All non-trivial updates extracted into separate commits, also `carho
hakari` data and its manifest format were updated.
3 sets of crates remain unupdated:
* `base64` — touches proxy in a lot of places and changed its api (by
0.21 version) quite strongly since our version (0.13).
* `opentelemetry` and `opentelemetry-*` crates
```
error[E0308]: mismatched types
--> libs/tracing-utils/src/http.rs:65:21
|
65 | span.set_parent(parent_ctx);
| ---------- ^^^^^^^^^^ expected struct `opentelemetry_api::context::Context`, found struct `opentelemetry::Context`
| |
| arguments to this method are incorrect
|
= note: struct `opentelemetry::Context` and struct `opentelemetry_api::context::Context` have similar names, but are actually distinct types
note: struct `opentelemetry::Context` is defined in crate `opentelemetry_api`
--> /Users/someonetoignore/.cargo/registry/src/github.com-1ecc6299db9ec823/opentelemetry_api-0.19.0/src/context.rs:77:1
|
77 | pub struct Context {
| ^^^^^^^^^^^^^^^^^^
note: struct `opentelemetry_api::context::Context` is defined in crate `opentelemetry_api`
--> /Users/someonetoignore/.cargo/registry/src/github.com-1ecc6299db9ec823/opentelemetry_api-0.18.0/src/context.rs:77:1
|
77 | pub struct Context {
| ^^^^^^^^^^^^^^^^^^
= note: perhaps two different versions of crate `opentelemetry_api` are being used?
note: associated function defined here
--> /Users/someonetoignore/.cargo/registry/src/github.com-1ecc6299db9ec823/tracing-opentelemetry-0.18.0/src/span_ext.rs:43:8
|
43 | fn set_parent(&self, cx: Context);
| ^^^^^^^^^^
For more information about this error, try `rustc --explain E0308`.
error: could not compile `tracing-utils` due to previous error
warning: build failed, waiting for other jobs to finish...
error: could not compile `tracing-utils` due to previous error
```
`tracing-opentelemetry` of version `0.19` is not yet released, that is
supposed to have the update we need.
* similarly, `rustls`, `tokio-rustls`, `rustls-*` and `tls-listener`
crates have similar issue:
```
error[E0308]: mismatched types
--> libs/postgres_backend/tests/simple_select.rs:112:78
|
112 | let mut make_tls_connect = tokio_postgres_rustls::MakeRustlsConnect::new(client_cfg);
| --------------------------------------------- ^^^^^^^^^^ expected struct `rustls::client::client_conn::ClientConfig`, found struct `ClientConfig`
| |
| arguments to this function are incorrect
|
= note: struct `ClientConfig` and struct `rustls::client::client_conn::ClientConfig` have similar names, but are actually distinct types
note: struct `ClientConfig` is defined in crate `rustls`
--> /Users/someonetoignore/.cargo/registry/src/github.com-1ecc6299db9ec823/rustls-0.21.0/src/client/client_conn.rs:125:1
|
125 | pub struct ClientConfig {
| ^^^^^^^^^^^^^^^^^^^^^^^
note: struct `rustls::client::client_conn::ClientConfig` is defined in crate `rustls`
--> /Users/someonetoignore/.cargo/registry/src/github.com-1ecc6299db9ec823/rustls-0.20.8/src/client/client_conn.rs:91:1
|
91 | pub struct ClientConfig {
| ^^^^^^^^^^^^^^^^^^^^^^^
= note: perhaps two different versions of crate `rustls` are being used?
note: associated function defined here
--> /Users/someonetoignore/.cargo/registry/src/github.com-1ecc6299db9ec823/tokio-postgres-rustls-0.9.0/src/lib.rs:23:12
|
23 | pub fn new(config: ClientConfig) -> Self {
| ^^^
For more information about this error, try `rustc --explain E0308`.
error: could not compile `postgres_backend` due to previous error
warning: build failed, waiting for other jobs to finish...
```
* aws crates: I could not make new API to work with bucket endpoint
overload, and console e2e tests failed.
Other our tests passed, further investigation is worth to be done in
https://github.com/neondatabase/neon/issues/4008
The PR changes module function-based walreceiver interface with a
`WalReceiver` struct that exposes a few public methods, `new`, `start`
and `stop` now.
Later, the same struct is planned to be used for getting walreceiver
stats (and, maybe, other extra data) to display during missing wal
errors for https://github.com/neondatabase/neon/issues/2106
Now though, the change required extra logic changes:
* due to the `WalReceiver` struct added, it became easier to pass `ctx`
and later do a `detached_child` instead of
bfee412701/pageserver/src/tenant/timeline.rs (L1379-L1381)
* `WalReceiver::start` which is now the public API to start the
walreceiver, could return an `Err` which now may turn a tenant into
`Broken`, same as the timeline that it tries to load during startup.
* `WalReceiverConf` was added to group walreceiver parameters from
pageserver's tenant config
Sometimes, it contained real values, sometimes just defaults if the
spec was not received yet. Make the state more clear by making it an
Option instead.
One consequence is that if some of the required settings like
neon.tenant_id are missing from the spec file sent to the /configure
endpoint, it is spotted earlier and you get an immediate HTTP error
response. Not that it matters very much, but it's nicer nevertheless.
Aarch64 doesn't implement some old syscalls like open and select. Use
openat instead of open to check if seccomp is supported. Leave both
select and pselect6 in the allowlist since we don't call select syscall
directly and may hope that libc will call pselect6 on aarch64.
To check whether some syscall is supported it is possible to use
`scmp_sys_resolver` from seccopm package:
```
> apt install seccopm
> scmp_sys_resolver -a x86_64 select
23
> scmp_sys_resolver -a aarch64 select
-10101
> scmp_sys_resolver -a aarch64 pselect6
72
```
Negative value means that syscall is not supported.
Another cross-check is to look up for the actuall syscall table in
`unistd.h`. To resolve all the macroses one can use `gcc -E` as it is
done in `dump_sys_aarch64()` function in
libseccomp/src/arch-syscall-validate.
---------
Co-authored-by: Heikki Linnakangas <heikki@neon.tech>
TCP_KEEPALIVE is not enabled by default, so this prevents hanged up connections
in case of abrupt client termination. Add 'closed' flag to PostgresBackendReader
and pass it during handles join to prevent attempts to read from socket if we
errored out previously -- now with timeouts this is a common situation.
It looks like
2023-04-10T18:08:37.493448Z INFO {cid=68}:WAL
receiver{ttid=59f91ad4e821ab374f9ccdf918da3a85/16438f99d61572c72f0c7b0ed772785d}:
terminated: timed out
Presumably fixes https://github.com/neondatabase/neon/issues/3971
Aarch64 doesn't implement some old syscalls like open and select. Use
openat instead of open to check if seccomp is supported. Leave both
select and pselect6 in the allowlist since we don't call select syscall
directly and may hope that libc will call pselect6 on aarch64.
To check whether some syscall is supported it is possible to use
`scmp_sys_resolver` from seccopm package:
```
> apt install seccopm
> scmp_sys_resolver -a x86_64 select
23
> scmp_sys_resolver -a aarch64 select
-10101
> scmp_sys_resolver -a aarch64 pselect6
72
```
Negative value means that syscall is not supported.
Another cross-check is to look up for the actuall syscall table
in `unistd.h`. To resolve all the macroses one can use `gcc -E` as
it is done in `dump_sys_aarch64()` function in
libseccomp/src/arch-syscall-validate.
This is in preparation of using compute_ctl to launch postgres nodes
in the neon_local control plane. And seems like a good idea to
separate the public interfaces anyway.
One non-mechanical change here is that the 'metrics' field is moved
under the Mutex, instead of using atomics. We were not using atomics
for performance but for convenience here, and it seems more clear to
not use atomics in the model for the HTTP response type.
We have enabled prefetch by default, let's use this in Nightly
Benchmarks:
- effective_io_concurrency=100 by default (instead of 32)
- maintenance_io_concurrency=100 by default (instead of 32)
Rename `neon-captest-prefetch` to `neon-captest-new` (for pgbench with
initialisation) and `neon-captest-reuse` (for OLAP scenarios)
Replaces `Box<(dyn io::AsyncRead + Unpin + Send + Sync + 'static)>` with
`impl io::AsyncRead + Unpin + Send + Sync + 'static` usages in the
`RemoteStorage` interface, to make it closer to
[`#![feature(async_fn_in_trait)]`](https://blog.rust-lang.org/inside-rust/2022/11/17/async-fn-in-trait-nightly.html)
For `GenericRemoteStorage`, replaces `type Target = dyn RemoteStorage`
with another impl with `RemoteStorage` methods inside it.
We can reuse the trait, that would require importing the trait in every
file where it's used and makes us farther from the unstable feature.
After this PR, I've manged to create a patch with the changes:
https://github.com/neondatabase/neon/compare/kb/less-dyn-storage...kb/nightly-async-trait?expand=1
Current rust implementation does not like recursive async trait calls,
so `UnreliableWrapper` was removed: it contained a
`GenericRemoteStorage` that implemented the `RemoteStorage` trait, and
itself implemented the trait, which nightly rustc did not like and
proposed to box the future.
Similarly, `GenericRemoteStorage` cannot implement `RemoteStorage` for
nightly rustc to work, since calls various remote storages' methods from
inside.
I've compiled current `main` and the nightly branch both with `time env
RUSTC_WRAPPER="" cargo +nightly build --all --timings` command, and got
```
Finished dev [optimized + debuginfo] target(s) in 2m 04s
env RUSTC_WRAPPER="" cargo +nightly build --all --timings 1283.19s user 50.40s system 1074% cpu 2:04.15 total
for the new feature tried and
Finished dev [optimized + debuginfo] target(s) in 2m 40s
env RUSTC_WRAPPER="" cargo +nightly build --all --timings 1288.59s user 52.06s system 834% cpu 2:40.71 total
for the old async_trait approach.
```
On my machine, the `remote_storage` lib compilation takes ~10 less time
with the nightly feature (left) than the regular main (right).
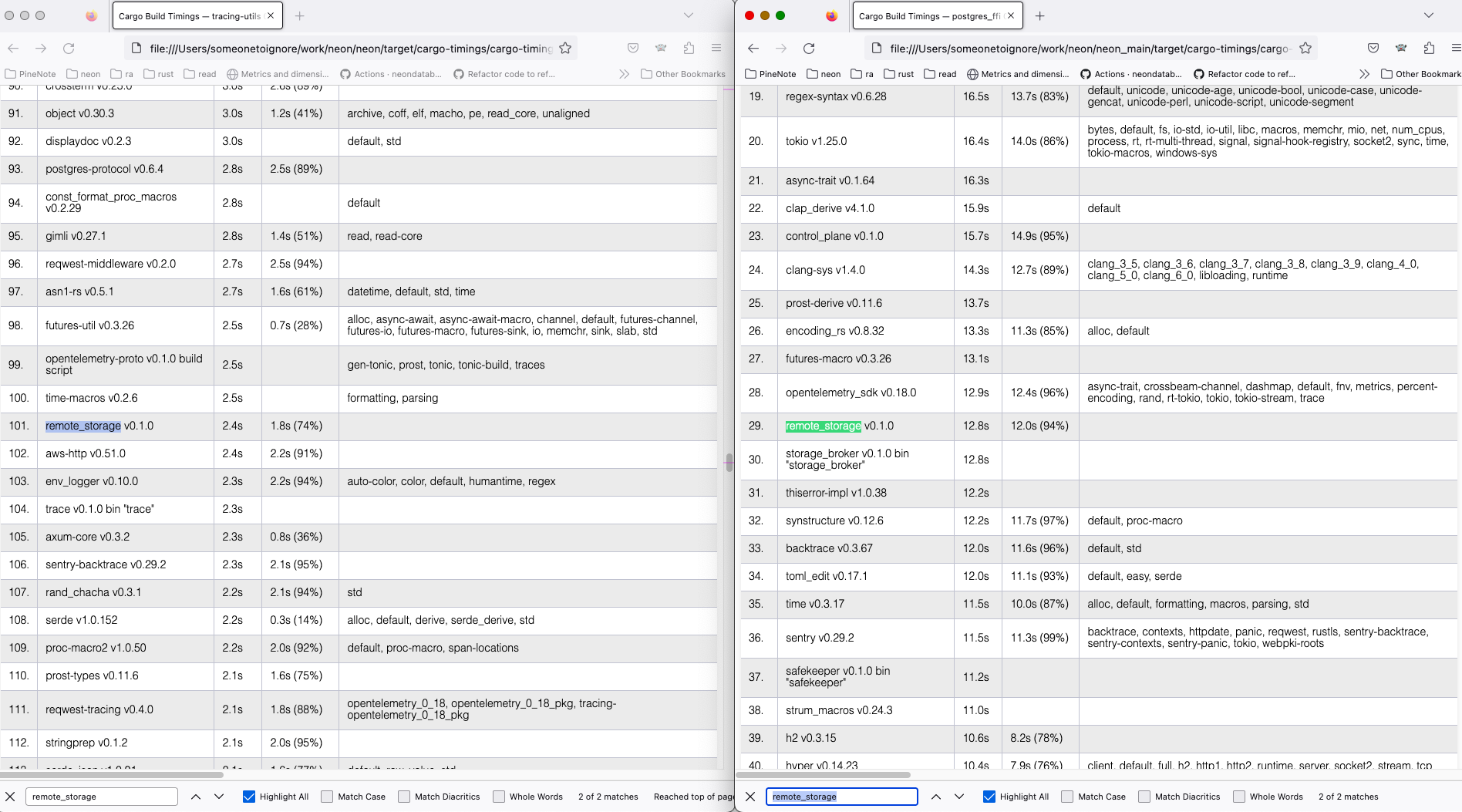
Full cargo reports are available at
[timings.zip](https://github.com/neondatabase/neon/files/11179369/timings.zip)
## Describe your changes
## Issue ticket number and link
## Checklist before requesting a review
- [ ] I have performed a self-review of my code.
- [ ] If it is a core feature, I have added thorough tests.
- [ ] Do we need to implement analytics? if so did you add the relevant
metrics to the dashboard?
- [ ] If this PR requires public announcement, mark it with
/release-notes label and add several sentences in this section.
## Checklist before merging
- [ ] Do not forget to reformat commit message to not include the above
checklist
Old coding here ignored non-wildcard common names and passed None instead. With my recent changes
I started throwing an error in that case. Old logic doesn't seem to be a great choice, so instead
of passing None I actually set non-wildcard common names too. That way it is possible to avoid handling
cases with None in downstream code.
This commit adds an option to start compute without spec and then pass
it a valid spec via `POST /configure` API endpoint. This is a main
prerequisite for maintaining the pool of compute nodes in the
control-plane.
For example:
1. Start compute with
```shell
cargo run --bin compute_ctl -- -i no-compute \
-p http://localhost:9095 \
-D compute_pgdata \
-C "postgresql://cloud_admin@127.0.0.1:5434/postgres" \
-b ./pg_install/v15/bin/postgres
```
2. Configure it with
```shell
curl -d "{\"spec\": $(cat ./compute-spec.json)}" http://localhost:3080/configure
```
Internally, it's implemented using a `Condvar` + `Mutex`. Compute spec
is moved under Mutex, as it's now could be updated in the http handler.
Also `RwLock` was replaced with `Mutex` because the latter works well
with `Condvar`.
First part of the neondatabase/cloud#4433
This allows to skip compatibility tests based on `CHECK_ONDISK_DATA_COMPATIBILITY` environment variable. When the variable is missing (default) compatibility tests wont be run.
Otherwise it can lag a lot, preventing WAL segments cleanup. Also max
wal_backup_lsn on update, pulling it down is pointless.
Should help with https://github.com/neondatabase/neon/issues/3957, but
will not fix it completely.
## Describe your changes
In https://github.com/neondatabase/cloud/issues/4354 we are making
scheduling of projects based on available disk space and overcommit, so
we need to know disk size and just in case instance type of the
pageserver
## Issue ticket number and link
https://github.com/neondatabase/cloud/issues/4354
## Checklist before requesting a review
- [x] I have performed a self-review of my code.
- [ ] ~If it is a core feature, I have added thorough tests.~
- [ ] ~Do we need to implement analytics? if so did you add the relevant
metrics to the dashboard?~
- [ ] ~If this PR requires public announcement, mark it with
/release-notes label and add several sentences in this section.~
in real env testing we noted that the disk-usage based eviction sails 1
percentage point above the configured value, which might be a source of
confusion, so it might be better to get rid of that confusion now.
confusion: "I configured 85% but pageserver sails at 86%".
Co-authored-by: Christian Schwarz <christian@neon.tech>
Make it possible to specify directory where proxy will look up for
extra certificates. Proxy will iterate through subdirs of that directory
and load `key.pem` and `cert.pem` files from each subdir. Certs directory
structure may look like that:
certs
|--example.com
| |--key.pem
| |--cert.pem
|--foo.bar
|--key.pem
|--cert.pem
Actual domain names are taken from certs and key, subdir names are
ignored.
This PR adds posting a comment with test results. Each workflow run
updates the comment with new results.
The layout and the information that we post can be changed to our needs,
right now, it contains failed tests and test which changes status after
rerun (i.e. flaky tests)
This PR adds a plugin that automatically reruns (up to 3 times) flaky
tests. Internally, it uses data from `TEST_RESULT_CONNSTR` database and
`pytest-rerunfailures` plugin.
As the first approximation we consider the test flaky if it has failed on
the main branch in the last 10 days.
Flaky tests are fetched by `scripts/flaky_tests.py` script (it's
possible to use it in a standalone mode to learn which tests are flaky),
stored to a JSON file, and then the file is passed to the pytest plugin.
In S3, pageserver only lists tenants (prefixes) on S3, no other keys.
Remove the list operation from the API, since S3 impl does not seem to
work normally and not used anyway,
For some reason, `tracing::instrument` proc_macro doesn't always print
elements specified via `fields()` or even show that it's impossible
(e.g. there's no Display impl).
Work around this using the `?foo` notation.
Before:
2023-04-03T14:48:06.017504Z INFO handle_client🤝 received SslRequest
After:
2023-04-03T14:51:24.424176Z INFO handle_client{session_id=7bd07be8-3462-404e-8ccc-0a5332bf3ace}🤝 received SslRequest
Leave disk_usage_based_eviction above the current max usage in prod
(82%ish), so that deploying this commit won't trigger
disk_usage_based_eviction.
As indicated in the TODO, we'll decrease the value to 80% later.
Also update the staging YAMLs to use the anchor syntax for
`evictions_low_residence_duration_metric_threshold` like we do in the
prod YAMLs as of this patch.
this will help log analysis with the counterpart of already logging all
remote download needs and downloads. ended up with a easily regexable
output in the final round.
This is the the feedback originating from pageserver, so change previous
confusing names to
s/ReplicationFeedback/PageserverFeedback
s/ps_writelsn/last_receive_lsn
s/ps_flushlsn/disk_consistent_lsn
s/ps_apply_lsn/remote_consistent_lsn
I haven't changed on the wire format to keep compatibility. However,
understanding of new field names is added to compute, so once all computes
receive this patch we can change the wire names as well. Safekeepers/pageservers
are deployed roughly at the same time and it is ok to live without feedbacks
during the short period, so this is not a problem there.
Add a condition to switch walreceiver connection to safekeeper that is
located in the same availability zone. Switch happens when commit_lsn of
a candidate is not less than commit_lsn from the active connection. This
condition is expected not to trigger instantly, because commit_lsn of a
current connection is usually greater than commit_lsn of updates from
the broker. That means that if WAL is written continuously, switch can
take a lot of time, but it should happen eventually.
Now protoc 3.15+ is required for building neon.
Fixes https://github.com/neondatabase/neon/issues/3200
{kind=link}