This patch adds basic access statistics for historic layers
and exposes them in the management API's `LayerMapInfo`.
We record the accesses in the `{Delta,Image}Layer::load()` function
because it's the common path of
* page_service (`Timline::get_reconstruct_data()`)
* Compaction (`PersistentLayer::iter()` and `PersistentLayer::key_iter()`)
The stats survive residence status changes, and record these as well.
When scraping the layer map endpoint to record its evolution over time,
one must account for stat resets because they are in-memory only and
will reset on pageserver restart.
Use the launch timestamp header added by (#3527) to identify pageserver restarts.
This is PR https://github.com/neondatabase/neon/pull/3496
Add new pageserver config setting `cached_metric_collection_interval`
with default `1 hour`.
This setting controls how often unchanged cached consumption metrics are sent to
the HTTP endpoint.
This is a workaround for billing service limitations.
fixes#3485
Follow-up to #3513.
This removes the old blanket `std::fmt::Debug` impl on `dyn Layer` which
did not seem to be used from anywhere (no compilation errors after
removing).
Adds `std::fmt::Debug` requirement and implementations for `trait Layer`
implementors:
- LayerDescriptor (derived)
- RemoteLayer (manual)
- DeltaLayer (manual)
- ImageLayer (manual)
Manual implementations are used to skip PageserverConf, tenant and
timeline ids, large collections.
Adds and adjusts some doc comments to be more rustdoc alike.
## Describe your changes
Expose the currently calculated synthetic size as a Prometheus metric
## Issue ticket number and link
#3509
## Checklist before requesting a review
- [X] I have performed a self-review of my code.
- [ ] If it is a core feature, I have added thorough tests.
- [ ] Do we need to implement analytics? if so did you add the relevant
metrics to the dashboard?
- [ ] If this PR requires public announcement, mark it with
/release-notes label and add several sentences in this section.
The PR adds an endpoint to show tenant's current config: `GET
/v1/tenant/:tenant_id/config`
Tenant's config consists of two parts: tenant overrides (could be
changed via other management API requests) and the default part,
substituting all missing overrides (constant, hardcoded in pageserver).
The API returns the custom overrides and the final tenant config, after
applying all the defaults.
Along the way, it had to fix two things in the config:
* allow to shorten the json version and omit all `null`'s (same as toml
serializer behaves by default), and to understand such shortened format
when deserialized. A unit test is added
* fix a bug, when `PUT /v1/tenant/config` endpoint rewritten the local
file with what had came in the request, but updating (not rewriting the
old values) the in-memory state instead.
That got uncovered during adjusting the e2e test and fixed to do the
replacement everywhere, otherwise there's no way to revert existing
overrides. Fixes#3471 (commit
dc688affe8)
* fixes https://github.com/neondatabase/neon/issues/3472 by reordering
the config saving operations
This patch adds a LaunchTimestamp type to the `metrics` crate,
along with a `libmetric_` Prometheus metric.
The initial user is pageserver.
In addition to exposing the Prometheus metric, it also reproduces
the launch timestamp as a header in the API responses.
The motivation for this is that we plan to scrape the pageserver's
/v1/tenant/:tenant_id/timeline/:timeline_id/layer
HTTP endpoint over time. It will soon expose access metrics (#3496)
which reset upon process restart. We will use the pageserver's launch
ID to identify a restart between two scrape points.
However, there are other potential uses. For example, we could use
the Prometheus metric to annotate Grafana plots whenever the launch
timestamp changes.
Cc: #3486
Adds a method to replace a particular layer from the LayerMap for the
purposes of remote layer download and layer eviction. In those use cases
read lock on layer map needs to be released after initial search, but
other operations could modify layermap before replacing thread gets to
run.
Co-authored-by: bojanserafimov <bojan.serafimov7@gmail.com>
## Describe your changes
Add libmetrics_build_info metrics with commit sha to storage_broken
/metrics, to match behaviour of proxy, pageserver and safekeeper.
## Describe your changes
## Issue ticket number and link
## Checklist before requesting a review
- [ ] I have performed a self-review of my code.
- [ ] If it is a core feature, I have added thorough tests.
- [ ] Do we need to implement analytics? if so did you add the relevant
metrics to the dashboard?
- [ ] If this PR requires public announcement, mark it with
/release-notes label and add several sentences in this section.
The project/endpoint should be set in the original (non-as_ref'd) creds,
because we call `wake_compute` not only in `try_password_hack` but also
later in the connection retry logic.
This PR also removes the obsolete `as_ref` method and makes the code
simpler because we no longer need this complication after a recent
refactoring.
Further action points: finally introduce typestate in creds (planned).
We do not need special enum variant for testing the file names, neither
its special handling across the code.
Current tests are able to create regular layers with normal layer names,
as the PR shows.
Closes https://github.com/neondatabase/neon/issues/3439
Adds a set of commands to manipulate the layer map:
* dump the layer map contents
* evict the layer form the layer map (remove the local file, put the
remote layer instead in the layer map)
* download the layer (operation, reversing the eviction)
The commands will change later, when the statistics is added on top, so
the swagger schema is not adjusted.
The commands might have issues with big amount of layers: no pagination
is done for the dump command, eviction and download commands look for
the layer to evict/download by iterating all layers sequentially and
comparing the layer names.
For now, that seems to be tolerable ("big" number of layers is ~2_000)
and further experiments are needed.
---------
Co-authored-by: Christian Schwarz <christian@neon.tech>
Adds two new tags, `run-extra-build-macos` and `run-extra-build-stats`
to trigger corresponding build jobs on any PR.
On every build for `main` or PR with `run-extra-build-stats` tag, publish a GitHub commit status with the link to the `cargo build --all --release --timings` report.
This patch adds a timed LRU cache implementation and a compute node info cache on top of that.
Cache entries might expire on their own (default ttl=5mins) or become invalid due to real-world events,
e.g. compute node scale-to-zero event, so we add a connection retry loop with a wake-up call.
Solved problems:
- [x] Find a decent LRU implementation.
- [x] Implement timed LRU on top of that.
- [x] Cache results of `proxy_wake_compute` API call.
- [x] Don't invalidate newer cache entries for the same key.
- [x] Add cmdline configuration knobs (requires some refactoring).
- [x] Add failed connection estab metric.
- [x] Refactor auth backends to make things simpler (retries, cache
placement, etc).
- [x] Address review comments (add code comments + cleanup).
- [x] Retry `/proxy_wake_compute` if we couldn't connect to a compute
(e.g. stalled cache entry).
- [x] Add high-level description for `TimedLru`.
TODOs (will be addressed later):
- [ ] Add cache metrics (hit, spurious hit, miss).
- [ ] Synchronize http requests across concurrent per-client tasks
(https://github.com/neondatabase/neon/pull/3331#issuecomment-1399216069).
- [ ] Cache results of `proxy_get_role_secret` API call.
- add parse_query_param()
- use Cow<> where possible
- move param parsing code to utils::http::request
This was originally PR https://github.com/neondatabase/neon/pull/3502
which targeted a different branch.
closes #3510
Add 'branch' input to specify commit for deploy scripts/configs. Commit
can't be passed to workflow as ref, and we need to pin configs to
specific commit for main/release deploys
Update deploy input descriptions to match GH interface
Extract deploy jobs from build_and_test.yml to deploy-dev and
deploy-prod workflows.
Add trigger to run this workflows after Neon is build and tested on main and
release branches.
This will allow us to redeploy/rollback/patch config without full
rebuild.
Related to: https://github.com/neondatabase/neon/issues/2848
`pageserver_storage_operations_seconds` is the most expensive metric we
have, as there are a lot of tenants/timelines and the histogram had 42
buckets. These are quite sparse too, so instead of having a histogram
per timeline, create a new histogram
`pageserver_storage_operations_seconds_global` without tenant and
timeline dimensions and replace `pageserver_storage_operations_seconds`
with sum and counter.
Co-authored-by: Joonas Koivunen <joonas@neon.tech>
I added these spans to trace how long the queries take, but I didn't realize
that there's a difference between:
let _ = span.entered();
and
let _guard = span.entered();
The former drops the guard immediately, while the latter holds it
until the end of the scope. As a result, the span was ended
immediately, and the query was executed outside the span.
## Describe your changes
Added a metric that allow to monitor tenants state
## Issue ticket number and link
https://github.com/neondatabase/neon/issues/3161
## Checklist before requesting a review
- [X] I have performed a self-review of my code.
- [X] I have added an e2e test for it.
- [ ] Do we need to implement analytics? if so did you add the relevant
metrics to the dashboard?
- [ ] If this PR requires public announcement, mark it with
/release-notes label and add several sentences in this section.
## Describe your changes
Whenever a tenant is detached or the pageserver is restarted the
pageserver_last_record_lsn metric is dropped
This fix resurrects the value from the metadata whenever the tenant is
attached again
## Issue ticket number and link
[3571](https://github.com/neondatabase/cloud/issues/3571)
## Checklist before requesting a review
- [X] I have performed a self-review of my code.
- [ ] If it is a core feature, I have added thorough tests.
- [ ] Do we need to implement analytics? if so did you add the relevant
metrics to the dashboard?
- [ ] If this PR requires public announcement, mark it with
/release-notes label and add several sentences in this section.
To fix `Error: The requested DurationSeconds exceeds the
MaxSessionDuration set for this role.`
Co-authored-by: Rory de Zoete <rdezoete@Rorys-Mac-Studio.fritz.box>
Currently `attach` doesn't write a tenant config, because we don't back
it up in the first place. The current implementation of
`Tenant::persist_tenant_config` does not allow changing tenant's
configuration through the http api which will fail because the file
wasn't created on attach and
`OpenOptions::truncate(true).write(true).create_new(false)` is used.
I think this patch allows for least controversial middle ground which
*enables* changing tenant configuration even for attached tenants (not
just created tenants).
Walreceiver is a per-timeline abstraction. Move it there to reflect
the hierarchy of abstractions and task_mgr tasks.
The code that sets up the global storage_broker client
is not timeline-scoped. So, break it out into a separate module.
The motivation for this change is to prepare the code base for replacing
the task_mgr global task registry with a more ownership-oriented
approach to manage task lifetimes.
I removed TaskStateUpdate::Init because, after doing the changes,
rustc warned that it was never constructed.
A quick search through the commit history shows that this
has always been true since
commit fb68d01449
Author: Dmitry Rodionov <dmitry@neon.tech>
Date: Mon Sep 26 23:57:02 2022 +0300
Preserve task result in TaskHandle by keeping join handle around (#2521)
So, the warning is not an indication of some accidental code removal.
This is PR: https://github.com/neondatabase/neon/pull/3456
Change the signature so that it takes an Arc<Timeline> reference to the
source timeline, instead of just the ID. All the callers have an Arc
reference at hand, so this is more convenient for everyone.
Reorder the code a bit and improve the comments, to make it more clear
what it does and why.
To fix errors such as:
`An error occurred (ImageAlreadyExistsException) when calling the
PutImage operation: Image with digest
'sha256:da6d8ad97d84e3aec4e6a240c3a35868b626692ee5d199cdd3fe45d29a8e54df'
and tag 'latest' already exists in the repository with name
'compute-node-v14' in registry with id '369495373322'`
Co-authored-by: Rory de Zoete <rdezoete@RorysMacStudio.fritz.box>
Co-authored-by: Rory de Zoete <rdezoete@Rorys-Mac-Studio.fritz.box>
This allows fine-grained distributed tracing of the 'start_compute'
operation from the cloud console. The startup actions performed by
'compute_ctl' are now performed in a child of the 'start_compute'
context, so you can trace through the whole compute start operation.
This needs a corresponding change in the cloud console to fill in the
'startup_tracing_context' field in the json spec. If it's missing, the
startup operations are simply traced as a separate trace, without
a parent.
This allows tracing the startup actions e.g. with Jaeger
(https://www.jaegertracing.io/). We use the "tracing-opentelemetry"
crate, which turns tracing spans into OpenTelemetry spans, so you can
use the usual "#[instrument]" directives to add tracing.
I put the tracing initialization code to a separate crate,
`tracing-utils`, so that we can reuse it in other programs. We
probably want to set up tracing in the same way in all our programs.
Co-authored-by: Joonas Koivunen <joonas@neon.tech>
This patch wrap the tenants hashmap into an enum that represents the
tenant manager's three major states:
- Initializing
- Open for business
- Shutting down.
See the enum doc comments for details.
In response, all the users of `TENANTS` are now forced to distinguish
those states.
The only major change is in `run_if_no_tenant_in_memory`, which,
before this patch, was used by the /attach and /load endpoints.
This patch rewrites that method under the name `tenant_map_insert`,
replacing the anyhow::Result with a std Result and a dedicated error
type.
Introducing this error types allows using `tenant_map_insert` in
`tenant_create`, thereby unifying all code paths that create tenants
objects to use `tenant_map_insert`.
This is beneficial because we can now systematically prevent tenants
from being created, attached, or `/load`ed during pageserver shutdown.
The management API remains available, but the endpoints that create
new tenants will fail with an error.
More work would need to be done to properly distinguish these errors
through HTTP status codes such as 503.
after executing
```sql
CREATE EXTENSION unit;
```
I saw such error
```
ERROR: could not open file "/usr/local/pgsql/share/extension/unit_prefixes.data" for reading: No such file or directory (SQLSTATE 58P01)
```
Co-authored-by: Anastasia Lubennikova <anastasia@neon.tech>
For use in production in case on-demand download turns out to be
problematic during tenant_attach, or when we eventually introduce layer
eviction.
Co-authored-by: Dmitry Rodionov <dmitry@neon.tech>
Motivation
==========
Layer Eviction Needs Context
----------------------------
Before we start implementing layer eviction, we need to collect some
access statistics per layer file or maybe even page.
Part of these statistics should be the initiator of a page read request
to answer the question of whether it was page_service vs. one of the
background loops, and if the latter, which of them?
Further, it would be nice to learn more about what activity in the pageserver
initiated an on-demand download of a layer file.
We will use this information to test out layer eviction policies.
Read more about the current plan for layer eviction here:
https://github.com/neondatabase/neon/issues/2476#issuecomment-1370822104
task_mgr problems + cancellation + tenant/timeline lifecycle
------------------------------------------------------------
Apart from layer eviction, we have long-standing problems with task_mgr,
task cancellation, and various races around tenant / timeline lifecycle
transitions.
One approach to solve these is to abandon task_mgr in favor of a
mechanism similar to Golang's context.Context, albeit extended to
support waiting for completion, and specialized to the needs in the
pageserver.
Heikki solves all of the above at once in PR
https://github.com/neondatabase/neon/pull/3228 , which is not yet
merged at the time of writing.
What Is This Patch About
========================
This patch addresses the immediate needs of layer eviction by
introducing a `RequestContext` structure that is plumbed through the
pageserver - all the way from the various entrypoints (page_service,
management API, tenant background loops) down to
Timeline::{get,get_reconstruct_data}.
The struct carries a description of the kind of activity that initiated
the call. We re-use task_mgr::TaskKind for this.
Also, it carries the desired on-demand download behavior of the entrypoint.
Timeline::get_reconstruct_data can then log the TaskKind that initiated
the on-demand download.
I developed this patch by git-checking-out Heikki's big RequestContext
PR https://github.com/neondatabase/neon/pull/3228 , then deleting all
the functionality that we do not need to address the needs for layer
eviction.
After that, I added a few things on top:
1. The concept of attached_child and detached_child in preparation for
cancellation signalling through RequestContext, which will be added in
a future patch.
2. A kill switch to turn DownloadBehavior::Error into a warning.
3. Renamed WalReceiverConnection to WalReceiverConnectionPoller and
added an additional TaskKind WalReceiverConnectionHandler.These were
necessary to create proper detached_child-type RequestContexts for the
various tasks that walreceiver starts.
How To Review This Patch
========================
Start your review with the module-level comment in context.rs.
It explains the idea of RequestContext, what parts of it are implemented
in this patch, and the future plans for RequestContext.
Then review the various `task_mgr::spawn` call sites. At each of them,
we should be creating a new detached_child RequestContext.
Then review the (few) RequestContext::attached_child call sites and
ensure that the spawned tasks do not outlive the task that spawns them.
If they do, these call sites should use detached_child() instead.
Then review the todo_child() call sites and judge whether it's worth the
trouble of plumbing through a parent context from the caller(s).
Lastly, go through the bulk of mechanical changes that simply forwards
the &ctx.
Before this patch, when `initialize_with_lock` was called via
`timeline_init_and_sync`, we would transition the timeline like so:
load_local_timeline/load_remote_timeline:
timeline_init_and_sync
Timeline::new
() => Loading
initialize_with_lock:
set_state(Active)
Loading => Active
timeline.activate()
Active => Active
this makes debugging problematic cases in the future easier, as we can
just request the model inputs, use them locally to reproduce the issue
with the model.
I noticed that `compute_ctl` updates all roles on each start, search for
rows like
> - web_access:[FILTERED] -> update
in the compute startup log.
It happens since we had an adhoc hack for md5 hashes comparison, which
doesn't work with scram hashes stored in the `pg_authid`. It doesn't
really hurt, as nothing changes, but we just run >= 2 extra queries on
each start, so fix it.
The TimelineState::Suspsended was dubious to begin with. I suppose
that the intention was that timelines could transition back and
forth between Active and Suspended states.
But practically, the code before this patch never did that.
The transitions were:
() ==Timeline::new==> Suspended ==*==> {Active,Broken,Stopping}
One exception: Tenant::set_stopping() could transition timelines like
so:
!Broken ==Tenant::set_stopping()==> Suspended
But Tenant itself cannot transition from stopping state to any other
state.
Thus, this patch removes TimelineState::Suspended and introduces a new
state Loading. The aforementioned transitions change as follows:
- () ==Timeline::new==> Suspended ==*==> {Active,Broken,Stopping}
+ () ==Timeline::new==> Loading ==*==> {Active,Broken,Stopping}
- !Broken ==Tenant::set_stopping()==> Suspended
+ !Broken ==Tenant::set_stopping()==> Stopping
Walreceiver's connection manager loop watches TimelineState to decide
whether it should retry connecting, or exit.
This patch changes the loop to exit when it observes the transition
into Stopping state.
Walreceiver isn't supposed to be started until the timeline transitions
into Active state. So, this patch also adds some warn!() messages
in case this happens anyways.
Small changes, but hopefully this will help with the panic detected in
staging, for which we cannot get the debugging information right now
(end-of-branch before branch-point).
Before only the timelines which have passed the `gc_horizon` were
processed which failed with orphans at the tree_sort phase. Example
input in added `test_branched_empty_timeline_size` test case.
The PR changes iteration to happen through all timelines, and in
addition to that, any learned branch points will be calculated as they
would had been in the original implementation if the ancestor branch had
been over the `gc_horizon`.
This also changes how tenants where all timelines are below `gc_horizon`
are handled. Previously tenant_size 0 was returned, but now they will
have approximately `initdb_lsn` worth of tenant_size.
The PR also adds several new tenant size tests that describe various corner
cases of branching structure and `gc_horizon` setting.
They are currently disabled to not consume time during CI.
Co-authored-by: Joonas Koivunen <joonas@neon.tech>
Co-authored-by: Anastasia Lubennikova <anastasia@neon.tech>
Previously, we were trying to re-assign owned objects of the already
deleted role. This were causing a crash loop in the case when compute
was restarted with a spec that includes delta operation for role
deletion. To avoid such cases, check that role is still present before
calling `reassign_owned_objects`.
Resolvesneondatabase/cloud#3553
This reverts commit 826e89b9ce.
The problem with that commit was that it deletes the TempDir while
there are still EphemeralFile instances open.
At first I thought this could be fixed by simply adding
Handle::current().block_on(task_mgr::shutdown(None, Some(tenant_id), None))
to TenantHarness::drop, but it turned out to be insufficient.
So, reverting the commit until we find a proper solution.
refs https://github.com/neondatabase/neon/issues/3385
Refactors Compute::prepare_and_run. It's split into subroutines
differently, to make it easier to attach tracing spans to the
different stages. The high-level logic for waiting for Postgres to
exit is moved to the caller.
Replace 'env_logger' with 'tracing', and add `#instrument` directives
to different stages fo the startup process. This is a fairly
mechanical change, except for the changes in 'spec.rs'. 'spec.rs'
contained some complicated formatting, where parts of log messages
were printed directly to stdout with `print`s. That was a bit messed
up because the log normally goes to stderr, but those lines were
printed to stdout. In our docker images, stderr and stdout both go to
the same place so you wouldn't notice, but I don't think it was
intentional.
This changes the log format to the default
'tracing_subscriber::format' format. It's different from the Postgres
log format, however, and because both compute_tools and Postgres print
to the same log, it's now a mix of two different formats. I'm not
sure how the Grafana log parsing pipeline can handle that. If it's a
problem, we can build custom formatter to change the compute_tools log
format to be the same as Postgres's, like it was before this commit,
or we can change the Postgres log format to match tracing_formatter's,
or we can start printing compute_tool's log output to a different
destination than Postgres
Before this patch, we would start all layer downloads simultaneously.
There is at most one download_all_remote_layers task per timeline.
Hence, the specified limit is per timeline.
There is still no global concurrency limit for layer downloads.
We'll have to revisit that at some point and also prioritize on-demand
initiated downloads over download_all_remote_layers downloads.
But that's for another day.
The general idea is that the VM informant binary is added to the
vm-compute-node images only. `compute_tools` then will run whatever's at
`/bin/vm-informant`, if the path exists.
- handle errors in calculate_synthetic_size_worker. Don't exit the bgworker if one tenant failed.
- add cached_synthetic_tenant_size to cache values calculated by the bgworker
- code cleanup: remove unneeded info! messages, clean comments
- handle collect_metrics_task() error. Don't exit collect_metrics worker if one task failed.
- add unit test to cover case when we have multiple branches at the same lsn
If we ran `compact_prefetch_buffers` with exactly one hole in the
buffers, the code would fail to remove the last, now unused, entry from
the array.
This is now fixed.
Also, add and adjust some comments in the compaction code so that the
algorithm used is a bit more clear.
Fixes#3192
This makes Timeline::get() async, and all functions that call it
directly or indirectly with it. The with_ondemand_download() mechanism
is gone, Timeline::get() now always downloads files, whether you want
it or not. That is what all the current callers want, so even though
this loses the capability to get a page only if it's already in the
pageserver, without downloading, we were not using that capability.
There were some places that used 'no_ondemand_download' in the WAL
ingestion code that would error out if a layer file was not found
locally, but those were dubious. We do actually want to on-demand
download in all of those places.
Per discussion at
https://github.com/neondatabase/neon/pull/3233#issuecomment-1368032358
When number of github actions workers is changed, some jobs get killed.
When helm if killed during the upgrade, release stuck in pending-upgrade
state. --atomic should initiate automatic rollback in this case.
With this patch, tenant_detach and timeline_delete's
task_mgr::shutdown_tasks() call will wait for on-demand
compaction to finish.
Before this patch, the on-demand compaction would grab the
layer_removal_cs after tenant_detach / timeline_delete had
removed the timeline directory.
This resulted in error
No such file or directory (os error 2)
NB: I already implemented this pattern for ondemand GC a while back.
fixes https://github.com/neondatabase/neon/issues/3136
- Fix and improve comments
- Rename 'physical_size' local variable to 'resident_size' for clarity.
- Remove one 'unnecessary wait_for_upload' call. The
'wait_for_sk_commit_lsn_to_reach_remote_storage' call after shutting
down compute is sufficient.
## Describe your changes
Added a PR template
## Issue ticket number and link
#3162
## Checklist before requesting a review
- [ ] I have performed a self-review of my code
- [ ] If it is a core feature, I have added thorough tests.
- [ ] Do we need to implement analytics? if so did you add the relevant
metrics to the dashboard?
- [ ] If this PR requires public announcement, mark it with
/release-notes label and add several sentences in this section.
This is a hacky implementation of WebSocket server, embedded into our
postgres proxy. The server is used to allow https://github.com/neondatabase/serverless
to connect to our postgres from browser and serverless javascript functions.
How it will work (general schema):
- browser opens a websocket connection to
`wss://ep-abc-xyz-123.xx-central-1.aws.neon.tech/`
- proxy accepts this connection and terminates TLS (https)
- inside encrypted tunnel (HTTPS), browser initiates plain
(non-encrypted) postgres connection
- proxy performs auth as in usual plain pg connection and forwards
connection to the compute
Related issue: #3225
Follow-up of https://github.com/neondatabase/neon/pull/3270 which made
an example from main README.md not working.
Fixes that, by adding a way to specify a default tenant now and modifies
the basic neon_local test to start postgres and check branching.
Not all neon_local commands are implemented, so not all README.md
contents is tested yet.
It's not OK to return early from within a PG_TRY-CATCH block. The
PG_TRY macro sets the global PG_exception_stack variable, and
PG_END_TRY restores it. If we jump out in between with "return NULL",
the PG_exception_stack is left to point to garbage. (I'm surprised the
comments in PG_TRY_CATCH don't warn about this.)
Add test that re-attaches tenant in pageserver while Postgres is
running. If the tenant is detached while compute is connected and
busy running queries, those queries will fail if they try to fetch any
pages. But when the tenant is re-attached, things should start working
again, without disconnecting the client <-> postgres connections.
Without this fix, this reproduced the segfault.
Fixes issue #3231
pageserver_disconnect() call invalidates 'pageserver_conn', including
the error message pointer we got from PQerrorMessage(pageserver_conn).
Copy the message to a temporary variable before disconnecting, like
we do in a few other places.
In the passing, clear 'pageserver_conn_wes' variable in a few places
where it was free'd. I didn't see any live bug from this, but since
pageserver_disconnect() checks if it's NULL, let's not leave it
dangling to already-free'd memory.
For every Python test, we start the storage first, and expect that
later, in the test, when we start a compute, it will work without
specific timeline and tenant creation or their IDs specified.
For that, we have a concept of "default" branch that was created on the
control plane level first, but that's not needed at all, given that it's
only Python tests that need it: let them create the initial timeline
during set-up.
Before, control plane started and stopped pageserver for timeline
creation, now Python harness runs an extra tenant creation request on
test env init.
I had to adjust the metrics test, turns out it registered the metrics
from the default tenant after an extra pageserver restart.
New model does not sent the metrics before the collection time happens,
and that was 30s before.
- Clean up redundant metric removal in TimelineMetrics::drop.
RemoteTimelineClientMetrics is responsible for cleaning up
REMOTE_OPERATION_TIME andREMOTE_UPLOAD_QUEUE_UNFINISHED_TASKS.
- Rename `pageserver_remote_upload_queue_unfinished_tasks` to
`pageserver_remote_timeline_client_calls_unfinished`. The new name
reflects that the metric is with respect to the entire call to remote
timeline client. This includes wait time in the upload queue and hence
it's a longer span than what `pageserver_remote_OPERATION_seconds`
measures.
- Add the `pageserver_remote_timeline_client_calls_started` histogram.
See the metric description for why we need it.
- Add helper functions `call_begin` etc to `RemoteTimelineClientMetrics`
to centralize the logic for updating the metrics above (they relate to
each other, see comments in code).
- Use these constructs to track ongoing downloads in
`pageserver_remote_timeline_client_calls_unfinished`
refs https://github.com/neondatabase/neon/issues/2029
fixes https://github.com/neondatabase/neon/issues/3249
closes https://github.com/neondatabase/neon/pull/3250
Before this change, we would not .measure_remote_op for index part
downloads.
And more generally, it's good to pass not just uploads but also
downloads through RemoteTimelineClient, e.g., if we ever want to
implement some timeline-scoped policies there.
Found this while working on https://github.com/neondatabase/neon/pull/3250
where I add a metric to measure the degree of concurrent downloads.
Layer download was missing in a test that I added there.
The Basebackup struct is really just a convenient place to carry the
various parameters around in send_tarball and its subroutines. Make it
internal to the send_tarball function.
This reverts commit 56a4466d0a.
Seems that flackiness increased after this commit, while the time
decrease was a couple of seconds.
With every regular Python test spawing 1 etcd, 3 safekeepers, 1
pageserver, few CLI commands and post-run cleanup hooks, it might be
hard to run many such tests in parallel.
We could return to this later, after we consider alternative test
structure and/or CI runner structure.
Closes https://github.com/neondatabase/neon/issues/3114
Adds more typization into errors that appear during protocol messages (`FeMessage`), postgres and walreceiver connections.
Socket IO errors are now better detected and logged with lesser (INFO, DEBUG) error level, without traces that they were logged before, when they were wrapped in anyhow context.
It was nice to have and useful at the time, but unfortunately the method
used to gather the profiling data doesn't play nicely with 'async'. PR
#3228 will turn 'get_page_at_lsn' function async, which will break the
profiling support. Let's remove it, and re-introduce some kind of
profiling later, using some different method, if we feel like we need it
again.
Makes the top-level functions in WalIngest async, and replaces
no_ondemand_download calls with with_ondemand_download.
This hopefully fixes the problem reported in issue #3230, although I
don't have a self-contained test case for it.
The synchronous 'tar' crate has required us to use block_in_place and
SyncIoBridge to work together with the async I/O in the client
connection. Switch to 'tokio-tar' crate that uses async I/O natively.
As part of this, move the CopyDataWriter implementation to
postgres_backend_async.rs. Even though it's only used in one place
currently, it's in principle generally applicable whenever you want to
use COPY out.
Unfortunately we cannot use the 'tokio-tar' as it is: the Builder
implementation requires the writer to have 'static lifetime. So we
have to use a modified version without that requirement. The 'static
lifetime was required just for the Drop implementation that writes
the end-of-archive sections if the Builder is dropped without calling
`finish`. But we don't actually want that behavior anyway; in fact
we had to jump through some hoops with the AbortableWrite hack to skip
those. With the modified version of 'tokio-tar' without that Drop
implementation, we don't need AbortableWrite either.
Co-authored-by: Kirill Bulatov <kirill@neon.tech>
I have experimented with the runner threads number, and looks like 8
threads win us a few seconds.
Bumping the thread count more did not improve the situation much:
* 20 threads were not allowed by pytest
* 16 threads were flacking quite notably
My guess would be that all pageservers, safekeepers, and other nodes we
start occupy quite much of the CPU and other resources to make this
approach more scalable.
I looked at "cargo tree" output and noticed that through various
dependencies, we are depending on both native-tls and rustls. We have
tried to standardize on rustls for everything, but dependencies on
native-tls have crept in recently. One such dependency came from
'reqwest' with default features in pageserver, used for
consumption_metrics. Another dependency was from 'sentry'. Both
'reqwest' and 'sentry' use native-tls by default, but can use 'rustls'
if compiled with the right feature flags.
Send this metric only when it is fully calculated.
Make consumption metrics more stable:
- Send per-timeline metrics only for active timelines.
- Adjust test assertions to make test_metric_collection test more stable.
Refactor update_gc_info function so that it calls the potentially
expensive find_lsn_for_timestamp() function before acquiring the
lock. This will also be needed if we make find_lsn_for_timestamp()
async in the future; it cannot be awaited while holding the lock.
Fixes:
- serialize TenantId and TimelineId as strings,
- skip TimelineId if none
- serialize `metric_type` field as `type`
- add `idempotency_key` field to uniquely identify metrics
Changes are:
* Pageserver: start reading from NEON_AUTH_TOKEN by default.
Warn if ZENITH_AUTH_TOKEN is used instead.
* Compute, Docs: fix the default token name.
* Control plane: change name of the token in configs and start
sequences.
Compatibility:
* Control plane in tests: works, no compatibility expected.
* Control plane for local installations: never officially supported
auth anyways. If someone did enable it, `pageserver.toml` should be updated
with the new `neon.pageserver_connstring` and `neon.safekeeper_token_env`.
* Pageserver is backward compatible: you can run new Pageserver with old
commands and environment configurations, but not vice-versa.
The culprit is the hard-coded `NEON_AUTH_TOKEN`.
* Compute has no code changes. As long as you update its configuration
file with `pageserver_connstring` in sync with the start up scripts,
you are good to go.
* Safekeeper has no code changes and has never used `ZENITH_AUTH_TOKEN` in
the first place.
While @bojanserafimov is still working on best replacement of R-Tree in
layer_map.rs there is obvious pitfall in the current `search` method
implementation: is returns delta layer even if there is image layer if
greater LSN. I think that it should be fixed.
The PR aims to fix two missing redownloads in a flacky
test_remote_storage_upload_queue_retries[local_fs]
([example](https://neon-github-public-dev.s3.amazonaws.com/reports/pr-3190/release/3759194738/index.html#categories/80f1dcdd7c08252126be7e9f44fe84e6/8a70800f7ab13620/))
1. missing redownload during walreceiver work
```
2022-12-22T16:09:51.509891Z ERROR wal_connection_manager{tenant=fb62b97553e40f949de8bdeab7f93563 timeline=4f153bf6a58fd63832f6ee175638d049}: wal receiver task finished with an error: walreceiver connection handling failure
Caused by:
Layer needs downloading
Stack backtrace:
0: pageserver::tenant::timeline::PageReconstructResult<T>::no_ondemand_download
at /__w/neon/neon/pageserver/src/tenant/timeline.rs:467:59
1: pageserver::walingest::WalIngest::new
at /__w/neon/neon/pageserver/src/walingest.rs:61:32
2: pageserver::walreceiver::walreceiver_connection::handle_walreceiver_connection::{{closure}}
at /__w/neon/neon/pageserver/src/walreceiver/walreceiver_connection.rs:178:25
....
```
That looks sad, but inevitable during the current approach: seems that
we need to wait for old layers to arrive in order to accept new data.
For that, `WalIngest::new` now started to return the
`PageReconstructResult`.
Sync methods from `import_datadir.rs` use `WalIngest::new` too, but both
of them import WAL during timeline creation, so no layers to download
are needed there, ergo the `PageReconstructResult` is converted to
`anyhow::Result` with `no_ondemand_download`.
2. missing redownload during compaction work
```
2022-12-22T16:09:51.090296Z ERROR compaction_loop{tenant_id=fb62b97553e40f949de8bdeab7f93563}:compact_timeline{timeline=4f153bf6a58fd63832f6ee175638d049}: could not compact, repartitioning keyspace failed: Layer needs downloading
Stack backtrace:
0: pageserver::tenant::timeline::PageReconstructResult<T>::no_ondemand_download
at /__w/neon/neon/pageserver/src/tenant/timeline.rs:467:59
1: pageserver::pgdatadir_mapping::<impl pageserver::tenant::timeline::Timeline>::collect_keyspace::{{closure}}
at /__w/neon/neon/pageserver/src/pgdatadir_mapping.rs:506:41
<core::future::from_generator::GenFuture<T> as core::future::future::Future>::poll
at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/core/src/future/mod.rs:91:19
pageserver::tenant::timeline::Timeline::repartition::{{closure}}
at /__w/neon/neon/pageserver/src/tenant/timeline.rs:2161:50
<core::future::from_generator::GenFuture<T> as core::future::future::Future>::poll
at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/core/src/future/mod.rs:91:19
2: pageserver::tenant::timeline::Timeline::compact::{{closure}}
at /__w/neon/neon/pageserver/src/tenant/timeline.rs:700:14
<core::future::from_generator::GenFuture<T> as core::future::future::Future>::poll
at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/core/src/future/mod.rs:91:19
3: <tracing::instrument::Instrumented<T> as core::future::future::Future>::poll
at /github/home/.cargo/registry/src/github.com-1ecc6299db9ec823/tracing-0.1.37/src/instrument.rs:272:9
4: pageserver::tenant::Tenant::compaction_iteration::{{closure}}
at /__w/neon/neon/pageserver/src/tenant.rs:1232:85
<core::future::from_generator::GenFuture<T> as core::future::future::Future>::poll
at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/core/src/future/mod.rs:91:19
pageserver::tenant_tasks::compaction_loop::{{closure}}::{{closure}}
at /__w/neon/neon/pageserver/src/tenant_tasks.rs:76:62
<core::future::from_generator::GenFuture<T> as core::future::future::Future>::poll
at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/core/src/future/mod.rs:91:19
pageserver::tenant_tasks::compaction_loop::{{closure}}
at /__w/neon/neon/pageserver/src/tenant_tasks.rs:91:6
```
Scan core dumps directory on exit. In case of existing core dumps
call gdb/lldb to get a backtrace and log it. By default look for
core dumps in postgres data directory as core.<pid>. That is how
core collection is configured in our k8s nodes (and a reasonable
convention in general).
1.66 release speeds up compile times for over 10% according to tests.
Also its Clippy finds plenty of old nits in our code:
* useless conversion, `foo as u8` where `foo: u8` and similar, removed
`as u8` and similar
* useless references and dereferenced (that were automatically adjusted
by the compiler), removed various `&` and `*`
* bool -> u8 conversion via `if/else`, changed to `u8::from`
* Map `.iter()` calls where only values were used, changed to
`.values()` instead
Standing out lints:
* `Eq` is missing in our protoc generated structs. Silenced, does not
seem crucial for us.
* `fn default` looks like the one from `Default` trait, so I've
implemented that instead and replaced the `dummy_*` method in tests with
`::default()` invocation
* Clippy detected that
```
if retry_attempt < u32::MAX {
retry_attempt += 1;
}
```
is a saturating add and proposed to replace it.
The code in this change was extracted from #2595 (Heikki’s on-demand
download draft PR).
High-Level Changes
- New RemoteLayer Type
- On-Demand Download As An Effect Of Page Reconstruction
- Breaking Semantics For Physical Size Metrics
There are several follow-up work items planned.
Refer to the Epic issue on GitHub: https://github.com/neondatabase/neon/issues/2029
closes https://github.com/neondatabase/neon/pull/3013
Co-authored-by: Kirill Bulatov <kirill@neon.tech>
Co-authored-by: Christian Schwarz <christian@neon.tech>
New RemoteLayer Type
====================
Instead of downloading all layers during tenant attach, we create
RemoteLayer instances for each of them and add them to the layer map.
On-Demand Download As An Effect Of Page Reconstruction
======================================================
At the heart of pageserver is Timeline::get_reconstruct_data(). It
traverses the layer map until it has collected all the data it needs to
produce the page image. Most code in the code base uses it, though many
layers of indirection.
Before this patch, the function would use synchronous filesystem IO to
load data from disk-resident layer files if the data was not cached.
That is not possible with RemoteLayer, because the layer file has not
been downloaded yet. So, we do the download when get_reconstruct_data
gets there, i.e., “on demand”.
The mechanics of how the download is done are rather involved, because
of the infamous async-sync-async sandwich problem that plagues the async
Rust world. We use the new PageReconstructResult type to work around
this. Its introduction is the cause for a good amount of code churn in
this patch. Refer to the block comment on `with_ondemand_download()`
for details.
Breaking Semantics For Physical Size Metrics
============================================
We rename prometheus metric pageserver_{current,resident}_physical_size to
reflect what this metric actually represents with on-demand download.
This intentionally BREAKS existing grafana dashboard and the cost model data
pipeline. Breaking is desirable because the meaning of this metrics has changed
with on-demand download. See
https://docs.google.com/document/d/12AFpvKY-7FZdR5a4CaD6Ir_rI3QokdCLSPJ6upHxJBo/edit#
for how we will handle this breakage.
Likewise, we rename the new billing_metrics’s PhysicalSize => ResidentSize.
This is not yet used anywhere, so, this is not a breaking change.
There is still a field called TimelineInfo::current_physical_size. It
is now the sum of the layer sizes in layer map, regardless of whether
local or remote. To compute that sum, we added a new trait method
PersistentLayer::file_size().
When updating the Python tests, we got rid of
current_physical_size_non_incremental. An earlier commit removed it from
the OpenAPI spec already, so this is not a breaking change.
test_timeline_size.py has grown additional assertions on the
resident_physical_size metric.
Add new background job to collect billing metrics for each tenant and
send them to the HTTP endpoint.
Metrics are cached, so we don't send non-changed metrics.
Add metric collection config parameters:
metric_collection_endpoint (default None, i.e. disabled)
metric_collection_interval (default 60s)
Add test_metric_collection.py to test metric collection
and sending to the mocked HTTP endpoint.
Use port distributor in metric_collection test
review fixes: only update cache after metrics were send successfully, simplify code
disable metric collection if metric_collection_endpoint is not provided in config
It's better to request the tasks to shut down only after setting the
timeline state to Stopping. Otherwise, it's possible that a new task
spawns after we have waited for the existing tasks to shut down, but
before we have changed the state. We would fail to wait for them.
Feels nicer from a readability point of view too.
Remote operations fail sometimes due to network failures or other
external reasons. Add retry logic to all the remote downloads, so that
a transient failure at pageserver startup or tenant attach doesn't
cause the whole tenant to be marked as Broken.
Like in the uploads retry logic, we print the failure to the log as a
WARNing after three retries, but keep retrying. We will retry up to 10
times now, before returning the error to the caller.
To test the retries, I created a new RemoteStorage wrapper that simulates
failures, by returning an error for the first N times that a remote
operation is performed. It can be enabled by setting a new
"test_remote_failures" option in the pageserver config file.
Fixes#3112
The new Timeline::freeze_and_flush function is equivalent to calling
Timeline::checkpoint(CheckpointConfig::Flush). There were only one
non-test caller that used CheckpointConfig::Forced, so replace that
with a call to the new Timeline::freeze_and_flush, followed by an
explicit call to Timeline::compact.
That only caller was to handle the mgmt API's 'checkpoint' endpoint.
Perhaps we should split that into separate 'flush' and 'compact'
endpoints too, but I didn't go that far yet.
Commit 6dec85b19d remove the `checkpoint_before_gc` argument, but failed
to update the comment. Remove its description, and while we're at it, try
to explain better how the `horizon` and `pitr` arguments are used.
This splits the storage_sync2::schedule_index_file into two (public)
functions:
1. `schedule_index_upload_for_metadata_update`, for when the metadata
(e.g. disk_consistent_lsn or last_gc_cutoff) has changed, and
2. `schedule_index_upload_for_file_changes`, for when layer file uploads
or deletions have been scheduled.
We now keep track of whether there have been any uploads or deletions
since the last index-file upload, and skip the upload in
`schedule_index_upload_for_file_changes` if there haven't been any
changes. That allows us to call the function liberally in timeline.rs,
whenever layer file uploads or deletions might've been scheduled,
without starting a lot of unnecessary index file uploads.
GC was covered earlier by commit c262390214, but that missed that we
have the same problem with compaction.
- Refactor logical_size_calculation_task, moving the pieces that are
specific to try_spawn_size_init_task into that function.
This allows us to spawn additional size calculation tasks that are not
init size calculation tasks.
- As part of this refactoring, stop logging cancellations as errors.
They are part of regular operations.
Logging them as errors was inadvertently introduced in earlier commit
427c1b2e9661161439e65aabc173d695cfc03ab4
initial logical size calculation: if it fails, retry on next call
- Change tenant size model request code to spawn task_mgr tasks using
the refactored logical_size_calculation_task function.
Using a task_mgr task ensures that the calculation cannot outlive
the timeline.
- There are presumably still some subtle race conditions if a size
requests comes in at exactly the same time as a detach / delete
request.
- But that's the concern of diferent area of the code (e.g., tenant_mgr)
and requires holistic solutions, such as the proposed TenantGuard.
- Make size calculation cancellable using CancellationToken.
This is more of a cherry on top.
NB: the test code doesn't use this because we _must_ return from
the failpoint, because the failpoint lib doesn't allow to just
continue execution in combination with executing the closure.
This commit fixes the tests introduced earlier in this patch series.
This exacerbates the problem pointed out in the previous commit.
Why? Because with this patch, deleting a timeline also exposes the issue.
Extend the test to expose the problem.
Before this patch, if the task fails, we would not reset
self.initial_size_computation_started.
So, if it fails, we will return the approximate value forever.
In practice, it probably never failed because the local filesystem
is quite reliable.
But with on-demand download, the logical size calculation may need
to download layers, which is more likely to fail at times.
There will be internal retires with a timeout, but eventually,
the downloads will give up.
We want to retry in those cases.
While we're at it, also change the handling of the timeline state
watch so that we treat it as an error. Most likely, we'll not be
called again, but if we are, retrying is the right thing.
This prevents us from overwriting all blocks of a relation when we
extend the relation without first caching the size - get_cached_relsize
does not guarantee a correct result when it returns `false`.
This fixes all kinds of problems related to missing params,
like broken timestamps (due to `integer_datetimes`).
This solution is not ideal, but it will help. Meanwhile,
I'm going to dedicate some time to improving connection machinery.
Note that this **does not** fix problems with passing certain parameters
in a reverse direction, i.e. **from client to compute**. This is a
separate matter and will be dealt with in an upcoming PR.
this should help us in the future to have more freedom with spawning
tasks and cancelling things, most importantly blocking tasks (assuming
the CancellationToken::is_cancelled is performant enough).
CancellationToken allows creation of hierarchical cancellations, which
would also simplify the task_mgr shutdown operation, rendering it
unnecessary.
Do not run Nightly Benchmarks on `neon-captest-new`.
This is a temporary solution to avoid spikes in the storage we consume
during the test run. To collect data for the default instance, we could
run tests weekly (i.e. not daily).
IMDSv2 has limits, and if we query it on every s3 interaction we are
going to go over those limits. Changes the s3_bucket client
configuration to use:
- ChainCredentialsProvider to handle env variables or imds usage
- LazyCachingCredentialsProvider to actually cache any credentials
Related: https://github.com/awslabs/aws-sdk-rust/issues/629
Possibly related: https://github.com/neondatabase/neon/issues/3118
I saw an excessive number of index file upload operations in
production, even when nothing on the timeline changes. It was because
our GC schedules index file upload if the GC cutoff LSN is advanced,
even if the GC had nothing else to do. The GC cutoff LSN marches
steadily forwards, even when there is no user activity on the
timeline, when the cutoff is determined by the time-based PITR
interval setting. To dial that down, only schedule index file upload
when GC is about to actually remove something.
Previously, the /v1/tenant/:tenant_id/timeline/:timeline_id/do_gc API
call performed a flush and compaction on the timeline before
GC. Change it not to do that, and change all the tests that used that
API to perform compaction explicitly.
The compaction happens at a slightly different point now. Previously,
the code performed the `refresh_gc_info_internal` step first, and only
then did compaction on all the timelines. I don't think that was what
was originally intended here. Presumably the idea with compaction was
to make some old layer files available for GC. But if we're going to
flush the current in-memory layer to disk, surely you would want to
include the newly-written layer in the compaction too. I guess this
didn't make any difference to the tests in practice, but in any case,
the tests now perform the flush and compaction before any of the GC
steps.
Some of the tests might not need the compaction at all, but I didn't
try hard to determine which ones might need it. I left it out from a
few tests that intentionally tested calling do_gc with an invalid
tenant or timeline ID, though.
- Use only one templated section for most postgres-versioned steps
- Clean up neon_walredo, too, when running neon-pg-ext-clean
- Depend on the various cleanup steps for `clean` instead of manually
executing those cleanup steps.
If we get cancelled before jh.await returns we've take()n the join handle but
drop the result on the floor.
Fix it by setting self.join_handle = None after the .await
fixes https://github.com/neondatabase/neon/issues/3104
We do the accounting exclusively after updating remote IndexPart successfully.
This is cleaner & more robust than doing it upon completion of
individual layer file uploads / deletions since we can uset .set()
insteaf of add()/sub().
NB: Originally, this work was intended to be part of #3013 but it
turns out that it's completely orthogonal.
So, spin it out into this PR for easier review.
Since this change is additive, it won't break anything.
Temporarily disable `test_seqscans` for remote projects; they acquire
too much space and time. We can try to reenable it back after switching
to per-test projects.
Closes https://github.com/neondatabase/neon/issues/1984
Closes https://github.com/neondatabase/neon/pull/2830
A follow-up of https://github.com/neondatabase/neon/pull/2830, I've
noticed that benchmarks failed again due to out of space issues.
Removes most of the pageserver and safekeeper files from disk after
every pytest suite run.
```
$ poetry run pytest -vvsk "test_tenant_redownloads_truncated_file_on_startup[local_fs]"
# ...
$ du -h test_output/test_tenant_redownloads_truncated_file_on_startup\[local_fs\]
# ...
104K test_output/test_tenant_redownloads_truncated_file_on_startup[local_fs]
$ poetry run pytest -vvsk "test_tenant_redownloads_truncated_file_on_startup[local_fs]" --preserve-database-files
# ...
$ du -h test_output/test_tenant_redownloads_truncated_file_on_startup\[local_fs\]
# ...
123M test_output/test_tenant_redownloads_truncated_file_on_startup[local_fs]
```
Co-authored-by: Bojan Serafimov <bojan.serafimov7@gmail.com>
Before this patch, when we decide to rename a layer file to backup
because of layer file size mismatch, we would not remove the layer from
the layer map, but remote the on-disk file.
Because we re-download the file immediately after, we simply end up with
two layer objects in memory that reference the same file in the layer
map. So, GetPage() would work fine until one of the layers gets
delete()'d. The other layer's delete() would then fail.
Future work: prevent insertion of the same layer at LayerMap level
so that we notice such bugs sooner.
Replace actions/setup-python@v4 with the ansible image to fix
```
Version 3.10 was not found in the local cache
Error: The version '3.10' with architecture 'x64' was not found for this operating system.
```
Removes the race during pageserver initial timeline creation that lead to partial layer uploads.
This race is only reproducible in test code, we do not create initial timelines in cloud (yet, at least), but still nice to remove the non-deterministic behavior.
This patch aims to fix some of the inconsistencies in error reporting,
for example "Internal error" or "Console request failed" instead of
"password authentication failed for user '<NAME>'".
refactor: use new type LayerFileName when referring to layer file names in PathBuf/RemotePath
Before this patch, we would sometimes carry around plain file names in
`Path` types and/or awkwardly "rebase" paths to have a unified
representation of the layer file name between local and remote.
This patch introduces a new type `LayerFileName` which replaces the use
of `Path` / `PathBuf` / `RemotePath` in the `storage_sync2` APIs.
Instead of holding a string, it contains the parsed representation of
the image and delta file name.
When we need the file name, e.g., to construct a local path or
remote object key, we construct the name ad-hoc.
`LayerFileName` is also serde {Dese,Se}rializable, and in an initial
version of this patch, it was supposed to be used directly inside
`IndexPart`, replacing `RemotePath`.
However,
commit 3122f3282f
Ignore backup files (ones with .n.old suffix) in download_missing
fixed handling of `*.old` backup file names in IndexPart, and we need
to carry that behavior forward.
The solution is to remove `*.old` backup files names during
deserialization. When we re-serialize the IndexPart, the `*.old` file
will be gone.
This leaks the `.old` file in the remote storage, but makes it safe
to clean it up later.
There is additional churn by a preliminary refactoring that got squashed
into this change:
split off LayerMap's needs from trait Layer into super trait
That refactoring renames `Layer` to `PersistentLayer` and splits off a subset
of the functions into a super-trait called `Layer`.
The upser trait implements just the functions needed by `LayerMap`, whereas
`PersisentLayer` adds the context of the pageserver.
The naming is imperfect as some functions that reside in `PersistentLayer`
have nothing persistence-specific to it. But it's a step in the right direction.
Part of https://github.com/neondatabase/neon/pull/2410 and
https://github.com/neondatabase/neon/pull/2407
* adds `hashFiles('rust-toolchain.toml')` into Rust cache keys, thus
removing one of the manual steps to do when upgrading rustc
* copies Python and Rust style checks from the `codestyle.yml` workflow
* adjusts shell defaults in the main workflow
* replaces `codestyle.yml` with a `neon_extra_builds.yml` worlflow
The new workflow runs on commits to `main` (`codestyle.yml` was run per
PR), and runs two custom builds on GH agents:
* macos-latest, to ensure the entire project compiles on it (no tests
run)
There were no frequent breakages on macOs in our builds, so we can check
it rarely without making every storage PR to wait for it to complete.
The updated mac build use release builds now, so presumably should work
a bit faster due to overall smaller files to cache between builds.
* ubuntu-latest, without caches, to produce full compilation stats for
Rust builds and upload it as an artifact to GitHub
Old `clippy build --timings` stats were collected from the builds that
use caches and incremental calculation hence never could produce a full
report, it got removed.
Increase table size four times to fix the following error:
```
______________________ test_seqscans[remote-100000-100-0] ______________________
test_runner/performance/test_seqscans.py:57: in test_seqscans
assert int(shared_buffers) < int(table_size)
E assert 536870912 < 181239808
E + where 536870912 = int(536870912)
E + and 181239808 = int(181239808)
```
536870912 / 181239808 ≈ 2.96
Closes https://github.com/neondatabase/neon/issues/3052
From what I could understand from the PR, we did not wait enough before
the attach failed.
Extended the wait period a bit and put a check for a status instead of
plain `sleep` to fail if we don't get the expected status.
This is rather a hack to resolve immediate issue:
https://github.com/neondatabase/neon/issues/3024
Properly cleaning this file from index part requires changes to
initialization of remote queue. Because we need to clean it up earlier
than we start warking around files.
With on-demand there will be no walk around layer files becase
download_missing is no longer needed, so I believe it will be
natural to unify this with load_layer_map
Several fixes are included, with among others:
- Prefetching for index bulkdelete calls (e.g. during vacuum), plus v14 compiler warning fix
- A fix for setting LSN on heap pages while setting vm bits
- Some style updates that were lost in the previous wave (v15 only)
Migrate Nightly Benchmarks from captest to staging.
- Migrate GitHub Workflows
- Replace `zenith-benchmarker` with regular runners
- Remove `environment` parameter from Neon GitHub Actions, add
`postgres_version`
- The only job left on captest is `neon-captest-reuse`, which will be
moved to staging after its project migration.
Ref https://github.com/neondatabase/cloud/issues/2836
Changes:
* Remove `RemoteObjectId` concept from remote_storage.
Operate directly on /-separated names instead.
These names are now represented by struct `RemotePath` which was renamed from struct `RelativePath`
* Require remote storage to operate on relative paths for its contents, thus simplifying the way to derive them in pageserver and safekeeper
* Make `IndexPart` to use `String` instead of `RelativePath` for its entries, since those are just the layer names
This patch centralize the logic of creating & reading pid files into the
new pid_file module and improves upon / makes explicit a few race conditions
that existed with the previous code.
Starting Processes / Creating Pidfiles
======================================
Before this patch, we had three places that had very similar-looking
match lock_file::create_lock_file { ... }
blocks.
After this change, they can use a straight-forward call provided
by the pid_file:
pid_file::claim_pid_file_for_pid()
Stopping Processes / Reading Pidfiles
=====================================
The new pid_file module provides a function to read a pidfile,
called read_pidfile(), that returns a
pub enum PidFileRead {
NotExist,
NotHeldByAnyProcess(PidFileGuard),
LockedByOtherProcess(Pid),
}
If we get back NotExist, there is nothing to kill.
If we get back NotHeldByAnyProcess, the pid file is stale and we must
ignore its contents.
If it's LockedByOtherProcess, it's either another pidfile reader
or, more likely, the daemon that is still running.
In this case, we can read the pid in the pidfile and kill it.
There's still a small window where this is racy, but it's not a
regression compared to what we have before.
The NotHeldByAnyProcess is an improvement over what we had before
this patch. Before, we would blindly read the pidfile contents
and kill, even if no other process held the flock.
If the pidfile was stale (NotHeldByAnyProcess), then that kill
would either result in ESRCH or hit some other unrelated process
on the system. This patch avoids the latter cacse by grabbing
an exclusive flock before reading the pidfile, and returning the
flock to the caller in the form of a guard object, to avoid
concurrent reads / kills.
It's hopefully irrelevant in practice, but it's a little robustness
that we get for free here.
Maintain flock on Pidfile of ETCD / any InitialPidFile::Create()
================================================================
Pageserver and safekeeper create their pidfiles themselves.
But for etcd, neon_local creates the pidfile (InitialPidFile::Create()).
Before this change, we would unlock the etcd pidfile as soon as
`neon_local start` exits, simply because no-one else kept the FD open.
During `neon_local stop`, that results in a stale pid file,
aka, NotHeldByAnyProcess, and it would henceforth not trust that
the PID stored in the file is still valid.
With this patch, we make the etcd process inherit the pidfile FD,
thereby keeping the flock held until it exits.
* We were missing one cluster in production:
`prod-ap-southeast-1-epsilon` configs.
* We had `metrics` enabled. This means creating `ServiceScrape` objects,
but since those clusters don't have `kube-prometheus-stack` like older
ones, we are missing the CRDs, so the helm deploy fails.
The new "trace_read_requests" option was missing from the
parse_toml_tenant_conf function that reads the config file. Because of
that, the option was ignored, which caused the test_read_trace.py test
to fail. It used to work before commit 9a6c0be823, because the
TenantConfigOpt struct was constructed directly in tenant_create_handler,
but now it is saved and read back from disk even for a newly created
tenant.
The abovementioned bug was fixed in commit 09393279c6 already, which
added the missing code to parse_toml_tenant_conf() to parse the
new "trace_read_requests" option. This commit fixes one more function
that was missed earlier, and adds more detail to the error message if
parsing the config file fails.
helm values for the new `storage-broker`. gRPC, over secure connection
with a proper certificate, but no authentication.
Uses alb ingress in the old cluster and nginx ingress for the new one.
The chart is deployed and the addresses are functional, while the
pipeline doesn't exist yet.
It used to be a separate piece of state, but after 9a6c0be823 it's just
an alias for the Tenant being in Attaching state. It was only used in
one assertion in a test, but that check doesn't make sense anymore, so
just remove it.
Fixes https://github.com/neondatabase/neon/issues/2930
Added basic instrumentation to integrate sentry with the proxy, pageserver, and safekeeper processes.
Currently in sentry there are three projects, one for each process. Sentry url is sent to all three processes separately via cli args.
Closes https://github.com/neondatabase/neon/issues/2537
Follow-up of https://github.com/neondatabase/neon/pull/2950
With the new model that prevents attaching without the remote storage,
it has started to be even more odd to add attach-with-files
functionality (in addition to the issues raised previously).
Adds two separate commands:
* `POST {tenant_id}/ignore` that places a mark file to skip such tenant
on every start and removes it from memory
* `POST {tenant_id}/schedule_load` that tries to load a tenant from
local FS similar to what pageserver does now on startup, but without
directory removals
Move missing_layers property to Option<HashSet<RelativePath>>
This will allow the safe removal of it once the upgrade of all page servers is done with this new code
- Replace `seqscan_prefetch_buffers` with `effective_io_concurrency` and
`maintenance_io_concurrency` for `clickbench-compare` job (see
https://github.com/neondatabase/neon/pull/2876)
- Get the database name in a runtime (it can be `main` or `neondb` or
something else)
```
warning: named argument `file` is not used by name
--> pageserver/src/tenant/timeline.rs:1078:54
|
1078 | trace!("downloading image file: {}", file = path.display());
| -- ^^^^ this named argument is referred to by position in formatting string
| |
| this formatting argument uses named argument `file` by position
|
= note: `#[warn(named_arguments_used_positionally)]` on by default
help: use the named argument by name to avoid ambiguity
|
1078 | trace!("downloading image file: {file}", file = path.display());
| ++++
```
Co-authored-by: Heikki Linnakangas <heikki@neon.tech>
- **Enable `enable_seqscan_prefetch` by default**
- Drop use of `seqscan_prefetch_buffers` in favor of
`[maintenance,effective]_io_concurrency`
This includes adding some fields to the HeapScan execution node, and
vacuum state.
- Cleanup some conditionals in vacuumlazy.c
- Clarify enable_seqscan_prefetch GUC description
- Fix issues in heap SeqScan prefetching where synchronize_seqscan
machinery wasn't handled properly.
- Change "WAL service" to "safekeepers" in the architecture section. The
safekeepers together form the WAL service, but we don't use that term
much in the code.
- Replace the short list of pageserver components with a link /docs. We
have more details there.
- Add "Other resources" to Documention section, with links to some blog
posts and a video presentation.
- Remove notice at the top about the Zenith -> Neon rename. There are
still a few references to Zenith in the codebase, but not so many that
we would need to call it out at the top anymore.
Our shutdown procedure for "pageserver init" was buggy. Firstly, it
merely sent the process a SIGKILL, but did not wait for it to actually
exit. Normally, it should exit quickly as SIGKILL cannot be caught or
ignored by the target process, but it's still asynchronous and the
process can still be alive when the kill(2) call returns. Secondly,
"neon_local" removed the PID file after sending SIGKILL, even though the
process was still running. That hid the first problem: if we didn't
remove the PID file, and you start a new pageserver process while the
old one is still running, you would get an error when the new process
tries to lock the PID file.
We've been seeing a lot of "Cannot assign requested address" failures in
the CI lately. Our theory is that when we run "pageserver init"
immediately followed by "pageserver start", the first process is still
running and listening on the port when the second invocation starts up.
This commit hopefully fixes the problem.
It is generally a bad idea for the "neon_local" to remove the PID file
on the child process's behalf. The correct way would be for the server
process to remove the PID file, after it has fully shutdown everything
else. We don't currently have a robust way to ensure that everything has
truly shut down and closed, however.
A simpler way is to simply never remove the PID file. It's not necessary
to remove the PID file for correctness: we cannot rely on the cleanup to
happen anyway, if the server process crashes for example. Because of
that, we already have all the logic in place to deal with a stale PID
file that belonged to a process that already exited. Let's rely on that
on normal shutdown too.
We used to have a bug where the pageserver just got stuck if the
client sent a CopyDone message before reaching end of tar stream. That
showed up with an empty tar file, as one example. That was
inadvertently fixed by code refactorings, but let's add a regression
test for it, so that we don't accidentally re-introduce the bug later.
Co-authored-by: Heikki Linnakangas <heikki@neon.tech>
I'm not a fan of "Paused", for two reasons:
- Paused implies that the tenant/timeline with no activity on it. That's
not true; the tenant/timeline can still have active tasks working on it.
- Paused implies that it can be resumed later. It can not. A tenant or
timeline in this state cannot be switched back to Active state anymore.
A completely new Tenant or Timeline struct can be constructed for the
same tenant or timeline later, e.g. if you detach and later re-attach
the same tenant, but that's a different thing.
Stopping describes the state better. I also considered "ShuttingDown",
but Stopping is simpler as it's a single word.
The code in this change was extracted from PR #2595, i.e., Heikki’s draft
PR for on-demand download.
High-Level Changes
- storage_sync module rewrite
- Changes to Tenant Loading
- Changes to Timeline States
- Crash-safe & Resumable Tenant Attach
There are several follow-up work items planned.
Refer to the Epic issue on GitHub:
https://github.com/neondatabase/neon/issues/2029
Metadata:
closes https://github.com/neondatabase/neon/pull/2785
unsquashed history of this patch: archive/pr-2785-storage-sync2/pre-squash
Co-authored-by: Dmitry Rodionov <dmitry@neon.tech>
Co-authored-by: Christian Schwarz <christian@neon.tech>
===============================================================================
storage_sync module rewrite
===========================
The storage_sync code is rewritten. New module name is storage_sync2, mostly to
make a more reasonable git diff.
The updated block comment in storage_sync2.rs describes the changes quite well,
so, we will not reproduce that comment here. TL;DR:
- Global sync queue and RemoteIndex are replaced with per-timeline
`RemoteTimelineClient` structure that contains a queue for UploadOperations
to ensure proper ordering and necessary metadata.
- Before deleting local layer files, wait for ongoing UploadOps to finish
(wait_completion()).
- Download operations are not queued and executed immediately.
Changes to Tenant Loading
=========================
Initial sync part was rewritten as well and represents the other major change
that serves as a foundation for on-demand downloads. Routines for attaching and
loading shifted directly to Tenant struct and now are asynchronous and spawned
into the background.
Since this patch doesn’t introduce on-demand download of layers we fully
synchronize with the remote during pageserver startup. See details in
`Timeline::reconcile_with_remote` and `Timeline::download_missing`.
Changes to Tenant States
========================
The “Active” state has lost its “background_jobs_running: bool” member. That
variable indicated whether the GC & Compaction background loops are spawned or
not. With this patch, they are now always spawned. Unit tests (#[test]) use the
TenantConf::{gc_period,compaction_period} to disable their effect (15db566).
This patch introduces a new tenant state, “Attaching”. A tenant that is being
attached starts in this state and transitions to “Active” once it finishes
download.
The `GET /tenant` endpoints returns `TenantInfo::has_in_progress_downloads`. We
derive the value for that field from the tenant state now, to remain
backwards-compatible with cloud.git. We will remove that field when we switch
to on-demand downloads.
Changes to Timeline States
==========================
The TimelineInfo::awaits_download field is now equivalent to the tenant being
in Attaching state. Previously, download progress was tracked per timeline.
With this change, it’s only tracked per tenant. When on-demand downloads
arrive, the field will be completely obsolete. Deprecation is tracked in
isuse #2930.
Crash-safe & Resumable Tenant Attach
====================================
Previously, the attach operation was not persistent. I.e., when tenant attach
was interrupted by a crash, the pageserver would not continue attaching after
pageserver restart. In fact, the half-finished tenant directory on disk would
simply be skipped by tenant_mgr because it lacked the metadata file (it’s
written last). This patch introduces an “attaching” marker file inside that is
present inside the tenant directory while the tenant is attaching. During
pageserver startup, tenant_mgr will resume attach if that file is present. If
not, it assumes that the local tenant state is consistent and tries to load the
tenant. If that fails, the tenant transitions into Broken state.
Change the default region for staging from `us-east-1` to `us-east-2`
for project creation.
Remove REGION_ID from `neon-branch-create` since we don't use it.
Nothing interesting in these changes. Passing through the
RUST_BACKTRACE=full will hopefully save someone else panick reproduction
time.
Co-authored-by: Heikki Linnakangas <heikki@neon.tech>
Sometimes CI build fails with
error: couldn't read storage_broker/src/../proto/storage_broker.rs: No such file or directory (os error 2)
--> storage_broker/src/lib.rs:14:5
|
14 | include!("../proto/storage_broker.rs");
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
The root cause is not clear, but it looks like interference with cachepot. Per
cargo docs, build scripts shouldn't output to anywhere but OUT_DIR; let's follow
this and see if it helps.
When a new root timeline is created, we want to flush all the data to
disk before we return success to the caller. We were using
checkpoint(CheckpointConfig::Forced) for that, but that also performs
compaction. With the default settings, compaction will have no work
after we have imported an empty database, as the image of that is too
small to require compaction. However, with very small
checkpoint_distance and compaction_target_size, compaction will run, and
it can take a while.
PR #2785 adds new tests that use very small checkpoint_distance and
compaction_target_size settings, and the test sometimes failed with
"operation timed out" error in the client, when the create_timeline step
took too long.
Add ClickBench benchmark, an OLAP-style benchmark, to Nightly
Benchmarks.
The full run of 43 queries on the original dataset takes more than 6h
(only 34 queries got processed on in 6h) on our default-sized compute.
Having this, currently, would mean having some really unstable tests
because of our regular deployment to staging/captest environment (see
https://github.com/neondatabase/cloud/issues/1872).
I've reduced the dataset size to the first 10^7 rows from the original
10^8 rows. Now it takes ~30-40 minutes to pass.
Ref https://github.com/ClickHouse/ClickBench/tree/main/aurora-postgresql
Ref https://benchmark.clickhouse.com/
Add `neon-branch-create` / `neon-branch-delete` to allow using branches
in tests.
I have a couple of use cases in mind:
- For destructive tests with a big DB, we can create the DB once in
advance and then use branches without the need to recreate the DB itself
after tests change it.
- We can run tests in parallel (if there're compute-bound).
Also migrate API v2 for `neon-project-create` / `neon-project-delete`
Many python tests were setting the GC/compaction period to large
values, to effectively disable GC / compaction. Reserve value 0 to
mean "explicitly disabled". We also set them to 0 in unit tests now,
although currently, unit tests don't launch the background jobs at
all, so it won't have any effect.
Fixes https://github.com/neondatabase/neon/issues/2917
Fix `test_seqscans` by disabling statement timeout.
Also, replace increasing statement timeout with disabling it for
performance tests. This should make tests more stable and allow us to
observe performance degradation instead of test failures.
**NB**: this PR doesn't update Python to 3.11; it makes tests
compatible with it and fixes a couple of warnings by updating
dependencies.
- `poetry add asyncpg@latest` to fix `./scripts/pysync`
- `poetry add boto3@latest "boto3-stubs[s3]@latest"` to fix
```
DeprecationWarning: 'cgi' is deprecated and slated for removal in Python 3.13
```
- `poetry update certifi` to fix
```
DeprecationWarning: path is deprecated. Use files() instead. Refer to https://importlib-resources.readthedocs.io/en/latest/using.html#migrating-from-legacy for migration advice.
```
- Move `types-toml` from `dep-dependencies` to `dependencies` to keep it
aligned with other `types-*` deps
* Fix https://github.com/neondatabase/neon/issues/1854
* Never log Safekeeper::conninfo in walproposer as it now contains a secret token
* control_panel, test_runner: generate and pass JWT tokens for Safekeeper to compute and pageserver
* Compute: load JWT token for Safekepeer from the environment variable. Do not reuse the token from
pageserver_connstring because it's embedded in there weirdly.
* Pageserver: load JWT token for Safekeeper from the environment variable.
* Rewrite docs/authentication.md
There will be different scopes for those two, so authorization code should be different.
The `check_permission` function is now not in the shared library. Its implementation
is very similar to the one which will be added for Safekeeper. In fact, we may reuse
the same existing root-like 'PageServerApi' scope, but I would prefer to have separate
root-like scopes for services.
Also, generate_management_token in tests is generate_pageserver_token now.
Downsides are:
* We store all components of the config separately. `Url` stores them inside a single
`String` and a bunch of ints which point to different parts of the URL, which is
probably more efficient.
* It is now impossible to pass arbitrary connection strings to the configuration file,
one has to support all components explicitly. However, we never supported anything
except for `host:port` anyway.
Upsides are:
* This significantly restricts the space of possible connection strings, some of which
may be either invalid or unsupported. E.g. Postgres' connection strings may include
a bunch of parameters as query (e.g. `connect_timeout=`, `options=`). These are nether
validated by the current implementation, nor passed to the postgres client library,
Hence, storing separate fields expresses the intention better.
* The same connection configuration may be represented as a URL in multiple ways
(e.g. either `password=` in the query part or a standard URL password).
Now we have a single canonical way.
* Escaping is provided for `options=`.
Other possibilities considered:
* `newtype` with a `String` inside and some validation on creation.
This is more efficient, but harder to log for two reasons:
* Passwords should never end up in logs, so we have to somehow
* Escaped `options=` are harder to read, especially if URL-encoded,
and we use `options=` a lot.
Which ought to replace etcd. This patch only adds the binary and adjusts
Dockerfile to include it; subsequent ones will add deploy of helm chart and the
actual replacement.
It is a simple and fast pub-sub message bus. In this patch only safekeeper
message is supported, but others can be easily added.
Compilation now requires protoc to be installed. Installing protobuf-compiler
package is fine for Debian/Ubuntu.
ref
https://github.com/neondatabase/neon/pull/2733https://github.com/neondatabase/neon/issues/2394
Imagine that you have a tenant with a single branch like this:
---------------==========>
^
gc horizon
where:
---- is the portion of the branch that is older than retention period
==== is the portion of the branch that is newer than retention period.
Before this commit, the sizing model included the logical size at the
GC horizon, but not the WAL after that. In particular, that meant that
on a newly created tenant with just one timeline, where the retention
period covered the whole history of the timeline, i.e. gc_cutoff was 0,
the calculated tenant size was always zero.
We now include the WAL after the GC horizon in the size. So in the
above example, the calculated tenant size would be the logical size
of the database the GC horizon, plus all the WAL after it (marked with
===).
This adds a new `insert_point` function to the sizing model, alongside
`modify_branch`, and changes the code in size.rs to use the new
function. The new function takes an absolute lsn and logical size as
argument, so we no longer need to calculate the difference to the
previous point. Also, the end-size is now optional, because we now
need to add a point to represent the end of each branch to the model,
but we don't want to or need to calculate the logical size at that
point.
- Pass through FAILPOINTS environment variable to the pageserver in
"neon_local pageserver start" command
- On startup, list any failpoints that were set with FAILPOINTS to the log
- Add optional "extra_env_vars" argument to the NeonPageserver.start()
function in the python fixture, so that you can pass FAILPOINTS
None of the tests use this functionality yet; that comes in a separate
commit.
closes https://github.com/neondatabase/neon/pull/2865
Increse the pgbench runtimes even further. The theory is that when
there are many other tests running at the same time, one pgbench run
could take a long time until it generates enough layers for GC to kick
in.
I saw these from the build of the compute docker image in the CI
(compute-node-image-v15):
pagestore_smgr.c: In function 'neon_prefetch':
pagestore_smgr.c:1654:2: warning: ISO C90 forbids mixed declarations and code [-Wdeclaration-after-statement]
1654 | BufferTag tag = (BufferTag) {
| ^~~~~~~~~
walproposer.c:197:1: warning: no previous prototype for 'WalProposerSync' [-Wmissing-prototypes]
197 | WalProposerSync(int argc, char *argv[])
| ^~~~~~~~~~~~~~~
libpagestore.c: In function 'pageserver_connect':
libpagestore.c💯9: warning: variable 'wc' set but not used [-Wunused-but-set-variable]
100 | int wc;
| ^~
libpagestore.c: In function 'call_PQgetCopyData':
libpagestore.c:144:9: warning: variable 'wc' set but not used [-Wunused-but-set-variable]
144 | int wc;
| ^~
Harmless warnings, but let's be tidy.
In the passing, I added some "extern" to a few function declarations
that were missing them, and marked WalProposerSync as "static". Those
changes are also purely cosmetic.
Commit d013a2b227 changed the test, so that it fails if pgbench runs
to completion without triggering the failpoint. That has now happened
several times in the CI. That's not expected, so this needs some
investigation, but as a quick fix just make the pgbench runs longer so
that we're closer to the situation before commit d013a2b227.
See https://github.com/neondatabase/neon/issues/2856
This allows us to error out in the case where we request flush but the
flush loop is not running.
Before, we would only track whether it was started, but not when it
exited.
Better to use an enum with 3 states than a 2-state bool because then
the error message can answer the question whether we ever started
the flush loop or not.
In a CI run, I got a test failure because of this error in the log,
from the test_get_tenant_size_with_multiple_branches test:
ERROR gc_loop{tenant_id=f1630516d4b526139836ced93be0c878}: Gc failed, retrying in 2s: No such file or directory (os error 2)
There are known race conditions between GC and timeline deletion,
which surely caused that error. But if we didn't know the cause, it
would be pretty hard to debug without a stack trace.
* Poll more frequently when waiting for process start/stop. This
speeds up startup and shutdown in tests. We did this already in
commit 52ce1c9d53, which reduced the interval to 100 ms, but it was
inadvertently increased back to 500 ms in commit d42700280f. Reduce
it to 100 ms again, for both start and stop operations.
* Harmonize the start and stop loops, printing the dots and notices
the same way in both. I considered extracting the logic to a
separate retry-function that takes a closure as argument that does
the polling, but as long as we only have two copies, the code
duplication isn't that bad.
* Remove newline after "Starting pageserver" and "Starting etcd"
messages, so that the progress-indicator dots that are printed once
a second are printed on the same line. Before:
Starting pageserver at '127.0.0.1:64000' in '.neon'
...
pageserver started, pid: 2538937
After:
Starting pageserver at '127.0.0.1:64000' in '.neon'...
pageserver started, pid: 2538937
The "Starting safekeeper" message already got this right.
* Update example output in README.md to match
Set correct `pg_distrib_dir` in `pageserver.toml` and in neon_local
`config`.
`test_forward_compatibility` shows flakiness during `neon_local pg
start`, so hopefully, the patch will help.
```
2022-11-15 16:07:34.091 GMT [13338] LOG: starting with zenith basebackup at LSN 0/A6A9310, prev 0/0
2022-11-15 16:07:34.091 GMT [13338] FATAL: cannot start in read-write mode from this base backup
2022-11-15 16:07:34.091 GMT [13337] LOG: startup process (PID 13338) exited with exit code 1
```
Despite tests working, on staging the library started to fail with the
following error:
```
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 2022-11-16T11:53:37.191211Z INFO init_tenant_mgr:local_tenant_timeline_files: Collected files for 16 tenants
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: thread 'main' panicked at 'A connector was not available. Either set a custom connector or enable the `rustls` and `native-tls` crate featu>
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: stack backtrace:
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 0: rust_begin_unwind
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/std/src/panicking.rs:584:5
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 1: core::panicking::panic_fmt
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/core/src/panicking.rs:142:14
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 2: core::panicking::panic_display
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/core/src/panicking.rs:72:5
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 3: core::panicking::panic_str
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/core/src/panicking.rs:56:5
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 4: core::option::expect_failed
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/core/src/option.rs:1854:5
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 5: <core::future::from_generator::GenFuture<T> as core::future::future::Future>::poll
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 6: <core::future::from_generator::GenFuture<T> as core::future::future::Future>::poll
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 7: <core::future::from_generator::GenFuture<T> as core::future::future::Future>::poll
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 8: <aws_types::credentials::provider::future::ProvideCredentials as core::future::future::Future>::poll
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 9: <tracing::instrument::Instrumented<T> as core::future::future::Future>::poll
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 10: <core::future::from_generator::GenFuture<T> as core::future::future::Future>::poll
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 11: <aws_types::credentials::provider::future::ProvideCredentials as core::future::future::Future>::poll
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 12: <core::future::from_generator::GenFuture<T> as core::future::future::Future>::poll
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 13: <core::future::from_generator::GenFuture<T> as core::future::future::Future>::poll
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 14: <aws_smithy_http_tower::map_request::MapRequestFuture<F,E> as core::future::future::Future>::poll
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 15: <core::pin::Pin<P> as core::future::future::Future>::poll
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/core/src/future/future.rs:124:9
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 16: <aws_smithy_http_tower::parse_response::ParseResponseService<InnerService,ResponseHandler,RetryPolicy> as tower_service::Service<aws_>
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /home/nonroot/.cargo/registry/src/github.com-1ecc6299db9ec823/aws-smithy-http-tower-0.51.0/src/parse_response.rs:109:34
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 17: <core::future::from_generator::GenFuture<T> as core::future::future::Future>::poll
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/core/src/future/mod.rs:91:19
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 18: <tracing::instrument::Instrumented<T> as core::future::future::Future>::poll
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /home/nonroot/.cargo/registry/src/github.com-1ecc6299db9ec823/tracing-0.1.37/src/instrument.rs:272:9
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 19: <core::pin::Pin<P> as core::future::future::Future>::poll
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/core/src/future/future.rs:124:9
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 20: <aws_smithy_client::timeout::TimeoutServiceFuture<InnerFuture> as core::future::future::Future>::poll
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /home/nonroot/.cargo/registry/src/github.com-1ecc6299db9ec823/aws-smithy-client-0.51.0/src/timeout.rs:189:70
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 21: <tower::retry::future::ResponseFuture<P,S,Request> as core::future::future::Future>::poll
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /home/nonroot/.cargo/registry/src/github.com-1ecc6299db9ec823/tower-0.4.13/src/retry/future.rs:77:41
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 22: <aws_smithy_client::timeout::TimeoutServiceFuture<InnerFuture> as core::future::future::Future>::poll
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /home/nonroot/.cargo/registry/src/github.com-1ecc6299db9ec823/aws-smithy-client-0.51.0/src/timeout.rs:189:70
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 23: aws_smithy_client::Client<C,M,R>::call_raw::{{closure}}
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /home/nonroot/.cargo/registry/src/github.com-1ecc6299db9ec823/aws-smithy-client-0.51.0/src/lib.rs:227:56
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 24: <core::future::from_generator::GenFuture<T> as core::future::future::Future>::poll
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/core/src/future/mod.rs:91:19
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 25: aws_smithy_client::Client<C,M,R>::call::{{closure}}
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /home/nonroot/.cargo/registry/src/github.com-1ecc6299db9ec823/aws-smithy-client-0.51.0/src/lib.rs:184:29
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 26: <core::future::from_generator::GenFuture<T> as core::future::future::Future>::poll
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/core/src/future/mod.rs:91:19
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 27: aws_sdk_s3::client::fluent_builders::GetObject::send::{{closure}}
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /home/nonroot/.cargo/registry/src/github.com-1ecc6299db9ec823/aws-sdk-s3-0.21.0/src/client.rs:7735:40
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 28: <core::future::from_generator::GenFuture<T> as core::future::future::Future>::poll
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/core/src/future/mod.rs:91:19
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 29: remote_storage::s3_bucket::S3Bucket::download_object::{{closure}}
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at libs/remote_storage/src/s3_bucket.rs:205:20
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 30: <core::future::from_generator::GenFuture<T> as core::future::future::Future>::poll
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/core/src/future/mod.rs:91:19
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 31: <remote_storage::s3_bucket::S3Bucket as remote_storage::RemoteStorage>::download::{{closure}}
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at libs/remote_storage/src/s3_bucket.rs:399:11
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 32: <core::future::from_generator::GenFuture<T> as core::future::future::Future>::poll
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/core/src/future/mod.rs:91:19
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 33: <core::pin::Pin<P> as core::future::future::Future>::poll
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/core/src/future/future.rs:124:9
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 34: remote_storage::GenericRemoteStorage::download_storage_object::{{closure}}
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at libs/remote_storage/src/lib.rs:264:55
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 35: <core::future::from_generator::GenFuture<T> as core::future::future::Future>::poll
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/core/src/future/mod.rs:91:19
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 36: pageserver::storage_sync::download::download_index_part::{{closure}}
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at pageserver/src/storage_sync/download.rs:148:57
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 37: <core::future::from_generator::GenFuture<T> as core::future::future::Future>::poll
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/core/src/future/mod.rs:91:19
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 38: pageserver::storage_sync::download::download_index_parts::{{closure}}::{{closure}}::{{closure}}
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at pageserver/src/storage_sync/download.rs:77:75
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 39: <core::future::from_generator::GenFuture<T> as core::future::future::Future>::poll
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/core/src/future/mod.rs:91:19
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 40: <futures_util::stream::futures_unordered::FuturesUnordered<Fut> as futures_core::stream::Stream>::poll_next
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /home/nonroot/.cargo/registry/src/github.com-1ecc6299db9ec823/futures-util-0.3.24/src/stream/futures_unordered/mod.rs:514:17
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 41: futures_util::stream::stream::StreamExt::poll_next_unpin
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /home/nonroot/.cargo/registry/src/github.com-1ecc6299db9ec823/futures-util-0.3.24/src/stream/stream/mod.rs:1626:9
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 42: <futures_util::stream::stream::next::Next<St> as core::future::future::Future>::poll
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /home/nonroot/.cargo/registry/src/github.com-1ecc6299db9ec823/futures-util-0.3.24/src/stream/stream/next.rs:32:9
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 43: pageserver::storage_sync::download::download_index_parts::{{closure}}
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at pageserver/src/storage_sync/download.rs:80:69
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 44: <core::future::from_generator::GenFuture<T> as core::future::future::Future>::poll
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/core/src/future/mod.rs:91:19
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 45: tokio::park:🧵:CachedParkThread::block_on::{{closure}}
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /home/nonroot/.cargo/registry/src/github.com-1ecc6299db9ec823/tokio-1.21.1/src/park/thread.rs:267:54
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 46: tokio::coop::with_budget::{{closure}}
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /home/nonroot/.cargo/registry/src/github.com-1ecc6299db9ec823/tokio-1.21.1/src/coop.rs:102:9
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 47: std:🧵:local::LocalKey<T>::try_with
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/std/src/thread/local.rs:445:16
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 48: std:🧵:local::LocalKey<T>::with
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/std/src/thread/local.rs:421:9
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 49: tokio::coop::with_budget
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /home/nonroot/.cargo/registry/src/github.com-1ecc6299db9ec823/tokio-1.21.1/src/coop.rs:95:5
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 50: tokio::coop::budget
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /home/nonroot/.cargo/registry/src/github.com-1ecc6299db9ec823/tokio-1.21.1/src/coop.rs:72:5
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 51: tokio::park:🧵:CachedParkThread::block_on
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /home/nonroot/.cargo/registry/src/github.com-1ecc6299db9ec823/tokio-1.21.1/src/park/thread.rs:267:31
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 52: tokio::runtime::enter::Enter::block_on
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /home/nonroot/.cargo/registry/src/github.com-1ecc6299db9ec823/tokio-1.21.1/src/runtime/enter.rs:152:13
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 53: tokio::runtime::scheduler::multi_thread::MultiThread::block_on
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /home/nonroot/.cargo/registry/src/github.com-1ecc6299db9ec823/tokio-1.21.1/src/runtime/scheduler/multi_thread/mod.rs:79:9
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 54: tokio::runtime::Runtime::block_on
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /home/nonroot/.cargo/registry/src/github.com-1ecc6299db9ec823/tokio-1.21.1/src/runtime/mod.rs:492:44
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 55: pageserver::storage_sync::spawn_storage_sync_task
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at pageserver/src/storage_sync.rs:656:34
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 56: pageserver::tenant_mgr::init_tenant_mgr
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at pageserver/src/tenant_mgr.rs:88:13
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 57: pageserver::start_pageserver
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at pageserver/src/bin/pageserver.rs:269:9
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 58: pageserver::main
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at pageserver/src/bin/pageserver.rs:103:5
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: 59: core::ops::function::FnOnce::call_once
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/core/src/ops/function.rs:248:5
Nov 16 11:53:37 pageserver-0.us-east-2.aws.neon.build pageserver[481974]: note: Some details are omitted, run with `RUST_BACKTRACE=full` for a verbose backtrace.
```
Feels like better testing on the env is needed later, maybe more e2e
tests have to be written (albeit we have download tests, so something
else happens here, tls issues?)
Thanks to the race condition, GC sometimes fails with "no such file or
directory" error, if the tenant is detached concurrently. That's a
known issue, but it didn't cause test failures until we started to
check for unexpected ERRORs in the log in commit 46d30bf054. We should
fix the race condition, of course, but until we do, let's silence the
failures.
Previously, if the failpoint was not reached for some reason, the test
would only fail because it would reach the 5 minute timeout we have on
all python tests. That's very subtle. Make it fail explicitly, if the
failpoint is not hit on each iteration of the loop.
Extracted from a larger PR, see
https://github.com/neondatabase/neon/pull/2785/files#r1022765794
- Refactor the code a little bit, removing the silly for-loop over a
single element.
- Make it more clear in log messages that the errors are expectd
- Check for a more precise error message "Failed to load delta layer"
instead of just "extracting base backup failed".
If there are any unexpected ERRORs or WARNs in pageserver.log after test
finishes, fail the test. This requires whitelisting the errors that *are*
expected in each test, and there's also a few common errors that are
printed by most tests, which are whitelisted in the fixture itself.
With this, we don't need the special abort() call in testing mode, when
compaction or GC fails. Those failures will print ERRORs to the logs,
which will be picked up by this new mechanisms.
A bunch of errors are currently whitelisted that we probably shouldn't
be emitting in the first place, but fixing those is out of scope for this
commit, so I just left FIXME comments on them.
It's more or less expected from pageserver's point of view. Change the
error kind to ConnectionReset, so that it gets logged at INFO level
instead of ERROR.
We passed the pageserver's libpq endpoint URL as the 'compute_ctl
--connstr' argument, but that was bogus: the --connstr URL is supposed
to be the URL to the *Postgres* instance that compute_ctl launches and
monitors, not to the pageserver. compute_ctl does need the pageserver
URL too, but it is read from the cluster spec JSON, not --connstr.
That was pretty confusing, as you got a lot of "unknown command"
errors in the pageserver log, when compute_tools tries to run regular
SQL commands on the pageserver. The test still passed, however, as it
doesn't require the SQL commands to succeed. But to make this less
confusing, use an invalid hostname instead, so that the queries will
fail to even connect.
- Update vendored PostgreSQL to address prefetch issues
- Make flushed state explicit in PrefetchState
- Move flush logic into prefetch_wait_for, where possible
- Clean up some prefetch state handling code in the various code
elements handling state transitions.
- Fix a race condition in neon_read_at_lsn where a hash entry pointer
was used after the hash table was updated. This could result in
incorrect state transitions and assertion failures after disconnects
during prefetch_wait_for in that neon_read_at_lsn.
Fixes#2780
Before we had separate images for v14 and v15, the compute node image
was called just "neondatabase/compute-node". It has been superseded by
the "neondatabase/compute-node-v14" and "neondatabase/compute-node-v15"
images. The old image is not used by the cloud console build or tests
anymore.
I saw this in 'perf' profile of a sequential scan:
> - 31.93% 0.21% compute request pageserver [.] <pageserver::walredo::PostgresRedoManager as pageserver::walredo::WalRedoManager>::request_redo
> - 31.72% <pageserver::walredo::PostgresRedoManager as pageserver::walredo::WalRedoManager>::request_redo
> - 31.26% pageserver::walredo::PostgresRedoManager::apply_batch_postgres
> + 7.64% <std::process::ChildStdin as std::io::Write>::write
> + 6.17% nix::poll::poll
> + 3.58% <std::process::ChildStderr as std::io::Read>::read
> + 2.96% std::sync::condvar::Condvar::notify_one
> + 2.48% std::sys::unix::locks::futex::Condvar::wait
> + 2.19% alloc::raw_vec::RawVec<T,A>::reserve::do_reserve_and_handle
> + 1.14% std::sys::unix::locks::futex::Mutex::lock_contended
> 0.67% __rust_alloc_zeroed
> 0.62% __stpcpy_ssse3
> 0.56% std::sys::unix::locks::futex::Mutex::wake
Note the 'do_reserve_handle' overhead. That's caused by having to grow
the buffer used to construct the WAL redo request. This commit
eliminates that overhead. It's only about 2% of the overall CPU usage,
but every little helps.
Also reuse the temp buffer when reading records from a DeltaLayer, and
call Vec::reserve to avoid growing a buffer when reading a blob across
pages. I saw a reduction from 2% to 1% of CPU spent in
do_reserve_and_handle in that codepath, but that's such a small change
that it could be just noise. Seems like it shouldn't hurt though.
Closes https://github.com/neondatabase/neon/issues/2697
Example:
https://github.com/neondatabase/neon/actions/runs/3416774593/jobs/5688394855
Adds a set of tests on the storage Docker images before they are pushed
to the public registries:
* tests that pageserver binary has the correct version string (other
binaries are built with the same library, so it should be enough to test
one)
* tests that the compose file set-up works and all components are able
to start and perform a single SQL query (CREATE TABLE)
This change wraps the std::process:Child that we spawn for WAL redo
into a type that ensures that we try to SIGKILL + waitpid() on it.
If there is no explicit call to kill_and_wait(), the Drop implementation
will spawns a task that does it in the BACKGROUND_RUNTIME.
That's an ugly hack but I think it's better than doing kill+wait
synchronously from Drop, since I think the general assumption in the
Rust ecosystem is that Drop doesn't block.
Especially since the drop sites can be _any_ place that drops the last
Arc<PostgresRedoManager>, e.g., compaction or GC.
The benefit of having the new type over just adding a Drop impl to
PostgresRedoProcess is that we can construct it earlier than the full
PostgresRedoProcess in PostgresRedoProcess::launch().
That allows us to correctly kill+wait the child if there is an error in
PostgresRedoProcess::launch() after spawning it.
I also took a stab at a regression test. I manually verified
that it fails before the fix to walredo.rs.
fixes https://github.com/neondatabase/neon/issues/2761
closes https://github.com/neondatabase/neon/pull/2776
Add `test_forward_compatibility`, which checks if it's going to
be possible to roll back a release to the previous version.
The test uses artifacts (Neon & Postgres binaries) from the previous
release to start Neon on the repo created by the current version. It
performs exactly the same checks as `test_backward_compatibility` does.
Single `ALLOW_BREAKING_CHANGES` env var got replaced by
`ALLOW_BACKWARD_COMPATIBILITY_BREAKAGE` &
`ALLOW_FORWARD_COMPATIBILITY_BREAKAGE` and can be set by `backward
compatibility breakage` and `forward compatibility breakage` labels
respectively.
When we repeatedly wait for the same events, it's faster to create the
event set once and reuse it. While testing with a sequential scan test
case, I saw WaitLatchOrSocket consuming a lot of CPU:
> - 40.52% 0.14% postgres postgres [.] WaitLatchOrSocket
> - 40.38% WaitLatchOrSocket
> + 17.83% AddWaitEventToSet
> + 9.47% close@plt
> + 8.29% CreateWaitEventSet
> + 4.57% WaitEventSetWait
This eliminates most of that overhead.
If we're not calling kill() before dropping the PostgresRedoProcess, we
currently leak it.
That's most likely the root cause for #2761.
This patch
1. adds an error log message for that case and
2. adds error handling for all errors on the kill() path. If we're a
`testing` build, we panic. Otherwise, we log an error and leak the
process.
The error handling changes (2) are necessary to conclusively state that
the root cause for #2761 is indeed (1). If we didn't have them, the root
cause could be missing error handling instead.
To make the log messages useful, I've added tracing::instrument
attributes that log the tenant_id and PID. That helps mapping back the
PID of `defunct` processes to pageserver log messages. Note that a
defunct process's `/proc/$PID/` directory isn't very useful. We have
left little more than its PID.
Once we have validated the root cause, we'll find a fix, but that's
still an ongoing discussion.
refs https://github.com/neondatabase/neon/issues/2761
closes https://github.com/neondatabase/neon/pull/2769
This PR replaces the following global variables in the test framework
with fixtures to make tests more configurable. I mainly need this for
the forward compatibility tests (draft in
https://github.com/neondatabase/neon/pull/2766).
```
base_dir
neon_binpath
pg_distrib_dir
top_output_dir
default_pg_version (this one got replaced with a fixture named pg_version)
```
Also, this PR adds more `Path` type where the code implies it.
Prefetch requests and responses are stored in a ringbuffer instead of a
queue, which means we can utilize prefetches of many relations
concurrently -- page reads of un-prefetched relations now don't imply
dropping prefetches.
In a future iteration, this may detect sequential scans based on the
read behavior of sequential scans, and will dynamically prefetch buffers
for such relations as needed. Right now, it still depends on explicit
prefetch requests from PostgreSQL.
The main improvement here is that we now have a buffer for prefetched
pages of 128 entries with random access. Before, we had a similarly sized
cache, but this cache did not allow for random access, which resulted in
dropped entries when multiple systems used the prefetching subsystem
concurrently.
See also: #2544
With more realistic selection of gc_horizon in tests there is an
immediate failure with trying to query logical size with lsn <
initdb_lsn. Fixes that, adds illustration gathered from clarity of
explaining this tenant size calculation to more people.
Cc: #2748, #2599.
Tenant size information is gathered by using existing parts of
`Tenant::gc_iteration` which are now separated as
`Tenant::refresh_gc_info`. `Tenant::refresh_gc_info` collects branch
points, and invokes `Timeline::update_gc_info`; nothing was supposed to
be changed there. The gathered branch points (through Timeline's
`GcInfo::retain_lsns`), `GcInfo::horizon_cutoff`, and
`GcInfo::pitr_cutoff` are used to build up a Vec of updates fed into the
`libs/tenant_size_model` to calculate the history size.
The gathered information is now exposed using `GET
/v1/tenant/{tenant_id}/size`, which which will respond with the actual
calculated size. Initially the idea was to have this delivered as tenant
background task and exported via metric, but it might be too
computationally expensive to run it periodically as we don't yet know if
the returned values are any good.
Adds one new metric:
- pageserver_storage_operations_seconds with label `logical_size`
- separating from original `init_logical_size`
Adds a pageserver wide configuration variable:
- `concurrent_tenant_size_logical_size_queries` with default 1
This leaves a lot of TODO's, tracked on issue #2748.
`test_tenant_relocation` ends up starting a temporary postgres instance with a fixed port. the change makes the port configurable at scripts/export_import_between_pageservers.py and uses that in test_tenant_relocation.
The spawn_blocking is pointless in this cases: get_tenant is not
expected to block for any meaningful amount of time. There are
get_tenant calls in most other functions in the file too, and they don't
bother with spawn_blocking. Let's remove the spawn_blocking from
tenant_status, too, to be consistent.
fixes https://github.com/neondatabase/neon/issues/2731
Gc needs to know about all branch points, not only ones for
timelines that are active at the moment of gc. If timeline
is inactive then we wont know about branch point. In this
case gc can delete data that is needed by child timeline.
For compaction it is less severe. Delaying compaction can
cause an effect on performance. So it is still better to run
it. There is a logic to exit it quickly if there is nothing
to compact
- Refactor the way the WalProposerMain function is called when started
with --sync-safekeepers. The postgres binary now explicitly loads
the 'neon.so' library and calls the WalProposerMain in it. This is
simpler than the global function callback "hook" we previously used.
- Move the WAL redo process code to a new library, neon_walredo.so,
and use the same mechanism as for --sync-safekeepers to call the
WalRedoMain function, when launched with --walredo argument.
- Also move the seccomp code to neon_walredo.so library. I kept the
configure check in the postgres side for now, though.
The main reason for that change is that Postgres 15 requires OpenSSL
for `pgcrypto` to work. Also not a bad idea to have SSL-enabled
Postgres in general.
plv8 can only be built with a fairly new gold linker version. We used to install
it via binutils packages from testing, but it also updates libc and that causes
troubles in the resulting image as different extensions were built against
different libc versions. We could either use libc from debian-testing everywhere
or restrain from using testing packages and install necessary programs manually.
This patch uses the latter approach: gold for plv8 and cmake for h3 are
installed manually.
In a passing declare h3_postgis as a safe extension (previous omission).
`GRANT CREATE ON SCHEMA public` fails if there is no schema `public`.
Disable it in release for now and make a better fix later (it is
needed for v15 support).
* Support configuring the log format as json or plain.
Separately test json and plain logger. They would be competing on the
same global subscriber otherwise.
* Implement log_format for pageserver config
* Implement configurable log format for safekeeper.
Similar to https://github.com/neondatabase/neon/pull/2395, introduces a state field in Timeline, that's possible to subscribe to.
Adjusts
* walreceiver to not to have any connections if timeline is not Active
* remote storage sync to not to schedule uploads if timeline is Broken
* not to create timelines if a tenant/timeline is broken
* automatically switches timelines' states based on tenant state
Does not adjust timeline's gc, checkpointing and layer flush behaviour much, since it's not safe to cancel these processes abruptly and there's task_mgr::shutdown_tasks that does similar thing.
This API is rather pointless, as sane choice anyway requires knowledge of peers
status and leaders lifetime in any case can intersect, which is fine for us --
so manual elections are straightforward. Here, we deterministically choose among
the reasonably caught up safekeepers, shifting by timeline id to spread the
load.
A step towards custom broker https://github.com/neondatabase/neon/issues/2394
* Fix bogus early exit from GC.
Commit 91411c415a added this failpoint, but the early exit was not
intentional.
* Cleanup test_gc_cutoff.py test.
- Remove the 'scale' parameter, this isn't a benchmark
- Tweak pgbench and pageserver options to create garbage faster that the
the GC can collect away. The test used to take just under 5 minutes,
which was uncomfortably close to the default 5 minute test timeout, and
annoyingly even without the hard limit. These changes bring it down to
about 1-2 minutes.
- Improve comments, fix typos
- Rename the failpoint. The old name, 'gc-before-save-metadata' implied
that the failpoint was before the metadata update, but it was in fact
much later in the function.
- Move the call to persist the metadata outside the lock, to avoid
holding it for too long.
To verify that this test still covers the original bug,
https://github.com/neondatabase/neon/issues/2539, I commenting out
updating the metadata file like this:
```
diff --git a/pageserver/src/tenant/timeline.rs b/pageserver/src/tenant/timeline.rs
index 1e857a9a..f8a9f34a 100644
--- a/pageserver/src/tenant/timeline.rs
+++ b/pageserver/src/tenant/timeline.rs
@@ -1962,7 +1962,7 @@ impl Timeline {
}
// Persist the new GC cutoff value in the metadata file, before
// we actually remove anything.
- self.update_metadata_file(self.disk_consistent_lsn.load(), HashMap::new())?;
+ //self.update_metadata_file(self.disk_consistent_lsn.load(), HashMap::new())?;
info!("GC starting");
```
It doesn't fail every time with that, but it did fail after about 5
runs.
If we cannot reconstruct an FSM or VM page, while creating image
layers, fill it with zeros instead. That should always be safe, for
the FSM and VM, in the sense that you won't lose actual user data. It
will get cleaned up by VACUUM later.
We had a bug with FSM/VM truncation, where we truncated the FSM and VM
at WAL replay to a smaller size than PostgreSQL originally did. We
thought was harmless, as the FSM and VM are not critical for
correctness and can be zeroed out or truncated without affecting user
data. However, it lead to a situation where PostgreSQL created
incremental WAL records for pages that we had already truncated away
in the pageserver, and when we tried to replay those WAL records, that
failed. That lead to a permanent error in image layer creation, and
prevented it from ever finishing. See
https://github.com/neondatabase/neon/issues/2601. With this patch,
those pages will be filled with zeros in the image layer, which allows
the image layer creation to finish.
Part of https://github.com/neondatabase/neon/pull/2239
Regular, from scratch, timeline creation involves initdb to be run in a separate directory, data from this directory to be imported into pageserver and, finally, timeline-related background tasks to start.
This PR ensures we don't leave behind any directories that are not marked as temporary and that pageserver removes such directories on restart, allowing timeline creation to be retried with the same IDs, if needed.
It would be good to later rewrite the logic to use a temporary directory, similar what tenant creation does.
Yet currently it's harder than this change, so not done.
Follow-up of #2636 and #2654 , fixing the test detection feature.
Pageserver currently outputs features as
```
/target/debug/pageserver --version
Neon page server git:7734929a8202c8cc41596a861ffbe0b51b5f3cb9 failpoints: true, features: ["testing", "profiling"]
```
These two tests, test_timeline_physical_size_post_compaction and
test_timeline_physical_size_post_gc, assumed that after you have
waited for the WAL from a bulk insertion to arrive, and you run a
cycle of checkpoint and compaction, no new layer files are created.
Because if a new layer file is created while we are calculating the
incremental and non-incremental physical sizes, they might differ.
However, the tests used a very small checkpoint_distance, so even a
small amount of WAL generated in PostgreSQL could cause a new layer
file to be created. Autovacuum can kick in at any time, and do that.
That caused occasional failues in the test. I was able to reproduce it
reliably by adding a long delay between the incremental and
non-incremental size calculations:
```
--- a/pageserver/src/http/routes.rs
+++ b/pageserver/src/http/routes.rs
@@ -129,6 +129,9 @@ async fn build_timeline_info(
}
};
let current_physical_size = Some(timeline.get_physical_size());
+ if include_non_incremental_physical_size {
+ std:🧵:sleep(std::time::Duration::from_millis(60000));
+ }
let info = TimelineInfo {
tenant_id: timeline.tenant_id,
```
To fix, disable autovacuum for the table. Autovacuum could still kick
in for other tables, e.g. catalog tables, but that seems less likely
to generate enough WAL to causea new layer file to be flushed.
If this continues to be a problem in the future, we could simply retry
the physical size call a few times, if there's a mismatch. A mismatch
could happen every once in a while, but it's very unlikely to happen
more than once or twice in a row.
Fixes https://github.com/neondatabase/neon/issues/2212
- Measure size of redo WAL (new histogram), with bounds between 24B-32kB
- Add 2 more buckets at the upper end of the redo time histogram
We often (>0.1% of several hours each day) take more than 250ms to do the
redo round-trip to the postgres process. We need to measure these redo
times more precisely.
We've got at least one user in production that cannot create a
database with a trailing space in the name.
This happens because we use `url` crate for manipulating the
DATABASE_URL, but it follows a standard that doesn't fit really
well with Postgres. For example, it trims all trailing spaces
from the path:
> Remove any leading and trailing C0 control or space from input.
> See: https://url.spec.whatwg.org/#url-parsing
But we used `set_path()` to set database name and it's totally valid
to have trailing spaces in the database name in Postgres.
Thus, use `postgres::config::Config` to modify database name in the
connection details.
* Persists latest_gc_cutoff_lsn before performing GC
* Peform some refactoring and code deduplication
refer #2539
* Add test for persisting GC cutoff
* Fix python test style warnings
* Bump postgres version
* Reduce number of iterations in test_gc_cutoff test
* Bump postgres version
* Undo bumping postgres version
In the Postgres backend, we cannot link directly with libpq (check the
pgsql-hackers arhive for all kinds of fun that ensued when we tried to
do that). Therefore, the libpq functions are used through the thin
wrapper functions in libpqwalreceiver.so, and libpqwalreceiver.so is
loaded dynamically. To hide the dynamic loading and make the calls
look like regular functions, we use macros to hide the function
pointers.
We had inherited the same indirections in libpqwalproposer, but it's
not needed since the neon extension is already a shared library that's
loaded dynamically. There's no problem calling the functions directly
there. Remove the indirections.
Speeds up layer_map::search somewhat. I also opened a PR in the upstream
rust-amplify repository with these changes,
see https://github.com/rust-amplify/rust-amplify/pull/148. We can switch
back to upstream version when that's merged.
Lookups in the R-tree call the "envelope" function for every comparison,
and our envelope function isn't very cheap, so that overhead adds up.
Create the envelope once, when the layer is inserted into the tree, and
store it along with the layer. That uses some more memory per layer, but
that's not very significant.
Speeds up the search operation 2x
This is the first step in verifying layer files. Next up on the road is
hashing the files and verifying the hashes.
The metadata additions do not require any migration. The idea is that
the change is backward and forward-compatible with regard to
`index_part.json` due to the softness of JSON schema and the
deserialization options in use.
New types added:
- LayerFileMetadata for tracking the file metadata
- starting with only the file size
- in future hopefully a sha256 as well
- IndexLayerMetadata, the serialized counterpart of LayerFileMetadata
LayerFileMetadata needing to have all fields Option is a problem but
that is not possible to handle without conflicting a lot more with other
ongoing work.
Co-authored-by: Kirill Bulatov <kirill@neon.tech>
* We had an issue with `lineinfile` usage for pageserver configuration
file: if the S3 bucket related values were changed, it would have
resulted in duplicate keys, resulting in invalid toml.
So to fix the issue, we should keep the configuration in structured
format (yaml in this case) so we can always generate syntactically
correct toml.
Inventories are converted to yaml just so that it's easier to maintain
the configuration there. Another alternative would have been a separate
variable files.
* Keep the ansible collections dir, but locally installed collections
should not be tracked.
* etcd-client is not updated, since we plan to replace it with another client and the new version errors with some missing prost library error
* clap had released another major update that requires changing every CLI declaration again, deserves a separate PR
The 'local' part was always filled in, so that was easy to merge into
into the TimelineInfo itself. 'remote' only contained two fields,
'remote_consistent_lsn' and 'awaits_download'. I made
'remote_consistent_lsn' an optional field, and 'awaits_download' is now
false if the timeline is not present remotely.
However, I kept stub versions of the 'local' and 'remote' structs for
backwards-compatibility, with a few fields that are actively used by
the control plane. They just duplicate the fields from TimelineInfo
now. They can be removed later, once the control plane has been
updated to use the new fields.
It was only None when you queried the status of a timeline with
'timeline_detail' mgmt API call, and it was still being downloaded. You
can check for that status with the 'tenant_status' API call instead,
checking for has_in_progress_downloads field.
Anothere case was if an error happened while trying to get the current
logical size, in a 'timeline_detail' request. It might make sense to
tolerate such errors, and leave the fields we cannot fill in as empty,
None, 0 or similar, but it doesn't make sense to me to leave the whole
'local' struct empty in tht case.
With the ability to pass commit_lsn. This allows to perform project WAL recovery
through different (from the original) set of safekeepers (or under different
ttid) by
1) moving WAL files to s3 under proper ttid;
2) explicitly creating timeline on safekeepers, setting commit_lsn to the
latest point;
3) putting the lastest .parital file to the timeline directory on safekeepers, if
desired.
Extend test_s3_wal_replay to exersise this behaviour.
Also extends timeline_status endpoint to return postgres information.
I'm using the Rust compiler and cargo versions from Debian packages,
but the latest available cargo Debian package is quite old, version
1.57. The 'named-profiles' features was not stabilized at that
version yet, so ever since commit a463749f5, I've had to manually add
this line to the Cargo.toml file to compile. I've been wishing that
someone would update the cargo Debian package, but it doesn't seem to
be happening any time soon.
This doesn't seem to bother anyone else but me, but it shouldn't hurt
anyone else either. If there was a good reason, I could install a
newer cargo version with 'rustup', but if all we need is this one line
in Cargo.toml, I'd prefer to continue using the Debian packages.
You cannot attach/detach an individual timeline, attach/detach always
applies to the whole tenant. However, you can *delete* a single timeline
from a tenant. Fix some comments and error messages that confused these
two operations.
Commit c634cb1d36 removed the trait and changed the function to return
a &TimelineWriter, as the FIXME said we should do, but forgot to remove
the FIXME.
* Test that we emit build info metric for pageserver, safekeeper and proxy with some non-zero length revision label
* Emit libmetrics_build_info on startup of pageserver, safekeeper and
proxy with label "revision" which tells the git revision.
The previous default of 1 s caused excessive CPU usage when there were
a lot of projects. Polling every timeline once a second was too aggressive
so let's reduce it.
Fixes https://github.com/neondatabase/neon/issues/2542, but we
probably also want do to something so that we don't poll timelines
that have received no new WAL or layers since last check.
* Add test for branching on page boundary
* Normalize start recovery point
Co-authored-by: Heikki Linnakangas <heikki@neon.tech>
Co-authored-by: Thang Pham <thang@neon.tech>
We had a problem where almost all of the threads were waiting on a futex syscall. More specifically:
- `/metrics` handler was inside `TimelineCollector::collect()`, waiting on a mutex for a single Timeline
- This exact timeline was inside `control_file::FileStorage::persist()`, waiting on a mutex for Lazy initialization of `PERSIST_CONTROL_FILE_SECONDS`
- `PERSIST_CONTROL_FILE_SECONDS: Lazy<Histogram>` was blocked on `prometheus::register`
- `prometheus::register` calls `DEFAULT_REGISTRY.write().register()` to take a write lock on Registry and add a new metric
- `DEFAULT_REGISTRY` lock was already taken inside `DEFAULT_REGISTRY.gather()`, which was called by `/metrics` handler to collect all metrics
This commit creates another Registry with a separate lock, to avoid deadlock in a case where `TimelineCollector` triggers registration of new metrics inside default registry.
Creates new `pageserver_api` and `safekeeper_api` crates to serve as the
shared dependencies. Should reduce both recompile times and cold compile
times.
Decreases the size of the optimized `neon_local` binary: 380M -> 179M.
No significant changes for anything else (mostly as expected).
Compute node startup time is very important. After launching
PostgreSQL, use 'notify' to be notified immediately when it has
updated the PID file, instead of polling. The polling loop had 100 ms
interval so this shaves up to 100 ms from the startup time.
The loop checked if the TCP port is open for connections, by trying to
connect to it. That seems unnecessary. By the time the postmaster.pid
file says that it's ready, the port should be open. Remove that check.
* Preserve task result in TaskHandle by keeping join handle around
The solution is not great, but it should hep to debug staging issue
I tried to do it in a least destructive way. TaskHandle used only in
one place so it is ok to use something less generic unless we want
to extend its usage across the codebase. In its current current form
for its single usage place it looks too abstract
Some problems around this code:
1. Task can drop event sender and continue running
2. Task cannot be joined several times (probably not needed,
but still, can be surprising)
3. Had to split task event into two types because ahyhow::Error
does not implement clone. So TaskContinueEvent derives clone
but usual task evend does not. Clone requirement appears
because we clone the current value in next_task_event.
Taking it by reference is complicated.
4. Split between Init and Started is artificial and comes from
watch::channel requirement to have some initial value.
To summarize from 3 and 4. It may be a better idea to use
RWLock or a bounded channel instead
Changes are:
* Correct typo "firts" -> "first"
* Change <empty panic with comment explaining> to <panic with message
taken from the comment>
* Fix weird indentation that rustfmt was failing to handle
* Use existing `anyhow::{anyhow,bail}!` as `{anyhow,bail}!` if it's
already in scope
* Spell `Result<T, anyhow::Error>` as `anyhow::Result<T>`
* In general, closer to matching the rest of the codebase
* Change usages of `hash_map::Entry` to `Entry` when it's already in
scope
* A quick search shows our style on this one varies across the files
it's used in
* Fix extreme metrics bloat in storage sync
From 78 metrics per (timeline, tenant) pair down to (max) 10 metrics per
(timeline, tenant) pair, plus another 117 metrics in a global histogram that
replaces the previous per-timeline histogram.
* Drop image sync operation metric series when dropping TimelineMetrics.
- Split postgres_ffi into two version specific files.
- Preserve pg_version in timeline metadata.
- Use pg_version in safekeeper code. Check for postgres major version mismatch.
- Clean up the code to use DEFAULT_PG_VERSION constant everywhere, instead of hardcoding.
- Parameterize python tests: use DEFAULT_PG_VERSION env and pg_version fixture.
To run tests using a specific PostgreSQL version, pass the DEFAULT_PG_VERSION environment variable:
'DEFAULT_PG_VERSION='15' ./scripts/pytest test_runner/regress'
Currently don't all tests pass, because rust code relies on the default version of PostgreSQL in a few places.
Replace the layer array and linear search with R-tree
So far, the in-memory layer map that holds information about layer
files that exist, has used a simple Vec, in no particular order, to
hold information about all the layers. That obviously doesn't scale
very well; with thousands of layer files the linear search was
consuming a lot of CPU. Replace it with a two-dimensional R-tree, with
Key and LSN ranges as the dimensions.
For the R-tree, use the 'rstar' crate. To be able to use that, we
convert the Keys and LSNs into 256-bit integers. 64 bits would be
enough to represent LSNs, and 128 bits would be enough to represent
Keys. However, we use 256 bits, because rstar internally performs
multiplication to calculate the area of rectangles, and the result of
multiplying two 128 bit integers doesn't necessarily fit in 128 bits,
causing integer overflow and, if overflow-checks are enabled,
panic. To avoid that, we use 256 bit integers.
Add a performance test that creates a lot of layer files, to
demonstrate the benefit.
Part of the general work on improving pageserver logs.
Brief summary of changes:
* Remove `ApiError::from_err`
* Remove `impl From<anyhow::Error> for ApiError`
* Convert `ApiError::{BadRequest, NotFound}` to use `anyhow::Error`
* Note: `NotFound` has more verbose formatting because it's more
likely to have useful information for the receiving "user"
* Explicitly convert from `tokio::task::JoinError`s into
`InternalServerError`s where appropriate
Also note: many of the places where errors were implicitly converted to
500s have now been updated to return a more appropriate error. Some
places where it's not yet possible to distinguish the error types have
been left as 500s.
Follow-up to PR #2433 (b8eb908a). There's still a few more unresolved
locations that have been left as-is for the same compatibility reasons
in the original PR.
Commit 43a4f7173e fixed the case that there are extra options in the
connection string, but broke it in the case when there are not. Fix
that. But on second thoughts, it's more straightforward set the
options with ALTER DATABASE, so change the workflow yaml file to do
that instead.
In commit 6985f6cd6c, I tried passing extra GUCs in the 'options' part
of the connection string, but it didn't work because the pgbench test
overrode it with the statement_timeout. Change it so that it adds the
statement_timeout to any other options, instead of replacing them.
* Set last written lsn for created relation
* use current LSN for updating last written LSN of relation metadata
* Update LSN for the extended blocks even for pges without LSN (zeroed)
* Update pgxn/neon/pagestore_smgr.c
Co-authored-by: Heikki Linnakangas <heikki@neon.tech>
Co-authored-by: Heikki Linnakangas <heikki@neon.tech>
Fixes#1873: previously any run of `make` caused the `postgres-v15-headers`
target to build. It copied a bunch of headers via `install -C`. Unfortunately,
some origins were symlinks in the `./pg_install/build` directory pointing
inside `./vendor/postgres-v15` (e.g. `pg_config_os.h` pointing to `linux.h`).
GNU coreutils' `install` ignores the `-C` key for non-regular files and
always overwrites the destination if the origin is a symlink. That in turn
made Cargo rebuild the `postgres_ffi` crate and all its dependencies because
it thinks that Postgres headers changed, even if they did not. That was slow.
Now we use a custom script that wraps the `install` program. It handles one
specific case and makes sure individual headers are never copied if their
content did not change. Hence, `postgres_ffi` is not rebuilt unless there were
some changes to the C code.
One may still have slow incremental single-threaded builds because Postgres
Makefiles spawn about 2800 sub-makes even if no files have been changed.
A no-op build takes "only" 3-4 seconds on my machine now when run with `-j30`,
and 20 seconds when run with `-j1`.
This commit does two things of note:
1. Bumps the bindgen dependency from `0.59.1` to `0.60.1`. This gets us
an actual error type from bindgen, so we can display what's wrong.
2. Adds `anyhow` as a build dependency, so our error message can be
prettier. It's already used heavily elsewhere in the crates in this
repo, so I figured the fact it's a build dependency doesn't matter
much.
I ran into this from running `cargo <cmd>` without running `make` first.
Here's a comparison of the compiler output in those two cases.
Before this commit:
```
error: failed to run custom build command for `postgres_ffi v0.1.0 ($repo_path/libs/postgres_ffi)`
Caused by:
process didn't exit successfully: `$repo_path/target/debug/build/postgres_ffi-2f7253b3ad3ca840/build-script-build` (exit status: 101)
--- stdout
cargo:rerun-if-changed=bindgen_deps.h
--- stderr
bindgen_deps.h:7:10: fatal error: 'c.h' file not found
bindgen_deps.h:7:10: fatal error: 'c.h' file not found, err: true
thread 'main' panicked at 'Unable to generate bindings: ()', libs/postgres_ffi/build.rs:135:14
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
```
After this commit:
```
error: failed to run custom build command for `postgres_ffi v0.1.0 ($repo_path/libs/postgres_ffi)`
Caused by:
process didn't exit successfully: `$repo_path/target/debug/build/postgres_ffi-e01fb59602596748/build-script-build` (exit status: 1)
--- stdout
cargo:rerun-if-changed=bindgen_deps.h
--- stderr
bindgen_deps.h:7:10: fatal error: 'c.h' file not found
Error: Unable to generate bindings
Caused by:
clang diagnosed error: bindgen_deps.h:7:10: fatal error: 'c.h' file not found
```
Also get rid if `with_safekeepers` parameter in tests.
Its meaning has changed: `False` meant "no safekeepers" which is not
supported anymore, so we assume it's always `True`.
See #1648
Previously, we compiled neon separately for Postgres v14 and v15, for
the codestyle checks. But that was bogus; we actually just ran "make
postgres", which always compiled both versions. The version really only
affected the caching.
Fix that, by copying the build steps from the main build_and_test.yml
workflow.
Running "make" at the top level calls "make install" to install the
PostgreSQL headers into the pg_install/ directory. That always updated
the modification time of the headers even if there were no changes,
triggering recompilation of the postgres_ffi bindings. To avoid that,
use 'install -C', to install the PostgreSQL headers.
However, there was an upstream PostgreSQL issue that the
src/include/Makefile didn't respect the INSTALL configure option. That
was just fixed in upstream PostgreSQL, so cherry-pick that fix to our
vendor/postgres repositories.
Fixes https://github.com/neondatabase/neon/issues/1873.
Commit f44afbaf62 updated vendor/postgres-v15 to point to a commit that
was built on top of PostgreSQL 14 rather than 15. So we accidentally had
two copies of PostgreSQL v14 in the repository. Oops. This updates
it to point to the correct version.
* Changes of neon extension to support local prefetch
* Catch exceptions in pageserver_receive
* Bump posgres version
* Bump posgres version
* Bump posgres version
* Bump posgres version
* github/actions: add neon projects related actions
* workflows/benchmarking: create projects using API
* workflows/pg_clients: create projects using API
Instead of spawning helper threads, we now use Tokio tasks. There
are multiple Tokio runtimes, for different kinds of tasks. One for
serving libpq client connections, another for background operations
like GC and compaction, and so on. That's not strictly required, we
could use just one runtime, but with this you can still get an
overview of what's happening with "top -H".
There's one subtle behavior in how TenantState is updated. Before this
patch, if you deleted all timelines from a tenant, its GC and
compaction loops were stopped, and the tenant went back to Idle
state. We no longer do that. The empty tenant stays Active. The
changes to test_tenant_tasks.py are related to that.
There's still plenty of synchronous code and blocking. For example, we
still use blocking std::io functions for all file I/O, and the
communication with WAL redo processes is still uses low-level unix
poll(). We might want to rewrite those later, but this will do for
now. The model is that local file I/O is considered to be fast enough
that blocking - and preventing other tasks running in the same thread -
is acceptable.
We had a pattern like this:
match remote_storage {
GenericRemoteStorage::Local(storage) => {
let source = storage.remote_object_id(&file_path)?;
...
storage
.function(&source, ...)
.await
},
GenericRemoteStorage::S3(storage) => {
... exact same code as for the Local case ...
},
This removes the code duplication, by allowing you to call the functions
directly on GenericRemoteStorage.
Also change RemoveObjectId to be just a type alias for String. Now that
the callers of GenericRemoteStorage functions don't know whether they're
dealing with the LocalFs or S3 implementation, RemoveObjectId must be the
same type for both.
Because the metadata was not locked, it could be updated concurrently
such that we wouldn't actually have the tail block.
The current ordering works better, as we still only start XLogBeginInsert()
once we have all potentially interesting buffers loaded in memory, but
still have correct lock lifetimes.
See also: access/transam/README section Write-Ahead Log Coding
Another preparatory commit for pg15 support:
* generate bindings for both pg14 and pg15;
* update Makefile and CI scripts: now neon build depends on both PostgreSQL versions;
* some code refactoring to decrease version-specific dependencies.
Commit f081419e68 moved all the prometheus counters to `metrics.rs`,
but accidentally replaced a couple of `register_int_counter!(...)`
calls with just `IntCounter::new(...)`. Because of that, the counters
were not registered in the metrics registry, and were not exposed
through the metrics HTTP endpoint.
Fixes failures we're seeing in a bunch of 'performance' tests because
of the missing metrics.
This caught or reproduced several bugs when I originally wrote this test
back in May, including #1731, #1740, #1751, and #707. I believe all the
issues have been fixed now, but since this was a very fruitful test,
let's add it to the test suite.
We didn't commit this earlier, because the test was very slow especially
with a debug build. We've since changed the build options so that even
the debug builds are not quite so slow anymore.
* Add test for pageserver metric cleanup once a tenant is detached.
* Remove tenant specific timeline metrics on detach.
* Use definitions from timeline_metrics in page service.
* Move metrics to own file from layered_repository/timeline.rs
* TIMELINE_METRICS: define smgr metrics
* REMOVE SMGR cleanup from timeline_metrics. Doesn't seem to work as
expected.
* Vritual file centralized metrics, except for evicted file as there's no
tenat id or timeline id.
* Use STORAGE_TIME from timeline_metrics in layered_repository.
* Remove timelineless gc metrics for tenant on detach.
* Rename timeline metrics -> metrics as it's more generic.
* Don't create a TimelineMetrics instance for VirtualFile
* Move the rest of the metric definitions to metrics.rs too.
* UUID -> ZTenantId
* Use consistent style for dict.
* Use Repository's Drop trait for dropping STORAGE_TIME metrics.
* No need for Arc, TimelineMetrics is used in just one place. Due to that,
we can fall back using ZTenantId and ZTimelineId too to avoid additional
string allocation.
* Add submodule postgres-15
* Support pg_15 in pgxn/neon
* Renamed zenith -> neon in Makefile
* fix name of codestyle check
* Refactor build system to prepare for building multiple Postgres versions.
Rename "vendor/postgres" to "vendor/postgres-v14"
Change Postgres build and install directory paths to be version-specific:
- tmp_install/build -> pg_install/build/14
- tmp_install/* -> pg_install/14/*
And Makefile targets:
- "make postgres" -> "make postgres-v14"
- "make postgres-headers" -> "make postgres-v14-headers"
- etc.
Add Makefile aliases:
- "make postgres" to build "postgres-v14" and in future, "postgres-v15"
- similarly for "make postgres-headers"
Fix POSTGRES_DISTRIB_DIR path in pytest scripts
* Make postgres version a variable in codestyle workflow
* Support vendor/postgres-v15 in codestyle check workflow
* Support postgres-v15 building in Makefile
* fix pg version in Dockerfile.compute-node
* fix kaniko path
* Build neon extensions in version-specific directories
* fix obsolete mentions of vendor/postgres
* use vendor/postgres-v14 in Dockerfile.compute-node.legacy
* Use PG_VERSION_NUM to gate dependencies in inmem_smgr.c
* Use versioned ECR repositories and image names for compute-node.
The image name format is compute-node-vXX, where XX is postgres major version number.
For now only v14 is supported.
Old format unversioned name (compute-node) is left, because cloud repo depends on it.
* update vendor/postgres submodule url (zenith->neondatabase rename)
* Fix postgres path in python tests after rebase
* fix path in regress test
* Use separate dockerfiles to build compute-node:
Dockerfile.compute-node-v15 should be identical to Dockerfile.compute-node-v14 except for the version number.
This is a hack, because Kaniko doesn't support build ARGs properly
* bump vendor/postgres-v14 and vendor/postgres-v15
* Don't use Kaniko cache for v14 and v15 compute-node images
* Build compute-node images for different versions in different jobs
Co-authored-by: Heikki Linnakangas <heikki@neon.tech>
* Update relation size cache only when latest LSN is requested
* Fix tests
* Add a test case for timetravel query after pageserver restart.
This test is currently failing, the queries return incorrect results.
I don't know why, needs to be investigated.
FAILED test_runner/batch_others/test_readonly_node.py::test_timetravel - assert 85 == 100000
If you remove the pageserver restart from the test, it passes.
* yapf3 test_readonly_node.py
* Add comment about cache correction in case of setting incorrect latest flag
* Fix formatting for test_readonly_node.py
* Remove unused imports
* Fix mypy warning for test_readonly_node.py
* Fix formatting of test_readonly_node.py
* Bump postgres version
Co-authored-by: Heikki Linnakangas <heikki@neon.tech>
* Fix pythin style
* Fix iport of test_backpressure in test_latency
* Apply changed to moved neon extension
* Apply changed to moved neon extension
* Merge with main
* Update pgxn/neon/pagestore_smgr.c
Co-authored-by: Heikki Linnakangas <heikki@zenith.tech>
* Bump postgres version
Co-authored-by: Heikki Linnakangas <heikki@zenith.tech>
* Move backpressure throttling implementation to neon extension and function for monitoring throttling time
* Add missing includes
* Bump postgres version
Seems a bit silly to have a separate crate just for the executable. It
relies on the control plane for everything it does, and it's the only
user of the control plane.
Slim down compute-node images:
- Optimize compute_ctl build for size, not performance & debug-ability
- Don't run unused stages. Saves time in not building the PLV8 extension.
- Do not include static libraries in clean postgres
- Do the installation and finishing touches in the final layer in one job
This allows docker (and kaniko) to only register one change to the files,
removing potentially duplicate changed files.
- The runtime library for libreadline-dev is libreadline8, changing the dependency saves 45 MB
- libprotobuf-c-dev -> libprotobuf-c1, saving 100 kB
- libossp-uuid-dev -> libossp-uuid16, saving 150 kB
- gdal-bin + libgdal-dev -> libgeos-c1v5 + libgdal28 + libproj19, saving 747MB
- binutils @ testing -> libc6 @ testing, saving 32 MB
Start the calculation on the first size request, return
partially calculated size during calculation, retry if failed.
Remove "fast" size init through the ancestor: the current approach is
fast enough for now and there are better ways to optimize the
calculation via incremental ancestor size computation
For better ergonomics. I always found it weird that we used UUID to
actually mean a tenant or timeline ID. It worked because it happened
to have the same length, 16 bytes, but it was hacky.
Update PLV8 to 3.1.4 - which is the latest release.
Update PostGIS to 3.3.0
Remove PLV8 from the final image -- there is an issue we hit when installing PLV8, and we don't quite know what it is yet.
The code correctly detected too short and too long inputs, but the error
message was bogus for the case the input stream was too long:
Error: Provided stream has actual size 5 fthat is smaller than the given stream size 4
That check was only supposed to check for too small inputs, but it in
fact caught too long inputs too. That was good, because the check
below that that was supposed to check for too long inputs was in fact
broken, and never did anything. It tried to read input a buffer of
size 0, to check if there is any extra data, but reading to a
zero-sized buffer always returns 0.
Merge batch_others and batch_pg_regress. The original idea was to
split all the python tests into multiple "batches" and run each batch
in parallel as a separate CI job. However, the batch_pg_regress batch
was pretty short compared to all the tests in batch_others. We could
split batch_others into multiple batches, but it actually seems better
to just treat them as one big pool of tests and use pytest's handle
the parallelism on its own. If we need to split them across multiple
nodes in the future, we could use pytest-shard or something else,
instead of managing the batches ourselves.
Merge test_neon_regress.py, test_pg_regress.py and test_isolation.py
into one file, test_pg_regress.py. Seems more clear to group all
pg_regress-based tests into one file, now that they would all be in
the same directory.
Previously, proxy didn't forward auxiliary `options` parameter
and other ones to the client's compute node, e.g.
```
$ psql "user=john host=localhost dbname=postgres options='-cgeqo=off'"
postgres=# show geqo;
┌──────┐
│ geqo │
├──────┤
│ on │
└──────┘
(1 row)
```
With this patch we now forward `options`, `application_name` and `replication`.
Further reading: https://www.postgresql.org/docs/current/libpq-connect.htmlFixes#1287.
* Add fork_at_current_lsn function which creates branch at current LSN
* Undo use of fork_at_current_lsn in test_branching because of short GC period
* Add missed return in fork_at_current_lsn
* Add missed return in fork_at_current_lsn
* Update test_runner/fixtures/neon_fixtures.py
Co-authored-by: Heikki Linnakangas <heikki@zenith.tech>
* Update test_runner/fixtures/neon_fixtures.py
Co-authored-by: Heikki Linnakangas <heikki@zenith.tech>
* Update test_runner/fixtures/neon_fixtures.py
Co-authored-by: Heikki Linnakangas <heikki@zenith.tech>
Co-authored-by: Heikki Linnakangas <heikki@zenith.tech>
`latest_gc_cutoff_lsn` tracks the cutoff point where GC has been
performed. Anything older than the cutoff might already have been GC'd
away, and cannot be queried by get_page_at_lsn requests. It's
protected by an RWLock. Whenever a get_page_at_lsn requests comes in,
it first grabs the lock and reads the current `latest_gc_cutoff`, and
holds the lock it until the request has been served. The lock ensures
that GC doesn't start concurrently and remove page versions that we
still need to satisfy the request.
With the lock, get_page_at_lsn request could potentially be blocked
for a long time. GC only holds the lock in exclusive mode for a short
duration, but depending on how whether the RWLock is "fair", a read
request might be queued behind the GC's exclusive request, which in
turn might be queued behind a long-running read operation, like a
basebackup. If the lock implementation is not fair, i.e. if a reader
can always jump the queue if the lock is already held in read mode,
then another problem arises: GC might be starved if a constant stream
of GetPage requests comes in.
To avoid the long wait or starvation, introduce a Read-Copy-Update
mechanism to replace the lock on `latest_gc_cutoff_lsn`. With the RCU,
reader can always read the latest value without blocking (except for a
very short duration if the lock protecting the RCU is contended;
that's comparable to a spinlock). And a writer can always write a new
value without waiting for readers to finish using the old value. The
old readers will continue to see the old value through their guard
object, while new readers will see the new value.
This is purely theoretical ATM, we don't have any reports of either
starvation or blocking behind GC happening in practice. But it's
simple to fix, so let's nip that problem in the bud.
It's used by e2e CI. Building Dockerfile.compute-node will take
unreasonable ammount of time without v2 runners.
TODO: remove once cloud repo CI is moved to v2 runners.
* Extract neon and neon_test_utils from postgres repo
* Remove neon from vendored postgres repo, and fix build_and_test.yml
* Move EmitWarningsOnPlaceholders to end of _PG_init in neon.c (from libpagestore.c)
* Fix Makefile location comments
* remove Makefile EXTRA_INSTALL flag
* Update Dockerfile.compute-node to build and include the neon extension
Previously, it could only distinguish REDO task durations down to 5ms, which
equates to approx. 200pages/sec or 1.6MB/sec getpage@LSN traffic.
This patch improves to 200'000 pages/sec or 1.6GB/sec, allowing for
much more precise performance measurement of the redo process.
* Add postgis & plv8 extensions
* Update Dockerfile & Fix typo's
* Update dockerfile
* Update Dockerfile
* Update dockerfile
* Use plv8 step
* Reduce giga layer
* Reduce layer size further
* Prepare for rollout
* Fix dependency
* Pass on correct build tag
* No longer dependent on building tools
* Use version from vendor
* Revert "Use version from vendor"
This reverts commit 7c6670c477.
* Revert and push correct set
* Add configure step for new approach
* Re-add configure flags
Co-authored-by: Rory de Zoete <rdezoete@RorysMacStudio.fritz.box>
Co-authored-by: Rory de Zoete <rdezoete@Rorys-Mac-Studio.fritz.box>
`///` is used for comments on the *next* code that follows, so the comment
actually applied to the `use std::collections::BTreeMap;` line that follows.
rustfmt complained about that:
error: an inner attribute is not permitted following an outer doc comment
--> /home/heikki/git-sandbox/neon/libs/utils/src/seqwait_async.rs:7:1
|
5 | ///
| --- previous doc comment
6 |
7 | #![warn(missing_docs)]
| ^^^^^^^^^^^^^^^^^^^^^^ not permitted following an outer attribute
8 |
9 | use std::collections::BTreeMap;
| ------------------------------- the inner attribute doesn't annotate this `use` import
|
= note: inner attributes, like `#![no_std]`, annotate the item enclosing them, and are usually found at the beginning of source files
help: to annotate the `use` import, change the attribute from inner to outer style
|
7 - #![warn(missing_docs)]
7 + #[warn(missing_docs)]
|
`//!` is the correct syntax for comments that apply to the whole file.
Every handler function now follows the same pattern:
1. extract parameters from the call
2. check permissions
3. execute command.
Previously, we extracted some parameters before permission check and
some after. Let's be consistent.
Added pytest to check correctness of the link authentication pipeline.
Context: this PR is the first step towards refactoring the link authentication pipeline to use https (instead of psql) to send the db info to the proxy. There was a test missing for this pipeline in this repo, so this PR adds that test as preparation for the actual change of psql -> https.
Co-authored-by: Bojan Serafimov <bojan.serafimov7@gmail.com>
Co-authored-by: Dmitry Rodionov <dmitry@neon.tech>
Co-authored-by: Stas Kelvic <stas@neon.tech>
Co-authored-by: Dimitrii Ivanov <dima@neon.tech>
There was a nominal split between the tests in layered_repository.rs and
repository.rs, such that tests specific to the layered implementation were
supposed to be in layered_repository.rs, and tests that should work with
any implementation of the traits were supposed to be in repository.rs.
In practice, the line was quite muddled. With minor tweaks, many of the
tests in layered_repository.rs should work with other implementations too,
and vice versa. And in practice we only have one implementation, so it's
more straightforward to gather all unit tests in one place.
usize/isize type corresponds to the CPU architecture's pointer width,
i.e. 64 bits on a 64-bit platform and 32 bits on a 32-bit platform.
The logical size of a database has nothing to do with the that, so
u64/i64 is more appropriate.
It doesn't make any difference in practice as long as you're on a
64-bit platform, and it's hard to imagine anyone wanting to run the
pageserver on a 32-bit platform, but let's be tidy.
Also add a comment on why we use signed i64 for the logical size
variable, even though size should never be negative. I'm not sure the
reasons are very good, but at least this documents them, and hints at
some possible better solutions.
* Update workflow to fix dependency issue
* Update workflow
* Update workflow and dockerfile
* Specify tag
* Update main dockerfile as well
* Mirror rust image to docker hub
* Update submodule ref
Co-authored-by: Rory de Zoete <rdezoete@Rorys-Mac-Studio.fritz.box>
Compute node docker image requires compute-tools to build, but this
dependency (and the argument for which image to pick) weren't described in the
workflow file. This lead to out-of-date binaries in latest builds, which
subsequently broke these images.
Including, but not limited to:
* Fixes to neon management code to support walproposer-as-an-extension
* Fix issue in expected output of pg settings serialization.
* Show the logs of a failed --sync-safekeepers process in CI
* Add compat layer for renamed GUCs in postgres.conf
* Update vendor/postgres to the latest origin/main
- There was an issue with zero commit_lsn `reason: LaggingWal { current_commit_lsn: 0/0, new_commit_lsn: 1/6FD90D38, threshold: 10485760 } }`. The problem was in `send_wal.rs`, where we initialized `end_pos = Lsn(0)` and in some cases sent it to the pageserver.
- IDENTIFY_SYSTEM previously returned `flush_lsn` as a physical end of WAL. Now it returns `flush_lsn` (as it was) to walproposer and `commit_lsn` to everyone else including pageserver.
- There was an issue with backoff where connection was cancelled right after initialization: `connected!` -> `safekeeper_handle_db: Connection cancelled` -> `Backoff: waiting 3 seconds`. The problem was in sleeping before establishing the connection. This is fixed by reworking retry logic.
- There was an issue with getting `NoKeepAlives` reason in a loop. The issue is probably the same as the previous.
- There was an issue with filtering safekeepers based on retry attempts, which could filter some safekeepers indefinetely. This is fixed by using retry cooldown duration instead of retry attempts.
- Some `send_wal.rs` connections failed with errors without context. This is fixed by adding a timeline to safekeepers errors.
New retry logic works like this:
- Every candidate has a `next_retry_at` timestamp and is not considered for connection until that moment
- When walreceiver connection is closed, we update `next_retry_at` using exponential backoff, increasing the cooldown on every disconnect.
- When `last_record_lsn` was advanced using the WAL from the safekeeper, we reset the retry cooldown and exponential backoff, allowing walreceiver to reconnect to the same safekeeper instantly.
Re-export only things that are used by other modules.
In the future, I'm imagining that we run bindgen twice, for Postgres
v14 and v15. The two sets of bindings would go into separate
'bindings_v14' and 'bindings_v15' modules.
Rearrange postgres_ffi modules.
Move function, to avoid Postgres version dependency in timelines.rs
Move function to generate a logical-message WAL record to postgres_ffi.
* Do not create initial tenant and timeline (adjust Python tests for that)
* Rework config handling during init, add --update-config to manage local config updates
The pg_control_ffi.h name implies that it only includes stuff related to
pg_control.h. That's mostly true currently, but really the point of the
file is to include everything that we need to generate Rust definitions
from.
* Use main, not branch for ref check
* Add more debug
* Count main, not head
* Try new approach
* Conform to syntax
* Update approach
* Get full history
* Skip checkout
* Cleanup debug
* Remove more debug
Co-authored-by: Rory de Zoete <rdezoete@RorysMacStudio.fritz.box>
This patch makes walreceiver logic more complicated, but it should work better in most cases. Added `test_wal_lagging` to test scenarios where alive safekeepers can lag behind other alive safekeepers.
- There was a bug which looks like `etcd_info.timeline.commit_lsn > Some(self.local_timeline.get_last_record_lsn())` filtered all safekeepers in some strange cases. I removed this filter, it should probably help with #2237
- Now walreceiver_connection reports status, including commit_lsn. This allows keeping safekeeper connection even when etcd is down.
- Safekeeper connection now fails if pageserver doesn't receive safekeeper messages for some time. Usually safekeeper sends messages at least once per second.
- `LaggingWal` check now uses `commit_lsn` directly from safekeeper. This fixes the issue with often reconnects, when compute generates WAL really fast.
- `NoWalTimeout` is rewritten to trigger only when we know about the new WAL and the connected safekeeper doesn't stream any WAL. This allows setting a small `lagging_wal_timeout` because it will trigger only when we observe that the connected safekeeper has stuck.
The new format has a few benefits: it's shorter, simpler and
human-readable as well. We don't use base64 anymore, since
url encoding got us covered.
We also show a better error in case we couldn't parse the
payload; the users should know it's all about passing the
correct project name.
This test failed consistently on `main` now. It's better to temporarily disable it to avoid blocking others' PRs while investigating the root cause for the test failure.
See: #2255, #2256
Resolves#2212.
- use `wait_for_last_flush_lsn` in `test_timeline_physical_size_*` tests
## Context
Need to wait for the pageserver to catch up with the compute's last flush LSN because during the timeline physical size API call, it's possible that there are running `LayerFlushThread` threads. These threads flush new layers into disk and hence update the physical size. This results in a mismatch between the physical size reported by the API and the actual physical size on disk.
### Note
The `LayerFlushThread` threads are processed **concurrently**, so it's possible that the above error still persists even with this patch. However, making the tests wait to finish processing all the WALs (not flushing) before calculating the physical size should help reduce the "flakiness" significantly
Resolves#2097
- use timeline modification's `lsn` and timeline's `last_record_lsn` to determine the corresponding LSN to query data in `DatadirModification::get`
- update `test_import_from_pageserver`. Split the test into 2 variants: `small` and `multisegment`.
+ `small` is the old test
+ `multisegment` is to simulate #2097 by using a larger number of inserted rows to create multiple segment files of a relation. `multisegment` is configured to only run with a `release` build
To flush inmemory layer eventually when no new data arrives, which helps
safekeepers to suspend activity (stop pushing to the broker). Default 10m should
be ok.
This script can be used to migrate a tenant across breaking storage versions, or (in the future) upgrading postgres versions. See the comment at the top for an overview.
Co-authored-by: Anastasia Lubennikova <anastasia@neon.tech>
A fair amount of the time in our python tests is spent waiting for the
pageserver and safekeeper processes to shut down. It doesn't matter so
much when you're running a lot of tests in parallel, but it's quite
noticeable when running them sequentially.
A big part of the slowness is that is that after sending the SIGTERM
signal, we poll to see if the process is still running, and the
polling happened at 1 s interval. Reduce it to 0.1 s.
Newer version of mypy fixes buggy error when trying to update only boto3 stubs.
However it brings new checks and starts to yell when we index into
cusror.fetchone without checking for None first. So this introduces a wrapper
to simplify quering for scalar values. I tried to use cursor_factory connection
argument but without success. There can be a better way to do that,
but this looks the simplest
Move all the fields that were returned by the wal_receiver endpoint into
timeline_detail. Internally, move those fields from the separate global
WAL_RECEIVERS hash into the LayeredTimeline struct. That way, all the
information about a timeline is kept in one place.
In the passing, I noted that the 'thread_id' field was removed from
WalReceiverEntry in commit e5cb727572, but it forgot to update
openapi_spec.yml. This commit removes that too.
It failed in staging environment a few times, and all we got in the
logs was:
ERROR could not start the compute node: failed to get basebackup@0/2D6194F8 from pageserver host=zenith-us-stage-ps-2.local port=6400
giving control plane 30s to collect the error before shutdown
That's missing all the detail on *why* it failed.
What the WAL receiver really connects to is the safekeeper. The
"producer" term is a bit misleading, as the safekeeper doesn't produce
the WAL, the compute node does.
This change also applies to the name of the field used in the mgmt API
in in the response of the
'/v1/tenant/:tenant_id/timeline/:timeline_id/wal_receiver' endpoint.
AFAICS that's not used anywhere else than one python test, so it
should be OK to change it.
Ref #1902.
- Track the layered timeline's `physical_size` using `pageserver_current_physical_size` metric when updating the layer map.
- Report the local timeline's `physical_size` in timeline GET APIs.
- Add `include-non-incremental-physical-size` URL flag to also report the local timeline's `physical_size_non_incremental` (similar to `logical_size_non_incremental`)
- Add a `UIntGaugeVec` and `UIntGauge` to represent `u64` prometheus metrics
Co-authored-by: Dmitry Rodionov <dmitry@neon.tech>
Previously DatadirTimeline was a separate struct, and there was a 1:1
relationship between each DatadirTimeline and LayeredTimeline. That was
a bit awkward; whenever you created a timeline, you also needed to create
the DatadirTimeline wrapper around it, and if you only had a reference
to the LayeredTimeline, you would need to look up the corresponding
DatadirTimeline struct through tenant_mgr::get_local_timeline_with_load().
There were a couple of calls like that from LayeredTimeline itself.
Refactor DatadirTimeline, so that it's a trait, and mark LayeredTimeline
as implementing that trait. That way, there's only one object,
LayeredTimeline, and you can call both Timeline and DatadirTimeline
functions on that. You can now also call DatadirTimeline functions from
LayeredTimeline itself.
I considered just moving all the functions from DatadirTimeline directly
to Timeline/LayeredTimeline, but I still like to have some separation.
Timeline provides a simple key-value API, and handles durably storing
key/value pairs, and branching. Whereas DatadirTimeline is stateless, and
provides an abstraction over the key-value store, to present an interface
with relations, databases, etc. Postgres concepts.
This simplified the logical size calculation fast-path for branch
creation, introduced in commit 28243d68e6. LayerTimeline can now
access the ancestor's logical size directly, so it doesn't need the
caller to pass it to it. I moved the fast-path to init_logical_size()
function itself. It now checks if the ancestor's last LSN is the same
as the branch point, i.e. if there haven't been any changes on the
ancestor after the branch, and copies the size from there. An
additional bonus is that the optimization will now work any time you
have a branch of another branch, with no changes from the ancestor,
not only at a create-branch command.
The layered_repository.rs file had grown to be very large. Split off
the LayeredTimeline struct and related code to a separate source file to
make it more manageable.
There are plans to move much of the code to track timelines from
tenant_mgr.rs to LayeredRepository. That will make layered_repository.rs
grow again, so now is a good time to split it.
There's a lot more cleanup to do, but this commit intentionally only
moves existing code and avoids doing anything else, for easier review.
[proxy] Add the `password hack` authentication flow
This lets us authenticate users which can use neither
SNI (due to old libpq) nor connection string `options`
(due to restrictions in other client libraries).
Note: `PasswordHack` will accept passwords which are not
encoded in base64 via the "password" field. The assumption
is that most user passwords will be valid utf-8 strings,
and the rest may still be passed via "password_".
## Overview
This patch reduces the number of memory allocations when running the page server under a heavy write workload. This mostly helps improve the speed of WAL record ingestion.
## Changes
- modified `DatadirModification` to allow reuse the struct's allocated memory after each modification
- modified `decode_wal_record` to allow passing a `DecodedWALRecord` reference. This helps reuse the struct in each `decode_wal_record` call
- added a reusable buffer for serializing object inside the `InMemoryLayer::put_value` function
- added a performance test simulating a heavy write workload for testing the changes in this patch
### Semi-related changes
- remove redundant serializations when calling `DeltaLayer::put_value` during `InMemoryLayer::write_to_disk` function call [1]
- removed the info span `info_span!("processing record", lsn = %lsn)` during each WAL ingestion [2]
## Notes
- [1]: in `InMemoryLayer::write_to_disk`, a deserialization is called
```
let val = Value::des(&buf)?;
delta_layer_writer.put_value(key, *lsn, val)?;
```
`DeltaLayer::put_value` then creates a serialization based on the previous deserialization
```
let off = self.blob_writer.write_blob(&Value::ser(&val)?)?;
```
- [2]: related: https://github.com/neondatabase/neon/issues/733
* More precisely control size of inmem layer
* Force recompaction of L0 layers if them contains large non-wallogged BLOBs to avoid too large layers
* Add modified version of test_hot_update test (test_dup_key.py) which should generate large layers without large number of tables
* Change test name in test_dup_key
* Add Layer::get_max_key_range function
* Add layer::key_iter method and implement new approach of splitting layers during compaction based on total size of all key values
* Add test_large_schema test for checking layer file size after compaction
* Make clippy happy
* Restore checking LSN distance threshold for checkpoint in-memory layer
* Optimize stoage keys iterator
* Update pageserver/src/layered_repository.rs
Co-authored-by: Heikki Linnakangas <heikki@zenith.tech>
* Update pageserver/src/layered_repository.rs
Co-authored-by: Heikki Linnakangas <heikki@zenith.tech>
* Update pageserver/src/layered_repository.rs
Co-authored-by: Heikki Linnakangas <heikki@zenith.tech>
* Update pageserver/src/layered_repository.rs
Co-authored-by: Heikki Linnakangas <heikki@zenith.tech>
* Update pageserver/src/layered_repository.rs
Co-authored-by: Heikki Linnakangas <heikki@zenith.tech>
* Fix code style
* Reduce number of tables in test_large_schema to make it fit in timeout with debug build
* Fix style of test_large_schema.py
* Fix handlng of duplicates layers
Co-authored-by: Heikki Linnakangas <heikki@zenith.tech>
We were getting a warning like this from the pg_regress tests:
=================== warnings summary ===================
/usr/lib/python3/dist-packages/_pytest/config/__init__.py:663
/usr/lib/python3/dist-packages/_pytest/config/__init__.py:663: PytestAssertRewriteWarning: Module already imported so cannot be rewritten: fixtures.pg_stats
self.import_plugin(import_spec)
-- Docs: https://docs.pytest.org/en/stable/warnings.html
------------------ Benchmark results -------------------
To fix, reorder the imports in conftest.py. I'm not sure what exactly
the problem was or why the order matters, but the warning is gone and
that's good enough for me.
If the WAL arrives at the pageserver slowly, it's possible that the
branch is created before all the data on the parent branch have
arrived. That results in a failure:
test_runner/batch_others/test_tenant_relocation.py:259: in test_tenant_relocation
timeline_id_second, current_lsn_second = populate_branch(pg_second, create_table=False, expected_sum=1001000)
test_runner/batch_others/test_tenant_relocation.py:133: in populate_branch
assert cur.fetchone() == (expected_sum, )
E assert (500500,) == (1001000,)
E At index 0 diff: 500500 != 1001000
E Full diff:
E - (1001000,)
E + (500500,)
To fix, specify the LSN to branch at, so that the pageserver will wait
for it arrive.
See https://github.com/neondatabase/neon/issues/2063
Resolves#2054
**Context**: branch creation needs to wait for GC to acquire `gc_cs` lock, which prevents creating new timelines during GC. However, because individual timeline GC iteration also requires `compaction_cs` lock, branch creation may also need to wait for compactions of multiple timelines. This results in large latency when creating a new branch, which we advertised as *"instantly"*.
This PR optimizes the latency of branch creation by separating GC into two phases:
1. Collect GC data (branching points, cutoff LSNs, etc)
2. Perform GC for each timeline
The GC bottleneck comes from step 2, which must wait for compaction of multiple timelines. This PR modifies the branch creation and GC functions to allow GC to hold the GC lock only in step 1. As a result, branch creation doesn't need to wait for compaction to finish but only needs to wait for GC data collection step, which is fast.
Simplifies the workflow. Makes the overall build a little faster, as
the build_postgres step doesn't need to upload the pg.tgz artifact,
and the build_neon step doesn't need to download it again.
This effectively reverts commit a490f64a68. That commit changed the
workflow so that the Postgres binaries were not included in the
neon.tgz artifact. With this commit, the pg.tgz artifact is gone, and
the Postgres binaries are part of neon.tgz again.
The "cargo metadata" and "cargo test --no-run" are used in the workflow
to just list names of the final binaries, but unless the same cargo
options like --release or --debug are used in those calls, they will in
fact recompile everything.
Reorganize existing READMEs and other documentation files into mdbook
format. The resulting Table of Contents is a mix of placeholders for
docs that we should write, and documentation files that we already had,
dropped into the most appropriate place.
Update the Pageserver overview diagram. Add sections on thread
management and WAL redo processes.
Add all the RFCs to the mdbook Table of Content too.
Per github issue #1979
On ProposerElected message receival WAL is truncated at streaming point; this
code expected that, once vote is given for the proposer / term switch happened,
flush_lsn can be advanced only by this proposer (or higher one). However, that
didn't take into account possibility of accumulating written WAL and flushing it
after vote is given -- flushing goes without term checks. Which eventually led
to the violation in question.
ref #2048
* Deduce `last_segment` automatically
* Get rid of local `wal_dir`/`wal_seg_size` variables
* Prepare to test parsing of WAL from multiple specific points, not just the start;
extract `check_end_of_wal` function to check both partial and non-partial WAL segments.
neon.tgz artifact in the github workflow included the contents of
'tmp_install', but that seems pointless, because the same files are
included earlier already in the pg.tgz artifact.
Uploading large artifacts is slow in github actions. To speed that up,
make the artifact smaller.
The code coverage tool doesn't require debug symbols, so remove them.
We've discussed doing the same for *all* binaries, but it's nice to
have debugging symbols for debugging purposes, and so that you get
more complete stack traces. The discussion is ongoing, but let's at
least do this for the test symbols now.
- Updated dependencies with "cargo update"
- Updated workspace_hack with "cargo hakari generate"
There's no particular reason to do this now, just a periodic refresh.
"cargo clippy" started to complain about these, after running "cargo
update". Not sure why it didn't complain before, but seems reasonable to
fix these. (The "cargo update" is not included in this commit)
Change the build options to enable basic optimizations even in debug
mode, and always build dependencies with more optimizations. That
makes the debug-mode binaries somewhat faster, without messing up
stack traces and line-by-line debugging too much.
See https://docs.github.com/en/actions/using-workflows/workflow-syntax-for-github-actions#concurrency
* Previously there was a single concurrency group per each branch.
As the `main` branch got pushed into frequently, very few commits got
tested to the end. It resulted in "broken" `main` branch as there were
no fully successful workflow runs.
Now the `main` branch gets a separate concurrency group for each commit.
* As GitHub Actions syntax does not have the conditional operator, it is
emulated via logical and/or operations. Although undocumented, they
return one of their operands instead of plain true/false.
* Replace 3-space indentation with 2-space indentation while we are here
to be consistent with the rest of the file.
* Wait for all computes (except one) to complete before proceeding with
the single compute.
* It previously waited for too few seconds. As the test is randomized, it was
not failing all the time, but only in specific unlucky cases.
E.g. when there were no successfuly queries by concurrent computes,
and the single node had big timeouts and spent lots of time making the
transaction.
See https://github.com/neondatabase/neon/runs/7234456482?check_suite_focus=true
(around line 980).
* Wait for exactly one extra transaction by the single compute.
We need both storage **and** compute images for deploy, because control plane
picks the compute version based on the storage version. If it notices a fresh
storage it may bump the compute version. And if compute image failed to build
it may break things badly.
Before this patch, importing a physical backup followed the same path
as ingesting any WAL records:
1. All the data pages from the backup are first collected in the
DatadirModification object.
2. Then, they are "committed" to the Repository. They are written to
the in-memory layer
3. Finally, the in-memory layer is frozen, and flushed to disk as a
L0 delta layer file.
This was pretty inefficient. In step 1, the whole physical backup was
held in memory. If the backup is large, you simply run out of
memory. And in step 3, the resulting L0 delta layer file is large,
holding all the data again. That's a problem if the backup is larger
than 5 GB: Amazon S3 doesn't allow uploading files larger than 5 GB
(without using multi-part upload, see github issue #1910). So we want
to avoid that.
To alleviate those problems, optimize the codepath for importing a
physical backup. The basic flow is the same as before, but step 1
is optimized so that it doesn't accumulate all the data in memory,
and step 3 writes the data in image layers instead of one large delta
layer.
Previously, upon branching, if no starting LSN is specified, we
determine the start LSN based on the source timeline's last record LSN
in `timelines::create_timeline` function, which then calls `Repository::branch_timeline`
to create the timeline.
Inside the `LayeredRepository::branch_timeline` function, to start branching,
we try to acquire a GC lock to prevent GC from removing data needed
for the new timeline. However, a GC iteration takes time, so the GC lock
can be held for a long period of time. As a result, the previously determined
starting LSN can become invalid because of GC.
This PR fixes the above issue by delaying the LSN calculation part and moving it to be
inside `LayeredRepository::branch_timeline` function.
* ensure_server_config() function is added to ensure the server does not have background processes
which intervene with WAL generation
* Rework command line syntax
* Add `print-postgres-config` subcommand which prints the required server configuration
download operations of all timelines for one tenant are now grouped
together so when attach is invoked pageserver downloads all of them
and registers them in a single apply_sync_status_update call so
branches can be used safely with attach/detach
I noticed that the pageserver has a very large virtual memory size,
several GB, even though it doesn't actually use that much
memory. That's not much of a problem normally, but I hit it because I
wanted to run tests with a limited virtual memory size, by calling
setrlimit(RLIMIT_AS), but the highest limit you can set is 2 GB. I was
not able to start pageserver with a limit of 2 GB.
On Linux, each thread allocates 32 MB of virtual memory. I read this
on some random forum on the Internet, but unfortunately could not find
the source again now. Empirically, reducing the number of threads clearly
helps to bring down the virtual memory size.
Aside from the virtual memory usage, it seems excessive to launch 40
threads in both of those thread pools. The tokio default is to have as
many worker threads as there are CPU cores in the system. That seems
like a fine heuristic for us, too, so remove the explicit setting of
the pool size and rely on the default. Note that the GC and compaction
tasks are actually run with tokio spawn_blocking, so the threads that
are actually doing the work, and possibly waiting on I/O, are not
consuming threads from the thread pool. The WAL receiver work is done
in the tokio worker threads, but the WAL receivers are more CPU bound
so that seems OK.
Also remove the explicit maxinum on blocking tasks. I'm not sure what
the right value for that would be, or whether the value we set (100)
would be better than the tokio default (512). Since the value was
arbitrary, let's just rely on the tokio default for that, too.
**NB: this PR must be merged only by 'Create a merge commit'!**
### Checklist when preparing for release
- [ ] Read or refresh [the release flow guide](https://github.com/neondatabase/cloud/wiki/Release:-general-flow)
- [ ] Ask in the [cloud Slack channel](https://neondb.slack.com/archives/C033A2WE6BZ) that you are going to rollout the release. Any blockers?
- [ ] Does this release contain any db migrations? Destructive ones? What is the rollback plan?
<!-- List everything that should be done**before** release, any issues / setting changes / etc -->
### Checklist after release
- [ ] Based on the merged commits write release notes and open a PR into `website` repo ([example](https://github.com/neondatabase/website/pull/219/files))
# The path includes a test name (test_create_snapshot) and directory that the test creates (compatibility_snapshot_pg14), keep the path in sync with the test
# This file is only read when `yapf` is run from this directory.
# Hence we only top-level directories here to avoid confusion.
# See source code for the exact file format: https://github.com/google/yapf/blob/c6077954245bc3add82dafd853a1c7305a6ebd20/yapf/yapflib/file_resources.py#L40-L43
storage_broker={version="0.1",path="./storage_broker/"}# Note: main broker code is inside the binary crate, so linking with the library shouldn't be heavy.
Neon is a serverless opensource alternative to AWS Aurora Postgres. It separates storage and compute and substitutes PostgreSQL storage layer by redistributing data across a cluster of nodes.
The project used to be called "Zenith". Many of the commands and code comments
still refer to "zenith", but we are in the process of renaming things.
Neon is a serverless open-source alternative to AWS Aurora Postgres. It separates storage and compute and substitutes the PostgreSQL storage layer by redistributing data across a cluster of nodes.
## Quick start
[Join the waitlist](https://neon.tech/) for our freetier to receive your serverless postgres instance. Then connect to it with your preferred postgres client (psql, dbeaver, etc) or use the online SQL editor.
Try the [Neon Free Tier](https://neon.tech/docs/introduction/technical-preview-free-tier/) to create a serverless Postgres instance. Then connect to it with your preferred Postgres client (psql, dbeaver, etc) or use the online [SQL Editor](https://neon.tech/docs/get-started-with-neon/query-with-neon-sql-editor/). See [Connect from any application](https://neon.tech/docs/connect/connect-from-any-app/) for connection instructions.
Alternatively, compile and run the project [locally](#running-local-installation).
## Architecture overview
A Neon installation consists of compute nodes and Neon storage engine.
A Neon installation consists of compute nodes and the Neon storage engine. Compute nodes are stateless PostgreSQL nodes backed by the Neon storage engine.
Compute nodes are stateless PostgreSQL nodes, backed by Neon storage engine.
The Neon storage engine consists of two major components:
- Pageserver. Scalable storage backend for the compute nodes.
- Safekeepers. The safekeepers form a redundant WAL service that received WAL from the compute node, and stores it durably until it has been processed by the pageserver and uploaded to cloud storage.
Neon storage engine consists of two major components:
- Pageserver. Scalable storage backend for compute nodes.
- WAL service. The service that receives WAL from compute node and ensures that it is stored durably.
Pageserver consists of:
- Repository - Neon storage implementation.
- WAL receiver - service that receives WAL from WAL service and stores it in the repository.
- Page service - service that communicates with compute nodes and responds with pages from the repository.
- WAL redo - service that builds pages from base images and WAL records on Page service request.
See developer documentation in [/docs/SUMMARY.md](/docs/SUMMARY.md) for more information.
## Running local installation
#### Installing dependencies on Linux
1. Install build dependencies and other useful packages
1. Install build dependencies and other applicable packages
* On Ubuntu or Debian this set of packages should be sufficient to build the code:
* On Ubuntu or Debian, this set of packages should be sufficient to build the code:
The project uses [rust toolchain file](./rust-toolchain.toml) to define the version it's built with in CI for testing and local builds.
This file is automatically picked up by [`rustup`](https://rust-lang.github.io/rustup/overrides.html#the-toolchain-file) that installs (if absent) and uses the toolchain version pinned in the file.
rustup users who want to build with another toolchain can use [`rustup override`](https://rust-lang.github.io/rustup/overrides.html#directory-overrides) command to set a specific toolchain for the project's directory.
non-rustup users most probably are not getting the same toolchain automatically from the file, so are responsible to manually verify their toolchain matches the version in the file.
Newer rustc versions most probably will work fine, yet older ones might not be supported due to some new features used by the project or the crates.
# The preferred and default is to make a debug build. This will create a
# demonstrably slower build than a release build. If you want to use a release
# build, utilize "`BUILD_TYPE=release make -j`nproc``"
# The preferred and default is to make a debug build. This will create a
# demonstrably slower build than a release build. For a release build,
# use "BUILD_TYPE=release make -j`nproc`"
make -j`nproc`
```
#### dependency installation notes
To run the `psql` client, install the `postgresql-client` package or modify `PATH` and `LD_LIBRARY_PATH` to include `tmp_install/bin` and `tmp_install/lib`, respectively.
#### Building on OSX
1. Build neon and patched postgres
```
# Note: The path to the neon sources can not contain a space.
# The preferred and default is to make a debug build. This will create a
# demonstrably slower build than a release build. For a release build,
# use "BUILD_TYPE=release make -j`sysctl -n hw.logicalcpu`"
make -j`sysctl -n hw.logicalcpu`
```
#### Dependency installation notes
To run the `psql` client, install the `postgresql-client` package or modify `PATH` and `LD_LIBRARY_PATH` to include `pg_install/bin` and `pg_install/lib`, respectively.
To run the integration tests or Python scripts (not required to use the code), install
Python (3.9 or higher), and install python3 packages using `./scripts/pysync` (requires poetry) in the project directory.
Python (3.9 or higher), and install python3 packages using `./scripts/pysync` (requires [poetry>=1.3](https://python-poetry.org/)) in the project directory.
#### running neon database
#### Running neon database
1. Start pageserver and postgres on top of it (should be called from repo root):
```sh
# Create repository in .neon with proper paths to binaries and data
# Later that would be responsibility of a package install script
make # builds also postgres and installs it to ./tmp_install
CARGO_BUILD_FLAGS="--features=testing" make
./scripts/pytest
```
## Documentation
Now we use README files to cover design ideas and overall architecture for each module and `rustdoc` style documentation comments. See also [/docs/](/docs/) a top-level overview of all available markdown documentation.
[/docs/](/docs/) Contains a top-level overview of all available markdown documentation.
- [/docs/sourcetree.md](/docs/sourcetree.md) contains overview of source tree layout.
To view your `rustdoc` documentation in a browser, try running `cargo doc --no-deps --open`
See also README files in some source directories, and `rustdoc` style documentation comments.
Other resources:
- [SELECT 'Hello, World'](https://neon.tech/blog/hello-world/): Blog post by Nikita Shamgunov on the high level architecture
- [Architecture decisions in Neon](https://neon.tech/blog/architecture-decisions-in-neon/): Blog post by Heikki Linnakangas
- [Neon: Serverless PostgreSQL!](https://www.youtube.com/watch?v=rES0yzeERns): Presentation on storage system by Heikki Linnakangas in the CMU Database Group seminar series
### Postgres-specific terms
Due to Neon's very close relation with PostgreSQL internals, there are numerous specific terms used.
Same applies to certain spelling: i.e. we use MB to denote 1024 * 1024 bytes, while MiB would be technically more correct, it's inconsistent with what PostgreSQL code and its documentation use.
Due to Neon's very close relation with PostgreSQL internals, numerous specific terms are used.
The same applies to certain spelling: i.e. we use MB to denote 1024 * 1024 bytes, while MiB would be technically more correct, it's inconsistent with what PostgreSQL code and its documentation use.
~/git-sandbox/zenith (cli-v2)$ ./target/debug/cli start main
Creating data directory from snapshot at 0/15FFB08...
waiting for server to start....2021-04-13 09:27:43.919 EEST [984664] LOG: starting PostgreSQL 14devel on x86_64-pc-linux-gnu, compiled by gcc (Debian 10.2.1-6) 10.2.1 20210110, 64-bit
2021-04-13 09:27:43.920 EEST [984664] LOG: listening on IPv6 address "::1", port 5432
2021-04-13 09:27:43.920 EEST [984664] LOG: listening on IPv4 address "127.0.0.1", port 5432
2021-04-13 09:27:43.927 EEST [984664] LOG: listening on Unix socket "/tmp/.s.PGSQL.5432"
2021-04-13 09:27:43.939 EEST [984665] LOG: database system was interrupted; last known up at 2021-04-13 09:27:33 EEST
2021-04-13 09:27:43.939 EEST [984665] LOG: creating missing WAL directory "pg_wal/archive_status"
2021-04-13 09:27:44.189 EEST [984665] LOG: database system was not properly shut down; automatic recovery in progress
2021-04-13 09:27:44.195 EEST [984665] LOG: invalid record length at 0/15FFB80: wanted 24, got 0
2021-04-13 09:27:44.195 EEST [984665] LOG: redo is not required
2021-04-13 09:27:44.225 EEST [984664] LOG: database system is ready to accept connections
Creating data directory from snapshot at 0/15FFB08...
waiting for server to start....2021-04-13 09:28:41.874 EEST [984766] LOG: starting PostgreSQL 14devel on x86_64-pc-linux-gnu, compiled by gcc (Debian 10.2.1-6) 10.2.1 20210110, 64-bit
2021-04-13 09:28:41.875 EEST [984766] LOG: listening on IPv6 address "::1", port 5433
2021-04-13 09:28:41.875 EEST [984766] LOG: listening on IPv4 address "127.0.0.1", port 5433
2021-04-13 09:28:41.883 EEST [984766] LOG: listening on Unix socket "/tmp/.s.PGSQL.5433"
2021-04-13 09:28:41.896 EEST [984767] LOG: database system was interrupted; last known up at 2021-04-13 09:27:33 EEST
2021-04-13 09:28:42.265 EEST [984767] LOG: database system was not properly shut down; automatic recovery in progress
2021-04-13 09:28:42.269 EEST [984767] LOG: redo starts at 0/15FFB80
2021-04-13 09:28:42.272 EEST [984767] LOG: invalid record length at 0/161F4B0: wanted 24, got 0
2021-04-13 09:28:42.272 EEST [984767] LOG: redo done at 0/161F478 system usage: CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s
2021-04-13 09:28:42.321 EEST [984766] LOG: database system is ready to accept connections
done
server started
Insert some a row on the 'experimental' branch:
~/git-sandbox/zenith (cli-v2)$ psql postgres -p5433 -c "select * from foo"
t
-----------------------------
inserted on the main branch
(1 row)
~/git-sandbox/zenith (cli-v2)$ psql postgres -p5433 -c "insert into foo values ('inserted on experimental')"
INSERT 0 1
~/git-sandbox/zenith (cli-v2)$ psql postgres -p5433 -c "select * from foo"
t
-----------------------------
inserted on the main branch
inserted on experimental
(2 rows)
See that the other Postgres instance is still running on 'main' branch on port 5432:
~/git-sandbox/zenith (cli-v2)$ psql postgres -p5432 -c "select * from foo"
t
-----------------------------
inserted on the main branch
(1 row)
Everything is stored in the .zenith directory:
~/git-sandbox/zenith (cli-v2)$ ls -l .zenith/
total 12
drwxr-xr-x 4 heikki heikki 4096 Apr 13 09:28 datadirs
drwxr-xr-x 4 heikki heikki 4096 Apr 13 09:27 refs
drwxr-xr-x 4 heikki heikki 4096 Apr 13 09:28 timelines
The 'datadirs' directory contains the datadirs of the running instances:
~/git-sandbox/zenith (cli-v2)$ ls -l .zenith/datadirs/
total 8
drwx------ 18 heikki heikki 4096 Apr 13 09:27 3c0c634c1674079b2c6d4edf7c91523e
drwx------ 18 heikki heikki 4096 Apr 13 09:28 697e3c103d4b1763cd6e82e4ff361d76
~/git-sandbox/zenith (cli-v2)$ ls -l .zenith/datadirs/3c0c634c1674079b2c6d4edf7c91523e/
total 124
drwxr-xr-x 5 heikki heikki 4096 Apr 13 09:27 base
drwxr-xr-x 2 heikki heikki 4096 Apr 13 09:27 global
drwxr-xr-x 2 heikki heikki 4096 Apr 13 09:27 pg_commit_ts
drwxr-xr-x 2 heikki heikki 4096 Apr 13 09:27 pg_dynshmem
-rw------- 1 heikki heikki 4760 Apr 13 09:27 pg_hba.conf
-rw------- 1 heikki heikki 1636 Apr 13 09:27 pg_ident.conf
drwxr-xr-x 4 heikki heikki 4096 Apr 13 09:32 pg_logical
drwxr-xr-x 4 heikki heikki 4096 Apr 13 09:27 pg_multixact
drwxr-xr-x 2 heikki heikki 4096 Apr 13 09:27 pg_notify
drwxr-xr-x 2 heikki heikki 4096 Apr 13 09:27 pg_replslot
drwxr-xr-x 2 heikki heikki 4096 Apr 13 09:27 pg_serial
drwxr-xr-x 2 heikki heikki 4096 Apr 13 09:27 pg_snapshots
drwxr-xr-x 2 heikki heikki 4096 Apr 13 09:27 pg_stat
drwxr-xr-x 2 heikki heikki 4096 Apr 13 09:34 pg_stat_tmp
drwxr-xr-x 2 heikki heikki 4096 Apr 13 09:27 pg_subtrans
drwxr-xr-x 2 heikki heikki 4096 Apr 13 09:27 pg_tblspc
drwxr-xr-x 2 heikki heikki 4096 Apr 13 09:27 pg_twophase
-rw------- 1 heikki heikki 3 Apr 13 09:27 PG_VERSION
lrwxrwxrwx 1 heikki heikki 52 Apr 13 09:27 pg_wal -> ../../timelines/3c0c634c1674079b2c6d4edf7c91523e/wal
drwxr-xr-x 2 heikki heikki 4096 Apr 13 09:27 pg_xact
-rw------- 1 heikki heikki 88 Apr 13 09:27 postgresql.auto.conf
-rw------- 1 heikki heikki 28688 Apr 13 09:27 postgresql.conf
-rw------- 1 heikki heikki 96 Apr 13 09:27 postmaster.opts
-rw------- 1 heikki heikki 149 Apr 13 09:27 postmaster.pid
Note how 'pg_wal' is just a symlink to the 'timelines' directory. The
datadir is ephemeral, you can delete it at any time, and it can be reconstructed
from the snapshots and WAL stored in the 'timelines' directory. So if you push/pull
the repository, the 'datadirs' are not included. (They are like git working trees)
Creating data directory from snapshot at 0/15FFB08...
waiting for server to start....2021-04-13 09:37:05.476 EEST [985340] LOG: starting PostgreSQL 14devel on x86_64-pc-linux-gnu, compiled by gcc (Debian 10.2.1-6) 10.2.1 20210110, 64-bit
2021-04-13 09:37:05.477 EEST [985340] LOG: listening on IPv6 address "::1", port 5433
2021-04-13 09:37:05.477 EEST [985340] LOG: listening on IPv4 address "127.0.0.1", port 5433
2021-04-13 09:37:05.487 EEST [985340] LOG: listening on Unix socket "/tmp/.s.PGSQL.5433"
2021-04-13 09:37:05.498 EEST [985341] LOG: database system was interrupted; last known up at 2021-04-13 09:27:33 EEST
2021-04-13 09:37:05.808 EEST [985341] LOG: database system was not properly shut down; automatic recovery in progress
2021-04-13 09:37:05.813 EEST [985341] LOG: redo starts at 0/15FFB80
2021-04-13 09:37:05.815 EEST [985341] LOG: invalid record length at 0/161F770: wanted 24, got 0
2021-04-13 09:37:05.815 EEST [985341] LOG: redo done at 0/161F738 system usage: CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s
2021-04-13 09:37:05.866 EEST [985340] LOG: database system is ready to accept connections
done
server started
~/git-sandbox/zenith (cli-v2)$ psql postgres -p5433 -c "select * from foo"
Some files were not shown because too many files have changed in this diff
Show More
Reference in New Issue
Block a user
Blocking a user prevents them from interacting with repositories, such as opening or commenting on pull requests or issues. Learn more about blocking a user.
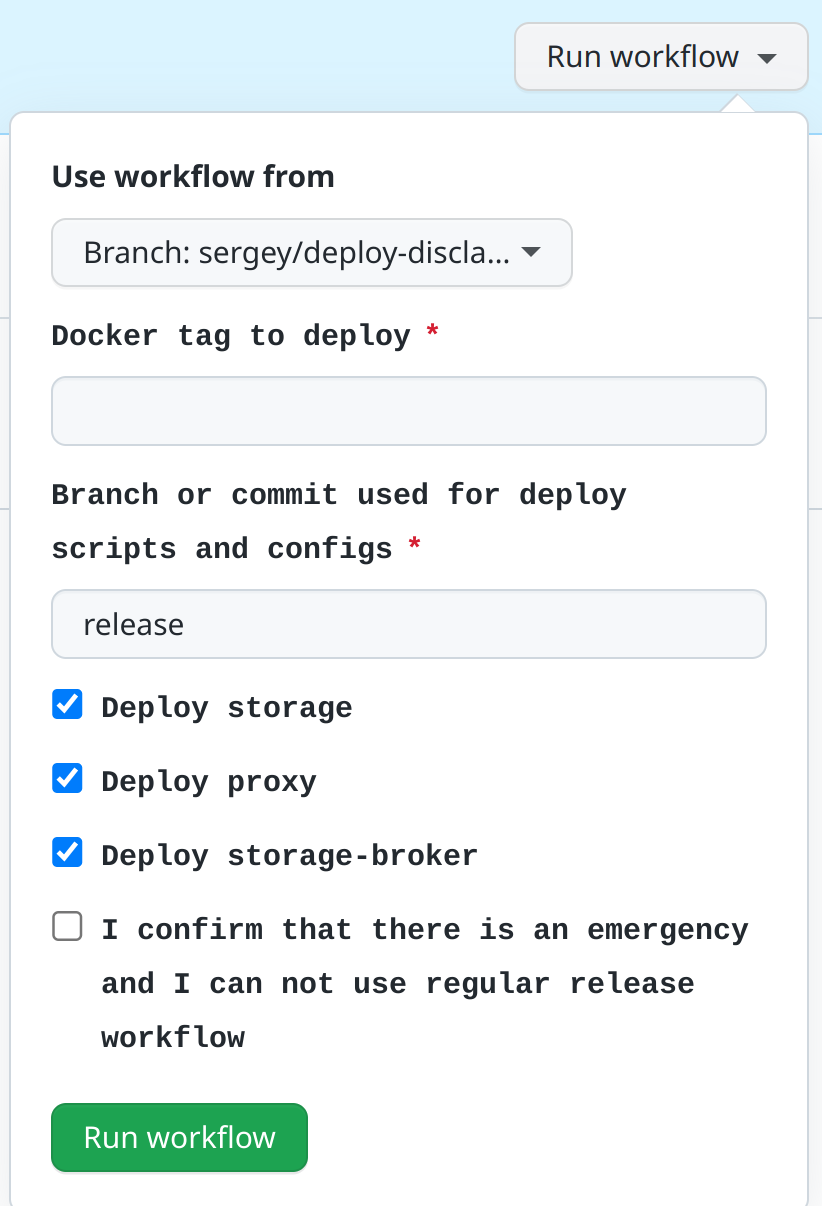{kind=link}