This patch adds a LaunchTimestamp type to the `metrics` crate,
along with a `libmetric_` Prometheus metric.
The initial user is pageserver.
In addition to exposing the Prometheus metric, it also reproduces
the launch timestamp as a header in the API responses.
The motivation for this is that we plan to scrape the pageserver's
/v1/tenant/:tenant_id/timeline/:timeline_id/layer
HTTP endpoint over time. It will soon expose access metrics (#3496)
which reset upon process restart. We will use the pageserver's launch
ID to identify a restart between two scrape points.
However, there are other potential uses. For example, we could use
the Prometheus metric to annotate Grafana plots whenever the launch
timestamp changes.
Cc: #3486
Adds a method to replace a particular layer from the LayerMap for the
purposes of remote layer download and layer eviction. In those use cases
read lock on layer map needs to be released after initial search, but
other operations could modify layermap before replacing thread gets to
run.
Co-authored-by: bojanserafimov <bojan.serafimov7@gmail.com>
## Describe your changes
Add libmetrics_build_info metrics with commit sha to storage_broken
/metrics, to match behaviour of proxy, pageserver and safekeeper.
## Describe your changes
## Issue ticket number and link
## Checklist before requesting a review
- [ ] I have performed a self-review of my code.
- [ ] If it is a core feature, I have added thorough tests.
- [ ] Do we need to implement analytics? if so did you add the relevant
metrics to the dashboard?
- [ ] If this PR requires public announcement, mark it with
/release-notes label and add several sentences in this section.
The project/endpoint should be set in the original (non-as_ref'd) creds,
because we call `wake_compute` not only in `try_password_hack` but also
later in the connection retry logic.
This PR also removes the obsolete `as_ref` method and makes the code
simpler because we no longer need this complication after a recent
refactoring.
Further action points: finally introduce typestate in creds (planned).
We do not need special enum variant for testing the file names, neither
its special handling across the code.
Current tests are able to create regular layers with normal layer names,
as the PR shows.
Closes https://github.com/neondatabase/neon/issues/3439
Adds a set of commands to manipulate the layer map:
* dump the layer map contents
* evict the layer form the layer map (remove the local file, put the
remote layer instead in the layer map)
* download the layer (operation, reversing the eviction)
The commands will change later, when the statistics is added on top, so
the swagger schema is not adjusted.
The commands might have issues with big amount of layers: no pagination
is done for the dump command, eviction and download commands look for
the layer to evict/download by iterating all layers sequentially and
comparing the layer names.
For now, that seems to be tolerable ("big" number of layers is ~2_000)
and further experiments are needed.
---------
Co-authored-by: Christian Schwarz <christian@neon.tech>
Adds two new tags, `run-extra-build-macos` and `run-extra-build-stats`
to trigger corresponding build jobs on any PR.
On every build for `main` or PR with `run-extra-build-stats` tag, publish a GitHub commit status with the link to the `cargo build --all --release --timings` report.
This patch adds a timed LRU cache implementation and a compute node info cache on top of that.
Cache entries might expire on their own (default ttl=5mins) or become invalid due to real-world events,
e.g. compute node scale-to-zero event, so we add a connection retry loop with a wake-up call.
Solved problems:
- [x] Find a decent LRU implementation.
- [x] Implement timed LRU on top of that.
- [x] Cache results of `proxy_wake_compute` API call.
- [x] Don't invalidate newer cache entries for the same key.
- [x] Add cmdline configuration knobs (requires some refactoring).
- [x] Add failed connection estab metric.
- [x] Refactor auth backends to make things simpler (retries, cache
placement, etc).
- [x] Address review comments (add code comments + cleanup).
- [x] Retry `/proxy_wake_compute` if we couldn't connect to a compute
(e.g. stalled cache entry).
- [x] Add high-level description for `TimedLru`.
TODOs (will be addressed later):
- [ ] Add cache metrics (hit, spurious hit, miss).
- [ ] Synchronize http requests across concurrent per-client tasks
(https://github.com/neondatabase/neon/pull/3331#issuecomment-1399216069).
- [ ] Cache results of `proxy_get_role_secret` API call.
- add parse_query_param()
- use Cow<> where possible
- move param parsing code to utils::http::request
This was originally PR https://github.com/neondatabase/neon/pull/3502
which targeted a different branch.
closes #3510
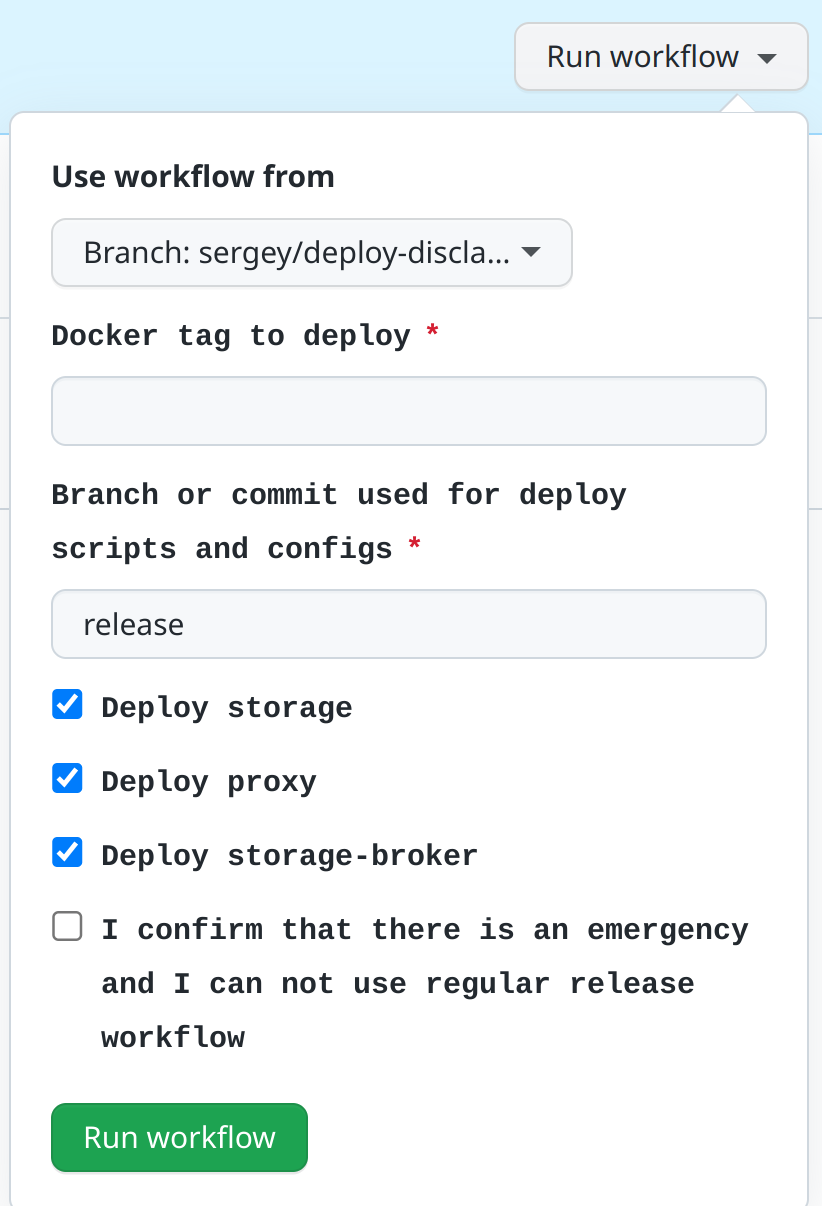
Add 'branch' input to specify commit for deploy scripts/configs. Commit
can't be passed to workflow as ref, and we need to pin configs to
specific commit for main/release deploys
Update deploy input descriptions to match GH interface
Extract deploy jobs from build_and_test.yml to deploy-dev and
deploy-prod workflows.
Add trigger to run this workflows after Neon is build and tested on main and
release branches.
This will allow us to redeploy/rollback/patch config without full
rebuild.
Related to: https://github.com/neondatabase/neon/issues/2848
`pageserver_storage_operations_seconds` is the most expensive metric we
have, as there are a lot of tenants/timelines and the histogram had 42
buckets. These are quite sparse too, so instead of having a histogram
per timeline, create a new histogram
`pageserver_storage_operations_seconds_global` without tenant and
timeline dimensions and replace `pageserver_storage_operations_seconds`
with sum and counter.
Co-authored-by: Joonas Koivunen <joonas@neon.tech>
I added these spans to trace how long the queries take, but I didn't realize
that there's a difference between:
let _ = span.entered();
and
let _guard = span.entered();
The former drops the guard immediately, while the latter holds it
until the end of the scope. As a result, the span was ended
immediately, and the query was executed outside the span.
## Describe your changes
Added a metric that allow to monitor tenants state
## Issue ticket number and link
https://github.com/neondatabase/neon/issues/3161
## Checklist before requesting a review
- [X] I have performed a self-review of my code.
- [X] I have added an e2e test for it.
- [ ] Do we need to implement analytics? if so did you add the relevant
metrics to the dashboard?
- [ ] If this PR requires public announcement, mark it with
/release-notes label and add several sentences in this section.
## Describe your changes
Whenever a tenant is detached or the pageserver is restarted the
pageserver_last_record_lsn metric is dropped
This fix resurrects the value from the metadata whenever the tenant is
attached again
## Issue ticket number and link
[3571](https://github.com/neondatabase/cloud/issues/3571)
## Checklist before requesting a review
- [X] I have performed a self-review of my code.
- [ ] If it is a core feature, I have added thorough tests.
- [ ] Do we need to implement analytics? if so did you add the relevant
metrics to the dashboard?
- [ ] If this PR requires public announcement, mark it with
/release-notes label and add several sentences in this section.
To fix `Error: The requested DurationSeconds exceeds the
MaxSessionDuration set for this role.`
Co-authored-by: Rory de Zoete <rdezoete@Rorys-Mac-Studio.fritz.box>
Currently `attach` doesn't write a tenant config, because we don't back
it up in the first place. The current implementation of
`Tenant::persist_tenant_config` does not allow changing tenant's
configuration through the http api which will fail because the file
wasn't created on attach and
`OpenOptions::truncate(true).write(true).create_new(false)` is used.
I think this patch allows for least controversial middle ground which
*enables* changing tenant configuration even for attached tenants (not
just created tenants).
Walreceiver is a per-timeline abstraction. Move it there to reflect
the hierarchy of abstractions and task_mgr tasks.
The code that sets up the global storage_broker client
is not timeline-scoped. So, break it out into a separate module.
The motivation for this change is to prepare the code base for replacing
the task_mgr global task registry with a more ownership-oriented
approach to manage task lifetimes.
I removed TaskStateUpdate::Init because, after doing the changes,
rustc warned that it was never constructed.
A quick search through the commit history shows that this
has always been true since
commit fb68d01449
Author: Dmitry Rodionov <dmitry@neon.tech>
Date: Mon Sep 26 23:57:02 2022 +0300
Preserve task result in TaskHandle by keeping join handle around (#2521)
So, the warning is not an indication of some accidental code removal.
This is PR: https://github.com/neondatabase/neon/pull/3456
Change the signature so that it takes an Arc<Timeline> reference to the
source timeline, instead of just the ID. All the callers have an Arc
reference at hand, so this is more convenient for everyone.
Reorder the code a bit and improve the comments, to make it more clear
what it does and why.
To fix errors such as:
`An error occurred (ImageAlreadyExistsException) when calling the
PutImage operation: Image with digest
'sha256:da6d8ad97d84e3aec4e6a240c3a35868b626692ee5d199cdd3fe45d29a8e54df'
and tag 'latest' already exists in the repository with name
'compute-node-v14' in registry with id '369495373322'`
Co-authored-by: Rory de Zoete <rdezoete@RorysMacStudio.fritz.box>
Co-authored-by: Rory de Zoete <rdezoete@Rorys-Mac-Studio.fritz.box>
This allows fine-grained distributed tracing of the 'start_compute'
operation from the cloud console. The startup actions performed by
'compute_ctl' are now performed in a child of the 'start_compute'
context, so you can trace through the whole compute start operation.
This needs a corresponding change in the cloud console to fill in the
'startup_tracing_context' field in the json spec. If it's missing, the
startup operations are simply traced as a separate trace, without
a parent.
This allows tracing the startup actions e.g. with Jaeger
(https://www.jaegertracing.io/). We use the "tracing-opentelemetry"
crate, which turns tracing spans into OpenTelemetry spans, so you can
use the usual "#[instrument]" directives to add tracing.
I put the tracing initialization code to a separate crate,
`tracing-utils`, so that we can reuse it in other programs. We
probably want to set up tracing in the same way in all our programs.
Co-authored-by: Joonas Koivunen <joonas@neon.tech>
{kind=link}