14 @@
|
||||
# Full-text search
|
||||
|
||||
LanceDB provides support for full-text search via [Tantivy](https://github.com/quickwit-oss/tantivy) (currently Python only), allowing you to incorporate keyword-based search (based on BM25) in your retrieval solutions. Our goal is to push the FTS integration down to the Rust level in the future, so that it's available for Rust and JavaScript users as well. Follow along at [this Github issue](https://github.com/lancedb/lance/issues/1195)
|
||||
LanceDB provides support for full-text search via Lance (before via [Tantivy](https://github.com/quickwit-oss/tantivy) (Python only)), allowing you to incorporate keyword-based search (based on BM25) in your retrieval solutions.
|
||||
|
||||
Currently, the Lance full text search is missing some features that are in the Tantivy full text search. This includes phrase queries, re-ranking, and customizing the tokenizer. Thus, in Python, Tantivy is still the default way to do full text search and many of the instructions below apply just to Tantivy-based indices.
|
||||
|
||||
|
||||
## Installation
|
||||
## Installation (Only for Tantivy-based FTS)
|
||||
|
||||
!!! note
|
||||
No need to install the tantivy dependency if using native FTS
|
||||
|
||||
To use full-text search, install the dependency [`tantivy-py`](https://github.com/quickwit-oss/tantivy-py):
|
||||
|
||||
@@ -14,42 +19,83 @@ pip install tantivy==0.20.1
|
||||
|
||||
## Example
|
||||
|
||||
Consider that we have a LanceDB table named `my_table`, whose string column `text` we want to index and query via keyword search.
|
||||
Consider that we have a LanceDB table named `my_table`, whose string column `text` we want to index and query via keyword search, the FTS index must be created before you can search via keywords.
|
||||
|
||||
```python
|
||||
import lancedb
|
||||
=== "Python"
|
||||
|
||||
uri = "data/sample-lancedb"
|
||||
db = lancedb.connect(uri)
|
||||
```python
|
||||
import lancedb
|
||||
|
||||
table = db.create_table(
|
||||
"my_table",
|
||||
data=[
|
||||
{"vector": [3.1, 4.1], "text": "Frodo was a happy puppy"},
|
||||
{"vector": [5.9, 26.5], "text": "There are several kittens playing"},
|
||||
],
|
||||
)
|
||||
```
|
||||
uri = "data/sample-lancedb"
|
||||
db = lancedb.connect(uri)
|
||||
|
||||
## Create FTS index on single column
|
||||
table = db.create_table(
|
||||
"my_table",
|
||||
data=[
|
||||
{"vector": [3.1, 4.1], "text": "Frodo was a happy puppy"},
|
||||
{"vector": [5.9, 26.5], "text": "There are several kittens playing"},
|
||||
],
|
||||
)
|
||||
|
||||
The FTS index must be created before you can search via keywords.
|
||||
# passing `use_tantivy=False` to use lance FTS index
|
||||
# `use_tantivy=True` by default
|
||||
table.create_fts_index("text")
|
||||
table.search("puppy").limit(10).select(["text"]).to_list()
|
||||
# [{'text': 'Frodo was a happy puppy', '_score': 0.6931471824645996}]
|
||||
# ...
|
||||
```
|
||||
|
||||
```python
|
||||
table.create_fts_index("text")
|
||||
```
|
||||
=== "TypeScript"
|
||||
|
||||
To search an FTS index via keywords, LanceDB's `table.search` accepts a string as input:
|
||||
```typescript
|
||||
import * as lancedb from "@lancedb/lancedb";
|
||||
const uri = "data/sample-lancedb"
|
||||
const db = await lancedb.connect(uri);
|
||||
|
||||
```python
|
||||
table.search("puppy").limit(10).select(["text"]).to_list()
|
||||
```
|
||||
const data = [
|
||||
{ vector: [3.1, 4.1], text: "Frodo was a happy puppy" },
|
||||
{ vector: [5.9, 26.5], text: "There are several kittens playing" },
|
||||
];
|
||||
const tbl = await db.createTable("my_table", data, { mode: "overwrite" });
|
||||
await tbl.createIndex("text", {
|
||||
config: lancedb.Index.fts(),
|
||||
});
|
||||
|
||||
This returns the result as a list of dictionaries as follows.
|
||||
await tbl
|
||||
.search("puppy")
|
||||
.select(["text"])
|
||||
.limit(10)
|
||||
.toArray();
|
||||
```
|
||||
|
||||
```python
|
||||
[{'text': 'Frodo was a happy puppy', 'score': 0.6931471824645996}]
|
||||
```
|
||||
=== "Rust"
|
||||
|
||||
```rust
|
||||
let uri = "data/sample-lancedb";
|
||||
let db = connect(uri).execute().await?;
|
||||
let initial_data: Box<dyn RecordBatchReader + Send> = create_some_records()?;
|
||||
let tbl = db
|
||||
.create_table("my_table", initial_data)
|
||||
.execute()
|
||||
.await?;
|
||||
tbl
|
||||
.create_index(&["text"], Index::FTS(FtsIndexBuilder::default()))
|
||||
.execute()
|
||||
.await?;
|
||||
|
||||
tbl
|
||||
.query()
|
||||
.full_text_search(FullTextSearchQuery::new("puppy".to_owned()))
|
||||
.select(lancedb::query::Select::Columns(vec!["text".to_owned()]))
|
||||
.limit(10)
|
||||
.execute()
|
||||
.await?;
|
||||
```
|
||||
|
||||
It would search on all indexed columns by default, so it's useful when there are multiple indexed columns.
|
||||
For now, this is supported in tantivy way only.
|
||||
|
||||
Passing `fts_columns="text"` if you want to specify the columns to search, but it's not available for Tantivy-based full text search.
|
||||
|
||||
!!! note
|
||||
LanceDB automatically searches on the existing FTS index if the input to the search is of type `str`. If you provide a vector as input, LanceDB will search the ANN index instead.
|
||||
@@ -57,20 +103,33 @@ This returns the result as a list of dictionaries as follows.
|
||||
## Tokenization
|
||||
By default the text is tokenized by splitting on punctuation and whitespaces and then removing tokens that are longer than 40 chars. For more language specific tokenization then provide the argument tokenizer_name with the 2 letter language code followed by "_stem". So for english it would be "en_stem".
|
||||
|
||||
```python
|
||||
table.create_fts_index("text", tokenizer_name="en_stem")
|
||||
```
|
||||
For now, only the Tantivy-based FTS index supports to specify the tokenizer, so it's only available in Python with `use_tantivy=True`.
|
||||
|
||||
The following [languages](https://docs.rs/tantivy/latest/tantivy/tokenizer/enum.Language.html) are currently supported.
|
||||
=== "use_tantivy=True"
|
||||
|
||||
```python
|
||||
table.create_fts_index("text", use_tantivy=True, tokenizer_name="en_stem")
|
||||
```
|
||||
|
||||
=== "use_tantivy=False"
|
||||
|
||||
[**Not supported yet**](https://github.com/lancedb/lance/issues/1195)
|
||||
|
||||
the following [languages](https://docs.rs/tantivy/latest/tantivy/tokenizer/enum.Language.html) are currently supported.
|
||||
|
||||
## Index multiple columns
|
||||
|
||||
If you have multiple string columns to index, there's no need to combine them manually -- simply pass them all as a list to `create_fts_index`:
|
||||
|
||||
```python
|
||||
table.create_fts_index(["text1", "text2"])
|
||||
```
|
||||
=== "use_tantivy=True"
|
||||
|
||||
```python
|
||||
table.create_fts_index(["text1", "text2"])
|
||||
```
|
||||
|
||||
=== "use_tantivy=False"
|
||||
|
||||
[**Not supported yet**](https://github.com/lancedb/lance/issues/1195)
|
||||
|
||||
Note that the search API call does not change - you can search over all indexed columns at once.
|
||||
|
||||
@@ -80,19 +139,48 @@ Currently the LanceDB full text search feature supports *post-filtering*, meanin
|
||||
applied on top of the full text search results. This can be invoked via the familiar
|
||||
`where` syntax:
|
||||
|
||||
```python
|
||||
table.search("puppy").limit(10).where("meta='foo'").to_list()
|
||||
```
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
table.search("puppy").limit(10).where("meta='foo'").to_list()
|
||||
```
|
||||
|
||||
=== "TypeScript"
|
||||
|
||||
```typescript
|
||||
await tbl
|
||||
.search("apple")
|
||||
.select(["id", "doc"])
|
||||
.limit(10)
|
||||
.where("meta='foo'")
|
||||
.toArray();
|
||||
```
|
||||
|
||||
=== "Rust"
|
||||
|
||||
```rust
|
||||
table
|
||||
.query()
|
||||
.full_text_search(FullTextSearchQuery::new(words[0].to_owned()))
|
||||
.select(lancedb::query::Select::Columns(vec!["doc".to_owned()]))
|
||||
.limit(10)
|
||||
.only_if("meta='foo'")
|
||||
.execute()
|
||||
.await?;
|
||||
```
|
||||
|
||||
## Sorting
|
||||
|
||||
!!! warning "Warn"
|
||||
Sorting is available for only Tantivy-based FTS
|
||||
|
||||
You can pre-sort the documents by specifying `ordering_field_names` when
|
||||
creating the full-text search index. Once pre-sorted, you can then specify
|
||||
`ordering_field_name` while searching to return results sorted by the given
|
||||
field. For example,
|
||||
field. For example,
|
||||
|
||||
```
|
||||
table.create_fts_index(["text_field"], ordering_field_names=["sort_by_field"])
|
||||
```python
|
||||
table.create_fts_index(["text_field"], use_tantivy=True, ordering_field_names=["sort_by_field"])
|
||||
|
||||
(table.search("terms", ordering_field_name="sort_by_field")
|
||||
.limit(20)
|
||||
@@ -105,8 +193,8 @@ table.create_fts_index(["text_field"], ordering_field_names=["sort_by_field"])
|
||||
error will be raised that looks like `ValueError: The field does not exist: xxx`
|
||||
|
||||
!!! note
|
||||
The fields to sort on must be of typed unsigned integer, or else you will see
|
||||
an error during indexing that looks like
|
||||
The fields to sort on must be of typed unsigned integer, or else you will see
|
||||
an error during indexing that looks like
|
||||
`TypeError: argument 'value': 'float' object cannot be interpreted as an integer`.
|
||||
|
||||
!!! note
|
||||
@@ -116,6 +204,9 @@ table.create_fts_index(["text_field"], ordering_field_names=["sort_by_field"])
|
||||
|
||||
## Phrase queries vs. terms queries
|
||||
|
||||
!!! warning "Warn"
|
||||
Phrase queries are available for only Tantivy-based FTS
|
||||
|
||||
For full-text search you can specify either a **phrase** query like `"the old man and the sea"`,
|
||||
or a **terms** search query like `"(Old AND Man) AND Sea"`. For more details on the terms
|
||||
query syntax, see Tantivy's [query parser rules](https://docs.rs/tantivy/latest/tantivy/query/struct.QueryParser.html).
|
||||
@@ -142,7 +233,7 @@ enforce it in one of two ways:
|
||||
|
||||
1. Place the double-quoted query inside single quotes. For example, `table.search('"they could have been dogs OR cats"')` is treated as
|
||||
a phrase query.
|
||||
2. Explicitly declare the `phrase_query()` method. This is useful when you have a phrase query that
|
||||
1. Explicitly declare the `phrase_query()` method. This is useful when you have a phrase query that
|
||||
itself contains double quotes. For example, `table.search('the cats OR dogs were not really "pets" at all').phrase_query()`
|
||||
is treated as a phrase query.
|
||||
|
||||
@@ -150,7 +241,7 @@ In general, a query that's declared as a phrase query will be wrapped in double
|
||||
double quotes replaced by single quotes.
|
||||
|
||||
|
||||
## Configurations
|
||||
## Configurations (Only for Tantivy-based FTS)
|
||||
|
||||
By default, LanceDB configures a 1GB heap size limit for creating the index. You can
|
||||
reduce this if running on a smaller node, or increase this for faster performance while
|
||||
@@ -164,6 +255,8 @@ table.create_fts_index(["text1", "text2"], writer_heap_size=heap, replace=True)
|
||||
|
||||
## Current limitations
|
||||
|
||||
For that Tantivy-based FTS:
|
||||
|
||||
1. Currently we do not yet support incremental writes.
|
||||
If you add data after FTS index creation, it won't be reflected
|
||||
in search results until you do a full reindex.
|
||||
|
||||
@@ -113,6 +113,10 @@ lists the indices that LanceDb supports.
|
||||
|
||||
::: lancedb.index.BTree
|
||||
|
||||
::: lancedb.index.Bitmap
|
||||
|
||||
::: lancedb.index.LabelList
|
||||
|
||||
::: lancedb.index.IvfPq
|
||||
|
||||
## Querying (Asynchronous)
|
||||
|
||||
@@ -5,4 +5,5 @@ pylance
|
||||
duckdb
|
||||
--extra-index-url https://download.pytorch.org/whl/cpu
|
||||
torch
|
||||
polars
|
||||
polars>=0.19, <=1.3.0
|
||||
|
||||
|
||||
4
node/package-lock.json
generated
4
node/package-lock.json
generated
@@ -1,12 +1,12 @@
|
||||
{
|
||||
"name": "vectordb",
|
||||
"version": "0.7.2",
|
||||
"version": "0.10.0-beta.0",
|
||||
"lockfileVersion": 3,
|
||||
"requires": true,
|
||||
"packages": {
|
||||
"": {
|
||||
"name": "vectordb",
|
||||
"version": "0.7.2",
|
||||
"version": "0.10.0-beta.0",
|
||||
"cpu": [
|
||||
"x64",
|
||||
"arm64"
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
{
|
||||
"name": "vectordb",
|
||||
"version": "0.7.2",
|
||||
"version": "0.10.0-beta.0",
|
||||
"description": " Serverless, low-latency vector database for AI applications",
|
||||
"main": "dist/index.js",
|
||||
"types": "dist/index.d.ts",
|
||||
|
||||
@@ -20,7 +20,6 @@ napi = { version = "2.16.8", default-features = false, features = [
|
||||
"async",
|
||||
] }
|
||||
napi-derive = "2.16.4"
|
||||
|
||||
# Prevent dynamic linking of lzma, which comes from datafusion
|
||||
lzma-sys = { version = "*", features = ["static"] }
|
||||
|
||||
|
||||
@@ -1,3 +1,4 @@
|
||||
import * as apiArrow from "apache-arrow";
|
||||
// Copyright 2024 Lance Developers.
|
||||
//
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
@@ -69,7 +70,7 @@ describe.each([arrow13, arrow14, arrow15, arrow16, arrow17])(
|
||||
return 3;
|
||||
}
|
||||
embeddingDataType() {
|
||||
return new arrow.Float32();
|
||||
return new arrow.Float32() as apiArrow.Float;
|
||||
}
|
||||
async computeSourceEmbeddings(data: string[]) {
|
||||
return data.map(() => [1, 2, 3]);
|
||||
@@ -82,7 +83,7 @@ describe.each([arrow13, arrow14, arrow15, arrow16, arrow17])(
|
||||
|
||||
const schema = LanceSchema({
|
||||
id: new arrow.Int32(),
|
||||
text: func.sourceField(new arrow.Utf8()),
|
||||
text: func.sourceField(new arrow.Utf8() as apiArrow.DataType),
|
||||
vector: func.vectorField(),
|
||||
});
|
||||
|
||||
@@ -119,7 +120,7 @@ describe.each([arrow13, arrow14, arrow15, arrow16, arrow17])(
|
||||
return 3;
|
||||
}
|
||||
embeddingDataType() {
|
||||
return new arrow.Float32();
|
||||
return new arrow.Float32() as apiArrow.Float;
|
||||
}
|
||||
async computeSourceEmbeddings(data: string[]) {
|
||||
return data.map(() => [1, 2, 3]);
|
||||
@@ -144,7 +145,7 @@ describe.each([arrow13, arrow14, arrow15, arrow16, arrow17])(
|
||||
return 3;
|
||||
}
|
||||
embeddingDataType() {
|
||||
return new arrow.Float32();
|
||||
return new arrow.Float32() as apiArrow.Float;
|
||||
}
|
||||
async computeSourceEmbeddings(data: string[]) {
|
||||
return data.map(() => [1, 2, 3]);
|
||||
@@ -154,7 +155,7 @@ describe.each([arrow13, arrow14, arrow15, arrow16, arrow17])(
|
||||
|
||||
const schema = LanceSchema({
|
||||
id: new arrow.Int32(),
|
||||
text: func.sourceField(new arrow.Utf8()),
|
||||
text: func.sourceField(new arrow.Utf8() as apiArrow.DataType),
|
||||
vector: func.vectorField(),
|
||||
});
|
||||
const expectedMetadata = new Map<string, string>([
|
||||
|
||||
@@ -31,7 +31,9 @@ import {
|
||||
Float64,
|
||||
Int32,
|
||||
Int64,
|
||||
List,
|
||||
Schema,
|
||||
Utf8,
|
||||
makeArrowTable,
|
||||
} from "../lancedb/arrow";
|
||||
import {
|
||||
@@ -331,6 +333,7 @@ describe("When creating an index", () => {
|
||||
const schema = new Schema([
|
||||
new Field("id", new Int32(), true),
|
||||
new Field("vec", new FixedSizeList(32, new Field("item", new Float32()))),
|
||||
new Field("tags", new List(new Field("item", new Utf8(), true))),
|
||||
]);
|
||||
let tbl: Table;
|
||||
let queryVec: number[];
|
||||
@@ -346,6 +349,7 @@ describe("When creating an index", () => {
|
||||
vec: Array(32)
|
||||
.fill(1)
|
||||
.map(() => Math.random()),
|
||||
tags: ["tag1", "tag2", "tag3"],
|
||||
})),
|
||||
{
|
||||
schema,
|
||||
@@ -428,6 +432,22 @@ describe("When creating an index", () => {
|
||||
}
|
||||
});
|
||||
|
||||
test("create a bitmap index", async () => {
|
||||
await tbl.createIndex("id", {
|
||||
config: Index.bitmap(),
|
||||
});
|
||||
const indexDir = path.join(tmpDir.name, "test.lance", "_indices");
|
||||
expect(fs.readdirSync(indexDir)).toHaveLength(1);
|
||||
});
|
||||
|
||||
test("create a label list index", async () => {
|
||||
await tbl.createIndex("tags", {
|
||||
config: Index.labelList(),
|
||||
});
|
||||
const indexDir = path.join(tmpDir.name, "test.lance", "_indices");
|
||||
expect(fs.readdirSync(indexDir)).toHaveLength(1);
|
||||
});
|
||||
|
||||
test("should be able to get index stats", async () => {
|
||||
await tbl.createIndex("id");
|
||||
|
||||
@@ -785,11 +805,26 @@ describe.each([arrow13, arrow14, arrow15, arrow16, arrow17])(
|
||||
];
|
||||
const table = await db.createTable("test", data);
|
||||
|
||||
expect(table.search("hello").toArray()).rejects.toThrow(
|
||||
expect(table.search("hello", "vector").toArray()).rejects.toThrow(
|
||||
"No embedding functions are defined in the table",
|
||||
);
|
||||
});
|
||||
|
||||
test("full text search if no embedding function provided", async () => {
|
||||
const db = await connect(tmpDir.name);
|
||||
const data = [
|
||||
{ text: "hello world", vector: [0.1, 0.2, 0.3] },
|
||||
{ text: "goodbye world", vector: [0.4, 0.5, 0.6] },
|
||||
];
|
||||
const table = await db.createTable("test", data);
|
||||
await table.createIndex("text", {
|
||||
config: Index.fts(),
|
||||
});
|
||||
|
||||
const results = await table.search("hello").toArray();
|
||||
expect(results[0].text).toBe(data[0].text);
|
||||
});
|
||||
|
||||
test.each([
|
||||
[0.4, 0.5, 0.599], // number[]
|
||||
Float32Array.of(0.4, 0.5, 0.599), // Float32Array
|
||||
|
||||
64
nodejs/examples/custom_embedding_function.ts
Normal file
64
nodejs/examples/custom_embedding_function.ts
Normal file
@@ -0,0 +1,64 @@
|
||||
// --8<-- [start:imports]
|
||||
import * as lancedb from "@lancedb/lancedb";
|
||||
import {
|
||||
LanceSchema,
|
||||
TextEmbeddingFunction,
|
||||
getRegistry,
|
||||
register,
|
||||
} from "@lancedb/lancedb/embedding";
|
||||
import { pipeline } from "@xenova/transformers";
|
||||
// --8<-- [end:imports]
|
||||
|
||||
// --8<-- [start:embedding_impl]
|
||||
@register("sentence-transformers")
|
||||
class SentenceTransformersEmbeddings extends TextEmbeddingFunction {
|
||||
name = "Xenova/all-miniLM-L6-v2";
|
||||
#ndims!: number;
|
||||
extractor: any;
|
||||
|
||||
async init() {
|
||||
this.extractor = await pipeline("feature-extraction", this.name);
|
||||
this.#ndims = await this.generateEmbeddings(["hello"]).then(
|
||||
(e) => e[0].length,
|
||||
);
|
||||
}
|
||||
|
||||
ndims() {
|
||||
return this.#ndims;
|
||||
}
|
||||
|
||||
toJSON() {
|
||||
return {
|
||||
name: this.name,
|
||||
};
|
||||
}
|
||||
async generateEmbeddings(texts: string[]) {
|
||||
const output = await this.extractor(texts, {
|
||||
pooling: "mean",
|
||||
normalize: true,
|
||||
});
|
||||
return output.tolist();
|
||||
}
|
||||
}
|
||||
// -8<-- [end:embedding_impl]
|
||||
|
||||
// --8<-- [start:call_custom_function]
|
||||
const registry = getRegistry();
|
||||
|
||||
const sentenceTransformer = await registry
|
||||
.get<SentenceTransformersEmbeddings>("sentence-transformers")!
|
||||
.create();
|
||||
|
||||
const schema = LanceSchema({
|
||||
vector: sentenceTransformer.vectorField(),
|
||||
text: sentenceTransformer.sourceField(),
|
||||
});
|
||||
|
||||
const db = await lancedb.connect("/tmp/db");
|
||||
const table = await db.createEmptyTable("table", schema, { mode: "overwrite" });
|
||||
|
||||
await table.add([{ text: "hello" }, { text: "world" }]);
|
||||
|
||||
const results = await table.search("greeting").limit(1).toArray();
|
||||
console.log(results[0].text);
|
||||
// -8<-- [end:call_custom_function]
|
||||
52
nodejs/examples/full_text_search.ts
Normal file
52
nodejs/examples/full_text_search.ts
Normal file
@@ -0,0 +1,52 @@
|
||||
// Copyright 2024 Lance Developers.
|
||||
//
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
import * as lancedb from "@lancedb/lancedb";
|
||||
|
||||
const db = await lancedb.connect("data/sample-lancedb");
|
||||
|
||||
const words = [
|
||||
"apple",
|
||||
"banana",
|
||||
"cherry",
|
||||
"date",
|
||||
"elderberry",
|
||||
"fig",
|
||||
"grape",
|
||||
];
|
||||
|
||||
const data = Array.from({ length: 10_000 }, (_, i) => ({
|
||||
vector: Array(1536).fill(i),
|
||||
id: i,
|
||||
item: `item ${i}`,
|
||||
strId: `${i}`,
|
||||
doc: words[i % words.length],
|
||||
}));
|
||||
|
||||
const tbl = await db.createTable("myVectors", data, { mode: "overwrite" });
|
||||
|
||||
await tbl.createIndex("doc", {
|
||||
config: lancedb.Index.fts(),
|
||||
});
|
||||
|
||||
// --8<-- [start:full_text_search]
|
||||
let result = await tbl
|
||||
.search("apple")
|
||||
.select(["id", "doc"])
|
||||
.limit(10)
|
||||
.toArray();
|
||||
console.log(result);
|
||||
// --8<-- [end:full_text_search]
|
||||
|
||||
console.log("SQL search: done");
|
||||
42
nodejs/examples/package-lock.json
generated
42
nodejs/examples/package-lock.json
generated
@@ -10,7 +10,11 @@
|
||||
"license": "Apache-2.0",
|
||||
"dependencies": {
|
||||
"@lancedb/lancedb": "file:../",
|
||||
"@xenova/transformers": "^2.17.2"
|
||||
"@xenova/transformers": "^2.17.2",
|
||||
"tsc": "^2.0.4"
|
||||
},
|
||||
"devDependencies": {
|
||||
"typescript": "^5.5.4"
|
||||
},
|
||||
"peerDependencies": {
|
||||
"typescript": "^5.0.0"
|
||||
@@ -18,7 +22,7 @@
|
||||
},
|
||||
"..": {
|
||||
"name": "@lancedb/lancedb",
|
||||
"version": "0.7.1",
|
||||
"version": "0.8.0",
|
||||
"cpu": [
|
||||
"x64",
|
||||
"arm64"
|
||||
@@ -43,26 +47,30 @@
|
||||
"@types/axios": "^0.14.0",
|
||||
"@types/jest": "^29.1.2",
|
||||
"@types/tmp": "^0.2.6",
|
||||
"apache-arrow-old": "npm:apache-arrow@13.0.0",
|
||||
"apache-arrow-13": "npm:apache-arrow@13.0.0",
|
||||
"apache-arrow-14": "npm:apache-arrow@14.0.0",
|
||||
"apache-arrow-15": "npm:apache-arrow@15.0.0",
|
||||
"apache-arrow-16": "npm:apache-arrow@16.0.0",
|
||||
"apache-arrow-17": "npm:apache-arrow@17.0.0",
|
||||
"eslint": "^8.57.0",
|
||||
"jest": "^29.7.0",
|
||||
"shx": "^0.3.4",
|
||||
"tmp": "^0.2.3",
|
||||
"ts-jest": "^29.1.2",
|
||||
"typedoc": "^0.25.7",
|
||||
"typedoc-plugin-markdown": "^3.17.1",
|
||||
"typescript": "^5.3.3",
|
||||
"typedoc": "^0.26.4",
|
||||
"typedoc-plugin-markdown": "^4.2.1",
|
||||
"typescript": "^5.5.4",
|
||||
"typescript-eslint": "^7.1.0"
|
||||
},
|
||||
"engines": {
|
||||
"node": ">= 18"
|
||||
},
|
||||
"optionalDependencies": {
|
||||
"@xenova/transformers": "^2.17.2",
|
||||
"@xenova/transformers": ">=2.17 < 3",
|
||||
"openai": "^4.29.2"
|
||||
},
|
||||
"peerDependencies": {
|
||||
"apache-arrow": "^15.0.0"
|
||||
"apache-arrow": ">=13.0.0 <=17.0.0"
|
||||
}
|
||||
},
|
||||
"node_modules/@huggingface/jinja": {
|
||||
@@ -785,6 +793,15 @@
|
||||
"b4a": "^1.6.4"
|
||||
}
|
||||
},
|
||||
"node_modules/tsc": {
|
||||
"version": "2.0.4",
|
||||
"resolved": "https://registry.npmjs.org/tsc/-/tsc-2.0.4.tgz",
|
||||
"integrity": "sha512-fzoSieZI5KKJVBYGvwbVZs/J5za84f2lSTLPYf6AGiIf43tZ3GNrI1QzTLcjtyDDP4aLxd46RTZq1nQxe7+k5Q==",
|
||||
"license": "MIT",
|
||||
"bin": {
|
||||
"tsc": "bin/tsc"
|
||||
}
|
||||
},
|
||||
"node_modules/tunnel-agent": {
|
||||
"version": "0.6.0",
|
||||
"resolved": "https://registry.npmjs.org/tunnel-agent/-/tunnel-agent-0.6.0.tgz",
|
||||
@@ -797,10 +814,11 @@
|
||||
}
|
||||
},
|
||||
"node_modules/typescript": {
|
||||
"version": "5.5.2",
|
||||
"resolved": "https://registry.npmjs.org/typescript/-/typescript-5.5.2.tgz",
|
||||
"integrity": "sha512-NcRtPEOsPFFWjobJEtfihkLCZCXZt/os3zf8nTxjVH3RvTSxjrCamJpbExGvYOF+tFHc3pA65qpdwPbzjohhew==",
|
||||
"peer": true,
|
||||
"version": "5.5.4",
|
||||
"resolved": "https://registry.npmjs.org/typescript/-/typescript-5.5.4.tgz",
|
||||
"integrity": "sha512-Mtq29sKDAEYP7aljRgtPOpTvOfbwRWlS6dPRzwjdE+C0R4brX/GUyhHSecbHMFLNBLcJIPt9nl9yG5TZ1weH+Q==",
|
||||
"dev": true,
|
||||
"license": "Apache-2.0",
|
||||
"bin": {
|
||||
"tsc": "bin/tsc",
|
||||
"tsserver": "bin/tsserver"
|
||||
|
||||
@@ -13,7 +13,16 @@
|
||||
"@lancedb/lancedb": "file:../",
|
||||
"@xenova/transformers": "^2.17.2"
|
||||
},
|
||||
"peerDependencies": {
|
||||
"typescript": "^5.0.0"
|
||||
"devDependencies": {
|
||||
"typescript": "^5.5.4"
|
||||
},
|
||||
"compilerOptions": {
|
||||
"target": "ESNext",
|
||||
"module": "ESNext",
|
||||
"moduleResolution": "Node",
|
||||
"strict": true,
|
||||
"esModuleInterop": true,
|
||||
"skipLibCheck": true,
|
||||
"forceConsistentCasingInFileNames": true
|
||||
}
|
||||
}
|
||||
|
||||
@@ -32,6 +32,7 @@ const _results2 = await tbl
|
||||
.distanceType("cosine")
|
||||
.limit(10)
|
||||
.toArray();
|
||||
console.log(_results2);
|
||||
// --8<-- [end:search2]
|
||||
|
||||
console.log("search: done");
|
||||
|
||||
@@ -103,50 +103,11 @@ export type IntoVector =
|
||||
| number[]
|
||||
| Promise<Float32Array | Float64Array | number[]>;
|
||||
|
||||
export type FloatLike =
|
||||
| import("apache-arrow-13").Float
|
||||
| import("apache-arrow-14").Float
|
||||
| import("apache-arrow-15").Float
|
||||
| import("apache-arrow-16").Float
|
||||
| import("apache-arrow-17").Float;
|
||||
export type DataTypeLike =
|
||||
| import("apache-arrow-13").DataType
|
||||
| import("apache-arrow-14").DataType
|
||||
| import("apache-arrow-15").DataType
|
||||
| import("apache-arrow-16").DataType
|
||||
| import("apache-arrow-17").DataType;
|
||||
|
||||
export function isArrowTable(value: object): value is TableLike {
|
||||
if (value instanceof ArrowTable) return true;
|
||||
return "schema" in value && "batches" in value;
|
||||
}
|
||||
|
||||
export function isDataType(value: unknown): value is DataTypeLike {
|
||||
return (
|
||||
value instanceof DataType ||
|
||||
DataType.isNull(value) ||
|
||||
DataType.isInt(value) ||
|
||||
DataType.isFloat(value) ||
|
||||
DataType.isBinary(value) ||
|
||||
DataType.isLargeBinary(value) ||
|
||||
DataType.isUtf8(value) ||
|
||||
DataType.isLargeUtf8(value) ||
|
||||
DataType.isBool(value) ||
|
||||
DataType.isDecimal(value) ||
|
||||
DataType.isDate(value) ||
|
||||
DataType.isTime(value) ||
|
||||
DataType.isTimestamp(value) ||
|
||||
DataType.isInterval(value) ||
|
||||
DataType.isDuration(value) ||
|
||||
DataType.isList(value) ||
|
||||
DataType.isStruct(value) ||
|
||||
DataType.isUnion(value) ||
|
||||
DataType.isFixedSizeBinary(value) ||
|
||||
DataType.isFixedSizeList(value) ||
|
||||
DataType.isMap(value) ||
|
||||
DataType.isDictionary(value)
|
||||
);
|
||||
}
|
||||
export function isNull(value: unknown): value is Null {
|
||||
return value instanceof Null || DataType.isNull(value);
|
||||
}
|
||||
|
||||
@@ -44,10 +44,20 @@ export interface CreateTableOptions {
|
||||
* The available options are described at https://lancedb.github.io/lancedb/guides/storage/
|
||||
*/
|
||||
storageOptions?: Record<string, string>;
|
||||
/**
|
||||
* The version of the data storage format to use.
|
||||
*
|
||||
* The default is `legacy`, which is Lance format v1.
|
||||
* `stable` is the new format, which is Lance format v2.
|
||||
*/
|
||||
dataStorageVersion?: string;
|
||||
|
||||
/**
|
||||
* If true then data files will be written with the legacy format
|
||||
*
|
||||
* The default is true while the new format is in beta
|
||||
*
|
||||
* Deprecated.
|
||||
*/
|
||||
useLegacyFormat?: boolean;
|
||||
schema?: SchemaLike;
|
||||
@@ -247,12 +257,19 @@ export class LocalConnection extends Connection {
|
||||
throw new Error("data is required");
|
||||
}
|
||||
const { buf, mode } = await Table.parseTableData(data, options);
|
||||
let dataStorageVersion = "legacy";
|
||||
if (options?.dataStorageVersion !== undefined) {
|
||||
dataStorageVersion = options.dataStorageVersion;
|
||||
} else if (options?.useLegacyFormat !== undefined) {
|
||||
dataStorageVersion = options.useLegacyFormat ? "legacy" : "stable";
|
||||
}
|
||||
|
||||
const innerTable = await this.inner.createTable(
|
||||
nameOrOptions,
|
||||
buf,
|
||||
mode,
|
||||
cleanseStorageOptions(options?.storageOptions),
|
||||
options?.useLegacyFormat,
|
||||
dataStorageVersion,
|
||||
);
|
||||
|
||||
return new LocalTable(innerTable);
|
||||
@@ -276,6 +293,13 @@ export class LocalConnection extends Connection {
|
||||
metadata = registry.getTableMetadata([embeddingFunction]);
|
||||
}
|
||||
|
||||
let dataStorageVersion = "legacy";
|
||||
if (options?.dataStorageVersion !== undefined) {
|
||||
dataStorageVersion = options.dataStorageVersion;
|
||||
} else if (options?.useLegacyFormat !== undefined) {
|
||||
dataStorageVersion = options.useLegacyFormat ? "legacy" : "stable";
|
||||
}
|
||||
|
||||
const table = makeEmptyTable(schema, metadata);
|
||||
const buf = await fromTableToBuffer(table);
|
||||
const innerTable = await this.inner.createEmptyTable(
|
||||
@@ -283,7 +307,7 @@ export class LocalConnection extends Connection {
|
||||
buf,
|
||||
mode,
|
||||
cleanseStorageOptions(options?.storageOptions),
|
||||
options?.useLegacyFormat,
|
||||
dataStorageVersion,
|
||||
);
|
||||
return new LocalTable(innerTable);
|
||||
}
|
||||
|
||||
@@ -15,13 +15,12 @@
|
||||
import "reflect-metadata";
|
||||
import {
|
||||
DataType,
|
||||
DataTypeLike,
|
||||
Field,
|
||||
FixedSizeList,
|
||||
Float,
|
||||
Float32,
|
||||
FloatLike,
|
||||
type IntoVector,
|
||||
isDataType,
|
||||
Utf8,
|
||||
isFixedSizeList,
|
||||
isFloat,
|
||||
newVectorType,
|
||||
@@ -93,11 +92,12 @@ export abstract class EmbeddingFunction<
|
||||
* @see {@link lancedb.LanceSchema}
|
||||
*/
|
||||
sourceField(
|
||||
optionsOrDatatype: Partial<FieldOptions> | DataTypeLike,
|
||||
): [DataTypeLike, Map<string, EmbeddingFunction>] {
|
||||
let datatype = isDataType(optionsOrDatatype)
|
||||
? optionsOrDatatype
|
||||
: optionsOrDatatype?.datatype;
|
||||
optionsOrDatatype: Partial<FieldOptions> | DataType,
|
||||
): [DataType, Map<string, EmbeddingFunction>] {
|
||||
let datatype =
|
||||
"datatype" in optionsOrDatatype
|
||||
? optionsOrDatatype.datatype
|
||||
: optionsOrDatatype;
|
||||
if (!datatype) {
|
||||
throw new Error("Datatype is required");
|
||||
}
|
||||
@@ -123,15 +123,17 @@ export abstract class EmbeddingFunction<
|
||||
let dims: number | undefined = this.ndims();
|
||||
|
||||
// `func.vectorField(new Float32())`
|
||||
if (isDataType(optionsOrDatatype)) {
|
||||
dtype = optionsOrDatatype;
|
||||
if (optionsOrDatatype === undefined) {
|
||||
dtype = new Float32();
|
||||
} else if (!("datatype" in optionsOrDatatype)) {
|
||||
dtype = sanitizeType(optionsOrDatatype);
|
||||
} else {
|
||||
// `func.vectorField({
|
||||
// datatype: new Float32(),
|
||||
// dims: 10
|
||||
// })`
|
||||
dims = dims ?? optionsOrDatatype?.dims;
|
||||
dtype = optionsOrDatatype?.datatype;
|
||||
dtype = sanitizeType(optionsOrDatatype?.datatype);
|
||||
}
|
||||
|
||||
if (dtype !== undefined) {
|
||||
@@ -173,7 +175,7 @@ export abstract class EmbeddingFunction<
|
||||
}
|
||||
|
||||
/** The datatype of the embeddings */
|
||||
abstract embeddingDataType(): FloatLike;
|
||||
abstract embeddingDataType(): Float;
|
||||
|
||||
/**
|
||||
* Creates a vector representation for the given values.
|
||||
@@ -192,6 +194,38 @@ export abstract class EmbeddingFunction<
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* an abstract class for implementing embedding functions that take text as input
|
||||
*/
|
||||
export abstract class TextEmbeddingFunction<
|
||||
M extends FunctionOptions = FunctionOptions,
|
||||
> extends EmbeddingFunction<string, M> {
|
||||
//** Generate the embeddings for the given texts */
|
||||
abstract generateEmbeddings(
|
||||
texts: string[],
|
||||
// biome-ignore lint/suspicious/noExplicitAny: we don't know what the implementor will do
|
||||
...args: any[]
|
||||
): Promise<number[][] | Float32Array[] | Float64Array[]>;
|
||||
|
||||
async computeQueryEmbeddings(data: string): Promise<Awaited<IntoVector>> {
|
||||
return this.generateEmbeddings([data]).then((data) => data[0]);
|
||||
}
|
||||
|
||||
embeddingDataType(): Float {
|
||||
return new Float32();
|
||||
}
|
||||
|
||||
override sourceField(): [DataType, Map<string, EmbeddingFunction>] {
|
||||
return super.sourceField(new Utf8());
|
||||
}
|
||||
|
||||
computeSourceEmbeddings(
|
||||
data: string[],
|
||||
): Promise<number[][] | Float32Array[] | Float64Array[]> {
|
||||
return this.generateEmbeddings(data);
|
||||
}
|
||||
}
|
||||
|
||||
export interface FieldOptions<T extends DataType = DataType> {
|
||||
datatype: T;
|
||||
dims?: number;
|
||||
|
||||
@@ -13,12 +13,11 @@
|
||||
// limitations under the License.
|
||||
|
||||
import { Field, Schema } from "../arrow";
|
||||
import { isDataType } from "../arrow";
|
||||
import { sanitizeType } from "../sanitize";
|
||||
import { EmbeddingFunction } from "./embedding_function";
|
||||
import { EmbeddingFunctionConfig, getRegistry } from "./registry";
|
||||
|
||||
export { EmbeddingFunction } from "./embedding_function";
|
||||
export { EmbeddingFunction, TextEmbeddingFunction } from "./embedding_function";
|
||||
|
||||
// We need to explicitly export '*' so that the `register` decorator actually registers the class.
|
||||
export * from "./openai";
|
||||
@@ -57,15 +56,15 @@ export function LanceSchema(
|
||||
Partial<EmbeddingFunctionConfig>
|
||||
>();
|
||||
Object.entries(fields).forEach(([key, value]) => {
|
||||
if (isDataType(value)) {
|
||||
arrowFields.push(new Field(key, sanitizeType(value), true));
|
||||
} else {
|
||||
if (Array.isArray(value)) {
|
||||
const [dtype, metadata] = value as [
|
||||
object,
|
||||
Map<string, EmbeddingFunction>,
|
||||
];
|
||||
arrowFields.push(new Field(key, sanitizeType(dtype), true));
|
||||
parseEmbeddingFunctions(embeddingFunctions, key, metadata);
|
||||
} else {
|
||||
arrowFields.push(new Field(key, sanitizeType(value), true));
|
||||
}
|
||||
});
|
||||
const registry = getRegistry();
|
||||
|
||||
@@ -13,7 +13,7 @@
|
||||
// limitations under the License.
|
||||
|
||||
import type OpenAI from "openai";
|
||||
import { type EmbeddingCreateParams } from "openai/resources";
|
||||
import type { EmbeddingCreateParams } from "openai/resources/index";
|
||||
import { Float, Float32 } from "../arrow";
|
||||
import { EmbeddingFunction } from "./embedding_function";
|
||||
import { register } from "./registry";
|
||||
|
||||
@@ -37,6 +37,13 @@ interface EmbeddingFunctionCreate<T extends EmbeddingFunction> {
|
||||
export class EmbeddingFunctionRegistry {
|
||||
#functions = new Map<string, EmbeddingFunctionConstructor>();
|
||||
|
||||
/**
|
||||
* Get the number of registered functions
|
||||
*/
|
||||
length() {
|
||||
return this.#functions.size;
|
||||
}
|
||||
|
||||
/**
|
||||
* Register an embedding function
|
||||
* @param name The name of the function
|
||||
|
||||
@@ -59,7 +59,7 @@ export {
|
||||
|
||||
export { Index, IndexOptions, IvfPqOptions } from "./indices";
|
||||
|
||||
export { Table, AddDataOptions, UpdateOptions } from "./table";
|
||||
export { Table, AddDataOptions, UpdateOptions, OptimizeOptions } from "./table";
|
||||
|
||||
export * as embedding from "./embedding";
|
||||
|
||||
|
||||
@@ -175,6 +175,45 @@ export class Index {
|
||||
static btree() {
|
||||
return new Index(LanceDbIndex.btree());
|
||||
}
|
||||
|
||||
/**
|
||||
* Create a bitmap index.
|
||||
*
|
||||
* A `Bitmap` index stores a bitmap for each distinct value in the column for every row.
|
||||
*
|
||||
* This index works best for low-cardinality columns, where the number of unique values
|
||||
* is small (i.e., less than a few hundreds).
|
||||
*/
|
||||
static bitmap() {
|
||||
return new Index(LanceDbIndex.bitmap());
|
||||
}
|
||||
|
||||
/**
|
||||
* Create a label list index.
|
||||
*
|
||||
* LabelList index is a scalar index that can be used on `List<T>` columns to
|
||||
* support queries with `array_contains_all` and `array_contains_any`
|
||||
* using an underlying bitmap index.
|
||||
*/
|
||||
static labelList() {
|
||||
return new Index(LanceDbIndex.labelList());
|
||||
}
|
||||
|
||||
/**
|
||||
* Create a full text search index
|
||||
*
|
||||
* A full text search index is an index on a string column, so that you can conduct full
|
||||
* text searches on the column.
|
||||
*
|
||||
* The results of a full text search are ordered by relevance measured by BM25.
|
||||
*
|
||||
* You can combine filters with full text search.
|
||||
*
|
||||
* For now, the full text search index only supports English, and doesn't support phrase search.
|
||||
*/
|
||||
static fts() {
|
||||
return new Index(LanceDbIndex.fts());
|
||||
}
|
||||
}
|
||||
|
||||
export interface IndexOptions {
|
||||
|
||||
@@ -88,6 +88,19 @@ export interface QueryExecutionOptions {
|
||||
maxBatchLength?: number;
|
||||
}
|
||||
|
||||
/**
|
||||
* Options that control the behavior of a full text search
|
||||
*/
|
||||
export interface FullTextSearchOptions {
|
||||
/**
|
||||
* The columns to search
|
||||
*
|
||||
* If not specified, all indexed columns will be searched.
|
||||
* For now, only one column can be searched.
|
||||
*/
|
||||
columns?: string | string[];
|
||||
}
|
||||
|
||||
/** Common methods supported by all query types */
|
||||
export class QueryBase<NativeQueryType extends NativeQuery | NativeVectorQuery>
|
||||
implements AsyncIterable<RecordBatch>
|
||||
@@ -134,6 +147,25 @@ export class QueryBase<NativeQueryType extends NativeQuery | NativeVectorQuery>
|
||||
return this.where(predicate);
|
||||
}
|
||||
|
||||
fullTextSearch(
|
||||
query: string,
|
||||
options?: Partial<FullTextSearchOptions>,
|
||||
): this {
|
||||
let columns: string[] | null = null;
|
||||
if (options) {
|
||||
if (typeof options.columns === "string") {
|
||||
columns = [options.columns];
|
||||
} else if (Array.isArray(options.columns)) {
|
||||
columns = options.columns;
|
||||
}
|
||||
}
|
||||
|
||||
this.doCall((inner: NativeQueryType) =>
|
||||
inner.fullTextSearch(query, columns),
|
||||
);
|
||||
return this;
|
||||
}
|
||||
|
||||
/**
|
||||
* Return only the specified columns.
|
||||
*
|
||||
|
||||
@@ -340,8 +340,14 @@ export function sanitizeType(typeLike: unknown): DataType<any> {
|
||||
if (typeof typeLike !== "object" || typeLike === null) {
|
||||
throw Error("Expected a Type but object was null/undefined");
|
||||
}
|
||||
if (!("typeId" in typeLike) || !(typeof typeLike.typeId !== "function")) {
|
||||
throw Error("Expected a Type to have a typeId function");
|
||||
if (
|
||||
!("typeId" in typeLike) ||
|
||||
!(
|
||||
typeof typeLike.typeId !== "function" ||
|
||||
typeof typeLike.typeId !== "number"
|
||||
)
|
||||
) {
|
||||
throw Error("Expected a Type to have a typeId property");
|
||||
}
|
||||
let typeId: Type;
|
||||
if (typeof typeLike.typeId === "function") {
|
||||
|
||||
@@ -270,22 +270,23 @@ export abstract class Table {
|
||||
* @returns {Query} A builder that can be used to parameterize the query
|
||||
*/
|
||||
abstract query(): Query;
|
||||
|
||||
/**
|
||||
* Create a search query to find the nearest neighbors
|
||||
* of the given query vector
|
||||
* @param {string} query - the query. This will be converted to a vector using the table's provided embedding function
|
||||
* @note If no embedding functions are defined in the table, this will error when collecting the results.
|
||||
* of the given query
|
||||
* @param {string | IntoVector} query - the query, a vector or string
|
||||
* @param {string} queryType - the type of the query, "vector", "fts", or "auto"
|
||||
* @param {string | string[]} ftsColumns - the columns to search in for full text search
|
||||
* for now, only one column can be searched at a time.
|
||||
*
|
||||
* This is just a convenience method for calling `.query().nearestTo(await myEmbeddingFunction(query))`
|
||||
* when "auto" is used, if the query is a string and an embedding function is defined, it will be treated as a vector query
|
||||
* if the query is a string and no embedding function is defined, it will be treated as a full text search query
|
||||
*/
|
||||
abstract search(query: string): VectorQuery;
|
||||
/**
|
||||
* Create a search query to find the nearest neighbors
|
||||
* of the given query vector
|
||||
* @param {IntoVector} query - the query vector
|
||||
* This is just a convenience method for calling `.query().nearestTo(query)`
|
||||
*/
|
||||
abstract search(query: IntoVector): VectorQuery;
|
||||
abstract search(
|
||||
query: string | IntoVector,
|
||||
queryType?: string,
|
||||
ftsColumns?: string | string[],
|
||||
): VectorQuery | Query;
|
||||
/**
|
||||
* Search the table with a given query vector.
|
||||
*
|
||||
@@ -581,27 +582,50 @@ export class LocalTable extends Table {
|
||||
query(): Query {
|
||||
return new Query(this.inner);
|
||||
}
|
||||
search(query: string | IntoVector): VectorQuery {
|
||||
if (typeof query !== "string") {
|
||||
return this.vectorSearch(query);
|
||||
} else {
|
||||
const queryPromise = this.getEmbeddingFunctions().then(
|
||||
async (functions) => {
|
||||
// TODO: Support multiple embedding functions
|
||||
const embeddingFunc: EmbeddingFunctionConfig | undefined = functions
|
||||
.values()
|
||||
.next().value;
|
||||
if (!embeddingFunc) {
|
||||
return Promise.reject(
|
||||
new Error("No embedding functions are defined in the table"),
|
||||
);
|
||||
}
|
||||
return await embeddingFunc.function.computeQueryEmbeddings(query);
|
||||
},
|
||||
);
|
||||
|
||||
return this.query().nearestTo(queryPromise);
|
||||
search(
|
||||
query: string | IntoVector,
|
||||
queryType: string = "auto",
|
||||
ftsColumns?: string | string[],
|
||||
): VectorQuery | Query {
|
||||
if (typeof query !== "string") {
|
||||
if (queryType === "fts") {
|
||||
throw new Error("Cannot perform full text search on a vector query");
|
||||
}
|
||||
return this.vectorSearch(query);
|
||||
}
|
||||
|
||||
// If the query is a string, we need to determine if it is a vector query or a full text search query
|
||||
if (queryType === "fts") {
|
||||
return this.query().fullTextSearch(query, {
|
||||
columns: ftsColumns,
|
||||
});
|
||||
}
|
||||
|
||||
// The query type is auto or vector
|
||||
// fall back to full text search if no embedding functions are defined and the query is a string
|
||||
if (queryType === "auto" && getRegistry().length() === 0) {
|
||||
return this.query().fullTextSearch(query, {
|
||||
columns: ftsColumns,
|
||||
});
|
||||
}
|
||||
|
||||
const queryPromise = this.getEmbeddingFunctions().then(
|
||||
async (functions) => {
|
||||
// TODO: Support multiple embedding functions
|
||||
const embeddingFunc: EmbeddingFunctionConfig | undefined = functions
|
||||
.values()
|
||||
.next().value;
|
||||
if (!embeddingFunc) {
|
||||
return Promise.reject(
|
||||
new Error("No embedding functions are defined in the table"),
|
||||
);
|
||||
}
|
||||
return await embeddingFunc.function.computeQueryEmbeddings(query);
|
||||
},
|
||||
);
|
||||
|
||||
return this.query().nearestTo(queryPromise);
|
||||
}
|
||||
|
||||
vectorSearch(vector: IntoVector): VectorQuery {
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
{
|
||||
"name": "@lancedb/lancedb-darwin-arm64",
|
||||
"version": "0.7.2",
|
||||
"version": "0.10.0-beta.0",
|
||||
"os": ["darwin"],
|
||||
"cpu": ["arm64"],
|
||||
"main": "lancedb.darwin-arm64.node",
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
{
|
||||
"name": "@lancedb/lancedb-darwin-x64",
|
||||
"version": "0.7.2",
|
||||
"version": "0.10.0-beta.0",
|
||||
"os": ["darwin"],
|
||||
"cpu": ["x64"],
|
||||
"main": "lancedb.darwin-x64.node",
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
{
|
||||
"name": "@lancedb/lancedb-linux-arm64-gnu",
|
||||
"version": "0.7.2",
|
||||
"version": "0.10.0-beta.0",
|
||||
"os": ["linux"],
|
||||
"cpu": ["arm64"],
|
||||
"main": "lancedb.linux-arm64-gnu.node",
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
{
|
||||
"name": "@lancedb/lancedb-linux-x64-gnu",
|
||||
"version": "0.7.2",
|
||||
"version": "0.10.0-beta.0",
|
||||
"os": ["linux"],
|
||||
"cpu": ["x64"],
|
||||
"main": "lancedb.linux-x64-gnu.node",
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
{
|
||||
"name": "@lancedb/lancedb-win32-x64-msvc",
|
||||
"version": "0.7.2",
|
||||
"version": "0.10.0-beta.0",
|
||||
"os": ["win32"],
|
||||
"cpu": ["x64"],
|
||||
"main": "lancedb.win32-x64-msvc.node",
|
||||
|
||||
13
nodejs/package-lock.json
generated
13
nodejs/package-lock.json
generated
@@ -1,12 +1,12 @@
|
||||
{
|
||||
"name": "@lancedb/lancedb",
|
||||
"version": "0.7.2",
|
||||
"version": "0.8.0",
|
||||
"lockfileVersion": 3,
|
||||
"requires": true,
|
||||
"packages": {
|
||||
"": {
|
||||
"name": "@lancedb/lancedb",
|
||||
"version": "0.7.2",
|
||||
"version": "0.8.0",
|
||||
"cpu": [
|
||||
"x64",
|
||||
"arm64"
|
||||
@@ -43,7 +43,7 @@
|
||||
"ts-jest": "^29.1.2",
|
||||
"typedoc": "^0.26.4",
|
||||
"typedoc-plugin-markdown": "^4.2.1",
|
||||
"typescript": "^5.3.3",
|
||||
"typescript": "^5.5.4",
|
||||
"typescript-eslint": "^7.1.0"
|
||||
},
|
||||
"engines": {
|
||||
@@ -9292,10 +9292,11 @@
|
||||
}
|
||||
},
|
||||
"node_modules/typescript": {
|
||||
"version": "5.3.3",
|
||||
"resolved": "https://registry.npmjs.org/typescript/-/typescript-5.3.3.tgz",
|
||||
"integrity": "sha512-pXWcraxM0uxAS+tN0AG/BF2TyqmHO014Z070UsJ+pFvYuRSq8KH8DmWpnbXe0pEPDHXZV3FcAbJkijJ5oNEnWw==",
|
||||
"version": "5.5.4",
|
||||
"resolved": "https://registry.npmjs.org/typescript/-/typescript-5.5.4.tgz",
|
||||
"integrity": "sha512-Mtq29sKDAEYP7aljRgtPOpTvOfbwRWlS6dPRzwjdE+C0R4brX/GUyhHSecbHMFLNBLcJIPt9nl9yG5TZ1weH+Q==",
|
||||
"dev": true,
|
||||
"license": "Apache-2.0",
|
||||
"bin": {
|
||||
"tsc": "bin/tsc",
|
||||
"tsserver": "bin/tsserver"
|
||||
|
||||
@@ -10,7 +10,7 @@
|
||||
"vector database",
|
||||
"ann"
|
||||
],
|
||||
"version": "0.7.2",
|
||||
"version": "0.10.0-beta.0",
|
||||
"main": "dist/index.js",
|
||||
"exports": {
|
||||
".": "./dist/index.js",
|
||||
@@ -53,7 +53,7 @@
|
||||
"ts-jest": "^29.1.2",
|
||||
"typedoc": "^0.26.4",
|
||||
"typedoc-plugin-markdown": "^4.2.1",
|
||||
"typescript": "^5.3.3",
|
||||
"typescript": "^5.5.4",
|
||||
"typescript-eslint": "^7.1.0"
|
||||
},
|
||||
"ava": {
|
||||
|
||||
@@ -13,13 +13,16 @@
|
||||
// limitations under the License.
|
||||
|
||||
use std::collections::HashMap;
|
||||
use std::str::FromStr;
|
||||
|
||||
use napi::bindgen_prelude::*;
|
||||
use napi_derive::*;
|
||||
|
||||
use crate::table::Table;
|
||||
use crate::ConnectionOptions;
|
||||
use lancedb::connection::{ConnectBuilder, Connection as LanceDBConnection, CreateTableMode};
|
||||
use lancedb::connection::{
|
||||
ConnectBuilder, Connection as LanceDBConnection, CreateTableMode, LanceFileVersion,
|
||||
};
|
||||
use lancedb::ipc::{ipc_file_to_batches, ipc_file_to_schema};
|
||||
|
||||
#[napi]
|
||||
@@ -120,7 +123,7 @@ impl Connection {
|
||||
buf: Buffer,
|
||||
mode: String,
|
||||
storage_options: Option<HashMap<String, String>>,
|
||||
use_legacy_format: Option<bool>,
|
||||
data_storage_options: Option<String>,
|
||||
) -> napi::Result<Table> {
|
||||
let batches = ipc_file_to_batches(buf.to_vec())
|
||||
.map_err(|e| napi::Error::from_reason(format!("Failed to read IPC file: {}", e)))?;
|
||||
@@ -131,8 +134,11 @@ impl Connection {
|
||||
builder = builder.storage_option(key, value);
|
||||
}
|
||||
}
|
||||
if let Some(use_legacy_format) = use_legacy_format {
|
||||
builder = builder.use_legacy_format(use_legacy_format);
|
||||
if let Some(data_storage_option) = data_storage_options.as_ref() {
|
||||
builder = builder.data_storage_version(
|
||||
LanceFileVersion::from_str(data_storage_option)
|
||||
.map_err(|e| napi::Error::from_reason(format!("{}", e)))?,
|
||||
);
|
||||
}
|
||||
let tbl = builder
|
||||
.execute()
|
||||
@@ -148,7 +154,7 @@ impl Connection {
|
||||
schema_buf: Buffer,
|
||||
mode: String,
|
||||
storage_options: Option<HashMap<String, String>>,
|
||||
use_legacy_format: Option<bool>,
|
||||
data_storage_options: Option<String>,
|
||||
) -> napi::Result<Table> {
|
||||
let schema = ipc_file_to_schema(schema_buf.to_vec()).map_err(|e| {
|
||||
napi::Error::from_reason(format!("Failed to marshal schema from JS to Rust: {}", e))
|
||||
@@ -163,8 +169,11 @@ impl Connection {
|
||||
builder = builder.storage_option(key, value);
|
||||
}
|
||||
}
|
||||
if let Some(use_legacy_format) = use_legacy_format {
|
||||
builder = builder.use_legacy_format(use_legacy_format);
|
||||
if let Some(data_storage_option) = data_storage_options.as_ref() {
|
||||
builder = builder.data_storage_version(
|
||||
LanceFileVersion::from_str(data_storage_option)
|
||||
.map_err(|e| napi::Error::from_reason(format!("{}", e)))?,
|
||||
);
|
||||
}
|
||||
let tbl = builder
|
||||
.execute()
|
||||
|
||||
@@ -14,7 +14,7 @@
|
||||
|
||||
use std::sync::Mutex;
|
||||
|
||||
use lancedb::index::scalar::BTreeIndexBuilder;
|
||||
use lancedb::index::scalar::{BTreeIndexBuilder, FtsIndexBuilder};
|
||||
use lancedb::index::vector::IvfPqIndexBuilder;
|
||||
use lancedb::index::Index as LanceDbIndex;
|
||||
use napi_derive::napi;
|
||||
@@ -76,4 +76,25 @@ impl Index {
|
||||
inner: Mutex::new(Some(LanceDbIndex::BTree(BTreeIndexBuilder::default()))),
|
||||
}
|
||||
}
|
||||
|
||||
#[napi(factory)]
|
||||
pub fn bitmap() -> Self {
|
||||
Self {
|
||||
inner: Mutex::new(Some(LanceDbIndex::Bitmap(Default::default()))),
|
||||
}
|
||||
}
|
||||
|
||||
#[napi(factory)]
|
||||
pub fn label_list() -> Self {
|
||||
Self {
|
||||
inner: Mutex::new(Some(LanceDbIndex::LabelList(Default::default()))),
|
||||
}
|
||||
}
|
||||
|
||||
#[napi(factory)]
|
||||
pub fn fts() -> Self {
|
||||
Self {
|
||||
inner: Mutex::new(Some(LanceDbIndex::FTS(FtsIndexBuilder::default()))),
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
@@ -12,6 +12,7 @@
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
use lancedb::index::scalar::FullTextSearchQuery;
|
||||
use lancedb::query::ExecutableQuery;
|
||||
use lancedb::query::Query as LanceDbQuery;
|
||||
use lancedb::query::QueryBase;
|
||||
@@ -42,6 +43,12 @@ impl Query {
|
||||
self.inner = self.inner.clone().only_if(predicate);
|
||||
}
|
||||
|
||||
#[napi]
|
||||
pub fn full_text_search(&mut self, query: String, columns: Option<Vec<String>>) {
|
||||
let query = FullTextSearchQuery::new(query).columns(columns);
|
||||
self.inner = self.inner.clone().full_text_search(query);
|
||||
}
|
||||
|
||||
#[napi]
|
||||
pub fn select(&mut self, columns: Vec<(String, String)>) {
|
||||
self.inner = self.inner.clone().select(Select::dynamic(&columns));
|
||||
@@ -138,6 +145,12 @@ impl VectorQuery {
|
||||
self.inner = self.inner.clone().only_if(predicate);
|
||||
}
|
||||
|
||||
#[napi]
|
||||
pub fn full_text_search(&mut self, query: String, columns: Option<Vec<String>>) {
|
||||
let query = FullTextSearchQuery::new(query).columns(columns);
|
||||
self.inner = self.inner.clone().full_text_search(query);
|
||||
}
|
||||
|
||||
#[napi]
|
||||
pub fn select(&mut self, columns: Vec<(String, String)>) {
|
||||
self.inner = self.inner.clone().select(Select::dynamic(&columns));
|
||||
|
||||
@@ -293,6 +293,7 @@ impl Table {
|
||||
.optimize(OptimizeAction::Prune {
|
||||
older_than,
|
||||
delete_unverified: None,
|
||||
error_if_tagged_old_versions: None,
|
||||
})
|
||||
.await
|
||||
.default_error()?
|
||||
|
||||
@@ -9,7 +9,8 @@
|
||||
"allowJs": true,
|
||||
"resolveJsonModule": true,
|
||||
"emitDecoratorMetadata": true,
|
||||
"experimentalDecorators": true
|
||||
"experimentalDecorators": true,
|
||||
"moduleResolution": "Node"
|
||||
},
|
||||
"exclude": ["./dist/*"],
|
||||
"typedocOptions": {
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
[tool.bumpversion]
|
||||
current_version = "0.11.0"
|
||||
current_version = "0.13.0-beta.0"
|
||||
parse = """(?x)
|
||||
(?P<major>0|[1-9]\\d*)\\.
|
||||
(?P<minor>0|[1-9]\\d*)\\.
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
[package]
|
||||
name = "lancedb-python"
|
||||
version = "0.11.0"
|
||||
version = "0.13.0-beta.0"
|
||||
edition.workspace = true
|
||||
description = "Python bindings for LanceDB"
|
||||
license.workspace = true
|
||||
|
||||
@@ -3,7 +3,7 @@ name = "lancedb"
|
||||
# version in Cargo.toml
|
||||
dependencies = [
|
||||
"deprecation",
|
||||
"pylance==0.15.0",
|
||||
"pylance==0.17.0-beta.2",
|
||||
"ratelimiter~=1.0",
|
||||
"requests>=2.31.0",
|
||||
"retry>=0.9.2",
|
||||
@@ -56,7 +56,7 @@ tests = [
|
||||
"pytest-asyncio",
|
||||
"duckdb",
|
||||
"pytz",
|
||||
"polars>=0.19",
|
||||
"polars>=0.19, <=1.3.0",
|
||||
"tantivy",
|
||||
]
|
||||
dev = ["ruff", "pre-commit"]
|
||||
@@ -76,6 +76,7 @@ embeddings = [
|
||||
"awscli>=1.29.57",
|
||||
"botocore>=1.31.57",
|
||||
"ollama",
|
||||
"ibm-watsonx-ai>=1.1.2",
|
||||
]
|
||||
azure = ["adlfs>=2024.2.0"]
|
||||
|
||||
|
||||
@@ -24,7 +24,7 @@ class Connection(object):
|
||||
mode: str,
|
||||
data: pa.RecordBatchReader,
|
||||
storage_options: Optional[Dict[str, str]] = None,
|
||||
use_legacy_format: Optional[bool] = None,
|
||||
data_storage_version: Optional[str] = None,
|
||||
) -> Table: ...
|
||||
async def create_empty_table(
|
||||
self,
|
||||
@@ -32,7 +32,7 @@ class Connection(object):
|
||||
mode: str,
|
||||
schema: pa.Schema,
|
||||
storage_options: Optional[Dict[str, str]] = None,
|
||||
use_legacy_format: Optional[bool] = None,
|
||||
data_storage_version: Optional[str] = None,
|
||||
) -> Table: ...
|
||||
|
||||
class Table:
|
||||
|
||||
@@ -560,6 +560,7 @@ class AsyncConnection(object):
|
||||
fill_value: Optional[float] = None,
|
||||
storage_options: Optional[Dict[str, str]] = None,
|
||||
*,
|
||||
data_storage_version: Optional[str] = None,
|
||||
use_legacy_format: Optional[bool] = None,
|
||||
) -> AsyncTable:
|
||||
"""Create an [AsyncTable][lancedb.table.AsyncTable] in the database.
|
||||
@@ -603,9 +604,15 @@ class AsyncConnection(object):
|
||||
connection will be inherited by the table, but can be overridden here.
|
||||
See available options at
|
||||
https://lancedb.github.io/lancedb/guides/storage/
|
||||
use_legacy_format: bool, optional, default True
|
||||
data_storage_version: optional, str, default "legacy"
|
||||
The version of the data storage format to use. Newer versions are more
|
||||
efficient but require newer versions of lance to read. The default is
|
||||
"legacy" which will use the legacy v1 version. See the user guide
|
||||
for more details.
|
||||
use_legacy_format: bool, optional, default True. (Deprecated)
|
||||
If True, use the legacy format for the table. If False, use the new format.
|
||||
The default is True while the new format is in beta.
|
||||
This method is deprecated, use `data_storage_version` instead.
|
||||
|
||||
|
||||
Returns
|
||||
@@ -765,13 +772,18 @@ class AsyncConnection(object):
|
||||
if mode == "create" and exist_ok:
|
||||
mode = "exist_ok"
|
||||
|
||||
if not data_storage_version:
|
||||
data_storage_version = (
|
||||
"legacy" if use_legacy_format is None or use_legacy_format else "stable"
|
||||
)
|
||||
|
||||
if data is None:
|
||||
new_table = await self._inner.create_empty_table(
|
||||
name,
|
||||
mode,
|
||||
schema,
|
||||
storage_options=storage_options,
|
||||
use_legacy_format=use_legacy_format,
|
||||
data_storage_version=data_storage_version,
|
||||
)
|
||||
else:
|
||||
data = data_to_reader(data, schema)
|
||||
@@ -780,7 +792,7 @@ class AsyncConnection(object):
|
||||
mode,
|
||||
data,
|
||||
storage_options=storage_options,
|
||||
use_legacy_format=use_legacy_format,
|
||||
data_storage_version=data_storage_version,
|
||||
)
|
||||
|
||||
return AsyncTable(new_table)
|
||||
|
||||
@@ -26,3 +26,4 @@ from .transformers import TransformersEmbeddingFunction, ColbertEmbeddings
|
||||
from .imagebind import ImageBindEmbeddings
|
||||
from .utils import with_embeddings
|
||||
from .jinaai import JinaEmbeddings
|
||||
from .watsonx import WatsonxEmbeddings
|
||||
|
||||
111
python/python/lancedb/embeddings/watsonx.py
Normal file
111
python/python/lancedb/embeddings/watsonx.py
Normal file
@@ -0,0 +1,111 @@
|
||||
# Copyright (c) 2023. LanceDB Developers
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import os
|
||||
from functools import cached_property
|
||||
from typing import List, Optional, Dict, Union
|
||||
|
||||
from ..util import attempt_import_or_raise
|
||||
from .base import TextEmbeddingFunction
|
||||
from .registry import register
|
||||
|
||||
import numpy as np
|
||||
|
||||
DEFAULT_WATSONX_URL = "https://us-south.ml.cloud.ibm.com"
|
||||
|
||||
MODELS_DIMS = {
|
||||
"ibm/slate-125m-english-rtrvr": 768,
|
||||
"ibm/slate-30m-english-rtrvr": 384,
|
||||
"sentence-transformers/all-minilm-l12-v2": 384,
|
||||
"intfloat/multilingual-e5-large": 1024,
|
||||
}
|
||||
|
||||
|
||||
@register("watsonx")
|
||||
class WatsonxEmbeddings(TextEmbeddingFunction):
|
||||
"""
|
||||
API Docs:
|
||||
---------
|
||||
https://cloud.ibm.com/apidocs/watsonx-ai#text-embeddings
|
||||
|
||||
Supported embedding models:
|
||||
---------------------------
|
||||
https://dataplatform.cloud.ibm.com/docs/content/wsj/analyze-data/fm-models-embed.html?context=wx
|
||||
"""
|
||||
|
||||
name: str = "ibm/slate-125m-english-rtrvr"
|
||||
api_key: Optional[str] = None
|
||||
project_id: Optional[str] = None
|
||||
url: Optional[str] = None
|
||||
params: Optional[Dict] = None
|
||||
|
||||
@staticmethod
|
||||
def model_names():
|
||||
return [
|
||||
"ibm/slate-125m-english-rtrvr",
|
||||
"ibm/slate-30m-english-rtrvr",
|
||||
"sentence-transformers/all-minilm-l12-v2",
|
||||
"intfloat/multilingual-e5-large",
|
||||
]
|
||||
|
||||
def ndims(self):
|
||||
return self._ndims
|
||||
|
||||
@cached_property
|
||||
def _ndims(self):
|
||||
if self.name not in MODELS_DIMS:
|
||||
raise ValueError(f"Unknown model name {self.name}")
|
||||
return MODELS_DIMS[self.name]
|
||||
|
||||
def generate_embeddings(
|
||||
self,
|
||||
texts: Union[List[str], np.ndarray],
|
||||
*args,
|
||||
**kwargs,
|
||||
) -> List[List[float]]:
|
||||
return self._watsonx_client.embed_documents(
|
||||
texts=list(texts),
|
||||
*args,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
@cached_property
|
||||
def _watsonx_client(self):
|
||||
ibm_watsonx_ai = attempt_import_or_raise("ibm_watsonx_ai")
|
||||
ibm_watsonx_ai_foundation_models = attempt_import_or_raise(
|
||||
"ibm_watsonx_ai.foundation_models"
|
||||
)
|
||||
|
||||
kwargs = {"model_id": self.name}
|
||||
if self.params:
|
||||
kwargs["params"] = self.params
|
||||
if self.project_id:
|
||||
kwargs["project_id"] = self.project_id
|
||||
elif "WATSONX_PROJECT_ID" in os.environ:
|
||||
kwargs["project_id"] = os.environ["WATSONX_PROJECT_ID"]
|
||||
else:
|
||||
raise ValueError("WATSONX_PROJECT_ID must be set or passed")
|
||||
|
||||
creds_kwargs = {}
|
||||
if self.api_key:
|
||||
creds_kwargs["api_key"] = self.api_key
|
||||
elif "WATSONX_API_KEY" in os.environ:
|
||||
creds_kwargs["api_key"] = os.environ["WATSONX_API_KEY"]
|
||||
else:
|
||||
raise ValueError("WATSONX_API_KEY must be set or passed")
|
||||
if self.url:
|
||||
creds_kwargs["url"] = self.url
|
||||
else:
|
||||
creds_kwargs["url"] = DEFAULT_WATSONX_URL
|
||||
kwargs["credentials"] = ibm_watsonx_ai.Credentials(**creds_kwargs)
|
||||
|
||||
return ibm_watsonx_ai_foundation_models.Embeddings(**kwargs)
|
||||
@@ -8,7 +8,7 @@ from ._lancedb import (
|
||||
)
|
||||
|
||||
|
||||
class BTree(object):
|
||||
class BTree:
|
||||
"""Describes a btree index configuration
|
||||
|
||||
A btree index is an index on scalar columns. The index stores a copy of the
|
||||
@@ -22,7 +22,8 @@ class BTree(object):
|
||||
sizeof(Scalar) * 4096 bytes to find the correct row ids.
|
||||
|
||||
This index is good for scalar columns with mostly distinct values and does best
|
||||
when the query is highly selective.
|
||||
when the query is highly selective. It works with numeric, temporal, and string
|
||||
columns.
|
||||
|
||||
The btree index does not currently have any parameters though parameters such as
|
||||
the block size may be added in the future.
|
||||
@@ -32,7 +33,44 @@ class BTree(object):
|
||||
self._inner = LanceDbIndex.btree()
|
||||
|
||||
|
||||
class IvfPq(object):
|
||||
class Bitmap:
|
||||
"""Describe a Bitmap index configuration.
|
||||
|
||||
A `Bitmap` index stores a bitmap for each distinct value in the column for
|
||||
every row.
|
||||
|
||||
This index works best for low-cardinality numeric or string columns,
|
||||
where the number of unique values is small (i.e., less than a few thousands).
|
||||
`Bitmap` index can accelerate the following filters:
|
||||
|
||||
- `<`, `<=`, `=`, `>`, `>=`
|
||||
- `IN (value1, value2, ...)`
|
||||
- `between (value1, value2)`
|
||||
- `is null`
|
||||
|
||||
For example, a bitmap index with a table with 1Bi rows, and 128 distinct values,
|
||||
requires 128 / 8 * 1Bi bytes on disk.
|
||||
"""
|
||||
|
||||
def __init__(self):
|
||||
self._inner = LanceDbIndex.bitmap()
|
||||
|
||||
|
||||
class LabelList:
|
||||
"""Describe a LabelList index configuration.
|
||||
|
||||
`LabelList` is a scalar index that can be used on `List<T>` columns to
|
||||
support queries with `array_contains_all` and `array_contains_any`
|
||||
using an underlying bitmap index.
|
||||
|
||||
For example, it works with `tags`, `categories`, `keywords`, etc.
|
||||
"""
|
||||
|
||||
def __init__(self):
|
||||
self._inner = LanceDbIndex.label_list()
|
||||
|
||||
|
||||
class IvfPq:
|
||||
"""Describes an IVF PQ Index
|
||||
|
||||
This index stores a compressed (quantized) copy of every vector. These vectors
|
||||
|
||||
@@ -99,6 +99,9 @@ class Query(pydantic.BaseModel):
|
||||
# if True then apply the filter before vector search
|
||||
prefilter: bool = False
|
||||
|
||||
# full text search query
|
||||
full_text_query: Optional[Union[str, dict]] = None
|
||||
|
||||
# top k results to return
|
||||
k: int
|
||||
|
||||
@@ -131,6 +134,7 @@ class LanceQueryBuilder(ABC):
|
||||
query_type: str,
|
||||
vector_column_name: str,
|
||||
ordering_field_name: str = None,
|
||||
fts_columns: Union[str, List[str]] = None,
|
||||
) -> LanceQueryBuilder:
|
||||
"""
|
||||
Create a query builder based on the given query and query type.
|
||||
@@ -226,6 +230,7 @@ class LanceQueryBuilder(ABC):
|
||||
self._limit = 10
|
||||
self._columns = None
|
||||
self._where = None
|
||||
self._prefilter = False
|
||||
self._with_row_id = False
|
||||
|
||||
@deprecation.deprecated(
|
||||
@@ -664,12 +669,19 @@ class LanceVectorQueryBuilder(LanceQueryBuilder):
|
||||
class LanceFtsQueryBuilder(LanceQueryBuilder):
|
||||
"""A builder for full text search for LanceDB."""
|
||||
|
||||
def __init__(self, table: "Table", query: str, ordering_field_name: str = None):
|
||||
def __init__(
|
||||
self,
|
||||
table: "Table",
|
||||
query: str,
|
||||
ordering_field_name: str = None,
|
||||
fts_columns: Union[str, List[str]] = None,
|
||||
):
|
||||
super().__init__(table)
|
||||
self._query = query
|
||||
self._phrase_query = False
|
||||
self.ordering_field_name = ordering_field_name
|
||||
self._reranker = None
|
||||
self._fts_columns = fts_columns
|
||||
|
||||
def phrase_query(self, phrase_query: bool = True) -> LanceFtsQueryBuilder:
|
||||
"""Set whether to use phrase query.
|
||||
@@ -689,6 +701,35 @@ class LanceFtsQueryBuilder(LanceQueryBuilder):
|
||||
return self
|
||||
|
||||
def to_arrow(self) -> pa.Table:
|
||||
tantivy_index_path = self._table._get_fts_index_path()
|
||||
if Path(tantivy_index_path).exists():
|
||||
return self.tantivy_to_arrow()
|
||||
|
||||
query = self._query
|
||||
if self._phrase_query:
|
||||
raise NotImplementedError(
|
||||
"Phrase query is not yet supported in Lance FTS. "
|
||||
"Use tantivy-based index instead for now."
|
||||
)
|
||||
if self._reranker:
|
||||
raise NotImplementedError(
|
||||
"Reranking is not yet supported in Lance FTS. "
|
||||
"Use tantivy-based index instead for now."
|
||||
)
|
||||
ds = self._table.to_lance()
|
||||
return ds.to_table(
|
||||
columns=self._columns,
|
||||
filter=self._where,
|
||||
limit=self._limit,
|
||||
prefilter=self._prefilter,
|
||||
with_row_id=self._with_row_id,
|
||||
full_text_query={
|
||||
"query": query,
|
||||
"columns": self._fts_columns,
|
||||
},
|
||||
)
|
||||
|
||||
def tantivy_to_arrow(self) -> pa.Table:
|
||||
try:
|
||||
import tantivy
|
||||
except ImportError:
|
||||
@@ -726,11 +767,11 @@ class LanceFtsQueryBuilder(LanceQueryBuilder):
|
||||
index, query, self._limit, ordering_field=self.ordering_field_name
|
||||
)
|
||||
if len(row_ids) == 0:
|
||||
empty_schema = pa.schema([pa.field("score", pa.float32())])
|
||||
empty_schema = pa.schema([pa.field("_score", pa.float32())])
|
||||
return pa.Table.from_pylist([], schema=empty_schema)
|
||||
scores = pa.array(scores)
|
||||
output_tbl = self._table.to_lance().take(row_ids, columns=self._columns)
|
||||
output_tbl = output_tbl.append_column("score", scores)
|
||||
output_tbl = output_tbl.append_column("_score", scores)
|
||||
# this needs to match vector search results which are uint64
|
||||
row_ids = pa.array(row_ids, type=pa.uint64())
|
||||
|
||||
@@ -784,8 +825,7 @@ class LanceFtsQueryBuilder(LanceQueryBuilder):
|
||||
LanceFtsQueryBuilder
|
||||
The LanceQueryBuilder object.
|
||||
"""
|
||||
self._reranker = reranker
|
||||
return self
|
||||
raise NotImplementedError("Reranking is not yet supported for FTS queries.")
|
||||
|
||||
|
||||
class LanceEmptyQueryBuilder(LanceQueryBuilder):
|
||||
@@ -856,13 +896,13 @@ class LanceHybridQueryBuilder(LanceQueryBuilder):
|
||||
# convert to ranks first if needed
|
||||
if self._norm == "rank":
|
||||
vector_results = self._rank(vector_results, "_distance")
|
||||
fts_results = self._rank(fts_results, "score")
|
||||
fts_results = self._rank(fts_results, "_score")
|
||||
# normalize the scores to be between 0 and 1, 0 being most relevant
|
||||
vector_results = self._normalize_scores(vector_results, "_distance")
|
||||
|
||||
# In fts higher scores represent relevance. Not inverting them here as
|
||||
# rerankers might need to preserve this score to support `return_score="all"`
|
||||
fts_results = self._normalize_scores(fts_results, "score")
|
||||
fts_results = self._normalize_scores(fts_results, "_score")
|
||||
|
||||
results = self._reranker.rerank_hybrid(
|
||||
self._fts_query._query, vector_results, fts_results
|
||||
@@ -1177,6 +1217,16 @@ class AsyncQueryBase(object):
|
||||
await batch_iter.read_all(), schema=batch_iter.schema
|
||||
)
|
||||
|
||||
async def to_list(self) -> List[dict]:
|
||||
"""
|
||||
Execute the query and return the results as a list of dictionaries.
|
||||
|
||||
Each list entry is a dictionary with the selected column names as keys,
|
||||
or all table columns if `select` is not called. The vector and the "_distance"
|
||||
fields are returned whether or not they're explicitly selected.
|
||||
"""
|
||||
return (await self.to_arrow()).to_pylist()
|
||||
|
||||
async def to_pandas(self) -> "pd.DataFrame":
|
||||
"""
|
||||
Execute the query and collect the results into a pandas DataFrame.
|
||||
|
||||
@@ -22,8 +22,9 @@ from lance import json_to_schema
|
||||
|
||||
from lancedb.common import DATA, VEC, VECTOR_COLUMN_NAME
|
||||
from lancedb.merge import LanceMergeInsertBuilder
|
||||
from lancedb.embeddings import EmbeddingFunctionRegistry
|
||||
|
||||
from ..query import LanceVectorQueryBuilder
|
||||
from ..query import LanceVectorQueryBuilder, LanceQueryBuilder
|
||||
from ..table import Query, Table, _sanitize_data
|
||||
from ..util import inf_vector_column_query, value_to_sql
|
||||
from .arrow import to_ipc_binary
|
||||
@@ -58,6 +59,21 @@ class RemoteTable(Table):
|
||||
resp = self._conn._client.post(f"/v1/table/{self._name}/describe/")
|
||||
return resp["version"]
|
||||
|
||||
@cached_property
|
||||
def embedding_functions(self) -> dict:
|
||||
"""
|
||||
Get the embedding functions for the table
|
||||
|
||||
Returns
|
||||
-------
|
||||
funcs: dict
|
||||
A mapping of the vector column to the embedding function
|
||||
or empty dict if not configured.
|
||||
"""
|
||||
return EmbeddingFunctionRegistry.get_instance().parse_functions(
|
||||
self.schema.metadata
|
||||
)
|
||||
|
||||
def to_arrow(self) -> pa.Table:
|
||||
"""to_arrow() is not yet supported on LanceDB cloud."""
|
||||
raise NotImplementedError("to_arrow() is not yet supported on LanceDB cloud.")
|
||||
@@ -213,7 +229,7 @@ class RemoteTable(Table):
|
||||
data, _ = _sanitize_data(
|
||||
data,
|
||||
self.schema,
|
||||
metadata=None,
|
||||
metadata=self.schema.metadata,
|
||||
on_bad_vectors=on_bad_vectors,
|
||||
fill_value=fill_value,
|
||||
)
|
||||
@@ -293,6 +309,7 @@ class RemoteTable(Table):
|
||||
"""
|
||||
if vector_column_name is None:
|
||||
vector_column_name = inf_vector_column_query(self.schema)
|
||||
query = LanceQueryBuilder._query_to_vector(self, query, vector_column_name)
|
||||
return LanceVectorQueryBuilder(self, query, vector_column_name)
|
||||
|
||||
def _execute_query(
|
||||
@@ -336,7 +353,7 @@ class RemoteTable(Table):
|
||||
|
||||
See [`Table.merge_insert`][lancedb.table.Table.merge_insert] for more details.
|
||||
"""
|
||||
super().merge_insert(on)
|
||||
return super().merge_insert(on)
|
||||
|
||||
def _do_merge(
|
||||
self,
|
||||
|
||||
@@ -1,9 +1,13 @@
|
||||
from abc import ABC, abstractmethod
|
||||
from packaging.version import Version
|
||||
from typing import Union, List, TYPE_CHECKING
|
||||
|
||||
import numpy as np
|
||||
import pyarrow as pa
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from ..table import LanceVectorQueryBuilder
|
||||
|
||||
ARROW_VERSION = Version(pa.__version__)
|
||||
|
||||
|
||||
@@ -130,12 +134,94 @@ class Reranker(ABC):
|
||||
combined = pa.concat_tables(
|
||||
[vector_results, fts_results], **self._concat_tables_args
|
||||
)
|
||||
row_id = combined.column("_rowid")
|
||||
|
||||
# deduplicate
|
||||
mask = np.full((combined.shape[0]), False)
|
||||
_, mask_indices = np.unique(np.array(row_id), return_index=True)
|
||||
mask[mask_indices] = True
|
||||
combined = combined.filter(mask=mask)
|
||||
combined = self._deduplicate(combined)
|
||||
|
||||
return combined
|
||||
|
||||
def rerank_multivector(
|
||||
self,
|
||||
vector_results: Union[List[pa.Table], List["LanceVectorQueryBuilder"]],
|
||||
query: Union[str, None], # Some rerankers might not need the query
|
||||
deduplicate: bool = False,
|
||||
):
|
||||
"""
|
||||
This is a rerank function that receives the results from multiple
|
||||
vector searches. For example, this can be used to combine the
|
||||
results of two vector searches with different embeddings.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
vector_results : List[pa.Table] or List[LanceVectorQueryBuilder]
|
||||
The results from the vector search. Either accepts the query builder
|
||||
if the results haven't been executed yet or the results in arrow format.
|
||||
query : str or None,
|
||||
The input query. Some rerankers might not need the query to rerank.
|
||||
In that case, it can be set to None explicitly. This is inteded to
|
||||
be handled by the reranker implementations.
|
||||
deduplicate : bool, optional
|
||||
Whether to deduplicate the results based on the `_rowid` column,
|
||||
by default False. Requires `_rowid` to be present in the results.
|
||||
|
||||
Returns
|
||||
-------
|
||||
pa.Table
|
||||
The reranked results
|
||||
"""
|
||||
vector_results = (
|
||||
[vector_results] if not isinstance(vector_results, list) else vector_results
|
||||
)
|
||||
|
||||
# Make sure all elements are of the same type
|
||||
if not all(isinstance(v, type(vector_results[0])) for v in vector_results):
|
||||
raise ValueError(
|
||||
"All elements in vector_results should be of the same type"
|
||||
)
|
||||
|
||||
# avoids circular import
|
||||
if type(vector_results[0]).__name__ == "LanceVectorQueryBuilder":
|
||||
vector_results = [result.to_arrow() for result in vector_results]
|
||||
elif not isinstance(vector_results[0], pa.Table):
|
||||
raise ValueError(
|
||||
"vector_results should be a list of pa.Table or LanceVectorQueryBuilder"
|
||||
)
|
||||
|
||||
combined = pa.concat_tables(vector_results, **self._concat_tables_args)
|
||||
|
||||
reranked = self.rerank_vector(query, combined)
|
||||
|
||||
# TODO: Allow custom deduplicators here.
|
||||
# currently, this'll just keep the first instance.
|
||||
if deduplicate:
|
||||
if "_rowid" not in combined.column_names:
|
||||
raise ValueError(
|
||||
"'_rowid' is required for deduplication. \
|
||||
add _rowid to search results like this: \
|
||||
`search().with_row_id(True)`"
|
||||
)
|
||||
reranked = self._deduplicate(reranked)
|
||||
|
||||
return reranked
|
||||
|
||||
def _deduplicate(self, table: pa.Table):
|
||||
"""
|
||||
Deduplicate the table based on the `_rowid` column.
|
||||
"""
|
||||
row_id = table.column("_rowid")
|
||||
|
||||
# deduplicate
|
||||
mask = np.full((table.shape[0]), False)
|
||||
_, mask_indices = np.unique(np.array(row_id), return_index=True)
|
||||
mask[mask_indices] = True
|
||||
deduped_table = table.filter(mask=mask)
|
||||
|
||||
return deduped_table
|
||||
|
||||
def _keep_relevance_score(self, combined_results: pa.Table):
|
||||
if self.score == "relevance":
|
||||
if "_score" in combined_results.column_names:
|
||||
combined_results = combined_results.drop_columns(["_score"])
|
||||
if "_distance" in combined_results.column_names:
|
||||
combined_results = combined_results.drop_columns(["_distance"])
|
||||
return combined_results
|
||||
|
||||
@@ -88,7 +88,7 @@ class CohereReranker(Reranker):
|
||||
combined_results = self.merge_results(vector_results, fts_results)
|
||||
combined_results = self._rerank(combined_results, query)
|
||||
if self.score == "relevance":
|
||||
combined_results = combined_results.drop_columns(["score", "_distance"])
|
||||
combined_results = self._keep_relevance_score(combined_results)
|
||||
elif self.score == "all":
|
||||
raise NotImplementedError(
|
||||
"return_score='all' not implemented for cohere reranker"
|
||||
@@ -113,6 +113,6 @@ class CohereReranker(Reranker):
|
||||
):
|
||||
result_set = self._rerank(fts_results, query)
|
||||
if self.score == "relevance":
|
||||
result_set = result_set.drop_columns(["score"])
|
||||
result_set = result_set.drop_columns(["_score"])
|
||||
|
||||
return result_set
|
||||
|
||||
@@ -73,7 +73,7 @@ class ColbertReranker(Reranker):
|
||||
combined_results = self.merge_results(vector_results, fts_results)
|
||||
combined_results = self._rerank(combined_results, query)
|
||||
if self.score == "relevance":
|
||||
combined_results = combined_results.drop_columns(["score", "_distance"])
|
||||
combined_results = self._keep_relevance_score(combined_results)
|
||||
elif self.score == "all":
|
||||
raise NotImplementedError(
|
||||
"OpenAI Reranker does not support score='all' yet"
|
||||
@@ -105,7 +105,7 @@ class ColbertReranker(Reranker):
|
||||
):
|
||||
result_set = self._rerank(fts_results, query)
|
||||
if self.score == "relevance":
|
||||
result_set = result_set.drop_columns(["score"])
|
||||
result_set = result_set.drop_columns(["_score"])
|
||||
|
||||
result_set = result_set.sort_by([("_relevance_score", "descending")])
|
||||
|
||||
|
||||
@@ -66,7 +66,7 @@ class CrossEncoderReranker(Reranker):
|
||||
combined_results = self._rerank(combined_results, query)
|
||||
# sort the results by _score
|
||||
if self.score == "relevance":
|
||||
combined_results = combined_results.drop_columns(["score", "_distance"])
|
||||
combined_results = self._keep_relevance_score(combined_results)
|
||||
elif self.score == "all":
|
||||
raise NotImplementedError(
|
||||
"return_score='all' not implemented for CrossEncoderReranker"
|
||||
@@ -96,7 +96,7 @@ class CrossEncoderReranker(Reranker):
|
||||
):
|
||||
fts_results = self._rerank(fts_results, query)
|
||||
if self.score == "relevance":
|
||||
fts_results = fts_results.drop_columns(["score"])
|
||||
fts_results = fts_results.drop_columns(["_score"])
|
||||
|
||||
fts_results = fts_results.sort_by([("_relevance_score", "descending")])
|
||||
return fts_results
|
||||
|
||||
@@ -92,7 +92,7 @@ class JinaReranker(Reranker):
|
||||
combined_results = self.merge_results(vector_results, fts_results)
|
||||
combined_results = self._rerank(combined_results, query)
|
||||
if self.score == "relevance":
|
||||
combined_results = combined_results.drop_columns(["score", "_distance"])
|
||||
combined_results = self._keep_relevance_score(combined_results)
|
||||
elif self.score == "all":
|
||||
raise NotImplementedError(
|
||||
"return_score='all' not implemented for JinaReranker"
|
||||
@@ -117,6 +117,6 @@ class JinaReranker(Reranker):
|
||||
):
|
||||
result_set = self._rerank(fts_results, query)
|
||||
if self.score == "relevance":
|
||||
result_set = result_set.drop_columns(["score"])
|
||||
result_set = result_set.drop_columns(["_score"])
|
||||
|
||||
return result_set
|
||||
|
||||
@@ -69,12 +69,12 @@ class LinearCombinationReranker(Reranker):
|
||||
vi = vector_list[i]
|
||||
fj = fts_list[j]
|
||||
# invert the fts score from relevance to distance
|
||||
inverted_fts_score = self._invert_score(fj["score"])
|
||||
inverted_fts_score = self._invert_score(fj["_score"])
|
||||
if vi["_rowid"] == fj["_rowid"]:
|
||||
vi["_relevance_score"] = self._combine_score(
|
||||
vi["_distance"], inverted_fts_score
|
||||
)
|
||||
vi["score"] = fj["score"] # keep the original score
|
||||
vi["_score"] = fj["_score"] # keep the original score
|
||||
combined_list.append(vi)
|
||||
i += 1
|
||||
j += 1
|
||||
@@ -103,7 +103,7 @@ class LinearCombinationReranker(Reranker):
|
||||
[("_relevance_score", "descending")]
|
||||
)
|
||||
if self.score == "relevance":
|
||||
tbl = tbl.drop_columns(["score", "_distance"])
|
||||
tbl = self._keep_relevance_score(tbl)
|
||||
return tbl
|
||||
|
||||
def _combine_score(self, score1, score2):
|
||||
|
||||
@@ -84,7 +84,7 @@ class OpenaiReranker(Reranker):
|
||||
combined_results = self.merge_results(vector_results, fts_results)
|
||||
combined_results = self._rerank(combined_results, query)
|
||||
if self.score == "relevance":
|
||||
combined_results = combined_results.drop_columns(["score", "_distance"])
|
||||
combined_results = self._keep_relevance_score(combined_results)
|
||||
elif self.score == "all":
|
||||
raise NotImplementedError(
|
||||
"OpenAI Reranker does not support score='all' yet"
|
||||
@@ -108,7 +108,7 @@ class OpenaiReranker(Reranker):
|
||||
def rerank_fts(self, query: str, fts_results: pa.Table):
|
||||
fts_results = self._rerank(fts_results, query)
|
||||
if self.score == "relevance":
|
||||
fts_results = fts_results.drop_columns(["score"])
|
||||
fts_results = fts_results.drop_columns(["_score"])
|
||||
|
||||
fts_results = fts_results.sort_by([("_relevance_score", "descending")])
|
||||
|
||||
|
||||
@@ -1,8 +1,12 @@
|
||||
from typing import Union, List, TYPE_CHECKING
|
||||
import pyarrow as pa
|
||||
|
||||
from collections import defaultdict
|
||||
from .base import Reranker
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from ..table import LanceVectorQueryBuilder
|
||||
|
||||
|
||||
class RRFReranker(Reranker):
|
||||
"""
|
||||
@@ -55,6 +59,46 @@ class RRFReranker(Reranker):
|
||||
)
|
||||
|
||||
if self.score == "relevance":
|
||||
combined_results = combined_results.drop_columns(["score", "_distance"])
|
||||
combined_results = self._keep_relevance_score(combined_results)
|
||||
|
||||
return combined_results
|
||||
|
||||
def rerank_multivector(
|
||||
self,
|
||||
vector_results: Union[List[pa.Table], List["LanceVectorQueryBuilder"]],
|
||||
query: str = None,
|
||||
deduplicate: bool = True, # noqa: F821 # TODO: automatically deduplicates
|
||||
):
|
||||
"""
|
||||
Overridden method to rerank the results from multiple vector searches.
|
||||
This leverages the RRF hybrid reranking algorithm to combine the
|
||||
results from multiple vector searches as it doesn't support reranking
|
||||
vector results individually.
|
||||
"""
|
||||
# Make sure all elements are of the same type
|
||||
if not all(isinstance(v, type(vector_results[0])) for v in vector_results):
|
||||
raise ValueError(
|
||||
"All elements in vector_results should be of the same type"
|
||||
)
|
||||
|
||||
# avoid circular import
|
||||
if type(vector_results[0]).__name__ == "LanceVectorQueryBuilder":
|
||||
vector_results = [result.to_arrow() for result in vector_results]
|
||||
elif not isinstance(vector_results[0], pa.Table):
|
||||
raise ValueError(
|
||||
"vector_results should be a list of pa.Table or LanceVectorQueryBuilder"
|
||||
)
|
||||
|
||||
# _rowid is required for RRF reranking
|
||||
if not all("_rowid" in result.column_names for result in vector_results):
|
||||
raise ValueError(
|
||||
"'_rowid' is required for deduplication. \
|
||||
add _rowid to search results like this: \
|
||||
`search().with_row_id(True)`"
|
||||
)
|
||||
|
||||
combined = pa.concat_tables(vector_results, **self._concat_tables_args)
|
||||
empty_table = pa.Table.from_arrays([], names=[])
|
||||
reranked = self.rerank_hybrid(query, combined, empty_table)
|
||||
|
||||
return reranked
|
||||
|
||||
@@ -1,15 +1,5 @@
|
||||
# Copyright 2023 LanceDB Developers
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
# SPDX-FileCopyrightText: Copyright The LanceDB Authors
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
@@ -59,10 +49,9 @@ from .util import (
|
||||
if TYPE_CHECKING:
|
||||
import PIL
|
||||
from lance.dataset import CleanupStats, ReaderLike
|
||||
|
||||
from ._lancedb import Table as LanceDBTable, OptimizeStats
|
||||
from .db import LanceDBConnection
|
||||
from .index import BTree, IndexConfig, IvfPq
|
||||
from .index import BTree, IndexConfig, IvfPq, Bitmap, LabelList
|
||||
|
||||
|
||||
pd = safe_import_pandas()
|
||||
@@ -350,6 +339,7 @@ class Table(ABC):
|
||||
def create_scalar_index(
|
||||
self,
|
||||
column: str,
|
||||
index_type: Literal["BTREE", "BITMAP", "LABEL_LIST"] = "BTREE",
|
||||
*,
|
||||
replace: bool = True,
|
||||
):
|
||||
@@ -511,6 +501,8 @@ class Table(ABC):
|
||||
query: Optional[Union[VEC, str, "PIL.Image.Image", Tuple]] = None,
|
||||
vector_column_name: Optional[str] = None,
|
||||
query_type: str = "auto",
|
||||
ordering_field_name: Optional[str] = None,
|
||||
fts_columns: Union[str, List[str]] = None,
|
||||
) -> LanceQueryBuilder:
|
||||
"""Create a search query to find the nearest neighbors
|
||||
of the given query vector. We currently support [vector search][search]
|
||||
@@ -1188,9 +1180,15 @@ class LanceTable(Table):
|
||||
index_cache_size=index_cache_size,
|
||||
)
|
||||
|
||||
def create_scalar_index(self, column: str, *, replace: bool = True):
|
||||
def create_scalar_index(
|
||||
self,
|
||||
column: str,
|
||||
index_type: Literal["BTREE", "BITMAP", "LABEL_LIST"] = "BTREE",
|
||||
*,
|
||||
replace: bool = True,
|
||||
):
|
||||
self._dataset_mut.create_scalar_index(
|
||||
column, index_type="BTREE", replace=replace
|
||||
column, index_type=index_type, replace=replace
|
||||
)
|
||||
|
||||
def create_fts_index(
|
||||
@@ -1201,6 +1199,7 @@ class LanceTable(Table):
|
||||
replace: bool = False,
|
||||
writer_heap_size: Optional[int] = 1024 * 1024 * 1024,
|
||||
tokenizer_name: str = "default",
|
||||
use_tantivy: bool = True,
|
||||
):
|
||||
"""Create a full-text search index on the table.
|
||||
|
||||
@@ -1211,6 +1210,7 @@ class LanceTable(Table):
|
||||
----------
|
||||
field_names: str or list of str
|
||||
The name(s) of the field to index.
|
||||
can be only str if use_tantivy=True for now.
|
||||
replace: bool, default False
|
||||
If True, replace the existing index if it exists. Note that this is
|
||||
not yet an atomic operation; the index will be temporarily
|
||||
@@ -1218,12 +1218,31 @@ class LanceTable(Table):
|
||||
writer_heap_size: int, default 1GB
|
||||
ordering_field_names:
|
||||
A list of unsigned type fields to index to optionally order
|
||||
results on at search time
|
||||
results on at search time.
|
||||
only available with use_tantivy=True
|
||||
tokenizer_name: str, default "default"
|
||||
The tokenizer to use for the index. Can be "raw", "default" or the 2 letter
|
||||
language code followed by "_stem". So for english it would be "en_stem".
|
||||
For available languages see: https://docs.rs/tantivy/latest/tantivy/tokenizer/enum.Language.html
|
||||
only available with use_tantivy=True for now
|
||||
use_tantivy: bool, default False
|
||||
If True, use the legacy full-text search implementation based on tantivy.
|
||||
If False, use the new full-text search implementation based on lance-index.
|
||||
"""
|
||||
if not use_tantivy:
|
||||
if not isinstance(field_names, str):
|
||||
raise ValueError("field_names must be a string when use_tantivy=False")
|
||||
# delete the existing legacy index if it exists
|
||||
if replace:
|
||||
fs, path = fs_from_uri(self._get_fts_index_path())
|
||||
index_exists = fs.get_file_info(path).type != pa_fs.FileType.NotFound
|
||||
if index_exists:
|
||||
fs.delete_dir(path)
|
||||
self._dataset_mut.create_scalar_index(
|
||||
field_names, index_type="INVERTED", replace=replace
|
||||
)
|
||||
return
|
||||
|
||||
from .fts import create_index, populate_index
|
||||
|
||||
if isinstance(field_names, str):
|
||||
@@ -1392,6 +1411,7 @@ class LanceTable(Table):
|
||||
vector_column_name: Optional[str] = None,
|
||||
query_type: str = "auto",
|
||||
ordering_field_name: Optional[str] = None,
|
||||
fts_columns: Union[str, List[str]] = None,
|
||||
) -> LanceQueryBuilder:
|
||||
"""Create a search query to find the nearest neighbors
|
||||
of the given query vector. We currently support [vector search][search]
|
||||
@@ -1446,6 +1466,10 @@ class LanceTable(Table):
|
||||
or raise an error if no corresponding embedding function is found.
|
||||
If the `query` is a string, then the query type is "vector" if the
|
||||
table has embedding functions, else the query type is "fts"
|
||||
fts_columns: str or list of str, default None
|
||||
The column(s) to search in for full-text search.
|
||||
If None then the search is performed on all indexed columns.
|
||||
For now, only one column can be searched at a time.
|
||||
|
||||
Returns
|
||||
-------
|
||||
@@ -1665,6 +1689,7 @@ class LanceTable(Table):
|
||||
"nprobes": query.nprobes,
|
||||
"refine_factor": query.refine_factor,
|
||||
},
|
||||
full_text_query=query.full_text_query,
|
||||
with_row_id=query.with_row_id,
|
||||
batch_size=batch_size,
|
||||
).to_reader()
|
||||
@@ -2088,7 +2113,7 @@ class AsyncTable:
|
||||
column: str,
|
||||
*,
|
||||
replace: Optional[bool] = None,
|
||||
config: Optional[Union[IvfPq, BTree]] = None,
|
||||
config: Optional[Union[IvfPq, BTree, Bitmap, LabelList]] = None,
|
||||
):
|
||||
"""Create an index to speed up queries
|
||||
|
||||
|
||||
@@ -22,7 +22,8 @@ import pytest
|
||||
from lancedb.pydantic import LanceModel, Vector
|
||||
|
||||
|
||||
def test_basic(tmp_path):
|
||||
@pytest.mark.parametrize("use_tantivy", [True, False])
|
||||
def test_basic(tmp_path, use_tantivy):
|
||||
db = lancedb.connect(tmp_path)
|
||||
|
||||
assert db.uri == str(tmp_path)
|
||||
@@ -55,7 +56,7 @@ def test_basic(tmp_path):
|
||||
assert len(rs) == 1
|
||||
assert rs["item"].iloc[0] == "foo"
|
||||
|
||||
table.create_fts_index(["item"])
|
||||
table.create_fts_index("item", use_tantivy=use_tantivy)
|
||||
rs = table.search("bar", query_type="fts").to_pandas()
|
||||
assert len(rs) == 1
|
||||
assert rs["item"].iloc[0] == "bar"
|
||||
|
||||
@@ -417,3 +417,28 @@ def test_openai_embedding(tmp_path):
|
||||
tbl.add(df)
|
||||
assert len(tbl.to_pandas()["vector"][0]) == model.ndims()
|
||||
assert tbl.search("hello").limit(1).to_pandas()["text"][0] == "hello world"
|
||||
|
||||
|
||||
@pytest.mark.slow
|
||||
@pytest.mark.skipif(
|
||||
os.environ.get("WATSONX_API_KEY") is None
|
||||
or os.environ.get("WATSONX_PROJECT_ID") is None,
|
||||
reason="WATSONX_API_KEY and WATSONX_PROJECT_ID not set",
|
||||
)
|
||||
def test_watsonx_embedding(tmp_path):
|
||||
from lancedb.embeddings import WatsonxEmbeddings
|
||||
|
||||
for name in WatsonxEmbeddings.model_names():
|
||||
model = get_registry().get("watsonx").create(max_retries=0, name=name)
|
||||
|
||||
class TextModel(LanceModel):
|
||||
text: str = model.SourceField()
|
||||
vector: Vector(model.ndims()) = model.VectorField()
|
||||
|
||||
db = lancedb.connect("~/.lancedb")
|
||||
tbl = db.create_table("watsonx_test", schema=TextModel, mode="overwrite")
|
||||
df = pd.DataFrame({"text": ["hello world", "goodbye world"]})
|
||||
|
||||
tbl.add(df)
|
||||
assert len(tbl.to_pandas()["vector"][0]) == model.ndims()
|
||||
assert tbl.search("hello").limit(1).to_pandas()["text"][0] == "hello world"
|
||||
|
||||
@@ -74,7 +74,12 @@ def test_create_index_with_stemming(tmp_path, table):
|
||||
assert os.path.exists(str(tmp_path / "index"))
|
||||
|
||||
# Check stemming by running tokenizer on non empty table
|
||||
table.create_fts_index("text", tokenizer_name="en_stem")
|
||||
table.create_fts_index("text", tokenizer_name="en_stem", use_tantivy=True)
|
||||
|
||||
|
||||
@pytest.mark.parametrize("use_tantivy", [True, False])
|
||||
def test_create_inverted_index(table, use_tantivy):
|
||||
table.create_fts_index("text", use_tantivy=use_tantivy)
|
||||
|
||||
|
||||
def test_populate_index(tmp_path, table):
|
||||
@@ -92,8 +97,15 @@ def test_search_index(tmp_path, table):
|
||||
assert len(results[1]) == 10 # _distance
|
||||
|
||||
|
||||
@pytest.mark.parametrize("use_tantivy", [True, False])
|
||||
def test_search_fts(table, use_tantivy):
|
||||
table.create_fts_index("text", use_tantivy=use_tantivy)
|
||||
results = table.search("puppy").limit(10).to_list()
|
||||
assert len(results) == 10
|
||||
|
||||
|
||||
def test_search_ordering_field_index_table(tmp_path, table):
|
||||
table.create_fts_index("text", ordering_field_names=["count"])
|
||||
table.create_fts_index("text", ordering_field_names=["count"], use_tantivy=True)
|
||||
rows = (
|
||||
table.search("puppy", ordering_field_name="count")
|
||||
.limit(20)
|
||||
@@ -125,8 +137,9 @@ def test_search_ordering_field_index(tmp_path, table):
|
||||
assert sorted(rows, key=lambda x: x["count"], reverse=True) == rows
|
||||
|
||||
|
||||
def test_create_index_from_table(tmp_path, table):
|
||||
table.create_fts_index("text")
|
||||
@pytest.mark.parametrize("use_tantivy", [True, False])
|
||||
def test_create_index_from_table(tmp_path, table, use_tantivy):
|
||||
table.create_fts_index("text", use_tantivy=use_tantivy)
|
||||
df = table.search("puppy").limit(10).select(["text"]).to_pandas()
|
||||
assert len(df) <= 10
|
||||
assert "text" in df.columns
|
||||
@@ -145,15 +158,15 @@ def test_create_index_from_table(tmp_path, table):
|
||||
]
|
||||
)
|
||||
|
||||
with pytest.raises(ValueError, match="already exists"):
|
||||
table.create_fts_index("text")
|
||||
with pytest.raises(Exception, match="already exists"):
|
||||
table.create_fts_index("text", use_tantivy=use_tantivy)
|
||||
|
||||
table.create_fts_index("text", replace=True)
|
||||
table.create_fts_index("text", replace=True, use_tantivy=use_tantivy)
|
||||
assert len(table.search("gorilla").limit(1).to_pandas()) == 1
|
||||
|
||||
|
||||
def test_create_index_multiple_columns(tmp_path, table):
|
||||
table.create_fts_index(["text", "text2"])
|
||||
table.create_fts_index(["text", "text2"], use_tantivy=True)
|
||||
df = table.search("puppy").limit(10).to_pandas()
|
||||
assert len(df) == 10
|
||||
assert "text" in df.columns
|
||||
@@ -161,20 +174,21 @@ def test_create_index_multiple_columns(tmp_path, table):
|
||||
|
||||
|
||||
def test_empty_rs(tmp_path, table, mocker):
|
||||
table.create_fts_index(["text", "text2"])
|
||||
table.create_fts_index(["text", "text2"], use_tantivy=True)
|
||||
mocker.patch("lancedb.fts.search_index", return_value=([], []))
|
||||
df = table.search("puppy").limit(10).to_pandas()
|
||||
assert len(df) == 0
|
||||
|
||||
|
||||
def test_nested_schema(tmp_path, table):
|
||||
table.create_fts_index("nested.text")
|
||||
table.create_fts_index("nested.text", use_tantivy=True)
|
||||
rs = table.search("puppy").limit(10).to_list()
|
||||
assert len(rs) == 10
|
||||
|
||||
|
||||
def test_search_index_with_filter(table):
|
||||
table.create_fts_index("text")
|
||||
@pytest.mark.parametrize("use_tantivy", [True, False])
|
||||
def test_search_index_with_filter(table, use_tantivy):
|
||||
table.create_fts_index("text", use_tantivy=use_tantivy)
|
||||
orig_import = __import__
|
||||
|
||||
def import_mock(name, *args):
|
||||
@@ -186,7 +200,7 @@ def test_search_index_with_filter(table):
|
||||
with mock.patch("builtins.__import__", side_effect=import_mock):
|
||||
rs = table.search("puppy").where("id=1").limit(10)
|
||||
# test schema
|
||||
assert rs.to_arrow().drop("score").schema.equals(table.schema)
|
||||
assert rs.to_arrow().drop("_score").schema.equals(table.schema)
|
||||
|
||||
rs = rs.to_list()
|
||||
for r in rs:
|
||||
@@ -204,7 +218,8 @@ def test_search_index_with_filter(table):
|
||||
assert r["_rowid"] is not None
|
||||
|
||||
|
||||
def test_null_input(table):
|
||||
@pytest.mark.parametrize("use_tantivy", [True, False])
|
||||
def test_null_input(table, use_tantivy):
|
||||
table.add(
|
||||
[
|
||||
{
|
||||
@@ -217,12 +232,12 @@ def test_null_input(table):
|
||||
}
|
||||
]
|
||||
)
|
||||
table.create_fts_index("text")
|
||||
table.create_fts_index("text", use_tantivy=use_tantivy)
|
||||
|
||||
|
||||
def test_syntax(table):
|
||||
# https://github.com/lancedb/lancedb/issues/769
|
||||
table.create_fts_index("text")
|
||||
table.create_fts_index("text", use_tantivy=True)
|
||||
with pytest.raises(ValueError, match="Syntax Error"):
|
||||
table.search("they could have been dogs OR").limit(10).to_list()
|
||||
|
||||
|
||||
@@ -1,10 +1,14 @@
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
# SPDX-FileCopyrightText: Copyright The LanceDB Authors
|
||||
|
||||
from datetime import timedelta
|
||||
import random
|
||||
|
||||
import pyarrow as pa
|
||||
import pytest
|
||||
import pytest_asyncio
|
||||
from lancedb import AsyncConnection, AsyncTable, connect_async
|
||||
from lancedb.index import BTree, IvfPq
|
||||
from lancedb.index import BTree, IvfPq, Bitmap, LabelList
|
||||
|
||||
|
||||
@pytest_asyncio.fixture
|
||||
@@ -25,8 +29,11 @@ NROWS = 256
|
||||
async def some_table(db_async):
|
||||
data = pa.Table.from_pydict(
|
||||
{
|
||||
"id": list(range(256)),
|
||||
"id": list(range(NROWS)),
|
||||
"vector": sample_fixed_size_list_array(NROWS, DIM),
|
||||
"tags": [
|
||||
[f"tag{random.randint(0, 8)}" for _ in range(2)] for _ in range(NROWS)
|
||||
],
|
||||
}
|
||||
)
|
||||
return await db_async.create_table(
|
||||
@@ -42,6 +49,7 @@ async def test_create_scalar_index(some_table: AsyncTable):
|
||||
# Can recreate if replace=True
|
||||
await some_table.create_index("id", replace=True)
|
||||
indices = await some_table.list_indices()
|
||||
assert str(indices) == '[Index(BTree, columns=["id"])]'
|
||||
assert len(indices) == 1
|
||||
assert indices[0].index_type == "BTree"
|
||||
assert indices[0].columns == ["id"]
|
||||
@@ -52,6 +60,22 @@ async def test_create_scalar_index(some_table: AsyncTable):
|
||||
await some_table.create_index("id", config=BTree())
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_create_bitmap_index(some_table: AsyncTable):
|
||||
await some_table.create_index("id", config=Bitmap())
|
||||
# TODO: Fix via https://github.com/lancedb/lance/issues/2039
|
||||
# indices = await some_table.list_indices()
|
||||
# assert str(indices) == '[Index(Bitmap, columns=["id"])]'
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_create_label_list_index(some_table: AsyncTable):
|
||||
await some_table.create_index("tags", config=LabelList())
|
||||
# TODO: Fix via https://github.com/lancedb/lance/issues/2039
|
||||
# indices = await some_table.list_indices()
|
||||
# assert str(indices) == '[Index(LabelList, columns=["id"])]'
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_create_vector_index(some_table: AsyncTable):
|
||||
# Can create
|
||||
|
||||
@@ -354,3 +354,11 @@ async def test_query_camelcase_async(tmp_path):
|
||||
|
||||
result = await table.query().select(["camelCase"]).to_arrow()
|
||||
assert result == pa.table({"camelCase": pa.array([1, 2])})
|
||||
|
||||
|
||||
@pytest.mark.asyncio
|
||||
async def test_query_to_list_async(table_async: AsyncTable):
|
||||
list = await table_async.query().to_list()
|
||||
assert len(list) == 2
|
||||
assert list[0]["vector"] == [1, 2]
|
||||
assert list[1]["vector"] == [3, 4]
|
||||
|
||||
@@ -1,4 +1,5 @@
|
||||
import os
|
||||
import random
|
||||
|
||||
import lancedb
|
||||
import numpy as np
|
||||
@@ -21,14 +22,17 @@ from lancedb.table import LanceTable
|
||||
pytest.importorskip("lancedb.fts")
|
||||
|
||||
|
||||
def get_test_table(tmp_path):
|
||||
def get_test_table(tmp_path, use_tantivy):
|
||||
db = lancedb.connect(tmp_path)
|
||||
# Create a LanceDB table schema with a vector and a text column
|
||||
emb = EmbeddingFunctionRegistry.get_instance().get("test")()
|
||||
meta_emb = EmbeddingFunctionRegistry.get_instance().get("test")()
|
||||
|
||||
class MyTable(LanceModel):
|
||||
text: str = emb.SourceField()
|
||||
vector: Vector(emb.ndims()) = emb.VectorField()
|
||||
meta: str = meta_emb.SourceField()
|
||||
meta_vector: Vector(meta_emb.ndims()) = meta_emb.VectorField()
|
||||
|
||||
# Initialize the table using the schema
|
||||
table = LanceTable.create(
|
||||
@@ -77,10 +81,15 @@ def get_test_table(tmp_path):
|
||||
]
|
||||
|
||||
# Add the phrases and vectors to the table
|
||||
table.add([{"text": p} for p in phrases])
|
||||
table.add(
|
||||
[
|
||||
{"text": p, "meta": phrases[random.randint(0, len(phrases) - 1)]}
|
||||
for p in phrases
|
||||
]
|
||||
)
|
||||
|
||||
# Create a fts index
|
||||
table.create_fts_index("text")
|
||||
table.create_fts_index("text", use_tantivy=use_tantivy)
|
||||
|
||||
return table, MyTable
|
||||
|
||||
@@ -88,12 +97,12 @@ def get_test_table(tmp_path):
|
||||
def _run_test_reranker(reranker, table, query, query_vector, schema):
|
||||
# Hybrid search setting
|
||||
result1 = (
|
||||
table.search(query, query_type="hybrid")
|
||||
table.search(query, query_type="hybrid", vector_column_name="vector")
|
||||
.rerank(normalize="score", reranker=reranker)
|
||||
.to_pydantic(schema)
|
||||
)
|
||||
result2 = (
|
||||
table.search(query, query_type="hybrid")
|
||||
table.search(query, query_type="hybrid", vector_column_name="vector")
|
||||
.rerank(reranker=reranker)
|
||||
.to_pydantic(schema)
|
||||
)
|
||||
@@ -101,7 +110,7 @@ def _run_test_reranker(reranker, table, query, query_vector, schema):
|
||||
|
||||
query_vector = table.to_pandas()["vector"][0]
|
||||
result = (
|
||||
table.search((query_vector, query))
|
||||
table.search((query_vector, query), vector_column_name="vector")
|
||||
.limit(30)
|
||||
.rerank(reranker=reranker)
|
||||
.to_arrow()
|
||||
@@ -116,11 +125,16 @@ def _run_test_reranker(reranker, table, query, query_vector, schema):
|
||||
assert np.all(np.diff(result.column("_relevance_score").to_numpy()) <= 0), err
|
||||
|
||||
# Vector search setting
|
||||
result = table.search(query).rerank(reranker=reranker).limit(30).to_arrow()
|
||||
result = (
|
||||
table.search(query, vector_column_name="vector")
|
||||
.rerank(reranker=reranker)
|
||||
.limit(30)
|
||||
.to_arrow()
|
||||
)
|
||||
assert len(result) == 30
|
||||
assert np.all(np.diff(result.column("_relevance_score").to_numpy()) <= 0), err
|
||||
result_explicit = (
|
||||
table.search(query_vector)
|
||||
table.search(query_vector, vector_column_name="vector")
|
||||
.rerank(reranker=reranker, query_string=query)
|
||||
.limit(30)
|
||||
.to_arrow()
|
||||
@@ -129,11 +143,13 @@ def _run_test_reranker(reranker, table, query, query_vector, schema):
|
||||
with pytest.raises(
|
||||
ValueError
|
||||
): # This raises an error because vector query is provided without reanking query
|
||||
table.search(query_vector).rerank(reranker=reranker).limit(30).to_arrow()
|
||||
table.search(query_vector, vector_column_name="vector").rerank(
|
||||
reranker=reranker
|
||||
).limit(30).to_arrow()
|
||||
|
||||
# FTS search setting
|
||||
result = (
|
||||
table.search(query, query_type="fts")
|
||||
table.search(query, query_type="fts", vector_column_name="vector")
|
||||
.rerank(reranker=reranker)
|
||||
.limit(30)
|
||||
.to_arrow()
|
||||
@@ -141,22 +157,48 @@ def _run_test_reranker(reranker, table, query, query_vector, schema):
|
||||
assert len(result) > 0
|
||||
assert np.all(np.diff(result.column("_relevance_score").to_numpy()) <= 0), err
|
||||
|
||||
# Multi-vector search setting
|
||||
rs1 = table.search(query, vector_column_name="vector").limit(10).with_row_id(True)
|
||||
rs2 = (
|
||||
table.search(query, vector_column_name="meta_vector")
|
||||
.limit(10)
|
||||
.with_row_id(True)
|
||||
)
|
||||
result = reranker.rerank_multivector([rs1, rs2], query)
|
||||
assert len(result) == 20
|
||||
result_deduped = reranker.rerank_multivector(
|
||||
[rs1, rs2, rs1], query, deduplicate=True
|
||||
)
|
||||
assert len(result_deduped) < 20
|
||||
result_arrow = reranker.rerank_multivector([rs1.to_arrow(), rs2.to_arrow()], query)
|
||||
assert len(result) == 20 and result == result_arrow
|
||||
|
||||
def _run_test_hybrid_reranker(reranker, tmp_path):
|
||||
table, schema = get_test_table(tmp_path)
|
||||
|
||||
def _run_test_hybrid_reranker(reranker, tmp_path, use_tantivy):
|
||||
table, schema = get_test_table(tmp_path, use_tantivy)
|
||||
# The default reranker
|
||||
result1 = (
|
||||
table.search("Our father who art in heaven", query_type="hybrid")
|
||||
table.search(
|
||||
"Our father who art in heaven",
|
||||
query_type="hybrid",
|
||||
vector_column_name="vector",
|
||||
)
|
||||
.rerank(normalize="score")
|
||||
.to_pydantic(schema)
|
||||
)
|
||||
result2 = ( # noqa
|
||||
table.search("Our father who art in heaven.", query_type="hybrid")
|
||||
table.search(
|
||||
"Our father who art in heaven.",
|
||||
query_type="hybrid",
|
||||
vector_column_name="vector",
|
||||
)
|
||||
.rerank(normalize="rank")
|
||||
.to_pydantic(schema)
|
||||
)
|
||||
result3 = table.search(
|
||||
"Our father who art in heaven..", query_type="hybrid"
|
||||
"Our father who art in heaven..",
|
||||
query_type="hybrid",
|
||||
vector_column_name="vector",
|
||||
).to_pydantic(schema)
|
||||
|
||||
assert result1 == result3 # 2 & 3 should be the same as they use score as score
|
||||
@@ -164,7 +206,7 @@ def _run_test_hybrid_reranker(reranker, tmp_path):
|
||||
query = "Our father who art in heaven"
|
||||
query_vector = table.to_pandas()["vector"][0]
|
||||
result = (
|
||||
table.search((query_vector, query))
|
||||
table.search((query_vector, query), vector_column_name="vector")
|
||||
.limit(30)
|
||||
.rerank(normalize="score")
|
||||
.to_arrow()
|
||||
@@ -179,14 +221,16 @@ def _run_test_hybrid_reranker(reranker, tmp_path):
|
||||
)
|
||||
|
||||
|
||||
def test_linear_combination(tmp_path):
|
||||
@pytest.mark.parametrize("use_tantivy", [True, False])
|
||||
def test_linear_combination(tmp_path, use_tantivy):
|
||||
reranker = LinearCombinationReranker()
|
||||
_run_test_hybrid_reranker(reranker, tmp_path)
|
||||
_run_test_hybrid_reranker(reranker, tmp_path, use_tantivy)
|
||||
|
||||
|
||||
def test_rrf_reranker(tmp_path):
|
||||
@pytest.mark.parametrize("use_tantivy", [True, False])
|
||||
def test_rrf_reranker(tmp_path, use_tantivy):
|
||||
reranker = RRFReranker()
|
||||
_run_test_hybrid_reranker(reranker, tmp_path)
|
||||
_run_test_hybrid_reranker(reranker, tmp_path, use_tantivy)
|
||||
|
||||
|
||||
@pytest.mark.skipif(
|
||||
|
||||
@@ -730,7 +730,7 @@ def test_create_scalar_index(db):
|
||||
indices = table.to_lance().list_indices()
|
||||
assert len(indices) == 1
|
||||
scalar_index = indices[0]
|
||||
assert scalar_index["type"] == "Scalar"
|
||||
assert scalar_index["type"] == "BTree"
|
||||
|
||||
# Confirm that prefiltering still works with the scalar index column
|
||||
results = table.search().where("x = 'c'").to_arrow()
|
||||
@@ -1034,6 +1034,12 @@ async def test_optimize(db_async: AsyncConnection):
|
||||
],
|
||||
)
|
||||
stats = await table.optimize()
|
||||
expected = (
|
||||
"OptimizeStats(compaction=CompactionStats { fragments_removed: 2, "
|
||||
"fragments_added: 1, files_removed: 2, files_added: 1 }, "
|
||||
"prune=RemovalStats { bytes_removed: 0, old_versions_removed: 0 })"
|
||||
)
|
||||
assert str(stats) == expected
|
||||
assert stats.compaction.files_removed == 2
|
||||
assert stats.compaction.files_added == 1
|
||||
assert stats.compaction.fragments_added == 1
|
||||
|
||||
@@ -1,21 +1,10 @@
|
||||
// Copyright 2024 Lance Developers.
|
||||
//
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
// SPDX-License-Identifier: Apache-2.0
|
||||
// SPDX-FileCopyrightText: Copyright The LanceDB Authors
|
||||
|
||||
use std::{collections::HashMap, sync::Arc, time::Duration};
|
||||
use std::{collections::HashMap, str::FromStr, sync::Arc, time::Duration};
|
||||
|
||||
use arrow::{datatypes::Schema, ffi_stream::ArrowArrayStreamReader, pyarrow::FromPyArrow};
|
||||
use lancedb::connection::{Connection as LanceConnection, CreateTableMode};
|
||||
use lancedb::connection::{Connection as LanceConnection, CreateTableMode, LanceFileVersion};
|
||||
use pyo3::{
|
||||
exceptions::{PyRuntimeError, PyValueError},
|
||||
pyclass, pyfunction, pymethods, Bound, PyAny, PyRef, PyResult, Python,
|
||||
@@ -91,7 +80,7 @@ impl Connection {
|
||||
mode: &str,
|
||||
data: Bound<'_, PyAny>,
|
||||
storage_options: Option<HashMap<String, String>>,
|
||||
use_legacy_format: Option<bool>,
|
||||
data_storage_version: Option<String>,
|
||||
) -> PyResult<Bound<'a, PyAny>> {
|
||||
let inner = self_.get_inner()?.clone();
|
||||
|
||||
@@ -104,8 +93,11 @@ impl Connection {
|
||||
builder = builder.storage_options(storage_options);
|
||||
}
|
||||
|
||||
if let Some(use_legacy_format) = use_legacy_format {
|
||||
builder = builder.use_legacy_format(use_legacy_format);
|
||||
if let Some(data_storage_version) = data_storage_version.as_ref() {
|
||||
builder = builder.data_storage_version(
|
||||
LanceFileVersion::from_str(data_storage_version)
|
||||
.map_err(|e| PyValueError::new_err(e.to_string()))?,
|
||||
);
|
||||
}
|
||||
|
||||
future_into_py(self_.py(), async move {
|
||||
@@ -120,7 +112,7 @@ impl Connection {
|
||||
mode: &str,
|
||||
schema: Bound<'_, PyAny>,
|
||||
storage_options: Option<HashMap<String, String>>,
|
||||
use_legacy_format: Option<bool>,
|
||||
data_storage_version: Option<String>,
|
||||
) -> PyResult<Bound<'a, PyAny>> {
|
||||
let inner = self_.get_inner()?.clone();
|
||||
|
||||
@@ -134,8 +126,11 @@ impl Connection {
|
||||
builder = builder.storage_options(storage_options);
|
||||
}
|
||||
|
||||
if let Some(use_legacy_format) = use_legacy_format {
|
||||
builder = builder.use_legacy_format(use_legacy_format);
|
||||
if let Some(data_storage_version) = data_storage_version.as_ref() {
|
||||
builder = builder.data_storage_version(
|
||||
LanceFileVersion::from_str(data_storage_version)
|
||||
.map_err(|e| PyValueError::new_err(e.to_string()))?,
|
||||
);
|
||||
}
|
||||
|
||||
future_into_py(self_.py(), async move {
|
||||
|
||||
@@ -84,6 +84,20 @@ impl Index {
|
||||
inner: Mutex::new(Some(LanceDbIndex::BTree(BTreeIndexBuilder::default()))),
|
||||
})
|
||||
}
|
||||
|
||||
#[staticmethod]
|
||||
pub fn bitmap() -> PyResult<Self> {
|
||||
Ok(Self {
|
||||
inner: Mutex::new(Some(LanceDbIndex::Bitmap(Default::default()))),
|
||||
})
|
||||
}
|
||||
|
||||
#[staticmethod]
|
||||
pub fn label_list() -> PyResult<Self> {
|
||||
Ok(Self {
|
||||
inner: Mutex::new(Some(LanceDbIndex::LabelList(Default::default()))),
|
||||
})
|
||||
}
|
||||
}
|
||||
|
||||
#[pyclass(get_all)]
|
||||
@@ -98,6 +112,13 @@ pub struct IndexConfig {
|
||||
pub columns: Vec<String>,
|
||||
}
|
||||
|
||||
#[pymethods]
|
||||
impl IndexConfig {
|
||||
pub fn __repr__(&self) -> String {
|
||||
format!("Index({}, columns={:?})", self.index_type, self.columns)
|
||||
}
|
||||
}
|
||||
|
||||
impl From<lancedb::index::IndexConfig> for IndexConfig {
|
||||
fn from(value: lancedb::index::IndexConfig) -> Self {
|
||||
let index_type = format!("{:?}", value.index_type);
|
||||
|
||||
@@ -60,6 +60,16 @@ pub struct Table {
|
||||
inner: Option<LanceDbTable>,
|
||||
}
|
||||
|
||||
#[pymethods]
|
||||
impl OptimizeStats {
|
||||
pub fn __repr__(&self) -> String {
|
||||
format!(
|
||||
"OptimizeStats(compaction={:?}, prune={:?})",
|
||||
self.compaction, self.prune
|
||||
)
|
||||
}
|
||||
}
|
||||
|
||||
impl Table {
|
||||
pub(crate) fn new(inner: LanceDbTable) -> Self {
|
||||
Self {
|
||||
@@ -266,6 +276,7 @@ impl Table {
|
||||
.optimize(OptimizeAction::Prune {
|
||||
older_than,
|
||||
delete_unverified: None,
|
||||
error_if_tagged_old_versions: None,
|
||||
})
|
||||
.await
|
||||
.infer_error()?
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
[package]
|
||||
name = "lancedb-node"
|
||||
version = "0.7.2"
|
||||
version = "0.10.0-beta.0"
|
||||
description = "Serverless, low-latency vector database for AI applications"
|
||||
license.workspace = true
|
||||
edition.workspace = true
|
||||
|
||||
@@ -320,12 +320,19 @@ impl JsTable {
|
||||
.map(|val| val.value(&mut cx))
|
||||
.unwrap_or_default(),
|
||||
);
|
||||
let error_if_tagged_old_versions: Option<bool> = Some(
|
||||
cx.argument_opt(2)
|
||||
.and_then(|val| val.downcast::<JsBoolean, _>(&mut cx).ok())
|
||||
.map(|val| val.value(&mut cx))
|
||||
.unwrap_or_default(),
|
||||
);
|
||||
|
||||
rt.spawn(async move {
|
||||
let stats = table
|
||||
.optimize(OptimizeAction::Prune {
|
||||
older_than: Some(older_than),
|
||||
delete_unverified,
|
||||
error_if_tagged_old_versions,
|
||||
})
|
||||
.await;
|
||||
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
[package]
|
||||
name = "lancedb"
|
||||
version = "0.7.2"
|
||||
version = "0.10.0-beta.0"
|
||||
edition.workspace = true
|
||||
description = "LanceDB: A serverless, low-latency vector database for AI applications"
|
||||
license.workspace = true
|
||||
@@ -29,6 +29,7 @@ lance-datafusion.workspace = true
|
||||
lance-index = { workspace = true }
|
||||
lance-linalg = { workspace = true }
|
||||
lance-testing = { workspace = true }
|
||||
lance-encoding = { workspace = true }
|
||||
pin-project = { workspace = true }
|
||||
tokio = { version = "1.23", features = ["rt-multi-thread"] }
|
||||
log.workspace = true
|
||||
@@ -46,15 +47,16 @@ serde_with = { version = "3.8.1" }
|
||||
reqwest = { version = "0.11.24", features = ["gzip", "json"], optional = true }
|
||||
polars-arrow = { version = ">=0.37,<0.40.0", optional = true }
|
||||
polars = { version = ">=0.37,<0.40.0", optional = true }
|
||||
hf-hub = {version = "0.3.2", optional = true}
|
||||
hf-hub = { version = "0.3.2", optional = true }
|
||||
candle-core = { version = "0.6.0", optional = true }
|
||||
candle-transformers = { version = "0.6.0", optional = true }
|
||||
candle-nn = { version = "0.6.0", optional = true }
|
||||
tokenizers = { version = "0.19.1", optional = true}
|
||||
tokenizers = { version = "0.19.1", optional = true }
|
||||
|
||||
[dev-dependencies]
|
||||
tempfile = "3.5.0"
|
||||
rand = { version = "0.8.3", features = ["small_rng"] }
|
||||
random_word = { version = "0.4.3", features = ["en"] }
|
||||
uuid = { version = "1.7.0", features = ["v4"] }
|
||||
walkdir = "2"
|
||||
aws-sdk-dynamodb = { version = "1.38.0" }
|
||||
@@ -70,7 +72,13 @@ fp16kernels = ["lance-linalg/fp16kernels"]
|
||||
s3-test = []
|
||||
openai = ["dep:async-openai", "dep:reqwest"]
|
||||
polars = ["dep:polars-arrow", "dep:polars"]
|
||||
sentence-transformers = ["dep:hf-hub", "dep:candle-core", "dep:candle-transformers", "dep:candle-nn", "dep:tokenizers"]
|
||||
sentence-transformers = [
|
||||
"dep:hf-hub",
|
||||
"dep:candle-core",
|
||||
"dep:candle-transformers",
|
||||
"dep:candle-nn",
|
||||
"dep:tokenizers"
|
||||
]
|
||||
|
||||
[[example]]
|
||||
name = "openai"
|
||||
|
||||
114
rust/lancedb/examples/full_text_search.rs
Normal file
114
rust/lancedb/examples/full_text_search.rs
Normal file
@@ -0,0 +1,114 @@
|
||||
// Copyright 2024 Lance Developers.
|
||||
//
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
use std::sync::Arc;
|
||||
|
||||
use arrow_array::{Int32Array, RecordBatch, RecordBatchIterator, RecordBatchReader, StringArray};
|
||||
use arrow_schema::{DataType, Field, Schema};
|
||||
|
||||
use futures::TryStreamExt;
|
||||
use lance_index::scalar::FullTextSearchQuery;
|
||||
use lancedb::connection::Connection;
|
||||
use lancedb::index::scalar::FtsIndexBuilder;
|
||||
use lancedb::index::Index;
|
||||
use lancedb::query::{ExecutableQuery, QueryBase};
|
||||
use lancedb::{connect, Result, Table};
|
||||
use rand::random;
|
||||
|
||||
#[tokio::main]
|
||||
async fn main() -> Result<()> {
|
||||
if std::path::Path::new("data").exists() {
|
||||
std::fs::remove_dir_all("data").unwrap();
|
||||
}
|
||||
let uri = "data/sample-lancedb";
|
||||
let db = connect(uri).execute().await?;
|
||||
let tbl = create_table(&db).await?;
|
||||
|
||||
create_index(&tbl).await?;
|
||||
search_index(&tbl).await?;
|
||||
Ok(())
|
||||
}
|
||||
|
||||
fn create_some_records() -> Result<Box<dyn RecordBatchReader + Send>> {
|
||||
const TOTAL: usize = 1000;
|
||||
|
||||
let schema = Arc::new(Schema::new(vec![
|
||||
Field::new("id", DataType::Int32, false),
|
||||
Field::new("doc", DataType::Utf8, true),
|
||||
]));
|
||||
|
||||
let words = random_word::all(random_word::Lang::En)
|
||||
.iter()
|
||||
.step_by(1024)
|
||||
.take(500)
|
||||
.map(|w| *w)
|
||||
.collect::<Vec<_>>();
|
||||
let n_terms = 3;
|
||||
let batches = RecordBatchIterator::new(
|
||||
vec![RecordBatch::try_new(
|
||||
schema.clone(),
|
||||
vec![
|
||||
Arc::new(Int32Array::from_iter_values(0..TOTAL as i32)),
|
||||
Arc::new(StringArray::from_iter_values((0..TOTAL).map(|_| {
|
||||
(0..n_terms)
|
||||
.map(|_| words[random::<usize>() % words.len()])
|
||||
.collect::<Vec<_>>()
|
||||
.join(" ")
|
||||
}))),
|
||||
],
|
||||
)
|
||||
.unwrap()]
|
||||
.into_iter()
|
||||
.map(Ok),
|
||||
schema.clone(),
|
||||
);
|
||||
Ok(Box::new(batches))
|
||||
}
|
||||
|
||||
async fn create_table(db: &Connection) -> Result<Table> {
|
||||
let initial_data: Box<dyn RecordBatchReader + Send> = create_some_records()?;
|
||||
let tbl = db.create_table("my_table", initial_data).execute().await?;
|
||||
Ok(tbl)
|
||||
}
|
||||
|
||||
async fn create_index(table: &Table) -> Result<()> {
|
||||
table
|
||||
.create_index(&["doc"], Index::FTS(FtsIndexBuilder::default()))
|
||||
.execute()
|
||||
.await?;
|
||||
Ok(())
|
||||
}
|
||||
|
||||
async fn search_index(table: &Table) -> Result<()> {
|
||||
let words = random_word::all(random_word::Lang::En)
|
||||
.iter()
|
||||
.step_by(1024)
|
||||
.take(500)
|
||||
.map(|w| *w)
|
||||
.collect::<Vec<_>>();
|
||||
let query = words[0].to_owned();
|
||||
println!("Searching for: {}", query);
|
||||
|
||||
let mut results = table
|
||||
.query()
|
||||
.full_text_search(FullTextSearchQuery::new(words[0].to_owned()))
|
||||
.select(lancedb::query::Select::Columns(vec!["doc".to_owned()]))
|
||||
.limit(10)
|
||||
.execute()
|
||||
.await?;
|
||||
while let Some(batch) = results.try_next().await? {
|
||||
println!("{:?}", batch);
|
||||
}
|
||||
Ok(())
|
||||
}
|
||||
@@ -22,7 +22,7 @@ use std::sync::Arc;
|
||||
use arrow_array::{RecordBatchIterator, RecordBatchReader};
|
||||
use arrow_schema::SchemaRef;
|
||||
use lance::dataset::{ReadParams, WriteMode};
|
||||
use lance::io::{ObjectStore, ObjectStoreParams, WrappingObjectStore};
|
||||
use lance::io::{ObjectStore, ObjectStoreParams, ObjectStoreRegistry, WrappingObjectStore};
|
||||
use object_store::{aws::AwsCredential, local::LocalFileSystem};
|
||||
use snafu::prelude::*;
|
||||
|
||||
@@ -35,6 +35,7 @@ use crate::io::object_store::MirroringObjectStoreWrapper;
|
||||
use crate::table::{NativeTable, TableDefinition, WriteOptions};
|
||||
use crate::utils::validate_table_name;
|
||||
use crate::Table;
|
||||
pub use lance_encoding::version::LanceFileVersion;
|
||||
|
||||
#[cfg(feature = "remote")]
|
||||
use log::warn;
|
||||
@@ -140,7 +141,7 @@ pub struct CreateTableBuilder<const HAS_DATA: bool, T: IntoArrow> {
|
||||
pub(crate) write_options: WriteOptions,
|
||||
pub(crate) table_definition: Option<TableDefinition>,
|
||||
pub(crate) embeddings: Vec<(EmbeddingDefinition, Arc<dyn EmbeddingFunction>)>,
|
||||
pub(crate) use_legacy_format: bool,
|
||||
pub(crate) data_storage_version: Option<LanceFileVersion>,
|
||||
}
|
||||
|
||||
// Builder methods that only apply when we have initial data
|
||||
@@ -154,7 +155,7 @@ impl<T: IntoArrow> CreateTableBuilder<true, T> {
|
||||
write_options: WriteOptions::default(),
|
||||
table_definition: None,
|
||||
embeddings: Vec::new(),
|
||||
use_legacy_format: true,
|
||||
data_storage_version: None,
|
||||
}
|
||||
}
|
||||
|
||||
@@ -186,7 +187,7 @@ impl<T: IntoArrow> CreateTableBuilder<true, T> {
|
||||
mode: self.mode,
|
||||
write_options: self.write_options,
|
||||
embeddings: self.embeddings,
|
||||
use_legacy_format: self.use_legacy_format,
|
||||
data_storage_version: self.data_storage_version,
|
||||
};
|
||||
Ok((data, builder))
|
||||
}
|
||||
@@ -220,7 +221,7 @@ impl CreateTableBuilder<false, NoData> {
|
||||
mode: CreateTableMode::default(),
|
||||
write_options: WriteOptions::default(),
|
||||
embeddings: Vec::new(),
|
||||
use_legacy_format: true,
|
||||
data_storage_version: None,
|
||||
}
|
||||
}
|
||||
|
||||
@@ -283,6 +284,14 @@ impl<const HAS_DATA: bool, T: IntoArrow> CreateTableBuilder<HAS_DATA, T> {
|
||||
self
|
||||
}
|
||||
|
||||
/// Set the data storage version.
|
||||
///
|
||||
/// The default is `LanceFileVersion::Legacy`.
|
||||
pub fn data_storage_version(mut self, data_storage_version: LanceFileVersion) -> Self {
|
||||
self.data_storage_version = Some(data_storage_version);
|
||||
self
|
||||
}
|
||||
|
||||
/// Set to true to use the v1 format for data files
|
||||
///
|
||||
/// This is currently defaulted to true and can be set to false to opt-in
|
||||
@@ -292,8 +301,13 @@ impl<const HAS_DATA: bool, T: IntoArrow> CreateTableBuilder<HAS_DATA, T> {
|
||||
///
|
||||
/// Once the new format is stable, the default will change to `false` for
|
||||
/// several releases and then eventually this option will be removed.
|
||||
#[deprecated(since = "0.9.0", note = "use data_storage_version instead")]
|
||||
pub fn use_legacy_format(mut self, use_legacy_format: bool) -> Self {
|
||||
self.use_legacy_format = use_legacy_format;
|
||||
self.data_storage_version = if use_legacy_format {
|
||||
Some(LanceFileVersion::Legacy)
|
||||
} else {
|
||||
Some(LanceFileVersion::Stable)
|
||||
};
|
||||
self
|
||||
}
|
||||
}
|
||||
@@ -789,13 +803,14 @@ impl Database {
|
||||
|
||||
let plain_uri = url.to_string();
|
||||
|
||||
let registry = Arc::new(ObjectStoreRegistry::default());
|
||||
let storage_options = options.storage_options.clone();
|
||||
let os_params = ObjectStoreParams {
|
||||
storage_options: Some(storage_options.clone()),
|
||||
..Default::default()
|
||||
};
|
||||
let (object_store, base_path) =
|
||||
ObjectStore::from_uri_and_params(&plain_uri, &os_params).await?;
|
||||
ObjectStore::from_uri_and_params(registry, &plain_uri, &os_params).await?;
|
||||
if object_store.is_local() {
|
||||
Self::try_create_dir(&plain_uri).context(CreateDirSnafu { path: plain_uri })?;
|
||||
}
|
||||
@@ -961,7 +976,7 @@ impl ConnectionInternal for Database {
|
||||
if matches!(&options.mode, CreateTableMode::Overwrite) {
|
||||
write_params.mode = WriteMode::Overwrite;
|
||||
}
|
||||
write_params.use_legacy_format = options.use_legacy_format;
|
||||
write_params.data_storage_version = options.data_storage_version;
|
||||
|
||||
match NativeTable::create(
|
||||
&table_uri,
|
||||
@@ -1202,7 +1217,7 @@ mod tests {
|
||||
|
||||
let tbl = db
|
||||
.create_table("v2_test", make_data())
|
||||
.use_legacy_format(false)
|
||||
.data_storage_version(LanceFileVersion::Stable)
|
||||
.execute()
|
||||
.await
|
||||
.unwrap();
|
||||
|
||||
@@ -14,24 +14,54 @@
|
||||
|
||||
use std::sync::Arc;
|
||||
|
||||
use scalar::FtsIndexBuilder;
|
||||
use serde::Deserialize;
|
||||
use serde_with::skip_serializing_none;
|
||||
|
||||
use crate::{table::TableInternal, Result};
|
||||
|
||||
use self::{
|
||||
scalar::BTreeIndexBuilder,
|
||||
scalar::{BTreeIndexBuilder, BitmapIndexBuilder, LabelListIndexBuilder},
|
||||
vector::{IvfHnswPqIndexBuilder, IvfHnswSqIndexBuilder, IvfPqIndexBuilder},
|
||||
};
|
||||
|
||||
pub mod scalar;
|
||||
pub mod vector;
|
||||
|
||||
/// Supported index types.
|
||||
pub enum Index {
|
||||
Auto,
|
||||
/// A `BTree` index is an sorted index on scalar columns.
|
||||
/// This index is good for scalar columns with mostly distinct values and does best when
|
||||
/// the query is highly selective. It can apply to numeric, temporal, and string columns.
|
||||
///
|
||||
/// BTree index is useful to answer queries with
|
||||
/// equality (`=`), inequality (`>`, `>=`, `<`, `<=`),and range queries.
|
||||
///
|
||||
/// This is the default index type for scalar columns.
|
||||
BTree(BTreeIndexBuilder),
|
||||
|
||||
/// A `Bitmap` index stores a bitmap for each distinct value in the column for every row.
|
||||
///
|
||||
/// This index works best for low-cardinality columns,
|
||||
/// where the number of unique values is small (i.e., less than a few hundreds).
|
||||
Bitmap(BitmapIndexBuilder),
|
||||
|
||||
/// [LabelListIndexBuilder] is a scalar index that can be used on `List<T>` columns to
|
||||
/// support queries with `array_contains_all` and `array_contains_any`
|
||||
/// using an underlying bitmap index.
|
||||
LabelList(LabelListIndexBuilder),
|
||||
|
||||
/// Full text search index using bm25.
|
||||
FTS(FtsIndexBuilder),
|
||||
|
||||
/// IVF index with Product Quantization
|
||||
IvfPq(IvfPqIndexBuilder),
|
||||
|
||||
/// IVF-HNSW index with Product Quantization
|
||||
IvfHnswPq(IvfHnswPqIndexBuilder),
|
||||
|
||||
/// IVF-HNSW index with Scalar Quantization
|
||||
IvfHnswSq(IvfHnswSqIndexBuilder),
|
||||
}
|
||||
|
||||
@@ -72,10 +102,14 @@ impl IndexBuilder {
|
||||
|
||||
#[derive(Debug, Clone, PartialEq)]
|
||||
pub enum IndexType {
|
||||
// Vector
|
||||
IvfPq,
|
||||
IvfHnswPq,
|
||||
IvfHnswSq,
|
||||
// Scalar
|
||||
BTree,
|
||||
Bitmap,
|
||||
LabelList,
|
||||
}
|
||||
|
||||
/// A description of an index currently configured on a column
|
||||
|
||||
@@ -28,3 +28,32 @@
|
||||
pub struct BTreeIndexBuilder {}
|
||||
|
||||
impl BTreeIndexBuilder {}
|
||||
|
||||
/// Builder for a Bitmap index.
|
||||
///
|
||||
/// It is a scalar index that stores a bitmap for each possible value
|
||||
///
|
||||
/// This index works best for low-cardinality (i.e., less than 1000 unique values) columns,
|
||||
/// where the number of unique values is small.
|
||||
/// The bitmap stores a list of row ids where the value is present.
|
||||
#[derive(Debug, Clone, Default)]
|
||||
pub struct BitmapIndexBuilder {}
|
||||
|
||||
/// Builder for LabelList index.
|
||||
///
|
||||
/// [LabeListIndexBuilder] is a scalar index that can be used on `List<T>` columns to
|
||||
/// support queries with `array_contains_all` and `array_contains_any`
|
||||
/// using an underlying bitmap index.
|
||||
///
|
||||
#[derive(Debug, Clone, Default)]
|
||||
pub struct LabelListIndexBuilder {}
|
||||
|
||||
/// Builder for a full text search index
|
||||
///
|
||||
/// A full text search index is an index on a string column that allows for full text search
|
||||
#[derive(Debug, Clone, Default)]
|
||||
pub struct FtsIndexBuilder {}
|
||||
|
||||
impl FtsIndexBuilder {}
|
||||
|
||||
pub use lance_index::scalar::FullTextSearchQuery;
|
||||
|
||||
@@ -13,7 +13,7 @@
|
||||
// limitations under the License.
|
||||
|
||||
//! [LanceDB](https://github.com/lancedb/lancedb) is an open-source database for vector-search built with persistent storage,
|
||||
//! which greatly simplifies retrevial, filtering and management of embeddings.
|
||||
//! which greatly simplifies retrieval, filtering and management of embeddings.
|
||||
//!
|
||||
//! The key features of LanceDB include:
|
||||
//! - Production-scale vector search with no servers to manage.
|
||||
@@ -133,6 +133,13 @@
|
||||
//!
|
||||
//! #### Create vector index (IVF_PQ)
|
||||
//!
|
||||
//! LanceDB is capable to automatically create appropriate indices based on the data types
|
||||
//! of the columns. For example,
|
||||
//!
|
||||
//! * If a column has a data type of `FixedSizeList<Float16/Float32>`,
|
||||
//! LanceDB will create a `IVF-PQ` vector index with default parameters.
|
||||
//! * Otherwise, it creates a `BTree` index by default.
|
||||
//!
|
||||
//! ```no_run
|
||||
//! # use std::sync::Arc;
|
||||
//! # use arrow_array::{FixedSizeListArray, types::Float32Type, RecordBatch,
|
||||
@@ -150,7 +157,10 @@
|
||||
//! # });
|
||||
//! ```
|
||||
//!
|
||||
//! #### Open table and run search
|
||||
//!
|
||||
//! User can also specify the index type explicitly, see [`Table::create_index`].
|
||||
//!
|
||||
//! #### Open table and search
|
||||
//!
|
||||
//! ```rust
|
||||
//! # use std::sync::Arc;
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user