all 3 example are running now with:
```
cargo run --example simple
cargo run --example full_text_search
cargo run --example ivf_pq
```
Signed-off-by: Yuval Lifshitz <ylifshit@ibm.com>
Co-authored-by: Weston Pace <weston.pace@gmail.com>
Adds tests to ensure that users can paginate through simple scan, FTS,
and vector search results using `limit` and `offset`.
Tests upstream work: https://github.com/lancedb/lance/pull/4318Closes#2459
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Documentation**
- Clarified and expanded explanations of data management concepts in
LanceDB.
- Added notes on automatic background fragment compaction and
incremental reindexing support in LanceDB Cloud/Enterprise.
- Updated details on disabling interim exhaustive kNN search during
background reindexing.
- Improved formatting and removed outdated FTS reindexing subsection.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
---------
Co-authored-by: Will Jones <willjones127@gmail.com>
These operations have existed in lance for a long while and many users
need to drop down to lance for this capability. This PR adds the API and
implements it using filters (e.g. `_rowid IN (...)`) so that in doesn't
currently add any load to `BaseTable`. I'm not sure that is sustainable
as base table implementations may want to specialize how they handle
this method. However, I figure it is a good starting point.
In addition, unlike Lance, this API does not currently guarantee
anything about the order of the take results. This is necessary for the
fallback filter approach to work (SQL filters cannot guarantee result
order)
Hello!
I'm new to lancedb and interested in the Rust SDK.
I couldn't find a good hybrid search example in Rust, so I created one.
## Usage
```bash
$ cargo run --quiet --example hybrid_search --features=sentence-transformers
Result: Python is a popular programming language.
Result: Mount Everest is the highest mountain in the world.
Result: The first computer programmer was Ada Lovelace.
Result: Coffee is one of the most popular beverages in the world.
Result: Basketball is a sport played with a ball and a hoop.
```
## Summary
- Enhanced vector column detection to use substring matching instead of
exact matching
- Now detects columns with names containing "vector" or "embedding"
(case-insensitive)
- Added integer vector support to Node.js implementation (matching
Python)
- Comprehensive test coverage for both float and integer vector types
## Changes
### Python (`python/python/lancedb/table.py`)
- Updated `_infer_target_schema()` to use substring matching with helper
function `_is_vector_column()`
- Preserved original field names instead of forcing "vector"
- Consolidated duplicate logic for better maintainability
### Node.js (`nodejs/lancedb/arrow.ts`)
- Enhanced type inference with `nameSuggestsVectorColumn()` helper
function
- Added `isAllIntegers()` function with performance optimization (checks
first 10 elements)
- Implemented integer vector support using `Uint8` type (matching
Python)
- Improved type safety by removing `any` usage
### Tests
- **Python**: Added
`test_infer_target_schema_with_vector_embedding_names()` in
`test_util.py`
- **Node.js**: Added comprehensive test case in `arrow.test.ts`
- Both test suites cover various naming patterns and integer/float
vector types
## Examples of newly supported column names:
- `user_vector`, `text_embedding`, `doc_embeddings`
- `my_vector_field`, `embedding_model`
- `VECTOR_COL`, `Vector_Mixed` (case-insensitive)
- Both float and integer arrays are properly converted to fixed-size
lists
## Test plan
- [x] All existing tests pass (backward compatibility maintained)
- [x] New tests pass for both Python and Node.js implementations
- [x] Integer vector detection works correctly in Node.js
- [x] Code passes linting and formatting checks
- [x] Performance optimized for large vector arrays
Fixes#2546🤖 Generated with [Claude Code](https://claude.ai/code)
---------
Co-authored-by: Claude <noreply@anthropic.com>
### Summary
This PR adds **SigLIP** (Sigmoid Loss Image Pretraining) as a new
embedding model in the LanceDB embedding registry. SigLIP improves
image-text alignment performance using sigmoid-based contrastive loss
and offers robust zero-shot generalization.
Fixes#2498
### What’s Implemented
#### 1. `SigLIP` Embedding Class
* Added `SigLIP` support under `python/lancedb/embeddings/siglip.py`
* Implements:
* `compute_source_embeddings`
* `_batch_generate_embeddings`
* Normalization logic
* Batch-wise progress logging for image embedding
#### 2. Registry Integration
* Registered `SigLIP` in `embeddings/__init__.py`
* `SigLIP` now usable via `connect(..., embedding="siglip")`
#### 3. Evaluation Benchmark Support
* Added SigLIP to `test_embeddings_slow.py` for side-by-side
benchmarking with OpenCLIP and ImageBind
### New Test Methods
#### `test_siglip`
* End-to-end test to verify embeddings table creation and vector shape
for SigLIP

#### `test_siglip_vs_openclip_vs_imagebind_benchmark_full`
* Benchmarks:
* **Recall\@1 / 5 / 10**
* **mAP (Mean Average Precision)**
* **Embedding & Search Latency**
* Dimensionality reporting

### Notes
* SigLIP outputs 768D embeddings (vs 512D for OpenCLIP)
* Benchmark shows competitive performance despite higher dimensionality
* I'm still new to contributing to open-source and learning as I go.
Please feel free to suggest any improvements — I'm happy to make
changes!
## Summary
- Adds an overall `timeout` parameter to `TimeoutConfig` that limits the
total time for the entire request
- Can be set via config or `LANCE_CLIENT_TIMEOUT` environment variable
- Exposed in Python and Node.js bindings
- Includes comprehensive tests
## Test plan
- [x] Unit tests for Rust TimeoutConfig
- [x] Integration tests for Python bindings
- [x] Integration tests for Node.js bindings
- [x] All existing tests pass
🤖 Generated with [Claude Code](https://claude.ai/code)
Co-authored-by: Claude <noreply@anthropic.com>
Update license field from `Apache 2.0` to be `Apache-2.0` for all
Node.js packages.
This was causing GitHub's Dependency Review license check to fail with:
> The validity of the licenses of the dependencies below could not be
determined. Ensure that they are valid SPDX licenses
`nprobes` with a value greater than 20 fails with the minimum error:
```
self = <lancedb.query.AsyncVectorQuery object at 0x10b749720>, minimum_nprobes = 30
def minimum_nprobes(self, minimum_nprobes: int) -> Self:
"""Set the minimum number of probes to use.
See `nprobes` for more details.
These partitions will be searched on every indexed vector query and will
increase recall at the expense of latency.
"""
> self._inner.minimum_nprobes(minimum_nprobes)
E ValueError: Invalid input, minimum_nprobes must be less than or equal to maximum_nprobes
python/lancedb/query.py:2744: ValueError
```
Putting the max set before the min seems reasonable but it causes this
reasonable case to fail:
```
def test_nprobes_min_max_works_sync(table):
LanceVectorQueryBuilder(table, [0, 0], "vector").minimum_nprobes(2).maximum_nprobes(4).to_list()
```
with
```
self = <lancedb.query.AsyncVectorQuery object at 0x1203f1c90>, maximum_nprobes = 4
def maximum_nprobes(self, maximum_nprobes: int) -> Self:
"""Set the maximum number of probes to use.
See `nprobes` for more details.
If this value is greater than `minimum_nprobes` then the excess partitions
will be searched only if we have not found enough results.
This can be useful when there is a narrow filter to allow these queries to
spend more time searching and avoid potential false negatives.
If this value is 0 then no limit will be applied and all partitions could be
searched if needed to satisfy the limit.
"""
> self._inner.maximum_nprobes(maximum_nprobes)
E ValueError: Invalid input, maximum_nprobes must be greater than or equal to minimum_nprobes
python/lancedb/query.py:2761: ValueError
```.
The case I care about is where min == max, but this solution handles it
even if they're not. If both min and max exist, we set both to the
minimum and then set the max. This isn't 100% the same as the minimum
setter checks for 0 on the min and `.nprobes` does not do any sanity
checking at all. But I figured this was the most reasonable and general
solution without touching more of this code.
As part of this I noticed the error messages were a bit ambiguous so I
made them symmetric and clarified them while I was here.
The `MetadataEraserExec` is super lightweight and doesn't really justify
partitioning. I had a plan recently that was partitioning just for this
node and that seems wasteful.
## Summary
Fixes IndexError when creating tables with empty list data and a
provided schema. Previously, `_into_pyarrow_reader()` would attempt to
access `data[0]` on empty lists, causing an IndexError. Now properly
handles empty lists by using the provided schema.
Also adds regression tests for GitHub issues #1968 and #303 to prevent
future regressions with empty table scenarios.
## Changes
- Fix IndexError in `_into_pyarrow_reader()` for empty list + schema
case
- Add Optional[pa.Schema] parameter to handle empty data gracefully
- Add `test_create_table_empty_list_with_schema` for the IndexError fix
- Add `test_create_empty_then_add_data` for issue #1968
- Add `test_search_empty_table` for issue #303
## Test plan
- [x] All new regression tests pass
- [x] Existing tests continue to pass
- [x] Code formatted with `make format`
## Summary
Fixes#2541
**Problem**: The `register` function was not accessible via `from
lancedb.embeddings import register` as documented, causing ImportError
for users trying to create custom embedding functions.
**Solution**: Added `register` to the exports in
`python/lancedb/embeddings/__init__.py` to match the documented API and
follow the same pattern as other registry functions (`get_registry`,
`EmbeddingFunctionRegistry`).
**Root Cause**: The function existed in `lancedb.embeddings.registry`
but wasn't exposed through the main embeddings module interface.
## Changes
- Add `register` to imports in
`/python/python/lancedb/embeddings/__init__.py`
## Test Plan
- [x] Verified `from lancedb.embeddings import register` works as
documented
- [x] Confirmed existing embedding tests pass
- [x] Checked that the fix follows existing patterns (same as
`get_registry`)
- [x] Validated linting and formatting passes
## References
Fixes#2541
This patch fix can not build on python3.9 dev
the reason is that for ibm-watsonx-ai the min version is py3.10
more can check on `pyoven` https://pyoven.org/package/ibm-watsonx-ai/
also fix tiny md lint
---------
Signed-off-by: yihong0618 <zouzou0208@gmail.com>
- Fix register() method's alias parameter type from 'str = None' to
'Optional[str] = None'
- Add return type annotation 'Type[EmbeddingFunction]' to get() method
- Import Type from typing module for proper type hints
currently, to_pydantic will always return LanceModel. If type checking
is enabled in my project. I have to use `cast(data,
List[RealModelType])` to solve type error. This PR uses generic to solve
this problem.
## Summary
- Fixed flaky Node.js integration test for mirrored store functionality
- Converted callback-based `fs.readdir()` to `fs.promises.readdir()`
with proper async/await
- Used unique temporary directories to prevent test isolation issues
- Updated test expectations to match current IVF-PQ index file structure
## Problem
The mirrored store integration test was experiencing random failures in
CI with errors like:
- `expected 2 to equal 1` at various assertion points
- `done() called multiple times`
## Root Causes Identified
1. **Race conditions**: Mixing callback-based filesystem operations with
async functions created timing issues where assertions ran before
filesystem operations completed
2. **Test isolation**: Multiple tests shared the same temp directory
(`tmpdir()`), causing one test to see files from another
3. **Outdated expectations**: IVF-PQ indexes now create 2 files
(`auxiliary.idx` + `index.idx`) instead of 1, but the test expected only
1
## Solution
- Replace all `fs.readdir()` callbacks with `fs.promises.readdir()` and
`await`
- Use `fs.promises.mkdtemp()` to create unique temporary directories for
each test run
- Update index file count expectations from 1 to 2 files to match
current Lance behavior
- Add descriptive assertion labels for easier debugging
## Analysis
The mirroring implementation in `MirroringObjectStore::put_opts` is
synchronous - it awaits writes to both secondary (local) and primary
(S3) stores before returning. The test failures were due to
callback/async pattern mismatch and test isolation issues, not actual
async mirroring behavior.
## Test plan
- [x] Local tests are running without timing-based failures
- [x] Integration tests with AWS credentials pass in CI
This resolves the flaky failures including 'expected 2 to equal 1'
assertions and 'done() called multiple times' errors seen in CI runs.
## Summary
- Exposes `Session` in Python and Typescript so users can set the
`index_cache_size_bytes` and `metadata_cache_size_bytes`
* The `Session` is attached to the `Connection`, and thus shared across
all tables in that connection.
- Adds deprecation warnings for table-level cache configuration
🤖 Generated with [Claude Code](https://claude.ai/code)
---------
Co-authored-by: Claude <noreply@anthropic.com>
## Summary
Fixes intermittent CI failures in `test_search_fts[False]` where boolean
FTS queries were returning fewer results than expected due to
non-deterministic test data generation.
## Problem
The test was using global `random` and `np.random` without seeding,
causing the boolean query `MatchQuery("puppy", "text") &
MatchQuery("runs", "text")` to sometimes return only 3 results instead
of the expected 5, leading to `AssertionError: assert 3 == 5`.
## Solution
- Replace global random calls with local `random.Random(42)` and
`np.random.RandomState(42)` objects in test fixtures
- Ensures deterministic test data while maintaining test isolation
- No impact on other tests since random state is scoped to fixtures only
## Test Results
- ✅ `test_search_fts[False]` now passes consistently
- ✅ All other FTS tests continue to pass
- ✅ No regression in other test suites (verified with `test_basic`)
- ✅ Maintains existing test behavior and coverage
## Summary
Fixed a minor grammar error in the error message for missing API key
when connecting to LanceDB cloud.
## Changes
- Changed 'api_key is required to connected LanceDB cloud' to 'api_key
is required to connect to LanceDB cloud'
- Location: `python/python/lancedb/__init__.py:95`
## Test plan
- Error message formatting is correct and grammatical
- No functional changes to existing behavior
## Summary
- Add `create_import_stub()` helper to `embeddings/utils.py` for
handling optional dependencies
- Fix MLX doctest collection failures by using import stubs in
`gte_mlx_model.py`
- Module now imports successfully for doctest collection even when MLX
is not installed
## Changes
- **New utility function**: `create_import_stub()` creates placeholder
objects that allow class inheritance but raise helpful errors when used
- **Updated MLX model**: Uses import stubs instead of direct imports
that fail immediately
- **Graceful degradation**: Clear error messages when MLX functionality
is accessed without MLX installed
## Test Results
- ✅ `pytest --doctest-modules python/lancedb` now passes (with and
without MLX installed)
- ✅ All existing tests continue to pass
- ✅ MLX functionality works normally when MLX is installed
- ✅ Helpful error messages when MLX functionality is used without MLX
installed
Fixes#2538
---------
Co-authored-by: Will Jones <willjones127@gmail.com>
## Summary
Add support for providing a custom `Session` when connecting to a
`ListingDatabase`. This allows users to configure object store
registries, caching, and other session-related settings while
maintaining full backward compatibility.
## Usage Example
```rust
use std::sync::Arc;
use lancedb::connect;
let custom_session = Arc::new(lance::session::Session::default());
let db = connect("/path/to/database")
.session(custom_session)
.execute()
.await?;
```
🤖 Generated with [Claude Code](https://claude.ai/code)
Co-authored-by: Claude <noreply@anthropic.com>
## Summary
Fixes#2515 by implementing comprehensive support for missing columns in
Arrow table inputs when using embedding functions.
### Problem
Previously, when an Arrow table was passed to `fromDataToBuffer` with
missing columns and a schema containing embedding functions, the system
would fail because `applyEmbeddingsFromMetadata` expected all columns to
be present in the table.
🤖 Generated with [Claude Code](https://claude.ai/code)
---------
Co-authored-by: Claude <noreply@anthropic.com>
this test adds a new vector and then performs vector search with
distance range.
this may fail if the new vector becomes the closest one to the query
vector
Signed-off-by: BubbleCal <bubble-cal@outlook.com>
This fixes two bugs with create_table storage handle reuse. First issue
is, the database object did not previously carry a session that
create_table operations could reuse for create_table operations.
Second issue is, the inheritance logic for create_table and open_table
was causing empty storage options (i.e Some({})) to get sent, instead of
None. Lance handles these differently:
* When None is set, the object store held in the session's storage
registry that was created at "connect" is used. This value stays in the
cache long-term (probably as long as the db reference is held).
* When Some({}) is sent, LanceDB will create a new connection and cache
it for an empty key. However, that cached value will remain valid only
as long as the client holds a reference to the table. After that, the
cache is poisoned and the next create_table with the same key, will
create a new connection. This confounds reuse if e.g python gc's the
table object before another table is created.
My feeling is that the second path, if intentional, is probably meant to
serve cases where tables are overriding settings and the cached
connection is assumed not to be generally applicable. The bug is we were
engaging that mechanism for all tables.
Previously `return_score="all"` was supported only for the default
reranker (RRF) and not the model based rerankers.
This adds support for keeping all scores in the base reranker so that
all model based rerankers can use it. Its a slower path than keeping
just the relevance score but can be useful in debugging
Thanks for all your work.
The docstring for `OptimizeOptions ` seems to reference a non-existent
method on `Table`. I believe this is the correct example for
`cleanupOlderThan`.
This also appears in the generated docs, but I assume they live
downstream from this code?
just noticed that we're doing a 'return' instead of a 'raise' while
trying to get remote functionality working for my project. I went ahead
and implemented tests for both of the unimplemented functions (to_pandas
and to_arrow) while I was in there.
---------
Co-authored-by: Cyrus Attoun <jattoun1@gmail.com>
I can't find any reason for pinning this dependency and the fact that it
is pinned can be kind of annoying to use downstream (e.g. datafusion
currently requires >= 2.6).
this also upgrades:
- datafusion 47.0 -> 48.0
- half 2.5.0 -> 2.6.0
to be consistent with lance
---------
Signed-off-by: BubbleCal <bubble-cal@outlook.com>
Make sure we only update the latest version if it's actually newer. This
is important if there are concurrent queries, as they can take different
amounts of time.
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
* **Chores**
* Updated dependencies to newer versions for improved compatibility and
stability.
* **Refactor**
* Improved internal handling of data ranges and stream lifetimes for
enhanced performance and reliability.
* Simplified code style for Python query object conversions without
affecting functionality.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
Other embedding integrations such as Cohere and OpenAI already send
requests in batches. We should do that for Ollama too to improve
throughput.
The Ollama [`.embed`
API](63ca747622/ollama/_client.py (L359-L378))
was added in version 0.3.0 (almost a year ago) so I updated the version
requirement in pyproject.
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Bug Fixes**
- Improved compatibility with newer versions of the "ollama" package by
requiring version 0.3.0 or higher.
- Enhanced embedding generation to process batches of texts more
efficiently and reliably.
- **Refactor**
- Improved type consistency and clarity for embedding-related methods.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Documentation**
- Improved formatting and clarity in instructional text within the
Multivector on LanceDB notebook.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
## Summary
Fixes issue #2465 where FTS explain plans only showed basic `LanceScan`
instead of detailed execution plans with FTS query details, limits, and
offsets.
## Root Cause
The `FTSQuery::explain_plan()` and `analyze_plan()` methods were missing
the `.full_text_search()` call before calling explain/analyze plan,
causing them to operate on the base query without FTS context.
## Changes
- **Fixed** `explain_plan()` and `analyze_plan()` in `src/query.rs` to
call `.full_text_search()`
- **Added comprehensive test coverage** for FTS explain plans with
limits, offsets, and filters
- **Updated existing tests** to expect correct behavior instead of buggy
behavior
## Before/After
**Before (broken):**
```
LanceScan: uri=..., projection=[...], row_id=false, row_addr=false, ordered=true
```
**After (fixed):**
```
ProjectionExec: expr=[id@2 as id, text@3 as text, _score@1 as _score]
Take: columns="_rowid, _score, (id), (text)"
CoalesceBatchesExec: target_batch_size=1024
GlobalLimitExec: skip=2, fetch=4
MatchQuery: query=test
```
## Test Plan
- [x] All new FTS explain plan tests pass
- [x] Existing tests continue to pass
- [x] FTS queries now show proper execution plans with MatchQuery,
limits, filters
Closes#2465🤖 Generated with [Claude Code](https://claude.ai/code)
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
* **Tests**
* Added new test cases to verify explain plan output for full-text
search, vector queries with pagination, and queries with filters.
* **Bug Fixes**
* Improved the accuracy of explain plan and analysis output for
full-text search queries, ensuring the correct query details are
reflected.
* **Refactor**
* Enhanced the formatting and hierarchical structure of execution plans
for hybrid queries, providing clearer and more detailed plan
representations.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
---------
Co-authored-by: Claude <noreply@anthropic.com>
lance [release
details](https://github.com/lancedb/lance/releases/tag/v0.30.0)
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Chores**
- Updated dependency specifications to use exact version numbers instead
of referencing a git repository and tag.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
Signed-off-by: BubbleCal <bubble-cal@outlook.com>
We are able to push commits over here:
cb7293e073/.github/workflows/make-release-commit.yml (L88-L95)
So I think it's safe to assume this will work.
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Chores**
- Updated workflow configuration to improve authentication and branch
targeting for automated release processes.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
This switches the default FTS to native lance FTS for Python sync table
API, the other APIs have switched to native implementation already
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **New Features**
- The default behavior for creating a full-text search index now uses
the new implementation rather than the legacy one.
- **Bug Fixes**
- Improved handling and error messages for phrase queries in full-text
search.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
---------
Signed-off-by: BubbleCal <bubble-cal@outlook.com>
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Chores**
- Updated the release workflow to explicitly check out the main branch
during the publishing process.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Chores**
- Updated internal dependencies for improved stability and
compatibility.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
- Enhanced error messages for schema inference failures to suggest
providing an explicit schema.
- Updated embedding application logic to check for existing destination
columns, allowing for filling embeddings in columns that are all null.
- Added comments for clarity on handling existing columns during
embedding application.
Fixes https://github.com/lancedb/lancedb/issues/2183
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
## Summary by CodeRabbit
- **Bug Fixes**
- Improved error messages for schema inference to enhance readability.
- Prevented redundant embedding application by skipping columns that
already contain data, avoiding unnecessary errors and computations.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Chores**
- Updated release workflow to set a specific Git user name and email for
automated commits during the package publishing process.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Chores**
- Updated internal dependencies to use a newer version of the Lance
library.
- **New Features**
- Added support for a new query occurrence type labeled "MUST NOT" in
search filters.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
This exposes the maximum_nprobes and minimum_nprobes feature that was
added in https://github.com/lancedb/lance/pull/3903
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **New Features**
- Added support for specifying minimum and maximum probe counts in
vector search queries, allowing finer control over search behavior.
- Users can now independently set minimum and maximum probes for vector
and hybrid queries via new methods and parameters in Python, Node.js,
and Rust APIs.
- **Bug Fixes**
- Improved parameter validation to ensure correct usage of minimum and
maximum probe values.
- **Tests**
- Expanded test coverage to validate correct handling, serialization,
and error cases for the new probe parameters.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
- operator for match query
- slop for phrase query
- boolean query
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **New Features**
- Introduced support for boolean full-text search queries with AND/OR
logic and occurrence conditions.
- Added operator options for match and multi-match queries to control
term combination logic.
- Enabled phrase queries to specify proximity (slop) for flexible phrase
matching.
- Added new enumerations (`Operator`, `Occur`) and the `BooleanQuery`
class for enhanced query expressiveness.
- **Bug Fixes**
- Improved validation and error handling for invalid operator and
occurrence inputs in full-text queries.
- **Tests**
- Expanded test coverage with new cases for boolean queries and
operator-based full-text searches.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
---------
Signed-off-by: BubbleCal <bubble-cal@outlook.com>
- AND operator
- phrase query slop param
- boolean query
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **New Features**
- Added support for combining full-text search queries using AND/OR
operators, enabling more flexible query composition.
- Introduced new query types and parameters, including boolean queries,
operator selection, occurrence constraints, and phrase slop for advanced
search scenarios.
- Enhanced asynchronous search to accept rich full-text query objects
directly.
- **Bug Fixes**
- Improved handling and validation of full-text search queries in both
synchronous and asynchronous search operations.
- **Tests**
- Updated and expanded tests to cover new full-text query types and
their usage in search functions.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
---------
Signed-off-by: BubbleCal <bubble-cal@outlook.com>
This updates lance to v0.29.1-beta.1.
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Chores**
- Updated workspace dependencies for improved consistency and
reliability. No changes to user-facing functionality.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Chores**
- Updated the release workflow to include an additional step for
improved process reliability. No changes to user-facing functionality.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
Adds a script to change the lance dependency easily. To make this
change, I just had to run:
```bash
python ci/set_lance_version.py stable
```
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **New Features**
- Added a script to automate updating the Lance package version in
project dependencies.
- **Chores**
- Updated workflows to improve lockfile management and automate updates
during releases and publishing.
- Switched Lance dependencies from git-based references to fixed version
numbers for improved stability.
- Enhanced lockfile update script with an option to amend commits and
quieter output.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
---------
Co-authored-by: coderabbitai[bot] <136622811+coderabbitai[bot]@users.noreply.github.com>
Follow up to #2416
Forgot to do `git add`.
Also need to delete old actions updating package lock.
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Chores**
- Removed legacy workflows related to updating package lock files.
- Improved the update lockfiles script to ensure updated lockfiles are
always included in amended commits.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Chores**
- Updated various internal dependencies to newer versions for improved
stability and compatibility.
- Increased the version number for the Python package.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
Just letting people know where to look starting June 1st.
Both docsites should be pointing to lancedb.github.io/documentation.
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Documentation**
- Added a notification banner to the documentation site informing users
about a new URL for accessing the latest documentation starting June
1st, 2025. The message includes a clickable link that opens in a new
tab.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
---------
Co-authored-by: Will Jones <willjones127@gmail.com>
Co-authored-by: coderabbitai[bot] <136622811+coderabbitai[bot]@users.noreply.github.com>
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Chores**
- Updated workflow to ignore changes in the `Cargo.lock` file during
documentation checks, reducing unnecessary workflow failures.
- Enhanced release process by adding automated lockfile updates for
Node.js and Rust components.
- Removed an obsolete package-lock update job from the publishing
workflow to streamline releases.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Chores**
- Downgraded version numbers for the Node.js, Python, and Rust packages.
No other user-facing changes were made.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
Closes#2412
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Bug Fixes**
- Improved the reliability of listing indices by logging warnings for
errors and skipping problematic entries, ensuring successful results are
returned.
- Internal indices used for optimization are now excluded from the
visible list of indices.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Chores**
- Updated internal dependencies for improved stability and
compatibility. No user-facing changes.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
this introduces some breaking changes in terms of rust API of creating
FTS index, and the default index params changed
Signed-off-by: BubbleCal <bubble-cal@outlook.com>
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **New Features**
- Updated default settings for full-text search (FTS) index creation:
stemming, stop word removal, and ASCII folding are now enabled by
default, while token position storage is disabled by default.
- **Refactor**
- Simplified and streamlined the configuration and handling of FTS index
parameters for improved maintainability and consistency across
interfaces.
- Enhanced serialization and request construction for FTS index
parameters to reduce manual handling and improve code clarity.
- Improved test coverage by explicitly enabling positional indexing in
FTS tests to support phrase queries.
- **Chores**
- Upgraded all internal dependencies related to FTS indexing to the
latest version for enhanced compatibility and performance.
- Updated package versions for Node.js, Python, and Rust components to
the latest beta releases.
- Improved CI workflows by adding Rust toolchain setup with formatting
and linting tools.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
---------
Signed-off-by: BubbleCal <bubble-cal@outlook.com>
Co-authored-by: Will Jones <willjones127@gmail.com>
Adds example for querying a dataset with SQL
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Documentation**
- Added new guides on querying LanceDB tables using SQL with DuckDB and
Apache Datafusion.
- Included detailed instructions for integrating LanceDB with Datafusion
in Python.
- Updated navigation to include Datafusion and SQL querying
documentation.
- Improved formatting in TypeScript and vectordb update examples for
consistency.
- **Tests**
- Added a new test demonstrating SQL querying on Lance tables via
DataFusion integration.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
---------
Co-authored-by: Weston Pace <weston.pace@gmail.com>
Added a new readme for better navigation, updated language and more
detail
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Documentation**
- Updated the README with a modernized header, improved structure, and
clearer descriptions of features and architecture.
- Expanded and reorganized key features and product offerings for better
clarity.
- Simplified installation instructions and added a table of SDK
interfaces with documentation links.
- Enhanced community and contributor sections with new visuals and links
to social and support channels.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Chores**
- Updated internal dependencies for improved compatibility and
stability. No changes to user-facing features.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Chores**
- Updated workspace dependencies to use a stable release version for
improved consistency and reliability. No changes to application features
or functionality.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Documentation**
- Added an integration banner image to the beginning of the
Genkitx-LanceDB documentation.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
This is for fe14671f1
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Chores**
- Updated internal dependencies to newer versions for improved stability
and performance. No changes to features or functionality.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Documentation**
- Added a comprehensive guide for integrating LanceDB with Genkit,
including installation instructions, setup, indexing, retrieval, and
building a custom RAG pipeline with example code and screenshots.
- Updated the documentation navigation to include the new Genkit
integration, making it accessible from the site menu.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
add default for result structs, when values are not provided, will go
with the default values
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Chores**
- Improved internal handling of table operation results to support
default values. No changes to user-facing features or functionality.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
Provides the ability to set a timeout for merge insert. The default
underlying timeout is however long the first attempt takes, or if there
are multiple attempts, 30 seconds. This has two use cases:
1. Make the timeout shorter, when you want to fail if it takes too long.
2. Allow taking more time to do retries.
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **New Features**
- Added support for specifying a timeout when performing merge insert
operations in Python, Node.js, and Rust APIs.
- Introduced a new option to control the maximum allowed execution time
for merge inserts, including retry timeout handling.
- **Documentation**
- Updated and added documentation to describe the new timeout option and
its usage in APIs.
- **Tests**
- Added and updated tests to verify correct timeout behavior during
merge insert operations.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
Prior to this commit, attempting to drop an index that did not exist
would return a TableNotFound error stating that the target table does
not exist -- even when it did exist. Instead, we now return an
IndexNotFound error.
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Bug Fixes**
- Improved error handling when attempting to drop a non-existent index,
providing a more accurate error message.
- **Tests**
- Added a test to verify correct error reporting when dropping an index
that does not exist.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
This moves the __len__ method from LanceTable and RemoteTable to Table
so that child classes don't need to implement their own. In the process,
it fixes the implementation of RemoteTable's length method, which was
previously missing a return statement.
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Refactor**
- Centralized the table length functionality in the base table class,
simplifying subclass behavior.
- Removed redundant or non-functional length methods from specific table
classes.
- **Tests**
- Added a new test to verify correct table length reporting for remote
tables.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
add restore with tag API in python and nodejs API and add tests to guard
them
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **New Features**
- The restore functionality now supports using version tags in addition
to numeric version identifiers, allowing you to revert tables to a state
marked by a tag.
- **Bug Fixes**
- Restoring with an unknown tag now properly raises an error.
- **Documentation**
- Updated documentation and examples to clarify that restore accepts
both version numbers and tags.
- **Tests**
- Added new tests to verify restore behavior with version tags and error
handling for unknown tags.
- Added tests for checkout and restore operations involving tags.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
add API originally returns a struct with request_id, add backward
compatibility for that
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Bug Fixes**
- Improved handling of empty server responses for various data
operations to ensure consistent behavior across server versions.
- Added default values to version and numeric fields to prevent errors
when response data is incomplete.
- **Tests**
- Expanded tests to cover multiple server response scenarios, validating
correct version handling in data operations.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
Reduce the duplicate code for remote write operation testing.
Avoid double call to remote to get version info, just return 0 instead
of suddenly adding extra API calls for end users when they are using old
servers.
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **New Features**
- Added version tracking to table operation results, allowing users to
see the commit version associated with add, update, delete, merge, and
column modification operations.
- **Bug Fixes**
- Improved compatibility with legacy servers by standardizing version
information as zero when the server does not return a version.
- **Documentation**
- Clarified the meaning of the version field in operation results,
especially for cases involving legacy server responses.
- **Tests**
- Enhanced test coverage to verify correct behavior with both legacy and
modern server responses.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
return version info for all write operations (add, update, merge_insert
and column modification operations)
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **New Features**
- Table modification operations (add, update, delete, merge,
add/alter/drop columns) now return detailed result objects including
version numbers and operation statistics.
- Result objects provide clearer feedback such as rows affected and new
table version after each operation.
- **Documentation**
- Updated documentation to describe new result objects and their fields
for all relevant table operations.
- Added documentation for new result interfaces and updated method
return types in Node.js and Python APIs.
- **Tests**
- Enhanced test coverage to assert correctness of returned versioning
and operation metadata after table modifications.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
Closes#2191
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Chores**
- Updated the required version of the pyarrow package to version 16 or
higher.
- Adjusted automated testing workflows to install pyarrow version 16 for
compatibility checks.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
Based on this comment:
https://github.com/lancedb/lancedb/issues/2228#issuecomment-2730463075
and https://github.com/lancedb/lance/pull/2357
Here is my attempt at implementing bindings for returning merge stats
from a `merge_insert.execute` call for lancedb.
Note: I have almost no idea what I am doing in Rust but tried to follow
existing code patterns and pay attention to compiler hints.
- The change in nodejs binding appeared to be necessary to get
compilation to work, presumably this could actual work properly by
returning some kind of NAPI JS object of the stats data?
- I am unsure of what to do with the remote/table.rs changes -
necessarily for compilation to work; I assume this is related to LanceDB
cloud, but unsure the best way to handle that at this point.
Proof of function:
```python
import pandas as pd
import lancedb
db = lancedb.connect("/tmp/test.db")
test_data = pd.DataFrame(
{
"title": ["Hello", "Test Document", "Example", "Data Sample", "Last One"],
"id": [1, 2, 3, 4, 5],
"content": [
"World",
"This is a test",
"Another example",
"More test data",
"Final entry",
],
}
)
table = db.create_table("documents", data=test_data, exist_ok=True, mode="overwrite")
update_data = pd.DataFrame(
{
"title": [
"Hello, World",
"Test Document, it's good",
"Example",
"Data Sample",
"Last One",
"New One",
],
"id": [1, 2, 3, 4, 5, 6],
"content": [
"World",
"This is a test",
"Another example",
"More test data",
"Final entry",
"New content",
],
}
)
stats = (
table.merge_insert(on="id")
.when_matched_update_all()
.when_not_matched_insert_all()
.execute(update_data)
)
print(stats)
```
returns
```
{'num_inserted_rows': 1, 'num_updated_rows': 5, 'num_deleted_rows': 0}
```
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
## Summary by CodeRabbit
- **New Features**
- Merge-insert operations now return detailed statistics, including
counts of inserted, updated, and deleted rows.
- **Bug Fixes**
- Tests updated to validate returned merge-insert statistics for
accuracy.
- **Documentation**
- Method documentation improved to reflect new return values and clarify
merge operation results.
- Added documentation for the new `MergeStats` interface detailing
operation statistics.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
---------
Co-authored-by: Will Jones <willjones127@gmail.com>
metadata{filename=xyz} filename would be there structurally, but ALWAYS
null.
I didn't include this as a file but it may be useful for understanding
the problem for people searching on this issue so I'm including it here
as documentation. Before this patch any field that is more than 1 deep
is accepted but returns null values for subfields when queried.
```js
const lancedb = require('@lancedb/lancedb');
// Debug logger
function debug(message, data) {
console.log(`[TEST] ${message}`, data !== undefined ? data : '');
}
// Log when our unwrapArrowObject is called
const kParent = Symbol.for("parent");
const kRowIndex = Symbol.for("rowIndex");
// Override console.log for our test
const originalConsoleLog = console.log;
console.log = function() {
// Filter out noisy logs
if (arguments[0] && typeof arguments[0] === 'string' && arguments[0].includes('[INFO] [LanceDB]')) {
originalConsoleLog.apply(console, arguments);
}
originalConsoleLog.apply(console, arguments);
};
async function main() {
debug('Starting test...');
// Connect to the database
debug('Connecting to database...');
const db = await lancedb.connect('./.lancedb');
// Try to open an existing table, or create a new one if it doesn't exist
let table;
try {
table = await db.openTable('test_nested_fields');
debug('Opened existing table');
} catch (e) {
debug('Creating new table...');
// Create test data with nested metadata structure
const data = [
{
id: 'test1',
vector: [1, 2, 3],
metadata: {
filePath: "/path/to/file1.ts",
startLine: 10,
endLine: 20,
text: "function test() { return true; }"
}
},
{
id: 'test2',
vector: [4, 5, 6],
metadata: {
filePath: "/path/to/file2.ts",
startLine: 30,
endLine: 40,
text: "function test2() { return false; }"
}
}
];
debug('Data to be inserted:', JSON.stringify(data, null, 2));
// Create the table
table = await db.createTable('test_nested_fields', data);
debug('Table created successfully');
}
// Query the table and get results
debug('Querying table...');
const results = await table.search([1, 2, 3]).limit(10).toArray();
// Log the results
debug('Number of results:', results.length);
if (results.length > 0) {
const firstResult = results[0];
debug('First result properties:', Object.keys(firstResult));
// Check if metadata is accessible and what properties it has
if (firstResult.metadata) {
debug('Metadata properties:', Object.keys(firstResult.metadata));
debug('Metadata filePath:', firstResult.metadata.filePath);
debug('Metadata startLine:', firstResult.metadata.startLine);
// Destructure to see if that helps
const { filePath, startLine, endLine, text } = firstResult.metadata;
debug('Destructured values:', { filePath, startLine, endLine, text });
// Check if it's a proxy object
debug('Result is proxy?', Object.getPrototypeOf(firstResult) === Object.prototype ? false : true);
debug('Metadata is proxy?', Object.getPrototypeOf(firstResult.metadata) === Object.prototype ? false : true);
} else {
debug('Metadata is not accessible!');
}
}
// Close the database
await db.close();
}
main().catch(e => {
console.error('Error:', e);
});
```
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
## Summary by CodeRabbit
- **Bug Fixes**
- Improved handling of nested struct fields to ensure accurate
preservation of values during serialization and deserialization.
- Enhanced robustness when accessing nested object properties, reducing
errors with missing or null values.
- **Tests**
- Added tests to verify correct handling of nested struct fields through
serialization and deserialization.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
---------
Co-authored-by: Will Jones <willjones127@gmail.com>
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Chores**
- Updated dependencies for related components to use the latest version
from a specific repository source. No changes to features or public
functionality.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
* Add a new "table stats" API to expose basic table and fragment
statistics with local and remote table implementations
### Questions
* This is using `calculate_data_stats` to determine total bytes in the
table. This seems like a potentially expensive operation - are there any
concerns about performance for large datasets?
### Notes
* bytes_on_disk seems to be stored at the column level but there does
not seem to be a way to easily calculate total bytes per fragment. This
may need to be added in lance before we can support fragment size
(bytes) statistics.
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **New Features**
- Added a method to retrieve comprehensive table statistics, including
total rows, index counts, storage size, and detailed fragment size
metrics such as minimum, maximum, mean, and percentiles.
- Enabled fetching of table statistics from remote sources through
asynchronous requests.
- Extended table interfaces across Python, Rust, and Node.js to support
synchronous and asynchronous retrieval of table statistics.
- **Tests**
- Introduced tests to verify the accuracy of the new table statistics
feature for both populated and empty tables.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
add the tag related API to list existing tags, attach tag to a version,
update the tag version, delete tag, get the version of the tag, and
checkout the version that the tag bounded to.
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **New Features**
- Introduced table version tagging, allowing users to create, update,
delete, and list human-readable tags for specific table versions.
- Enabled checking out a table by either version number or tag name.
- Added new interfaces for tag management in both Python and Node.js
APIs, supporting synchronous and asynchronous workflows.
- **Bug Fixes**
- None.
- **Documentation**
- Updated documentation to describe the new tagging features, including
usage examples.
- **Tests**
- Added comprehensive tests for tag creation, updating, deletion,
listing, and version checkout by tag in both Python and Node.js
environments.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
Fix hybrid search explain plan analyze plan API
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **New Features**
- Added options to view the execution plan and analyze the runtime
performance of hybrid queries.
- **Refactor**
- Improved internal handling of query setup for better modularity and
maintainability.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
Upstream changelog:
https://github.com/lancedb/lance/releases/tag/v0.26.0
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Chores**
- Updated dependency management to use published crate versions for
improved reliability and maintainability.
- Added a temporary workaround for build issues by pinning a specific
version of a dependency.
- **Refactor**
- Improved resource management and concurrency by updating internal
ownership models for object storage components.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **New Features**
- Added support for distance range filtering in hybrid vector queries,
allowing users to specify lower and upper bounds for search results.
- **Tests**
- Introduced new tests to validate distance range filtering and
reranking in both synchronous and asynchronous hybrid query scenarios.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
---------
Signed-off-by: BubbleCal <bubble-cal@outlook.com>
To workaround this issue: https://github.com/lancedb/lancedb/issues/2211
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Bug Fixes**
- Improved handling of large query parameters to prevent potential
overflow issues when using the "k" parameter in queries.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
Fixes#2315.
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Refactor**
- Enhanced query processing to maintain smooth functionality across
different dependency versions, ensuring improved stability and
performance.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Chores**
- Improved CI workflow for documentation builds by optimizing Rust build
settings and updating the runner environment.
- Fixed a typo in a workflow step name.
- Streamlined caching steps to reduce redundancy and improve efficiency.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
Closes https://github.com/lancedb/lancedb/issues/2307
* Adds retries to remote operations with stream bodies (add,
merge_insert)
* Change default retryable status codes to 409, 429, 500, 502, 503, 504
* Don't retry add or merge_insert operations on 5xx responses
Notes:
* Supporting retries on stream bodies means we have to buffer the body
into memory so it can be cloned on retry. This will impact memory use
patterns for the remote client. This buffering can be disabled by
disabling retries (i.e. setting retries to 0 in RetryConfig)
* It does not seem that retry config can be specified by env vars as the
documentation suggests. I added a follow-up issue
[here](https://github.com/lancedb/lancedb/issues/2350)
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
## Summary by CodeRabbit
- **New Features**
- Enhanced retry support for remote requests with configurable limits
and exponential backoff with jitter.
- Added robust retry logic for streaming data uploads, enabling retries
with buffered data to ensure reliability.
- **Bug Fixes**
- Improved error handling and retry behavior for HTTP status codes 409
and 504.
- **Refactor**
- Centralized and modularized HTTP request sending and retry logic
across remote database and table operations.
- Streamlined request ID management for improved traceability.
- Simplified error message construction in index waiting functionality.
- **Tests**
- Added a test verifying merge-insert retries on HTTP 409 responses.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
I added a timeout to query execution options in
https://github.com/lancedb/lancedb/pull/2288. However, this was send to
the request timeout, but the retry implementation is unaware of this
timeout. So once the query timed out, a retry would be triggered.
Instead, this PR changes it so the timeout happens outside the retry
loop.
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Bug Fixes**
- Improved query timeout handling to provide clearer error messages and
more reliable cancellation if a query takes too long to complete.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
Fixes#2344
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Tests**
- Updated tests to use PyArrow Tables instead of pandas DataFrames where
possible, reducing reliance on pandas.
- Tests that require pandas are now automatically skipped if pandas is
not installed.
- **Chores**
- Improved workflow to uninstall both pylance and pandas in a specific
test step.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
The docs in the Guide here do not match the [API reference]
(https://lancedb.github.io/lancedb/js/classes/Table/#updateopts) for the
nodejs client.
I am writing an Elixir wrapper over the typescript library (Rust
forthcoming!) and confirmed in testing that the API reference is correct
vs the Guide.
Following the Guide docs, the error I got was:
"lance error: Invalid user input: Schema error: No field named bar.
Valid fields are foo. For a query of:
await table.update({foo: "buzz"}, { where: "foo = 'bar'"});
Over a table with a schema of just {foo: Utf8}.
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Documentation**
- Reformatted a code snippet in the guide to enhance readability by
splitting it into multiple lines for improved clarity.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
* Add new wait_for_index() table operation that polls until indices are
created/fully indexed
* Add an optional wait timeout parameter to all create_index operations
* Python and NodeJS interfaces
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
## Summary by CodeRabbit
- **New Features**
- Added optional waiting for index creation completion with configurable
timeout.
- Introduced methods to poll and wait for indices to be fully built
across sync and async tables.
- Extended index creation APIs to accept a wait timeout parameter.
- **Bug Fixes**
- Added a new timeout error variant for improved error reporting on
index operations.
- **Tests**
- Added tests covering successful index readiness waiting, timeout
scenarios, and missing index cases.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
This PR adds ColPali support with ColPaliEmbeddings class (tagged
"colpali") using ColQwen2.5 for multi-vector text/image embeddings. Also
added MultiVector Pydantic type to handle the vector lists.
I've added some integration test for the embedding model and some unit
test for the new Pydantic type. Could be a template for other ColPali
variants as well. or until transformers🤗 starts supporting it.
Still `TODO`:
- [ ] Documentation
- [ ] Add an example
_Could also allow Image as query, but didn't work well when testing it._
[ColPali-Engine](https://github.com/illuin-tech/colpali) version:
0.3.9.dev17+g3faee24
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **New Features**
- Introduced support for ColPali-based multimodal multi-vector
embeddings for both text and images.
- Added a new embedding class for generating multi-vector embeddings,
configurable for various model and processing options.
- Added a new Pydantic type for multi-vector embeddings, supporting
validation and schema generation for lists of fixed-dimension vectors.
- **Bug Fixes**
- Ensured proper asynchronous index creation in query tests for improved
reliability.
- **Tests**
- Added integration tests for ColPali embeddings, including
text-to-image search and validation of multi-vector fields.
- Added comprehensive tests for the new multi-vector Pydantic type,
covering schema, validation, and default value behavior.
- **Chores**
- Updated optional dependencies to include the ColPali engine.
- Added utility to check for availability of flash attention support.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **New Features**
- Added the ability to prewarm (load into memory) table indexes via new
methods in Python, Node.js, and Rust APIs, potentially reducing
cold-start query latency.
- **Bug Fixes**
- Ensured prewarming an index does not interfere with subsequent search
operations.
- **Tests**
- Introduced new test cases to verify full-text search index creation,
prewarming, and search functionalities in both Python and Node.js.
- **Chores**
- Updated dependencies for improved compatibility and performance.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
---------
Co-authored-by: Lu Qiu <luqiujob@gmail.com>
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Documentation**
- Updated the link in the documentation to correctly reference the
workflow file, ensuring accurate navigation from the current context.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
Signed-off-by: Guspan Tanadi <36249910+guspan-tanadi@users.noreply.github.com>
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **New Features**
- Enhanced full-text search capabilities with support for phrase
queries, fuzzy matching, boosting, and multi-column matching.
- Search methods now accept full-text query objects directly, improving
query flexibility and precision.
- Python and JavaScript SDKs updated to handle full-text queries
seamlessly, including async search support.
- **Tests**
- Added comprehensive tests covering fuzzy search, phrase search, and
boosted queries to ensure robust full-text search functionality.
- **Documentation**
- Updated query class documentation to reflect new constructor options
and removal of deprecated methods for clarity and simplicity.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
---------
Signed-off-by: BubbleCal <bubble-cal@outlook.com>
This change allows to centrally manage the plance depndency without
everybody needing to monitor for compatibility manually.
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **New Features**
- Introduced an optional dependency that enhances development support.
Users can now benefit from improved static analysis capabilities when
installing the recommended version (0.23.2 or later).
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
This reverts commit a547c523c2 or #2281
The current implementation can cause panics and performance degradation.
I will bring this back with more testing in
https://github.com/lancedb/lancedb/pull/2311
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Documentation**
- Enhanced clarity on read consistency settings with updated
descriptions and default behavior.
- Removed outdated warnings about eventual consistency from the
troubleshooting guide.
- **Refactor**
- Streamlined the handling of the read consistency interval across
integrations, now defaulting to "None" for improved performance.
- Simplified internal logic to offer a more consistent experience.
- **Tests**
- Updated test expectations to reflect the new default representation
for the read consistency interval.
- Removed redundant tests related to "no consistency" settings for
streamlined testing.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
---------
Co-authored-by: coderabbitai[bot] <136622811+coderabbitai[bot]@users.noreply.github.com>
I found some edge cases while running experiments that - depending on
the base reranking libraries, some of them don't handle empty lists
well. This PR manually checks if the result set to be reranked is empty
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Bug Fixes**
- Enhanced search result processing by ensuring that reordering only
occurs when valid, non-empty results are available, thereby preventing
unnecessary operations and potential errors.
- **Tests**
- Added automated tests to verify that empty search result sets are
handled correctly, ensuring consistent behavior across various
rerankers.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Chores**
- Updated internal library dependencies to the latest beta version for
improved system stability.
- **Tests**
- Added automated tests to validate full-text search functionality on
list-based text fields.
- **Refactor**
- Enhanced the search processing logic to provide robust support for
list-type text data, ensuring more reliable results.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
---------
Signed-off-by: BubbleCal <bubble-cal@outlook.com>
This should prevent the failures we are seeing in Node release.
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Chore**
- Enhanced the package deprecation process with improved security
measures, ensuring smoother and more reliable updates during package
deprecation.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
This bug was introduced in https://github.com/lancedb/lancedb/pull/2281
Likely introduced during a rebase when fixing merge conflicts.
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Refactor**
- Updated the refresh process so that reloading now uses the existing
dataset version instead of automatically updating to the latest version.
This change may affect workflows that rely on immediate data updates
during refresh.
- **New Features**
- Introduced a new module for tracking I/O statistics in object store
operations, enhancing monitoring capabilities.
- Added a new test module to validate the functionality of the dataset
operations.
- **Bug Fixes**
- Reintroduced the `write_options` method in the `CreateTableBuilder`,
ensuring consistent functionality across different builder variants.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
Closes#2287
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **New Features**
- Added configurable timeout support for query executions. Users can now
specify maximum wait times for queries, enhancing control over
long-running operations across various integrations.
- **Tests**
- Expanded test coverage to validate timeout behavior in both
synchronous and asynchronous query flows, ensuring timely error
responses when query execution exceeds the specified limit.
- Introduced a new test suite to verify query operations when a timeout
is reached, checking for appropriate error handling.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
The issue we fixed in https://github.com/lancedb/lancedb/pull/2296 was
caused by an upgrade in dependencies. This could have been caught if we
had run these CI jobs when we did the dependency change.
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Chores**
- Updated our automated pipeline to trigger additional stability checks
when dependency configurations change, ensuring smoother build and
release processes.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Chores**
- Updated core dependency versions to v0.25.3-beta.2.
- Enabled additional functionality with a new "dynamodb" feature.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
missed to support it in `search()` API and there were some pydantic
errors
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **New Features**
- Enhanced full-text search capabilities by incorporating additional
parameters, enabling more flexible query definitions.
- Extended table search functionality to support full-text queries
alongside existing search types.
- **Tests**
- Introduced new tests that validate both structured and conditional
full-text search behaviors.
- Expanded test coverage for various query types, including MatchQuery,
BoostQuery, MultiMatchQuery, and PhraseQuery.
- **Bug Fixes**
- Fixed a logic issue in query processing to ensure correct handling of
full-text search queries.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
---------
Signed-off-by: BubbleCal <bubble-cal@outlook.com>
Fixes#2255
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Chores**
- Enhanced the build process to improve performance and reliability
across Linux platforms.
- Updated environment settings for more accurate compiler integration.
- Activated previously inactive build configurations to support advanced
feature support.
- Added support for the x86_64 architecture on Linux systems utilizing
the musl C library.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
We recently allowed this for lance but there was a check in lancedb as
well that was preventing it
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **New Features**
- Added support for indexing fixed-size binary data using B-tree
structures for efficient data storage and retrieval.
- **Tests**
- Implemented automated tests to ensure the new binary indexing works
correctly and meets the expected configuration.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
- **Chores**
- Updated dependency versions for improved performance and
compatibility.
- **New Features**
- Added support for structured full-text search with expanded query
types (e.g., match, phrase, boost, multi-match) and flexible input
formats.
- Introduced a new method to check server support for structural
full-text search features.
- Enhanced the query system with new classes and interfaces for handling
various full-text queries.
- Expanded the functionality of existing methods to accept more complex
query structures, including updates to method signatures.
- **Bug Fixes**
- Improved error handling and reporting for full-text search queries.
- **Refactor**
- Enhanced query processing with streamlined input handling and improved
error reporting, ensuring more robust and consistent search results
across platforms.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
---------
Signed-off-by: BubbleCal <bubble-cal@outlook.com>
Co-authored-by: BubbleCal <bubble-cal@outlook.com>
Fix restore to always checkout latest version, following local restore
api implementation
a1d1833a40/rust/lancedb/src/table.rs (L1910)
Otherwise
table.create_table -> version 1
table.add_table -> version 2
table.checkout(1), table.restore() -> the version remains at 1 (should
checkout_latest inside restore method to update version to latest
version and allow write operation)
table.checkout_latest() -> version is 3
can do write operations
add analyze plan api to allow executing the queries and see runtime
metrics.
Which help identify the query IO overhead and help identify query
slowness
Previously, when we loaded the next version of the table, we would block
all reads with a write lock. Now, we only do that if
`read_consistency_interval=0`. Otherwise, we load the next version
asynchronously in the background. This should mean that
`read_consistency_interval > 0` won't have a meaningful impact on
latency.
Along with this change, I felt it was safe to change the default
consistency interval to 5 seconds. The current default is `None`, which
means we will **never** check for a new version by default. I think that
default is contrary to most users expectations.
This fixes an issue for people wishing to use different kinds of
rerankers in lancedb via AnswerDotAI rerankers. Currently, the arguments
are passed sequentially, but they don't match the[Reranker class
implementation](d604a8c47d/rerankers/reranker.py (L179)):
the second argument is expected to be an optional "lang" for default
models, while model_type should be passed explicitly.
The one line changes in this PR fixes it and enables the use of other
methods (eg LLMs-as-rerankers)
* direct users to cloud.lancedb.com since LanceDB Cloud is in public
beta
* removed the `cast vector dimension` from alter columns as we don't
support it
This PR adds a `to_query_object` method to the various query builders
(except not hybrid queries yet). This makes it possible to inspect the
query that is built.
In addition this PR does some normalization between the sync and async
query paths. A few custom defaults were removed in favor of None (with
the default getting set once, in rust).
Also, the synchronous to_batches method will now actually stream results
Also, the remote API now defaults to prefiltering
This PR fixes build issues associated with `aws-lc-rs`, while
simplifying the build process. Previously, we used custom scripts for
the musl and Windows ARM builds. These were complicated and prone to
breaking. This PR switches to a setup that mirrors
https://github.com/napi-rs/package-template/blob/main/.github/workflows/CI.yml.
* linux glibc and musl builds now use the Docker images provided by the
napi project
* Windows ARM build now just cross compiles from Windows x64, which
turns out to work quite well.
- adds `loss` into the index stats for vector index
- now `optimize` can retrain the vector index
---------
Signed-off-by: BubbleCal <bubble-cal@outlook.com>
We soon won't rely on cross compiling from Linux to windows, so can
remove this check. Instead, check that we can cross compile from Windows
between architectures.
`object_store` already hard codes `rustls` as the TLS implementation, so
we have been shipping a mix of `rustls` and `openssl`. For simplicity of
builds, we should consolidate to one, and that has to be `rustls`.
vectordb is deprecated, and these platforms are particularly difficult
to maintain. Removing now to prevent further headaches.
We will keep these platforms supported on `@lancedb/lancedb`.
The `ConnectRequest` has a set of properties that only make sense for
listing databases / catalogs and a set of properties that only make
sense for remote databases.
This PR reduces all options to a single `HashMap<String, String>`. This
makes it easier to add new database / catalog implementations and makes
it clearer to users which options are applicable in which situations.
I don't believe there are any breaking changes here. The closest thing
is that I placed the `ConnectBuilder` methods `api_key`, `region`, and
`host_override` behind a `remote` feature gate. This is not strictly
needed and I could remove the feature gate but it seemed appropriate.
Since using these methods without the remote feature would have been
meaningless I don't feel this counts as a breaking change.
We could look at removing these methods entirely from the
`ConnectBuilder` (and encouraging users to use `RemoteDatabaseOptions`
instead) but I'm not sure how I feel about that.
Another approach we could take is to move these methods into a
`RemoteConnectBuilderExt` trait (and there could be a similar
`ListingConnectBuilderExt` trait to add methods for the listing database
/ catalog).
For now though my main goal is to simplify `ConnectRequest` as much as
possible (I see this being part of the key public API for database /
catalog integrations, similar to the `BaseTable`, `Catalog`, and
`Database` traits and I'd like it to be simple).
Closes#2114
Starting in #1965, we no longer pass the table schema into
`pa.Table.from_pylist()`. This means PyArrow is choosing the order of
the struct subfields, and apparently it does them in alphabetical order.
This is fine in theory, since in Lance we support providing fields in
any order. However, before we pass it to Lance, we call
`pa.Table.cast()` to align column types to the table types.
`pa.Table.cast()` is strict about field order, so we need to create a
cast target schema that aligns with the input data. We were doing this
at the top-level fields, but weren't doing this in nested fields. This
PR adds support to do this for nested ones.
Hello LanceDB team,
while developing using `lancedb` as a library I encountered a typing
problem affecting IDE hints and completions during development.
---
## Current Situation
Currently, the abstract base class `lancedb.query:LanceQueryBuilder`
uses method chaining to build up the search parameters, where the
methods have `LanceQueryBuilder` as a return type hint.
This leads to two issues:
1. Implementing subclasses of `LanceQueryBuilder` need to override
methods to modify the return type hint, even when they don't need to
change its implementation, just to ensure adequate IDE hints and
completions.
2. When using method chaining the first method directly inherited from
the abstract `LanceQueryBuilder` causes the inferred type to switch back
to `LanceQueryBuilder`. So even when the type starts from
`lancdb.table:LanceTable.search(query_type="vector", ...)` and therefor
correctly is inferred as `LanceVectorQueryBuilder`, after calling e.g.
`LanceVectorQueryBuilder.limit(...)` it is seen as the abstract
`LanceQueryBuilder` from that point on.
### Example of current situation

## Proposed changes
I propose to change the return type hints of the corresponding methods
(including classmethod `create()`) in the abstract base class
`LanceQueryBuilder` from `LanceQueryBuilder` to `Self`.
`Self` is already imported in the module:
```py
if sys.version_info >= (3, 11):
from typing import Self
else:
from typing_extensions import Self
```
### Further possible changes
Additionally, the implementing subclasses could also change the return
type hints to `Self` to potentially allow for further inheritance
easily.
> [!NOTE]
> **However this is not part of this pull request as of writing.**
### Example after proposed changes

---
Best regards
Martin
Previously, users could only specify new data types in `alterColumns` as
strings:
```ts
await tbl.alterColumns([
path: "price",
dataType: "float"
]);
```
But this has some problems:
1. It wasn't clear what were valid types
2. It was impossible to specify nested types, like lists and vector
columns.
This PR changes it to take an Arrow data type, similar to how the Python
API works. This allows casting vector types:
```ts
await tbl.alterColumns([
{
path: "vector",
dataType: new arrow.FixedSizeList(
2,
new arrow.Field("item", new arrow.Float16(), false),
),
},
]);
```
Closes#2185
Hello LanceDB team,
---
I have fixed a discrepancy in the class docstring of
`lancedb.embeddings.base:EmbeddingFunction` and made consistency
alignments to that docstring.
### Changes made
1. The docstring referred to the abstract method
`get_source_embeddings()`.
This method does not exist in the repository at the current state.
I have changed the mention to refer to the actual abstract method
`compute_source_embeddings()`.
2. Also, I aligned the consistency within the ordered list which is
describing the methods to be implemented by concrete embedding
functions.
---
Thank you for developing this useful library. 👍
Best regards
Martin
We attempted to make pylance optional in
https://github.com/lancedb/lancedb/pull/2156 but it appears this did not
quite work. Users are unable to use lancedb from a fresh install. This
reverts the optional-ness so we can get back in a working state while we
fix the issue.
Prior to this commit, issuing drop_all_tables on a listing database with
an external manifest store would delete physical tables but leave
references behind in the manifest store. The table drop would succeed,
but subsequent creation of a table with the same name would fail with a
conflict.
With this patch, the external manifest store is updated to account for
the dropped tables so that dropped table names can be reused.
@wjones127 is there a standard way you guys setup your virtualenv? I can
either relist all the dependencies in the pyright precommit section, or
specify a venv, or the user has to be in the virtual environment when
they run git commit. If the venv location was standardized or a python
manager like `uv` was used it would be easier to avoid duplicating the
pyright dependency list.
Per your suggestion, in `pyproject.toml` I added in all the passing
files to the `includes` section.
For ruff I upgraded the version and removed "TCH" which doesn't exist as
an option.
I added a `pyright_report.csv` which contains a list of all files sorted
by pyright errors ascending as a todo list to work on.
I fixed about 30 issues in `table.py` stemming from str's being passed
into methods that required a string within a set of string Literals by
extracting them into `types.py`
Can you verify in the rust bridge that the schema should be a property
and not a method here? If it's a method, then there's another place in
the code where `inner.schema` should be `inner.schema()`
``` python
class RecordBatchStream:
@property
def schema(self) -> pa.Schema: ...
```
Also unless the `_lancedb.pyi` file is wrong, then there is no
`__anext__` here for `__inner` when it's not an `AsyncGenerator` and
only `next` is defined:
``` python
async def __anext__(self) -> pa.RecordBatch:
return await self._inner.__anext__()
if isinstance(self._inner, AsyncGenerator):
batch = await self._inner.__anext__()
else:
batch = await self._inner.next()
if batch is None:
raise StopAsyncIteration
return batch
```
in the else statement, `_inner` is a `RecordBatchStream`
```python
class RecordBatchStream:
@property
def schema(self) -> pa.Schema: ...
async def next(self) -> Optional[pa.RecordBatch]: ...
```
---------
Co-authored-by: Will Jones <willjones127@gmail.com>
Datafusion makes the batch size available as part of the `SessionState`.
We should use that to set the `max_batch_length` property in the
`QueryExecutionOptions`.
This PR makes it possible to create a table using an asynchronous stream
of input data. Currently only a synchronous iterator is supported. There
are a number of follow-ups not yet tackled:
* Support for embedding functions (the embedding functions wrapper needs
to be re-written to be async, should be an easy lift)
* Support for async input into the remote table (the make_ipc_batch
needs to change to accept async input, leaving undone for now because I
think we want to support actual streaming uploads into the remote table
soon)
* Support for async input into the add function (pretty essential, but
it is a fairly distinct code path, so saving for a different PR)
It seems that `RecordBatch::with_schema` is unable to remove schema
metadata from a batch. It fails with the error `target schema is not
superset of current schema`.
I'm not sure how the `test_metadata_erased` test is passing. Strangely,
the metadata was not present by the time the batch arrived at the
metadata eraser. I think maybe the schema metadata is only present in
the batch if there is a filter.
I've created a new unit test that makes sure the metadata is erased if
we have a filter also
In earlier PRs (#1886, #1191) we made the default limit 10 regardless of
the query type. This was confusing for users and in many cases a
breaking change. Users would have queries that used to return all
results, but instead only returned the first 10, causing silent bugs.
Part of the cause was consistency: the Python sync API seems to have
always had a limit of 10, while newer APIs (Python async and Nodejs)
didn't.
This PR sets the default limit only for searches (vector search, FTS),
while letting scans (even with filters) be unbounded. It does this
consistently for all SDKs.
Fixes#1983Fixes#1852Fixes#2141
This also changes the pylance pin from `==0.23.2` to `~=0.23.2` which
should allow the pylance dependency to float a little. The pylance
dependency is actually not used for much anymore and so it should be
tolerant of patch changes.
BREAKING CHANGE: embedding function implementations in Node need to now
call `resolveVariables()` in their constructors and should **not**
implement `toJSON()`.
This tries to address the handling of secrets. In Node, they are
currently lost. In Python, they are currently leaked into the table
schema metadata.
This PR introduces an in-memory variable store on the function registry.
It also allows embedding function definitions to label certain config
values as "sensitive", and the preprocessing logic will raise an error
if users try to pass in hard-coded values.
Closes#2110Closes#521
---------
Co-authored-by: Weston Pace <weston.pace@gmail.com>
Reviving #1966.
Closes#1938
The `search()` method can apply embeddings for the user. This simplifies
hybrid search, so instead of writing:
```python
vector_query = embeddings.compute_query_embeddings("flower moon")[0]
await (
async_tbl.query()
.nearest_to(vector_query)
.nearest_to_text("flower moon")
.to_pandas()
)
```
You can write:
```python
await (await async_tbl.search("flower moon", query_type="hybrid")).to_pandas()
```
Unfortunately, we had to do a double-await here because `search()` needs
to be async. This is because it often needs to do IO to retrieve and run
an embedding function.
Address usage mistakes in
https://github.com/lancedb/lancedb/issues/2135.
* Add example of how to use `LanceModel` and `Vector` decorator
* Add test for pydantic doc
* Fix the example to directly use LanceModel instead of calling
`MyModel.to_arrow_schema()` in the example.
* Add cross-reference link to pydantic doc site
* Configure mkdocs to watch code changes in python directory.
we found a bug that flat KNN plan node's stats is not in right order as
fields in schema, it would cause an error if querying with distance
range and new unindexed rows.
we've fixed this in lance so add this test for verifying it works
Signed-off-by: BubbleCal <bubble-cal@outlook.com>
panicked at 'index out of bounds: the len is 24 but the index is
25':Lancedb/rust/lancedb/src/index/vector.rs:26\n
load_indices() on the old manifest while use the newer manifest to get
column names could result in index out of bound if some columns are
removed from the new version.
This change reduce the possibility of index out of bound operation but
does not fully remove it.
Better that lance can directly provide column name info so no need extra
calls to get column name but that require modify the public APIs
If we start supporting external catalogs then "drop database" may be
misleading (and not possible). We should be more clear that this is a
utility method to drop all tables. This is also a nice chance for some
consistency cleanup as it was `drop_db` in rust, `drop_database` in
python, and non-existent in typescript.
This PR also adds a public accessor to get the database trait from a
connection.
BREAKING CHANGE: the `drop_database` / `drop_db` methods are now
deprecated.
Similar to
c269524b2f
this PR reworks and exposes an internal trait (this time
`TableInternal`) to be a public trait. These two PRs together should
make it possible for others to integrate LanceDB on top of other
catalogs.
This PR also adds a basic `TableProvider` implementation for tables,
although some work still needs to be done here (pushdown not yet
enabled).
Closes#1106
Unfortunately, these need to be set at the connection level. I
investigated whether if we let users provide a callback they could use
`AsyncLocalStorage` to access their context. However, it doesn't seem
like NAPI supports this right now. I filed an issue:
https://github.com/napi-rs/napi-rs/issues/2456
This opens up the door for more custom database implementations than the
two we have today. The biggest change should be inivisble:
`ConnectionInternal` has been renamed to `Database`, made public, and
refactored
However, there are a few breaking changes. `data_storage_version` and
`enable_v2_manifest_paths` have been moved from options on
`create_table` to options for the database which are now set via
`storage_options`.
Before:
```
db = connect(uri)
tbl = db.create_table("my_table", data, data_storage_version="legacy", enable_v2_manifest_paths=True)
```
After:
```
db = connect(uri, storage_options={
"new_table_enable_v2_manifest_paths": "true",
"new_table_data_storage_version": "legacy"
})
tbl = db.create_table("my_table", data)
```
BREAKING CHANGE: the data_storage_version, enable_v2_manifest_paths
options have moved from options to create_table to storage_options.
BREAKING CHANGE: the use_legacy_format option has been removed,
data_storage_version has replaced it for some time now
* Make `npm run docs` fail if there are any warnings. This will catch
items missing from the API reference.
* Add a check in our CI to make sure `npm run dos` runs without warnings
and doesn't generate any new files (indicating it might be out-of-date.
* Hide constructors that aren't user facing.
* Remove unused enum `WriteMode`.
Closes#2068
Some Rust jobs (such as
[Rust/linux](https://github.com/lancedb/lancedb/actions/runs/13019232960/job/36315830779))
take almost minutes. This can be a bit of a bottleneck.
* Two fixes to make caches more effective
* Check in `Cargo.lock` so that dependencies don't change much between
runs
* Added a new CI job to validate we can build without a lockfile
* Altered build commands so they don't have contradictory features and
therefore don't trigger multiple builds
Sadly, I don't think there's much to be done for windows-arm64, as much
of the compile time is because the base image is so bare we need to
install the build tools ourselves.
This PR aims to fix#2047 by doing the following things:
- Add a distance_type parameter to the sync query builders of Python
SDK.
- Make metric an alias to distance_type.
* `createTable()` now saves embeddings in the schema metadata.
Previously, it would drop them. (`createEmptyTable()` was already tested
and worked.)
* `mergeInsert()` now uses embeddings.
Fixes#2066
Fixes#2031
When we do hybrid search, we normalize the scores. We do this
calculation in-place, because the Rerankers expect the `_distance` and
`_score` columns to be the normalized ones. So I've changed the logic so
that we restore the original distance and scores by matching on row ids.
When calling `replace_field_metadata` we pass in an iter of tuples
`(u32, HashMap<String, String>)`.
That `u32` needs to be the field id from the lance schema
7f60aa0a87/rust/lance-core/src/datatypes/field.rs (L123)
This can sometimes be different than the index of the field in the arrow
schema (e.g. if fields have been dropped).
This PR adds docs that try to clarify what that argument should be, as
well as corrects the usage in the test (which was improperly passing the
index of the arrow schema).
This includes several improvements and fixes to the Python Async query
builders:
1. The API reference docs show all the methods for each builder
2. The hybrid query builder now has all the same setter methods as the
vector search one, so you can now set things like `.distance_type()` on
a hybrid query.
3. Re-rankers are now properly hooked up and tested for FTS and vector
search. Previously the re-rankers were accidentally bypassed in unit
tests, because the builders overrode `.to_arrow()`, but the unit test
called `.to_batches()` which was only defined in the base class. Now all
builders implement `.to_batches()` and leave `.to_arrow()` to the base
class.
4. The `AsyncQueryBase` and `AsyncVectoryQueryBase` setter methods now
return `Self`, which provides the appropriate subclass as the type hint
return value. Previously, `AsyncQueryBase` had them all hard-coded to
`AsyncQuery`, which was unfortunate. (This required bringing in
`typing-extensions` for older Python version, but I think it's worth
it.)
related to #2014
this fixes:
- linear reranker may lost some results if the merging consumes all
vector results earlier than fts results
- linear reranker inverts the fts score but only vector distance can be
inverted
---------
Signed-off-by: BubbleCal <bubble-cal@outlook.com>
BREAKING CHANGE: For a field "vector", list of integers will now be
converted to binary (uint8) vectors instead of f32 vectors. Use float
values instead for f32 vectors.
* Adds proper support for inserting and upserting subsets of the full
schema. I thought I had previously implemented this in #1827, but it
turns out I had not tested carefully enough.
* Refactors `_santize_data` and other utility functions to be simpler
and not require `numpy` or `combine_chunks()`.
* Added a new suite of unit tests to validate sanitization utilities.
## Examples
```python
import pandas as pd
import lancedb
db = lancedb.connect("memory://demo")
intial_data = pd.DataFrame({
"a": [1, 2, 3],
"b": [4, 5, 6],
"c": [7, 8, 9]
})
table = db.create_table("demo", intial_data)
# Insert a subschema
new_data = pd.DataFrame({"a": [10, 11]})
table.add(new_data)
table.to_pandas()
```
```
a b c
0 1 4.0 7.0
1 2 5.0 8.0
2 3 6.0 9.0
3 10 NaN NaN
4 11 NaN NaN
```
```python
# Upsert a subschema
upsert_data = pd.DataFrame({
"a": [3, 10, 15],
"b": [6, 7, 8],
})
table.merge_insert(on="a").when_matched_update_all().when_not_matched_insert_all().execute(upsert_data)
table.to_pandas()
```
```
a b c
0 1 4.0 7.0
1 2 5.0 8.0
2 3 6.0 9.0
3 10 7.0 NaN
4 11 NaN NaN
5 15 8.0 NaN
```
This includes a handful of minor edits I made while reading the docs. In
addition to a few spelling fixes,
* standardize on "rerank" over "re-rank" in prose
* terminate sentences with periods or colons as appropriate
* replace some usage of dashes with colons, such as in "Try it yourself
- <link>"
All changes are surface-level. No changes to semantics or structure.
---------
Co-authored-by: Will Jones <willjones127@gmail.com>
it reports error `AttributeError: 'builtins.FTSQuery' object has no
attribute 'select_columns'`
because we missed `select_columns` method in rust
Signed-off-by: BubbleCal <bubble-cal@outlook.com>
Support hybrid search in both rust and node SDKs.
- Adds a new rerankers package to rust LanceDB, with the implementation
of the default RRF reranker
- Adds a new hybrid package to lancedb, with some helper methods related
to hybrid search such as normalizing scores and converting score column
to rank columns
- Adds capability to LanceDB VectorQuery to perform hybrid search if it
has both a nearest vector and full text search parameters.
- Adds wrappers for reranker implementations to nodejs SDK.
Additional rerankers will be added in followup PRs
https://github.com/lancedb/lancedb/issues/1921
---
Notes about how the rust rerankers are wrapped for calling from JS:
I wanted to keep the core reranker logic, and the invocation of the
reranker by the query code, in Rust. This aligns with the philosophy of
the new node SDK where it's just a thin wrapper around Rust. However, I
also wanted to have support for users who want to add custom rerankers
written in Javascript.
When we add a reranker to the query from Javascript, it adds a special
Rust reranker that has a callback to the Javascript code (which could
then turn around and call an underlying Rust reranker implementation if
desired). This adds a bit of complexity, but overall I think it moves us
in the right direction of having the majority of the query logic in the
underlying Rust SDK while keeping the option open to support custom
Javascript Rerankers.
We upgraded the toolchain in #1960, but didn't realize we hardcoded it
in `npm-publish.yml`. I found if I just removed the hard-coded
toolchain, it selects the correct one.
This didn't fully fix Windows Arm, so I created a follow-up issue here:
https://github.com/lancedb/lancedb/issues/1975
binary vectors and hamming distance can work on only IVF_FLAT, so
introduce them all in this PR.
---------
Signed-off-by: BubbleCal <bubble-cal@outlook.com>
Hi lancedb team,
This PR adds the `bypass_vector_index` logic to the sync API, as
described in [Issue
#535](https://github.com/lancedb/lancedb/issues/535). (Closes#535).
Iv'e implemented it only for the regular vector search. If you think it
should also be supported for FTS, Hybrid, or Empty queries and for the
cloud solution, please let me know, and I’ll be happy to extend it.
Since there’s no `CONTRIBUTING.md` or contribution guidelines, I opted
for the simplest implementation to get this started.
Looking forward to your feedback!
Thanks!
---------
Co-authored-by: Will Jones <willjones127@gmail.com>
* Add `See Also` section to `cleanup_old_files` and `compact_files` so
they know it's linked to `optimize`.
* Fixes link to `compact_files` arguments
* Improves formatting of note.
* Upgrades our toolchain file to v1.83.0, since many dependencies now
have MSRV of 1.81.0
* Reverts Rust changes from #1946 that were working around this in a
dumb way
* Adding an MSRV check
* Reduce MSRV back to 1.78.0
### Changes to sync API
* Updated `LanceTable` and `LanceDBConnection` reprs
* Add `storage_options`, `data_storage_version`, and
`enable_v2_manifest_paths` to sync create table API.
* Add `storage_options` to `open_table` in sync API.
* Add `list_indices()` and `index_stats()` to sync API
* `create_table()` will now create only 1 version when data is passed.
Previously it would always create two versions: 1 to create an empty
table and 1 to add data to it.
### Changes to async API
* Add `embedding_functions` to async `create_table()` API.
* Added `head()` to async API
### Refactors
* Refactor index parameters into dataclasses so they are easier to use
from Python
* Moved most tests to use an in-memory DB so we don't need to create so
many temp directories
Closes#1792Closes#1932
---------
Co-authored-by: Weston Pace <weston.pace@gmail.com>
User reported on Discord, when using
`table.vector_search([np.float16(1.0), np.float16(2.0), ...])`, it
yields `TypeError: 'numpy.float16' object is not iterable`
* Sets `"useCodeBlocks": true`
* Adds a post-processing script `nodejs/typedoc_post_process.js` that
puts the parameter description on the same line as the parameter name,
like it is in our Python docs. This makes the text hierarchy clearer in
those sections and also makes the sections shorter.
db.connect with azure storage account name is supported in async connect
but not sync connect.
Add this functionality
---------
Co-authored-by: Will Jones <willjones127@gmail.com>
* One doctest was running for > 60 seconds in CI, since it was
(unsuccessfully) trying to connect to LanceDB Cloud.
* Fixed the example for `Query::full_text_query()`, which was incorrect.
Previously, whenever `Table.add()` was called, we would write and
re-open the underlying dataset. This was bad for performance, as it
reset the table cache and initiated a lot of IO. It also could be the
source of bugs, since we didn't necessarily pass all the necessary
connection options down when re-opening the table.
Closes#1655
Closes#1791Closes#1764Closes#1897 (Makes this unnecessary)
BREAKING CHANGE: when using azure connection string `az://...` the call
to connect will fail if the azure storage credentials are not set. this
is breaking from the previous behaviour where the call would fail after
connect, when user invokes methods on the connection.
This currently only works for local tables (remote tables cannot be
queried)
This is also exclusive to the sync interface. However, since the pyarrow
dataset interface is synchronous I am not sure if there is much value in
making an async-wrapping variant.
In addition, I added a `to_batches` method to the base query in the sync
API. This already exists in the async API. In the sync API this PR only
adds support for vector queries and scalar queries and not for hybrid or
FTS queries.
fixes that all `neon pack-build` packs are named
`vectordb-linux-x64-musl-*.tgz` even when cross-compiling
adds 2nd param:
`TARGET_TRIPLE=${2:-x86_64-unknown-linux-gnu}`
`npm run pack-build -- -t $TARGET_TRIPLE`
Users who call the remote SDK from code that uses futures (either
`ThreadPoolExecutor` or `asyncio`) can get odd errors like:
```
Traceback (most recent call last):
File "/usr/lib/python3.12/asyncio/events.py", line 88, in _run
self._context.run(self._callback, *self._args)
RuntimeError: cannot enter context: <_contextvars.Context object at 0x7cfe94cdc900> is already entered
```
This PR fixes that by executing all LanceDB futures in a dedicated
thread pool running on a background thread. That way, it doesn't
interact with their threadpool.
The code to support VoyageAI embedding and rerank models was added in
the https://github.com/lancedb/lancedb/pull/1799 PR.
Some of the documentation changes was also made, here adding the
VoyageAI embedding doc link to the index page.
These are my first PRs in lancedb and while i checked the
documentation/code structure, i might missed something important. Please
let me know if any changes required!
# PR Summary
PR fixes the `migration.md` reference in `docs/src/guides/tables.md`. On
the way, it also fixes some typos found in that document.
Signed-off-by: Emmanuel Ferdman <emmanuelferdman@gmail.com>
Hello, this is a simple PR that supports `rustls-tls` feature.
The `reqwest`\`s default TLS `default-tls` is enabled by default, to
dismiss the side-effect.
The user can use `rustls-tls` like this:
```toml
lancedb = { version = "*", default-features = false, features = ["rustls-tls"] }
```
* Test that we can insert subschemas (omit nullable columns) in Python.
* More work is needed to support this in Node. See:
https://github.com/lancedb/lancedb/issues/1832
* Test that we can insert data with nullable schema but no nulls in
non-nullable schema.
* Add `"null"` option for `on_bad_vectors` where we fill with null if
the vector is bad.
* Make null values not considered bad if the field itself is nullable.
Allows users to pass multiple query vector as part of a single query
plan. This just runs the queries in parallel without any further
optimization. It's mostly a convenience.
Previously, I think this was only handled by the sync Python remote API.
This makes it common across all SDKs.
Closes https://github.com/lancedb/lancedb/issues/1803
```python
>>> import lancedb
>>> import asyncio
>>>
>>> async def main():
... db = await lancedb.connect_async("./demo")
... table = await db.create_table("demo", [{"id": 1, "vector": [1, 2, 3]}, {"id": 2, "vector": [4, 5, 6]}], mode="overwrite")
... return await table.query().nearest_to([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0], [4.0, 5.0, 6.0]]).limit(1).to_pandas()
...
>>> asyncio.run(main())
query_index id vector _distance
0 2 2 [4.0, 5.0, 6.0] 0.0
1 1 2 [4.0, 5.0, 6.0] 0.0
2 0 1 [1.0, 2.0, 3.0] 0.0
```
This is done as setup for a PR that will fix the OpenAI dependency
issue.
* [x] FTS examples
* [x] Setup mock openai
* [x] Ran `npm audit fix`
* [x] sentences embeddings test
* [x] Double check formatting of docs examples
Hello team,
I'm the maintainer of [Anteon](https://github.com/getanteon/anteon). We
have created Gurubase.io with the mission of building a centralized,
open-source tool-focused knowledge base. Essentially, each "guru" is
equipped with custom knowledge to answer user questions based on
collected data related to that tool.
I wanted to update you that I've manually added the [LanceDB
Guru](https://gurubase.io/g/lancedb) to Gurubase. LanceDB Guru uses the
data from this repo and data from the
[docs](https://lancedb.github.io/lancedb/) to answer questions by
leveraging the LLM.
In this PR, I showcased the "LanceDB Guru", which highlights that
LanceDB now has an AI assistant available to help users with their
questions. Please let me know your thoughts on this contribution.
Additionally, if you want me to disable LanceDB Guru in Gurubase, just
let me know that's totally fine.
Signed-off-by: Kursat Aktas <kursat.ce@gmail.com>
we don't really need these trait in lancedb, but all fields in `Index`
implement the 2 traits, so do it for possibility to use `Index`
somewhere
Signed-off-by: BubbleCal <bubble-cal@outlook.com>
* Replaces Python implementation of Remote SDK with Rust one.
* Drops dependency on `attrs` and `cachetools`. Makes `requests` an
optional dependency used only for embeddings feature.
* Adds dependency on `nest-asyncio`. This was required to get hybrid
search working.
* Deprecate `request_thread_pool` parameter. We now use the tokio
threadpool.
* Stop caching the `schema` on a remote table. Schema is mutable and
there's no mechanism in place to invalidate the cache.
* Removed the client-side resolution of the vector column. We should
already be resolving this server-side.
* `open_table` uses `POST` not `GET`
* `update` uses `predicate` key not `only_if`
* For FTS search, vector cannot be omitted. It must be passed as empty.
* Added logging of JSON request bodies to debug level logging.
Sometimes it is acceptable to users to only search indexed data and skip
and new un-indexed data. For example, if un-indexed data will be shortly
indexed and they don't mind the delay. In these cases, we can save a lot
of CPU time in search, and provide better latency. Users can activate
this on queries using `fast_search()`.
Fixes several minor issues with Rust remote SDK:
* Delete uses `predicate` not `filter` as parameter
* Update does not return the row value in remote SDK
* Update takes tuples
* Content type returned by query node is wrong, so we shouldn't validate
it. https://github.com/lancedb/sophon/issues/2742
* Data returned by query endpoint is actually an Arrow IPC file, not IPC
stream.
When running `index_stats()` for an FTS index, users would get the
deserialization error:
```
InvalidInput { message: "error deserializing index statistics: unknown variant `Inverted`, expected one of `IvfPq`, `IvfHnswPq`, `IvfHnswSq`, `BTree`, `Bitmap`, `LabelList`, `FTS` at line 1 column 24" }
```
This exposes the `LANCEDB_LOG` environment variable in node, so that
users can now turn on logging.
In addition, fixes a bug where only the top-level error from Rust was
being shown. This PR makes sure the full error chain is included in the
error message. In the future, will improve this so the error chain is
set on the [cause](https://nodejs.org/api/errors.html#errorcause)
property of JS errors https://github.com/lancedb/lancedb/issues/1779Fixes#1774
BREAKING CHANGE: default tokenizer no longer does stemming or stop-word
removal. Users should explicitly turn that option on in the future.
- upgrade lance to 0.19.1
- update the FTS docs
- update the FTS API
Upstream change notes:
https://github.com/lancedb/lance/releases/tag/v0.19.1
---------
Signed-off-by: BubbleCal <bubble-cal@outlook.com>
Co-authored-by: Will Jones <willjones127@gmail.com>
Closes#1741
If we checkout a version, we need to make a `HEAD` request to get the
size of the manifest. The new `checkout_latest()` code path can skip
this IOP. This makes the refresh slightly faster.
## user story
fixes https://github.com/lancedb/lancedb/issues/1480https://github.com/invl/retry has not had an update in 8 years, one if
its sub-dependencies via requirements.txt
(https://github.com/pytest-dev/py) is no longer maintained and has a
high severity vulnerability (CVE-2022-42969).
retry is only used for a single function in the python codebase for a
deprecated helper function `with_embeddings`, which was created for an
older tutorial (https://github.com/lancedb/lancedb/pull/12) [but is now
deprecated](https://lancedb.github.io/lancedb/embeddings/legacy/).
## changes
i backported a limited range of functionality of the `@retry()`
decorator directly into lancedb so that we no longer have a dependency
to the `retry` package.
## tests
```
/Users/james/src/lancedb/python $ ruff check .
All checks passed!
/Users/james/src/lancedb/python $ pytest python/tests/test_embeddings.py
python/tests/test_embeddings.py .......s.... [100%]
================================================================ 11 passed, 1 skipped, 2 warnings in 7.08s ================================================================
```
* Adds nicer errors to remote SDK, that expose useful properties like
`request_id` and `status_code`.
* Makes sure the Python tracebacks print nicely by mapping the `source`
field from a Rust error to the `__cause__` field.
A few bugs uncovered by integration tests:
* We didn't prepend `/v1` to the Table endpoint URLs
* `/create_index` takes `metric_type` not `distance_type`. (This is also
an error in the OpenAPI docs.)
* `/create_index` expects the `metric_type` parameter to always be
lowercase.
* We were writing an IPC file message when we were supposed to send an
IPC stream message.
This PR ports over advanced client configuration present in the Python
`RestfulLanceDBClient` to the Rust one. The goal is to have feature
parity so we can replace the implementation.
* [x] Request timeout
* [x] Retries with backoff
* [x] Request id generation
* [x] User agent (with default tied to library version ✨ )
* [x] Table existence cache
* [ ] Deferred: ~Request id customization (should this just pick up OTEL
trace ids?)~
Fixes#1684
Resovles #1709. Adds `trust_remote_code` as a parameter to the
`TransformersEmbeddingFunction` class with a default of False. Updated
relevant documentation with the same.
BREAKING CHANGE: the return value of `index_stats` method has changed
and all `index_stats` APIs now take index name instead of UUID. Also
several deprecated index statistics methods were removed.
* Removes deprecated methods for individual index statistics
* Aligns public `IndexStatistics` struct with API response from LanceDB
Cloud.
* Implements `index_stats` for remote Rust SDK and Python async API.
- fixes https://github.com/lancedb/lancedb/issues/1697.
- unifies vector column inference logic for remote and local table to
prevent future disparities.
- Updates docstring in RemoteTable to specify empty queries are not
supported
Right now when passing vector and query explicitly for hybrid search ,
vector_column_name is not deduced.
(https://lancedb.github.io/lancedb/hybrid_search/hybrid_search/#hybrid-search-in-lancedb
). Because vector and query can be both none when initialising the
QueryBuilder in this case. This PR forces deduction of query type if it
is set to "hybrid"
- Enforce all rerankers always return _relevance_score. This was already
loosely done in tests before but based on user feedback its better to
always have _relevance_score present in all reranked results
- Deprecate LinearCombinationReranker in docs. And also fix a case where
it would not return _relevance_score if one result set was missing
- Add overloads to Table.search, to preserve the return information
of different types of QueryBuilder objects for LanceTable
- Fix fts_column type annotation by including making it `Optional`
resolves#1550
---------
Co-authored-by: sayandip-dutta <sayandip.dutta@nevaehtech.com>
Co-authored-by: Will Jones <willjones127@gmail.com>
* Adding a simple test facility, which allows you to mock a single
endpoint at a time with a closure.
* Implementing all the database-level endpoints
Table-level APIs will be done in a follow up PR.
---------
Co-authored-by: Weston Pace <weston.pace@gmail.com>
The `ratelimiter` package hasn't been updated in ages and is no longer
maintained. This PR removes the dependency on `ratelimiter` and replaces
it with a custom rate limiter implementation.
---------
Co-authored-by: Will Jones <willjones127@gmail.com>
The new V2 manifest path scheme makes discovering the latest version of
a table constant time on object stores, regardless of the number of
versions in the table. See benchmarks in the PR here:
https://github.com/lancedb/lance/pull/2798Closes#1583
first off, apologies for any folly since i'm new to contributing to
lancedb. this PR is the continuation of [a discord
thread](https://discord.com/channels/1030247538198061086/1030247538667827251/1278844345713299599):
## user story
here's the lance db search query i'd like to run:
```
def search(phrase):
logger.info(f'Searching for phrase: {phrase}')
phrase_embedding = get_embedding(phrase)
df = (table.search((phrase_embedding, phrase), query_type='hybrid')
.limit(10).to_list())
logger.info(f'Success search with row count: {len(df)}')
search('howdy (howdy)')
search('howdy(howdy)')
```
the second search fails due to `ValueError: Syntax Error: howdy(howdy)`
i saw on the
[docs](https://lancedb.github.io/lancedb/fts/#phrase-queries-vs-terms-queries)
that i can use `phrase_query()` to [enable a
flag](https://github.com/lancedb/lancedb/blob/main/python/python/lancedb/query.py#L790-L792)
to wrap the query in double quotes (as well as sanitize single quotes)
prior to sending the query to search. this works for [normal
FTS](https://lancedb.github.io/lancedb/fts/), but the command is
unavailable on [hybrid
search](https://lancedb.github.io/lancedb/hybrid_search/hybrid_search/).
## changes
i added `phrase_query()` function to `LanceHybridQueryBuilder` by
propagating the call down to its `self. _fts_query` object. i'm not too
familiar with the codebase and am not sure if this is the best way to
implement the functionality. feel free to riff on this PR or discard
## tests
```
(lancedb) JamesMPB:python james$ pwd
/Users/james/src/lancedb/python
(lancedb) JamesMPB:python james$ pytest python/tests/test_table.py
python/tests/test_table.py ....................................... [100%]
====================================================== 39 passed, 1 warning in 2.23s =======================================================
```
Though the markdown can be rendered well on GitHub (GFM style?), but it
seems that it's required to insert a blank line between a paragraph and
a list block to make it render well with `mkdocs`?
see also the web page:
https://lancedb.github.io/lancedb/concepts/index_hnsw/
Docs used `get_registry.get(...)` whereas what works is
`get_registry().get(...)`. Fixing the two instances I found. I tested
the open clip version by trying it locally in a Jupyter notebook.
- Both LinearCombination (the current default) and RRF are pretty fast
compared to model based rerankers. RRF is slightly faster.
- In our tests RRF has also been slightly more accurate.
This PR:
- Makes RRF the default reranker
- Removed duplicate docs for rerankers
Refine and improve the language clarity and quality across all example
pages in the documentation to ensure better understanding and
readability.
---------
Co-authored-by: Ayush Chaurasia <ayush.chaurarsia@gmail.com>
Currently, the only documented way of performing hybrid search is by
using embedding API and passing string queries that get automatically
embedded. There are use cases where users might like to pass vectors and
text manually instead.
This ticket contains more information and historical context -
https://github.com/lancedb/lancedb/issues/937
This breaks a undocumented pathway that allowed passing (vector, text)
tuple queries which was intended to be temporary, so this is marked as a
breaking change. For all practical purposes, this should not really
impact most users
### usage
```
results = table.search(query_type="hybrid")
.vector(vector_query)
.text(text_query)
.limit(5)
.to_pandas()
```
Before this we ignored the `fts_columns` parameter, and for now we
support to search on only one column, it could lead to an error if we
have multiple indexed columns for FTS
---------
Signed-off-by: BubbleCal <bubble-cal@outlook.com>
This PR:
- Adds missing license headers
- Integrates with answerdotai Rerankers package
- Updates ColbertReranker to subclass answerdotai package. This is done
to keep backwards compatibility as some users might be used to importing
ColbertReranker directly
- Set `trust_remote_code` to ` True` by default in CrossEncoder and
sentence-transformer based rerankers
- Update ColBertReranker architecture: The current implementation
doesn't use the right arch. This PR uses the implementation in Rerankers
library. Fixes https://github.com/lancedb/lancedb/issues/1546
Benchmark diff (hit rate):
Hybrid - 91 vs 87
reranked vector - 85 vs 80
- Reranking in FTS is basically disabled in main after last week's FTS
updates. I think there's no blocker in supporting that?
- Allow overriding accelerators: Most transformer based Rerankers and
Embedding automatically select device. This PR allows overriding those
settings by passing `device`. Fixes:
https://github.com/lancedb/lancedb/issues/1487
---------
Co-authored-by: BubbleCal <bubble-cal@outlook.com>
Lance now supports FTS, so add it into lancedb Python, TypeScript and
Rust SDKs.
For Python, we still use tantivy based FTS by default because the lance
FTS index now misses some features of tantivy.
For Python:
- Support to create lance based FTS index
- Support to specify columns for full text search (only available for
lance based FTS index)
For TypeScript:
- Change the search method so that it can accept both string and vector
- Support full text search
For Rust
- Support full text search
The others:
- Update the FTS doc
BREAKING CHANGE:
- for Python, this renames the attached score column of FTS from "score"
to "_score", this could be a breaking change for users that rely the
scores
---------
Signed-off-by: BubbleCal <bubble-cal@outlook.com>
Currently targeting the following usage:
```
from lancedb.rerankers import CrossEncoderReranker
reranker = CrossEncoderReranker()
query = "hello"
res1 = table.search(query, vector_column_name="vector").limit(3)
res2 = table.search(query, vector_column_name="text_vector").limit(3)
res3 = table.search(query, vector_column_name="meta_vector").limit(3)
reranked = reranker.rerank_multivector(
[res1, res2, res3],
deduplicate=True,
query=query # some reranker models need query
)
```
- This implements rerank_multivector function in the base reranker so
that all rerankers that implement rerank_vector will automatically have
multivector reranking support
- Special case for RRF reranker that just uses its existing
rerank_hybrid fcn to multi-vector reranking.
---------
Co-authored-by: Weston Pace <weston.pace@gmail.com>
Building with Node 16 produced this error:
```
npm ERR! code ENOENT
npm ERR! syscall chmod
npm ERR! path /io/nodejs/node_modules/apache-arrow-15/bin/arrow2csv.cjs
npm ERR! errno -2
npm ERR! enoent ENOENT: no such file or directory, chmod '/io/nodejs/node_modules/apache-arrow-15/bin/arrow2csv.cjs'
npm ERR! enoent This is related to npm not being able to find a file.
npm ERR! enoent
```
[CI
Failure](https://github.com/lancedb/lancedb/actions/runs/10117131772/job/27981475770).
This looks like it is https://github.com/apache/arrow/issues/43341
Upgrading to Node 18 makes this goes away. Since Node 18 requires glibc
>= 2_28, we had to upgrade the manylinux version we are using. This is
fine since we already state a minimum Node version of 18.
This also upgrades the openssl version we bundle, as well as
consolidates the build files.
### Fix markdown table rendering issue
This PR adds a missing whitespace before a markdown table in the
documentation. This issue causes the table to not render properly in
mkdocs, while it does render properly in GitHub's markdown viewer.
#### Change Details:
- Added a single line of whitespace before the markdown table to ensure
proper rendering in mkdocs.
#### Note:
- I wasn't able to test this fix in the mkdocs environment, but it
should be safe as it only involves adding whitespace which won't break
anything.
---
Cohere supports following input types:
| Input Type | Description |
|-------------------------|---------------------------------------|
| "`search_document`" | Used for embeddings stored in a vector|
| | database for search use-cases. |
| "`search_query`" | Used for embeddings of search queries |
| | run against a vector DB |
| "`semantic_similarity`" | Specifies the given text will be used |
| | for Semantic Textual Similarity (STS) |
| "`classification`" | Used for embeddings passed through a |
| | text classifier. |
| "`clustering`" | Used for the embeddings run through a |
| | clustering algorithm |
Usage Example:
Correct the timeout argument to `connect` in @lancedb/lancedb node SDK.
`RemoteConnectionOptions` specified two fields `connectionTimeout` and
`readTimeout`, probably to be consistent with the python SDK, but only
`connectionTimeout` was being used and it was passed to axios in such a
way that this covered the enture remote request (connect + read). This
change adds a single parameter `timeout` which makes the args to
`connect` consistent with the legacy vectordb sdk.
BREAKING CHANGE: This is a breaking change b/c users who would have
previously been passing `connectionTimeout` will now be expected to pass
`timeout`.
I noticed that setting up a simple project with
[Yarn](https://yarnpkg.com/) failed because unlike others [npm, pnpm,
bun], yarn does not automatically resolve peer dependencies, so i added
a quick note about it in the installation guide.
previously if you tried to install both vectordb and @lancedb/lancedb,
you would get a peer dependency issue due to `vectordb` requiring
`14.0.2` and `@lancedb/lancedb` requiring `15.0.0`. now
`@lancedb/lancedb` should just work with any arrow version 13-17
* Labelled jobs `vectordb` and `lancedb` so it's clear which package
they are for
* Fix permission issue in aarch64 Linux `vectordb` build that has been
blocking release for two months.
* Added Slack notifications for failure of these publish jobs.
We track issues on the GitHub issue tracker. If you are looking for something to
work on, check the [good first issue](https://github.com/lancedb/lancedb/contribute) label. These issues are typically the best described and have the smallest scope.
If there's an issue you are interested in working on, please leave a comment on the issue. This will help us avoid duplicate work. Additionally, if you have questions about the issue, please ask them in the issue comments. We are happy to provide guidance on how to approach the issue.
## Configuring Git
First, fork the repository on GitHub, then clone your fork:
<imgsrc="https://github.com/user-attachments/assets/92dad0a2-2a37-4ce1-b783-0d1b4f30a00c"alt="LanceDB Cloud Public Beta"width="100%"style="max-width: 100%;">
[**How to Install** ](#how-to-install) ✦ [**Detailed Documentation**](https://lancedb.github.io/lancedb/) ✦ [**Tutorials and Recipes**](https://github.com/lancedb/vectordb-recipes/tree/main) ✦ [**Contributors**](#contributors)
**The ultimate multimodal data platform for AI/ML applications.**
LanceDB is designed for fast, scalable, and production-ready vector search. It is built on top of the Lance columnar format. You can store, index, and search over petabytes of multimodal data and vectors with ease.
LanceDB is a central location where developers can build, train and analyze their AI workloads.
</p>
</div>
<hr/>
<br>
LanceDB is an open-source database for vector-search built with persistent storage, which greatly simplifies retrieval, filtering and management of embeddings.
## **Demo: Multimodal Search by Keyword, Vector or with SQL**
* Store, query and filter vectors, metadata and multi-modal data (text, images, videos, point clouds, and more).
## **Key Features**:
*Support for vector similarity search, full-text search and SQL.
-**Fast Vector Search**: Search billions of vectors in milliseconds with state-of-the-art indexing.
- **Comprehensive Search**: Support for vector similarity search, full-text search and SQL.
- **Multimodal Support**: Store, query and filter vectors, metadata and multimodal data (text, images, videos, point clouds, and more).
- **Advanced Features**: Zero-copy, automatic versioning, manage versions of your data without needing extra infrastructure. GPU support in building vector index.
* Native Python and Javascript/Typescript support.
### **Products**:
- **Open Source & Local**: 100% open source, runs locally or in your cloud. No vendor lock-in.
- **Cloud and Enterprise**: Production-scale vector search with no servers to manage. Complete data sovereignty and security.
* Zero-copy, automatic versioning, manage versions of your data without needing extra infrastructure.
### **Ecosystem**:
- **Columnar Storage**: Built on the Lance columnar format for efficient storage and analytics.
- **Seamless Integration**: Python, Node.js, Rust, and REST APIs for easy integration. Native Python and Javascript/Typescript support.
- **Rich Ecosystem**: Integrations with [**LangChain** 🦜️🔗](https://python.langchain.com/docs/integrations/vectorstores/lancedb/), [**LlamaIndex** 🦙](https://gpt-index.readthedocs.io/en/latest/examples/vector_stores/LanceDBIndexDemo.html), Apache-Arrow, Pandas, Polars, DuckDB and more on the way.
* GPU support in building vector index(*).
## **How to Install**:
* Ecosystem integrations with [LangChain 🦜️🔗](https://python.langchain.com/docs/integrations/vectorstores/lancedb/), [LlamaIndex 🦙](https://gpt-index.readthedocs.io/en/latest/examples/vector_stores/LanceDBIndexDemo.html), Apache-Arrow, Pandas, Polars, DuckDB and more on the way.
Follow the [Quickstart](https://lancedb.github.io/lancedb/basic/) doc to set up LanceDB locally.
LanceDB's core is written in Rust 🦀 and is built using <ahref="https://github.com/lancedb/lance">Lance</a>, an open-source columnar format designed for performant ML workloads.
**API & SDK:** We also support Python, Typescript and Rust SDKs
We welcome contributions from everyone! Whether you're a developer, researcher, or just someone who wants to help out.
consttable=awaitdb.createTable({
name:'vectors',
data:[
{id:1,vector:[0.1,0.2],item:"foo",price:10},
{id:2,vector:[1.1,1.2],item:"bar",price:50}
]
})
If you have any suggestions or feature requests, please feel free to open an issue on GitHub or discuss it on our [**Discord**](https://discord.gg/G5DcmnZWKB) server.
constquery=table.search([0.1,0.3]).limit(2);
constresults=awaitquery.execute();
[**Check out the GitHub Issues**](https://github.com/lancedb/lancedb/issues) if you would like to work on the features that are planned for the future. If you have any suggestions or feature requests, please feel free to open an issue on GitHub.
// You can also search for rows by specific criteria without involving a vector search.
* 📈 <ahref="https://blog.lancedb.com/benchmarking-random-access-in-lance/">2000x better performance with Lance over Parquet</a>
* 🤖 <ahref="https://github.com/lancedb/lancedb/blob/main/docs/src/notebooks/youtube_transcript_search.ipynb">Build a question and answer bot with LanceDB</a>
parser=argparse.ArgumentParser(description="Set the version of the Lance package.")
parser.add_argument(
"version",
type=str,
help="The version to set for the Lance package. Use 'stable' for the latest stable version, 'preview' for latest preview version, or a specific version number (e.g., '0.1.0'). You can also specify 'local' to use a local path.",
📚 Starting June 1st, 2025, please use <ahref="https://lancedb.github.io/documentation"target="_blank"rel="noopener noreferrer">lancedb.github.io/documentation</a> for the latest docs.
@@ -70,7 +69,7 @@ Lance supports `IVF_PQ` index type by default.
The following IVF_PQ paramters can be specified:
- **distance_type**: The distance metric to use. By default it uses euclidean distance "`L2`".
- **distance_type**: The distance metric to use. By default it uses euclidean distance "`l2`".
We also support "cosine" and "dot" distance as well.
- **num_partitions**: The number of partitions in the index. The default is the square root
of the number of rows.
@@ -83,6 +82,7 @@ The following IVF_PQ paramters can be specified:
- **num_sub_vectors**: The number of sub-vectors (M) that will be created during Product Quantization (PQ).
For D dimensional vector, it will be divided into `M` subvectors with dimension `D/M`, each of which is replaced by
a single PQ code. The default is the dimension of the vector divided by 16.
- **num_bits**: The number of bits used to encode each sub-vector. Only 4 and 8 are supported. The higher the number of bits, the higher the accuracy of the index, also the slower search. The default is 8.
!!! note
@@ -126,7 +126,9 @@ You can specify the GPU device to train IVF partitions via
accelerator="mps"
)
```
!!! note
GPU based indexing is not yet supported with our asynchronous client.
Troubleshooting:
If you see `AssertionError: Torch not compiled with CUDA enabled`, you need to [install
@@ -140,23 +142,27 @@ There are a couple of parameters that can be used to fine-tune the search:
- **limit** (default: 10): The amount of results that will be returned
- **nprobes** (default: 20): The number of probes used. A higher number makes search more accurate but also slower.<br/>
Most of the time, setting nprobes to cover 5-10% of the dataset should achieve high recall with low latency.<br/>
e.g., for 1M vectors divided up into 256 partitions, nprobes should be set to ~20-40.<br/>
Note: nprobes is only applicable if an ANN index is present. If specified on a table without an ANN index, it is ignored.
Most of the time, setting nprobes to cover 5-15% of the dataset should achieve high recall with low latency.<br/>
- _For example_, For a dataset of 1 million vectors divided into 256 partitions, `nprobes` should be set to ~20-40. This value can be adjusted to achieve the optimal balance between search latency and search quality. <br/>
- **refine_factor** (default: None): Refine the results by reading extra elements and re-ranking them in memory.<br/>
A higher number makes search more accurate but also slower. If you find the recall is less than ideal, try refine_factor=10 to start.<br/>
e.g., for 1M vectors divided into 256 partitions, if you're looking for top 20, then refine_factor=200 reranks the whole partition.<br/>
Note: refine_factor is only applicable if an ANN index is present. If specified on a table without an ANN index, it is ignored.
- _For example_, For a dataset of 1 million vectors divided into 256 partitions, setting the `refine_factor` to 200 will initially retrieve the top 4,000 candidates (top k * refine_factor) from all searched partitions. These candidates are then reranked to determine the final top 20 results.<br/>
!!! note
Both `nprobes` and `refine_factor` are only applicable if an ANN index is present. If specified on a table without an ANN index, those parameters are ignored.
@@ -273,9 +291,17 @@ Product quantization can lead to approximately `16 * sizeof(float32) / 1 = 64` t
`num_partitions` is used to decide how many partitions the first level `IVF` index uses.
Higher number of partitions could lead to more efficient I/O during queries and better accuracy, but it takes much more time to train.
On `SIFT-1M` dataset, our benchmark shows that keeping each partition 1K-4K rows lead to a good latency / recall.
On `SIFT-1M` dataset, our benchmark shows that keeping each partition 4K-8K rows lead to a good latency / recall.
`num_sub_vectors` specifies how many Product Quantization (PQ) short codes to generate on each vector. Because
`num_sub_vectors` specifies how many Product Quantization (PQ) short codes to generate on each vector. The number should be a factor of the vector dimension. Because
PQ is a lossy compression of the original vector, a higher `num_sub_vectors` usually results in
less space distortion, and thus yields better accuracy. However, a higher `num_sub_vectors` also causes heavier I/O and
more PQ computation, and thus, higher latency. `dimension / num_sub_vectors` should be a multiple of 8 for optimum SIMD efficiency.
less space distortion, and thus yields better accuracy. However, a higher `num_sub_vectors` also causes heavier I/O and more PQ computation, and thus, higher latency. `dimension / num_sub_vectors` should be a multiple of 8 for optimum SIMD efficiency.
!!! note
if `num_sub_vectors` is set to be greater than the vector dimension, you will see errors like `attempt to divide by zero`
### How to choose `m` and `ef_construction` for `IVF_HNSW_*` index?
`m` determines the number of connections a new node establishes with its closest neighbors upon entering the graph. Typically, `m` falls within the range of 5 to 48. Lower `m` values are suitable for low-dimensional data or scenarios where recall is less critical. Conversely, higher `m` values are beneficial for high-dimensional data or when high recall is required. In essence, a larger `m` results in a denser graph with increased connectivity, but at the expense of higher memory consumption.
`ef_construction` balances build speed and accuracy. Higher values increase accuracy but slow down the build process. A typical range is 150 to 300. For good search results, a minimum value of 100 is recommended. In most cases, setting this value above 500 offers no additional benefit. Ensure that `ef_construction` is always set to a value equal to or greater than `ef` in the search phase
Unlike other package managers, Yarn does not automatically resolve peer dependencies. If you are using Yarn, you will need to manually install 'apache-arrow':
```shell
yarn add apache-arrow
```
=== "vectordb (deprecated)"
```shell
@@ -53,6 +62,15 @@
}
})
```
!!! note "Yarn users"
Unlike other package managers, Yarn does not automatically resolve peer dependencies. If you are using Yarn, you will need to manually install 'apache-arrow':
```shell
yarn add apache-arrow
```
=== "Rust"
```shell
@@ -115,21 +133,22 @@ recommend switching to stable releases.
LanceDB comes with Pydantic support, which allows you to define the schema of your data using Pydantic models. This makes it easy to work with LanceDB tables and data. Learn more about all supported types in [tables guide](./guides/tables.md).
@@ -250,7 +287,7 @@ similar to a `CREATE TABLE` statement in SQL.
This section provides answers to the most common questions asked about LanceDB Cloud. By following these guidelines, you can ensure a smooth, performant experience with LanceDB Cloud.
### Should I reuse the database connection?
Yes! It is recommended to establish a single database connection and maintain it throughout your interaction with the tables within.
LanceDB uses HTTP connections to communicate with the servers. By re-using the Connection object, you avoid the overhead of repeatedly establishing HTTP connections, significantly improving efficiency.
### Should I re-use the `Table` object?
`table = db.open_table()` should be called once and used for all subsequent table operations. If there are changes to the opened table, `table` always reflect the **latest version** of the data.
### What should I do if I need to search for rows by `id`?
LanceDB Cloud currently does not support an ID or primary key column. You are recommended to add a
user-defined ID column. To significantly improve the query performance with SQL causes, a scalar BITMAP/BTREE index should be created on this column.
### What are the vector indexing types supported by LanceDB Cloud?
We support `IVF_PQ` and `IVF_HNSW_SQ` as the `index_type` which is passed to `create_index`. LanceDB Cloud tunes the indexing parameters automatically to achieve the best tradeoff between query latency and query quality.
### When I add new rows to a table, do I need to manually update the index?
No! LanceDB Cloud triggers an asynchronous background job to index the new vectors.
Even though indexing is asynchronous, your vectors will still be immediately searchable. LanceDB uses brute-force search to search over unindexed rows. This makes you new data is immediately available, but does increase latency temporarily. To disable the brute-force part of search, set the `fast_search` flag in your query to `true`.
### Do I need to reindex the whole dataset if only a small portion of the data is deleted or updated?
No! Similar to adding data to the table, LanceDB Cloud triggers an asynchronous background job to update the existing indices. Therefore, no action is needed from users and there is absolutely no
downtime expected.
### How do I know whether an index has been created?
While index creation in LanceDB Cloud is generally fast, querying immediately after a `create_index` call may result in errors. It's recommended to use `list_indices` to verify index creation before querying.
### Why is my query latency higher than expected?
Multiple factors can impact query latency. To reduce query latency, consider the following:
- Send pre-warm queries: send a few queries to warm up the cache before an actual user query.
- Check network latency: LanceDB Cloud is hosted in AWS `us-east-1` region. It is recommended to run queries from an EC2 instance that is in the same region.
- Create scalar indices: If you are filtering on metadata, it is recommended to create scalar indices on those columns. This will speedup searches with metadata filtering. See [here](../guides/scalar_index.md) for more details on creating a scalar index.
LanceDB Cloud is a SaaS (software-as-a-service) solution that runs serverless in the cloud, clearly separating storage from compute. It's designed to be highly scalable without breaking the bank. LanceDB Cloud is currently in private beta with general availability coming soon, but you can apply for early access with the private beta release by signing up below.
[Try out LanceDB Cloud](https://noteforms.com/forms/lancedb-mailing-list-cloud-kty1o5?notionforms=1&utm_source=notionforms){ .md-button .md-button--primary }
[Try out LanceDB Cloud (Public Beta)](https://cloud.lancedb.com){ .md-button .md-button--primary }
@@ -13,7 +13,7 @@ The following concepts are important to keep in mind:
- Data is versioned, with each insert operation creating a new version of the dataset and an update to the manifest that tracks versions via metadata
!!! note
1. First, each version contains metadata and just the new/updated data in your transaction. So if you have 100 versions, they aren't 100 duplicates of the same data. However, they do have 100x the metadata overhead of a single version, which can result in slower queries.
1. First, each version contains metadata and just the new/updated data in your transaction. So if you have 100 versions, they aren't 100 duplicates of the same data. However, they do have 100x the metadata overhead of a single version, which can result in slower queries.
2. Second, these versions exist to keep LanceDB scalable and consistent. We do not immediately blow away old versions when creating new ones because other clients might be in the middle of querying the old version. It's important to retain older versions for as long as they might be queried.
## What are fragments?
@@ -37,6 +37,10 @@ Depending on the use case and dataset, optimal compaction will have different re
- It’s always better to use *batch* inserts rather than adding 1 row at a time (to avoid too small fragments). If single-row inserts are unavoidable, run compaction on a regular basis to merge them into larger fragments.
- Keep the number of fragments under 100, which is suitable for most use cases (for *really* large datasets of >500M rows, more fragments might be needed)
!!! note
LanceDB Cloud/Enterprise supports [auto-compaction](https://docs.lancedb.com/enterprise/architecture/architecture#write-path) which automatically optimizes fragments in the background as data changes.
## Deletion
Although Lance allows you to delete rows from a dataset, it does not actually delete the data immediately. It simply marks the row as deleted in the `DataFile` that represents a fragment. For a given version of the dataset, each fragment can have up to one deletion file (if no rows were ever deleted from that fragment, it will not have a deletion file). This is important to keep in mind because it means that the data is still there, and can be recovered if needed, as long as that version still exists based on your backup policy.
@@ -50,13 +54,9 @@ Reindexing is the process of updating the index to account for new data, keeping
Both LanceDB OSS and Cloud support reindexing, but the process (at least for now) is different for each, depending on the type of index.
When a reindex job is triggered in the background, the entire data is reindexed, but in the interim as new queries come in, LanceDB will combine results from the existing index with exhaustive kNN search on the new data. This is done to ensure that you're still searching on all your data, but it does come at a performance cost. The more data that you add without reindexing, the impact on latency (due to exhaustive search) can be noticeable.
In LanceDB OSS, re-indexing happens synchronously when you call either `create_index` or `optimize` on a table. In LanceDB Cloud, re-indexing happens asynchronously as you add and update data in your table.
### Vector reindex
By default, queries will search new data even if it has yet to be indexed. This is done using brute-force methods, such as kNN for vector search, and combined with the fast index search results. This is done to ensure that you're always searching over all your data, but it does come at a performance cost. Without reindexing, adding more data to a table will make queries slower and more expensive. This behavior can be disabled by setting the [fast_search](https://lancedb.github.io/lancedb/python/python/#lancedb.query.AsyncQuery.fast_search) parameter which will instruct the query to ignore un-indexed data.
* LanceDB Cloud supports incremental reindexing, where a background process will trigger a new index build for you automatically when new data is added to a dataset
* LanceDB Cloud/Enterprise supports [automatic incremental reindexing](https://docs.lancedb.com/core#vector-index) for vector, scalar, and FTS indices, where a background process will trigger a new index build for you automatically when new data is added or modified in a dataset
* LanceDB OSS requires you to manually trigger a reindex operation -- we are working on adding incremental reindexing to LanceDB OSS as well
### FTS reindex
FTS reindexing is supported in both LanceDB OSS and Cloud, but requires that it's manually rebuilt once you have a significant enough amount of new data added that needs to be reindexed. We [updated](https://github.com/lancedb/lancedb/pull/762) Tantivy's default heap size from 128MB to 1GB in LanceDB to make it much faster to reindex, by up to 10x from the default settings.
Approximate Nearest Neighbor (ANN) search is a method for finding data points near a given point in a dataset, though not always the exact nearest one. HNSW is one of the most accurate and fastest Approximate Nearest Neighbour search algorithms, It’s beneficial in high-dimensional spaces where finding the same nearest neighbor would be too slow and costly
[Jump to usage](#usage)
There are three main types of ANN search algorithms:
* **Tree-based search algorithms**: Use a tree structure to organize and store data points.
* **Hash-based search algorithms**: Use a specialized geometric hash table to store and manage data points. These algorithms typically focus on theoretical guarantees, and don't usually perform as well as the other approaches in practice.
* **Graph-based search algorithms**: Use a graph structure to store data points, which can be a bit complex.
HNSW is a graph-based algorithm. All graph-based search algorithms rely on the idea of a k-nearest neighbor (or k-approximate nearest neighbor) graph, which we outline below.
HNSW also combines this with the ideas behind a classic 1-dimensional search data structure: the skip list.
## k-Nearest Neighbor Graphs and k-approximate Nearest neighbor Graphs
The k-nearest neighbor graph actually predates its use for ANN search. Its construction is quite simple:
* Each vector in the dataset is given an associated vertex.
* Each vertex has outgoing edges to its k nearest neighbors. That is, the k closest other vertices by Euclidean distance between the two corresponding vectors. This can be thought of as a "friend list" for the vertex.
* For some applications (including nearest-neighbor search), the incoming edges are also added.
Eventually, it was realized that the following greedy search method over such a graph typically results in good approximate nearest neighbors:
* Given a query vector, start at some fixed "entry point" vertex (e.g. the approximate center node).
* Look at that vertex's neighbors. If any of them are closer to the query vector than the current vertex, then move to that vertex.
* Repeat until a local optimum is found.
The above algorithm also generalizes to e.g. top 10 approximate nearest neighbors.
Computing a k-nearest neighbor graph is actually quite slow, taking quadratic time in the dataset size. It was quickly realized that near-identical performance can be achieved using a k-approximate nearest neighbor graph. That is, instead of obtaining the k-nearest neighbors for each vertex, an approximate nearest neighbor search data structure is used to build much faster.
In fact, another data structure is not needed: This can be done "incrementally".
That is, if you start with a k-ANN graph for n-1 vertices, you can extend it to a k-ANN graph for n vertices as well by using the graph to obtain the k-ANN for the new vertex.
One downside of k-NN and k-ANN graphs alone is that one must typically build them with a large value of k to get decent results, resulting in a large index.
## HNSW: Hierarchical Navigable Small Worlds
HNSW builds on k-ANN in two main ways:
* Instead of getting the k-approximate nearest neighbors for a large value of k, it sparsifies the k-ANN graph using a carefully chosen "edge pruning" heuristic, allowing for the number of edges per vertex to be limited to a relatively small constant.
* The "entry point" vertex is chosen dynamically using a recursively constructed data structure on a subset of the data, similarly to a skip list.
This recursive structure can be thought of as separating into layers:
* At the bottom-most layer, an k-ANN graph on the whole dataset is present.
* At the second layer, a k-ANN graph on a fraction of the dataset (e.g. 10%) is present.
* At the Lth layer, a k-ANN graph is present. It is over a (constant) fraction (e.g. 10%) of the vectors/vertices present in the L-1th layer.
Then the greedy search routine operates as follows:
* At the top layer (using an arbitrary vertex as an entry point), use the greedy local search routine on the k-ANN graph to get an approximate nearest neighbor at that layer.
* Using the approximate nearest neighbor found in the previous layer as an entry point, find an approximate nearest neighbor in the next layer with the same method.
* Repeat until the bottom-most layer is reached. Then use the entry point to find multiple nearest neighbors (e.g. top 10).
## Usage
There are three key parameters to set when constructing an HNSW index:
*`metric`: Use an `l2` euclidean distance metric. We also support `dot` and `cosine` distance.
*`m`: The number of neighbors to select for each vector in the HNSW graph.
*`ef_construction`: The number of candidates to evaluate during the construction of the HNSW graph.
We can combine the above concepts to understand how to build and query an HNSW index in LanceDB.
`num_partitions`=256 and `num_sub_vectors`=96 does not work for every dataset. Those values needs to be adjusted for your particular dataset.
The `num_partitions` is usually chosen to target a particular number of vectors per partition. `num_sub_vectors` is typically chosen based on the desired recall and the dimensionality of the vector. See the [FAQs](#faq) below for best practices on choosing these parameters.
The `num_partitions` is usually chosen to target a particular number of vectors per partition. `num_sub_vectors` is typically chosen based on the desired recall and the dimensionality of the vector. See [here](../ann_indexes.md/#how-to-choose-num_partitions-and-num_sub_vectors-for-ivf_pq-index) for best practices on choosing these parameters.
We have support for [imagebind](https://github.com/facebookresearch/ImageBind) model embeddings. You can download our version of the packaged model via - `pip install imagebind-packaged==0.1.2`.
This function is registered as `imagebind` and supports Audio, Video and Text modalities(extending to Thermal,Depth,IMU data):
| Parameter | Type | Default Value | Description |
|---|---|---|---|
| `name` | `str` | `"imagebind_huge"` | Name of the model. |
| `device` | `str` | `"cpu"` | The device to run the model on. Can be `"cpu"` or `"gpu"`. |
| `normalize` | `bool` | `False` | set to `True` to normalize your inputs before model ingestion. |
Below is an example demonstrating how the API works:
If you have any questions about the embeddings API, supported models, or see a relevant model missing, please raise an issue [on GitHub](https://github.com/lancedb/lancedb/issues).
We support CLIP model embeddings using the open source alternative, [open-clip](https://github.com/mlfoundations/open_clip) which supports various customizations. It is registered as `open-clip` and supports the following customizations:
| Parameter | Type | Default Value | Description |
|---|---|---|---|
| `name` | `str` | `"ViT-B-32"` | The name of the model. |
| `pretrained` | `str` | `"laion2b_s34b_b79k"` | The name of the pretrained model to load. |
| `device` | `str` | `"cpu"` | The device to run the model on. Can be `"cpu"` or `"gpu"`. |
| `batch_size` | `int` | `64` | The number of images to process in a batch. |
| `normalize` | `bool` | `True` | Whether to normalize the input images before feeding them to the model. |
This embedding function supports ingesting images as both bytes and urls. You can query them using both test and other images.
!!! info
LanceDB supports ingesting images directly from accessible links.
```python
importlancedb
fromlancedb.pydanticimportLanceModel,Vector
fromlancedb.embeddingsimportget_registry
db=lancedb.connect(tmp_path)
func=get_registry().get("open-clip").create()
classImages(LanceModel):
label:str
image_uri:str=func.SourceField()# image uri as the source
image_bytes:bytes=func.SourceField()# image bytes as the source
AWS Bedrock supports multiple base models for generating text embeddings. You need to setup the AWS credentials to use this embedding function.
You can do so by using `awscli` and also add your session_token:
```shell
aws configure
aws configure set aws_session_token "<your_session_token>"
```
to ensure that the credentials are set up correctly, you can run the following command:
```shell
aws sts get-caller-identity
```
Supported Embedding modelIDs are:
*`amazon.titan-embed-text-v1`
*`cohere.embed-english-v3`
*`cohere.embed-multilingual-v3`
Supported parameters (to be passed in `create` method) are:
| Parameter | Type | Default Value | Description |
|---|---|---|---|
| **name** | str | "amazon.titan-embed-text-v1" | The model ID of the bedrock model to use. Supported base models for Text Embeddings: amazon.titan-embed-text-v1, cohere.embed-english-v3, cohere.embed-multilingual-v3 |
| **region** | str | "us-east-1" | Optional name of the AWS Region in which the service should be called (e.g., "us-east-1"). |
| **profile_name** | str | None | Optional name of the AWS profile to use for calling the Bedrock service. If not specified, the default profile will be used. |
| **assumed_role** | str | None | Optional ARN of an AWS IAM role to assume for calling the Bedrock service. If not specified, the current active credentials will be used. |
| **role_session_name** | str | "lancedb-embeddings" | Optional name of the AWS IAM role session to use for calling the Bedrock service. If not specified, a "lancedb-embeddings" name will be used. |
| **runtime** | bool | True | Optional choice of getting different client to perform operations with the Amazon Bedrock service. |
| **max_retries** | int | 7 | Optional number of retries to perform when a request fails. |
Using cohere API requires cohere package, which can be installed using `pip install cohere`. Cohere embeddings are used to generate embeddings for text data. The embeddings can be used for various tasks like semantic search, clustering, and classification.
You also need to set the `COHERE_API_KEY` environment variable to use the Cohere API.
Supported models are:
- embed-english-v3.0
- embed-multilingual-v3.0
- embed-english-light-v3.0
- embed-multilingual-light-v3.0
- embed-english-v2.0
- embed-english-light-v2.0
- embed-multilingual-v2.0
Supported parameters (to be passed in `create` method) are:
| Parameter | Type | Default Value | Description |
|---|---|--------|---------|
| `name` | `str` | `"embed-english-v2.0"` | The model ID of the cohere model to use. Supported base models for Text Embeddings: embed-english-v3.0, embed-multilingual-v3.0, embed-english-light-v3.0, embed-multilingual-light-v3.0, embed-english-v2.0, embed-english-light-v2.0, embed-multilingual-v2.0 |
| `source_input_type` | `str` | `"search_document"` | The type of input data to be used for the source column. |
| `query_input_type` | `str` | `"search_query"` | The type of input data to be used for the query. |
With Google's Gemini, you can represent text (words, sentences, and blocks of text) in a vectorized form, making it easier to compare and contrast embeddings. For example, two texts that share a similar subject matter or sentiment should have similar embeddings, which can be identified through mathematical comparison techniques such as cosine similarity. For more on how and why you should use embeddings, refer to the Embeddings guide.
The Gemini Embedding Model API supports various task types:
| "`retrieval_query`" | Specifies the given text is a query in a search/retrieval setting. |
| "`retrieval_document`" | Specifies the given text is a document in a search/retrieval setting. Using this task type requires a title but is automatically proided by Embeddings API |
| "`semantic_similarity`" | Specifies the given text will be used for Semantic Textual Similarity (STS). |
| "`classification`" | Specifies that the embeddings will be used for classification. |
| "`clusering`" | Specifies that the embeddings will be used for clustering. |
We offer support for all Hugging Face models (which can be loaded via [transformers](https://huggingface.co/docs/transformers/en/index) library). The default model is `colbert-ir/colbertv2.0` which also has its own special callout - `registry.get("colbert")`. Some Hugging Face models might require custom models defined on the HuggingFace Hub in their own modeling files. You may enable this by setting `trust_remote_code=True`. This option should only be set to True for repositories you trust and in which you have read the code, as it will execute code present on the Hub on your local machine.
Generate text embeddings using IBM's watsonx.ai platform.
## Supported Models
You can find a list of supported models at [IBM watsonx.ai Documentation](https://dataplatform.cloud.ibm.com/docs/content/wsj/analyze-data/fm-models-embed.html?context=wx). The currently supported model names are:
-`ibm/slate-125m-english-rtrvr`
-`ibm/slate-30m-english-rtrvr`
-`sentence-transformers/all-minilm-l12-v2`
-`intfloat/multilingual-e5-large`
## Parameters
The following parameters can be passed to the `create` method:
| Parameter | Type | Default Value | Description |
[Instructor](https://instructor-embedding.github.io/) is an instruction-finetuned text embedding model that can generate text embeddings tailored to any task (e.g. classification, retrieval, clustering, text evaluation, etc.) and domains (e.g. science, finance, etc.) by simply providing the task instruction, without any finetuning.
If you want to calculate customized embeddings for specific sentences, you can follow the unified template to write instructions.
!!! info
Represent the `domain``text_type` for `task_objective`:
*`domain` is optional, and it specifies the domain of the text, e.g. science, finance, medicine, etc.
*`text_type` is required, and it specifies the encoding unit, e.g. sentence, document, paragraph, etc.
*`task_objective` is optional, and it specifies the objective of embedding, e.g. retrieve a document, classify the sentence, etc.
More information about the model can be found at the [source URL](https://github.com/xlang-ai/instructor-embedding).
| Argument | Type | Default | Description |
|---|---|---|---|
| `name` | `str` | "hkunlp/instructor-base" | The name of the model to use |
| `batch_size` | `int` | `32` | The batch size to use when generating embeddings |
| `device` | `str` | `"cpu"` | The device to use when generating embeddings |
| `show_progress_bar` | `bool` | `True` | Whether to show a progress bar when generating embeddings |
| `normalize_embeddings` | `bool` | `True` | Whether to normalize the embeddings |
| `quantize` | `bool` | `False` | Whether to quantize the model |
| `source_instruction` | `str` | `"represent the docuement for retreival"` | The instruction for the source column |
| `query_instruction` | `str` | `"represent the document for retreiving the most similar documents"` | The instruction for the query |
LanceDB registers the OpenAI embeddings function in the registry by default, as `openai`. Below are the parameters that you can customize when creating the instances:
| Parameter | Type | Default Value | Description |
|---|---|---|---|
| `name` | `str` | `"text-embedding-ada-002"` | The name of the model. |
| `dim` | `int` | Model default | For OpenAI's newer text-embedding-3 model, we can specify a dimensionality that is smaller than the 1536 size. This feature supports it |
| `use_azure` | bool | `False` | Set true to use Azure OpenAPI SDK |
You can also load many other model architectures from the library. For example models from sources such as BAAI, nomic, salesforce research, etc.
See this HF hub page for all [supported models](https://huggingface.co/models?library=sentence-transformers).
!!! note "BAAI Embeddings example"
Here is an example that uses BAAI embedding model from the HuggingFace Hub [supported models](https://huggingface.co/models?library=sentence-transformers)
```python
import lancedb
from lancedb.pydantic import LanceModel, Vector
from lancedb.embeddings import get_registry
db = lancedb.connect("/tmp/db")
model = get_registry().get("sentence-transformers").create(name="BAAI/bge-small-en-v1.5", device="cpu")
Voyage AI provides cutting-edge embedding and rerankers.
Using voyageai API requires voyageai package, which can be installed using `pip install voyageai`. Voyage AI embeddings are used to generate embeddings for text data. The embeddings can be used for various tasks like semantic search, clustering, and classification.
You also need to set the `VOYAGE_API_KEY` environment variable to use the VoyageAI API.
Supported models are:
- voyage-3
- voyage-3-lite
- voyage-finance-2
- voyage-multilingual-2
- voyage-law-2
- voyage-code-2
Supported parameters (to be passed in `create` method) are:
| Parameter | Type | Default Value | Description |
|---|---|--------|---------|
| `name` | `str` | `None` | The model ID of the model to use. Supported base models for Text Embeddings: voyage-3, voyage-3-lite, voyage-finance-2, voyage-multilingual-2, voyage-law-2, voyage-code-2 |
| `input_type` | `str` | `None` | Type of the input text. Default to None. Other options: query, document. |
| `truncation` | `bool` | `True` | Whether to truncate the input texts to fit within the context length. |
@@ -15,198 +15,234 @@ There is another optional layer of abstraction available: `TextEmbeddingFunction
Let's implement `SentenceTransformerEmbeddings` class. All you need to do is implement the `generate_embeddings()` and `ndims` function to handle the input types you expect and register the class in the global `EmbeddingFunctionRegistry`
method. This prevents users from accidentally instantiating the embedding
function with hard-coded secrets.
Now you can use this embedding function to create your table schema and that's it! you can then ingest data and run queries without manually vectorizing the inputs.
You can always implement the `EmbeddingFunction` interface directly if you want or need to, `TextEmbeddingFunction` just makes it much simpler and faster for you to do so, by setting up the boiler plat for text-specific use case
You can always implement the `EmbeddingFunction` interface directly if you want or need to, `TextEmbeddingFunction` just makes it much simpler and faster for you to do so, by setting up the boiler plat for text-specific use case
## Multi-modal embedding function example
You can also use the `EmbeddingFunction` interface to implement more complex workflows such as multi-modal embedding function support. LanceDB implements `OpenClipEmeddingFunction` class that suppports multi-modal seach. Here's the implementation that you can use as a reference to build your own multi-modal embedding functions.
You can also use the `EmbeddingFunction` interface to implement more complex workflows such as multi-modal embedding function support.
```python
@register("open-clip")
classOpenClipEmbeddings(EmbeddingFunction):
name:str="ViT-B-32"
pretrained:str="laion2b_s34b_b79k"
device:str="cpu"
batch_size:int=64
normalize:bool=True
_model=PrivateAttr()
_preprocess=PrivateAttr()
_tokenizer=PrivateAttr()
=== "Python"
def__init__(self,*args,**kwargs):
super().__init__(*args,**kwargs)
open_clip=attempt_import_or_raise("open_clip","open-clip")# EmbeddingFunction util to import external libs and raise if not found
LanceDB implements `OpenClipEmeddingFunction` class that suppports multi-modal seach. Here's the implementation that you can use as a reference to build your own multi-modal embedding functions.
There are various embedding functions available out of the box with LanceDB to manage your embeddings implicitly. We're actively working on adding other popular embedding APIs and models.
# 📚 Available Embedding Models
## Text embedding functions
Contains the text embedding functions registered by default.
There are various embedding functions available out of the box with LanceDB to manage your embeddings implicitly. We're actively working on adding other popular embedding APIs and models. 🚀
* Embedding functions have an inbuilt rate limit handler wrapper for source and query embedding function calls that retry with exponential backoff.
* Each `EmbeddingFunction` implementation automatically takes `max_retries` as an argument which has the default value of 7.
Before jumping on the list of available models, let's understand how to get an embedding model initialized and configured to use in our code:
### Sentence transformers
Allows you to set parameters when registering a `sentence-transformers` object.
!!! info
Sentence transformer embeddings are normalized by default. It is recommended to use normalized embeddings for similarity search.
| Parameter | Type | Default Value | Description |
|---|---|---|---|
| `name` | `str` | `all-MiniLM-L6-v2` | The name of the model |
| `device` | `str` | `cpu` | The device to run the model on (can be `cpu` or `gpu`) |
| `normalize` | `bool` | `True` | Whether to normalize the input text before feeding it to the model |
??? "Check out available sentence-transformer models here!"
You can also load many other model architectures from the library. For example models from sources such as BAAI, nomic, salesforce research, etc.
See this HF hub page for all [supported models](https://huggingface.co/models?library=sentence-transformers).
!!! note "BAAI Embeddings example"
Here is an example that uses BAAI embedding model from the HuggingFace Hub [supported models](https://huggingface.co/models?library=sentence-transformers)
!!! example "Example usage"
```python
import lancedb
from lancedb.pydantic import LanceModel, Vector
from lancedb.embeddings import get_registry
db = lancedb.connect("/tmp/db")
model = get_registry().get("sentence-transformers").create(name="BAAI/bge-small-en-v1.5", device="cpu")
actual = table.search(query).limit(1).to_pydantic(Words)[0]
print(actual.text)
```
Visit sentence-transformers [HuggingFace HUB](https://huggingface.co/sentence-transformers) page for more information on the available models.
### Huggingface embedding models
We offer support for all huggingface models (which can be loaded via [transformers](https://huggingface.co/docs/transformers/en/index) library). The default model is `colbert-ir/colbertv2.0` which also has its own special callout - `registry.get("colbert")`
Example usage -
```python
import lancedb
import pandas as pd
from lancedb.embeddings import get_registry
from lancedb.pydantic import LanceModel, Vector
model = get_registry().get("huggingface").create(name='facebook/bart-base')
actual = table.search(query).limit(1).to_pydantic(Words)[0]
print(actual.text)
```
### OpenAI embeddings
LanceDB registers the OpenAI embeddings function in the registry by default, as `openai`. Below are the parameters that you can customize when creating the instances:
| Parameter | Type | Default Value | Description |
|---|---|---|---|
| `name` | `str` | `"text-embedding-ada-002"` | The name of the model. |
| `dim` | `int` | Model default | For OpenAI's newer text-embedding-3 model, we can specify a dimensionality that is smaller than the 1536 size. This feature supports it |
actual = table.search(query).limit(1).to_pydantic(Words)[0]
print(actual.text)
```
### Instructor Embeddings
[Instructor](https://instructor-embedding.github.io/) is an instruction-finetuned text embedding model that can generate text embeddings tailored to any task (e.g. classification, retrieval, clustering, text evaluation, etc.) and domains (e.g. science, finance, etc.) by simply providing the task instruction, without any finetuning.
If you want to calculate customized embeddings for specific sentences, you can follow the unified template to write instructions.
!!! info
Represent the `domain` `text_type` for `task_objective`:
* `domain` is optional, and it specifies the domain of the text, e.g. science, finance, medicine, etc.
* `text_type` is required, and it specifies the encoding unit, e.g. sentence, document, paragraph, etc.
* `task_objective` is optional, and it specifies the objective of embedding, e.g. retrieve a document, classify the sentence, etc.
More information about the model can be found at the [source URL](https://github.com/xlang-ai/instructor-embedding).
| Argument | Type | Default | Description |
|---|---|---|---|
| `name` | `str` | "hkunlp/instructor-base" | The name of the model to use |
| `batch_size` | `int` | `32` | The batch size to use when generating embeddings |
| `device` | `str` | `"cpu"` | The device to use when generating embeddings |
| `show_progress_bar` | `bool` | `True` | Whether to show a progress bar when generating embeddings |
| `normalize_embeddings` | `bool` | `True` | Whether to normalize the embeddings |
| `quantize` | `bool` | `False` | Whether to quantize the model |
| `source_instruction` | `str` | `"represent the docuement for retreival"` | The instruction for the source column |
| `query_instruction` | `str` | `"represent the document for retreiving the most similar documents"` | The instruction for the query |
```python
import lancedb
from lancedb.pydantic import LanceModel, Vector
from lancedb.embeddings import get_registry, InstuctorEmbeddingFunction
texts = [{"text": "Capitalism has been dominant in the Western world since the end of feudalism, but most feel[who?] that..."},
{"text": "The disparate impact theory is especially controversial under the Fair Housing Act because the Act..."},
{"text": "Disparate impact in United States labor law refers to practices in employment, housing, and other areas that.."}]
tbl.add(texts)
```
### Gemini Embeddings
With Google's Gemini, you can represent text (words, sentences, and blocks of text) in a vectorized form, making it easier to compare and contrast embeddings. For example, two texts that share a similar subject matter or sentiment should have similar embeddings, which can be identified through mathematical comparison techniques such as cosine similarity. For more on how and why you should use embeddings, refer to the Embeddings guide.
The Gemini Embedding Model API supports various task types:
| "`retrieval_query`" | Specifies the given text is a query in a search/retrieval setting. |
| "`retrieval_document`" | Specifies the given text is a document in a search/retrieval setting. Using this task type requires a title but is automatically proided by Embeddings API |
| "`semantic_similarity`" | Specifies the given text will be used for Semantic Textual Similarity (STS). |
| "`classification`" | Specifies that the embeddings will be used for classification. |
| "`clusering`" | Specifies that the embeddings will be used for clustering. |
Usage Example:
```python
import lancedb
import pandas as pd
from lancedb.pydantic import LanceModel, Vector
from lancedb.embeddings import get_registry
model = get_registry().get("gemini-text").create()
Using cohere API requires cohere package, which can be installed using `pip install cohere`. Cohere embeddings are used to generate embeddings for text data. The embeddings can be used for various tasks like semantic search, clustering, and classification.
You also need to set the `COHERE_API_KEY` environment variable to use the Cohere API.
Supported models are:
```
* embed-english-v3.0
* embed-multilingual-v3.0
* embed-english-light-v3.0
* embed-multilingual-light-v3.0
* embed-english-v2.0
* embed-english-light-v2.0
* embed-multilingual-v2.0
```
Supported parameters (to be passed in `create` method) are:
| Parameter | Type | Default Value | Description |
|---|---|---|---|
| `name` | `str` | `"embed-english-v2.0"` | The model ID of the cohere model to use. Supported base models for Text Embeddings: embed-english-v3.0, embed-multilingual-v3.0, embed-english-light-v3.0, embed-multilingual-light-v3.0, embed-english-v2.0, embed-english-light-v2.0, embed-multilingual-v2.0 |
| `source_input_type` | `str` | `"search_document"` | The type of input data to be used for the source column. |
| `query_input_type` | `str` | `"search_query"` | The type of input data to be used for the query. |
model = get_registry().get("model_id").create(...params)
```
**This👆 line effectively creates a configured instance of an `embedding function` with `model` of choice that is ready for use.**
### AWS Bedrock Text Embedding Functions
AWS Bedrock supports multiple base models for generating text embeddings. You need to setup the AWS credentials to use this embedding function.
You can do so by using `awscli` and also add your session_token:
```shell
aws configure
aws configure set aws_session_token "<your_session_token>"
```
to ensure that the credentials are set up correctly, you can run the following command:
```shell
aws sts get-caller-identity
```
- `get_registry()` : This function call returns an instance of a `EmbeddingFunctionRegistry` object. This registry manages the registration and retrieval of embedding functions.
Supported Embedding modelIDs are:
* `amazon.titan-embed-text-v1`
* `cohere.embed-english-v3`
* `cohere.embed-multilingual-v3`
- `.get("model_id")` : This method call on the registry object and retrieves the **embedding models functions** associated with the `"model_id"` (1) .
{ .annotate }
Supported parameters (to be passed in `create` method) are:
1. Hover over the names in table below to find out the `model_id` of different embedding functions.
| Parameter | Type | Default Value | Description |
|---|---|---|---|
| **name** | str | "amazon.titan-embed-text-v1" | The model ID of the bedrock model to use. Supported base models for Text Embeddings: amazon.titan-embed-text-v1, cohere.embed-english-v3, cohere.embed-multilingual-v3 |
| **region** | str | "us-east-1" | Optional name of the AWS Region in which the service should be called (e.g., "us-east-1"). |
| **profile_name** | str | None | Optional name of the AWS profile to use for calling the Bedrock service. If not specified, the default profile will be used. |
| **assumed_role** | str | None | Optional ARN of an AWS IAM role to assume for calling the Bedrock service. If not specified, the current active credentials will be used. |
| **role_session_name** | str | "lancedb-embeddings" | Optional name of the AWS IAM role session to use for calling the Bedrock service. If not specified, a "lancedb-embeddings" name will be used. |
| **runtime** | bool | True | Optional choice of getting different client to perform operations with the Amazon Bedrock service. |
| **max_retries** | int | 7 | Optional number of retries to perform when a request fails. |
- `.create(...params)` : This method call is on the object returned by the `get` method. It instantiates an embedding model function using the **specified parameters**.
Usage Example:
??? question "What parameters does the `.create(...params)` method accepts?"
**Checkout the documentation of specific embedding models (links in the table below👇) to know what parameters it takes**.
```python
import lancedb
from lancedb.pydantic import LanceModel, Vector
from lancedb.embeddings import get_registry
!!! tip "Moving on"
Now that we know how to get the **desired embedding model** and use it in our code, let's explore the comprehensive **list** of embedding models **supported by LanceDB**, in the tables below.
model = get_registry().get("bedrock-text").create()
## Text Embedding Functions 📝
These functions are registered by default to handle text embeddings.
- 🔄 **Embedding functions** have an inbuilt rate limit handler wrapper for source and query embedding function calls that retry with **exponential backoff**.
- 🌕 Each `EmbeddingFunction` implementation automatically takes `max_retries` as an argument which has the default value of 7.
tbl.add(df)
rs = tbl.search("hello").limit(1).to_pandas()
```
🌟 **Available Text Embeddings**
## Multi-modal embedding functions
Multi-modal embedding functions allow you to query your table using both images and text.
### OpenClip embeddings
We support CLIP model embeddings using the open source alternative, [open-clip](https://github.com/mlfoundations/open_clip) which supports various customizations. It is registered as `open-clip` and supports the following customizations:
| Parameter | Type | Default Value | Description |
|---|---|---|---|
| `name` | `str` | `"ViT-B-32"` | The name of the model. |
| `pretrained` | `str` | `"laion2b_s34b_b79k"` | The name of the pretrained model to load. |
| `device` | `str` | `"cpu"` | The device to run the model on. Can be `"cpu"` or `"gpu"`. |
| `batch_size` | `int` | `64` | The number of images to process in a batch. |
| `normalize` | `bool` | `True` | Whether to normalize the input images before feeding them to the model. |
This embedding function supports ingesting images as both bytes and urls. You can query them using both test and other images.
!!! info
LanceDB supports ingesting images directly from accessible links.
```python
import lancedb
from lancedb.pydantic import LanceModel, Vector
from lancedb.embeddings import get_registry
db = lancedb.connect(tmp_path)
func = get_registry.get("open-clip").create()
class Images(LanceModel):
label: str
image_uri: str = func.SourceField() # image uri as the source
image_bytes: bytes = func.SourceField() # image bytes as the source
We have support for [imagebind](https://github.com/facebookresearch/ImageBind) model embeddings. You can download our version of the packaged model via - `pip install imagebind-packaged==0.1.2`.
This function is registered as `imagebind` and supports Audio, Video and Text modalities(extending to Thermal,Depth,IMU data):
| Parameter | Type | Default Value | Description |
|---|---|---|---|
| `name` | `str` | `"imagebind_huge"` | Name of the model. |
| `device` | `str` | `"cpu"` | The device to run the model on. Can be `"cpu"` or `"gpu"`. |
| `normalize` | `bool` | `False` | set to `True` to normalize your inputs before model ingestion. |
Below is an example demonstrating how the API works:
query_image = "./assets/dog_image2.jpg" #download an image and enter that path here
actual = table.search(query_image).limit(1).to_pydantic(ImageBindModel)[0]
print(actual.text == "dog")
```
#### audio search
```python
query_audio = "./assets/car_audio2.wav" #download an audio clip and enter path here
actual = table.search(query_audio).limit(1).to_pydantic(ImageBindModel)[0]
print(actual.text == "car")
```
#### Text search
You can add any input query and fetch the result as follows:
```python
query = "an animal which flies and tweets"
actual = table.search(query).limit(1).to_pydantic(ImageBindModel)[0]
print(actual.text == "bird")
```
If you have any questions about the embeddings API, supported models, or see a relevant model missing, please raise an issue [on GitHub](https://github.com/lancedb/lancedb/issues).
### Jina Embeddings
Jina embeddings can also be used to embed both text and image data, only some of the models support image data and you can check the list
under [https://jina.ai/embeddings/](https://jina.ai/embeddings/)
Supported parameters (to be passed in `create` method) are:
| Parameter | Type | Default Value | Description |
|---|---|---|---|
| `name` | `str` | `"jina-clip-v1"` | The model ID of the jina model to use |
Usage Example:
```python
import os
import requests
import lancedb
from lancedb.pydantic import LanceModel, Vector
from lancedb.embeddings import get_registry
import pandas as pd
os.environ['JINA_API_KEY'] = 'jina_*'
db = lancedb.connect("~/.lancedb")
func = get_registry().get("jina").create()
| **Embedding** :material-information-outline:{ title="Hover over the name to find out the model_id" } | **Description** | **Documentation** |
|-----------|-------------|---------------|
| [**Sentence Transformers**](available_embedding_models/text_embedding_functions/sentence_transformers.md "sentence-transformers") | 🧠 **SentenceTransformers** is a Python framework for state-of-the-art sentence, text, and image embeddings. | [<img src="https://raw.githubusercontent.com/lancedb/assets/main/docs/assets/logos/sbert_2.png" alt="Sentence Transformers Icon" width="90" height="35">](available_embedding_models/text_embedding_functions/sentence_transformers.md)|
| [**Huggingface Models**](available_embedding_models/text_embedding_functions/huggingface_embedding.md "huggingface") |🤗 We offer support for all **Huggingface** models. The default model is `colbert-ir/colbertv2.0`. | [<img src="https://raw.githubusercontent.com/lancedb/assets/main/docs/assets/logos/hugging_face.png" alt="Huggingface Icon" width="130" height="35">](available_embedding_models/text_embedding_functions/huggingface_embedding.md) |
| [**Ollama Embeddings**](available_embedding_models/text_embedding_functions/ollama_embedding.md "ollama") | 🔍 Generate embeddings via the **Ollama** python library. Ollama supports embedding models, making it possible to build RAG apps. | [<img src="https://raw.githubusercontent.com/lancedb/assets/main/docs/assets/logos/Ollama.png" alt="Ollama Icon" width="110" height="35">](available_embedding_models/text_embedding_functions/ollama_embedding.md)|
| [**OpenAI Embeddings**](available_embedding_models/text_embedding_functions/openai_embedding.md "openai")| 🔑 **OpenAI’s** text embeddings measure the relatedness of text strings. **LanceDB** supports state-of-the-art embeddings from OpenAI. | [<img src="https://raw.githubusercontent.com/lancedb/assets/main/docs/assets/logos/openai.png" alt="OpenAI Icon" width="100" height="35">](available_embedding_models/text_embedding_functions/openai_embedding.md)|
| [**Instructor Embeddings**](available_embedding_models/text_embedding_functions/instructor_embedding.md "instructor") | 📚 **Instructor**: An instruction-finetuned text embedding model that can generate text embeddings tailored to any task and domains by simply providing the task instruction, without any finetuning. | [<img src="https://raw.githubusercontent.com/lancedb/assets/main/docs/assets/logos/instructor_embedding.png" alt="Instructor Embedding Icon" width="140" height="35">](available_embedding_models/text_embedding_functions/instructor_embedding.md) |
| [**Gemini Embeddings**](available_embedding_models/text_embedding_functions/gemini_embedding.md "gemini-text") | 🌌 Google’s Gemini API generates state-of-the-art embeddings for words, phrases, and sentences. | [<img src="https://raw.githubusercontent.com/lancedb/assets/main/docs/assets/logos/gemini.png" alt="Gemini Icon" width="95" height="35">](available_embedding_models/text_embedding_functions/gemini_embedding.md) |
| [**Cohere Embeddings**](available_embedding_models/text_embedding_functions/cohere_embedding.md "cohere") | 💬 This will help you get started with **Cohere** embedding models using LanceDB. Using cohere API requires cohere package. Install it via `pip`. | [<img src="https://raw.githubusercontent.com/lancedb/assets/main/docs/assets/logos/cohere.png" alt="Cohere Icon" width="140" height="35">](available_embedding_models/text_embedding_functions/cohere_embedding.md) |
| [**Jina Embeddings**](available_embedding_models/text_embedding_functions/jina_embedding.md "jina") | 🔗 World-class embedding models to improve your search and RAG systems. You will need **jina api key**. | [<img src="https://raw.githubusercontent.com/lancedb/assets/main/docs/assets/logos/jina.png" alt="Jina Icon" width="90" height="35">](available_embedding_models/text_embedding_functions/jina_embedding.md) |
| [ **AWS Bedrock Functions**](available_embedding_models/text_embedding_functions/aws_bedrock_embedding.md "bedrock-text") | ☁️ AWS Bedrock supports multiple base models for generating text embeddings. You need to setup the AWS credentials to use this embedding function. | [<img src="https://raw.githubusercontent.com/lancedb/assets/main/docs/assets/logos/aws_bedrock.png" alt="AWS Bedrock Icon" width="120" height="35">](available_embedding_models/text_embedding_functions/aws_bedrock_embedding.md) |
| [**IBM Watsonx.ai**](available_embedding_models/text_embedding_functions/ibm_watsonx_ai_embedding.md "watsonx") | 💡 Generate text embeddings using IBM's watsonx.ai platform. **Note**: watsonx.ai library is an optional dependency. | [<img src="https://raw.githubusercontent.com/lancedb/assets/main/docs/assets/logos/watsonx.png" alt="Watsonx Icon" width="140" height="35">](available_embedding_models/text_embedding_functions/ibm_watsonx_ai_embedding.md) |
| [**VoyageAI Embeddings**](available_embedding_models/text_embedding_functions/voyageai_embedding.md "voyageai") | 🌕 Voyage AI provides cutting-edge embedding and rerankers. This will help you get started with **VoyageAI** embedding models using LanceDB. Using voyageai API requires voyageai package. Install it via `pip`. | [<img src="https://www.voyageai.com/logo.svg" alt="VoyageAI Icon" width="140" height="35">](available_embedding_models/text_embedding_functions/voyageai_embedding.md) |
class Images(LanceModel):
label: str
image_uri: str = func.SourceField() # image uri as the source
image_bytes: bytes = func.SourceField() # image bytes as the source
Multi-modal embedding functions allow you to query your table using both images and text. 💬🖼️
🌐 **Available Multi-modal Embeddings**
| Embedding :material-information-outline:{ title="Hover over the name to find out the model_id" } | Description | Documentation |
|-----------|-------------|---------------|
| [**OpenClip Embeddings**](available_embedding_models/multimodal_embedding_functions/openclip_embedding.md "open-clip") | 🎨 We support CLIP model embeddings using the open source alternative, **open-clip** which supports various customizations. | [<img src="https://raw.githubusercontent.com/lancedb/assets/main/docs/assets/logos/openclip_github.png" alt="openclip Icon" width="150" height="35">](available_embedding_models/multimodal_embedding_functions/openclip_embedding.md) |
| [**Imagebind Embeddings**](available_embedding_models/multimodal_embedding_functions/imagebind_embedding.md "imageind") | 🌌 We have support for **imagebind model embeddings**. You can download our version of the packaged model via - `pip install imagebind-packaged==0.1.2`. | [<img src="https://raw.githubusercontent.com/lancedb/assets/main/docs/assets/logos/imagebind_meta.png" alt="imagebind Icon" width="150" height="35">](available_embedding_models/multimodal_embedding_functions/imagebind_embedding.md)|
| [**Jina Multi-modal Embeddings**](available_embedding_models/multimodal_embedding_functions/jina_multimodal_embedding.md "jina") | 🔗 **Jina embeddings** can also be used to embed both **text** and **image** data, only some of the models support image data and you can check the detailed documentation. 👉 | [<img src="https://raw.githubusercontent.com/lancedb/assets/main/docs/assets/logos/jina.png" alt="jina Icon" width="90" height="35">](available_embedding_models/multimodal_embedding_functions/jina_multimodal_embedding.md) |
!!! note
If you'd like to request support for additional **embedding functions**, please feel free to open an issue on our LanceDB [GitHub issue page](https://github.com/lancedb/lancedb/issues).
@@ -2,8 +2,8 @@ Representing multi-modal data as vector embeddings is becoming a standard practi
For this purpose, LanceDB introduces an **embedding functions API**, that allow you simply set up once, during the configuration stage of your project. After this, the table remembers it, effectively making the embedding functions *disappear in the background* so you don't have to worry about manually passing callables, and instead, simply focus on the rest of your data engineering pipeline.
!!! Note "LanceDB cloud doesn't support embedding functions yet"
LanceDB Cloud does not support embedding functions yet. You need to generate embeddings before ingesting into the table or querying.
!!! Note "Embedding functions on LanceDB cloud"
When using embedding functions with LanceDB cloud, the embeddings will be generated on the source device and sent to the cloud. This means that the source device must have the necessary resources to generate the embeddings.
!!! warning
Using the embedding function registry means that you don't have to explicitly generate the embeddings yourself.
@@ -99,34 +99,32 @@ LanceDB registers the Sentence Transformers embeddings function in the registry
Coming Soon!
### Jina Embeddings
LanceDB registers the JinaAI embeddings function in the registry as `jina`. You can pass any supported model name to the `create`. By default it uses `"jina-clip-v1"`.
`jina-clip-v1` can handle both text and images and other models only support `text`.
You need to pass `JINA_API_KEY` in the environment variable or pass it as `api_key` to `create` method.
### Embedding function with LanceDB cloud
Embedding functions are now supported on LanceDB cloud. The embeddings will be generated on the source device and sent to the cloud. This means that the source device must have the necessary resources to generate the embeddings. Here's an example using the OpenAI embedding function:
The term **dimension** is a synonym for the number of elements in a feature vector. Each feature can be thought of as a different axis in a geometric space.
High-dimensional data means there are many features(or attributes) in the data.
!!! example
1. An image is a data point and it might have thousands of dimensions because each pixel could be considered as a feature.
2. Text data, when represented by each word or character, can also lead to high dimensions, especially when considering all possible words in a language.
Embedding captures **meaning and relationships** within data by mapping high-dimensional data into a lower-dimensional space. It captures it by placing inputs that are more **similar in meaning** closer together in the **embedding space**.
## What are Vector Embeddings?
Vector embeddings is a way to convert complex data, like text, images, or audio into numerical coordinates (called vectors) that can be plotted in an n-dimensional space(embedding space).
The closer these data points are related in the real world, the closer their corresponding numerical coordinates (vectors) will be to each other in the embedding space. This proximity in the embedding space reflects their semantic similarities, allowing machines to intuitively understand and process the data in a way that mirrors human perception of relationships and meaning.
In a way, it captures the most important aspects of the data while ignoring the less important ones. As a result, tasks like searching for related content or identifying patterns become more efficient and accurate, as the embeddings make it possible to quantify how **closely related** different **data points** are and **reduce** the **computational complexity**.
??? question "Are vectors and embeddings the same thing?"
When we say “vectors” we mean - **list of numbers** that **represents the data**.
When we say “embeddings” we mean - **list of numbers** that **capture important details and relationships**.
Although the terms are often used interchangeably, “embeddings” highlight how the data is represented with meaning and structure, while “vector” simply refers to the numerical form of that representation.
## Embedding vs Indexing
We already saw that creating **embeddings** on data is a method of creating **vectors** for a **n-dimensional embedding space** that captures the meaning and relationships inherent in the data.
Once we have these **vectors**, indexing comes into play. Indexing is a method of organizing these vector embeddings, that allows us to quickly and efficiently locate and retrieve them from the entire dataset of vector embeddings.
## What types of data/objects can be embedded?
The following are common types of data that can be embedded:
1.**Text**: Text data includes sentences, paragraphs, documents, or any written content.
2.**Images**: Image data encompasses photographs, illustrations, or any visual content.
3.**Audio**: Audio data includes sounds, music, speech, or any auditory content.
4.**Video**: Video data consists of moving images and sound, which can convey complex information.
Large datasets of multi-modal data (text, audio, images, etc.) can be converted into embeddings with the appropriate model.
!!! tip "LanceDB vs Other traditional Vector DBs"
While many vector databases primarily focus on the storage and retrieval of vector embeddings, **LanceDB** uses **Lance file format** (operates on a disk-based architecture), which allows for the storage and management of not just embeddings but also **raw file data (bytes)**. This capability means that users can integrate various types of data, including images and text, alongside their vector embeddings in a unified system.
With the ability to store both vectors and associated file data, LanceDB enhances the querying process. Users can perform semantic searches that not only retrieve similar embeddings but also access related files and metadata, thus streamlining the workflow.
## How does embedding works?
As mentioned, after creating embedding, each data point is represented as a vector in a n-dimensional space (embedding space). The dimensionality of this space can vary depending on the complexity of the data and the specific embedding technique used.
Points that are close to each other in vector space are considered similar (or appear in similar contexts), and points that are far away are considered dissimilar. To quantify this closeness, we use distance as a metric which can be measured in the following way -
1.**Euclidean Distance (l2)**: It calculates the straight-line distance between two points (vectors) in a multidimensional space.
2.**Cosine Similarity**: It measures the cosine of the angle between two vectors, providing a normalized measure of similarity based on their direction.
3.**Dot product**: It is calculated as the sum of the products of their corresponding components. To measure relatedness it considers both the magnitude and direction of the vectors.
## How do you create and store vector embeddings for your data?
1.**Creating embeddings**: Choose an embedding model, it can be a pre-trained model (open-source or commercial) or you can train a custom embedding model for your scenario. Then feed your preprocessed data into the chosen model to obtain embeddings.
??? question "Popular choices for embedding models"
For text data, popular choices are OpenAI’s text-embedding models, Google Gemini text-embedding models, Cohere’s Embed models, and SentenceTransformers, etc.
For image data, popular choices are CLIP (Contrastive Language–Image Pretraining), Imagebind embeddings by meta (supports audio, video, and image), and Jina multi-modal embeddings, etc.
2.**Storing vector embeddings**: This effectively requires **specialized databases** that can handle the complexity of vector data, as traditional databases often struggle with this task. Vector databases are designed specifically for storing and querying vector embeddings. They optimize for efficient nearest-neighbor searches and provide built-in indexing mechanisms.
!!! tip "Why LanceDB"
LanceDB **automates** the entire process of creating and storing embeddings for your data. LanceDB allows you to define and use **embedding functions**, which can be **pre-trained models** or **custom models**.
This enables you to **generate** embeddings tailored to the nature of your data (e.g., text, images) and **store** both the **original data** and **embeddings** in a **structured schema** thus providing efficient querying capabilities for similarity searches.
Let's quickly [get started](./index.md) and learn how to manage embeddings in LanceDB.
## Bonus: As a developer, what you can create using embeddings?
As a developer, you can create a variety of innovative applications using vector embeddings. Check out the following -
<divclass="grid cards"markdown>
-__Chatbots__
---
Develop chatbots that utilize embeddings to retrieve relevant context and generate coherent, contextually aware responses to user queries.
[:octicons-arrow-right-24: Check out examples](../examples/python_examples/chatbot.md)
-__Recommendation Systems__
---
Develop systems that recommend content (such as articles, movies, or products) based on the similarity of keywords and descriptions, enhancing user experience.
[:octicons-arrow-right-24: Check out examples](../examples/python_examples/recommendersystem.md)
-__Vector Search__
---
Build powerful applications that harness the full potential of semantic search, enabling them to retrieve relevant data quickly and effectively.
[:octicons-arrow-right-24: Check out examples](../examples/python_examples/vector_search.md)
-__RAG Applications__
---
Combine the strengths of large language models (LLMs) with retrieval-based approaches to create more useful applications.
[:octicons-arrow-right-24: Check out examples](../examples/python_examples/rag.md)
-__Many more examples__
---
Explore applied examples available as Colab notebooks or Python scripts to integrate into your applications.
To help you get started, we provide some examples, projects and applications that use the LanceDB Python API. You can always find the latest examples in our [VectorDB Recipes](https://github.com/lancedb/vectordb-recipes) repository.
To help you get started, we provide some examples, projects, and applications that use the LanceDB Python API. These examples are designed to get you right into the code with minimal introduction, enabling you to move from an idea to a proof of concept in minutes.
| Example | Interactive Envs | Scripts |
|-------- | ---------------- | ------ |
| | | |
| [Youtube transcript search bot](https://github.com/lancedb/vectordb-recipes/tree/main/examples/youtube_bot/) | <ahref="https://colab.research.google.com/github/lancedb/vectordb-recipes/blob/main/examples/youtube_bot/main.ipynb"><imgsrc="https://colab.research.google.com/assets/colab-badge.svg"alt="Open In Colab"></a>| [](https://github.com/lancedb/vectordb-recipes/tree/main/examples/youtube_bot/main.py)|
| [Movie Recommender](https://github.com/lancedb/vectordb-recipes/tree/main/examples/movie-recommender/) | <ahref="https://colab.research.google.com/github/lancedb/vectordb-recipes/blob/main/examples/movie-recommender/main.ipynb"><imgsrc="https://colab.research.google.com/assets/colab-badge.svg"alt="Open In Colab"></a> | [](https://github.com/lancedb/vectordb-recipes/tree/main/examples/movie-recommender/main.py) |
| [Audio Search](https://github.com/lancedb/vectordb-recipes/tree/main/examples/audio_search/) | <ahref="https://colab.research.google.com/github/lancedb/vectordb-recipes/blob/main/examples/audio_search/main.ipynb"><imgsrc="https://colab.research.google.com/assets/colab-badge.svg"alt="Open In Colab"></a> | [](https://github.com/lancedb/vectordb-recipes/tree/main/examples/audio_search/main.py) |
| [Multimodal Image + Text Search](https://github.com/lancedb/vectordb-recipes/tree/main/examples/multimodal_search/) | <ahref="https://colab.research.google.com/github/lancedb/vectordb-recipes/blob/main/examples/multimodal_search/main.ipynb"><imgsrc="https://colab.research.google.com/assets/colab-badge.svg"alt="Open In Colab"></a> | [](https://github.com/lancedb/vectordb-recipes/tree/main/examples/multimodal_search/main.py) |
| [Evaluating Prompts with Prompttools](https://github.com/lancedb/vectordb-recipes/tree/main/examples/prompttools-eval-prompts/) | <ahref="https://colab.research.google.com/github/lancedb/vectordb-recipes/blob/main/examples/prompttools-eval-prompts/main.ipynb"><imgsrc="https://colab.research.google.com/assets/colab-badge.svg"alt="Open In Colab"></a> | |
You can find the latest examples in our [VectorDB Recipes](https://github.com/lancedb/vectordb-recipes) repository.
**Introduction**
Explore applied examples available as Colab notebooks or Python scripts to integrate into your applications. You can also checkout our blog posts related to the particular example for deeper understanding.
| [**Build from Scratch with LanceDB** 🛠️🚀](python_examples/build_from_scratch.md) | Start building your **GenAI applications** from the **ground up** using **LanceDB's** efficient vector-based document retrieval capabilities! Get started quickly with a solid foundation. |
| [**Multimodal Search with LanceDB** 🤹♂️🔍](python_examples/multimodal.md) | Combine **text** and **image queries** to find the most relevant results using **LanceDB’s multimodal** capabilities. Leverage the efficient vector-based similarity search. |
| [**RAG (Retrieval-Augmented Generation) with LanceDB** 🔓🧐](python_examples/rag.md) | Build RAG (Retrieval-Augmented Generation) with **LanceDB** for efficient **vector-based information retrieval** and more accurate responses from AI. |
| [**Vector Search: Efficient Retrieval** 🔓👀](python_examples/vector_search.md) | Use **LanceDB's** vector search capabilities to perform efficient and accurate **similarity searches**, enabling rapid discovery and retrieval of relevant documents in Large datasets. |
| [**Chatbot applications with LanceDB** 🤖](python_examples/chatbot.md) | Create **chatbots** that retrieves relevant context for **coherent and context-aware replies**, enhancing user experience through advanced conversational AI. |
| [**Evaluation: Assessing Text Performance with Precision** 📊💡](python_examples/evaluations.md) | Develop **evaluation** applications that allows you to input reference and candidate texts to **measure** their performance across various metrics. |
| [**AI Agents: Intelligent Collaboration** 🤖](python_examples/aiagent.md) | Enable **AI agents** to communicate and collaborate efficiently through dense vector representations, achieving shared goals seamlessly. |
| [**Recommender Systems: Personalized Discovery** 🍿📺](python_examples/recommendersystem.md) | Deliver **personalized experiences** by efficiently storing and querying item embeddings with **LanceDB's** powerful vector database capabilities. |
| **Miscellaneous Examples🌟** | Find other **unique examples** and **creative solutions** using **LanceDB**, showcasing the flexibility and broad applicability of the platform. |
| [YOLOExplorer](https://github.com/lancedb/yoloexplorer) | Iterate on your YOLO / CV datasets using SQL, Vector semantic search, and more within seconds | 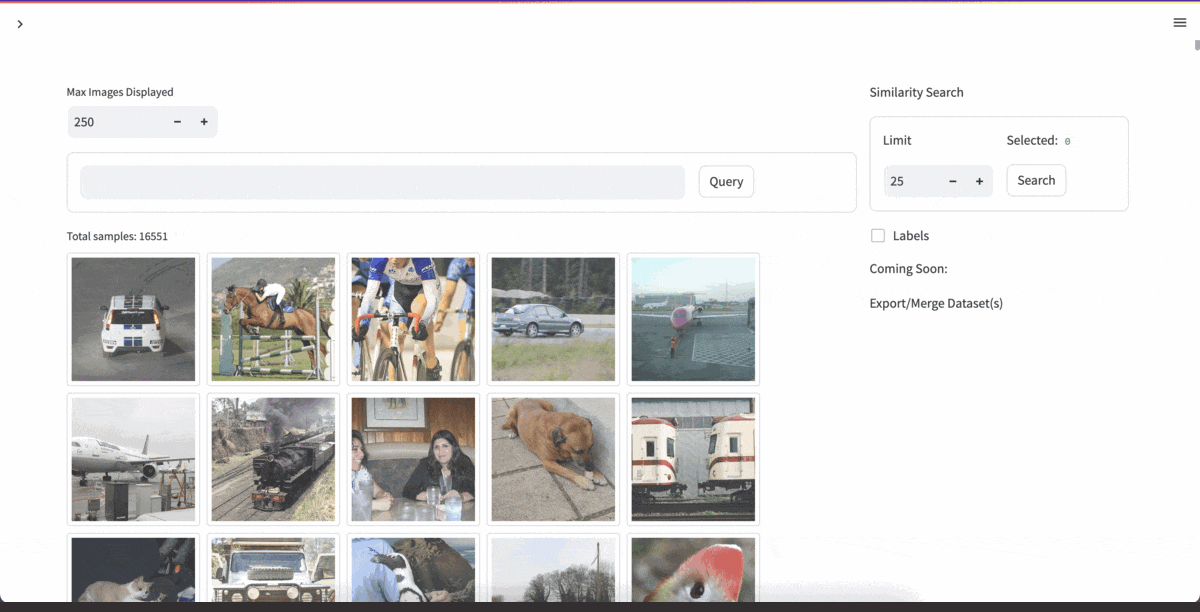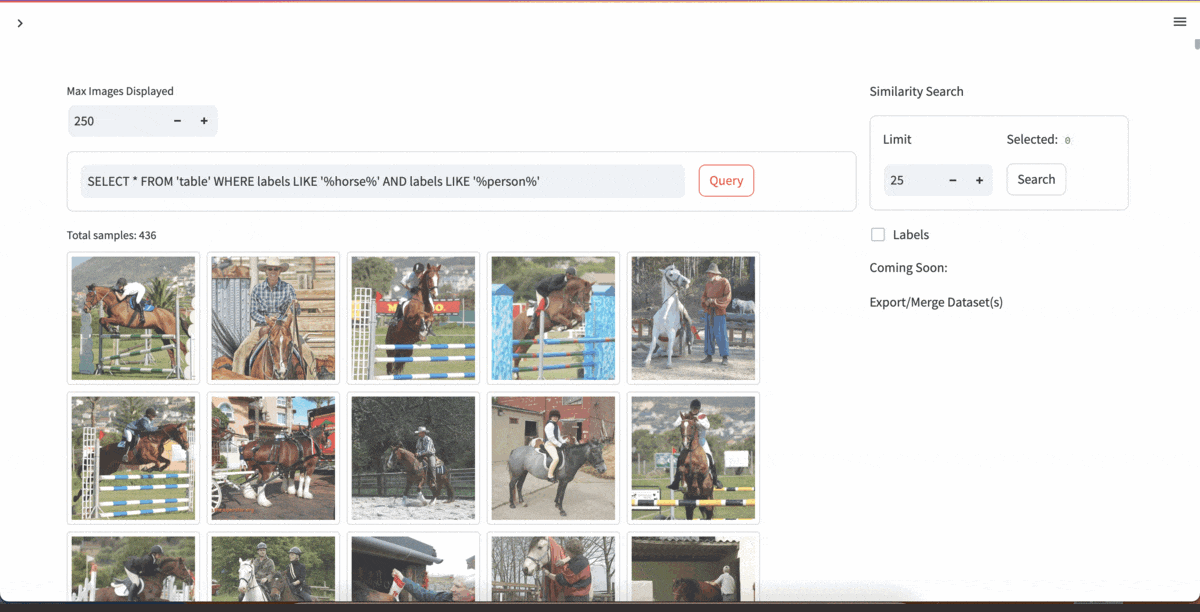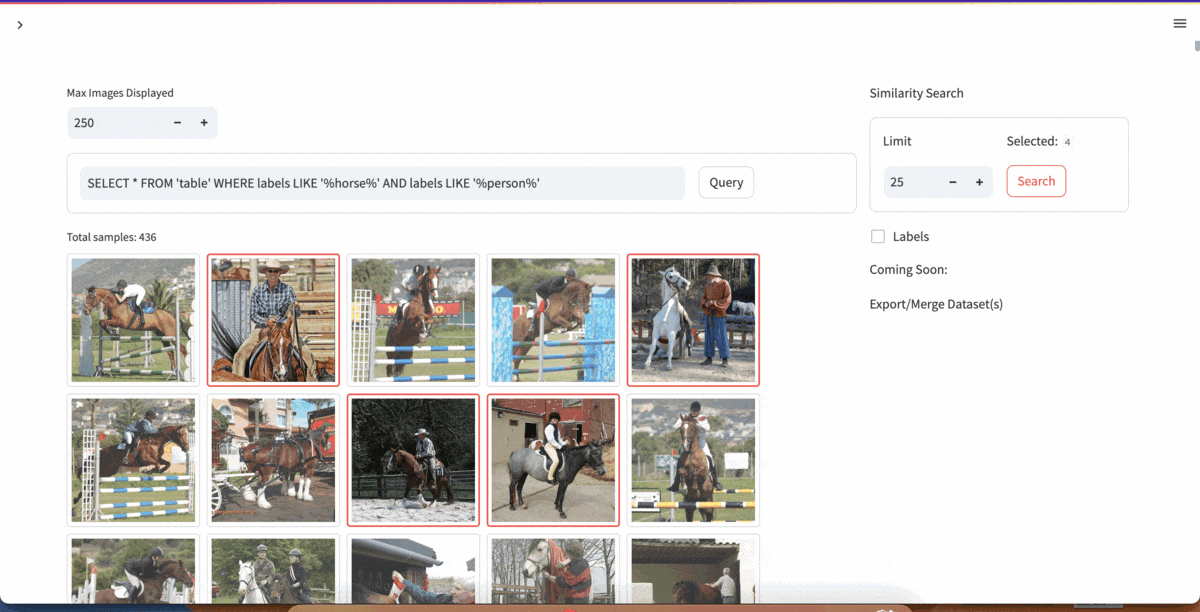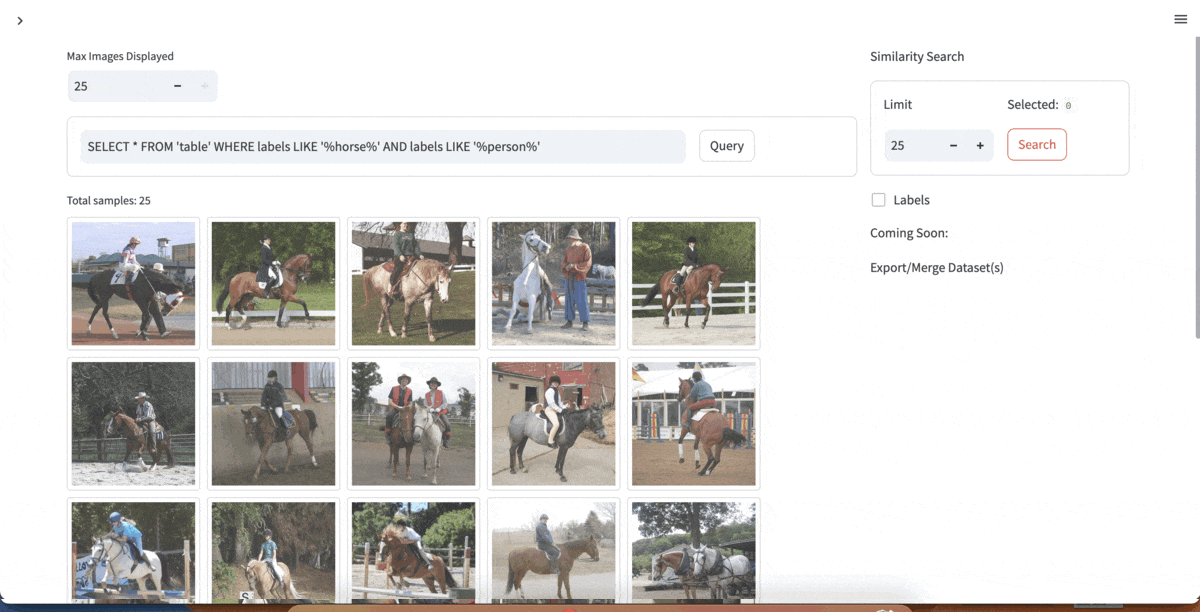 |
| [Website Chatbot (Deployable Vercel Template)](https://github.com/lancedb/lancedb-vercel-chatbot) | Create a chatbot from the sitemap of any website/docs of your choice. Built using vectorDB serverless native javascript package. |  |
!!! tip "Hosted LanceDB"
If you want S3 cost-efficiency and local performance via a simple serverless API, checkout **LanceDB Cloud**. For private deployments, high performance at extreme scale, or if you have strict security requirements, talk to us about **LanceDB Enterprise**. [Learn more](https://docs.lancedb.com/)
Think of a platform where AI Agents can seamlessly exchange information, coordinate over tasks, and achieve shared targets with great efficiency💻📈.
## Vector-Based Coordination: The Technical Advantage
Leveraging LanceDB's vector-based capabilities, we can enable **AI agents 🤖** to communicate and collaborate through dense vector representations. AI agents can exchange information, coordinate on a task or work towards a common goal, just by giving queries📝.
| **AI Agents** | **Description** | **Links** |
|:--------------|:----------------|:----------|
| **AI Agents: Reducing Hallucinationt📊** | 🤖💡 **Reduce AI hallucinations** using Critique-Based Contexting! Learn by Simplifying and Automating tedious workflows by going through fitness trainer agent example.💪 | [][hullucination_github] <br>[][hullucination_colab] <br>[][hullucination_python] <br>[][hullucination_ghost] |
| **AI Trends Searcher: CrewAI🔍️** | 🔍️ Learn about **CrewAI Agents** ! Utilize the features of CrewAI - Role-based Agents, Task Management, and Inter-agent Delegation ! Make AI agents work together to do tricky stuff 😺| [][trend_github] <br>[][trend_colab] <br>[][trend_ghost] |
| **SuperAgent Autogen🤖** | 💻 AI interactions with the Super Agent! Integrating **Autogen**, **LanceDB**, **LangChain**, **LiteLLM**, and **Ollama** to create AI agent that excels in understanding and processing complex queries.🤖 | [][superagent_github] <br>[][superagent_colab] |
Start building your GenAI applications from the ground up using **LanceDB's** efficient vector-based document retrieval capabilities! 📑
**Get Started in Minutes ⏱️**
These examples provide a solid foundation for building your own GenAI applications using LanceDB. Jump from idea to **proof of concept** quickly with applied examples. Get started and see what you can create! 💻
| **Build From Scratch** | **Description** | **Links** |
| **Build RAG from Scratch🚀💻** | 📝 Create a **Retrieval-Augmented Generation** (RAG) model from scratch using LanceDB. | [](https://github.com/lancedb/vectordb-recipes/tree/main/tutorials/RAG-from-Scratch)<br>[]() |
| **Local RAG from Scratch with Llama3🔥💡** | 🐫 Build a local RAG model using **Llama3** and **LanceDB** for fast and efficient text generation. | [](https://github.com/lancedb/vectordb-recipes/tree/main/tutorials/Local-RAG-from-Scratch)<br>[](https://github.com/lancedb/vectordb-recipes/blob/main/tutorials/Local-RAG-from-Scratch/rag.py) |
| **Multi-Head RAG from Scratch📚💻** | 🤯 Develop a **Multi-Head RAG model** from scratch, enabling generation of text based on multiple documents. | [](https://github.com/lancedb/vectordb-recipes/tree/main/tutorials/Multi-Head-RAG-from-Scratch)<br>[](https://github.com/lancedb/vectordb-recipes/tree/main/tutorials/Multi-Head-RAG-from-Scratch) |
Some files were not shown because too many files have changed in this diff
Show More
Reference in New Issue
Block a user
Blocking a user prevents them from interacting with repositories, such as opening or commenting on pull requests or issues. Learn more about blocking a user.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}